增強問句和文本交互的答案抽取方法
2024-09-14 00:00:00鄧涵
現代電子技術 2024年6期
關鍵詞:深度學習





摘 "要: 答案抽取對提高問答的質量和性能有著重要的作用,但現有的答案抽取方法存在問句和文本信息交互的問題。結合上下文的答案抽取模型雖然可以從文本中抽取出給定問題的答案,但這種抽取方法并未考慮文本和問句的信息交互。而只有問句和文本數據時,要從文本中獲取更加精準的問句答案,可以利用問句和文本之間的語義信息,預測問句與文本實體之間的關聯。基于此,使用問句對齊層和多頭注意力機制構建一個交互文本和問句之間的信息模型。實驗結果表明,相較于BIDAF?INDEPENDENT模型,改進后模型的EM值和F1值分別提高了1.281%和1.296%。
關鍵詞: 答案抽取; 問答系統(tǒng); 信息交互; 語義信息; 深度學習; 多頭注意力機制
中圖分類號: TN919.6+5?34; TP391 " " " " " " " " " 文獻標識碼: A " " " " " " " " 文章編號: 1004?373X(2024)06?0179?08
Method of answer extraction for enhancing question and text interaction
DENG Han
(Faculty of Information Engineering and Automation, Kunming University of Science and Technology, Kunming 650500, China)
Abstract: The question answering quality and performance are significantly enhanced by means of the answer extraction. The existing answer extraction methods suffer from the problem of interaction between questions and text information. The answer extraction model that combines context can extract the answer to a given question from the text, but this extraction method does not consider the information interaction between the text and the question. When there is only question and text data, to obtain more accurate question answers from the text, the semantic information between the question and the text can be used to predict the association between the question and the text entity. When there is only question and text data, the semantic information between the question and the text can be used to predict the association between the question and the text entity, so as to to obtain more accurate question answers from the text. On this basis, a question alignment layer and multi head attention mechanism are used to construct an information model between interactive text and questions. The experimental results show that, in comparison with the BIDAF INDEPENDENT model, the improved model has an increase of 1.281% in EM value and 1.296% in F1 value, respectively.
Keywords: answer extraction; Qamp;A system; information exchange; semantic information; deep learning; multi head attention mechanism
0 "引 "言
MRC(機器閱讀理解)作為自動化學習的重要組成部分,其主要任務就是幫助計算機深入了解并準確地應對特定的文本內容,從而達到預期的學習效果。這個任務通常包括兩個關鍵方面:文本理解和問題回答。MRC的核心目標是通過分析給定的上下文提取出有效的信息,以便更好地解決問題。
為此,目前已經有多個國際公開的數據集[1]可供使用,如SQuAD、MS?MARCO[2]、NewsQA[3]、TriviaQA[4]等。2016年,斯坦福大學的研究人員Rajpurkar發(fā)布了一個名為SQuAD的問答數據集[5],它不僅提供了一些具有挑戰(zhàn)性的問題,而且還提供了一系列可以從給定文本中獲得正確答案的令牌序列。
閱讀理解任務不僅要求計算機能夠提取關鍵信息、理解句子和段落的含義,還需要理解問題的意思并準確回答問題。因此,閱讀理解任務可以有不同的形式,例如抽取式問答和生成式問答。抽取式問答要求計算機從給定文本中選擇合適的答案,而生成式問答則要求計算機基于理解的內容生成自己的答案。
在大多數基準數據集中,問題可以被看作多項選擇問題,其正確答案將從一組提供的候選答案中選擇,這屬于抽取式問答。根據現有大量實驗推測,具有更多給定候選答案的問題更具有挑戰(zhàn)性。SQuAD數據集自提出以來就引起了學術界的極大關注,使得閱讀理解任務成為問答技術研究的熱門,它也成為了抽取式問答技術核心的基準數據集,并推動了一大批抽取式閱讀理解模型的研究。隨后,若干大規(guī)模問答數據集被相繼提出,如MS?MARCO、NewsQA以及TriviaQA等,以擴充閱讀理解的任務形式,也不斷催生新的問答模型的產生。此外,與其他一些以完形填空形式去自動創(chuàng)建問題和答案的數據集不同,SQuAD中的問題和答案是由人類通過云檢索創(chuàng)建的,這使得數據集更加真實。鑒于SQuAD數據集的這些優(yōu)勢,在本文中專注于這個新的數據集來研究文本機器理解中的答案抽取任務。
神經閱讀理解技術是一種利用深度神經網絡來處理復雜的語言現象的技術,它可以有效地提升閱讀理解的準確性和效率[6],而且這種技術的優(yōu)勢遠遠超過了傳統(tǒng)的人工設計的模型,它可以幫助人們更好地理解和處理復雜的語言現象。
開放域問答系統(tǒng)中,答案抽取是一項非常重要的任務,它旨在從給定的文本中提取出準確的答案,并且能夠根據文本內容創(chuàng)建出更加復雜的答案。一般來說,系統(tǒng)會先以一段文本形式呈現,比如新聞、故事等,然后期待機器回答與文本相關的一個或多個問題。
通過對以上背景和方法的研究與分析,本文將增強問句和文本信息用于深度學習網絡,提出一種節(jié)省內存、訓練更快的增強問句和文本交互的答案抽取方法(Answer Extraction Method for Enhancing Question and Text Interaction, AEMEQA)。AEMEQA是一種基于多種神經網絡的深度學習技術,它可以幫助機器學習者更好地理解和處理復雜的信息,其中包括雙向長短期記憶網絡(BiLSTM)、多頭注意力網絡和GloVe預訓練模型,它們可以幫助機器更加準確、高效地完成任務。AEMEQA將多種獨立的學習環(huán)節(jié),如編碼、特征提取、文本?問題交互以及答案抽取等整合到一個統(tǒng)一的深度學習框架中,從而構建出一種全新且可以被廣泛應用的閱讀理解網絡。
1 "相關概念
1.1 機器閱讀理解
機器閱讀理解的核心任務包括:完成多項選擇題,提取關鍵信息并進行自主回答,其中完形填空測試通過從段落中刪除一些單詞或實體來生成問題。完形填空測試是一項極具挑戰(zhàn)性的任務,因為它要求機器人填寫空白部分,并且需要理解上下文和詞匯用法。這種測試不僅會增加閱讀難度,還會讓機器人面臨更大的挑戰(zhàn)。完形填空測試的最顯著特征是答案來自于上下文段落中的單詞或實體,此任務可以視為單詞或實體的預測。多項選擇是一種更加靈活的考試方式,它不僅要求考生根據上下文段落中的單詞或實體來選擇正確的答案,而且還要求考生能夠根據自己的理解和判斷,從多個可能的答案中挑選出最合適的[7]。
雖然完形填寫和多項式挑戰(zhàn)考驗了人類在處理自然語言方面的表現,但它們仍存在一定的局限。例如,在一些特定的場景中,如果一個單詞無法準確地表達意思,而且在許多情境下也無法找到合適的替代方案,就必須使用一個完整的句子。而通過進行跨域抽樣,能夠有效地解決這些問題,這個過程需要根據特定的背景知識來抽樣一段文字,并將其用于回答特定的問題。
跨度提取任務的出現大大改善了機器學習解決問題的能力,它不僅可以提供更加靈活的答案,而且可以從多個上下文中獲取有效的數據,從而使機器能夠更加準確地回答問題。在這4個任務中,自由回答是最具挑戰(zhàn)性的,它的表達方式不受任何限制,而且更加符合實際的應用需求。圖1所示為跨度提取任務的SQuAD數據集示例。
總而言之,完形填寫題目可以輕松地創(chuàng)建一組數據,以便對其進行評估。然而,由于題目的表達方式只局限于一些特定的字母和字母組合,因此,它們難以準確地反映出人類的閱讀和寫作技巧,也難以滿足日常的使用需求。多項選擇是檢驗學生能力的一種有效方法,無論在解決什么樣的問題時,都能夠通過多種方式獲得有價值的信息。這種方法的優(yōu)勢在于能夠快速地收集和分析大量的信息,從而更好地判斷學生的能力。但該方法的候選答案導致合成數據集和實際應用之間存在差距。自由回答任務在理解、靈活性和應用范圍方面很有優(yōu)勢,這是最接近實際應用的,但是其回答形式靈活,很難構建數據集,因而如何有效評估這些任務的性能仍然是一項挑戰(zhàn)。相比之下,跨度提取任務是一個適度的選擇,其數據集易于構建和評估,并且接近實際應用[6]。
1.2 注意力機制
引入注意力機制(Attention Mechanism)可以充分利用計算資源,從而克服信息超載的困境[8],提升神經網絡的性能。此外,隨著模型的參數增加,其可以提供的表示效果和可用的信息量也有所增加,從而減少了信息的負擔。采用注意力分配技術將大量的外部資源集中到當前任務的核心部分,減少對外部資源的依賴,可以有效地抑制外部資源的干擾,從而有助于緩解資源的緊張狀態(tài),進而極大地提高任務的完成速度與精確度。這種方法的應用就像人類的眼睛一樣,能夠觀察整個畫面,找到想要的焦點,然后集中精力去捕捉它,并且不會放棄任何一個不相干的部分,在有限的時間內,迅速地提煉出最具價值的內容。
注意力機制并不是一種特定的神經網絡結構,而是一種通用的機制,可以應用于不同的神經網絡結構中。比如,可以在卷積神經網絡中使用注意力機制來關注輸入圖像中的重要區(qū)域,也可以在循環(huán)神經網絡中使用注意力機制來關注輸入序列中的重要部分。一般來說,注意力機制可分為自我調節(jié)(Self?Attention)、多頭調節(jié)(Multi?head Attention)等多種形式,它們的基本原理可歸納為三個步驟:
1) 計算每個輸入位置的注意力權重。這個權重可以根據輸入數據的不同部分進行加權,即對不同部分賦予不同的權重。權重的計算通常是基于輸入數據和模型參數的函數,可以使用不同的方式進行計算,比如點積注意力、加性注意力、自注意力等。
2) 將每個輸入位置的權重與其他輸入位置的權重相乘,從而得到一個加權的輸入表示,它能夠更準確地反映出輸入數據中的關鍵信息,從而提高模型的準確性和可靠性。
3) 根據加權的輸入表示和其他模型參數計算輸出結果,這個輸出結果可以作為下一層的輸入,也可以作為最終的輸出。
2 "相關工作
2.1 "神經閱讀理解
近年來,機器讀寫理解能力的研究取得了巨大的進展,這得益于兩個重要的推動力:一是大量的讀寫理解能力數據的收集;二是基于端口的機器學習技能的深入理解模式的開發(fā)。這些技術的開發(fā)可以使機器學習的效果得到顯著改善,同時,機器學習技術的改善更有利于應對機器學習所面臨的挑戰(zhàn)和難度。
當前,許多神經網絡信息技術如循環(huán)神經網絡(Recurrent Neural Network, RNN)[9]、卷積神經網絡(Convolutional Neural Network, CNN)[10]和注意力機制技術,已經被廣泛應用于神經閱讀和理解領域,并取得了顯著的進展。在編碼領域,GPT和BERT使用Transformer架構,而其余的模擬則使用LSTM、GRU(Gated Recurrent Unit networks)、 CNN等信息技術[11]。編碼層主要是采用雙向長短期記憶網絡方法和雙向門控循環(huán)單元,并且采取較多的技術手段來改善模型的可識別性;而在交互層,學術界正致力于探索一種更為靈活的方法,既可以利用傳統(tǒng)的注意力機制,也可以利用新的自適應技術,以改善模型的表現。
BiDAF模型是一種重要的神經閱讀理解模型[12],它通過總結前人的研究成果,提出了雙向注意力機制這一概念。這一概念首次將雙向注意力機制納入BiDAF模型,以表征上下文中哪些單詞與問題中的單詞有最大的相關性。BiDAF模型具有靈活的輸出層編碼能力,能夠有效地處理各種復雜的數據集。
文獻[13]將Maxout網絡[14]及Highway網絡[15]的特性有機地融入到BiDAF的研究中,并以HMN(Highway Maxout Network)為核心,構建出具有高度靈活性的DCN模型。Chen和其他研究者提出的DrQA模型旨在支持開放式的閱讀理解[16],它首先使用Document Retriever 搜尋與問題有關的文本,接著使用Document Reader查詢文本,并以Wikipedia為基礎,最終將結果輸入SQuAD1.1的數據庫,以實現有效的學習。DrQA在這方面取得了巨大的進步,它首次將命名實體識別和其他特征融合在一起,取得了巨大的成就。
D. Weissenborn等學者指出,當前的神經網絡閱讀理解技術存在著較大的復雜性,其中包括兩個主要部分:一個用來構建文本序列的模型,另一個則用來處理段落與相關的問題[17]。因此,他們提出了輕量級的模型FastQA。FastQA利用RNN編碼技術將復雜的段落與簡單的問題結合起來,并利用定向搜索(beam?search)技術提取出有效的答案。
R?Net模型被認為是神經閱讀理解領域的里程碑[18],它首次將自我調節(jié)的概念引入到模型的第2個交互層,以便更好地識別和處理包含相關知識的句子,并且能夠更好地預測句子的長度和復雜度。R?Net的出色表現,自我調節(jié)能力變得更加重要,因此,它已被廣泛應用于各種神經網絡學習和認知領域,并且被認定是未來發(fā)展中的必備技術。
2.2 "多頭注意力機制
多頭注意力(Multi?Head Attention)是注意力機制的一種擴展形式,可以在處理序列數據時更有效地提取信息,結構如圖2所示。
在標準的注意力機制中,計算一個加權的上下文向量來表示輸入序列的信息。而在多頭注意力中,使用多組注意力權重,每組權重可以學習到不同的語義信息,并且每組權重都會產生一個上下文向量。最后,這些上下文向量會被拼接起來,再通過一個線性變換得到最終的輸出[8],公式為:
[headi=AttentionQWQi,KWKi,VWVi] "(1)
根據圖2可以看出,在進行線性變換時,需要進行h次,即多頭。在Query、Key、Value等關系中,頭與頭的參數獨立,而且在進行線性變換時,頭與頭的參數W會有差異。通過h次的放大和減小,可以構建出一個具有多個輸入的集合,并通過線性變換來獲取它們的最終形式。這種方法可以讓本文模型從各種不同的輸入中獲取有用的信息,具體公式如下:
[MultiHeadQ,K,V=Concathead1,head2,…,headhWO] (2)
3 "深度學習實驗模型
3.1 深度學習框架
利用深度學習技術建立一種新的機器學習和認知框架。根據圖3機器閱讀理解系統(tǒng)的基礎構架,一個典型的機器學習系統(tǒng)由4個部分組成:嵌入、特征提取、上下文?交互以及預測。它能夠根據上下文和問題的信息,自動生成有效的答案。
由于機器無法直接學習和認知自然語言,故MRC系統(tǒng)最初由嵌入模塊將輸入單詞更改為固定長度的向量是必不可少的。該模塊以上下文和問題為輸入,通過各種方法輸出上下文嵌入和問題嵌入。通常使用的經典單詞表示方法one?hot或word2vec有時將其與其他語言功能結合使用,如詞性標注、命名實體識別和問題類別等,以表示單詞中的語義和句法信息。此外,由大型語料庫預訓練的上下文化詞表示法在編碼上下文信息方面也顯示出優(yōu)異的性能。
通過將相關的數據嵌入到神經網絡模塊,可以獲得有關上下文的詳細信息。這可以通過循環(huán)神經網絡(RNN)或者卷積神經網絡(CNN)來實現,它們可以有效地收集并分析這些數據,以便對這些數據有所洞察。
MRC系統(tǒng)通過利用單向或雙向注意力機制,可以有效地檢測出上下文?問題交互模塊中的相關性,從而更準確地預測出最終的答案。這種方法可以幫助機器更好地理解問題,并且更快地找到最有效的解決方案。為了更好地探索上下文與問題之間的聯系,可能會進行多次跳轉,以模擬人類的思維過程,從而更深入地理解它們。
MRC系統(tǒng)的最后一個功能是答案預測,其能夠將所有已經收集的數據按照特定的方法和結果有效地劃分成多個子任務[6],并且能夠快速準確地提供給用戶。例如,在完形填寫題目中,這個模塊能夠快速提供準確的結果,使用戶能夠更加輕松地獲得所需的知識。這個模塊專門針對特殊情況,它可以從特殊的上下文中抽取信息,并使用Wang等人提出的邊界模型[19]來估算問題的起點和終點;它還可以使用一些特殊的算法來解決這些問題,且這些算法可以根據特殊情況進行調整。
大多數基于端到端神經網絡的機器學習模型都采用4層架構[20],如圖4所示。
圖4中,嵌入層包括字符、詞、上下文以及特征級別,它們分別代表C維的詞匯和d維的問題;另一些模型則利用注意力機制,將問題的詞匯信息融入上下文段落[21],以便更好地理解上下文內容。接著,模型會將預先嵌入的上下文和問句輸入到編碼層,并利用循環(huán)或卷積神經網絡來提取其中的內在特征,最終通過注意力機制生成能夠反映上下文段落的表達或者能夠反映出上下文段落的問題表達[12]。本文使用一種新的模型來處理問題和上下文的關系。這種模型使用自注意力機制來捕捉這些關系中的信息,并將它們融合到一起;再使用循環(huán)或卷積神經網絡來解碼這些關系,并生成一個最終的表示。根據最終任務的類型,輸出層將會有不同的表示方式。
3.2 "實驗模型結構
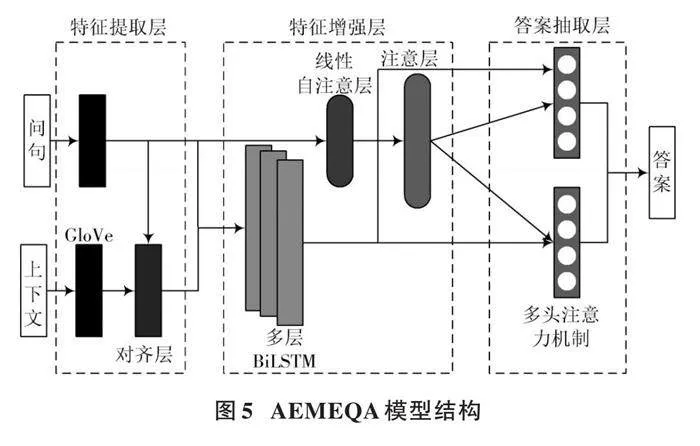
鑒于深度學習強大的泛化能力和特征提取能力,AEMEQA模型主要由特征提取層、特征增強層、答案抽取層三部分組成,其結構如圖5所示。
首先,需要為給定的上下文和問題創(chuàng)建一個虛擬詞典,通過訪問訓練集和測試集來獲取已知的答案,并將它們作為標簽;然后,在數據集中創(chuàng)建一個詞匯表,并將這些文本和問題逐一輸入到模型中,模型對預處理后的上下文和問句進行特征提取,將答案抽取任務視為輸入的文本和問句的一個匹配任務,抽取出文本的語義信息和問句的語義信息,比較兩者的相關性,將融合問句信息后的文本信息和問句作為輸入特征,調節(jié)網絡參數;最后,模型進行答案抽取。在上述訓練完成后,將數據輸入深度學習網絡,深度學習網絡進行計算處理后輸出預測答案的開始和結束位置,并與預訓練得到的答案位置標簽進行比較,判斷答案抽取結果是否正確。
3.2.1 "預處理
對數據集的文本和問句中離群值進行檢索并刪除,對文本中的單詞建立詞匯表,將用于訓練集和驗證集的文本和問句數字化;再檢索刪除字符級錯誤以及由于空格等原因出現的錯誤數據;最后從文本中得到答案的開始和結束位置,作為訓練問答系統(tǒng)模型的基本標簽。輸入訓練的數據包含已經處理成令牌級別的文本和令牌級別的問句,以及從文本段落本身所得到答案的起始位置和結束位置。問句數據示例如圖6所示。
3.2.2 "特征提取
預處理之后的問句和文本通過使用預訓練的GloVe模型詞向量初始化的嵌入層傳遞,其中GloVe模型是840 B網絡爬蟲版本的300維向量版本,有220萬個單詞的詞匯量。針對存在于數據集中但是不存在于GloVe預訓練模型詞匯中的單詞,即詞匯表外單詞,由零向量進行初始化。這些詞向量用于將單詞投影轉換為浮點向量,該浮點向量將與詞相關的各種特征編碼為其維度。這種轉換是十分必要的,因為計算機不能直接將單詞作為字符串處理,但可以無縫地處理大量的浮點矩陣。通過這樣的轉換,語義相似的單詞向量之間的點積接近于1,反之,越不相似的單詞向量之間的點積接近于0。
本文針對上下文文本和問句有不同的編碼程序,文本的編碼更加詳細徹底。上下文文本問句對齊層包括以下額外的特征:
1) 精確匹配(Exact Match, EM),指的是如果可以完全匹配到一個原始、引理或者小寫形式的相關單詞,對其進行二進制特征處理和編碼,得到一個準備匹配的結果。
2) 令牌特征,包括文本段令牌級的詞性標注、實體識別和詞頻表示,以及問句對齊嵌入。在上下文文本問句對齊層中,主要是實現了與問句的對齊嵌入。將計算向量化并直接處理張量,是問句嵌入的加權表示,此操作使模型能夠了解文本上下文的哪一部分對于問題更重要或更相關。當問句和文本上下文中的相似單詞相乘時,可確保在標記級別進行預測的乘積有更高的值,這是通過反向傳播和訓練密集層的權重來實現的。在實現時,首先計算文本上下文和問句向量的投影;然后使用torch.bmm來計算分子中的乘積,對乘積進行掩碼;最后通過softmax函數將結果與問句嵌入進行相乘。該層輸出一個附加的文本上下文嵌入,然后與GloVe嵌入連接起來。
經過上下文問句對齊層的處理,文本向量具備了兩個獨特的特性:GloVe模型嵌入和問句對齊嵌入。這些特性被傳遞到三層雙向長短期記憶網絡層,在這里,每層都會收集隱藏單元的數據,并將其串聯起來,以實現更加高效的信息處理。通過前向傳播,循環(huán)遍歷LSTM,存儲每層的隱藏狀態(tài),最后返回串聯輸出。
線性自注意層用于對問句進行編碼,比前面的層更加簡潔。令牌級的問句首先經過GloVe嵌入層,然后經過多層雙向長短期記憶網絡層,最后到達這一層。該層用于計算問句中每個單詞的重要性,通過在輸入上采用softmax函數來實現。但是為了向模型添加更多的學習能力,問句向量還需要輸入并乘上可訓練的權重向量,然后再通過一個softmax函數。本質上,該層正在對輸入執(zhí)行“注意”這一行為。
平均權重層則是將線性自注意層所計算的權重乘以問句通過多層雙向長短期記憶網絡層的輸出,這使得模型可以為每個問題中的重要單詞分配更高的值。
3.2.3 "抽取答案
處理過的文本向量和問句向量分別輸入到兩個多頭注意力網絡,從文本上下文中返回答案的開始和結束位置。多頭注意力機制將每個頭所輸出的結果拼接起來,然后再通過一個線性層映射成一個輸出,針對每個注意力,每個頭篩選到的信息不同,信息越豐富,越有利于最終模型取得更好的效果。
4 "實驗設置
4.1 實驗數據集
4.1.1 "數據集
2016年,P. Rajpurkar等發(fā)表的SQuAD數據集[1]收錄了10萬個經精心編輯的優(yōu)秀回復,并且涵蓋了500篇維基百科的相關內容,這些回復都是基于特定的文字背景,從而使得它們更容易進行準確的分析。SQuAD數據集是一個廣泛應用于閱讀理解任務的數據集,旨在讓計算機根據給定的文章上下文段落來回答問題。
在SQuAD任務中,每個樣本由一篇文章上下文段落和與該上下文段落相關的一系列問題組成。計算機的目標是從上下文段落中正確理解并提取出與每個問題相關的答案。SQuAD數據集中的答案通常是上下文段落中的連續(xù)片段,因此屬于提取式問答。SQuAD任務的挑戰(zhàn)在于計算機需要準確理解文章的內容、句子的結構和問題的意圖,然后從上下文段落中找到正確的答案。這要求計算機具備語義理解、推理和推斷的能力,并且能夠在大量文本中進行準確的定位和抽取。圖7中顯示了一段文本樣本及其3個相關問題。
SQuAD任務的研究和評估推動了閱讀理解領域的發(fā)展,許多模型和算法被設計和優(yōu)化,以在SQuAD數據集上獲得更高的準確率和更好的效果。這些模型的進步對于實際應用中的問答系統(tǒng)和信息提取任務都具有重要的意義。
斯坦福數據集的數據格式是由標題、上下文段落構成,標題主要是表達上下文段落的一個主題,文本段落包含問答對以及上下文段落。同一個主題可能會由幾個文本構成,但是問答對總會在相應的文本前面。主題一般是無用的,利用的信息主要是問答對中的問句和文本,其中問答對里面的is_impossible屬性有些時候是1和true,表明了是否有相應的答案,如果為true,則表明該問題回答不了。
4.1.2 "數據預處理
通過采用有效的降噪技術,可以有效地清除數據集中的文本、問題以及其他不必要的信息,包括刪減標點符號、刪減多余的空白,以及把大寫字母變成小寫;此外,還可以把原有的數值標識替換成文本標識,詳見圖8。
4.2 "基 "線
在答案抽取中,有多種方法可以用來根據上下文推理答案并從上下文中抽取出答案。以下是一些常見的方法:
1) BIDAF是一種用于閱讀理解的先進技術,它將字符和詞匯嵌入到模型中,并采用多粒度結構,在交互層中實現雙向注意力機制,從而能夠準確地預測出模型對上下文單詞級別的理解能力[12]。
2) 通過將Match?LSTM with Ans?Ptr與Match?LSTM with Ans?Ptr(Boundary)相結合[19],可以更好地利用神經網絡技術來預測答案的起止位置[22],這是閱讀理解領域最早的應用之一。PointerNet也提供了類似的模型,可以更準確地預測答案的起止位置。其中,PointerNet中的Boundary Model模型是O. Vinyals等人提出的一個序列到序列的模型[23],其用來實現從輸入序列中查找相應的令牌來作為答案輸出。通過Attention,可以從輸入序列中精確定位一個特定的詞,并以此作為輸出,來實現對該詞的準確定義。
3) BIDAF?INDEPENDENT:通過獨立目標訓練后的BIDAF模型[24]。
4) BIDAF?COMPOUND:通過復合目標訓練后的BIDAF模型[24]。
本文實驗選取的基線均選用答案抽取領域內較為前沿的技術。與以往的方式相比,新一代的技術不但擁有出色的性能,還擁有極大的靈活性,已成為各種領域的理想選擇。
4.3 參數設置
本文基于Featurize的數據庫,采用RTX 3060和Python 3.7的技術,構建了一個5層的模擬系統(tǒng)。該系統(tǒng)包含37 367 549個參數,每個參數的嵌入字數達到了300個,每個字的隱含維度達到了128個,每個字的dropout值達到了dropout=0.3,每個字的epoch數達到了10個,多頭個數達到了12個。
5 "實驗結果與分析
在解決問題時,通常會使用P. Rajpurkar等人提供的EM(Exact Match)值和F1值[1]來評估解決方法。EM值描述了在解決問題時,假設解決方法能夠得到正確的結果,并且可能會發(fā)現所用的解決方法并非總能達到理想的效果。F1值描述了在解決問題時,假設解決方法能夠得到正確的結果,并且可能會發(fā)現解決方法并不總能達到理想的效果,公式如下:
[F1=2×P×RP+R ] " " " " " " " "(3)
式中:P代表精確率;R代表召回率[20]。
為了直觀地反映AEMEQA模型的答案抽取性能,對模型進行實驗,并與BIDAF?INDEPENDENT模型和BIDAF?COMPOUND模型結果進行對比,如表1所示。
由表1可見,AEMEQA模型的答案抽取性能相較于Match?LSTM with Ans?Ptr(Boundary)模型、BIDAF?INDEPENDENT模型和BIDAF?COMPOUND模型都有一定的提升,雖然精度提升較低,EM值分別只提升了5.113%、1.281%和1.05%,F1值分別提升了7.69%、1.296%和1.335%,但AEMEQA模型在提升性能的同時,能夠節(jié)省內存,訓練更快,進一步提升了深度學習在答案抽取任務的效果。
6 "結 "語
本文提出了一種增強問句和文本交互的答案抽取方法,通過融合問句和文本的語義信息,使用更少的參數量來實現交互。實驗證明,這種方法在閱讀理解任務中獲得了較好的答案抽取結果;在模型訓練時,答案抽取效果有所提升。未來的工作將著手于問句的分類處理,將問句分類信息輸入模型進行更加充分的利用,對上下文進行實體識別,提高交互信息利用效率。此外,由于模型參數數量限制,實驗未使用大規(guī)模模型去進行答案抽取任務,但目前已經有許多自然語言領域的大規(guī)模模型,如BERT、ALBERT等,未來將研究這些大規(guī)模模型是否與現有答案抽取任務框架適配,進一步提高模型的答案抽取能力。
參考文獻
[1] RAJPURKAR P, JIA R, LIANG P. Know what you don't know: Unanswerable questions for SquAD [EB/OL]. [2022?01?14]. https://arxiv.org/abs/1806.03822.
[2] NGUYEN T, ROSENBERG M, SONG X, et al. Msmarco: A human?generated machine reading comprehension dataset [EB/OL]. [2022?07?01]. https://arxiv.org/abs/1611.09268.
[3] TRISCHLER A, WANG T, YUAN X, et al. Newsqa: A machine comprehension dataset [EB/OL]. [2022?01?20]. https://ui.adsabs.harvard.edu/abs/2016arXiv161109830T/abstract.
[4] JOSHI M, CHOI E, WELD D S, et al. Triviaqa: A large scale distantly supervised challenge dataset for reading comprehension [EB/OL]. [2022?10?03]. https://ui.adsabs.harvard.edu/abs/2017arXiv170503551J/abstract.
[5] 唐竑軒,武愷莉,朱朦朦,等.基于雙向注意力機制的多文檔神經閱讀理解[J].計算機工程,2020,46(12):43?51.
[6] LIU S, ZHANG X, ZHANG S, et al. Neural machine reading comprehension: methods and trends [J]. Applied sciences, 2019, 9(18): 3698.
[7] CHEN D. Neural reading comprehension and beyond [M]. California: Stanford University, 2018.
[8] VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need [C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. California: ACM, 6000?6010.
[9] GOODFELLOW I, BENGIO Y, COURVILLE A, et al. Deep learning [M]. Cambridge: MIT Press, 2016.
[10] CHENG J, WANG P S, GANG L I, et al. Recent advances in efficient computation of deep convolutional neural networks [J]. Frontiers of information technology amp; electronic engineering, 2018, 19(1): 64?77.
[11] SUNDERMEYER M, SCHLüTER R, NEY H. LSTM neural networks for language modeling [C]// Interspeech. [S.l.]: IEEE, 2012: 601?604.
[12] SEO M, KEMBHAVI A, FARHADI A, et al. Bidirectional attention flow for machine comprehension [EB/OL]. [2022?04?07]. http://arxiv.org/pdf/1611.01603.
[13] XIONG C, ZHONG V, SOCHER R. Dynamic coattention networks for question answering [EB/OL]. [2022?07?11]. https://www.semanticscholar.org/.
[14] GOODFELLOW I, WARDE?FARLEY D, MIRZA M, et al. Maxout networks [C]// International Conference on Machine Learning. Atlanta: ACM, 2013: 1319?1327.
[15] SRIVASTAVA R K, GREFF K, SCHMIDHUBER J. Training very deep networks [C]// Proceedings of the 28th International Conference on Neural Information Processing Systems. Montreal: ACM, 2015: 2377?2385.
[16] CHEN D, FISCH A, WESTON J, et al. Reading wikipedia to answer open?domain questions [C]// Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics. Vancouver: ACL, 2017: 1870?1879.
[17] WEISSENBORN D, WIESE G, SEIFFE L. Making neural QA as simple as possible but not simpler [EB/OL]. [2022?03?02]. http://arxiv.org/abs/1703.04816v3.
[18] WANG W, YANG N, WEI F, et al. Gated self?matching networks for reading comprehension and question answering [C]// Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics. Vancouver: ACL, 2017: 189?198.
[19] WANG S, JIANG J. Learning natural language inference with LSTM [EB/OL]. [2022?01?12]. https://ui.adsabs.harvard.edu/abs/2015arXiv151208849W/abstract.
[20] 顧迎捷,桂小林,李德福,等.基于神經網絡的機器閱讀理解綜述[J].軟件學報,2020,31(7):2095?2126.
[21] HUANG H Y, CHOI E, YIH W. Flowqa: grasping flow in history for conversational machine comprehension [EB/OL]. [2022?03?11]. http://arxiv.org/pdf/1810.06683.
[22] WANG S, JIANG J. Machine comprehension using match?lstm and answer pointer [EB/OL]. [2022?02?11]. https://ui.adsabs.harvard.edu/abs/2016arXiv160807905W/abstract.
[23] VINYALS O, FORTUNATO M, JAITLY N. Pointer networks [J]. Advances in neural information processing systems, 2015(1): 28.
[24] FAJCIK M, JON J, SMRZ P. Rethinking the objectives of extractive question answering [EB/OL]. [2023?02?07]. https://arxiv.org/abs/2008.12804.
猜你喜歡
中國教育技術裝備(2016年19期)2016-12-27 19:23:52
中國遠程教育(2016年11期)2016-12-27 18:07:31
現代商貿工業(yè)(2016年25期)2016-12-26 09:58:02
江蘇教育·中學教學版(2016年11期)2016-12-21 11:45:08
江蘇教育·中學教學版(2016年11期)2016-12-21 11:36:29
現代情報(2016年10期)2016-12-15 11:50:53
考試周刊(2016年94期)2016-12-12 12:15:04
新教育時代·教師版(2016年23期)2016-12-06 06:02:38
法制與社會(2016年32期)2016-12-01 15:25:53
軟件導刊(2016年9期)2016-11-07 22:20:49
