基于SciBERT-BiLSTM-CRF-wordMixup的軟件實體識別研究
2024-10-08 00:00:00潘雪蓮錢雨菲王憲雨
現代情報 2024年10期


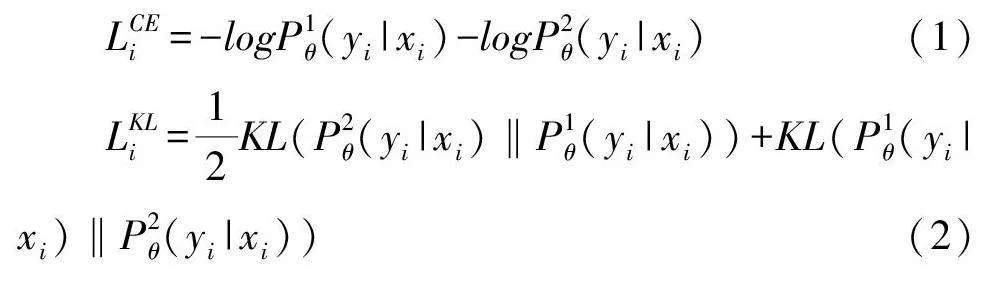
關鍵詞: 軟件實體識別; 命名實體識別; 深度學習; 數據增強;SciBERT
DOI:10.3969 / j.issn.1008-0821.2024.10.007
〔中圖分類號〕TP391 〔文獻標識碼〕A 〔文章編號〕1008-0821 (2024) 10-0075-11
軟件在現代科學研究中發揮著重要作用, 它被用于科學研究的諸多方面, 但其學術價值一直被低估甚至忽略。近年來, 隨著數據密集型科學研究范式的興起和數據價值認可度的提高, 一些學者開始呼吁重視軟件的價值, 因為“幾乎所有的數據都需要軟件進行某種形式的處理”[1] 。一些國外組織機構也開始將軟件認定為有效科研成果[2-3],以鼓勵科學家開發和共享軟件。在此背景下, 學界開始探討如何量化評價軟件的影響力。一些學者提出使用被引次數來測度軟件的學術影響力[4] 。然而研究發現,學術論文中軟件引用缺失嚴重且普遍存在[5-6] 。因此, 有學者提出用學術論文全文中的軟件使用頻次來評價軟件的學術影響力[7] 。隨之而來的問題是, 如何從學術論文全文中識別軟件。快速準確地從學術論文全文中識別出軟件實體, 將使得從軟件使用視角大規模量化評估軟件學術影響力成為可能, 為有關部門將軟件納入科研評價體系提供數據支撐, 對深入認識軟件的學術價值、促進科學軟件可持續發展和學術生態體系均衡發展具有重要意義。此外, 對學術論文中的軟件實體進行識別和量化分析, 也有助于豐富和拓展信息計量學的研究對象, 還可以為其他知識實體的識別和計量提供方法參考。
軟件實體在學術論文中的分布非常稀疏, 邊界不清晰且形式多變, 識別難度較大。早期的軟件實體的識別大多基于人工或規則。基于人工的識別方法具有可靠性高的優點, 但是十分耗費時間成本和人力成本, 難以滿足多領域大規模的軟件識別需求。基于規則和詞典的方法相較于人工識別能夠節省人力, 但是其可擴展性并不高。首先, 規則的制定與詞典的生成依賴相關領域專家意見, 規則和詞典規模的擴大通常可以提高模型的識別準確率和召回率,但這給專家構建規則帶來了更大負擔; 其次, 不同研究領域制定的規則和詞典往往難以被其他領域利用, 其可擴展性有限; 最后, 對于軟件實體識別領域而言, 提及軟件的模式多變以及新軟件的不斷涌現使得制定普適性的軟件識別規則十分困難。鑒于此, 近年來一些學者使用機器學習和深度學習方法來自動識別軟件實體。然而, 需要大量人工標注數據訓練模型的有監督的機器學習方法也存在耗時長的缺點, 不適合用來處理多領域大規模的軟件識別任務。深度學習方法可以自動學習詞匯語義、上下文依賴關系等, 已成為識別命名實體的一種較為有效的方法[8-10] 。因此, 一些學者嘗試將深度學習方法引入軟件實體識別領域。例如, Schindler D 等[11]在自建的社會科學研究語料庫上, 使用BiLSTMCRF進行訓練以識別軟件名稱, 孫超[12] 使用Glove-BiLSTM-CRF、BERT-BiLSTM-CRF 和BERT-BiL?STM-GCN-CRF 模型對軟件工程文本中的軟件實體進行識別。這些研究為基于學術論文全文的軟件實體識別任務提供了借鑒思路。
本研究以學術論文中的軟件實體為研究對象。首先, 通過軟件實體定義和BIO 標注構建軟件實體識別領域語料庫; 然后, 在此基礎上提出改進的SciBERT-BiLSTM-CRF-wordMixup 模型并對該模型的識別效果進行評估。此外, 本研究還針對人工標注語料庫耗時耗力問題, 設計一種基于小型知識庫的程序輔助標注方案。
1相關工作概述
命名實體識別(Named Entity Recognition,NER)是自然語言處理中的一個重要基礎任務, 旨在從非結構化文本中識別出人名、地名、事件名等具有特定含義的實體并加以歸類, 對句法分析、文本分類、機器翻譯等許多自然語言處理下游任務均具有重要的支撐作用[13] 。命名實體識別方法主要包括基于人工識別、基于規則和詞典提取、基于傳統機器學習和基于深度學習的抽取方法。軟件實體不是人名、地名、機構名、時間、日期、貨幣和百分比這些傳統意義上的命名實體,軟件實體形式多樣, 在學術論文中邊界不清晰, 提及軟件實體的模式多變, 且提及軟件的模式也常被用來提及實驗儀器設備和化學試劑等, 自動識別難度較大。因此, 一些學者采用人工對有限數量論文中的軟件實體進行識別。例如, Li K 等[14]為探究PLOS ONE 期刊論文中的R包引用情況, 對391篇抽樣論文全文文本中的R包進行人工識別; Yang B等[15] 采用人工對生物信息學領域期刊論文全文中的軟件實體進行識別, 并據此探究科學軟件對生物信息學研究的重要性; 孟文靜等[16] 采用人工方法對圖書情報學國際期刊論文中使用的Python軟件包進行標注, 并據此探究Python 軟件工具在圖書情報學領域的應用擴散過程。人工識別軟件實體具有可靠性高的優點, 但十分耗費時間和人力, 該方法通常僅適用于樣本數量有限的小規模研究, 不太適用于針對多學科大規模文本數據的軟件識別任務。
基于規則和詞典的命名實體識別方法比人工識別方法效率高, 但由于軟件種類繁多, 目前尚無軟件詞典可用且新軟件不斷涌現, 基于規則和詞典的方法難以很好地完成軟件實體識別任務。因此, 一些學者將基于規則和詞典的方法與機器學習方法相結合來識別非結構化自由文本中的軟件、數據庫等有價值命名實體。例如, Thelen M 等[17] 提出了一種基于自擴展的命名實體識別方法, 該方法只需要少量的種子詞和一個未標注文本語料庫作為輸入。此后, 一些學者對該算法進行改進以提高算法性能。Yangarber R 等[18] 設計出模式精度和模式信度等指標來過濾識別出來的模式和實體, 以提高算法精度。然而, 刪除小于一定閾值的模式會導致實體抽取的低召回率。Gupta S 等[19] 通過預判未標注實體的標簽來提高基于自擴展的命名實體識別算法的性能。但是該算法需要借助外部領域詞典完成預判工作,并且該算法將高分模式抽取出的實體全部默認為正確實體, 無法從中識別出錯誤實體。Duck G 等[20]于2013 年開發了一種基于規則的命名實體識別器bioNerDS, 用于從生物信息學原始文獻中抽取數據庫和軟件名稱, F1 值位于63%~91%區間。Duck G等[21] 于2015 年對之前提出的針對數據庫和軟件實體的識別算法進行改進, 實驗結果表明, 基于詞典的方法F1 值為46%, 而機器學習方法在嚴格匹配和寬松匹配模式下的F1 值分別達63%和70%。Pan XL等[6] 借鑒Thelen M 等[17] 和Gupta S等[19] 的命名實體識別算法, 提出一種改進的基于自擴展的軟件實體自動識別算法, 該算法對PLOS ONE 期刊論文文本中的軟件實體進行識別, 識別效果(F1 值)為58%。
隨著深度學習技術的不斷發展和應用的日益拓展, 一些學者開始將深度學習方法應用于軟件實體識別任務, 以提高識別效果。例如, Schindler D 等[11]在自建的社會科學研究語料庫上, 使用BiLSTMCRF進行訓練以識別軟件名稱, 該算法在測試集上的F1 值達82%。Lopez P 等[22] 使用CRF、BiL?STM-CRF(包括未加入特征、加入特征、加入EL?MO)、BERT-CRF 以及SCIBERT-CRT 模型對軟件實體進行識別, 各模型在實驗語料上的F1 值分別為66.3%、69.8%、69.3%、71.6%、65.3%和74.6%。孫超[12] 使用Glove-BiLSTM-CRF、BERT-BiLSTMCRF和BERT-BiLSTM-GCN-CRF 模型對軟件工程文本中的軟件實體進行識別, 3 個模型對軟件實體的整體識別F1 值分別為67.37%、79.51%和79.60%。Zhang H 等[23] 基于SciBERT 和級聯二元標注框架構建了技術相關實體識別模型, 模型對自然語言處理領域論文中方法、數據集、指標和工具4 種技術相關實體的整體識別F1 值為87%, 但文章并未給出模型對工具類實體的識別效果。章成志等[24] 使用CRF、BiLSTM-CRF、BERT-CRF、SciBERT-CRF模型對自然語言處理領域學術論文中的方法實體進行識別, 4 個模型對工具實體的整體識別F1 值分別為27%、38%、56%和57%。深度學習方法已證實在軟件實體識別任務中的適用性, 但已有研究構建的識別模型F1 值大多在80%以下, 模型識別效果有待進一步提升。
2語料庫與識別模型構建
2.1語料來源
本研究主要涉及兩個語料來源,一是SchindlerD等[25] 的公開數據集SoMeSci ( Version 0.2, ht?tps:/ / zenodo. org/record/4968738#.Yf9D49FBzb0),二是基于PLOS ONE期刊學術論文構建的樣本庫PLoSSo。SoMeSci 是人工基于PubMed Center 開放獲取子集收錄的生物醫學領域學術論文文本構建的語料庫, 包含論文“方法部分” 文檔、“全文文本”文檔等多個原始文本及對應標注文件。PubMed Cen?ter 是生物醫學領域開放獲取出版物的優質來源,覆蓋率高, 且已被Du C等[26] 和Duck G 等[27] 多位學者用作軟件提及黃金標準數據集構建和軟件使用研究的語料來源。相較其他軟件公開數據集, So?MeSci 對軟件實體的標注更為細致, 在對軟件實體類別進行細分的同時還對軟件使用類型進行劃分,并對軟件的版本、發布時間、開發者等相關信息加以標注。前人研究[28] 表明, 大部分軟件實體出現在學術文章的方法部分, 因此, 本研究選擇SoMeSci數據集中學術論文方法部分的數據(包括480 篇方法部分原始文本數據及其對應標注數據)作為正例補充。為擴展語料庫的適用范圍, 本研究還選擇PLOS ONE 期刊刊載的學術論文作為新增語料來源,使用自編Python 程序抽取章節名包含“Method”的段落文本構建樣本庫PLoSSo, 該樣本庫包括6 114篇論文, 12 280個段落, 64 577個句子。選擇PLOS ONE 作為新增語料來源, 一方面是因為PLOS ONE 是開放獲取期刊且其刊載了數量可觀的生物學、醫學、計算機科學、社會科學、工程技術等多學科學術論文, 另一方面是因為可以通過PLOS ONE 出版商提供的公共API 快速獲取適合機器處理的期刊論文全文本數據且該期刊的全文本數據已被Pan X L 等[7] 、Schindler D 等[11] 和Li K等[14] 多位學者用作軟件識別研究以及軟件黃金標準數據集構建的語料來源。
2.2數據標注
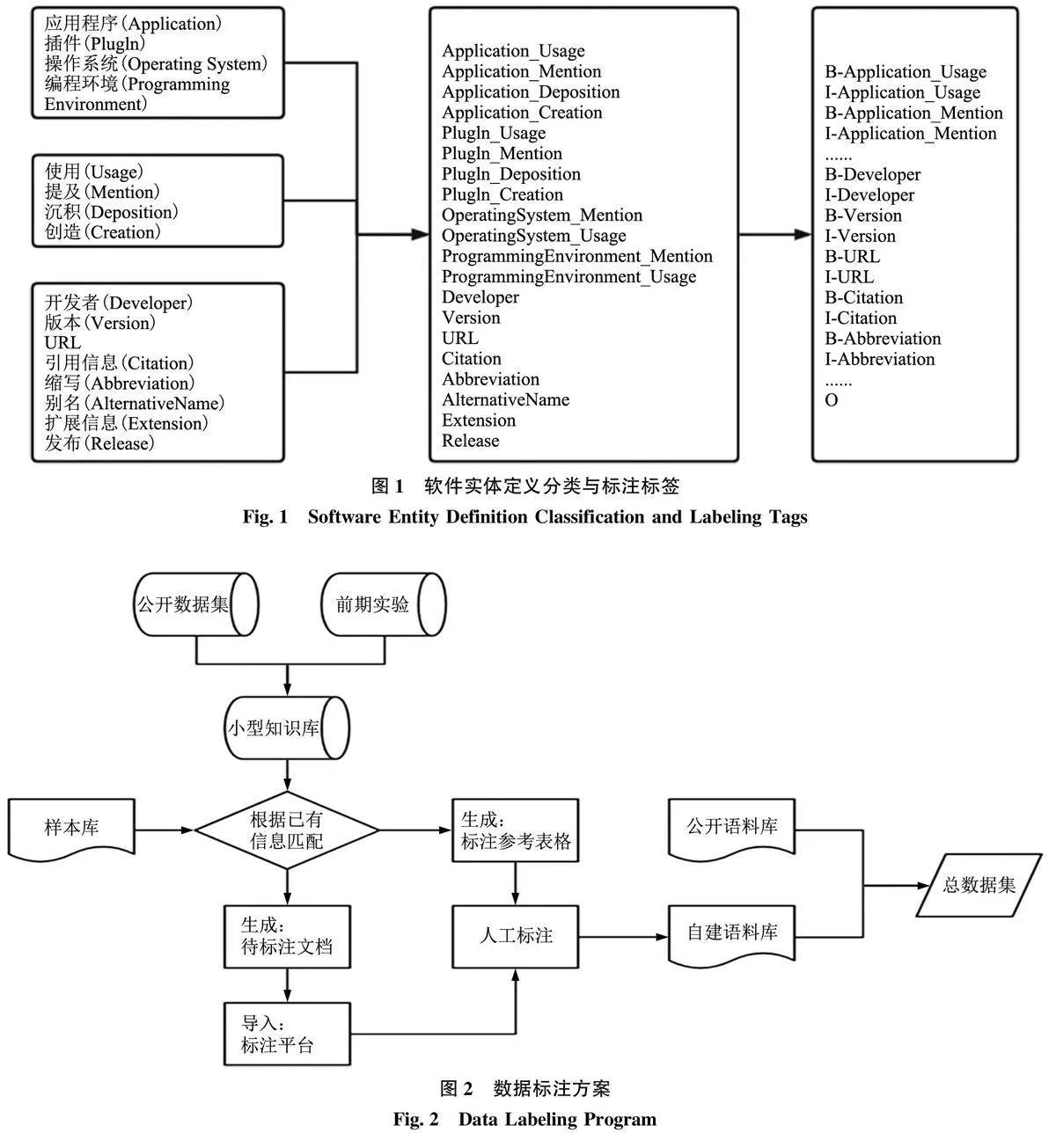
標注好的數據才能輸入到機器學習模型和深度學習模型中, 使模型理解其蘊含的語義信息[29] 。在進行數據標注前, 本研究參考Li K 等[30] 、SchindlerD 等[31] 的軟件類別劃分方法將軟件劃分為應用程序(Application)、插件(PlugIn)、操作系統(Oper?ating System)、編程環境( Programming Environ?ment)四大類別。其中, 應用程序指的是為終端用戶設計的獨立程序, 對應用程序的使用通常會產出數據或項目文件的結果, 如Excel、Stata 等, Web端的應用程序也包含在此類別中。插件指的是對于軟件的擴充, 而其本身不能單獨存在使用, 例如Ggplot2 是R 的一個繪圖擴展包, 并不能脫離于R這個平臺單獨成為一個軟件工具。操作系統是一種特殊類型的軟件, 是用來管理計算機所有硬件且執行所有軟件進程的軟件。編程環境指的是一個圍繞編程語言構建的集成環境, 用于設計程序或腳本,通常包括編譯器和解釋器, 如C 語言環境等。
除了對軟件類型加以劃分外, 本研究還參考軟件使用和提及相關研究[25,32] 將軟件提及類型劃分為使用(Usage)、提及(Mention)、沉積(Deposi?tion)、創造(Creation)四大類。其中, 使用指的是科研人員在其研究過程中所使用的軟件, 如“本研究所有分析均使用SPSS 軟件完成”。提及指的是科研人員在學術文章中提到但實際并沒有使用到當前研究中的軟件。沉積指的是科研人員在研究過程中根據自身研究需求對軟件進行的調整、優化或更新等工作。創造指的是科研人員在研究過程中產出了新的軟件, 較可能出現于提出技術創新的學術文章中。此外, 本研究還對軟件的屬性特征進行定義, 歸納出如下8 種常見的屬性特征: 開發者(De?veloper)、版本(Version)、URL、引用信息(Citation)、縮寫(Abbreviation)、別名(Alternative Name)、擴展信息(Extension)和發布(Release)。
合適的標注工具能夠幫助標注人員更加便捷、快速地完成相應的語料文本標注任務。因此, 本研究在進行數據標注前對常用的標注工具進行比較分析, 據此選擇能夠滿足本研究的標注需求、易用且操作體驗較好的Markup 在線標注平臺(https://get?markup.com/)作為標注工具。
在標注模式方面, 本研究使用命名實體識別領域常用的BIO 標注法。BIO標注法是CoNLL-2003采用的標注法, 其中B 表示Begin, I 表示Inside,O表示Outside。以“Tom Hanks is My Name” 為例,Tom 的標注即為B -PER, Hanks 的標注即為IPER,其他3 個詞由于與所要提取的實體無關, 因此皆標注為O。將BIO 標注法與上述標注類型定義相結合共產生41 個標簽, 如圖1 所示。其中, 應用程序和插件分別對應4 種提及類型, 即Applica?tion_Usage、Application_Mention、Application_Depo?sition、Application_Creation、PlugIn_Usage、PlugIn_Mention、PlugIn_Deposition 和PlugIn_Creation, 而操作系統和編程環境在實際情況中較少會出現沉積以及創造類型, 因而對其設定兩種提及類型, 即OperatingSystem_ Mention、OperatingSystem _ Usage、ProgrammingEnvironment_ Mention、ProgrammingEn?vironment_Usage。
為節省標注人力和標注時間, 本研究設計了一種基于小型知識庫的程序輔助標注方案, 如圖2 所示。需要說明的是, 該標注方案中的知識庫概念并非目前學術界廣泛使用的知識庫概念, 而是采用了狹義的知識庫定義, 即一個知識合集[33],后續可隨著標注語料的不斷擴充對知識進行增補。本研究首先對軟件實體識別領域的公開數據集以及前期相關實驗產生的數據集進行收集, 并編寫程序對已標注的軟件實體及其相關信息進行合并去重; 其次,將相應實體與參考標注類型進行關聯, 形成“詳例—類型” 列表, 并對其中的軟件實體進行篩選生成“名稱—類型” 的標注知識(如ViewPoint—Application_Usage)。對屬于多個類型的軟件實體進行標注時, 優先考慮選擇標注頻次最高的類型。經過上述處理, 一共獲得865個消歧后的軟件實體名稱, 1 364個包含開發者等信息的標注參考數據和621個聚焦于軟件“名稱—類型” 標注參考數據。
在標注方案的主流程部分, 本研究首先使用自編Python程序將所選的樣本庫與上述所建小型知識庫中的信息加以匹配, 同時生成待標注文檔和標注參考表格供后續使用,如圖2 所示。然后, 將待標注文檔導入Markup在線標注平臺, 并依據上一步驟得到的標注參考表格對待標注文檔進行人工標注。按此標注流程對上述基于PLOS ONE期刊學術論文自建的樣本庫PLoSSo 進行標注, 共得到3634個實體。需要指出的是, 為控制標注質量, 先由一名擁有軟件標注經驗的老師擬定軟件實體標注規范, 再由一名情報學專業三年級碩士研究生對語料進行先后兩輪的標注, 隨后由老師和碩士研究生對兩輪標注結果中不一致的地方進行討論決定一致標注結果。最后, 將處理后的SoMeSci 標注結果與PLoSSo 的標注結果進行合并, 形成最終實驗所用的黃金標準數據集。實驗數據集共包括6 773個實體, 各類別實體數量分布情況如表1 所示, 學術論文對應用程序、插件、操作系統、編程環境4 種類型軟件的提及和使用存在明顯差別。應用程序在學術論文中得到了更多的提及和使用, 兩個數據集共標注“Ap?plication”類型的軟件實體2472個(占實體總數的36.50%),其中“Application_Usage” 類型實體個數最多(2 359個),“Application_Mention”類型實體個數次之(97 個), 而“Application_Creation”和“Application_Deposition” 類型實體則相對較少(共16 個)。較之應用程序, 學術論文對其他三類軟件的提及和使用較少。其中, 編程環境類軟件實體有463個, 插件類軟件實體有428 個, 操作系統類軟件實體有81 個。編程環境和插件類軟件實體數量相當可能是因為作者提及具體插件的同時通常也會提及其所在編程環境, 例如R 和“lme4”常在同一句話中出現。此外, 作者更傾向于提及軟件的版本(1 250個, 占比36.30%) 和開發者(888個,25.78%)信息,而較少提及其URL、發布等其他相關信息。
2.3基于SciBERT-BiLSTM-CRF-wordMixup的軟件實體識別模型
通過對已有軟件實體識別相關研究進行調研發現, 現有基于深度學習的軟件實體識別研究的實驗框架主要包括CRF、BiLSTM-CRF、BERT-CRF、Sci?BERT-CRF 4 種組合類型[9,11,14,27,34] , 涉及LSTM、CRF、BERT 3 種基礎模型。其中, LSTM 模型, 又稱長短期記憶網絡(Long Short-Term Memory)模型,是一種特殊的循環神經網絡(Recurrent Neural Net?works, RNN)模型。LSTM 模型在RNN 模型的基礎上加入遺忘門、輸入門以及輸出門來控制信息的遺忘、保存以及輸出[35] 。然而,單向的LSTM 模型只能考慮到先前的輸入信息對當前內容的影響, 但文本序列中, 一個詞語的出現可能與上下文信息都密切相關。因此, 為了包含下文信息的影響, 在網絡結構中再加入一層LSTM 構成雙向長短期記憶網絡(Bidirectional Long Short-Term Memory Network,BiLSTM)。BiLSTM 由負責從前往后掃描上文信息的向前LSTM 層和負責從后往前掃描下文信息的后向LSTM 層組成, 最后以向前LSTM 層與后向LSTM 層的輸出結合計算得到最終的輸出結果[36] 。考慮到本研究是基于詞的軟件實體自動識別, 在模型訓練中需要同時考慮當前詞的上下文信息, 因此, 本研究選擇BiLSTM 模型而非LSTM 模型, 以提高軟件實體識別的準確性。CRF 模型, 又稱條件隨機場(Conditional Random Fields)模型, 是由Lafferty J D等[37] 于2001 年提出的一個通過建立概率模型獲取和標記序列數據的模型, 其通過將所有特征進行全局歸一化來得到全局最優解, 能夠較好地解決標記偏置等問題[37-38] 。雖然BiLSTM 能夠學習到當前詞的上下文信息, 但不會考慮前后輸出結果之間的關系, 這可能導致預測錯誤。鑒于此, 一些學者在BiLSTM 的輸出層后再加入一層CRF 結構(即BiL?STM-CRF模型)來獲取前后輸出結果之間的關系,以確保最終預測結果是有效的、符合邏輯的, 從而提高預測序列的準確度[10] 。BERT 是由谷歌AI 團隊于2018 年發布的以Transformer 雙向編碼器表示的一種新的語言表征模型, 該模型可以獲取語境化的詞向量, 在包括命名實體識別在內的多項自然語言處理任務上表現優異[39] 。近年來, 一些學者將BERT 與BiLSTM-CRF 相結合形成混合模型BERTBiLSTM-CRF 以提升命名實體識別性能[40-42] 。
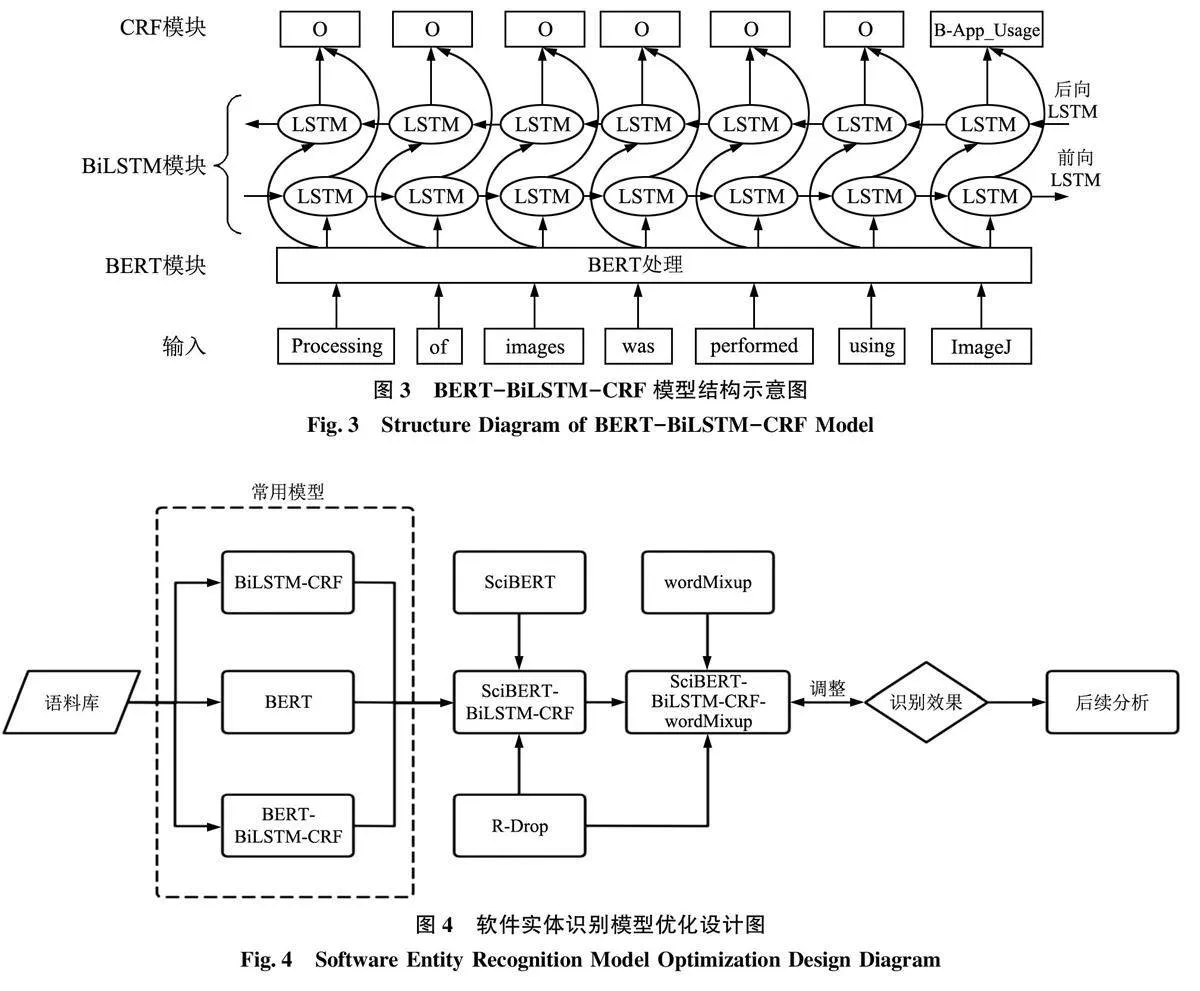
綜合考慮上述模型的優缺點以及相關命名實體識別的實驗結果, 本研究選擇在命名實體識別任務上表現較好的BiLSTM-CRF 模型作為基線, 然后引入BERT 預訓練語言模型。為了更好地對比模型識別效果, 分別進行單獨的BERT 訓練以及將BERT加入基線模型的BERT-BiLSTM-CRF模型訓練。本文使用的BERT-BiLSTM-CRF 模型包括3 個模塊, 總體結構如圖3所示。首先, 利用BERT 預訓練語言模型將原始輸入文本轉換為相應的詞向量;然后, 將得到的詞向量輸入到BiLSTM 中以進一步提取輸入文本的上下文特征; 最后, 使用CRF模塊對BiLSTM 模塊的輸出結果進行解碼并輸出具有最高概率的標注序列。
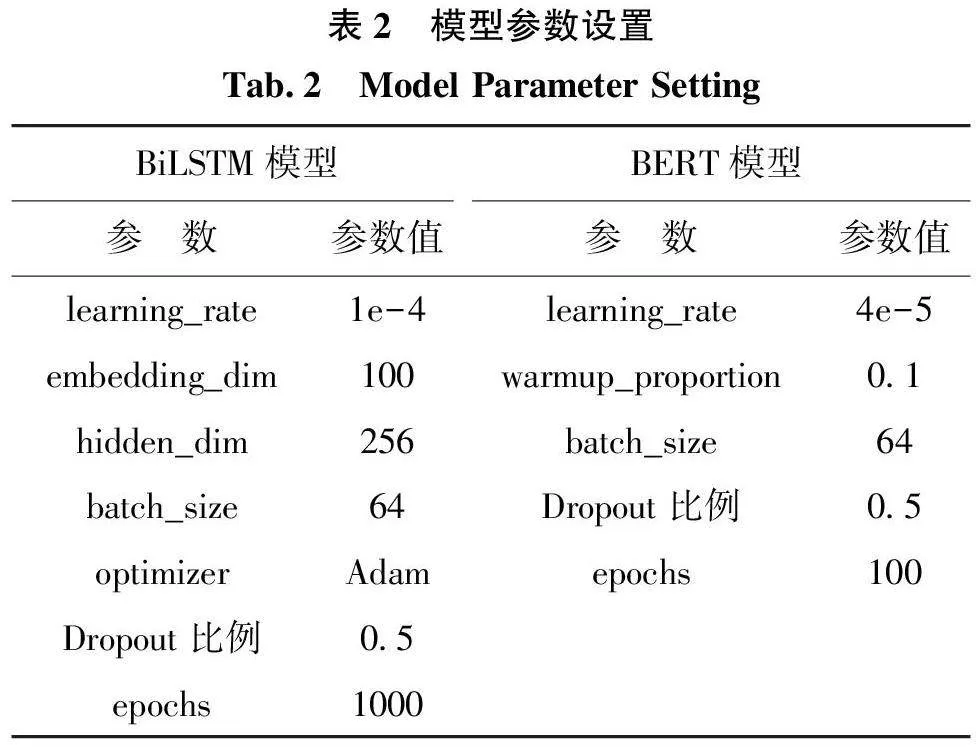
本研究在BERT-BiLSTM-CRF模型框架基礎上進行優化, 主要包括數據層面以及模型層面兩方面的優化工作, 具體優化設計如圖4 所示。本研究在數據層面分別使用BERT 和SciBERT 詞向量訓練模型獲取模型輸入數據的特征表示, 再依據識別實驗結果擇優選擇。之所以分別嘗試BERT 和SciB?ERT,是因為考慮到SciBERT是Beltagy I 等[43] 于2019 年提出的用于尋找與新冠肺炎相關文章的算法模型, 該模型是由醫學以及計算機科學領域共計114 萬篇學術文章預訓練而來, 可能更適用于本研究的自然語言處理任務。
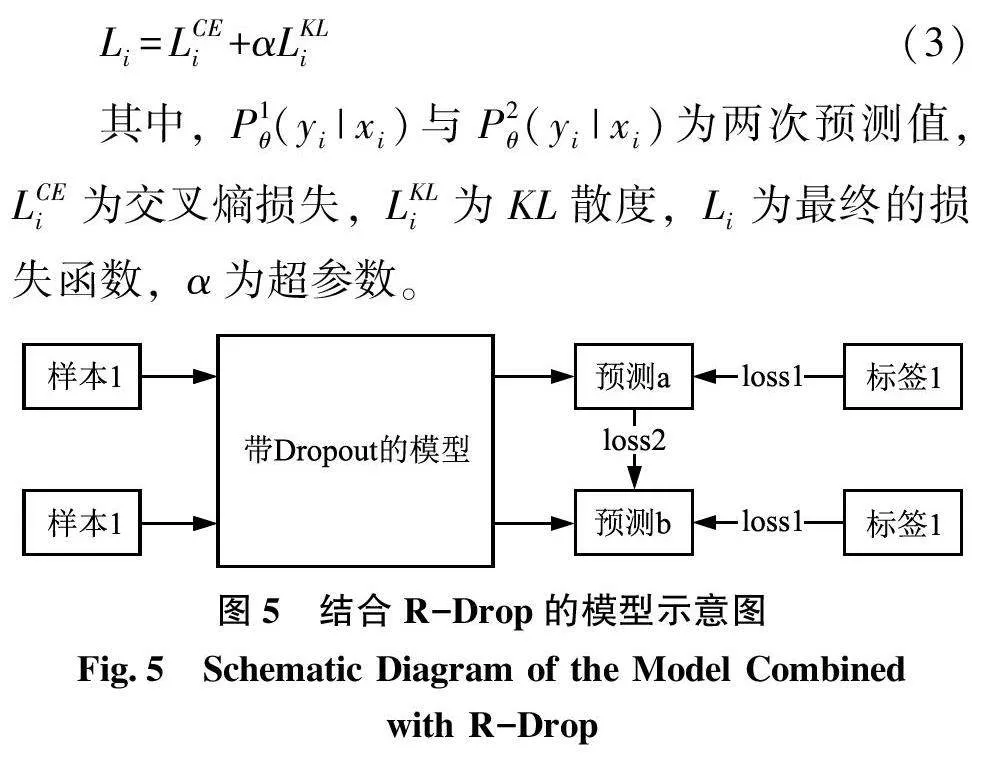
考慮到本研究的訓練數據規模較小, 神經網絡模型在此情況下可能會出現過擬合的問題, 在數據層面引入R-Drop 以防止模型過擬合, 增強模型魯棒性和泛化性。R-Drop[44] 將Dropout兩次的想法應用在有監督文本分類任務上, 在常規交叉熵的基礎上加上一項強化模型魯棒性的正則項, 用以彌補Dropout帶來的訓練模型以及測試模型的不一致性。結合R-Drop的模型如圖5 所示, 每個訓練樣本會經過兩次向前傳播, 從而得到兩次預測輸出。具體計算公式如式(1) ~(3) 所示:
此外, 為解決數據匱乏的問題, 在模型層面引入Mixup[45] 進行數據增強。之所以不選擇常用的EDA(Easy Data Augmentation)作為本研究的數據增強方法, 是因為EDA 包含的同義詞替換、隨機插入、隨機交換、隨機刪除4 種操作都有可能破壞命名實體的合法性, 從而使得數據集出現謬誤[46] , 這導致其不適用于命名實體識別任務。而Mixup 是從計算機視覺領域引入的一種數據增強方法。Guo HY 等[47] 將Mixup 引入到NLP 領域, 提出了將Mix?up 應用于句子分類任務的兩種策略, 一種是基于句子的senMixup, 一種是基于詞的wordMixup。由于命名實體識別任務需要對每個單詞進行分類, 本研究選擇基于詞的wordMixup。
3實驗
3.1實驗設定
本研究以Google Research 團隊開發的Colabo?ratory(https://colab.research.google.com/ , 簡稱Co?lab)為實驗環境。Colab 是一種托管式Jupyter 筆記本服務, 用戶可以通過Colab 使用免費的GPU 等計算資源, 減少了很多環境配置問題。本研究各項實驗均在Python 3.8.5 環境下編寫運行。數據處理部分主要涉及Pandas、Numpy、Stanza 等軟件庫, 其中, Stanza ( v1.4.2, https://stanfordnlp. github. io/stanza/ installation_usage.html)是斯坦福大學自然語言處理組開發的一個純Python 版本的深度學習NLP 工具包, 被用來對本研究的學術論文文本數據進行分詞處理。神經網絡模型部分采用Facebook人工智能研究院開發的開源軟件庫PyTorch 框架實現。相較于被廣泛使用的Tensorflow 框架, PyTorch是更Python 化的框架, 具有內置的動態DAG, 可以隨時定義、隨時更改、隨時執行節點, 相當靈活且易用性好, 還在代碼理解等方面表現優異。
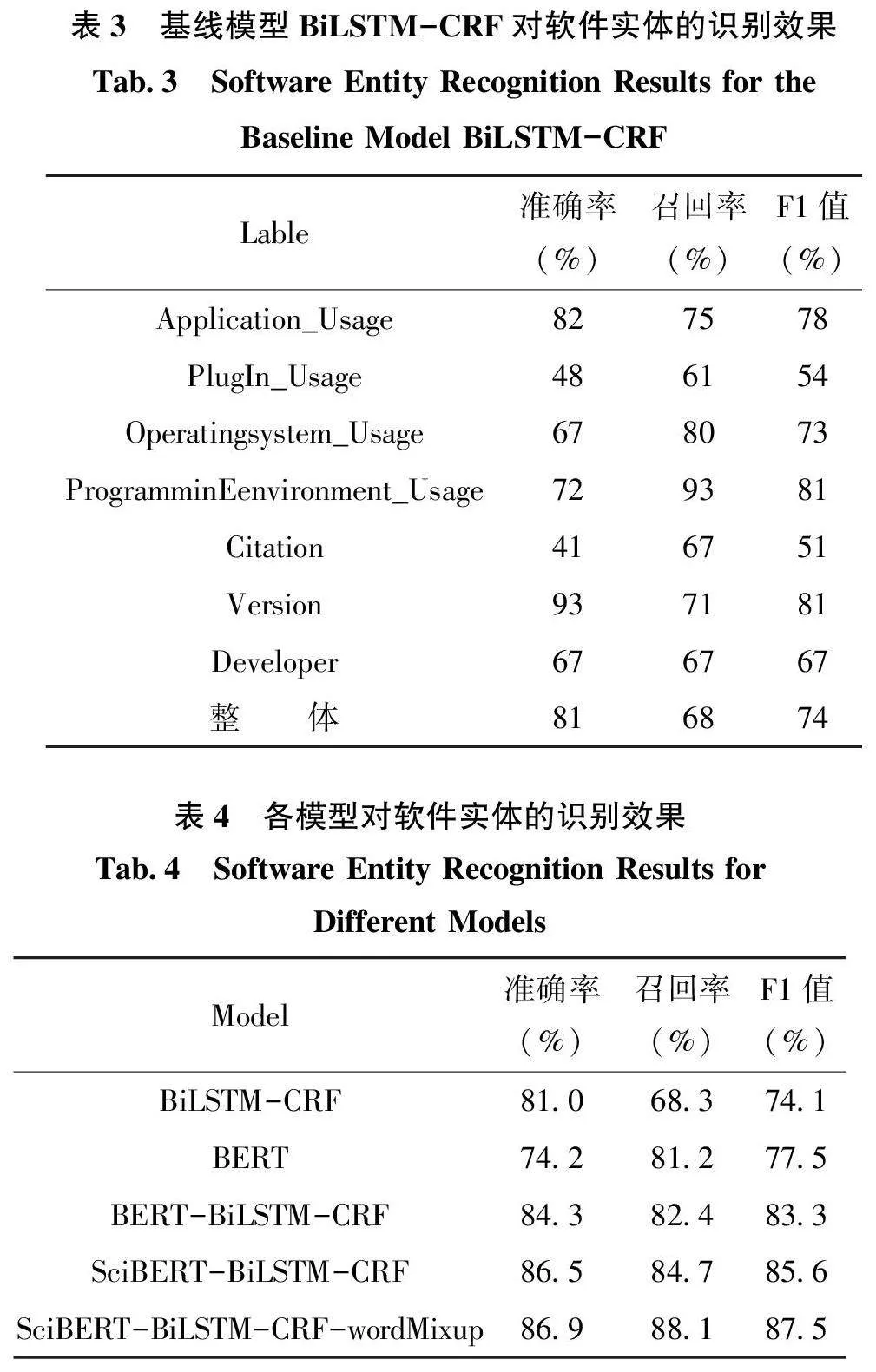
本實驗中的BiLSTM 模型和BERT 模型的關鍵參數設置如表2 所示。其中, BiLSTM 模型的關鍵參數設置如下: 學習率(learning_rate)設為1e-4,詞向量維度(embedding_dim)設為100, 編碼層隱藏層大小(hidden_dim)設為256,單次訓練樣本數(batch_size) 為64, 優化器(optimizer) 為Adam,Dropout 比例設為0. 5, 訓練迭代次數(epochs)設為1000。BERT 模型的關鍵參數設置如下: 學習率(learning_rate)設為4e-5, 預熱學習率(warmup_proportion)設為0.1, 單次訓練樣本數(batch_size)為64,Dropout 比例設為0. 5, 訓練迭代次數(ep?ochs)設為100。此外, 本實驗將數據集按照0.70∶0.15∶0.15的比例劃分為訓練集、測試集和驗證集。進行3次實驗, 最后取3 次實驗結果的均值作為最終的實驗結果。
3.2實驗評估指標
本研究選擇通用的命名實體識別評價指標, 即準確率P、召回率R 和調和平均數F1 值對模型的識別效果進行評估。準確率指標用來評估模型識別結果的準確程度, 召回率指標用來評估模型將正例正確識別的能力, F1 值用來評估模型的綜合性能,是對模型準確率和召回率進行綜合評價的指標。3個評價指標的計算公式如式(4) ~(6) 所示:
其中, T表示模型正確識別的實體數量, F表示模型識別錯誤的實體數量, F 表示模型沒有檢測到的相關實體的個數。
3.3實驗結果分析
軟件命名實體識別結果如表3 和表4 所示。表3列出了基線模型BiLSTM-CRF 在實驗數據集上的軟件實體識別結果。從表3 可以看出, BiLSTM-CRF模型的整體F1 值為74%, 略低于Schindler D 等[11]基于SoMeSci 數據集的F1 值(76%)。這可能與本研究的軟件類別細化程度更高有關, Schindler D 等[11]的研究是對軟件整體進行識別, 而本研究是對軟件各細分類別進行識別。從表3 還可以看出, 不同標簽的識別效果具有較大差別。例如, “Citation” 的F1 值最低, 僅有51%, 而“Version” 和“Program?mingEnvironment_Usage” 的F1 值高達81%。此外,通過實驗發現, 樣本量很少的類別(如“Applica?tion_Creation” 等)容易出現無法識別出實體和結果較為振蕩的問題。
表4顯示了基于多種模型的軟件實體識別結果。從表4 可以看出, 相較于基線模型BiLSTMCRF,單純使用BERT 預訓練模型所得的模型準確率偏低(74.2%), 但在召回率上得到了較大幅度的提升, 整體F1 值提升了3.4%, 這說明BERT 預訓練語言模型比傳統的word2vec 能更好地表示訓練語料詞匯的語義信息。將BERT 與BiLSTM-CRF 結合之后的模型BERT-BiLSTM-CRF 對軟件實體的識別效果比單獨使用BiLSTM-CRF 或BERT 有較大提升, 準確率和召回率均達到了80%以上, 整體F1 值提升超過5%。而將SciBERT 預訓練語言模型和R-Drop引入基線模型得到的SciBERT-BiLSTMCRF模型的識別性能獲得進一步提高, 各項評價指標均提升了1~2 個百分點, 說明在本研究的軟件實體識別任務中, SciBERT 和R-Drop 的結合使用能夠進一步優化識別效果。SciBERT-BiLSTMCRF模型引入wordMixup 后的改進模型的識別性能得到進一步提升, 改進模型SciBERT-BiLSTM -CRF-wordMixup 的整體F1 值達到87.5%, 說明數據匱乏問題對軟件實體識別任務有較大影響, 在模型訓練時有必要進行數據增強處理。
本研究將改進模型SciBERT-BiLSTM-CRFwordMixup在測試集上的識別結果與人工標注結果進行對比分析發現, 該模型在識別軟件實體方面還存在一些不足: ①召回結果存在偏差, 包括召回信息不完全和召回多余信息等情況。例如, 在“AllStatistical Analyses Were Conducted Using SPSS22. ”中, 該模型將“SPSS22” 識別為軟件實體, 但實際上“SPSS” 為軟件實體, “22” 為版本信息, 由于模型將“SPSS22” 整體識別為軟件實體, 導致識別結果中的軟件版本信息遺漏。或者, 模型將“Frequencies and Percentages Were Calculated UsingMicrosoft Excel Version 14.6.8” 中的“ MicrosoftExcel” 識別為軟件實體, 但實際上該句中的“Ex?cel” 為軟件實體, “Microsoft” 為開發商信息, 模型錯誤地將軟件開發商信息也抽取進軟件實體, 這會給后續的軟件實體消歧合并帶來困難; ②識別錯誤, 主要涉及將硬件、操作設備、研究方法等實體錯誤識別為軟件實體。例如, 模型將“For MultipleGroup Comparisons, We Used One-way ANOVA Fol?lowed by t Tests with Bonferroni Corrections” 中的“One-way ANOVA” 識別為軟件實體, 但實際上One-way ANOVA 是一種統計分析方法。針對上述發現的不足, 未來可以通過增加更多的標注樣本和增加負反饋機制來提升識別效果。
4結論
本研究聚焦在科學研究中發揮著重要作用的軟件實體, 構建了軟件黃金標準語料庫并提出改進的軟件實體自動識別模型SciBERT-BiLSTM-CRFwordMixup。在黃金標準語料庫構建部分, 本研究先對軟件實體、軟件使用類型實體、軟件相關信息實體加以細化定義, 并按照BIO標注法生成41個實體標簽, 接著設計一種基于小型知識庫的程序輔助標注方案幫助人工快速標注語料, 最終基于PLOSONE 期刊論文文本構建出共包含6 773個實體的軟件黃金標準語料庫。該語料庫可以為后續軟件識別實驗所使用。在軟件實體識別模型優化部分, 本研究將目前廣泛應用于實體識別領域的BiLSTM-CRF模型作為基線模型, 測試其在本研究語料庫上的識別效果。接著對BiLSTM-CRF 基線模型加以優化改進, 分別引入目前通用命名實體識別領域流行的BERT 模型和針對科學論文文本訓練出的SciBERT模型來代替Word2vec 作為詞向量訓練模型。然后,在數據層面引入R-Drop 以增強模型的魯棒性和泛化性, 在模型層面引入Mixup 進行數據增強。實驗結果表明, 在BiLSTM-CRF、BERT、BERT-BiL?STM-CRF、SciBERT-BiLSTM-CRF 和SciBERT -BiLSTM- CRF- wordMixu 5種模型中, SciBERT -BiLSTM-CRF-wordMixu模型在本研究語料庫上的識別表現最好, 其整體F1 值達到87.5%。這說明,本研究提出的改進模型SciBERT-BiLSTM-CRF-wordMixup 能夠有效地從學術論文文本中識別出軟件及其相關信息實體。
本研究還存在一些不足之處。首先, 本研究僅以PLOS ONE 期刊論文作為實驗語料數據, 數據集較小, 未來研究將擴大數據集并在PLOS ONE 期刊論文以外的數據集上開展軟件實體識別, 以提升模型的泛化能力; 其次, 本研究提出的改進模型的軟件實體識別性能尚有提升空間, 未來將考慮在改進模型中引入注意力機制來提高模型的軟件實體識別性能。
