基于圖像處理和深度學習的答題卡評分算法
2024-09-04 00:00:00張志方少卿
電腦知識與技術 2024年20期



關鍵詞:答題卡識別;圖像處理;深度學習;OCR識別;文本相似度計算
0 引言
隨著教育信息化的發展,答題卡作為一種常見的考試方式,被廣泛應用于各種教育場景,如學校的期中考試、期末考試、高考、托福、雅思等。然而,傳統的答題卡評分方法需要人工掃描和閱卷,耗時耗力,且容易出錯。因此,如何利用計算機技術實現對答題卡的自動識別和評分,是一個亟待解決的問題。
圖像處理是一種利用計算機對數字圖像進行分析和處理的技術,它可以實現對圖像中信息的提取、變換和增強。圖像處理技術在答題卡識別和評分中的主要作用是對答題卡圖像進行預處理,如去噪、灰度化、二值化等,以便于后續的圖像識別和分析。
深度學習是一種基于多層神經網絡的機器學習方法,它可以從大量數據中自動學習特征和規律,實現對復雜問題的高效求解。深度學習技術在答題卡識別和評分中的主要作用是對答題卡中主觀題答案的相似度計算、成績統計等。
基于圖像處理和深度學習的答題卡識別和評分算法是一種結合了圖像處理技術和深度學習技術的答題卡評分方法,它可以實現對答題卡的自動識別和評分,提高評分的效率和準確性,減輕教師的工作負擔,為教育改革和教學改進提供科學依據。
近年來,基于圖像處理和深度學習的答題卡識別和評分算法受到了國內外學者的廣泛關注,取得了一些研究進展。例如,高強[1] 等人提出了一種基于Hough和Canny的機器視覺方法對答題卡的客觀題進行評分的處理方法,實現了對答題卡的客觀題成績分析。杜聰[2]提出了一種基于圖像處理和卷積神經網絡的技術,實現了對答題卡的客觀題自動識別和評分。陳敏[3]提出了一種基于MATLAB的答題卡檢測系統,利用數字圖像處理的手段,實現了對答題卡圖像的預處理、傾斜校正和識別判斷。NV7VSbdvhpLL+wJkr6uJbll/670P+ANIYVxKvlCkdys=
盡管已有一些研究成果,但是基于圖像處理和深度學習的答題卡識別和評分算法仍然存在一些問題和挑戰,如答題卡圖像的質量、光照、尺寸、傾斜等因素的影響,能否對主觀題進行識別、主觀題的手寫風格、答案的語義理解等因素的影響,以及算法的通用性、魯棒性、可擴展性等因素的影響。因此,本文旨在針對這些問題和挑戰,提出一種更優化、更智能、更實用的基于圖像處理和深度學習的答題卡識別和評分算法,為答題卡評分提供一種新的解決方案。本文的主要貢獻如下:
1) 提出了一種圖像處理方法,可以對答題卡圖像進行預處理,如去噪、灰度化、二值化、校正等,以便于后續的圖像識別和分析。
2) 提出了一種基于深度學習的方法,可以對經過OCR[4](Optical Character Recognition,光學字符識別)識別出的主觀題答案與正確的主觀題答案進行句子相似度計算,對結果進行分析與成績統計。
3) 在真實的答題卡數據集上進行了實驗,驗證了本文算法的有效性和準確性,與人工評分的結果進行了對比,表明本文算法可以大大提高答題卡評分的效率和質量。
1 相關工作
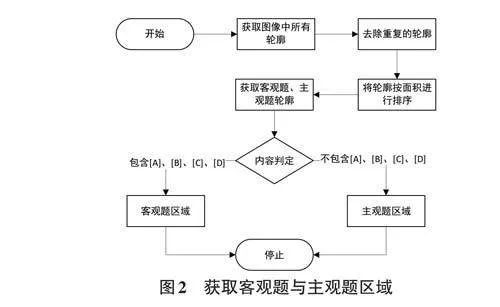
答題卡識別評分通常包括兩個部分的工作:客觀題的識別與評分,以及主觀題的識別與評分。因此,首先需要提取答題卡中客觀題與主觀題的區域。這可以通過圖像預處理以及OCR技術來獲取相應區域的輪廓。
對于客觀題的處理,通常使用圖像輪廓的相關方法進行答案的獲取。當然,還可以使用透視變換等其他技術,不同的方法適用于不同的場景。
主觀題的識別同樣運用了OCR技術。在評分時,需要對兩個句子的相似度進行計算。可采用的方法有多種,例如:1) 余弦相似度[5]:通過計算兩個向量間的夾角余弦值來衡量它們的相似程度。2) Jaccard相似度[6]:通過計算兩個集合的交集與并集的比值來衡量它們的相似度。3) 編輯距離[7]:通過計算將一個句子轉換為另一個句子所需的最小插入、刪除和替換操作步驟數。
本研究采用BERT[8](Bidirectional Encoder Repre?sentations from Transformers,基于Transformer 的雙向編碼器)模型進行句子相似度的計算。
1.1 光學字符識別
OCR(Optical Character Recognition,光學字符識別)是指對文本材料的圖像文件進行分析識別處理,以獲取文字和版面信息的過程。簡言之,就是將圖像中的文字識別并轉換為文本形式。OCR的基本流程可以簡單分為以下幾個步驟:
1) 預處理。對輸入的圖像進行預處理,包括圖像去噪、二值化、灰度化、裁剪等操作,以提高后續字符識別的準確性。
2) 特征提取。提取圖像中的特征,例如字符的邊緣、形狀、像素分布等信息,用于區分不同的字符。
3) 字符分類。使用機器學習或模式識別算法對提取的特征進行分類,將字符識別為對應的文本。
4) 后處理。對識別結果進行后處理,包括校正、校驗、拼接等操作,以提高識別準確性和整體質量。
目前,有許多開源的OCR工具和框架,可用于不同的應用場景和語言。比如:PaddleOCR[9]:飛槳首次開源文字識別模型套件,旨在打造豐富、領先、實用的文本識別模型/工具庫。CnOCR[10]:Python3下的文字識別工具包,支持簡體中文、繁體中文(部分模型)、英文和數字的常見字符識別,支持豎排文字的識別。EasyOCR[11]:一種通用的OCR,可以讀取自然場景文本和文檔中的密集文本。TesseractOCR[12]:可在各種操作系統運行的OCR引擎,是比較常用的一種文本識別工具。Chineseocr[13]:常用于中文文本識別的工具。
1.2 BERT 模型
BERT (BidirectionalEncoder Representationsfrom Transformers) 是一種基于Transformer架構的預訓練語言模型,由Google在2018年提出。它通過在大規模文本語料庫上進行無監督的預訓練,學習文本中的語義信息,并將學到的知識編碼為詞向量或句子向量。BERT可應用于多種自然語言處理任務,如文本分類、命名實體識別、問答系統等。
BERT模型的主要特點包括:
1) 雙向性。BERT采用雙向Transformer編碼器,能夠同時考慮文本中左右兩個方向的上下文信息,從而更好地捕捉單詞之間的關系。
2) 多層表示。BERT模型由多個Transformer編碼器堆疊而成,每個編碼器包含多個自注意力層和前饋神經網絡層,可以學習不同層次的文本表示。
3) 預訓練與微調。BERT模型首先在大規模文本語料上進行預訓練,然后可以在特定任務上進行微調,以適應不同的應用場景。
在句子相似度計算中,BERT模型通常采用以下步驟:1) 輸入表示。將兩個句子分別進行分詞,并添加特殊的開始和結束標記,然后將分詞結果轉換為詞向量。
2) 編碼器堆疊。將詞向量輸入BERT模型的多個編碼器中,每個編碼器會逐步提取句子的語義信息,生成多層次的表示。
3) 池化。從編碼器的輸出中選擇一個特定的表示,通常選擇CLS標記對應的向量作為整個句子的表示。
4) 相似度計算。通過計算兩個句子的表示之間的余弦相似度或其他相似度度量方法,來評估兩個句子之間的相似程度。
BERT模型在句子相似度計算中的應用原理主要是利用其在大規模語料上學習到的語義信息,將句子表示映射到高維空間中,然后計算它們之間的距離或相似度,從而判斷句子之間的語義相似度。由于BERT模型能夠考慮到句子中的上下文信息和詞語之間的關系,因此在句子相似度計算任務中通常能夠取得較好的性能。
2 算法具體實現
2.1 圖像預處理
獲取完整的答題卡圖像后,須對圖像進行去噪處理,以獲得可識別的答題卡圖像。本實驗采用以下步驟進行去噪。
去除圖像噪點后,開始對圖像中的客觀題與主觀題區域進行截取。此過程主要通過分析答題卡各輪廓的面積來實現。
通過上述步驟,可以從答題卡圖像中提取出評分所需的客觀題和主觀題答題區域。
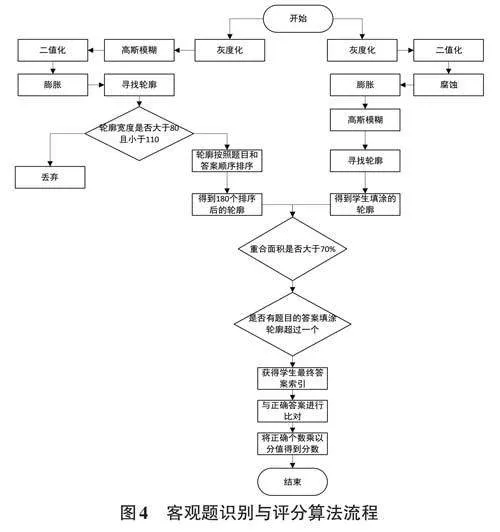
2.2 客觀題識別及評分
客觀題的識別主要通過計算兩種輪廓來確定學生的選擇題答案:一種是所有答案的輪廓,另一種是學生填涂的答案輪廓。通過計算這兩種輪廓的重疊面積,可以確定學生所選擇的答案。獲得客觀題區域截圖后,按照以下步驟處理即可得出學生客觀題的最終得分。
在上述流程中,對輪廓進行排序時,首先獲得180 個輪廓,然后通過輪廓計算其中心點。將這些中心點按照題號及四個選項的順序進行排序,從而得到排序后的180個坐標點。根據這180個坐標點分別被包含在哪個輪廓區域內,可以對180個輪廓進行排序。
隨后,通過計算學生填涂區域與排序后的180個輪廓的重合面積,可以判定學生客觀題填涂的具體答案。重合面積判定標準設定為70%,即重合部分面積小于輪廓面積的1.3倍時,判定兩個輪廓重合。將最終獲得的正確答案數量乘以對應題目的分值,即可得到客觀題的最終得分。
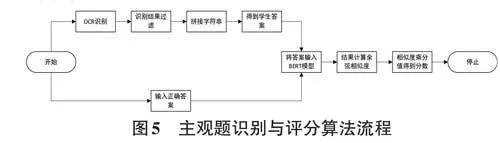
2.3 主觀題識別與評分
主觀題的識別主要依靠OCR技術和BERT大模型進行答案提取與相似度計算。具體實現步驟如圖5 所示。
本研究使用的OCR技術為PaddleOCR技術,從主觀題的答題區域識別學生的手寫答案。將識別出的字符串進行拼接,得到完整的學生答案。隨后,將手動輸入的正確答案與學生答案作為模型輸入,通過BERT模型轉換為兩個句子向量。利用余弦相似度計算這兩個向量的相似度,得到一個0到1之間的數值,其中0表示兩個句子的意思完全不同,1表示兩個句子的意思完全一致。將相似度結果與該題目的分值相乘,即可得到最終的主觀題得分。
2.4 結果分析
根據上述算法步驟,本實驗采用了一種通用的答題卡進行識別及評分。具體實現結果如圖6所示。
從圖6可以看出,學生填涂的45個題目答案均被正確檢測。與正確答案比對后發現,學生正確回答了45道選擇題,每題2分,因此選擇題最終得分為90分。在主觀題部分,學生手寫答案與OCR識別后的答案幾乎一致,僅有部分標點符號存在微小差異,但這并不影響語句的整體含義。經BERT模型計算,兩個答案的相似度為90%。該題目滿分為10分,因此學生在這部分獲得9分。將兩部分得分相加,得到學生的最終得分99分。
圖6中答題卡的科目區域顯示“90+10”,代表教師手動改卷的得分,其中90為選擇題分數,10為主觀題分數,最終總分為100分。這表明,基于圖像處理和深度學習的答題卡識別和評分算法與人工評分方法的結果幾乎一致。此外,該算法在處理速度上有顯著提升,同時可以避免人為主觀影響和人工誤差等問題。
3 總結與展望
本研究提出了一種結合圖像處理、OCR技術及深度學習模型的算法,用于識別和評分學生答題卡。該方法首先將答題卡中的客觀題與主觀題分開處理。對于客觀題,通過圖像輪廓篩選、排序以及重合面積計算,能夠快速獲取學生的答案并計算得分。主觀題部分則采用OCR 技術獲取學生手寫答案,并利用BERT模型對學生答案與標準答案進行相似度計算,將結果乘以分值得到主觀題得分。最后,將客觀題和主觀題得分相加,得出學生的最終成績。
盡管本研究已取得一定成果,仍有改進空間。例如,可以擴展答題卡的題目類型,并考慮光照條件和答題卡印刷質量對圖像處理的影響。因此,后續研究可探討如何避免圖像受到此類問題的干擾。總體而言,該算法在當前答題卡視覺識別與評分領域展現出一定的創新性,并取得了較好的效果。
