融合MacBERT和Talking?Heads Attention實體關系聯合抽取模型
2024-09-12 00:00:00王春亮姚潔儀李昭
現代電子技術 2024年5期







摘" 要: 針對現有的醫學文本關系抽取任務模型在訓練過程中存在語義理解能力不足,可能導致關系抽取的效果不盡人意的問題,文中提出一種融合MacBERT和Talking?Heads Attention的實體關系聯合抽取模型。該模型首先利用MacBERT語言模型來獲取動態字向量表達,MacBERT作為改進的BERT模型,能夠減少預訓練和微調階段之間的差異,從而提高模型的泛化能力;然后,將這些動態字向量表達輸入到雙向門控循環單元(BiGRU)中,以便提取文本的上下文特征。BiGRU是一種改進的循環神經網絡(RNN),具有更好的長期依賴捕獲能力。在獲取文本上下文特征之后,使用Talking?Heads Attention來獲取全局特征。Talking?Heads Attention是一種自注意力機制,可以捕獲文本中不同位置之間的關系,從而提高關系抽取的準確性。實驗結果表明,與實體關系聯合抽取模型GRTE相比,該模型[F1]值提升1%,precision值提升0.4%,recall值提升1.5%。
關鍵詞: MacBERT; BiGRU; 關系抽取; 醫學文本; Talking?Heads Attention; 深度學習; 全局特征; 神經網絡
中圖分類號: TN911.1?34" " " " " " " " " " " " " 文獻標識碼: A" " " " " " " " " " " "文章編號: 1004?373X(2024)05?0127?05
Entity relation joint extraction model fusing MacBERT and Talking?Heads Attention
WANG Chunliang1, YAO Jieyi1, 2, LI Zhao1, 2
(1. Hubei Key Laboratory of Intelligent Vision Based Monitoring for Hydroelectric Engineering, Yichang 443000, China;
2. College of Computer and Information Technology, China Three Gorges University, Yichang 443000, China)
Abstract: The existing models for the task of relation extraction of medical text have the deficiency of insufficient semantic comprehension during the training process. This may result in unsatisfactory extraction outcomes. Therefore, a joint extraction model that fuses MacBERT and Talking?Heads Attention for entity relation joint extraction is proposed. In the model, the MacBERT language model is utilized to obtain dynamic word vector representations. MacBERT, as an upgraded BERT model, can lessen the differences between the pre?training and fine?tuning stages, so as to improve the model′s generalization capability. The dynamic word vector representations are then fed into a bidirectional gated recurrent unit (BiGRU), so as to extract textual contextual features. BiGRU is an improved recurrent neural network (RNN) with better long?term dependency capture. After obtaining the text context features, the Talking?Heads Attention is used to obtain the global features. It is a self?attentive mechanism that can capture the relations between different locations in the text, so as to improve the accuracy of relation extraction. The experimental results show that the proposed model can improve the [F1] value by 1%, the precision value by 0.4% and the recall value by 1.5% in comparison with the entity relation joint extraction model GRTE.
Keywords: MacBERT; BiGRU; relation extraction; medical text; Talking?Heads Attention; deep learning; global feature; neural network
0" 引" 言
隨著生物醫學領域的不斷發展,醫療數據的數字化記錄日益增多。這些中文醫療文本中包含了豐富的醫學知識,如病歷、醫學文獻等。這些文本數據中包含著大量的實體和關系信息,如疾病、癥狀、藥物等實體以及這些實體之間的關系。因此,構建一個穩定的關系抽取模型,將非結構化文本信息精準和全面地自動轉化為符合大眾需求的結構化信息,對于支持醫療領域的各種應用,如知識圖譜[1]、信息檢索等具有重要的意義。在關系抽取領域,大量學者進行了研究,以從非結構化的醫學文本數據中提取出有用的信息,并服務于下游子任務。醫學教材以及電子病例數據等均為非結構化的醫學文本數據,從這些文本中識別出醫學實體,并確定醫學實體之間關系的過程即為醫學領域的關系抽取。
基于深度學習的關系抽取方法在解決手動特征工程問題[2]方面取得了比較好的成果。基于深度學習的流水線實體關系抽取方法[3]主要是將命名實體識別和關系抽取作為兩個獨立的任務來完成。雖然這些方法能夠自動獲取文本特征,但它們無法有效解決錯誤傳播的問題。與之不同,基于深度學習的聯合抽取方法[4]的主要目的是同時實現句子中實體的識別和實體對關系之間關聯信息的抽取,這顯著提高了模型的性能。然而,現有的聯合實體關系抽取模型在訓練過程中存在語義理解能力不足的問題。針對上述問題,本文提出了一種融合MacBERT和Talking?Heads Attention的實體關系聯合抽取模型。該模型旨在提高對醫學文本的語義理解能力,從而更好地實現醫學領域的實體關系抽取。
本文貢獻如下:
1) 通過結合MacBERT的中文預訓練模型和BiGRU的長距離依賴捕獲能力,可以增強模型在復雜任務中的語義理解能力。
2) 通過引入Talking?Heads Attention,可以在保持較低計算復雜度的同時提高模型的準確性。
3) 將DuIE和CMeIE數據集應用于該模型得到了最好的結果。
1" 相關工作
關系抽取是指自動識別文本數據中實體并確定它們之間關系的任務。近年來,隨著關系抽取技術的快速發展,基于深度學習的流水線和聯合實體關系抽取方法在關系抽取方向得到廣泛的應用。
1.1" 流水線實體關系抽取方法
基于神經網絡的流水線實體關系抽取方法受到了廣泛關注。其中,文獻[5]提出了一種基于注意力機制的圖卷積網絡模型,該模型采用軟剪枝方法,能夠有選擇地自動學習對關系提取任務有用的相關子結構。文獻[6]融合了Bi?LSTM和CNN的特點,這種模型能夠更好地捕捉實體之間的關系信息,提高了關系抽取的準確性和效率。文獻[7]使用了兩個獨立的編碼器,一個用于實體識別,另一個用于關系抽取,使用相同的預訓練模型就達到了良好的性能。
1.2" 實體關系聯合抽取方法
為了解決流水線關系抽取帶來的誤差傳遞和特征共享等問題,基于深度學習的實體關系聯合抽取方法引起了越來越多研究者的關注。文獻[8]提出一種編碼器?解碼器體系結構實體關系聯合抽取方法(WDec)。文獻[9]設計兩種不同的編碼器在學習過程中獲取這兩種不同類型的信息。考慮到關系三元組重疊問題,文獻[10]提出一種基于多任務學習的模型(CopyMTL),具有新的實體復制體系結構。為了解決實體重疊問題,文獻[11]提出了一個新的級聯二進制標記框架(CasRel),該框架采用Span標記的方法,這種方法根據每個關系識別出相應的客體。然而,局部Span實體抽取方案缺乏魯棒性。文獻[12]提出了TPLinker關系抽取模型,該模型采用token對預測方案,通過執行兩個[O(n2)]矩陣操作來提取實體,導致了關系冗余判斷問題。文獻[13]提出基于表格填充的面向全局特征的新型關系三元組提取模型(GRTE),該方法認為現有的方法在填充關系表時僅僅依賴于局部特征,局部特征從單一的token pair或者從有限的token pairs的填充歷史中提取得到,然而卻忽略了兩種有價值的全局特征(Global Feature),即token pairs和各類關系的全局關聯關系。文獻[14]提出一種集合生成網絡(SPN4RE),該模型通過二位圖執行[O(n2)]矩陣操作匹配出最優三元組。文獻[15]提出基于依存圖卷積的實體關系抽取模型,該模型使用依存句法分析文本構圖,然后通過雙向GraphSage提取其結構特征,融入句法結構的特征向量在預測關系時有著更好的表現。
2" 模型算法架構
2.1" 編碼器模塊
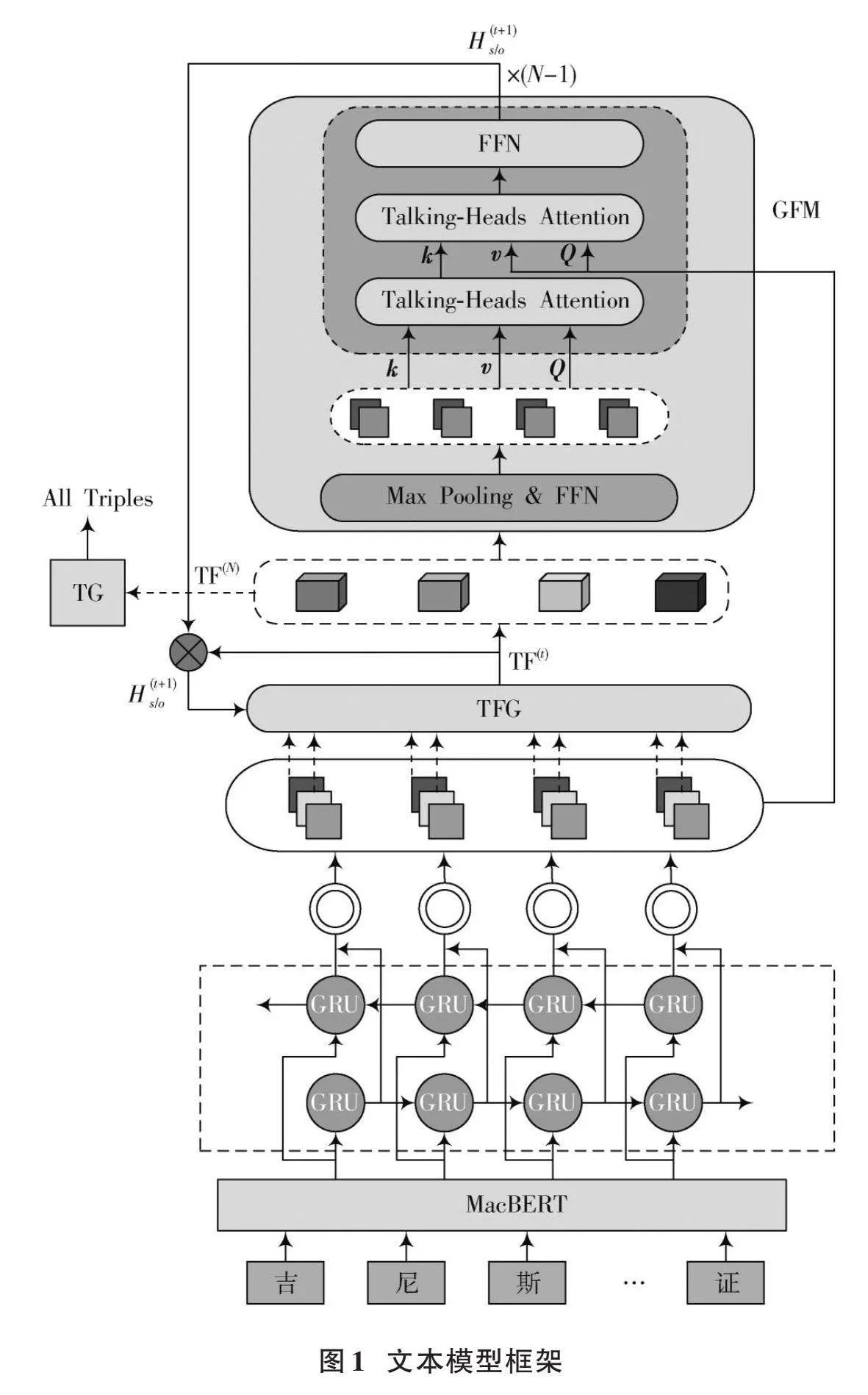
圖1展示了本文提出的模型框架,該框架由四部分組成:MacBERT編碼器層、BiGRU層、表格填充模塊和解碼層。其工作原理如下:
首先,利用MacBERT編碼器層將中文文本數據轉化為字符向量;然后,將MacBERT提取到的字符向量輸入到BiGRU層中進行特征提取;接著,利用解碼器對生成的字符向量進行解碼,生成相應的標簽序列。
本文中使用預訓練Chinese?MacBERT?Base(Cased)模型與BiGRU作為編碼器。首先編碼器將給定的句子編碼成一個字符特征序列[H]([H∈Rn×dh]),然后將[H]輸入到兩個分離的前饋網絡(FFN)中,生成初始的主體特征和客體特征(分別表示為[H1s和H1o]),其公式如下:
[H1s=W1H+b1]" (1)
[H1o=W2H+b2]" (2)
式中:[W1/2∈Rdh×dh]是可訓練的權重;[b1/2∈Rdh]是可訓練的偏差。
2.1.1" MacBERT層
為了提升實體關系抽取模型的準確性,本文將MacBERT引入到本模型中。MacBERT是一種基于Transformer的中文自然語言處理模型,是在RoBERTa基礎上進行修改得到的。MacBERT采用了一種改進的掩碼策略,使用相似的詞來進行掩碼,而不是使用[MASK]標記,使得模型能夠學習到豐富的詞匯和句子表示。將MacBERT引入本模型中,可以使模型在抽取實體關系時更好地理解句子中的語義信息,從而提高關系抽取的精確性。其次,MacBERT是在大規模無標簽文本數據上進行預訓練,學習到通用的語言表示,可以使模型在關系抽取任務上具備更強的泛化能力。
2.1.2" BiGRU層
為了改進RNN,引入LSTM并進行了修改。LSTM包含三個門控單元:輸入門、輸出門和遺忘門。GRU將輸入門和遺忘門合并成為更新門,以簡化計算。GRU通過引入“記憶元素”和“門元素”,保存長期序列信息。“記憶元素”長期保存信息,不隨時間流逝而消失;“門元素”包含更新門和重置門,處理輸入數據和更新重置。重置門決定新輸入與記憶元素的結合方式,更新門決定保存多少記憶元素到當前步長。其計算公式如下:
[zt=σ(Wzxt+Uzht-1+bz)] (3)
[rt=σ(Wrxt+Urht-1+br)] (4)
[ht=tanh(Wxt+rt?Uht-1)] (5)
[ht=zt?ht-1+(1-zt)?ht] (6)
GRU結構如圖2所示。因單向GRU傳輸特征向量只能向前單向傳播,易丟失重要特征,因此提出雙向GRU網絡結構,利用MacBERT層獲取的字向量輸入到雙向GRU中進行特征提取,可充分利用特征向量聯系上下文信息。
2.2" 表格填充模塊和解碼器模塊
該方法將為每個關系維護一個表,該表中的項通常表示擁有該特定關系的兩個實體的開始和結束位置。因此三元組關系抽取任務被轉換為準確有效地填充這些表的任務。首先,給出一個句子[S]=[w1,w2,…,wn],將為每個關系[r]([r∈R],[R]是關系集)維護一個表[tabler](大小為[n]×[n])。TFG模塊將第[t]次迭代時的主體特征和客體特征分別表示為[H(t)s]和[H(t)o]。然后將它們作為輸入,該模塊為每個關系生成一個表特征。關系[r]在第[t]次迭代時的表特征為[TF(t)r],它與[tabler]具有相同的大小,[TF(t)r]中的每個項表示實體對的標簽特征。具體地說,對于一對([wi],[wj]),把它的標簽特征表示為[TF(t)r(i,j)],用公式(7)計算:
[TF(t)r=WrGeLU(H(t)s,i°H(t)o,j)+br] (7)
式中:“[°]”表示哈達瑪積;GeLU是激活函數;[H(t)s,i]和[H(t)o,j]分別是第[t]次迭代時字符[wi]和[wj]的特征表示。GFM模塊挖掘期望的兩類全局特征,在此基礎上生成新的主體和客體特征,然后這兩個新生成的特征將反饋給TFG進行下一次迭代。具體來說,該模塊包括以下三個步驟:
步驟1:組合表特征。假設當前迭代是[t],首先將所有關系的表特征串聯在一起,生成一個統一表特征(表示為[TF(t)]),并且這個統一表特征將包含實體對和關系的信息;然后,在[TF(t)]上使用最大池化操作和FFN模型,分別生成主體相關表特征[TF(t)s]和客體相關表特征[TF(t)o]等,如式(8)、式(9)所示:
[TF(t)s=Wsmaxpool(TF(t))+bs] (8)
[TF(t)o=Womaxpool(TF(t))+bo] (9)
式中:[Ws/o∈R(|L|×|R|)×dh]是可訓練權重;[bs/o∈Rdh]是可訓練偏差。
步驟2:挖掘期望的兩類全局特征。首先,在[TF(t)s/o]上使用交談注意力方法來挖掘全局關聯關系;其次,采用交談注意力方法挖掘字符對的全局關聯。句子向量[H]也作為輸入的一部分,由于輸入句子是作為一個整體編碼的,因此[H]可能在一定程度上包含了字符的全局語義信息,從而有助于從整個句子的角度挖掘字符對之間的全局關聯;最后利用FFN模型生成新的主體和客體的特征。整個全局關聯挖掘過程可以用以下公式計算:
[TF(t)(s/o)=TalkingHeadAtt(TF(t)(s/o))] (10)
[H(t+1)(s/o)=TalkingHeadAtt(TF(t)(s/o),H,H)] (11)
[H(t+1)(s/o)=GeLU(H(t+1)(s/o)W+b)] " " "(12)
步驟3:進一步調整步驟2生成的主體和客體特征。如果深度迭代TFG和GFM模塊,本文的模型相當于一個非常深的網絡,因此可能出現梯度消失。為了避免這種情況,使用殘差網絡生成最終的主體和客體特征,如公式(13)所示:
[H(t+1)(s/o)=LayerNorm(H(t)(so)+H(t+1)(so))]" (13)
TG模塊以最后一次迭代時的表特征[TF(N)]為輸入,式(14)、式(15)解碼輸出所有三元組:
[tabler(i,j)=softmax(TF(N)r(i,j))] " " (14)
[tabler(i,j)=argmax?∈L(tabler(i,j)[?])] " (15)
損失函數為:
[L=i=1nj=1nr=1R-logp(yr,(i,j)=tabler(i,j))=i=1nj=1nr=1R-logtabler(i,j)[yr,(i,j)]] " (16)
式中[yr,(i,j)∈1,?]是([wi],[wj])關于關系[r]的真實標簽索引。
3" 實驗與結果分析
3.1" 數據集
為了測試本文提出模型的性能,選取了兩個公開的中文數據集。CMeIE是在CHIP2020中發布[16]的基于schema的中文醫學信息抽取數據集。在數據集中近7.5萬三元組數據,2.8萬條疾病語句并定義了53個關系,包括10個同義子關系和其他43個其他子關系。DuIE是中國第一個大規模、高質量的IE數據集[17],數據集中包括49種常用的關系類型,45萬個獨特的主語謂語對象(SPO)三元組和21萬條句子。
表1統計了2個數據集中的訓練集和測試集的數據。
3.2" 實驗設置
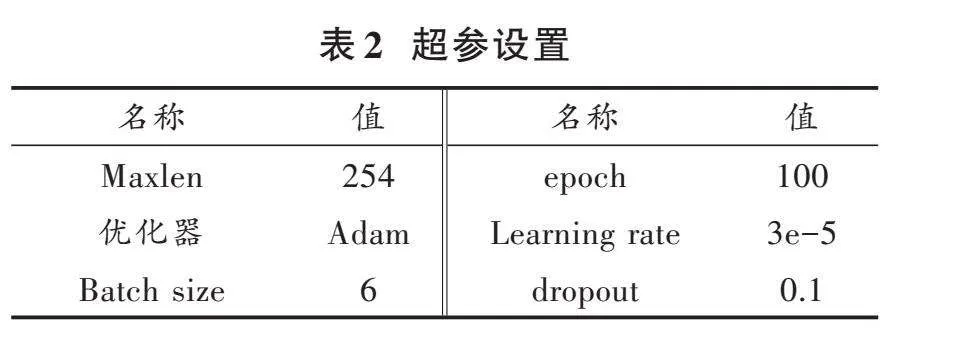
本實驗環境如下:使用Ubuntu 20.04操作系統,顯卡為RTX3090,顯卡大小為64 GB,Python版本為3.8.10,深度學習框架為PyTorch版本為1.7.0。具體超參設置如表2所示。
3.3" 結果分析
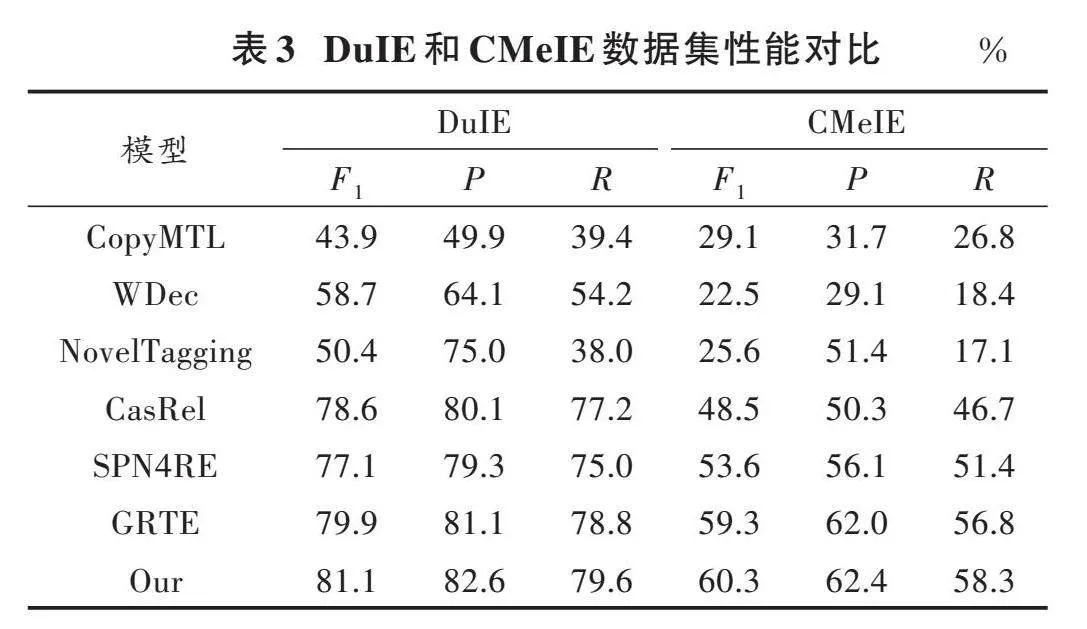
為了驗證本文提出的模型在抽取任務中的性能,將幾種模型與本文所提出的模型進行了對比,如表3所示。從表3的深度神經網絡對比結果可以看出,本文提出的方法取得了最好的結果。
通過觀察得出,本文提出的模型在所有的評估指標方面幾乎都較優于其他關系抽取模型。值得注意的是,本文模型在CMeIE數據集上[F1]值相比GRTE值取得了1.0%的提升。其原因在于:本文提出的新模型在模型編碼器模塊將MacBERT預訓練模型與BiGRU結構相結合,增強了模型的語義理解能力;其次引入Talking?Heads Attention模塊,這是一種輕量級的注意力機制,通過將注意力權重映射到一個低維空間來減少計算復雜度。這種方法可以在保持高性能的同時,降低計算成本和內存需求。
3.4" 模型消融實驗
為了分析本文提出的實體關系聯合抽取模型中各個模塊在模型中的貢獻,在CMeIE數據集上做了相關消融實驗。表4展示了消融實驗的性能指標結果。
BiGRU對模型性能的貢獻:BiGRU能更好地捕捉到文本句子中的長距離依賴關系,提高模型語義理解能力。移除BiGRU后,模型可能在處理復雜句子結構時表現較差。
Talking?Heads Attention對模型性能的貢獻:通過引入Talking?Heads Attention,可以在保持較低計算復雜度的同時提高模型的準確性。
4" 結" 論
本文為提高模型語義理解能力,提出一種融合MacBERT和Talking?Heads Attention的實體關系聯合抽取模型。MacBERT可以通過對中文文本進行編碼,得到更加準確和豐富的語義表示,BiGRU可以捕捉到文本中的上下文信息,并將這些信息應用于關系抽取任務中,兩者結合可以進一步提高模型性能。通過引入Talking?Heads Attention,可以在保持較低計算復雜度的同時提高模型的準確性。由于Talking?Heads Attention降低了計算復雜度,因此可以加速模型的訓練和推理過程,使其適用于大規模數據集和實時應用。然而,關系抽取任務中還存在一些挑戰和問題:數據集中存在噪聲和不一致性,這會對模型性能產生影響;數據集中存在長尾問題,即模型難以學習到數量較少的類別,如何處理長尾問題也是一個值得關注的問題。
注:本文通訊作者為王春亮。
參考文獻
[1] 付瑞,李劍宇,王笳輝,等.面向領域知識圖譜的實體關系聯合抽取[J].華東師范大學學報(自然科學版),2021(5):24?36.
[2] 張東東,彭敦陸.ENT?BERT:結合BERT和實體信息的實體關系分類模型[J].小型微型計算機系統,2020,41(12):2557?2562.
[3] 張仰森,劉帥康,劉洋,等.基于深度學習的實體關系聯合抽取研究綜述[J].電子學報,2023,51(4):1093?1116.
[4] YU B, ZHANG Z, SHU X, et al. Joint extraction of entities and relations based on a novel decomposition strategy [C]// European Conference on Artificial Intelligence. [S.l.: s.n.], 2020: 2282?2289.
[5] ZHANG Y, GUO Z, LU W. Attention guided graph convolutional networks for relation extraction [EB/OL]. [2020?09?06]. https://arxiv.org/abs/1906.07510v5.
[6] LI Z, YANG Z, SHEN C, et al. Integrating shortest dependency path and sentence sequence into a deep learning framework for relation extraction in clinical text [J]. BMC medical informatics and decision making, 2019, 19(1): 1?8.
[7] ZHONG Z, CHEN D. A frustratingly easy approach for entity and relation extraction [EB/OL]. [2021?03?23]. https://arxiv.org/abs/2010.12812.
[8] NAYAK T, NG H T. Effective modeling of encoder?decoder architecture for joint entity and relation extraction [J]. Proceedings of the AAAI conference on artificial intelligence, 2020, 34(5): 8528?8535.
[9] WANG J, LU W. Two are better than one: Joint entity and relation extraction with table?sequence encoders [EB/OL]. [2020?10?08]. https://arxiv.org/abs/2010.03851v1.
[10] ZENG D, ZHANG R H, LIU Q. Copymtl: Copy mechanism for joint extraction of entities and relations with multi?task learning [J]. Proceedings of the AAAI conference on artificial intelligence, 2020, 34(5): 9507?9514.
[11] WEI Z, SU J, WANG Y, et al. A novel cascade binary tagging framework for relational triple extraction [C]// Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: ACL, 2020: 1476?1488.
[12] WANG Y, YU B, ZHANG Y, et al. TPLinker: Single?stage joint extraction of entities and relations through token pair linking [C]// International Conference on Computational Linguistics. [S.l.]: International Committee on Computational Linguistics, 2020: 1572?1582.
[13] REN F, ZHANG L, YIN S, et al. A novel global feature?oriented relational triple extraction model based on table filling [EB/OL]. [2021?09?26]. edu/abs/2021arXiv210906705R/abstract.
[14] SUI D, CHEN Y, LIU K, et al. Joint entity and relation extraction with set prediction networks [EB/OL]. [2022?10?02]. https://arxiv.org/abs/2011.01675.
[15] 劉源,劉勝全,常超義,等.基于依存圖卷積的實體關系抽取模型[J].現代電子技術,2022,45(13):111?117.
[16] GUAN T, ZAN H, ZHOU X, et al. CMeIE: Construction and evaluation of Chinese medical information extraction dataset [C]// Natural Language Processing and Chinese Computing: 9th CCF International Conference. Heidelberg, Germany: Springer International Publishing, 2020: 270?282.
[17] LI S, HE W, SHI Y, et al. DuIE: A large?scale Chinese dataset for information extraction [C]// Natural Language Processing and Chinese Computing: 8th CCF International Conference. Heidelberg, Germany: Springer International Publishing, 2019: 791?800.
猜你喜歡
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
制造技術與機床(2019年10期)2019-10-26 02:48:08
當代陜西(2019年10期)2019-06-03 10:12:04
電子制作(2018年18期)2018-11-14 01:48:06
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
Coco薇(2016年2期)2016-03-22 02:42:52
小學教學參考(2015年20期)2016-01-15 08:44:38
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
語文知識(2014年1期)2014-02-28 21:59:13
