基于機器學習的惡意網站分類研究
2024-09-04 00:00:00聶碹乃皮沙·艾斯卡爾謝志杰高福陽李軒張志豪
電腦知識與技術 2024年20期

關鍵詞:機器學習;數據采集;Web安全;惡意網站;監督式學習
0 引言
進入Web2.0時代以來,每天都有海量信息資源發布在各種網站上。人們在享受互聯網發展帶來便利的同時,遭受網絡攻擊的情況也日益增加。各種掛馬網站、色情網站、暴力網站、詐騙網站等利用不正當手段,通過偽裝成正常網站,仿冒正常網站的URL地址或頁面內容,欺騙用戶以竊取個人信息(如信用卡、銀行卡賬戶、密碼等)和財產。在此過程中,面臨的安全形勢和即將應對的安全壓力日顯迫切。根據相關報告顯示,惡意網站已成為當今網絡安全所面臨的主要威脅之一。
針對惡意網站鑒別問題,研究人員提出了多種識別技術和方案。Justin Ma 等學者利用DNS 信息、WHOIS信息和URL語法特征結合機器學習算法來辨識惡意URL[1]。Davide Canali及其團隊在此基礎上加入了JavaScript和HTML特征,從而拓展至網頁內容檢測,提高了惡意網頁識別的準確度[2]。2012年,張慧琳等學者以網站木馬的原理為基礎,探討了掛馬檢測、特征分析和防范技術等方面,但缺少對各種檢測方法的橫向比較和深入探討[3]。這些研究成果為惡意網站識別領域的發展提供了重要參考和啟示。本文將根據現有技術和環境,以及本次設計的需求,結合所需的應用場景,實現基于機器學習的惡意網站分類研究。
1 機器學習基礎
1.1 機器學習概述
機器學習是一門多領域交叉學科,旨在從數據中學習算法。它試圖從海量歷史數據中提取隱含的模式,并將其應用于回歸(預測)或分類。概括而言,機器學習的目標是從機器中獲取直接編程所不能實現的特性。在現有數據或過去經驗的基礎上,進行機器學習算法的選擇、構造模型、對新數據進行預測,并將知識結構重新組合以持續改進性能。機器學習的一般過程如圖1所示。
機器學習建模過程中的相關術語解釋如表1所示。
1.2 機器學習算法
目前機器學習主要分為兩大類:有監督學習和無監督學習。兩者的區別在于訓練數據中是否包含目標變量。在監督學習中,提供了帶有正確結果標記的數據,即事先知道數據的正確輸出值。而在無監督學習中,數據并沒有標記。
1.2.1 有監督學習
有監督學習通過不斷迭代模型訓練進行。首先,利用正文內容中的系列變量創建一個函數,將輸入值映射為所需的輸出值。然后,通過迭代調整參數來提高預測能力。最后,通過增加新的參數值更新模型,直到模型從訓練數據中達到預設的準確性時停止訓練。典型的監督學習算法包括:邏輯回歸(Regres?sion) 、決策樹(Decision Tree) 、隨機森林(Random For?est) 和K最近鄰(KNN) 等。
1.2.2 無監督學習
無監督學習通常用于前期數據處理環節,主要功能是對原始數據集進行篩選并整理出標簽集。訓練集數據僅有特征x而無標簽y,其目的在于嘗試抽取數據所蘊含的結構與模式。常見的無監督學習算法有K-means、降維和文本處理(特征提取)等。
2 惡意網站分類方法構建
2.1 惡意網站定義
目前對惡意網站尚無明確的學術定義。Google 將其描述為一種不安全的網站,可能存在行為誘導用戶下載惡意軟件或通過網頁彈窗誘騙用戶輸入個人信息等[4]。百度百科則將惡意網站定義為故意執行惡意任務的病毒、蠕蟲和木馬的網站,其特征是采用網站形式正常展示內容,同時非法獲取用戶數據,甚至入侵用戶電腦系統[5-8]。這些定義有兩個要點:“在網頁上進行惡意攻擊”和“非法盜用用戶信息資料”。
2.2 惡意網頁識別
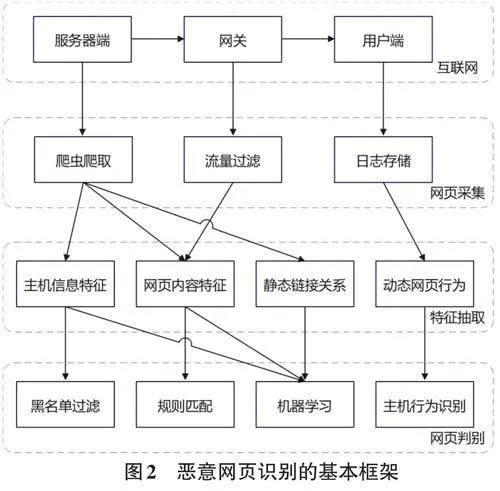
惡意網站識別是當今互聯網安全領域中的一個重要問題,其本質屬于一個二分類問題。雖然惡意網站的形態多樣,包括釣魚網站、惡意下載網站、欺詐網站等,其特征不易捕捉,但良性網站和惡意網站在內容和行為上存在顯著差異。惡意網頁識別通常包括以下三個關鍵步驟:網頁采集、特征抽取、網頁判別。
系統從互聯網上收集大量的網頁樣本,包括可能存在惡意內容的網頁和正常的良性網頁,作為后續特征抽取和模型訓練的數據來源。然后從采集到的網頁樣本中提取出一系列有助于區分惡意網頁和良性網頁的特征。這些特征可以包括網頁的結構特征、內容特征、域名特征、鏈接特征等。最后利用特征抽取得到的特征,結合訓練好的分類模型,對新的待分類網頁進行判斷,根據模型的輸出結果,將網頁劃分為惡意網頁或良性網頁。
惡意網站識別基本框架如圖2所示。
2.3 機器學習分類算法
2.3.1 邏輯回歸
邏輯回歸(Logistic Regression) 是一種計算過程類似于線性回歸的算法。線性回歸通常用于解決數據預測問題,而邏輯回歸則用于處理分類問題。邏輯回歸通過使用邏輯函數(也稱為Sigmoid函數)將連續的預測值映射到0~1的概率值,從而實現分類任務。在訓練過程中,邏輯回歸模型通過最大化似然函數來擬合數據,并利用梯度下降等優化算法來更新模型參數。
2.3.2 支持向量機
支持向量機(Support Vector Machine) 是目前廣泛使用的監督學習算法,主要用于分類問題和回歸分析。其核心思想在于通過在特征空間中找到一個最佳的邊界,這個邊界被稱為“超平面”,使得不同類別的樣本可以被有效地分離開來。
在訓練過程中,SVM通過最大化支持向量到超平面的距離,同時將分類錯誤的樣本點的分類間隔控制在一個合適的范圍內,以避免過擬合。當二元分類問題的正負樣本無法通過直線分割時,支持向量機可以利用靈活多樣的核方法將數據映射至高維空間,利用高維空間的超平面進行數據分離,從而實現在原始空間中無法線性分割的樣本分類。
2.3.3 決策樹
決策樹(Decision Trees) 是一種基于樹形結構的決策分類方法。它以直觀的方式呈現分類過程和結果,具有高效、易解釋和可視化等優點。
決策樹算法的生成過程包括特征選擇、節點劃分、遞歸構建和剪枝處理等步驟。特征選擇階段通過計算信息增益、基尼指數或信息熵等指標,選擇最佳特征進行節點劃分。然后,根據選定的特征對數據集進行劃分,生成子節點,并遞歸地構建決策樹,直到滿足停止條件。
2.3.4 隨機森林
隨機森林(Random Forest) 是一種隨機生成的算法。這種算法由多個決策樹組成,每棵決策樹都是獨立構建的,彼此之間沒有相關性。一旦建立了隨機森林模型,當新的輸入樣本到來時,可以分別對每棵決策樹進行獨立的判斷,然后綜合它們的結果來做出最終的分類決策,確定該樣本屬于哪一類別(在分類問題中)。隨后,統計出現次數最多的類別,從而預測該樣本所屬的類別。
2.3.5 K 最近鄰分類算法
K 最近鄰分類算法(k-Nearest Neighbors) 是一種基于實例的分類方法,屬于惰性學習(lazy learning) 。該算法通過在特征空間中找到與待分類樣本相似度最高的K個樣本,如果這K個樣本中的大多數屬于同一類別,則將待分類樣本劃分到這一類別。K最近鄰方法僅根據一個或多個最接近的鄰居來確定樣本的分類。K最近鄰算法沒有明確的訓練過程,而K值的選擇會顯著影響算法的結果。
3 惡意網站分類實證研究
3.1 數據采集與處理
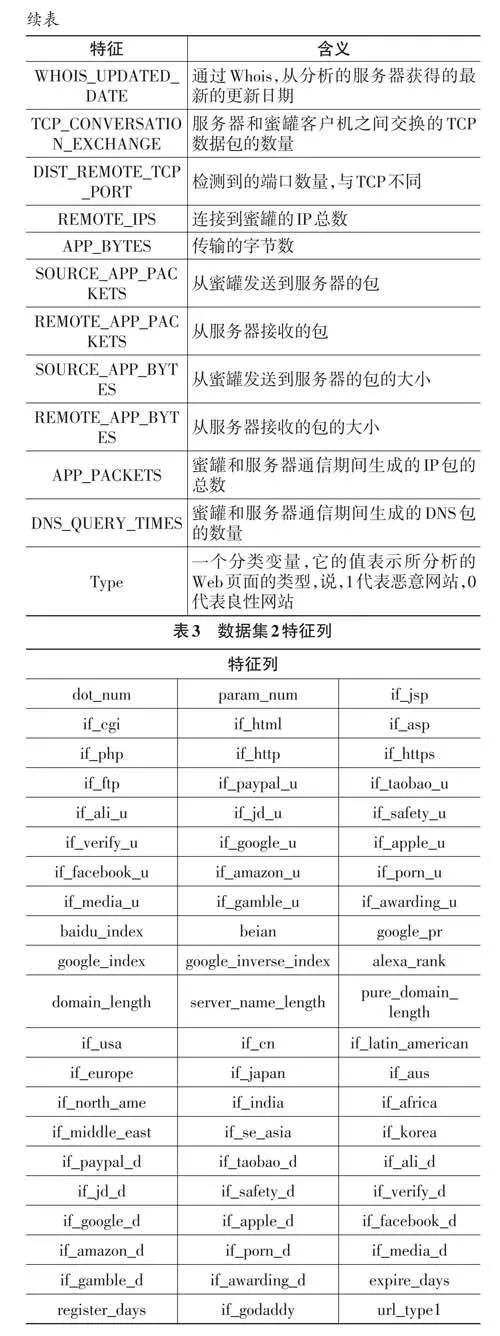
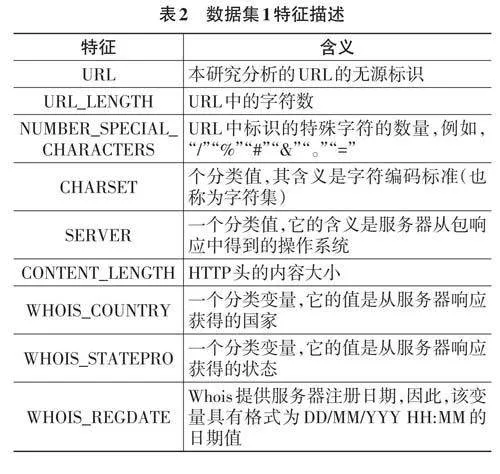
本文所使用的兩個數據集均來自Kaggle競賽平臺。數據集1共包含1 781條數據記錄,其中包括21 個特征(包括輸入和輸出)。在這些記錄中,良性網站數據有1 565條,惡意網站數據有216條。數據集2共包含50 000條記錄,包括63個特征。其中良性網站數據有35 056條,惡意網站數據有14 944條。數據集特征如表2和表3所示。
3.2 數據預處理
在數據預處理過程中,需要根據研究內容篩選出符合要求的數據集,并對數據進行預處理和必要的數據清洗,以滿足研究需求。具體步驟如下:
1) 刪除無關列:首先,移除數據集中的URL列,因為它僅作為唯一標識符,對于惡意網站的分類并不具備重要意義。
2) 處理空值:在數據集中,許多條目的CONTENT_LENGTH、SERVER 和DNS_QUERY_TIMES 存在缺失值。針對這種情況,需要填充CONTENT_LENGTH列的缺失值,并刪除包含其他兩個空值的條目。
3) 特征處理與數據分離:將數據集中的列轉換為虛擬列,并根據“類型”列將數據集分成兩個不同的數據幀。這樣在模型訓練時能更好地處理分類數據。
通過以上預處理步驟,可以準備好適合用于分類模型訓練的數據集,確保數據質量和特征的有效性,為后續的實驗提供可靠的基礎。
3.3 訓練模型
對于惡意網站分類任務,本文采用的算法包括邏輯回歸、支持向量機、決策樹、隨機森林和K最近鄰分類算法等。
在數據預處理完成后,根據7∶3的比例將收集到的數據集分離為訓練集(train) 和測試集(test) 。其中,X表示前19列作為輸入特征,Y表示最后一列"type" 作為輸出的預測結果(標簽),將得到的訓練集和測試集分別表示為:X_train, X_test, Y_train, Y_test。
利用訓練集(X_train, Y_train) 進行模型擬合(train?ing) ,通過學習樣本數據的特征與標簽之間的關系,調整模型參數以最大程度地擬合訓練數據,并在不同的特征空間中構建決策邊界,以實現對惡意網站的準確分類。
然后利用測試集(X_test) 對訓練好的模型進行評估。通過將測試集輸入訓練好的模型中,得到模型在未見數據上的分類結果,并計算模型的性能指標,如準確率、召回率、F1值等,用于客觀地評價模型的分類效果,并為進一步優化提供參考依據。
最后,對實驗結果進行分析和比較。通過比較不同算法模型在測試集上的表現,評估它們在惡意網站分類任務中的優劣勢,并找出最適合該任務的模型。同時對模型在不同參數設置下的性能進行分析,為模型調優和改進提供指導。
3.4 實驗結果與分析
1) 預測測試集數據。對測試集數據X_test分別賦予訓練后的模型以預測結果predict_Y。
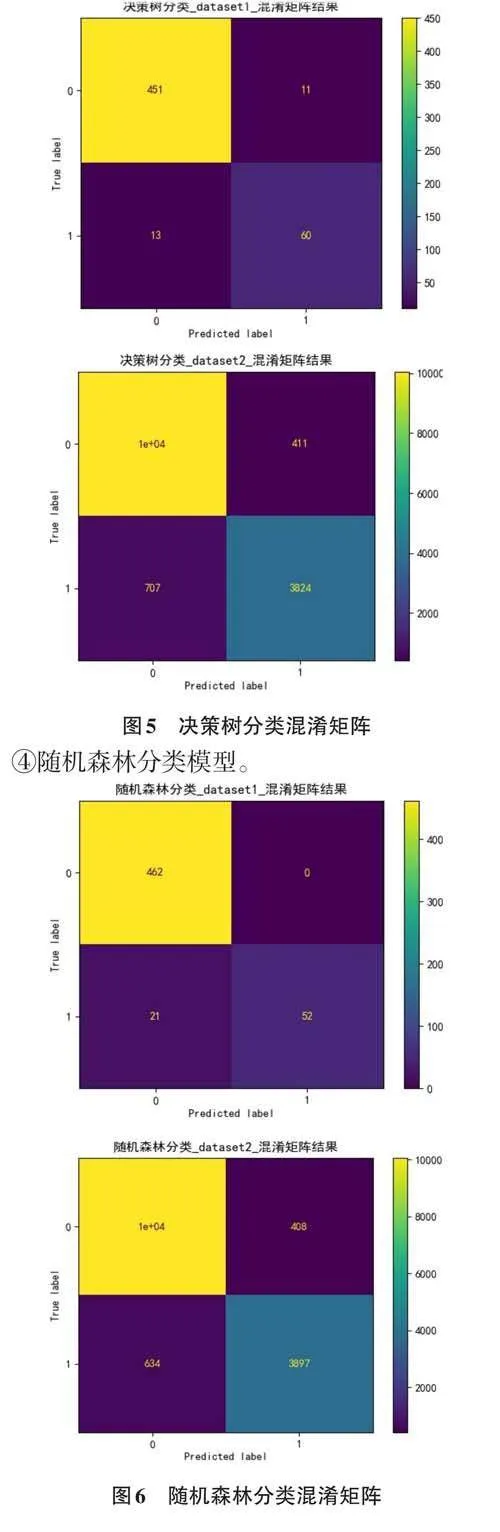
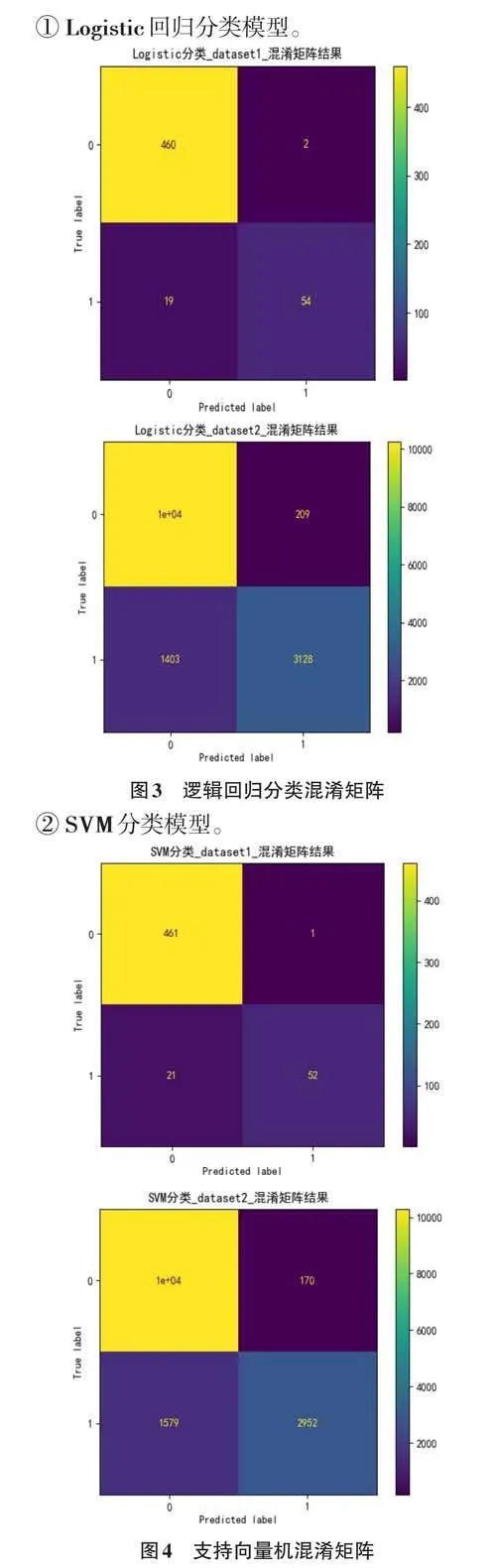
2) 分析預測準確性。對于兩個數據集中的數據,比較真實測試集中的Y_test和模型預測得到的pre?dict_Y的準確率。并通過混淆矩陣得出的結果展示圖如下:
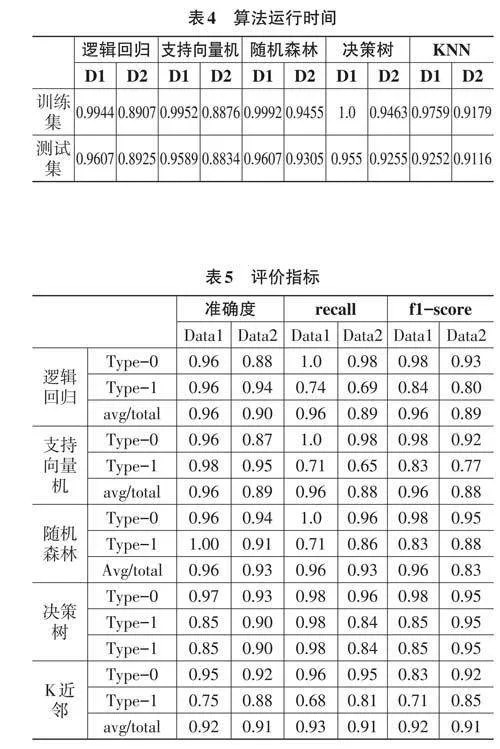
3) 得到結果。通過對比上圖中各個算法的混淆矩陣,可以發現在使用的5種算法中,支持向量機和隨機森林的準確率較高,而KNN算法的準確率最低。如表4所示,其中展示了訓練集和測試集的結果。
接下來,通過分類模型的幾個評價指標,包括召回率(recall) 和F1分數(f1-score) ,來評估各個分類模型的適用性。最終結果如表5所示:
4 結論
實驗初步結果表明,在應用的各個監督式學習算法中,支持向量機(SVM) 和隨機森林的預測準確率和模型評價指標表現較為理想。首先,SVM是對二分類問題效果最佳的算法模型,它在向高維空間映射時不會增加復雜度,能夠解決非線性特征的相互作用。然而,該算法仍存在一些缺點:SVM對缺失值敏感,當數據量大時訓練時間較長。此外,本研究中的模型使用默認參數,未進行參數調優,通過調優后預測效果可能會有所提升。
隨機森林算法本身的精度優于大多數單個算法,因此在測試集上表現良好,且具有較強的抗干擾能力。但是,它在解決回歸問題方面的表現不如分類問題。同時,隨機森林對小規模數據或低維數據的分類效果不佳。因此,這兩種算法在某些方面仍有提升空間。
