基于Storm的可擴展的分布式網絡爬蟲系統設計研究
2024-09-04 00:00:00池國俊
電腦知識與技術 2024年20期
關鍵詞:Storm;可擴展;分布式;網絡爬蟲;系統設計
0 引言
在互聯網時代背景下,大量新型商業模式被廣泛應用于互聯網領域中,造成互聯網上所創建的站點數量急劇增加,導致互聯網上的信息資源呈現出指數型爆炸式增長。在海量互聯網信息資源中,人們若想快速檢索和查閱自己感興趣的網絡資源,必須加強對網絡爬蟲技術的應用[1]。然而,傳統單機網絡爬蟲技術過于落后,難以滿足現代化日益增長的數據抓取使用需求。分布式網絡爬蟲系統的設計和應用可以解決上述問題,該系統主要應用Storm云平臺,確保多臺機器在運行期間能夠高效地分工合作,使得網絡爬蟲速率和性能不斷提升。因此,在Storm云平臺的應用背景下,強化對新型分布式網絡爬蟲系統設計和實現的研究顯得尤為重要。
1 提出問題
傳統單機網絡爬蟲技術因過于落后,難以滿足現代化日益增長的數據抓取使用需求。而分布式網絡爬蟲系統的設計和應用可以解決以上問題,該系統主要應用Storm云平臺,確保多臺機器在運行期間,能夠高效地分工合作,使得網絡爬蟲速率和性能不斷提升。
2 具體設計方案
2.1 系統設計原則與關鍵技術
2.1.1 系統設計原則
該系統設計目的是提高分布式網絡爬蟲的速度和性能,為用戶打造安全可靠的網絡環境。因此,系統設計應遵循以下幾個原則:1) 效率性原則。通過提升系統效率,避免因系統運行過慢而降低用戶體驗。為滿足系統效率性需求,應將系統內部網絡帶寬設置在萬兆以上,避免因網絡運行緩慢而降低系統整體運行效率。2) 可靠性原則。系統可靠性主要是指系統正常執行一段時間所對應的概率,系統實際運行過程中,如果出現非法輸入數據行為,或者某硬件部分出現異常問題,此時,系統仍然繼續穩定執行相關功能的概率,通過提高系統可靠性,可以確保系統能夠正常、穩定、安全地運行。3) 安全性原則。系統安全性需求主要涉及數據預防丟失、禁止網絡病毒入侵系統等,通過對系統進行安全化設計,可以實現對系統數據訪問流程的保護,避免系統數據出現丟失、泄露等風險,同時,還要加強對系統權限安全化管理,避免因出現非法人員登錄和訪問該系統造成重要系統數據丟失。
2.1.2 Storm 云平臺
Storm的出現填補了這一空白。Storm云平臺由Nathan Marz開發,后被Twitter收購。收購后,Twitter 將Storm開源,隨后社區越來活躍,使用者越來越多,名聲大噪,被很多企業采納使用,甚至很多被用于二次開發,催生了許多優秀產品。Storm主打計算實時流數據,使得對源源不斷的流數據處理起來變得更加方便,彌補了Hadoop批處理在實時數據的低效性[2]。
2.2 系統總體設計
2.2.1 系統框架設計
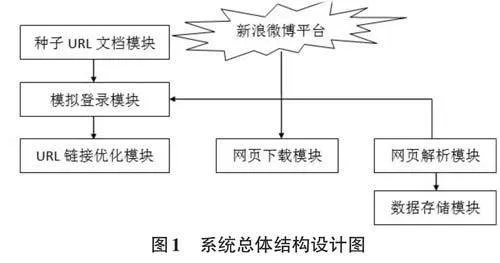
應用本文系統抓取新浪微博平臺數據時,首先,利用Storm云平臺對網絡爬蟲相關數據進行抓取,隨后,將抓取好的數據安全傳輸并存儲至分布式數據庫中,為后期的聚類、分類等業務處理提供依據。與傳統單機網絡爬蟲技術相比,本文系統具有數據處理速度快、容錯性高等優勢。本文系統總體框架如圖1所示,從圖1中可以看出,本文系統主要包含種子URL 文檔、模擬登錄、URL優化鏈接、網頁下載等模塊,這些模塊既相互獨立又相互聯系,在實際運行期間分工明確[3]。
2.2.2 系統數據庫設計
當網絡數據被成功抓取后,需將抓取的數據存儲到數據庫中,以便后期相關人員查看和調用。因此,在進行本文系統設計期間,要重視對系統數據庫的設計。系統數據庫中包含多種數據表,為保證數據庫設計質量,本文重點設計了搜索結果表、用戶信息表、微博評論信息表、微博轉發信息表等數據表[4]。其中,搜索結果表包含微博發表時間、微博發表設備、微博地址、微博內容等屬性;用戶信息表包含用戶姓名、用戶昵稱、用戶地址、用戶粉絲數、用戶微博數、用戶關注數等屬性;微博評論信息表主要包含微博評論內容、評論時間、被點贊次數等屬性;微博轉發信息表主要包含微博轉發時間、微博轉發次數、微博點贊次數、微博URL地址等屬性。
另外,為確保所設計的數據庫能更好地滿足數據的增刪改查操作,現將數據庫操作封裝類的主要代碼編寫如下:
2.3 系統模塊設計
2.3.1 種子URL 文檔模塊
首先初始化種子URL文檔。Storm集群在Topol?ogy的Spout中將該種子URL讀入集群中,作為網絡爬蟲的入口。在該Topology中,Spout為系統消息讀入的接口,因此種子URL在該Spout中的nextTuple()函數中發送給下一個Bolt來處理。Storm的Topology在初始化的時候會先初始化open()函數,因此種子URL可以在該函數中直接獲取[5]。
2.3.2 模擬登錄模塊設計
模擬登錄模塊是使用程序模擬真實新浪微博用戶來登錄新浪微博平臺,目的是獲取Cookie。其中,需要跟新浪微博身份認證平臺進行一系列的交互。
2.3.3 URL 優化鏈接模塊
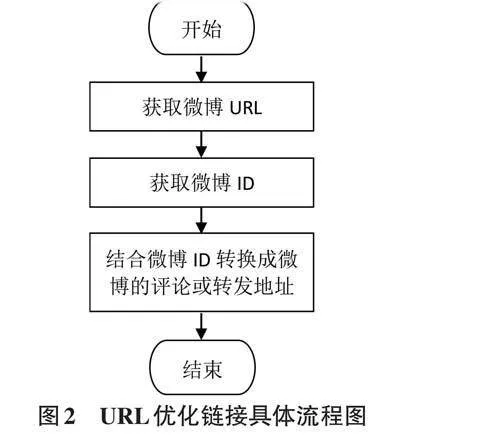
URL優化鏈接的具體流程如圖2所示。從圖2中可以看出,首先獲取微博URL,通過應用Chrome瀏覽器開發工具快速查找和獲取微博URL地址(如:http://weibo. com/aj/v6/comment/big? id=3817652743101226&page=2) 。其次,獲取微博ID。結合所獲取的微博URL,不難發現微博的唯一ID為“3817652743101226”。最后,對獲取的微博URL地址進行轉化,使其轉化為某條微博評論或者轉發期間可以翻頁的地址,該地址可被新浪微博平臺快速識別和獲取[6]。
2.3.4 網頁下載模塊設計
在設計網頁下載模塊時,為提高網頁下載速度,須運用多線程思想。具體操作包括:使用線程連接池對線程進行統一管理,減少線程的創建或者銷毀,從而達到提高系統程序執行性能的目的。在進行網頁信息抓取時,要運用get請求,當get請求發送結束后,從新浪微博平臺中抓取和查找HTTP狀態響應值。針對所獲取的狀態響應值進行個性化操作和處理。當響應碼顯示為“200”,說明本文系統服務器成功接收和發送get請求,并成功返回相應的響應數據,此時網頁下載成功[7]。
2.3.5 網頁解析模塊設計
運用網頁下載模塊,所下載的網頁通常含有冗余、無利用價值的數據,此時,需要將所下載好的原始網頁數據傳輸和發送至網頁解析模塊,由網頁解析模塊對這些數據進行篩選解析處理。在設計網頁解析模塊時,通常會用到HTML文檔解析器。該解析模塊所解析內容主要包含以下兩個部分:1) 從網頁中,解析出所需要的URL鏈接,然后,將該鏈接發送和傳輸至URL鏈接優化模塊中,由URL鏈接優化模塊對該鏈接進行優化處理,并將最終優化處理結果發送和存儲至數據庫中[8]。2) 從網頁中解析出微博評論等所需數據。總之,網頁解析模塊用于對微博數據、微博用戶數據、微博轉發數據等多種數據的統一解析處理。
2.3.6 數據存儲模塊設計
在設計數據存儲模塊時,需要使用Java來操作分布式數據庫,需要在工程中添加mongojavadriver2.9.3.jar依賴,而后可以通過程序來對分布式數據庫進行增刪改查等操作。在操作整個集群的時候,由于仲裁節點不存儲數據,只負責投票,因此前端不需要連接到仲裁節點。在分布式數據庫中建立一個名為“的數據庫,然后連接到數據庫中具體的集合。
3 設計方案執行效果
3.1 Storm 集群環境搭建
在Storm集群中,含有三個節點,這些節點主要運行于Nimbus、Supervisor后臺程序中。在搭建Storm集群環境時,需要在下載和安裝Zookeeper集群的基礎上,做好對Storm相關參數的配置,然后,啟動所創建好的Storm集群。
3.2 系統功能測試
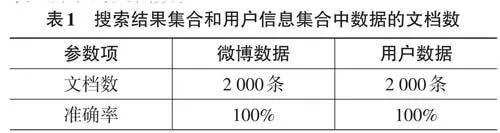
為測試系統功能實現效果,本文以“新浪微博”為應用場景,通過對“地震”“傷亡”關鍵字眼進行主題搜索,從微博數據、用戶數據兩個角度分析,測試系統所抓取信息數據情況。通過搜索以上關鍵字眼,系統會自動呈現出2 000條微博數據,即2 000個用戶發表了2 000條微博數據。通過查看分布式數據庫,獲得如表1所示的文檔數。
從表1中的數據可以看出,本文系統抓取準確率達到百分之百,這說明新浪微博中“地震”“傷亡”不同主題下的各項數據均成功抓取。因此,本文系統所含有的模擬登錄、網頁下載、數據存儲等功能模塊可以正常、穩定地運行。
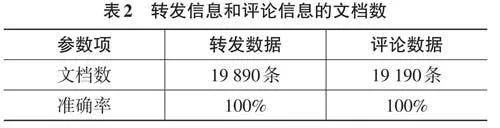
為測試和驗證本文系統在抓取微博評論信息、微博轉發信息方面的性能,以“某一條微博”為案例,該條微博含有19 890條微博轉發量和19 190條微博評論量,通過調用分布式數據庫查看轉發信息和評論信息所對應的文檔數,獲得如表2所示的查看結果。
從表2中的數據可以看出,本文系統抓取準確率達到百分之百,這說明本文系統全部下載所有評論數、轉發數。因此,本文系統通過利用微博的UR地址,可以成功抓取和獲得所有微博的評論數和轉發數,具有穩定可靠、數據處理能力強等特點。
4 結束語
綜上所述,本文所設計的分布式網絡爬蟲系統主要運用Storm云平臺,該云平臺具有強大的在功能拓展性和并行處理能力等特性,通過運用Storm云平臺這些特性,可以最大限度地提高分布式網絡爬蟲速度和性能。本文系統在具體設計時,選用“新浪微博”這一應用場景,通過抓取新浪微博平臺相關數據,并將所抓取好的數據安全、可靠地存儲到指定的數據庫中,方便其他人員查看和調用。總之,本文提出的基于Storm可擴展的分布式網絡爬蟲系統設計方案具有較高的有效性和可靠性;實現對系統種子URL文檔、模擬登錄、URL優化鏈接、網頁下載等多個模塊的成功設計和開發,保證系統各功能模塊運行安全性和可靠性,符合預期設計標準和要求,值得被進一步推廣和應用。
