基于改進BiLSTM?CRF模型的網絡安全知識圖譜構建
2024-09-14 00:00:00黃智勇余雅寧林仁明黃鑫張鳳荔
現代電子技術 2024年6期








摘 "要: 針對網絡安全領域的圖譜構建任務,基于BiLSTM?CRF模型引入了外部網絡安全詞典來加強網絡安全文本的特征,并結合多頭注意力機制提取多層特征,最終在網絡安全數據集取得了更優異的結果。利用企業內部的日常網絡運維數據,設計并構建了一個面向企業網絡安全運維管理的知識圖譜,為后續進一步研究基于圖譜的企業網絡安全智能決策等應用奠定基礎。
關鍵詞: BiLSTM?CRF; 網絡安全; 知識圖譜; 特征提取; 企業網絡; 注意力機制; 本體建模; 知識抽取
中圖分類號: TN911?34; TP391 " " " " " " " " " 文獻標識碼: A " " " " " " " " " " "文章編號: 1004?373X(2024)06?0015?07
Knowledge graph construction for network security base on modified BiLSTM?CRF
HUANG Zhiyong1, 2, YU Yaning1, LIN Renming2, HUANG Xin1, ZHANG Fengli1
(1. School of Information and Software Engineering, University of Electronic Science and Technology, Chengdu 610054, China;
2. Data Application Center of Sichuan Provincial Market Supervision Administration, Chengdu 610066, China)
Abstract: On focus of the task of constructing graphs in the field of network security, an external network security dictionary is introduced based on the BiLSTM?CRF model to enhance the features of network security texts, and a multi head attention mechanism is combined to extract multi?layer features. Better results are achieved in the network security dataset. A knowledge graph for enterprise network security operation and maintenance management is designed and constructed by means of daily network operation and maintenance data within the enterprise, laying the foundation for further research on intelligent decision?making of enterprise network security based on graphs.
Keywords: BiLSTM?CRF; network security; knowledge graph; feature extraction; enterprise network; attention mechanism; ontology modeling; knowledge extraction
0 "引 "言
隨著互聯網技術的發展,企業的網絡資產比重逐漸增大。根據2022年中國互聯網發展報告[1]顯示,來自網絡空間的安全威脅愈發嚴重,經濟財產損失風險逐年攀升。前沿網絡安全防控智能化技術更注重于從全維度、多視角的方面來感知網絡空間威脅,而挖掘企業各類網絡攻擊的關聯性、策略、后果等要素能夠有效地提升企業對網絡安全運維管理的效率[2]。知識圖譜(Knowledge Graph, KG)通過在特定領域海量數據中抽取的知識構建領域知識圖譜,數據規模、特殊語義關系使其實用性變得更強[3]。
目前,企業內的網絡空間中所存在的威脅知識大部分沒有形成很好的知識組織,在面向企業的網絡安全運維的場景下,缺少能夠有效涵蓋網絡空間威脅信息、反映企業網絡安全態勢以及支撐輔助安全決策的知識圖譜;開源的漏洞信息庫和威脅信息庫等大多都是半結構化知識,而企業日常的網絡安全運維數據中又包含大量的結構化和非結構化的報告,這些異構數據難以被企業直接利用來進行網絡空間的防護。知識圖譜能夠有效地整合這些存在潛在聯系的網絡安全運維相關知識,將離散的多源異構數據通過基于深度學習的信息提取模型形成圖譜中的知識節點和知識的有機聯合,為企業的網絡安全運維管理工作提供支持。
針對網絡安全領域的圖譜構建任務,改進BiLSTM?CRF模型,提出一種基于BERT的網絡安全知識嵌入和多頭注意力機制的網絡安全實體抽取模型,并在開源網絡安全實體抽取任務,相較基線模型性能有所提升。本文提出一種面向企業網絡安全運維管理的知識圖譜構建方案,并構建了一個具有業務、設備、事件、威脅以及策略五類實體的網絡安全運維知識圖譜。
1 "相關工作
知識圖譜的構建包含從邏輯概念層面形成圖譜架構以及從數據層面形成圖譜的內容支撐[4]。本體建模則是在邏輯上構建出領域知識圖譜的框架,文獻[5]以抽象的概念并結合圖的點邊結構化方式表示網絡安全領域知識的本體,領域知識本體在邏輯層面對知識圖譜的數據進行有機管理。文獻[6]通過預先設計網絡安全知識本體,構建一個網絡空間知識圖譜。
信息抽取包括實體抽取和關系抽取。在實體抽取任務的研究領域,傳統的抽取方法分為基于規則、基于統計機器學習和基于深度學習三類方法[3]。前兩者通過大量的人工介入控制抽取,帶來了高準確率,但效率較低;而深度學習有良好的學習能力及向量表示和神經網絡所賦予的語義挖掘能力,在現階段應用廣泛。文獻[7]通過雙向的LSTM網絡考慮了文本上下位關系,結合一層CRF網絡解決了標簽預測順序錯誤的問題。文獻[8]設計實現了BERT模型,極大地提高了實體識別任務在開放域的提取性能。文獻[9?11]是BERT模型的優秀改良變體,優化了BERT存在的參數爆炸、實體邊界模糊等問題。文獻[12]采用自注意力機制訓練外嵌特征,證明了注意力機制在通過特征嵌入優化實體識別性能上的有效性。
2 "網絡安全知識圖譜構建
企業網絡安全運維領域的數據來源廣泛,傳統的網絡安全知識工程系統、專家構建的經驗知識庫等已結構化的數據可以直接支撐自頂向下的網絡安全運維知識圖譜構建。而在實際的日常網絡安全運維管理過程中,又會產生大量的運維數據、技術人員的實操日志等半/非結構化數據,也包含了非常豐富的網絡安全領域知識,可以通過信息抽取技術提取出其中的相關知識,并聚類歸納到相應的概念,輸入到網絡安全運維知識本體中,實現自底向上的圖譜構建。企業網絡安全運維知識圖譜的構建流程示意圖如圖1所示。
本文結合自頂向下和自底向上的兩種構建方式,將已有的結構化的企業內部拓撲數據、開源漏洞庫等數據直接通過映射的方式輸入圖譜中,并通過本文設計的實體抽取模型對企業網絡安全運維日志、網絡安全防護手冊等非結構化數據進行實體抽取,評估其抽取效果。再根據每份數據中存在的各類實體與本體進行上下位關系匹配,獲得實體間關系。最后將兩個過程的輸出相結合并存入圖數據庫中進行集中管理,實現對網絡安全運維知識圖譜的構建。
2.1 "本體建模
通過分析企業網絡安全運維數據以及領域內開源數據集成分特征,確定了包括企業業務網絡實體、企業網絡設備實體、網絡安全威脅實體等五種類型實體,以及包含(include)、發生(happened)、原因(reasonOf)、響應(responseOf)四種關系,如表1所示。這些實體和關系所形成的本體模型能夠反映出企業的網絡安全運維整體情況,能夠為知識圖譜的構建提供邏輯支撐。根據本體結構進一步定義其中的實體以及關系的屬性,補充相應的特異性數據,以區分同一類實體概念下的不同實體,如表2所示。
這些實體概念和關系的屬性進一步形成了對網絡安全離散數據的約束。在經過對現有的數據分析,完成頂層的知識本體建模后,還需要通過信息抽取算法對其他半/非結構化的網絡安全運維數據進行網絡安全運維知識抽取,自底向上地填充知識本體,構建完善的知識圖譜。
2.2 "知識抽取
知識抽取工作分為對結構化網絡安全運維數據與半/非結構化數據的抽取。結構化數據通過映射的方式直接將相應數據轉化為網絡安全運維實體及其關系存入圖數據庫中;對于非結構化數據,需要通過機器學習算法學習數據中網絡安全運維實體的特征,并通過本體匹配的方式賦予相應的關系。參考通用的實體抽取(NER)方法,將網絡安全運維實體抽取問題作為一個序列標注問題來解決。實體的開始詞匯標記為“B?Type(Begin)”,實體的內部詞匯標記為“I?Type(Inside)”,結束詞匯標記為“E?Type(End)”,非實體詞匯標記為“O?Type(Outside)”。基于BiLSTM?CRF模型,在數據驅動模式[13]的基礎上,結合網絡安全預訓練模型Cyber?BERT[14]進行先驗網絡安全知識嵌入,完成知識抽取。
2.2.1 "網絡安全運維實體抽取
考慮到CNVD和企業網絡安全運維日志與報告等待抽取數據中存在的大量跨語言現象,網絡安全領域數據中包含著大量的非標準英文縮寫以及復雜的中文長實體,基于BiLSTM?CRF模型,在數據驅動模式[13]的基礎上,結合網絡安全預訓練模型Cyber?BERT[14]進行先驗網絡安全知識嵌入,采用訓練詞向量和注意力機制來加強對復雜長實體的學習能力。得到的改進后BiLSTM?CRF模型結構如圖2所示,整個模型由輸入層、嵌入層、BiLSTM層、注意力層和CRF層五部分組成。其中:輸入層構建包含文本和文本特征的輸入序列;嵌入層通過BERT模型加載網絡安全預訓練詞嵌入向量來獲取文本的詞匯語義信息和詞典中的實體,一同訓練出實體編碼輸入模型;BiLSTM層執行全局特征提取,將其向量輸出到注意力層;注意力層對全局特征中的各個向量進行注意力計算,以提取局部特征,將包含全局特征、局部特征和領域字典特征的聯合特征向量序列輸入到CRF解碼層;CRF層命名實體識別模型,用于預測全局最優標記序列。
1) 輸入層
輸入層負責文本預處理,對于輸入的文本集合[Stt=1,2,…,n],生成BERT模型能夠接受的輸入序列[att=1,2,…,n],其中[at]包含三段輸入,[at=awordt,atagt,apost],即字符序列、標簽序列以及位置編碼序列。
2) 嵌入層
嵌入層包括單詞嵌入和領域詞典嵌入。單詞嵌入以文本中的句子為輸入,得到向量表示,是一種分布式的單詞表示方法,能夠從廣域數據中學習單詞的語義和語法信息。采用文獻[14]的Cyber?BERT模型作為文本編碼器,其利用大量網絡安全領域的語料進行預訓練,對網絡安全領域文本的特征更敏感。給定一組句子輸入序列[att=1,2,…,n],通過BERT模型預訓練的標記嵌入矩陣映射生成單詞向量,表示為[xtt=1,2,…,n],作為BiLSTM編碼層的輸入。
領域詞典特征嵌入參考LUKE[15]模型的思想,在訓練時將句子在領域詞典Dsec索引出網絡安全實體,一同加入到句子輸入尾部并標記,表示基于給定詞典的單詞標簽。再通過BERT模型提取,得到表示句子中網絡安全實體的詞級邊界特征。給定一個輸入序列[att=1,2,…,n]和一個外部域字典Dsec,基于BERT模型并通過LUKE的特征范式構造文本段序列[et=Ewordt,Etagt,Epostt=1,2,…,n]。其中,[Ewordt=w1,w2,…,wn,wn∈Dsec];[Etagt=entity,entity,…];[Epost=d1,d2,…,dn]。本文使用的特征范式如表3所示。
對于每個句子,將句子在詞典中匹配到的實體單獨加入到句子尾部,并計算相對位置編碼以及新標簽,表示為:[atet=awordtEwordt,atagtEtagt,apostEpost]。
最后將序列輸入到Cyber?BERT模型中獲得包含單詞嵌入[xtt=1,2,…,n]和句子網絡安全實體邊界信息的特征嵌入向量序列[gtt=1,2,…,n],用公式表示為:
[xt,gt=BERTCyberatet] (1)
3) BiLSTM層
LSTM解決了傳統遞歸循環神經網絡(RNN)結構訓練過程中梯度消失和梯度爆炸的問題。BiLSTM構造是雙向的LSTM,從正向和反向兩層LSTM網絡提取出輸入序列的隱層狀態[ht]和[ht]。對于輸入序列[att=1,2,…,n],進入嵌入層獲得嵌入序列[xtt=1,2,…,n],輸入到LSTM層后獲得包含上下位信息的特征向量[hxt],而字典特征嵌入序列[gtt=1,2,…,n]輸入到LSTM層后,獲得包含邊界信息的特征向量[hgt]。這兩組BiLSTM網絡相互獨立,不共享任何參數,因此可以公式化定義如下:
[hxt=BiLSTMhxt+1,hxt-1,xt] (2)
[hgt=BiLSTMhgt+1,hgt-1,gt] (3)
4) 注意力層
注意力機制是一種選擇機制,它有選擇地關注某些重要信息,忽略同時收到的其他信息。BiLSTM在文本處理中考慮了上下位信息,根據文本中信息的重要性為關鍵信息賦予更大的權重,而為其他信息賦予更小的權重。注意力分數計算公式如下:
[AttentionQ,K,V=softmaxQKTdK·V] (4)
式中:Q、K、V分別為Query、Key和Value三個向量矩陣;[dK]是縮放因子,具體為K的維度。
這里采用多頭注意力模型,在不共享參數的前提下,多頭注意力機制中的每一層通過參數矩陣映射V、K和Q,然后執行縮放點積注意力計算。根據多頭注意力的層數h,執行h次相同的操作。最后,拼接每一層的結果,獲得來自不同角度、不同維度的序列特征。計算公式如下:
[headi=AttentionQWQi,KWKi,VWVi] (5)
[MultiHeadQ,K,V=Concatheadi,…,headh] (6)
式中:[WQi]、[WKi∈RdK×dK]、[WVi∈RdV×dV];Concat(·)為拼接每一層注意力的函數。
5) CRF層
在CRF層通過輸入多組相同的特征向量[hxt],具體為注意力頭數,經過注意力層獲得注意力向量[st]。然后將[hxt]和[st]連接起來,得到結合上下位特征和自身特征的信息向量[ot]。具體公式如下:
[st=MultiHeadhxt,…] (7)
[ot=Concatst,hxt] (8)
將信息向量[ot]和包含領域字典特征以及邊界信息的特征向量[hgt]結合,得到最終的信息向量表示[pt],作為CRF層的輸入。
[pt=Concatot,hgt] (9)
在實際的標簽序列中,標簽本身有一定的約束規則,如句子開頭的單詞標簽只能是“O”或“B?type”,“I?type”必須跟在“B?type”后面,不能單獨出現。使用條件隨機場(CRF)模型對前一層生成的信息向量進行解碼,正確考慮標簽之間的隱性約束,獲得準確性更高的標簽預測序列。
給定一組輸入序列[p=(p1,p2,…,pn)],通過CRF層預測標簽的得分[y=(y1,y2,…,yn)]。最后,使用softmax函數歸一化所有可能的標簽選擇,獲得y的條件概率。計算公式如下:
[sp,y=i=0nZi,yi+i=0nTyi,yi+1] (10)
[pyp=expsp,yy∈Yexpsp,y] (11)
式中:p是由BiLSTM層和注意力層生成的信息向量矩陣;[Zi,yi]是句子中第i個單詞對應標簽[yi]的可能性分數;[Tyi,yi+1]代表從標簽狀態[yi]~[yi+1]的轉移概率;[y]是真實標簽值;y是所有可能標簽序列的集合。
最后通過標簽序列逆向解讀文本,將對應實體標簽下的文本段抽取出來,形成實體集合[C=(c1,c2,…,cn)],即可完成對企業網絡安全運維數據中的實體抽取。
2.2.2 "基于本體匹配的網絡安全關系生成
由于企業網絡安全數據本身具有較為明確的關聯性,通過流水線實體關系抽取模式,在對每一份網絡安全運維文本數據抽取出各類實體后,再基于本體匹配的方式對抽取出的各網絡安全實體進行關系匹配,生成相應的三元組[Ttt=1,2,…,n],形成網絡安全實體之間的關系鏈接。最后將三元組存入數據庫中,則可構建出網絡安全運維知識圖譜(KG)。整個過程可公式化為:
[Tt=Mapcm,cn=cm,r,cn]
[r∈include,happened,reasonOf,responseOf] (12)
[KG=T1,T2,…,Tn]
式中:[Map·]表示基于本體的上下位實體關系匹配函數;[r]為實體間的關系。
3 "實 "驗
3.1 "數據集
由于目前在網絡安全領域沒有統一的數據語料庫,所以使用開源的網絡安全語料來訓練和評估抽取模型的性能。該數據集[16]由基于機器學習算法從網絡安全領域提取的數據組成,從Freebuf網站和Wooyun漏洞數據庫收集數據并標注構建出中國網絡安全NER數據集,主要包括技術共享、網絡安全、漏洞信息等安全文本數據。這個數據集包括6種類型的安全實體,即技術人員(PER)、地理位置(LOC)、網絡安全組織(ORG)、軟件(SW)、相關術語(RT)和漏洞(VUL_ID)。完整的數據集包含478 000個句子,選擇其中80%作為訓練集,10%作為驗證集,其余10%作為測試集。
表4描述了數據集的大小,同時,額外添加了一些漏洞數據以平衡數據分布。
表5詳細說明了每個實體類別在不同數據集中的分布。
網絡安全詞典來自文獻[13]所構建的網絡安全實體詞典,包含7 892個實體,其中5 709個來自NVD和CVE數據集,1 263個來自網絡安全博客數據,920個來自維基百科,如表6所示。
3.2 "基線模型及實驗指標
在實驗中,使用精確度(P)、召回率(R)和F1值三個指標評估網絡安全NER模型。在本文中,BiLSTM?CRF作為基線模型,消融模型是BiLSTM?Att?CRF使用注意力機制;BERT?BiLSTM?Att?CRF模型添加了BERT編碼特征向量。本文模型是BERT(with dict)?BiLSTM?Att?CRF,進一步添加了實體嵌入功能,為模型提供了網絡安全實體的詞級特征邊界信息。
3.3 "模型設置
模型的標準是在BiLSTM層設置隱層大小為128,Batch Size為32,學習率為0.001,訓練40個Epoch。本文模型的特征BiLSTM大小設置為32,注意力頭為8。
3.4 "實驗分析
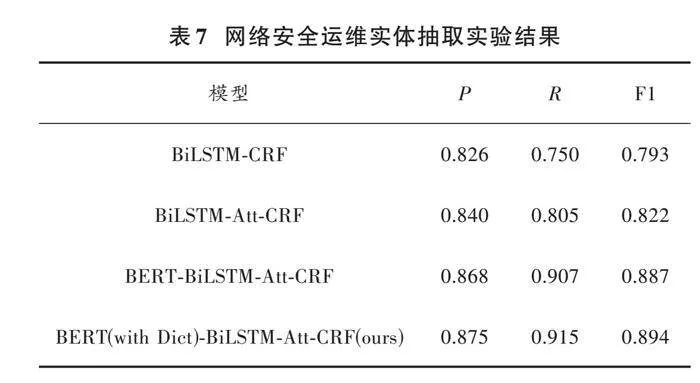
表7列出了這些模型的實驗結果。在基線模型中添加字典信息和注意力機制可以提高網絡安全運維數據NER的F1值。在標注模型中加入適當的外部知識或特征,有利于提高識別結果。使用多頭自注意力機制可以捕獲多個不同子空間中的上下位信息,提高不規則文本的實體識別性能。本文模型達到了最佳結果,準確率、召回率和F1值為87.5%、91.5%和89.4%,分別比基線模型高4.9%、16.5%、10.1%,在充分捕捉句子特征的基礎上添加外部信息,可以更好地幫助識別網絡安全實體。
從表8中可以看出,相比基線模型而言,本文模型對數據集中的6種標簽都有更好的性能。此外,模型在表示網絡軟件(SW)的抽取中表現不佳,分析可能的原因是模型對于夾雜英文以及命名方式不規則的軟件長實體存在邊界混淆。未來針對這種嵌入式的復雜實體采用雙重標注方法,使模型在訓練時能夠學習到嵌入式的復雜實體邊界規則,以期望獲得更好的實體抽取性能。
3.5 "圖譜構造結果
從來自于某企業的日常網絡安全運維管理所產生的10萬份運維日志中抽取出大量的網絡安全運維實體以及關系。將這些實體與關系數據輸入到Neo4j進行圖譜的可視化管理以及存儲。企業網絡安全運維知識圖譜構建結果如圖3所示。
圖3中包含了本體建模所構造的五類共100 648個企業網絡安全運維實體、四類共300 098個實體間關系的企業網絡安全運維知識圖譜,能夠有效地反映出企業在日常網絡安全運維的網絡態勢。相較于傳統的基于預先設定規則的監控系統,知識圖譜能夠展示更深層次的關聯情況,為管理人員在進行網絡安全運維管理時提供可靠的知識輔助。
4 "結 "語
本文通過加入基于BERT模型的網絡安全詞典特征嵌入模塊以及多頭注意力機制,改良了基線模型BiLSTM?CRF在對于網絡安全運維數據的實體抽取性能,并初步設計構建了一個面向企業網絡安全運維管理的知識圖譜。該成果可以進一步指導后續開展基于圖譜的網絡安全策略推薦系統或網絡安全攻擊分類識別系統等研究。本文模型在面對一些無特定語法的跨語言網絡安全實體的抽取上表現并不如意,未來期望針對這類實體特征進行研究,提出準確率更高的模型。
參考文獻
[1] 佚名.《中國互聯網發展報告(2022)》正式發布[J].新聞世界,2022(10):58.
[2] 丁兆云,劉凱,劉斌,等.網絡安全知識圖譜研究綜述[J].華中科技大學學報(自然科學版),2021,49(7):79?91.
[3] ABU?SALIH B. Domain?specific knowledge graphs: a survey [J]. Journal of network and computer applications, 2021, 185: 103076.
[4] JI S, PAN S, CAMBRIA E, et al. A survey on knowledge graphs: representation, acquisition, and applications [J]. IEEE transactions on neural networks and learning systems, 2021, 33(2): 494?514.
[5] RAZZAQ A,ANWAR Z,AHMAD H F,et al.Ontology for attack detection: an intelligent approach to web application security [J]. Computers amp; security, 2014, 45(S1): 124?146.
[6] ZHU X, HUANG J, ZHOU B, et al. Real?time personalized twitter search based on semantic expansion and quality model [J]. Neurocomputing, 2017, 254(6): 13?21.
[7] HUANG Z N, XU W, YU K. Bidirectional LSTM?CRF models for sequence tagging [J]. Computer science, 2015(1): 01991.
[8] DEVLIN J, CHANG M W, LEE K, et al. Bert: pre?training of deep bidirectional transformers for language understanding [EB/OL]. [2022?04?17]. https://arxiv.org/pdf/1810.04805.
[9] LAN Z, CHEN M, GOODMAN S, et al. Albert: a lite BERT for self?supervised learning of language representations [EB/OL]. [2022?11?04]. https://arxiv.org/abs/1909.11942.
[10] LI X, YAN H, QIU X, et al. FLAT: Chinese NER using flat?lattice transformer [EB/OL]. [2022?07?08]. http://arxiv.org/abs/2004.11795.
[11] LIU W, ZHOU P, ZHAO Z, et al. K?bert: Enabling language representation with knowledge graph [J]. Proceedings of the AAAI conference on artificial intelligence, 2020, 34(3): 2901?2908.
[12] AN Y, XIA X, CHEN X, et al. Chinese clinical named entity recognition via multi?head self?attention based BiLSTM?CRF [J]. Artificial intelligence in medicine, 2022, 127: 102282.
[13] GAO C, ZHANG X, LIU H. Data and knowledge?driven named entity recognition for cyber security [J]. Cybersecurity, 2021, 4(1): 1?13.
[14] AMERI K, HEMPEL M, SHARIF H, et al. CyBERT: cyber?security claim classification by fine?tuning the bert language model [J]. Journal of cybersecurity and privacy, 2021, 1(4): 615?637.
[15] YAMADA I, ASAI A, SHINDO H, et al. Luke: deep context?ualized entity representations with entity?aware self?attention [EB/OL]. [2022?01?11]. https://arxiv.org/abs/2010.01057v1.
[16] QIN Y, SHEN G, ZHAO W, et al. A network security entity recognition method based on feature template and CNN?BiLSTM?CRF [J]. Frontiers of information technology amp; electronic engineering, 2019, 20(6): 872?884.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
中國生殖健康(2019年10期)2019-01-07 01:21:04
信息安全研究(2018年12期)2018-12-29 11:01:46
小學生必讀(中年級版)(2018年4期)2018-07-05 06:00:48
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
