改進一致性哈希優化存儲郵政數據算法的研究
2024-09-14 00:00:00李澤山
現代電子技術 2024年6期
關鍵詞:數據存儲



摘 "要: 隨著電子商務不斷發展,郵政快遞行業數據日益增多,傳統方式對于郵政數據存儲的理論與方法都已無法滿足需求。基于此情況,使用一致性哈希算法來解決存儲系統的橫向彈性擴展,結合一致性哈希的虛擬節點與加權輪詢算法優化Hadoop平臺下分布式文件系統(HDFS)存儲策略,實現集群在同構與異構條件下的數據均衡效果。同時介紹集群節點數據轉移思想,設計負載因子與系統自檢周期,實現了集群動態權重的負載轉移,并進行實驗驗證。實驗結果表明,文章提出的改進算法與HDFS、普通一致性哈希相比,在不同條件下集群負載差值均有不同程度的提升,證明了該策略可以有效降低集群節點間負載差值。
關鍵詞: 數據存儲; 一致性哈希算法; 加權輪詢算法; 分布式文件系統; 負載均衡; 異構集群; 分配策略
中圖分類號: TN919?34; TP319.9 " " " " " " " " " 文獻標識碼: A " " " " " " " " " "文章編號: 1004?373X(2024)06?0043?06
Research on improved consistency hash optimization algorithm for storing postal data
LI Zeshan
(The Information Center of National Forestry and Grassland Administration, Beijing 100714, China)
Abstract: With the continuous development of e?commerce and the increasing number of data in the postal express industry, traditional methods are no longer meet the needs for the theories and methods of postal data storage. Based on this situation, the consistent hash algorithm is used to solve the horizontal elastic expansion of the storage system, and the storage strategy of distributed file system (HDFS) on Hadoop platform is optimized by combining consistent hashing with virtual nodes and weighted polling algorithm to realize the data balance in clusters under homogeneous and heterogeneous conditions. The concept of cluster node data transfer is introduced, and the load factors and system self check cycles is designed, so as to realize the load transfer of dynamic cluster weights, and conduct the experimental verification. The experimental results show that the proposed improved algorithm has different degrees of improvement in cluster load difference compared with HDFS and regular consistency hashing under different conditions, proving that this strategy can effectively reduce the load difference between cluster nodes.
Keywords: data storage; consistent hashing algorithm; weighted polling algorithm; distributed file system; load balancing; heterogeneous clusters; allocation strategy
0 "引 言
隨著大數據時代到來,人們的生活逐漸依附網絡,使網絡信息數據急劇猛增,給郵政業務帶來了新的挑戰。合理地存儲郵政龐大數據才能使用戶、快遞企業和郵政管理者之間工作效率提高,降低企業投訴率。2022年全國快遞業務量為1 105.81 億件,同比增長2.1%,預計2023年全年郵政業業務的快遞業務量將達到1 300億件。
在此背景下,使用分布式存儲海量數據[1]成為數據存儲的主要技術。其中HDFS是分布式系統基礎架構Hadoop的核心功能模塊,由于其具有數據傳輸速率高和容錯性好的特性,可以有效解決郵政數據的存儲問題。如文獻[2]提出在HDFS分布式系統上層,使用Hbase將郵政數據存放在數據庫中,用以解決企業海量數據存儲問題。文獻[3]提出基于Hadoop框架下的大數據分析功能對郵政快遞的寄遞系統進行設計。文獻[4]在Hadoop框架基礎上,結合內存數據庫構建大數據模型,對存儲在HDFS中的數據進行檢測、監控與分析,設計一套反洗錢系統。但這些研究都在HDFS原有存儲策略上進行,HDFS隨機性放置數據的策略容易造成系統節點數據分布不均,直接影響系統性能,限制了存儲效率。
1 "相關工作
針對HDFS隨機放置數據的問題,學者們提出如下解決方案:文獻[5]存放數據的思想是計算所有節點當前的使用情況,選擇使用空閑的節點存儲數據;文獻[6]把緩存問題轉換為整數規劃問題,設計了一種兼顧存儲成本與帶寬成本的對等方法;文獻[7]提出根據集群內節點存儲性能和網絡拓撲距離,找到集群的最優節點進行數據存放。這些方法在數據均衡方面取得了一定進展,但沒有兼顧到可靠性與系統單調性的問題。
在此基礎上,文獻[8]提出一種單純使用一致性哈希算法解決的方案,以實現系統單調的問題。文獻[9]提出在Hadoop下通過Datanode緩存部分小文件的策略,來解決Namenode在存儲時負載失衡問題;文獻[10]提出一種基于跳躍Hash的對象分布算法,憑借占用資源更少而優化存儲數據效率。這些研究很大程度提升了數據可靠性,但未考慮到節點性能不同的異構集群數據存儲情況。
之后的研究中,文獻[11]基于Eclipse的研發環境,設計一個任務調度器用以最大化利用分布式系統內的內存對集群中的內存與緩存進行負載均衡,經實驗證明,在部分場景下該方法比傳統分布式系統具有更好的效率;文獻[12]基于Nginx服務器研究了集群負載均衡的場景,提出基于動態權重的連接算法,根據該算法得出數據的分配方法。
以上算法多數能與其他算法相兼容,說明使用算法仍然可以優化HDFS分布式系統的負載均衡。本文提出一種使用一致性哈希算法結合加權輪詢的數據分配策略,在分布式系統中,集群的動態擴展利用一致性哈希可以較好解決。但一致性哈希算法中沒有對于負載均衡的描述,單一的一致性哈希容易導致系統的負載傾斜。因此,引入虛擬節點思想來均分數據,并結合加權輪詢算法進行存儲節點權值的數據分配,針對快遞數據特點來改進HDFS分布式系統存儲策略。將此方法與HDFS原存儲策略以及基于虛擬節點的普通一致性哈希分配策略進行實驗對比,證明文章研究的策略在不同條件下的數據存儲負載均衡方面得到較大提升。
2 "存儲分配策略的研究
2.1 "一致性哈希算法
一致性哈希是負載均衡領域里一種應用廣泛的算法,最早于1997年,由麻省理工學院的David Karger提出,用于改進P2P網絡中哈希表重映射的問題。算法中首先抽象整個存儲系統形成一個封閉的232-1環形哈希空間,再使用哈希算法將存儲節點與數據映射到哈希環內。
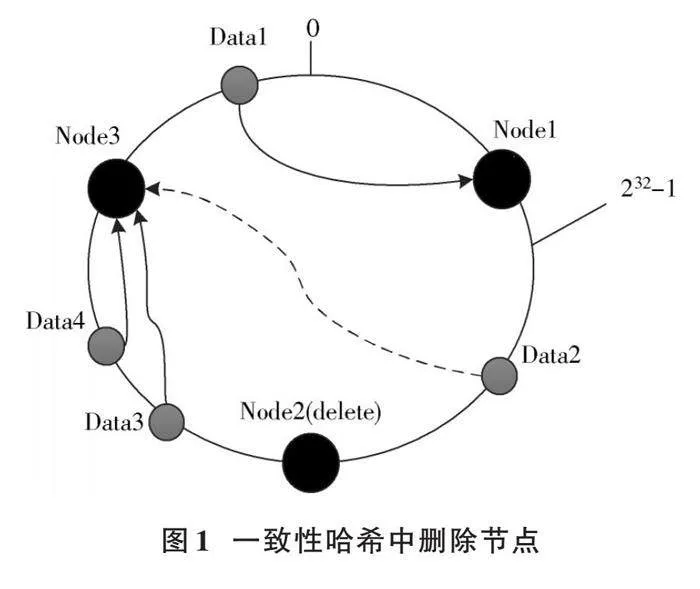
如圖1所示,哈希環內有Node1、Node2、Node3三臺機器,以及Data1、Data2、Data3、Data4四個存儲對象。當Node2被刪除,根據一致性哈希順時針遷移原則,原本存儲在Noede2的數據Data3會被存儲到Node3中,系統內對象沒有任何的改動,極大地減小了刪除節點數據分布時系統的壓力。
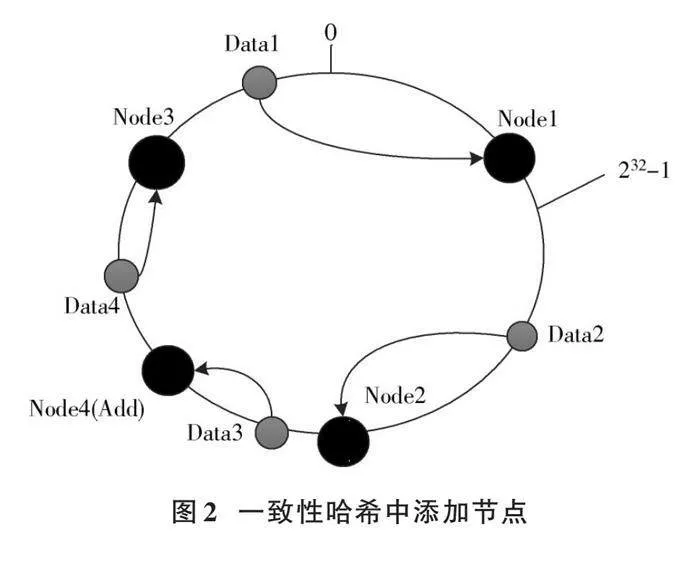
如圖2所示,在集群內進行節點(機器)添加操作時,在集群中添加一個新的節點Node4,通過順時針遷移原則,Data3會存儲到Node4中。這種特殊的哈希算法實現了少量數據的遷移,避免了幾乎全部數據的移動。因此,一致性哈希算法是對動態擴展能力進行優化的一種哈希算法[13]。
2.2 "虛擬節點分配策略
虛擬節點是一種廣泛應用于各種工程場景的概念,但當存儲節點的數量太少,會導致其無法做到在哈希環上均勻分布,進而出現負載失衡。針對此問題,本文在物理節點與數據之間設計一個虛擬層,虛擬層由大量虛擬節點構成,如圖3所示。虛擬節點被真實物理節點包含,多個虛擬節點對應一個物理節點,數據通過哈希函數映射到虛擬節點上,實際存儲到對應的物理節點中,通過這種方法就有足夠的虛擬節點來進行一致性哈希操作。
如果系統內分配較少的虛擬節點,會造成一致性哈希無法滿足系統負載均衡的效果;而虛擬節點過多又會導致存儲系統需花費較長時間才能找到對應的虛擬節點,拖慢系統效率。因此,設計虛擬節點的數量十分重要。
在集群節點性能一致的同構條件下,根據郵政快遞數據快遞單號的唯一性,更改HDFS中的塊存儲隨機放置策略,將每一條數據中的單號作為key值,映射到哈希環上,然后把節點的IP地址再次映射到哈希環上,整個環內作1∶N 配比的虛擬節點映射。該哈希環便可分割為N+1個獨立的區間,將key分發到哈希環,由于key的數量巨大,每個區間都能夠分發到相對均勻的key。可以推測,在一個1∶N 配比的虛擬節點映射的一致性哈希系統中,假設某個物理節點的初始哈希位置為P,其所代表的所有映射節點的哈希位置應當表示為:
[P'=232-1N+1k+Pmod(232-1), "k=0,1,2,…,N] (1)
在哈希環內為減少哈希映射的重復度,本文還為該系統采用一種完美哈希算法(Perfect Hashing)作為計算哈希值的依據。其中,在性能和使用領域都比較有優勢的是BKDR哈希算法,以h表示特征字符串的哈希結果,l表示字符串長度,s表示前后字符在哈希運算中的權重比(取值可以為31、131、1 313等),其計算公式表達為:
[h=n=0l-1xn·sn] (2)
由于在一致性哈希系統中,該計算結果需要對 232-1 的哈希環長度進行取模運算,因此最終的哈希結果表示為:
[h=n=0l-1xn·snmod(232-1)] (3)
異構服務器集群中,由于各個節點性能不一,通常要配置數量巨大的虛擬節點來平衡異構狀態。這種方法會造成為虛擬節點分配較多的額外資源,還降低了系統內查找效率。若節點為[i],其計算能力設為[ai],每臺節點的虛擬層引入的虛擬節點個數為[klogN],其中N為設備總數,k為常數。假設集群內,算力最低的節點用[amin]表示,那么在一致性哈希算法中,系統在異構條件下分配虛擬節點個數為:[i=0NaiaminklogN]。可以看出,當[aiamin]值很大時,則將引入大量的虛擬節點,降低了存儲系統效率。
2.3 "加權輪詢算法分配策略
以上的分析說明在異構條件下僅憑虛擬節點的引入無法保證數據均衡,需結合加權輪詢算法繼續優化數據分配策略。加權輪詢算法是對輪詢算法的改進,用權值來表示節點之間存在的差異,權值高的節點分配的存儲任務多,權值低的節點分配的存儲任務少。
在傳統加權輪詢算法中,一般人為設置算法內權值大小,這樣無法動態表述節點間差異。本文提出的加權輪詢實現負載均衡算法是在分配數據階段通過獲取節點的存儲空間ROM利用率,對比平均值進行數據的存儲分配。其中,存儲空間ROM利用率即為算法中要收集的負載因子。
對于負載因子的收集,在Hadoop中,通過API接口編寫相應依賴包可以采集磁盤的使用情況。通過命令hdfs dfsadmin?report獲取磁盤的使用情況。
磁盤的利用率公式為:
[η=disctotal+discfreedisctotal] " " "(4)
式中:[η]表示服務器磁盤的利用率;[disctotal]表示磁盤空間;[discfree]表示磁盤剩余空間。
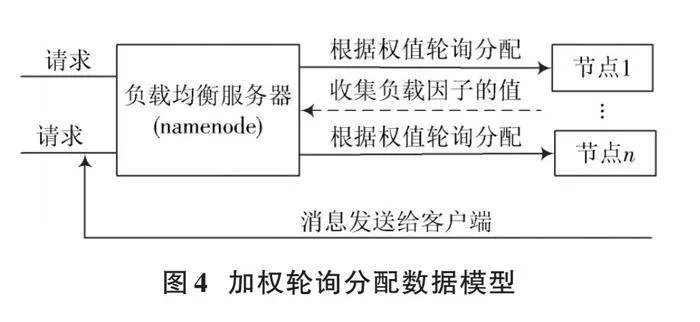
Hadoop中,主節點(namenode)作為負載均衡服務器,處理客戶端發送的存儲數據請求,之后發揮負載均衡服務器作用,對各個從節點實時反饋其負載狀態,即負載因子信息,然后把請求根據權值輪詢分配到各節點,從節點根據實時負載情況分配數據,完成處理請求,將結果發送給主節點,之后主節點直接發送給客戶端,完成分配。加權輪詢分配的工作模型如圖4所示。
具體執行分配數據步驟如下:
1) 系統收到數據存儲請求后,開始收集當前各節點負載因子的值。
2) 將各個負載因子的值與系統內負載平均值作比較,設系統平均負載為[L],節點為[i],若存在[L≥Li],則將這臺服務器的權值設置為0,此次存儲不再對這臺節點進行數據分配;若[Llt;Li],則根據負載因子計算各個節點權重,根據權重進行節點的數據分配。
3) 對分配的數據節點,根據負載因子按比分配數據,完成權值輪詢分配任務。
2.4 "節點間負載轉移策略
在HDFS分布式系統中,為達到負載均衡更好的效果,需要滿足節點間的數據遷移。此外,當某些節點中的讀寫頻率較高,將造成此節點負載壓力較大,嚴重時甚至導致系統崩潰。因此,需要結合虛擬節點與加權輪詢算法進行節點間動態負載均衡轉移策略設計。
實現系統動態負載均衡的過程是時刻獲取每個節點當前負載信息。由于此操作需花費系統額外性能,因此文章設計抓取的節點負載信息以周期性的方式收集,用來降低這些額外開銷。在時間周期上,兼顧算法的效率,本文收集的時間周期是30 s(T=30 s)。根據上文,設集群內負載因子最輕節點負載為[Lmin],負載因子最重節點負載為[Lmax],負載因子居中節點為[Lmid],[i]為節點,調整負載均衡的上限為[Threshold],若有節點[i]中[Lmax-Lmidgt;Thresholdi],即對負載超重進行調整,策略為減少[Lmax]節點對應的虛擬層中節點。同時把計劃存儲到此節點的數據按照順時針遷移原則轉存環內順時針下一個節點,并清空節點預警信息。
同理,若節點[i]中[Lmid-Lmingt;Thresholdi],即進行負載過輕調控,對應地增加[Lmin]虛擬層中虛擬節點數量,并對比環內逆時針下一節點中數據量,均衡兩節點數據存儲量,清空節點預警信息。
3 "實驗結果及分析
3.1 "實驗平臺及部署
實驗使用高性能計算機在VMware Workstation軟件上進行。系統平臺的參數如表1所示。默認已搭建完成Hadoop全分布式系統實驗平臺。
3.2 "實驗數據的選取
本文研究針對郵政行業快遞數據的存儲,快遞公司的工作人員每掃描一份快遞面單,系統會記錄一條數據。實驗的數據選取自內蒙古自治區郵政行業大數據信息統計系統內數據,由中通快遞公司提供。此數據為掃描快遞面單的部分信息,共有A~K等11個字段,如掃描時間、快遞單號等。遞面單信息的部分數據截圖如圖5所示。
3.3 "集群負載均衡實驗
同構條件下,在VMware Workstation軟件配置虛擬機階段,對一臺節點服務器配置完成后,再次復制此虛擬機,以達到從節點配置統一、負載因子一致的效果。使用3.2節中的實驗數據,將快遞單號作為唯一標識符,映射到哈希環上,真實服務器以IP地址同樣映射到環上,使用IntelliJ IDEA開發軟件編寫Java代碼,將改進的一致性哈希通過API連接到Hadoop的存儲接口,覆蓋其自帶塊存儲策略。在同一大小數據下,進行多次數據存放實驗取統計平均,可以得到不同存儲節點的負載差值,結果如圖6所示。
系統中,所有節點負載數據量最大和最小的差值與節點平均負載值的比率為負載率差值。理想的負載率差值應是根據系統節點數量的變化維持在穩定的水平上。
本文算法基于權值的虛擬節點一致性哈希在數據劃分中,節點存儲的數據量取決于負載因子大小。集群配置相同時,從圖6可以看到,本文算法與普通虛擬節點的一致性哈希存儲數據策略相差不大,不同集群規模在劃分數據時,節點中負載差值在5%~8%,相比HDFS存儲數據的分配策略有一定提升。可以推測到,隨著測試實驗數據量與集群存儲節點數量的增多,測試結果也將穩定在這一區間內。
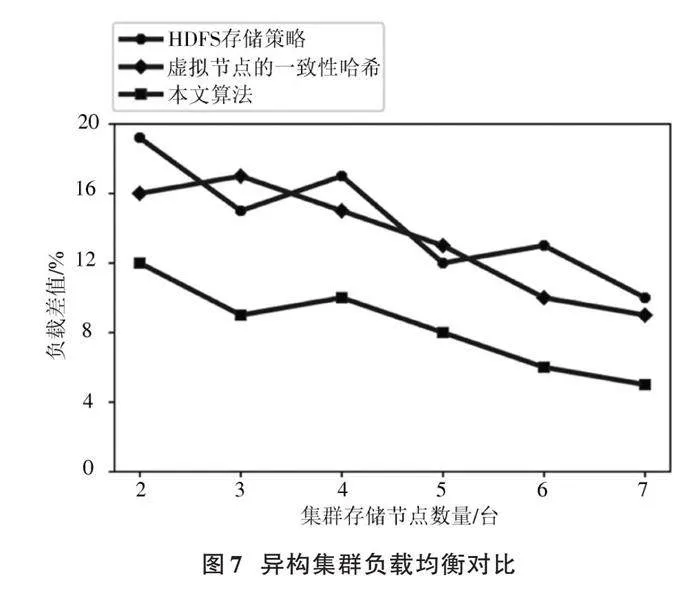
在虛擬機的配置階段,將存儲節點的磁盤空間設置為各不相同,以區分負載因子,設置集群的異構條件。重復上一實驗步驟,將數據分發給不同從節點,進行多次數據存放實驗取統計平均,得到不同從節點的負載差值,如圖7所示。
可以看到,HDFS與虛擬節點的一致性哈希兩種數據存儲策略在面對異構集群時,負載差值波動較大,原因是兩種策略并沒有對集群的節點間性能不同進行針對性的優化,導致在此情況下,負載差值相近;而本文算法根據設定好的負載因子,計算節點在分配數據時按結果進行比例劃分,隨著數據量與節點數量的增加,可以推測整個集群的負載差值穩定在6%左右,集群負載差值明顯降低。
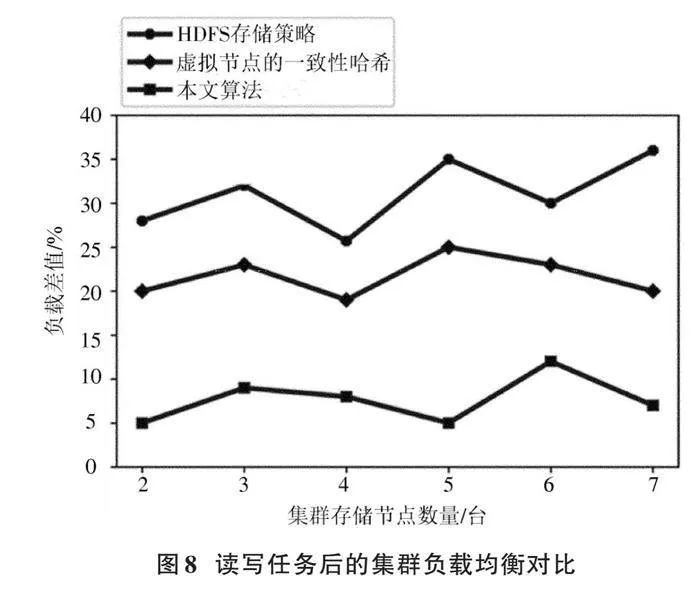
為驗證集群動態數據均衡情況,在圖7基礎上,對存儲節點的數據進行10 000次讀寫操作,進行數據節點間負載轉移策略實驗,結果如圖8所示。可以看到相比HDFS存儲策略,使用虛擬節點的一致性哈希節點數據分布相對更均勻,負載差值穩定在23%左右;本文算法引入周期(T=30 s)節點負載轉移思想,實現集群動態自適應調整數據,多次測試取平均,負載差值達到10%以下(約為8%),實用性得到顯著提升,達到了設計的要求。同時,在實驗中的系統負載變化平緩,節點數量發生變化而整個負載沒有較大波動,說明存儲系統中增刪節點的操作不會對系統造成過大的影響。
4 "結 "語
本文基于Hadoop平臺下HDFS分布式系統,使用分布式思想來解決日益增多的郵政數據的存放問題。實驗結果表明,文章提出的改進算法與HDFS、普通一致性哈希相比,在不同條件下集群負載差值均有不同程度的提升,證明了該策略可以有效降低集群節點間負載差值。實驗驗證了加權輪詢與虛擬節點的一致性哈希算法相融合的可行性,為郵政企業面對海量數據的存儲提供新的解決思路。之后準備搭建真實的集群環境,進一步進行實驗,為項目的應用進行技術儲備。
注:本文通訊作者為李澤山。
參考文獻
[1] 危華明,廖劍平.海量數據存儲中云服務器性能加速方法仿真[J].計算機仿真,2023,40(5):515?519.
[2] 王衛鋒,楊林.基于Hadoop的郵政寄遞大數據分析系統設計與實現[J].中國科學院大學學報,2017,34(3):395?400.
[3] 李朝暉.基于HADOOP平臺及內存數據庫架構的反洗錢系統[Z].北京:中國郵政儲蓄銀行股份有限公司,2017?11?01.
[4] 陳偉.一種改進的HDFS副本放置策略[J].長春師范大學學報,2018,37(4):15?20.
[5] 邱寧佳,胡小娟,王鵬,等.一致性哈希的數據集群存儲優化策略研究[J].信息與控制,2016,45(6):747?752.
[6] 李中華,羅尚平,王慧.D?Spillover負載均衡的算法研究[J].重慶師范大學學報(自然科學版),2020,37(6):7?12.
[7] LI R, LI Y, LI W. An integrated load?balancing scheduling algorithm for Nginx?based web application clusters [J]. Journal of physics: conference series, 2018(1): 012078.
[8] 秦加偉,劉輝,方木云.大數據平臺下基于類型的小文件合并方法[J].軟件工程,2020,23(10):12?14.
[9] 聶世強,伍衛國,張興軍,等.一種基于跳躍hash的對象分布算法[J].軟件學報,2017,28(8):1929?1939.
[10] SANCHEZ V A B, KIM W, EOM Y, et al. EclipseMR: distributed and parallel task processing with consistent hashing [C]// IEEE International Conference on Cluster Computing. Honolulu, HI, USA: IEEE, 2017: 322?332.
[11] 劉宏宇,鄭煜.大數據在京東物流中的應用[J].現代經濟信息,2019(5):374.
[12] 韓超,鄭銳韜,于偉,等.基于一致性哈希算法的分布式數據庫高效擴展方法[J].計算機科學與應用,2020,10(1):6.
[13] 郭宗睿,湯志鳳.基于一致性哈希算法的分布式數據庫高效擴展方法研究[J].通訊世界,2021(2):307?308.
[14] 劉沛津,王柳月,孫昱,等.基于一致性哈希算法的分布式機電系統海量數據存儲策略研究[J].機床與液壓,2023,51(22):31?38.
[15] 盧麗,孫林夫,鄒益勝.基于一致性哈希環多主節點的改進實用拜占庭容錯算法[J].計算機集成制造系統,2023(1):25?35.
[16] 張開琦,劉曉燕,王信,等.基于動態權重的一致性哈希微服務負載均衡優化[J].計算機工程與科學,2020(8):1339?1344.
猜你喜歡
文理導航(2017年2期)2017-02-16 13:18:46
辦公室業務(2016年11期)2017-01-09 18:02:44
中國科技博覽(2016年24期)2016-12-28 23:25:48
電子技術與軟件工程(2016年20期)2016-12-21 11:11:51
電腦知識與技術(2016年28期)2016-12-21 10:13:14
電腦知識與技術(2016年27期)2016-12-15 20:33:05
電腦知識與技術(2016年12期)2016-06-14 19:10:43
電腦知識與技術(2016年12期)2016-06-14 01:13:57
科教導刊·電子版(2016年11期)2016-06-03 19:01:33
電腦知識與技術(2016年8期)2016-05-19 13:33:11
