基于數據增強和CNN的小樣本圖像分類研究
2024-09-14 00:00:00黃志偉
電腦知識與技術 2024年23期



摘要:為解決卷積神經網絡在研究圖像分類問題時,由于訓練樣本過少而導致模型過擬合、測試準確率低的問題,本文整合了一套輕量級的數據增強方案,可以快速擴充圖像樣本。本文以Fashion-MNIST和CIFAR-10數據集為例,在只選取少量初始樣本的前提下進行數據擴充,采用TensorFlow深度學習框架和Keras搭建VGGNet-13和ResNet-18模型進行訓練和測試。結果表明,模型在測試集上表現出較好的準確率,有效應對小樣本學習帶來的過擬合問題,驗證了該數據增強方案的有效性。
關鍵詞: 數據增強; 卷積神經網絡; 小樣本學習; 圖像分類; 隨機填充
中圖分類號:TP18 文獻標識碼:A
文章編號:1009-3044(2024)23-0021-04
開放科學(資源服務)標識碼(OSID)
0 引言
Yann LeCun等人[1]在1998年提出了卷積神經網絡(Convolutional Neural Networks,CNN) ,該技術在識別手寫數字方面取得了顯著的成績。經過二十多年的發展,卷積神經網絡在許多領域都起著至關重要的作用,例如圖像分類[2]、語音識別[3]、目標檢測[4]、人臉識別[5]等。圖像分類是利用算法對已有的圖像進行特征學習,找出其所屬的類別。雖然卷積神經網絡在圖像分類問題上有著顯著的效果,但前提是需要收集大量的圖像樣本用于訓練,否則神經網絡將很難學到足夠的特征信息。然而,獲取充足且具有較好區分度、特征清晰的樣本通常比較困難。在只有少量樣本的情況下,如果直接使用卷積神經網絡對小樣本進行訓練,很容易出現過擬合現象,且模型不具備泛化能力。
小樣本學習[6]是在只有少量初始樣本的前提下,訓練出一個能解決實際問題的模型。針對小樣本困境,數據增強[7]是一種實用且非常有效的方法,它可以大量增加樣本的數量和特征。數據增強的具體實現策略較多,包括圖像的幾何變換、色彩變換、圖像拼接和模型生成等。而且,不同的策略有著不同的實現要求,任意的數據增強方法也不一定兼容。因此,本文以輕量化、低成本和兼容性為出發點,選擇不基于模型、只對單圖像進行變換的數據增強方法,即隨機裁剪[8]、隨機翻轉、隨機擦除[9]和隨機填充[10]4種方法對小樣本數據進行擴充。
本文分別從Fashion-MNIST和CIFAR-10數據集的訓練集中隨機抽取少量樣本,以構造小樣本困境,兩個數據集中的測試集用于驗證模型測試的準確率。接著將4種數據增強方法進行整合,按比例對小樣本進行數據擴充。最后選擇VGGNet-13[11]和ResNet-18[12]模型做圖像分類的訓練和測試,通過研究小樣本在有數據增強和無數據增強的兩種不同情況下,計算出卷積神經網絡在測試集上的準確率,驗證該方案的有效性。
1 實驗環境與數據集
1.1 實驗環境
本文在Windows 11系統下進行訓練和測試。實驗基于Anaconda 2022平臺,采用深度學習框架TensorFlow 2.10和Keras 2.10搭建神經網絡模型,運用Numpy庫和Matplotlib庫對數據進行數據預處理和數據可視化。
1.2 數據集
本文采用的數據集為Fashion-MNIST和CIFAR-10,這兩個數據集均可從Keras中下載。
1) Fashion-MNIST數據集。Fashion-MNIST數據集包含有10個類別、70 000張像素為28×28的灰度圖像。其中訓練數據集中每個類別含有6 000個樣本,測試數據集中每個類別含有1 000個樣本。數據集的類別分別是:T-shirt(T恤)、Trouser(牛仔褲)、Pullover(套衫)、Dress(裙子)、Coat(外套)、Sandal(涼鞋)、Shirt(襯衫)、Sneaker(運動鞋)、Bag(包)以及Ankle Boot(短靴)。訓練樣本實例如圖1所示。
2) CIFAR-10數據集。CIFAR-10數據集由60 000張分辨率為32×32的彩色圖像組成,包含50 000個訓練圖像和10 000個測試圖像。該數據集共有10個類別,分別為:Airplane(飛機)、Automobile(汽車)、Bird(鳥)、Cat(貓)、Deer(鹿)、Dog(狗)、Frog(青蛙)、Horse(馬)、Ship(船)以及Truck(卡車),每個類別包含6 000張圖像。訓練樣本實例如圖1所示。
1.3 小樣本數據
由于小樣本所指代的具體樣本數量沒有明確的定義,因此,本文分別對Fashion-MNIST和CIFAR-10數據集構造出3種不同的小樣本初始狀態。具體地,初始樣本數量分別設置為1 500、3 000和4 500個,其中,每一類樣本分別占150、300和450個樣本。這些樣本均是隨機從訓練集中抽取。這樣做的好處是在于,可以研究不同樣本數量的初始狀態與數據增強方案之間的聯系。
2 數據增強方法
2.1 隨機填充
隨機填充(Random Padding,RP) 的概念由Nan Yang等提出。他們認為,CNN通過學習圖像中不同位置的同一物體,可以提高模型的識別精度。這是因為特征空間信息會阻礙模型對特征關系的學習,而隨機填充的數據增強方法可以減弱模型對特征位置信息的學習。
RP是一種用于訓練CNN的新填充方法,它通過在圖像的一半邊界上隨機添加零填充來實現。這種操作隨機地改變特征位置的信息,可以有效削弱模型對位置信息的學習能力。該方法結構簡單,不需要參數學習,并且與其他CNN識別圖像的模型兼容。RP的實現過程非常簡單,它通過隨機地對特征圖相鄰的兩個邊界(左上、右上、左下和右下)進行零填充,填充一次則圖像的尺寸增加1。常見的填充厚度為n = 1、2、3,選擇填充厚度后RP會執行2n次填充操作。
令輸入圖像為I,其中T、B、L、R分別為圖像的上、下、左、右四個邊界,S表示圖像的四種相鄰邊界的組合,從中選擇一種記為Sn,輸出為隨機填充的圖像I′。RP的實現步驟如下:
INPUT: I
PROCESS:
T = B = L = R = 0
S = [[1,0,1,0],[1,0,0,1],[0,1,1,0],[0,1,0,1]]
FOR i = 1,2,..,2n DO
Sn = RANDOM_CHOICE(S,1)
T += Sn [0]
B += Sn [1]
L += Sn [2]
R += Sn [3]
END FOR
I′ = I([T , B , L , R])
OUTPUT: I′
2.1.1 圖像的RP
采用RP數據增強方法,對Fashion-MNIST和CIFAR-10數據集的初始樣本進行數據增廣,每個樣本進行4次RP操作,即每張原圖被擴充為4張。因此,初始樣本數變為N1 = 6 000、12 000、18 000。本文的隨機填充厚度統一設置為n = 3,而隨機填充操作會改變圖像的原有尺寸。因此,原圖像經過RP操作后,兩個數據集的樣本尺寸分別從28×28和32×32增加到34×34和38×38。原始樣本經過RP操作的實例如圖2所示。
2.2 隨機裁剪
隨機裁剪(Random Cropping,RC) 是一種簡易的單圖像數據增強方法。RC需要預先定義圖像的裁剪面積大小和裁剪次數,以及目標區域的裁剪概率。RC通過對原圖像進行多次操作得到許多不同的圖像,從而達到數據擴充的目的。經過裁剪后的圖像,其尺寸有可能不相同,這種情況可以根據任務需求,將圖像重新調整為與裁剪之前相同的尺寸。RC可以快速增加圖像的數量和多樣性,進而降低模型過擬合的風險。
2.2.1 圖像的RC+RP
本文運用RC對每張初始圖像進行2次裁剪,設定裁剪面積為原圖像的80%,并且將裁剪圖像重新調整為原圖的尺寸。最后,采用RP對2張裁剪圖像分別進行2次零填充。因此,經過RC+RP操作后,1張初始圖像擴充為4張,而初始樣本被增廣為N2 = 6 000、12 000、18 000。原圖經過RC+RP操作后的實例如圖3所示。
2.3 隨機翻轉
圖像翻轉包括:鏡像翻轉(左右翻轉)、垂直翻轉(上下翻轉)、鏡像加垂直翻轉(左右和上下同時翻轉),共3種翻轉方式。而隨機翻轉(Random Flipping,RF) 是從3種翻轉方法中隨機選擇,以增加圖像樣本數量,并提高圖像特征的多樣性。
2.3.1 圖像的RF+RP
本文從3種RF方式中隨機選擇2種對初始圖像進行操作,得到2張翻轉圖像,然后對每張翻轉圖像進行2次RP操作。因此,1張原圖增廣為4張。最終,初始樣本被增廣為N3 = 6 000、12 000、18 000。原圖經過RF+RP操作后的實例如圖4所示。
2.4 隨機擦除
隨機擦除(Random Erasing,RE) 是在圖像中隨機選擇一個矩形區域進行擦除,用0像素值代替擦除區域的像素值。這種技術可以對同一張圖像進行多次擦除操作,產生許多具有不同遮擋程度的圖像,從而達到數據擴充的目的。RE的優點在于其實現難度低,屬于輕量級的技術,并且不需要模型參數學習。此外,增加RE處理的圖像可以降低模型過擬合的風險,提高模型對遮擋圖像的魯棒性。
RE的實現過程并不復雜。首先,根據輸入圖像的寬度W和高度H,計算出圖像的面積A = W×H;然后,需要定義最小擦除面積比例sl和最大擦除面積比例sh,以避免出現無效擦除和過度擦除的情況。隨機從[sl,sh]之間取值,可得到初始化擦除面積Se。最后,定義擦除面積的最小長寬比re,則擦除面積的高為He = (Se×re)1/2,寬為We = (Se / re)1/2。根據這些參數設置,可以實現隨機選擇圖像的擦除面積和擦除位置。
2.4.1 圖像的RE+RP
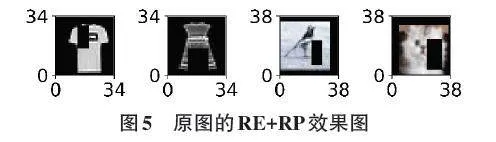
本文對初始樣本進行2次RE操作,然后使用RP對每張被擦除的圖像進行2次RP操作,使1張原圖擴充為4張。因此,初始樣本被增廣為N4 = 6 000、12 000、18 000。原始圖像經過RE+RP操作后的實例如圖5所示。
2.5 訓練集與測試集
Fashion-MNIST和CIFAR-10數據集的小樣本經過RP、RC+RP、RF+RP、RE+RP的操作之后,初始樣本數量從開始的1 500、3 000、4 500個,分別擴充為N1 + N2 + N3 + N4 = 24 000、48 000、72 000,即每張原始圖像按照1:16的比例進行了數據擴充。由于隨機填充改變了圖像的原始尺寸,兩個數據集的擴充樣本尺寸分別為34×34和38×38。這些經過一整套低成本數據增強方案得到的增強樣本,會根據不同的初始樣本情況,分別用于模型的訓練。
另外,為了證明數據增強方案的有效性,本文還研究了在沒有采用數據增強方案的情況下,直接將1 500、3 000、4 500個初始樣本用于模型訓練的情況。然而,Fashion-MNIST數據集的初始樣本尺寸只有28×28,這個圖像尺寸會導致VGGNet-13網絡無法完成卷積和池化過程。因此,在研究這一問題時,本文對Fashion-MNIST的1 500、3 000、4 500個初始樣本采用傳統的0填充方式,將圖像尺寸從28×28增大至34×34。
為了更好地驗證模型的泛化性能,本文將Fashion-MNIST和CIFAR-10數據集中的10 000個測試樣本用于模型測試,計算模型的準確率。由于兩個測試集的樣本尺寸分別為28×28和32×32,無法直接用于測試,這是因為訓練樣本的尺寸已經被改變。因此,本文將Fashion-MNIST和CIFAR-10數據集中的測試樣本全部進行傳統0填充,將圖像尺寸分別增大至34×34和38×38。
3 模型結構與實驗
3.1 卷積神經網絡
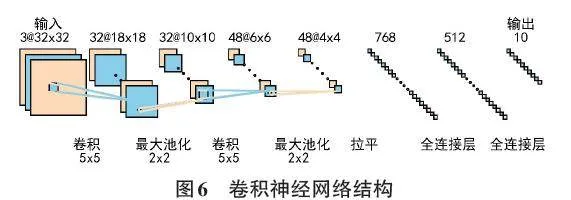
卷積神經網絡的結構包括輸入層、卷積層、池化層、全連接層和輸出層,如圖6所示。輸入是單通道的灰度圖像或三通道的彩色圖像。卷積是一種特殊的線性運算,根據設置的卷積核數量和大小對輸入圖像進行卷積操作,得到特征圖,再經過非線性激活函數運算,即為卷積層的輸出。卷積操作之后一般進行池化操作。池化層通過指定池化大小對卷積結果做進一步處理,這個步驟可以降低特征圖的維度,減少網絡參數。卷積和池化操作結束之后,需要將特征圖拉平成一維,成為全連接層的輸入。全連接層對特征向量進行計算,最終實現分類的目的。
VGG和ResNet模型是較為流行的卷積神經網絡,由于其結構的創新設計,在圖像分類方面取得了較好的成績。本文選擇了VGGNet-13和ResNet-18這兩個在各自系列中相對不太復雜的模型,它們的參數量相對較少。而且,通過對比兩種不同網絡結構的模型,可以檢驗本文整合的數據增強方案對不同模型的適應性。
3.2 模型超參數設置
本文對VGGNet-13和ResNet-18模型的原始超參數和網絡結構進行了調整。VGGNet-13模型的兩個全連接層部分,神經元數量由原始的4 096分別調整為512和128。ResNet-18模型的第一個卷積層,其卷積核大小由原來的7×7調整為3×3,步長(stride) 由原來的2調整為1,并刪除了3×3的最大池化(maxpool) 。
為了提高模型的泛化能力和收斂速度,VGGNet-13和ResNet-18模型都加入了Batch Normalization操作。批次大小設定為128,訓練輪數(epochs) 設定為15,并且加入了dropout以降低過擬合風險。模型的損失函數選擇SparseCategoricalCrossentropy,度量方式采用準確率。優化算法方面,VGGNet-13采用的是Adam,學習率為0.01;ResNet-18采用的是SGD,學習率為0.1。
3.3 實驗結果和分析
本文首先研究了Fashion-MNIST數據集。針對1 500、3 000、4 500個樣本的初始狀態,均采用同一套數據增強方案對小樣本進行數據擴充。將無數據增強的初始樣本和數據增強樣本分別用于VGGNet-13和ResNet-18模型的訓練。經過15次迭代后,在10 000個樣本的測試集上驗證模型的泛化性能。實驗結果如表1所示。
結果表明,直接使用1 500個初始樣本進行訓練,模型測試的準確率只有0.10。然而,采用經過數據增強方案得到的24 000個樣本進行訓練,模型測試的準確率最高可以達到0.87,兩者相差了0.77,遠高于沒有采用數據增強方案的模型。此外,使用3 000和4 500個初始樣本進行訓練,模型的測試準確率依舊偏低。使用48 000和72 000個數據增強樣本進行模型訓練,發現在測試集上的準確率最高可達0.90。
表1的結果證明,在Fashion-MNIST數據集的小樣本困境下,本文整合的數據增強方案不僅可以快速地增加樣本數量,而且還增加了樣本特征的多樣性。這些樣本可以有效地提高模型的泛化性能,降低過擬合風險,提高模型的魯棒性。表1還展示了VGGNet-13和ResNet-18兩個不同模型的研究結果,發現2個模型都具有較高的準確率。
為了進一步驗證本文的數據增強方案在其他數據集的小樣本問題上是否依然具有提升模型準確率的能力,本文還研究了CIFAR-10數據集。VGGNet-13和ResNet-18模型經過15次迭代,在測試集上的準確率如表2所示。
結果發現,直接使用1 500個初始樣本進行訓練,模型測試的準確率最高只有0.18。而采用經過數據增強方案得到的24 000個樣本進行訓練,模型測試的準確率最高可以達到0.52,兩者相差了0.34,同樣高于沒有采用數據增強方案的模型。使用72 000個數據增強樣本進行訓練,學得模型在測試集上的準確率最高為0.69。雖然0.69的準確率并不算高,但本文旨在研究數據增強方案的有效性。
表2的結果說明了CIFAR-10數據集的小樣本,經過本文整合的數據增強方案,依舊可以提升模型在測試集上的準確率。而隨著初始樣本數量的增加,模型的準確率顯著上升。要想進一步提升模型在測試集上的準確率,需要增加初始樣本數量,以及增加兼容的數據增強方法。
4 結論
本文將隨機填充、隨機裁剪、隨機翻轉、隨機擦除這4種數據增強方法融合為一套數據增強方案,并對其有效性進行了系列驗證。通過分析表1和表2的計算結果,發現該方案可以提高模型測試的準確率,即使變換數據集和神經網絡結構,模型的測試精度依然有較好的提升,證明了該方案的有效性。本文的研究可以為其他圖像分類的小樣本問題提供參考方案。
該方案尚有不足之處,如模型測試的準確率還有提升空間、可以增加其他兼容且互補的數據增強方法等。在未來的工作中,將對這些不足之處進行進一步研究。
參考文獻:
[1] LECUN Y,BOTTOU L,BENGIO Y,et al.Gradient-based learning applied to document recognition[J].Proceedings of the IEEE,1998,86(11):2278-2324.
[2] 張珂,馮曉晗,郭玉榮,等.圖像分類的深度卷積神經網絡模型綜述[J].中國圖象圖形學報,2021,26(10):2305-2325.
[3] ABDEL-HAMID O,MOHAMED A R,JIANG H,et al.Convolutional neural networks for speech recognition[J].IEEE/ACM Transactions on Audio,Speech,and Language Processing,2014,22(10):1533-1545.
[4] 盧宏濤,張秦川.深度卷積神經網絡在計算機視覺中的應用研究綜述[J].數據采集與處理,2016,31(1):1-17.
[5] 梁路宏,艾海舟,徐光祐,等.人臉檢測研究綜述[J].計算機學報,2002,25(5):449-458.
[6] 趙凱琳,靳小龍,王元卓.小樣本學習研究綜述[J].軟件學報,2021,32(2):349-369.
[7] 孫書魁,范菁,孫中強,等.基于深度學習的圖像數據增強研究綜述[J].計算機科學,2024,51(1):150-167.
[8] TAKAHASHI R,MATSUBARA T,UEHARA K.Data augmentation using random image cropping and patching for deep CNNs[J].IEEE Transactions on Circuits and Systems for Video Technology,2020,30(9):2917-2931.
[9] ZHONG Z,ZHENG L,KANG G L,et al.Random erasing data augmentation[J].Proceedings of the AAAI Conference on Artificial Intelligence,2020,34(7):13001-13008.
[10] YANG N,ZHONG L C,HUANG F,et al.Random padding data augmentation[M]//Communications in Computer and Information Science.Singapore:Springer Nature Singapore,2023:3-18.
[11] SIMONYAN K,ZISSERMAN A.Very deep convolutional networks for large-scale image recognition[EB/OL].2014:1409. 1556.https://arxiv.org/abs/1409.1556v6
[12] HE K M,ZHANG X Y,REN S Q,et al.Deep residual learning for image recognition[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).June 27-30,2016,Las Vegas,NV,USA.IEEE,2016:770-778.
【通聯編輯:唐一東】
