一種基于強化學習的軟件安全實體關系預測方法
2024-08-23 00:00:00楊鵬劉亮張磊劉林李子強賈凱
四川大學學報(自然科學版) 2024年4期

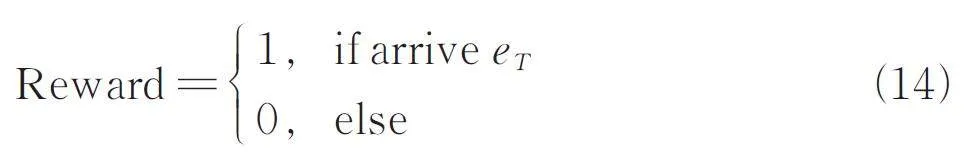
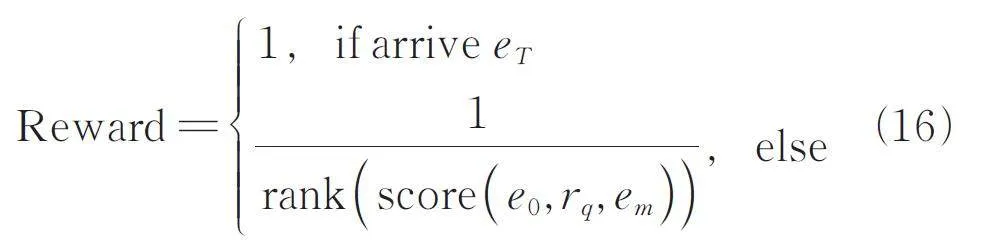
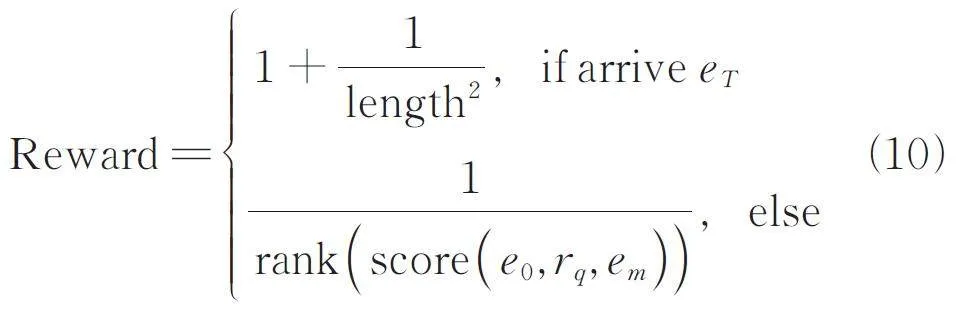
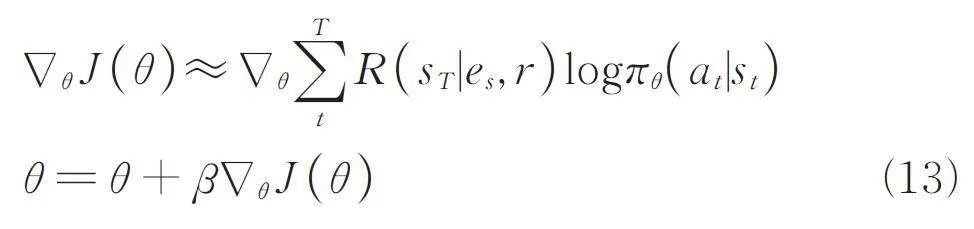


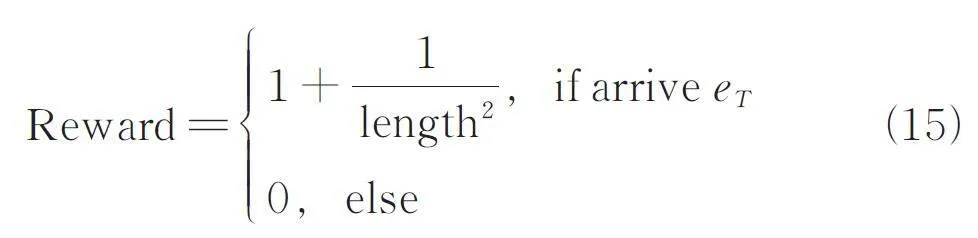
摘 要: 為改善現有基于翻譯的軟件安全知識圖譜實體關系預測方法不具備可解釋性,而基于路徑推理的方法準確性不高的現狀,本研究提出一種基于強化學習的預測方法. 該方法首先分別使用TuckER 模型和SBERT 模型將軟件安全知識圖譜的結構信息和描述信息表示為低維度向量,接著將實體關系預測過程建模為強化學習過程,將TuckER 模型計算得到的得分引入強化學習的獎勵函數,并且使用輸入的實體關系向量訓練強化學習的策略網絡,最后使用波束搜索得到答案實體的排名列表和與之對應的推理路徑. 實驗結果表明,該方法給出了所有預測結果相應的關系路徑,在鏈接預測實驗 中hit@5 為0. 426,hit@10 為0. 797,MRR 為0. 672,在事實預測實驗中準確率為0. 802,精確率為0. 916,在準確性方面與同類實體關系預測模型相比具有不同程度的提升,并且通過進行可解釋性分析實驗,驗證了該方法所具備的可解釋性.
關鍵詞: 軟件安全實體關系;強化學習;鏈接預測;知識圖譜;可解釋推理
中圖分類號: TP391. 1 文獻標志碼: A DOI: 10. 19907/j. 0490-6756. 2024. 042008
1 引言
軟件弱點和漏洞危害系統的完整性、可用性和機密性[1]. 為更好地分析來自外部環境的惡意攻擊,研究人員建立安全數據庫來管理軟件漏洞、弱點和攻擊模式. 這其中包括常見漏洞和披露(CVE)[2]、常見弱點枚舉(CWE)[3]和常見攻擊模式枚舉和分類(CAPEC)[4]. 這些數據庫包含豐富的軟件安全知識. 然而有研究表明[5],底層知識表示(超鏈接文檔)不支持對軟件安全實體關系的有效預測,僅僅依靠數據庫難以挖掘出深層次的安全知識. 例如CWE-190 與CWE-119 在2. 0 版本中存在precede 關系,而這一關系在1. 0 版本中不存在. 另一方面當前網絡環境下網絡攻擊的手段越來越多樣,CVE、CWE 和CAPEC 數據庫不可避免的丟失一些軟件安全實體和關系,手動更新這些數據需要的時間過多,這使得系統暴露在威脅之中. 為應對以上問題,近年來有學者提出將軟件安全數據表示為軟件安全知識圖譜,使用知識圖譜表示學習將軟件安全實體和關系嵌入到低維向量表示中,同時,使用Word2Vec[6]等方法將軟件安全實體描述也嵌入到低維向量中,根據向量的相關性來預測軟件安全知識圖譜中缺失的信息[5].
當前已有軟件安全實體關系預測模型大都是嵌入模型,將軟件安全知識圖譜表示低維成向量后,利用得分函數計算這些向量的相似性進行預測,然而這使得預測出的結果不具有可解釋性. 在實際應用中,安全分析員得到預測結果后無法對其成因進行分析. 近年來,多跳模型由于充分利用實體之間的路徑信息,在知識推理任務中具有良好的效果[7]. 多跳模型除了輸出預測結果外,還產生與之對應的推理路徑,該路徑可以對預測結果的成因給出解釋. 而基于強化學習的推理模型作為多跳推理模型的一種,由于其良好的性能受到廣泛關注[8-10].
本文針對現有軟件安全實體關系預測模型存在的問題,提出了基于強化學習模型的軟件安全實體關系預測方法,通過學習2 個安全實體之間的關系路徑信息,將軟件安全實體關系的預測問題轉化為強化學習的序列決策問題. 本文的主要貢獻如下.
(1)提出了基于強化學習模型的軟件安全實體關系預測方法,該方法通過學習軟件安全實體之間已有的關系路徑補全缺失信息,其預測結果具有可解釋性.
(2)設計出了強化學習獎勵計算方法,該方法結合基于嵌入的方法準確率高的優點,通過在訓練過程中不同情況下給出不同獎勵,保證預測的準確性并且進一步增強可解釋性.
(3)通過鏈路預測(Link-prediction)和事實預測(Fact-prediction),驗證本文提出的基于強化學習的方法在軟件安全知識圖譜上預測實體關系的有效性. 通過消融實驗驗證獎勵函數的有效性.
2 相關工作
2. 1 軟件安全知識圖譜
Han 等[5]研究常見軟件弱點的知識圖譜表示以及知識圖譜上的推理任務,將CWE 的結構和文本知識嵌入到低維向量表示中,但他們的研究并沒有涉及異構安全概念和安全實例. Xiao 等[11]建立了集成異構安全概念和實例的軟件安全知識圖譜,將CWE、CVE 和CAPEC 數據庫的數據整合到1 個知識圖譜中,在軟件安全實體關系預測任務中同時嵌入知識圖譜結構和描述信息. 但是上述研究工作在預測時僅單獨考慮相關三元組,忽略了周圍的相鄰實體的重要語義信息. 為此,Liu 等[12]設計了文本增強的GAT 模型,該模型強調知識在圍繞三元組的2-hop 鄰居中的重要性. Wang 等[13]設計了基于SBert 表示學習的模型,并通過在2 個實體中引入多跳鄰居的輔助關系來增強軟件安全知識圖譜的表示向量,以從遠鄰獲取知識.
然而現有軟件安全實體關系預測方法存在不具有可解釋性問題. 本文提出的基于強化學習的軟件安全實體關系預測方法通過學習知識圖譜中已有關系路徑預測缺失信息,其預測結果具有可解釋性.
2. 2 知識推理技術
知識推理是知識圖譜的重要應用,它利用知識圖譜中已知的知識推理得到未知的知識,從而得到豐富而有價值的信息. 基于嵌入表示的推理模型是當前應用比較廣泛的知識推理技術,將復雜的數據結構轉化為向量化的表示,可以實現知識圖譜中的鏈路預測任務. 其中學界對基于翻譯的模型transE、transH、transR 和transD 等已經進行了廣泛的研究[14-17]. 上述方法不具有可解釋性,然而僅獲得預測結果是不夠的,模型還應該解釋獲得這個預測結果的過程,來建立安全分析員與推理模型的信任[18]. 近年來,多跳推理方法由于其推理結果的可解釋性,有不少學者對此進行了大量的研究. 而將推理過程建模為強化學習過程是常用且高效的多跳推理方法. Xiong 等[8]將強化學習應用于知識推理,提出了基于強化學習的知識推理框架(DeepPath),但是該模型只能完成比較簡單的推理任務例如. 對此,Das 等[9]提出了MINERVA 模型用以回答更復雜的推理任務,例如lt;h,r,?gt;.
然而雖然現有基于強化學習的知識圖譜推理模型具有很強的可解釋性,但在推理效率上較嵌入類模型偏低,原因首先是多數強化學習方法沒有對實體和關系進行較好的嵌入,其次是部分知識圖譜存在的稀疏性會產生大量的失敗訓練,這使代理的訓練過程變得困難. 本文提出基于嵌入模型的強化學習獎勵計算方法,首先使用基于張量分解的模型(TuckER)[19]的得分函數計算出近鄰三元組排名,再根據排名計算出智能體所應獲得的獎勵,這使得智能體在大量失敗的訓練中也能提高訓練的效率.
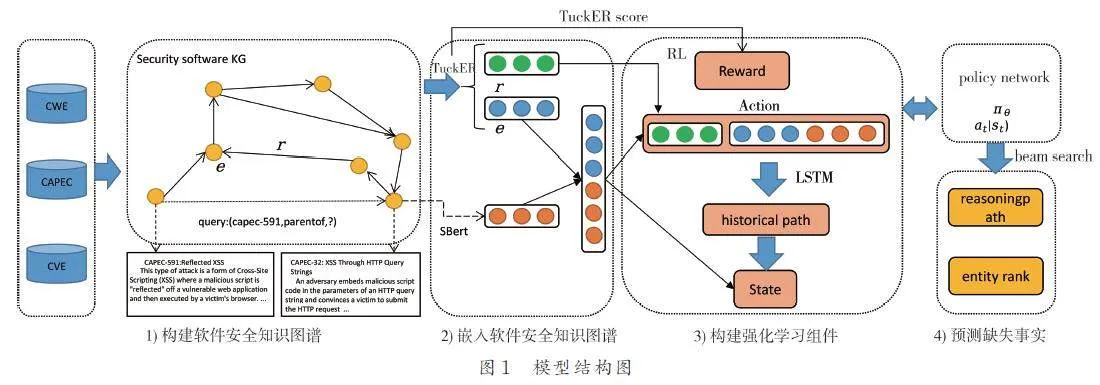
本文方法的架構如圖1 所示. 對于問題lt;h,r,?gt;,首先收集3 個軟件安全實體關系數據庫的數據,分別整合為結構信息和實體描述信息,使用三元組來表示結構信息構成知識圖譜;然后分別使用TuckER 和 SBert 嵌入結構和實體描述信息,并將結構嵌入得到的實體向量和該實體的描述向量拼接為新的表示該實體的向量;接著定義強化學習環境和策略網絡,將上一步得到的向量作為輸入來訓練策略網絡;最后使用波束搜索(Beamsearch)根據代理到達實體的軌跡的概率,得到答案實體的排名列表和對應的推理路徑來完成預測任務. 本章接下來首先介紹軟件安全知識圖譜的嵌入方法,接著描述強化學習的各個組件,最后定義策略網絡并闡述策略網絡的訓練方法.
3. 1 基于TuckER 和SBert 的聯合嵌入
在進行推理任務之前,需要將軟件安全實體關系結構和實體描述分別表示為向量形式,將結構嵌入得到的實體向量與實體描述嵌入得到的向量拼接成新向量,然后用這個向量來替換之前的實體向量.
結構嵌入:使用嵌入模型TuckER[19]將軟件安全實體和關系嵌入到連續的向量空間. TuckER 模型是具有完全表達能力的嵌入模型,在知識圖譜推理任務中的性能良好.
描述嵌入:為使具有相似描述的實體在向量空間中也具有相似性,本文采用Wang 等[13]提出的基于SBert 的嵌入方法,將軟件安全實體描述表示成固定長度的句子向量.
3. 2 基于改進獎勵的強化學習推理框架
近年來的研究將知識圖譜的多跳推理建模為馬爾可夫過程(Markov Decision Process, MDP).在知識圖譜推理中,外部環境指定了智能體和KG之間交互的動態,它被建模為馬爾可夫過程(MDP). MDP 用元組來表示,其中S 是某時刻的狀態(State),A 是狀態轉移的動作(Action),T 表示從當前狀態轉移到下一狀態(Transition),R 表示獎勵(Reward).
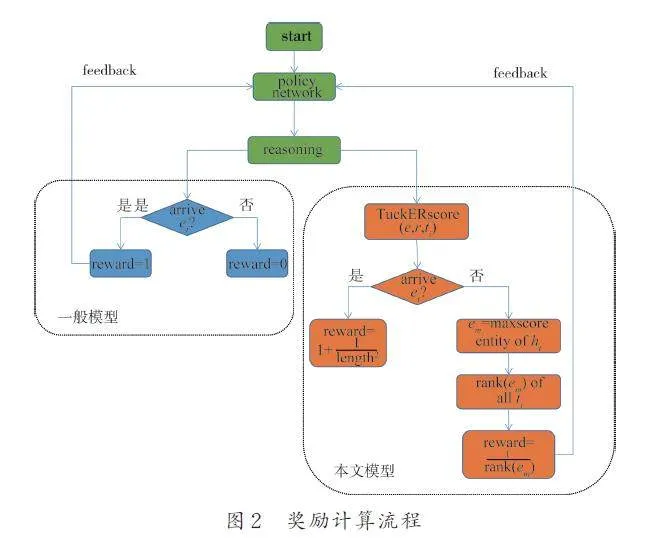
在代理的訓練過程中,成功找到答案實體將獲得獎勵,失敗則沒有獎勵. 一般的強化學習方法簡單的將這2 種情況下的獎勵定義為1 和0,然而在實際情況中由于知識圖譜的稀疏性會產生的大量無效訓練,導致訓練效果很差[10]. 針對這一問題,本文考慮對獎勵計算過程進行改進,提出了基于嵌入模型(TuckER)的強化學習獎勵計算方法.圖2 描述了一般模型和本文模型的獎勵函數反饋策略網絡的過程.
總的來說,該部分利用TuckER 模型的得分函數和LSTM 定義智能體尋路失敗時的獎勵. 接下來本文將具體描述各MDP 組件和策略網絡. 對于查詢任務(e0,rq,?)在T 步之內的答案,本文首先使用TuckER 的得分函數計算待排名實體替換尾實體之后的得分,將TuckER 的得分函數表示為式(1)
score( e,r,t ) (1)
計算待排名實體替換尾實體之后的得分,這里的待排名實體為最大跳數T 步之內能到達的所有實體,而不是像基于嵌入的方法一樣對知識圖譜中所有實體進行排名. 本文使用廣度優先算法(BFS)搜索起始節點T 步之內的所有節點的集合ET.
ET = BFS (e0,T ) (2)
State:狀態信息可以表示為
st = (rq,et,ht ) (3)
et 表示當前狀態的實體,r q 表示查詢關系.
Action:在st 狀態空間下的動作
At ={(r,e) |(et,r,e) } (4)
At 表示從當前實體到達與它相鄰的實體的所有動作空間. 此外本文在每個動作空間中添加額外的動作.
Ahold = (rhold,et ) (5)
它允許智能體停留在當前的節點,即在此時智能體認為停留在當前的節點是更好的選擇.
本文使用LSTM 儲存歷史路徑信息,代理每選擇1 個動作就將該動作儲存到LSTM 內.
ht = LSTM (ht - 1,at - 1 ) (6)
它表示在第t 跳下,LSTM 對歷史路徑信息的編碼結果. 如果最終代理沒有到達正確的實體,則查詢歷史路徑信息為
ht = (a0,a1,…,at - 1 ) (7)
使用TuckER 的得分函數score( e,r,t ) 計算出得分最高的實體記為em (mlt;T). m 為起始結點算起最高得分實體的序號. 最后將歷史路徑信息修改為
hm = (a0,a1,…,am ) (8)
Transition:s t 狀態下,選擇(rn,en ) ∈ At 動作,可到達en,n ∈ ( 0,t )狀態變為
st + 1 = (rq,et,ht + 1 ) (9)
Reward:對于查詢(e0,rq,?),有獎勵
尋路成功的獎勵:如果成功找到答案,在安全分析員對軟件安全實體間路徑進行分析時,短路徑的可讀性較強,所以短路徑比長路徑具有更強的可解釋性[8]. 本文將路徑長度length 加入到獎勵函數中,這使得代理更傾向于選擇可解釋性較強的短路徑. eT 為答案節點,如果代理成功到達eT,那么獎勵為1 加上當前路徑長度的平方的倒數,路徑越長,代理所獲得的獎勵就越少.
尋路失敗的獎勵:如果代理沒有成功到達答案,則查看em 在集合ET 中的排名,獎勵即為該排名的倒數. 排名越高,獎勵越多. em 為歷史路徑上得分最高的實體. 尋路失敗情況下的獎勵函數反映路徑與查詢(e0,rq,?)的相關性,這使智能體在大量失敗的訓練中也能提高訓練效率.
策略網絡:代理選擇正確的動作需要策略網絡的指導,將策略網絡定義為動作空間At 中的所有動作的概率分布.
πθ (at |st)= σ (At ) (W1ReLU (W2 st)) (11)
本文使用2 個線性神經網絡( w1,w2 ) 來參數化策略函數π,其中ReLU 是激活函數. 最后輸出層使用softmax 函數進行歸一化,σ 表示softmax算子.
策略優化:θ 是神經網絡參數,本文使用REINFORCE(Williams,1992)梯度策略方法優化參數θ,訓練過程是使訓練集中的每個三元組查詢的期望獎勵最大化.
J ( θ )=E (es,r,et) ∈KGE a1,...,aT ∈ πθ [ R (sT |es,r ) ] (12)
REINFORCE 梯度策略使用當前的策略生成歷史軌跡迭代遍歷所有訓練集中的三元組來估計隨機數,然后使用隨機梯度來更新.
3. 3 策略網絡訓練算法
策略網絡的具體訓練過程如下.
4 實驗及分析
在嵌入過程中,實體結構嵌入向量的維度為100,實體描述嵌入的維度也為100,所以最后拼接而成的實體向量維度為200,嵌入過程經過1000 個epoch 的訓練.
本文使用Adam[20]作為優化器,學習率 β 設置為{0. 001,0. 002,0. 003},路徑編碼器LSTM 設置為3 層,隱藏層維度為200.
為評估本文方法的有效性,本文進行了鏈接預測(Link-prediction)、事實預測(Fact-prediction)、消融實驗和可解釋性分析.
鏈接預測是給定頭實體和關系,然后對候選尾實體進行排名,正確尾實體的排名反應預測的準確性. 例如在軟件安全實體預測中,安全分析員希望找到CAPEC-591(Reflected XSS)的父級攻擊模式有哪些,那么就可以通過以三元組的形式向軟件安全知識圖譜提出.
事實預測是給出完整形式三元組,然后判斷該三元組的正確與否,這是二分類問題. 例如,安全分析員希望確定三元組是否為正確的三元組,那么軟件安全知識圖譜應該回答正確與否.
消融實驗中本文使用控制變量法討論各部分獎勵函數對實驗結果的影響,從而說明獎勵函數的有效性.
4. 1 數據集
本文使用Xiao 等[11]構建的開源數據集來建立知識圖譜,使用CVE-ID、CWE-ID 和CAPEC-ID作為實體,relationship-Nature 作為關系組成三元組. 例如 表示弱點實體cwe521 的目標是實體capec112. 數據集包括2846 個Linux CVE 實體、806 個CWE 實體、515 個CAPEC 實體和8 種關系. 一共構成8067 個三元組. 此外,本文還將每個三元組的逆三元組添加到數據集中. 最后,將數據集的80% 作為訓練三元組,20% 作為測試三元組. 將測試集三元組所有的尾實體去掉.
另外,在事實預測實驗中,由于本文構建的數據集不包含負樣本,所以在此實驗中,將測試集中三元組的尾實體進行隨機替換以生成負樣本. 最后得到事實預測數據集.
4. 2 基線設置
本文使用當前已有的5 個軟件安全實體關系預測模型作為基線與本文方法進行對比.
基線1: 使用基于嵌入的方法transH[15]預測軟件安全實體和關系.
基線2: 使用張量分解方法(TuckER)[19]的得分函數預測軟件安全實體和關系.
基線3: 由Xiao 等[11]提出,是同時嵌入實體結構和描述信息的預測框架.
基線4: 由Liu 等[12]提出,是文本增強的GAT模型.
基線5: 由Wang 等[13]提出,是基于SBert 和GAT 的模型.
4. 2. 1 鏈接預測實驗
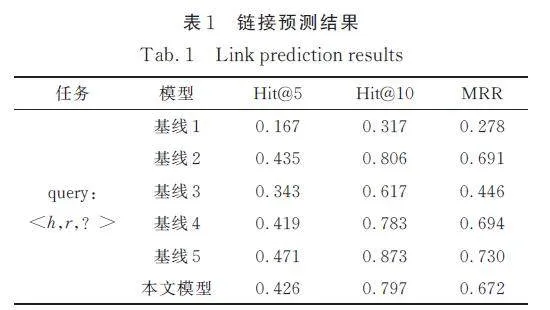
本文使用Hit@10、Hit@5和MRR(Mean Reciprocal Ranking)來衡量模型的性能. 將測試集三元組中每個尾實體去掉后視為1個查詢,本文方法根據代理到達實體的軌跡的概率,使用波束搜索(Beam search)生成答案實體的排序,波束的寬度為3. 正確實體排名在前10 位的比例為Hit@10,正確實體排名在前5 位的比例為Hit@5. 設置最大跳數T=5,基線為1~5.
得到的實驗結果如表1 所示,它由測試集中所有三元組的預測結果取平均值得到.
在鏈接預測實驗中,3 個指標最好的模型是基線5,本文模型這3 個指標好于基線1、基線2、基線3 和基線 4,略低于基線5. 這驗證了本文模型在軟件安全實體鏈接預測任務上的有效性. 雖然對比最先進的模型犧牲了一些準確性,但仍然優于大部分基線.
4. 2. 2 事實預測實驗
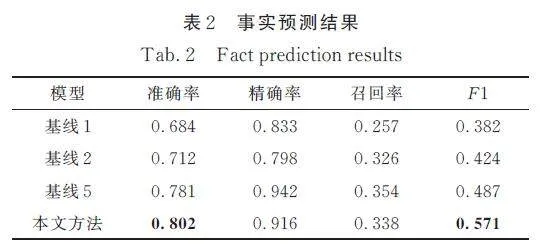
進行事實預測實驗之前需要先進行鏈接預測實驗. 首先使用鏈接預測得到每個事實預測數據集中三元組的尾實體排名列表,然后使用該三元組的名次訓練二分類器(邏輯回歸). 本文采用十折交叉驗證的方式進行訓練和測試,使用準確性、精度、召回率和F1 來評估事實預測的整體性能. 由于基線3 和基線4 中不包括事實預測實驗,所以本文對照的基線為基線1、基線2和基線5. 得到的實驗結果如表2 所示.
在事實預測實驗中,本文方法的準確率和F1均優于所有基線模型,只有精確率和召回率低于基線5. 結果表明,本文方法可以成功完成事實預測任務.
4. 2. 3 可解釋性分析
為分析實驗得到的路徑的可解釋性,對路徑進行定性分析,對于上面提出的問題,本文方法給出排名靠前的答案列表,并且展示得到每個答案的具體路徑.
安全分析員可以通過人工的方式分析排名靠前的路徑是否符合攻擊模式和弱點利用的邏輯.表3 列出了使用波束搜索得到的得分最高的5 條路徑.
表3 中的正確答案實體進行了加粗,帶有下劃線的實體同樣也是該問題的答案,因為該問題有多個答案,帶下劃線實體并不是當前測試三元組的正確答案.
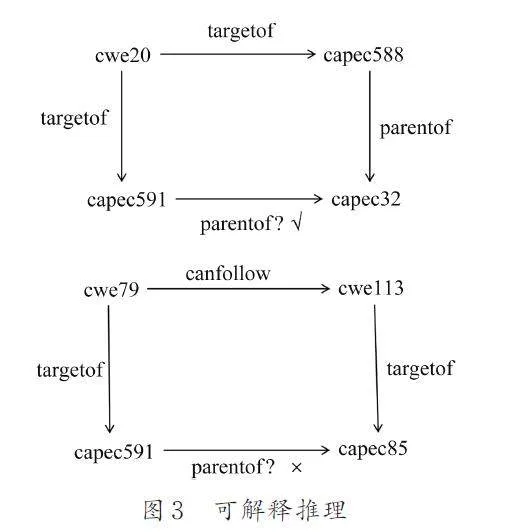
根據表3 得到的得分最高的路徑是(capec591-targetof-1-gt;cwe20-targetof-gt;capec588-parentof-gt;capec32).
圖3 表示的是推理路徑的解釋過程. 分析第1條路徑,得到攻擊模式capec591( 反射XSS)和capec588(基于Dom 的XSS)都利用了弱點cwe20(輸入驗證不當),而capec588(基于Dom 的XSS)是capec32(http 字符查詢)的父級節點,那么反射capec591(反射XSS)則極有可能也是capec32(http字符查詢)的父級節點. 以上解釋合乎安全分析的邏輯,安全分析員可以以此確定其為正確推理.
分析第3 條路徑,得到攻擊模式capec591 利用弱點cwe79,攻擊模式capec85 利用弱點cwe113,而弱點cwe113 是利用弱點cwe79 的前置條件. 這樣的路徑并不能構成合乎邏輯的證據來說明攻擊模式capec591 是capec85 的父級節點. 所以安全分析員可以確定該路徑為錯誤推理.
4. 2. 4 消融實驗
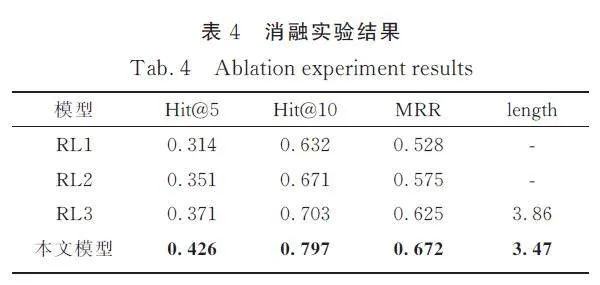
為觀察所設計的獎勵函數計算方法的有效性,本文設計了消融實驗,將獎勵函數的每個部分分別去掉,然后重新進行鏈路預測實驗. 如下式(14)是一般RL 模型的獎勵函數.
在式(15)中,移除無法找到正確答案時的獎勵,以此來觀察模型訓練中尋路失敗時獎勵的有效性.
在式(16)中移除訓練時尋路的長度獎勵,以此來觀察該部分對路徑長度的影響.
表4 列出了在移除不同獎勵函數部分之后模型的鏈接預測效果,本文取得分top-5 的路徑長度的平均值作為length 的值.
在消融實驗中,可以看到在使用一般形式的獎勵函數時,本文方法的預測性能下降比較明顯.移除基于嵌入模型的獎勵函數部分后的性能也有一定的下降. 最后在移除長度獎勵部分之后,得到的推理路徑長度小幅度變長,這表明軟件安全知識圖譜中的推理路徑長度為3 的占比較多.
5 結論
知識圖譜表示學習是預測軟件安全實體關系的重要手段. 針對現有預測方法不具有可解釋性的問題,本文提出基于強化學習的軟件安全實體預測方法. 在軟件安全實體關系的鏈接預測任務中,hit@5 為0. 426,hit@10 為0. 797,MRR 為0. 672. 在事實預測任務中,準確率為0. 802,精確率為0. 916,召回率為0. 415,F1 為0. 571. 本文模型除了給出答案外還給出了推理路徑,是具有良好可解釋性的模型. 同時本文設計的獎勵函數在一定程度上緩解了多跳模型對鏈接預測實驗準確率的影響.
今后的工作可以結合圖注意力機制,研究如何提高多跳模型的準確率,以及如何評估可解釋性. 這對軟件安全實體關系預測的研究具有積極作用.
參考文獻:
[1] Wu Y, Gandhi R A, Siy H. Using semantic templatesto study vulnerabilities recorded in large softwarerepositories [C]//Proceedings of the 2010ICSE Workshop on Software Engineering for SecureSystems. Cape Town, South Africa: ACM,2010: 22.
[2] The MITRE Corporation. CVE [EB/OL].(2022-08-14)[2023-04-10]. https://cve. mitre. org.
[3] The MITRE Corporation. CWE [EB/OL].(2023-03-22)[2023-04-10]. https://cwe. mitre. org.
[4] The MITRE Corporation. CAPEC [EB/OL].(2022-07-06)[2023-04-10]. https://cwe. mitre. org.
[5] Han Z, Li X, Liu H, et al. Deepweak: Reasoningcommon software weaknesses via knowledge graphembedding [C]//2018 IEEE 25th International Conferenceon Software Analysis, Evolution and Reengineering(SANER). Campobasso, Italy: IEEE,2018: 456.
[6] Mikolov T, Sutskever I, Chen K, et al. Distributedrepresentations of words and phrases and their compositionality[ J]. NIPS, 2013, 2: 3111.
[7] Du H F, Wang H F, Shi Y H, et al. Progress,challengesand research trends of reasoning in multi-hopknowledge graph based question answering [J]. BigData Research, 2021, 7: 60.[杜會芳, 王昊奮, 史英慧, 等. 知識圖譜多跳問答推理研究進展,挑戰與展望[J]. 大數據, 2021, 7: 60.]
[8] Xiong W, Hoang T, Wang W Y. DeepPath: A reinforcementlearning method for knowledge graph reasoning[C]//Proceedings of the 2017 conference onempirical methods in natural language processing. Copenhagen,Denmark: ACL, 2017: 564.
[9] Das R, Dhuliawala S, Zaheer M, et al. Go for a walkand arrive at the answer: Reasoning over paths inknowledge bases using reinforcement learning[ C]//6thInternational Conference on Learning Representations.Vancouver, Canada: OpenReview, 2018.
[10] Lv X, Han X, Hou L, et al. Dynamic anticipationand completion for multi-hop reasoning over sparseknowledge graph [C]//Proceedings of the 2020 conferenceon empirical methods in natural language processing.Punta, Cana: ACL, 2020: 5694.
[11] Xiao H B, Xing Z C, Li X H, et al. Embedding andpredicting software security entity relationships: Aknowledge graph based approach [C]//Internationalconference on neural information processing ICONIP2019. Sydney, Australia: Springer, 2019: 50.
[12] Liu Y, Bai Y D, Xing Z C, et al. Predicting entityrelations across different security databases by usinggraph attention network [C]//2021 IEEE 45th annualcomputers, software, and applications conference.Madrid, Spain: IEEE, 2021: 834.
[13] Wang Y, Hou X W, Ma X, et al. A software securityentity relationships prediction framework basedon knowledge graph embedding using sentence-Bert [C]//Wireless algorithms, systems, and applications17th international conference. Dalian, Chnia:Springer, 2022: 501.
[14] Bordes A, Usunier N, Garcia-Durán A, et al. Translatingembeddings for modeling multi-relationaldata [C]//Proceedings of the 26th international conferenceon neural information processing systemsvolume2. Lake Tahoe Nevada, America: ACM,2013: 2787.
[15] Wang Z, Zhang J, Feng J, et al. Knowledge graphembedding by translating on hyperplanes [C]//Proceedingsof the twenty-eighth AAAI conference onartificial intelligence. Quebec City, Canada: ACM,2014: 1112.
[16] Lin Y K, Liu Z Y, Sun M Y, et al. Learning entityand relation embeddings with entity description forknowledge graph completion [C]//Proceedings ofthe twenty-ninth AAAI conference on artificial intelligence.Austin, America: ACM, 2015: 2181.
[17] Ji G L, He S Z, Xu L H, et al. Knowledge graphembedding via dynamic mapping matrix [C]//Proceedingsof the 53rd annual meeting of the associationfor computational linguistics and the 7th internationaljoint conference on natural language processing( volume1: long papers). Beijing, China: ACL,2015: 687.
[18] Hou Z N, Jin X L, Chen J Y, et al. Survey of interpretablereasoning on knowledge graphs [J]. J Software,2022, 33: 4644.[侯中妮, 靳小龍, 陳劍赟,等. 知識圖譜可解釋推理研究綜述[J]. 軟件學報,2022, 33: 4644.]
[19] Balazevic I, Allen C, Hospedales T. TuckER: Tensorfactorization for knowledge graph completion[ C]//Proceedings of the 2019 conference on em?pirical methods in natural language processing and the9th international joint conference on natural languageprocessing (EMNLP-IJCNLP). Hong Kong,China: ACL, 2019: 5185.
[20] Kingma D P, Ba J. Adam: A method for stochasticoptimization [C]//3rd international conference forlearning representations. San Diego, America: Open?Review, 2015.
(責任編輯: 白林含)
基金項目: 四川省科技計劃項目資助(2022YFG0171); 專職博士后研發基金資助(SCU221092)
