基于注意力機制的漸進式圖像復制粘貼篡改檢測
2024-08-23 00:00:00劉亮何雯晶張磊
四川大學學報(自然科學版) 2024年4期


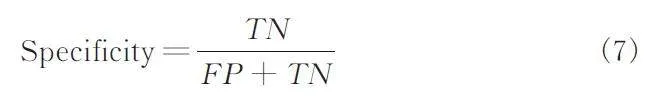
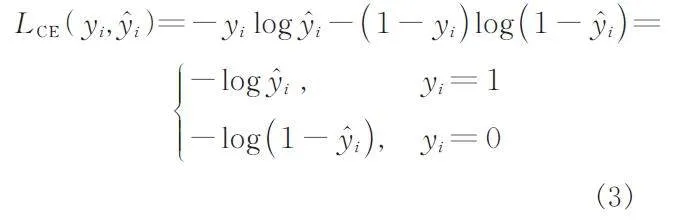
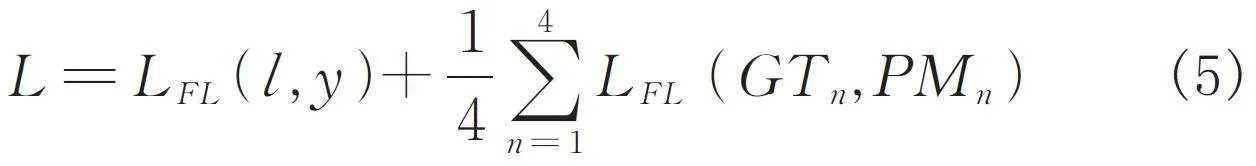

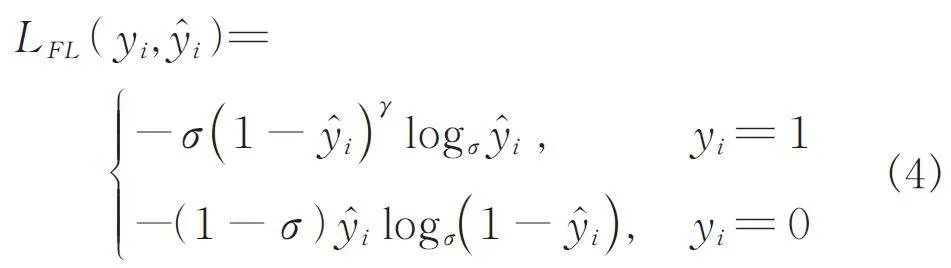
摘要: 針對圖像復制粘貼篡改檢測深度學習方法中特征提取階段信息丟失問題,本文提出基于注意力機制的漸進式圖像復制粘貼篡改檢測模型. 該模型在特征提取階段不同于先下采樣得到強語義信息,再上采樣恢復高分辨率恢復位置信息的常見結構,而是整個過程保持并行多分辨率,不同分辨率分支之間信息交互,同時達到強語義信息和精準位置信息的目的. 特征提取的關鍵是:首先給出不同分辨率特征圖;然后結合空間與通道的注意力機制由低到高漸進式進行特征連接,生成對應分辨率下的子掩碼;同時,在圖像級檢測中,特征按分辨率由高到低逐漸連接豐富信息;最后引入焦點損失來降低類別不平衡對模型帶來的影響,對不同分辨率下的掩碼進行同等權重監督. 實驗結果表明,論文提出的檢測方法在公開數據集像素級與圖像級的檢測結果中優于現有方法,驗證了注意力機制和漸進式特征連接的有效性.
關鍵詞: 復制粘貼; 篡改檢測; 注意力機制; 特征連接
中圖分類號: TP391. ;41 文獻標志碼: A DOI: 10. 19907/j. 0490-6756. 2024. 042002
1 引言
數字圖像在現代社會常作為娛樂、信息或證據的載體. 然而,隨著圖像編輯軟件的編輯水平的發展和易用性的提升,對數字圖像進行篡改越來越容易,圖像的真實性和可信度受到了極大的影響. 復制粘貼篡改是最常見也最容易操作的數字圖像篡改方式[1]. 復制粘貼篡改是指將圖像中某部分內容復制后粘貼到該圖像的其他位置,從而隱藏或添加某些對象[2]. 這種篡改可能會改變圖像傳達的信息或意義,甚至造成誤導或欺騙. 復制粘貼篡改檢測的難點在于處理各種攻擊和干擾,例如幾何變換、壓縮、濾波、隨機噪聲等,這些操作會破壞或掩蓋篡改痕跡[3]. 復制粘貼篡改檢測(CopymoveForgery Detection, CMFD)不需要任何先驗知識或額外信息,只依賴于圖像本身. 復制粘貼篡改檢測的目標是找出圖像中的篡改區域,通常輸出與被檢測圖像等大的掩碼來標識篡改區域.
檢測圖像復制粘貼篡改的方法主要分為2 大類:基于特征和基于深度學習[4]. 基于特征提取的方法是指從圖像中提取表示圖像內容或結構的特征,并利用特征之間的相似性或差異性來檢測篡改區域. 這類方法可以分為基于塊的方法和基于關鍵點的方法[5] . 基于塊的方法原理是將圖像劃分為重疊或不重疊的小塊進行特征提取和比對.基于關鍵點的方法是指從圖像中檢測出具有顯著性或不變性的關鍵點,并對每個關鍵點進行特征提取和匹配[6]. 基于特征提取的方法通常檢測速度較快,但也存在局限性,例如對特征選擇和參數設置敏感、對復雜場景和多重篡改不適應等[7].
基于深度學習的方法是指利用深度學習技術來自動學習圖像特征,并利用分類器或回歸器來檢測和定位篡改區域. 基于深度學習的方法可以進一步分為基于整幅圖像和基于局部圖像兩類.基于整幅圖像的方法是指將整個圖像作為輸入,輸出指示圖像是否被篡改的二元標簽. 基于局部圖像的方法是指將圖像分割成若干小塊或補丁,輸出每個塊或補丁的二元標簽或坐標來定位篡改區域. 通常基于深度學習的方法精度和魯棒性較優,但也存在一些問題,例如對數據數量和質量的依賴、對計算資源的需求、特征提取過程中信息丟失等[8].
針對圖像復制粘貼篡改檢測特征提取過程中的信息丟失問題,本文提出基于注意力機制的漸進式圖像復制粘貼篡改檢測模型. 首先,在特征提取網絡整個過程中保持高分辨率,同時高分辨率和低分辨率并行連接,同步推進,漸進地對圖像進行多層次的特征提取. 之后在掩碼生成模塊包含4個不同尺度的特征,經過注意力機制模塊由低到高進行上采樣后連接,獲得更準確的圖像掩碼. 將圖像特征輸入圖像級篡改檢測模塊,得到圖像級篡改檢測結果. 最后,選擇焦點損失函數以解決復制粘貼篡改檢測圖像中像素點類別不平衡問題.
2 相關工作
在圖像復制粘貼篡改檢測中,目前大多數研究都以深度學習為基礎. Li 等發現在殘差域中篡改圖像塊包含較少的高頻分量,與原始圖像塊表現出明顯的差異,因此設計了HP-FCN[9],圖像經過高通濾波后圖像殘差以增強偽造痕跡,輸入殘差網絡中進行特征提取,上采樣放大特征圖進行定位和判別. CR-CNN[10]同樣關注噪聲流,使用BayarConv[11]作為初始卷積層,通過初始的約束卷積層能夠捕捉豐富的篡改痕跡,之后經殘差網絡輸出特征到邊界檢測模塊和掩碼生成模塊,邊界檢測模塊也向掩碼生成模塊進行輸入,再經過卷積與激活層獲得掩碼. RGB-N[12]不僅關注圖像噪聲流,還關注到RGB 流,提出雙流Faster R-CNN端到端網絡以檢測給定圖像的篡改區域,在FasterR-CNN[13] 的基礎上增加噪聲流,圖像經SRM 濾波器獲取噪聲特征圖,作為額外的輔助特征. 雙流特征通過感興趣區域池化、雙線性池化,在全連接層之前進行融合,再經過Softmax 得到預測結果.GSR-Net[14]提出基于GAN[15]結構的圖像篡改檢測模型,增加輔助邊界分支來增強對篡改區域的識別,生成器進行復制粘貼篡改,再經過深度卷積網絡努力生成真假難辨的篡改圖像;鑒別器分為分割階段和細化階段,2 個階段共享網絡參數,分割階段負責識別篡改圖像中的篡改邊界,再經過細化階段生成新的篡改邊界. CAT-Net[16]通過RGB流和DCT 流來識別篡改,RGB 流學習視覺偽影,DCT 流學習壓縮偽影(即DCT 系數分布),特征融合階段融合來自2 個流的多個分辨率特征,生成最終的圖像掩碼.
3 基于注意力機制的漸進式圖像復制粘貼篡改檢測
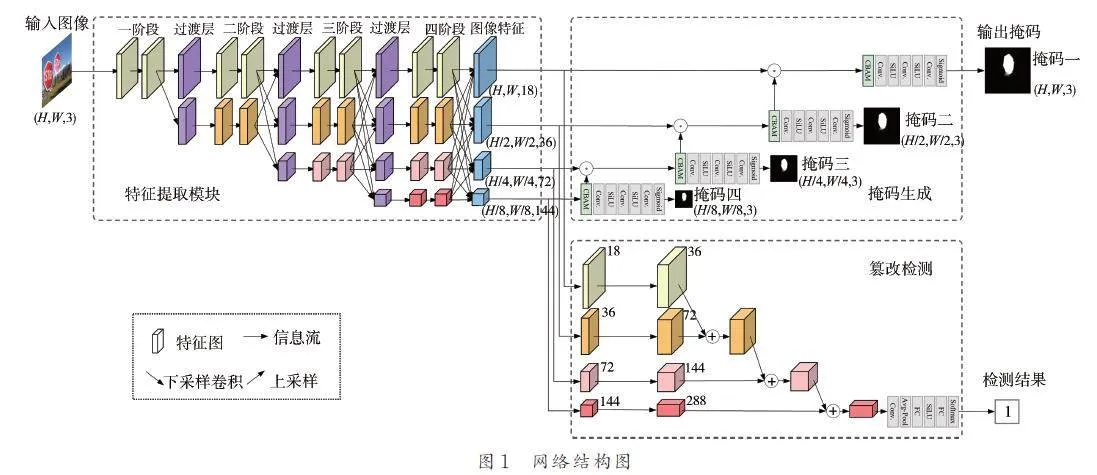
針對圖像復制粘貼篡改檢測特征提取過程中信息丟失問題,本文在圖像特征提取過程中保持高分辨率,交流融合不同分辨率下的圖像特征,提出的基于注意力機制的漸進式圖像復制粘貼篡改檢測模型的網絡結構如圖1 所示.
3. 1 網絡結構
本文提出的基于注意力機制的漸進式圖像復制粘貼篡改檢測模型分為3 個模塊:特征提取模塊、掩碼生成模塊和篡改檢測模塊.
高分辨率表征對于圖像篡改定位等位置信息敏感的視覺任務極其重要,ResNet[17]、VGGNet[18]、U-Net[19]等目前流行的框架首先通過串聯的高分辨率卷積至低分辨率卷積子網絡將輸入的圖像編碼為低分辨率表征,然后從已編碼的低分辨率表征中上采樣恢復高分辨率表征,然而這種做法會導致大量的有效信息在不斷的上下采樣過程中丟失. 為了解決這一問題,在特征提取模塊中本文選用HRNetV2p-W18[20]為骨干網絡,將階段縮小比例s 設置為2,在4 個階段中將高分辨率與低分辨率卷積流并行連接,而不是像以往一樣串聯連接. 因此能夠保持高分辨率,而不是從低分辨率中恢復高分辨率,從而使學習到的表征在空間上更精確. 同時在每個階段都進行高低分辨率融合來互相增強高分辨率、低分辨率的表征. 因此在每個階段的高、低分辨率表征都是具有強語義的.圖像經過特征提取模塊得到4 個不同尺度下的圖像特征,輸入后續的掩碼生成模塊和篡改檢測模塊.
在掩碼生成模塊中,輸入圖像經特征提取模塊得到的4 個不同尺度下的圖像特征,先通過注意力機制模塊(Convolutional Block Attention Module,CBAM)[21]根據關注目標的重要性程度改變資源分配方式,使資源更多的向關注的對象傾斜,提高對于關注對象的特征提取能力. 具體地,特征圖F ( H × W × C ) 先經過通道注意力模塊,再通過空間注意力模塊. 通道注意力模塊公式如式(1)所示.
Mc ( F )= σ ( MLP ( AvgPool( F ) )+MLP ( MaxPool( F ) ) )=σ (W1 (W0 (F cavg ) )+ W1 (W0 (Fcmax ) )) (1)
式(1)中,F 為輸入的特征圖,F 尺寸為H × W × C;AvgPool 代表全局平均池化;MaxPool 代表全局最大池化;MLP 代表多層感知機,是2 層全連接神經網絡;W0 和W1 為MLP 的各層權重;AvgPool 和MaxPool 共享同一MLP;σ 代表sigmoid 激活函數.F 基于尺寸H 和W 進行AvgPool 和MaxPool,結果為2 個1 × 1 × C 的特征圖F cavg 與Fcmax. 之后分別經過共享的MLP 后按元素進行相加后通過σ 得到通道注意力特征Mc ( F ). 最后將Mc ( F ) 與F 按元素進行相乘,得到F 經過了通道注意力模塊的新特征F '.
空間注意力模塊公式如式(2)所示.
Ms ( F ')= σ ( f 7 × 7 ( [ AvgPool( F ') );MLP ( MaxPool( F ') ] ) )=σ ( f 7 × 7 ( [ F ' cavg ; F 'cmax ] ) ) (2)
式(2)中,AvgPool 代表全局平均池化;MaxPool 代表全局最大池化;f 7 × 7 代表7×7 卷積;σ 代表sigmoid激活函數. F ' 基于通道C 進行AvgPool 和MaxPool,結果為2 個H × W × 1 的特征圖F ' cavg 與F 'cmax,對F ' cavg 和F 'cmax 進行拼接得到H × W × 2 的特征圖. 之后經過7×7 卷積降維為H × W × 1,再進行σ 得到空間注意力特征,即Ms ( F '),將Ms ( F ')和F '相乘即得到最終生成的特征.
低尺寸的特征圖經過注意力模塊后進行雙線性插值上采樣后與相鄰的更高尺寸特征圖做元素乘法操作,分辨率較低的特征圖中包含的圖片高層語義信息漸進地與分辨率較高的特征圖中包含的更多位置、細節信息融合. 在信息不斷向上融合的過程中圖像掩碼逐漸清晰準確,此過程稱為特征連接. 同時經過了特征融合的特征圖由后續的一系列卷積單元生成對應分辨率的掩碼.
在篡改檢測模塊中,根據圖像經特征提取模塊得到的4 個不同尺寸特征圖分別進行升維,然后按照分辨率從大到小依次進行下采樣同時從上到下逐級融合相加,之后經過1 × 1 卷積降維,再經過平均池化后輸入到2 個全連接層,2 層之間包含了SiLU 激活函數,對全連接層輸出計算Softmax,得到圖像級篡改檢測結果.
3. 2 損失函數
在復制粘貼圖像篡改檢測中,篡改像素點在數量上與未篡改像素點不平衡,而當研究目標中包含圖像級篡改檢測而加入未篡改圖像時像素點類別不平衡問題更嚴重.
常用的二分類交叉熵損失函數公式如式(3)所示:
式(3)中,i 為模型預測圖像或像素點;yi 為i 篡改的概率;y?i 為i 的標簽. 在不平衡的圖像復制粘貼篡改數據集中,負樣本數量明顯多于正樣本,這會導致使用交叉熵作為損失函數的模型更傾向于預測多數類別,從而忽略了少數類別.
為了解決復制粘貼篡改檢測圖像中像素點類別不平衡問題,本文選擇焦點損失函數[22],公式如式(4)所示.
焦點損失函數在交叉熵的基礎上增設了聚焦參數γ 和平衡參數σ,增加網絡對難分類樣本的關注度,降低正負樣本不平衡對模型帶來的影響. 本文根據實驗對比與分析[22],選擇σ = 0. 5,γ = 2.
在網絡中通過對真實掩碼依據縮小比例s 下采樣到4 個指定分辨率子掩碼GTn ( n = 1,2,3,4 ),對4 個分辨率下的預測掩碼PMn ( n = 1,2,3,4 ) 都進行監督并計算損失函數. 在圖像級別,記圖像標簽為l,預測值為y. 因此,網絡最終的損失函數L如式(5)所示.
4 實驗與分析
4. 1 實驗說明
基于注意力機制的漸進式圖像復制粘貼篡改檢測模型在訓練時分為2 個階段:第1 階段是預訓練階段,在此階段完成消融實驗;第2 階段在上一階段的模型基礎上,繼續在復制粘貼圖像公開數據集上進行訓練,在此階段完成對比試驗.
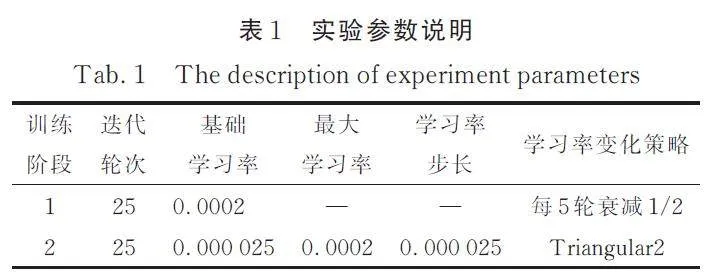
論文實驗在Ubuntu 20. 04 上使用2 張NVIDIA 3080 GPU 完成,所有實驗均使用Pytorch框架完成. 訓練時使用Adam 優化器,預訓練Epoch為25,初始學習率設置為0. 0002,每5 輪衰減到原來的1/2;第2 階段Epoch 為25,學習率應用了CyclicLR[23]的震蕩衰減策略,上邊界學習率設置為0. 0002,下邊界學習率設置為0. 000 025,步長0. 000 025,震蕩模式選擇triangular2,實驗參數如表1 所示.
4. 2 數據集
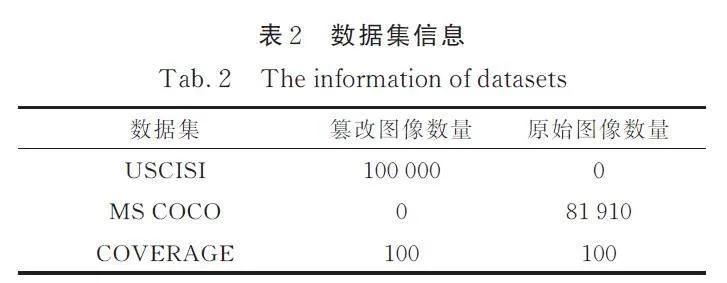
圖像復制粘貼篡改領域的公開數據集大多數包含的圖像數量為僅幾百到幾千,Wu 等[24]創建數據集USCISI. 為了加強圖像級篡改檢測結果可信度,加入MS COCO[25]作為未篡改圖像數據集進行訓練. 在第2 階段選擇Wen 等[26]創建的公開數據集COVERAGE 進行驗證. 實驗中所用數據集信息如表2 所示.
4. 3 評估指標
論文在像素級與圖像級均進行了實驗. 在像素級實驗中,使用F1 分數作為評估模型的指標.首先計算出每張圖像的TP、TN、FP、FN;其中TP代表準確檢測出的篡改像素點總數,TN 代表準確檢測出的原始像素點總數,FP 代表錯誤檢測為篡改的原始像素點總數,FN 代表錯誤檢測為原始的篡改像素點總數. 按式(6)所示計算出每張圖像F1 分數,之后在測試集上取平均值.
在圖像級實驗中,使用了AUC、靈敏度(Sensitivity)、特異度(Specificity)與F1 分數作為評估模型的指標. 與像素級實驗中一致,仍然是篡改圖像代表正例,原始圖像代表負例. 靈敏度又稱為召回率(Recall),計算公式與式(6)中一致,特異度計算公式如式(7)所示.
4. 4 實驗結果與分析
4. 4. 1 消融實驗
為驗證本文所提方法各組件有效性,選取不同組件設計出5 個網絡,在USCISI上進行消融實驗,如表3 所示.
網絡差異及其設計目的如下.
(1) Baseline: 基礎模型,圖像經過編碼器后只使用最大特征圖輸入到解碼器,在解碼器模塊中不加入注意力機制且只產生最大掩碼,使用交叉熵作為損失函數.
(2) Net1: 使用焦點損失作為損失函數,其余模組與Baseline 一致. 用于驗證焦點損失降低正負樣本不平衡影響的有效性.
(3) Net2: 在Net1 的基礎上加入CBAM 注意力機制,其余模組與Net1 保持一致. 用于驗證注意力機制的有效性.
(4) Net3: 在Net1 的基礎上加入漸進特征連接,其余模組與Net1 保持一致. 用于驗證漸進特征連接的有效性.
(5) Net4: 在Baseline 的基礎上加入注意力機制與漸進特征連接,使用交叉熵作為損失函數,其余模組與Baseline 保持一致. 與Net1 聯合驗證焦點損失函數的有效性.
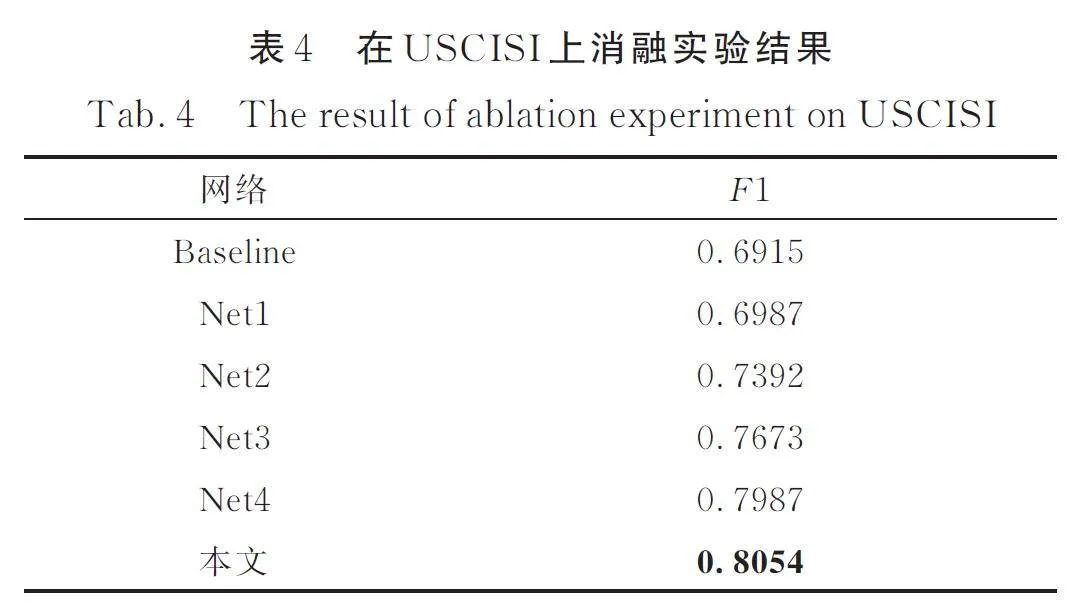
在USCISI 數據集上消融實驗結果如表4 所示. Net1 比Baseline 的F1 分數高0. 72%、本文模型比Net4 的F1 分數高0. 67% 聯合驗證了焦點損失對于降低正負樣本不平衡影響的有效性. 對比Net1,添加了CBAM 注意力機制后Net2 的F1 分數提高了4. 05%,證明了注意力機制有效提高了對于關注對象的特征抓取能力. 而在Net1 的基礎上添加特征連接后的Net3,F1 分數增長了6. 86%,有效證明多尺度特征提取與漸進式特征連接對于圖像復制粘貼篡改檢測的能力提升作用,這與圖像在篡改時通常遭遇了尺度變化分不開,多尺度的特征提取能夠抓住不同尺度上的相似特征. 本文模型相較于未添加特征連接Net2 的F1 分數提高了6. 62%,相較于未添加注意力機制Net3 的F1 分數提高了3. 81%,相較于未使用焦點損失函數Net4 的F1 分數提高了0. 67%. 通過實驗結果經分析可知,焦點損失對于降低正負樣本不平衡影響有效,注意力機制與漸進式特征連接對于模型性能有明顯提升.
4. 4. 2 對比實驗
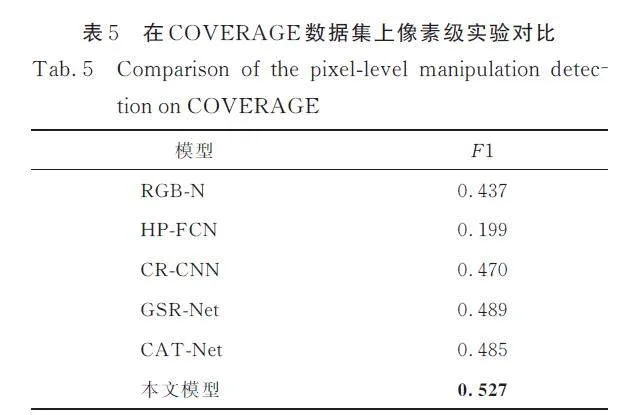
為了評估本文模型的性能,分別在像素級和圖像級與其他深度學習模型在公開數據集COVERAGE 上進行對比. 在像素級對比實驗中選擇5 個基于深度學習的模型進行比較,分別是RGB-N[12]、HP-FCN[9]、CR-CNN[10]、GSRNet[14]和CAT-Net[16],實驗結果如表5 所示. 從表5 可以看出,本文模型表現最佳,比排名第二的GSR-Net 高3. 8%. 這歸功于本文模型對圖像進行并行多分辨率特征提取并進行漸進式特征連接,并加入注意力機制提高模型對于關注對象的特征提取能力,還引入焦點損失降低像素點類別不平衡問題對模型帶來的影響.
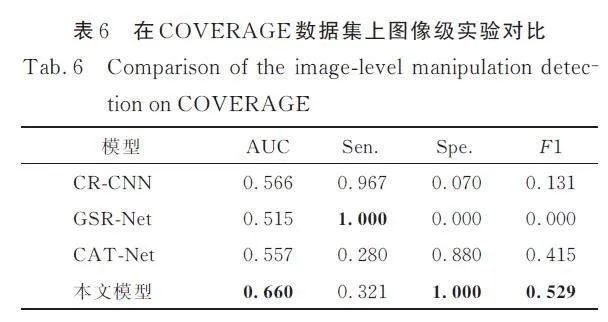
在圖像級對比實驗中選擇CR-CNN 、GSRNet、CAT-Net 進行對比,對比實驗結果如表6 所示. 本文所提出的模型在AUC、特異度和F1 分數等3 個評估指標下取得最佳效果. 從表5 可以看出,CR-CNN 與GSR-Net 更注重靈敏度而忽視特異度,也即漏報少而誤報多. 而CAT-Net 和本文所提出的模型則是更偏重特異度,在靈敏度方面有所不足. 通過AUC 可以分析得知,本文模型可以更好地平衡靈敏度和特異度,F1 分數說明本文模型在精確率和召回率之間與其他3 個模型相比也能達到更優的平衡點.
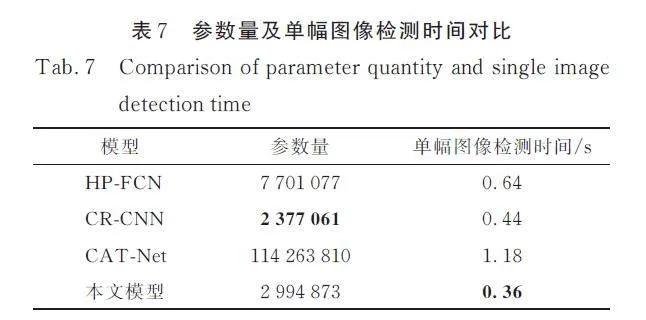
除像素級與圖像級檢測效果外,本文還對比了幾個模型的參數量以及COVERAGE 數據集上單幅圖像平均檢測時間,結果如表7 所示. 本文模型在參數量上僅次于參數量最少的模型CRCNN.盡管參數量并非最少,本文模型在檢測時間上卻表現出最佳的性能,能實現最短的單幅圖像檢測時間.
為了更直觀地對比各模型的檢測效果,選取COVERAGE 數據集中多幅圖像進行檢測并生成掩碼,如圖2 所示. 圖2a 和圖2b 為篡改圖像與其真實掩碼,圖2c~ 圖2e 分別是HP-FCN、CR-CNN、CAT-NET 對相應篡改圖像進行檢測后生成的掩碼,圖2f 為本文所提方法生成的掩碼. 從圖2 第1行中可以看出,本文方法能精確識別出篡改區域,其他3 個模型并未能正確標識;第2 行中本文方法與CR-CNN 表現表現不錯但均有不足,CR-CNN會漏檢部分篡改區域,本文則是誤檢了部分真實區域;第3 行中CR-CNN、CAT-NET 與本文方法均能標識出篡改區域,但CAT-NET 誤檢了部分真實區域. 由圖2 可視化結果可以看出,本文方法的檢測結果最佳,能夠在生成的掩碼中準確地標識出篡改區域.
5 結論
本文提出了基于注意力機制的漸進式圖像復制粘貼篡改檢測模型. 該模型主要針對目前基于卷積神經網絡的方法在特征提取過程中信息丟失以及像素點類別不平衡問題,利用并行高分辨率編碼器網絡提取4 個分辨率下的特征圖,再對特征圖通過注意力機制調整,漸進地從低到高進行特征連接,每個分辨率下的特征圖都生成相應的掩碼并對其進行監督,通過焦點損失函數以解決復制粘貼篡改檢測圖像中像素點類別不平衡問題.消融實驗表明,注意力模塊提高了對于關注對象的特征抓取能力,漸進式特征連接融合了多尺度圖像特征,均有效提升模型性能. 在公開數據集上的實驗表明,本文所提模型不論是在像素級別還是圖像級別F1 分數均優于其他模型,同時單幅圖像檢測時間最短.
參考文獻:
[1] Saber A H, Khan M A, Mejbel B G. A survey onimage forgery detection using different forensic approaches[J]. Adv Sci Technol Eng Syst J, 2020,5: 361.
[2] Zhang Y X, Zhao X F, Cao Y, et al. A survey onblind detection of tampered digital images[J]. J CyberSecur, 2022, 7: 56.[張怡暄, 趙險峰, 曹紜. 數字圖像篡改盲檢測綜述[J]. 信息安全學報, 2022,7: 56.]
[3] Li X L, Yu N H, Zhang X P, et al. Overview ofdigital media forensics technology [J]. J ImageGraphics, 2021,26:1216.[李曉龍,俞能海,張新鵬等. 數字媒體取證技術綜述[J]. 中國圖象圖形學報, 2021, 26:1216.]
[4] Warif N B A, Idris M Y I, Wahab A W A, et al. Acomprehensive evaluation procedure for copy-moveforgery detection methods: results from a systematicreview[J]. Multimed Tools Appl, 2022, 81: 15171.
[5] Xing W B, Du Z C. Digital image forensics for copyand paste tampering[J]. Computer Sci, 2019, 46:380.[邢文博,杜志淳. 數字圖像復制粘貼篡改取證[J]. 計算機科學, 2019, 46: 380.]
[6] Li R C, Ju S G, Zhou G, et al. Research of internalimage Move-Copy tampering forensics algorithm[J].J Sichuan Univ(Nat Sci Ed), 2016, 53: 67.[李若晨, 琚生根, 周剛, 等. 圖像內部 Move-Copy 篡改盲取證算法研究[J]. 四川大學學報(自然科學版),2016, 53: 67.]
[7] Barad Z J, Goswami M M. Image forgery detectionusing deep learning: a survey[C]//Proceedings ofthe 2020 6th International Conference on AdvancedComputing and Communication Systems( ICACCS).Coimbatore, India: IEEE, 2020.
[8] Elaskily M A, Dessouky M M, Faragallah O S, etal. A survey on traditional and deep learning copymove forgery detection (CMFD) techniques[J].Multimed Tools Appl, 2023, 82: 34409.
[9] Li H, Huang J. Localization of deep inpainting usinghigh-pass fully convolutional network[C]//Proceedingsof the IEEE/CVF International Conference onComputer Vision (ICCV). Seoul, Korea (South):IEEE, 2019.
[10] Yang C, Li H, Lin F, et al. Constrained R-CNN: A general image manipulation detection model[C]//Proceedings of the IEEE International Conferenceon Multimedia and Expo (ICME). London, UK:IEEE, 2020.
[11] Bayar B, Stamm M C. Constrained convolutionalneural networks: A new approach towards generalpurpose image manipulation detection[J]. IEEE TInf Foren Sec, 2018, 13: 2691.
[12] Zhou P , Han X , Morariu V I , et al. Learning richfeatures for image manipulation detection[C]//Proceedingsof the IEEE/CVF Conference on ComputerVision and Pattern Recognition( CVPR). Salt LakeCity, USA: IEEE, 2018.
[13] Ren S, He K, Girshick R, et al. Faster R-CNN:Towards real-time object detection with region proposalnetworks [J]. IEEE T Pattern Anal, 2017,39: 1137.
[14] Zhou P, Chen B C, Han X, et al. Generate, segment,and refine: Towards generic manipulation segmentation[C]//Proceedings of the AAAI Conferenceon Artificial Intelligence (AAAI). New York,USA: AAAI, 2020.
[15] Goodfellow I J, Pouget-Abadie J, Mirza M, et al.Generative adversarial nets[C]//Neural InformationProcessing Systems (NIPS). Cambridge: MITPress, 2014.
[16] Kwon M J, Yu I J, Nam S H, et al. Cat-net: Compressionartifact tracing network for detection and localizationof image splicing[C]//Proceedings of theIEEE/CVF Winter Conference on Applications ofComputer Vision. Waikoloa, USA: IEEE, 2021.
[17] He K, Zhang X, Ren S, et al. Deep residual learningfor image recognition[C]//Proceedings of the IEEEConference on Computer Vision and Pattern Recognition.Las Vegas, USA: IEEE, 2016.
[18] Simonyan K, Zisserman A. Very deep convolutionalnetworks for large-Scale image recognition [EB/OL].[2014-09-04]. https://arxiv. org/abs/1409. 1556.
[19] Ronneberger O, Fischer P, Brox T. U-net: Convolutionalnetworks for biomedical image segmentation[C]//Proceedings of the 18th International Conferenceon Medical Image Computing and Computer-Assisted Intervention (MICCAI). Munich, Germany:Springer International Publishing, 2015.
[20] Sun K, Xiao B, Liu D, et al. Deep high-resolutionrepresentation learning for human pose estimation[C]//Proceedings of the IEEE/CVF Conferenceon Computer Vision and Pattern Recognition(CVPR). Long Beach, USA: IEEE, 2019.
[21] Woo S, Park J, Lee J Y, et al. CBAM: Convolutionalblock attention module [C]//Proceedings ofthe European Conference on Computer Vision(ECCV). Munich, Germany: Springer, 2018.
[22] Lin T Y, Goyal P, Girshick R, et al. Ieee, Focalloss for dense object detection[C]//Proceedings ofthe 16th IEEE International Conference on ComputerVision( ICCV). Venice, Italy: IEEE, 2017.
[23] Smith L N. Cyclical learning rates for training neuralnetworks [C]//Proceedings of the IEEE WinterConference on Applications of Computer Vision(WACV). Santa Rosa: IEEE, 2017.
[24] Wu Y, Abd-Almageed W, Natarajan P. Busternet:Detecting copy-move image forgery with source/targetlocalization[C]//Proceedings of the EuropeanConference on Computer Vision (ECCV). Munich,Germany: Springer, 2018.
[25] Lin T Y, Maire M, Belongie S, et al. Microsoftcoco: Common objects in context[C]//Proceedingsof the European Conference on Computer Vision(ECCV). Zurich, Switzerland: Springer, 2014.
[26] Wen B, Zhu Y, Subramanian R, et al. COVERAGE―A novel database for copy-move forgery detection[ C]//Proceedings of the IEEE International Conference onImage Processing( ICIP). Phoenix, US: IEEE, 2016.
(責任編輯: 伍少梅)
基金項目: 四川省科技計劃資助(2022YFG0171)
