基于表示學習的圖書館專利信息語義融合模型研究
2024-10-29 00:00:00陳隆葵
圖書館學刊 2024年9期
[摘 要]在對表示學習、圖書館專利信息、圖書館專利信息語義融合、基于表示學習的圖書館專利信息語義融合相關研究進行概述的基礎上,分析表示學習在圖書館專利信息語義融合中的優勢,通過對圖書館專利信息語義實體描述,從專利實體類、機構類、人員類、事件類、內容類及各類的核心屬性5個維度構建了基于表示學習的圖書館專利信息語義融合模型,旨在促進圖書館為用戶提供專業的專利信息語義檢索服務。
[關鍵詞]表示學習 圖書館專利信息 語義融合模型
[分類號]G205
表示學習(Representation learning)是人工智能學科與圖情專業研究的新熱點,作為圖情信息數據實現語義檢索和智慧學習的新技術、新方法,其主要功能是將復雜信息數據中的語義實體、核心屬性與關系表示到低維向量空間,通過向量空間的語義測量工具測試語義實體間的距離,由智能系統學習語義實體的分布式表示狀態,從而實現知識數據的深層次關聯和序列化表示,并借助語義結構可視化圖譜進行可視化顯示,進而為用戶提供專業的智慧語義檢索服務。美國科學數據研究中心(Center for Scientific Data Research of America,CSDRA)是國外較早開展表示學習的科學專利數據語義融合機構,在實現跨學科、跨機構的科學專利數據語義融合中采用表示學習技術已取得初步成效[1]。而國內圖書館專利信息語義融合領域對表示學習的實踐應用尚處于空白,針對基于表示學習的專利信息語義融合模型構建更為少見。因此,筆者在剖析表示學習、圖書館專利信息及表示學習在圖書館專利信息語義融合模型相關研究的基礎上,通過對圖書館專利信息進行語義描述、構建語義實體及核心屬性的方式設計了圖書館專利信息語義融合模型,為圖書館提供專業專利信息語義檢索服務提供參考和借鑒。
1 相關研究概述
1.1 表示學習的內涵
表示學習在人工智能領域也稱為“學習表示”,主要被應用在機器學習和深度學習領域,“表示”是指通過模型參數、應用何種形式、何種方式表示模型輸入的觀測樣本X[2]。表示學習是指智能系統或者學習模型對觀測樣本X的有效表示[3]。簡單而言,表示學習是通過機器訓練獲取深度學習特征的技術集合,是將多源異構化數據轉變為能被機器識別、獲取、使用和學習的結構化數據的一種方式,賦予了智能系統“學習如何學習”的能力[4]。
1.2 圖書館專利信息內涵及類型
1.2.1 圖書館專利信息內涵
圖書館專利信息是指圖書館以專利產權信息、專利資源信息、專利知識成果、專利文獻為基礎,通過分解、加工、整合、標引、統計、分析、轉化等一系列信息處理手段,并綜合應用多種信息處理方式構建形成與專利技術、專利文獻及專利知識成果有關的各種信息集合[5]。圖書館面向用戶提供專利信息服務,包括專利查新、專利檢索、專利信息使用現狀分析、專利資源分布統計、專項知識產權分析、企業專利應用現狀分析、特殊技術領域專利分析、專利技術成果分析與預警服務等[6]。
1.2.2 圖書館專利信息類型
圖書館專利信息按照內容、來源可以劃分為技術信息、法律信息、經濟信息、著錄信息和戰略信息。(1)技術信息是指在實用新型專利、外觀設計專利、發明專利的專利說明書、權利要求書、圖表、摘要、介紹等專利文獻中闡述的與技術有關的信息,或是通過專利文獻檢索匯總形成專利報告及其他文獻提供與專利有關的技術信息。(2)法律信息是指在專利的權利要求書、專利公報及登記簿等專利文獻中記載的與權利保護及有效性相關的信息。(3)經濟信息是指在專利文獻中記錄與行業、組織和政府經濟活動具有密切聯系的信息。(4)著錄信息是指和專利文獻中著錄項目高度關聯的信息,如專利權人信息、發明人信息、專利申請號、國別信息等。(5)戰略信息是指通過對上述技術信息、法律信息、經濟信息、著錄信息進行聚合、分析、加工形成的具有戰略特征的技術信息或經濟信息。如通過對專利文獻信息整合加工形成的技術評估報告、戰略決策報告等。
1.3 圖書館專利信息語義融合相關研究
圖書館專利信息語義融合的相關研究源于1990年后人工智能領域自然語言處理技術的發展。隨著近年來科學數據開放運動(Scientific data open movement)的發展,一些科技大國在圖書館專利信息語義描述、語義關聯等方面研究進展加快,并涌現出一批有代表性的研究成果,主要集中在以下兩個方面。
(1)圖書館專利信息語義模型的研究。基于用戶專利信息使用需求構建實現精準檢索、大數據分析和精準推薦的專利信息語義融合模型是實現圖書館專利信息語義融合的基礎。國外相關研究成果主要借助專利信息元數據語義描述、本體構建、RDF Schema集成模型等語義技術,通過對圖書館專利信息對象的關系識別、關系屬性描述、情境關系抓取、關聯結構密封[7],實現專利信息對象、關聯關系的語義表達,為圖書館專利信息資源整合構建RDA、BIB等語義模型。
(2)圖書館專利信息語義關系的發現研究。實現圖書館專利信息的語義描述,并借助語義描述挖掘專利信息對象的語義關聯聯系,構建語義融合模型,實現專利信息語義關聯關系的發現與識別。當前,西方學者關注圖書館專利語義關聯關系算法工具與發現工具的應用,如美國專利事務局為加州大學圖書館設計了專利信息識別和發現語義相似度算法,能夠精準識別圖書館專利信息中的潛在語義關聯關系[8]。同時,歐洲“Patent data integration”項目對圖書館開放的專利數據云設計了可供用戶直接使用的語義關聯工具,用于發現不同主題專利信息的語義關聯關系[9]。
1.4 基于表示學習的圖書館專利信息語義融合研究
從當前學界的研究趨勢來看,借助知識抽取、數據挖掘、語義抽取技術促進專利信息融合是圖書館專利信息服務發展進程中要解決的核心問題。圖書館促進專利信息語義融合的根本目的是促進不同類型、學科、領域、行業的專利信息資源聚合成為主題專利信息資源集,便于用戶精準檢索并通過檢索結果進行知識發現和技術創新,進而將圖書館專利信息的價值最大程度發揮出來[10]。翟東升等認為,表示學習應用到圖書館專利信息中是將專利信息的語義信息表示成低維連續的向量,兩個專利信息對象的空間距離越近則說明其語義相似度越高[11]。楊宏章等將表示學習應用到圖書館專利信息語義聚合過程中發現,表示學習是將圖書館專利信息的實體和關系嵌入低維連續向量空間,并學習這些專利信息實體與關系的分布式表示[12]。周雷等認為,表示學習應用到圖書館專利信息語義融合過程不僅能清晰度量實體、表示實體、揭示實體與關系間的語義關聯,還能促進學習模型提高計算效率,促進異構化專利信息數據融合[13]。綜上來看,基于表示學習促進圖書館專利信息語義融合已成為圖情界學者的共識,并成為圖書館實現精準化專利信息服務的重要前提,應用表示學習技術構建科學有效的專利信息語義融合模型能推動專利信息智慧分析、深度挖掘、精準檢索,為用戶的專利決策和技術創新提供支持。
2 表示學習在圖書館專利信息語義融合中的優勢作用
表示學習作為語義信息較為有效的表示方式,將信息數據表示成兩個可直接使用與參考的低維向量,通過對兩個對象空間距離測量,測試其語義相似度。因此,表示學習借助其技術優勢可以為圖書館實現專利信息語義融合提供保障。
2.1 為圖書館專利信息語義融合提供統一標準
表示學習為信息數據存儲、管理、組織與標準化處理提供了簡單、標準的技術機制,通常借助實體(Entity)、關系(Relation)以及相關屬性信息結構化的符號表示形式描述信息資源的概念及相互關系,由知識三元組(頭實體、關系、尾實體)進行可視化表達,并將實體和關系嵌入低維連續向量空間學習它們的分布表示[14]。表示學習的基礎結構是知識圖譜,而知識圖譜具有的知識三元組為圖書館專利信息標識提供了基本方法,采用統一的標記結構標識專利信息,創建具有唯一標識且不可更改的對象名稱;表示學習中對語義信息向低維向量的轉化為圖書館專利信息提供了統一的表示模型,可以使不同結構、不同形式的專利信息在表示模型上具有一致性,借助算法工具學習它們的分布式表示形式,而無需考慮其表示形式的轉化。OWL是表示學習中常用的本體描述語言,可以準確對專利信息的語義實體及關聯關系進行描述;HTTP協議是表示學習應用的統一存取機制,是專利信息實體和關系嵌入低維向量空間的分布式表示的統一接口[15],使所有的程序訪問具有統一的標準,實現圖書館專利信息更深層次的開放獲取。用戶在進行專利信息檢索過程中,HTTP協議提供了統一的標準化訪問接口,用戶可直接通過SPARQL查詢專利信息。
2.2 促進圖書館專利信息整體融合
基于表示學習的專利信息語義網絡可以將不同來源的專利信息及其相關數據進行融合,能將多種結構、類型、形態的分散的專利信息源融合關聯,為用戶提供該項專利所有相關數據的知識圖譜,允許用戶在不同類型專利信息源檢索瀏覽,并提供不同主題的專利信息數據集供用戶參考與決策,降低了圖書館融合多源專利信息數據的復雜性。同時,基于表示學習的圖書館專利信息語義融合不僅可以融合同一主題的專利信息,還能對不同學科、不同領域的專利信息建立關聯關系,使專利發明人、專利名稱、技術領域、專利說明、專利權類型、授權號、專利發布時間、專利權利范圍、專利申請國等信息融合在一起,真正實現圖書館專利信息的整體融合。
2.3 實現圖書館專利信息語義服務
首先,表示學習可以為圖書館分布式、異構化的專利信息提供語義融合的可視化圖譜,專利產權人發布的專利信息可以通過統一的端口發布,用戶可以借助統一的操作界面登錄檢索查詢[16]。同時,用戶可通過語義檢索的方式獲取圖書館專利信息,清晰探察專利信息語義本體,更精準掌握專利信息的關聯結構。其次,圖書館應用表示學習實現專利信息語義融合還能將專利信息通過語義瀏覽和語義推薦的方式直接呈現給用戶,并對重點內容做出解釋,方便用戶理解。再次,基于表示學習的圖書館專利信息語義融合還能使專利發布者進行分布式的內容創建,語義融合模型能高效搜集發布者創建的內容,并進行統一存儲,借助知識圖譜呈現給用戶[17]。最后,圖書館基于表示學習的語義門戶網站可以為專利產權人提供專業、共享、低成本的發布渠道,并實現專利產權的快速認證和共享。
3 基于表示學習的圖書館專利信息語義融合模型構建
基于表示學習的圖書館專利信息語義融合模型重視將專利信息中的語義實體與關系表示成為低維連續向量,并對兩個鄰近對象的空間距離進行測量,探察二者語義相似度,同時學習它們的分布式表示。圖書館專利信息涉及較多的語義本體,在描述專利信息時要建立本體間的關系,將這些關系精準描述并嵌入低維向量空間,構建一個完整反映專利信息特征的語義融合模型,從而形成更完整的語義融合系統。
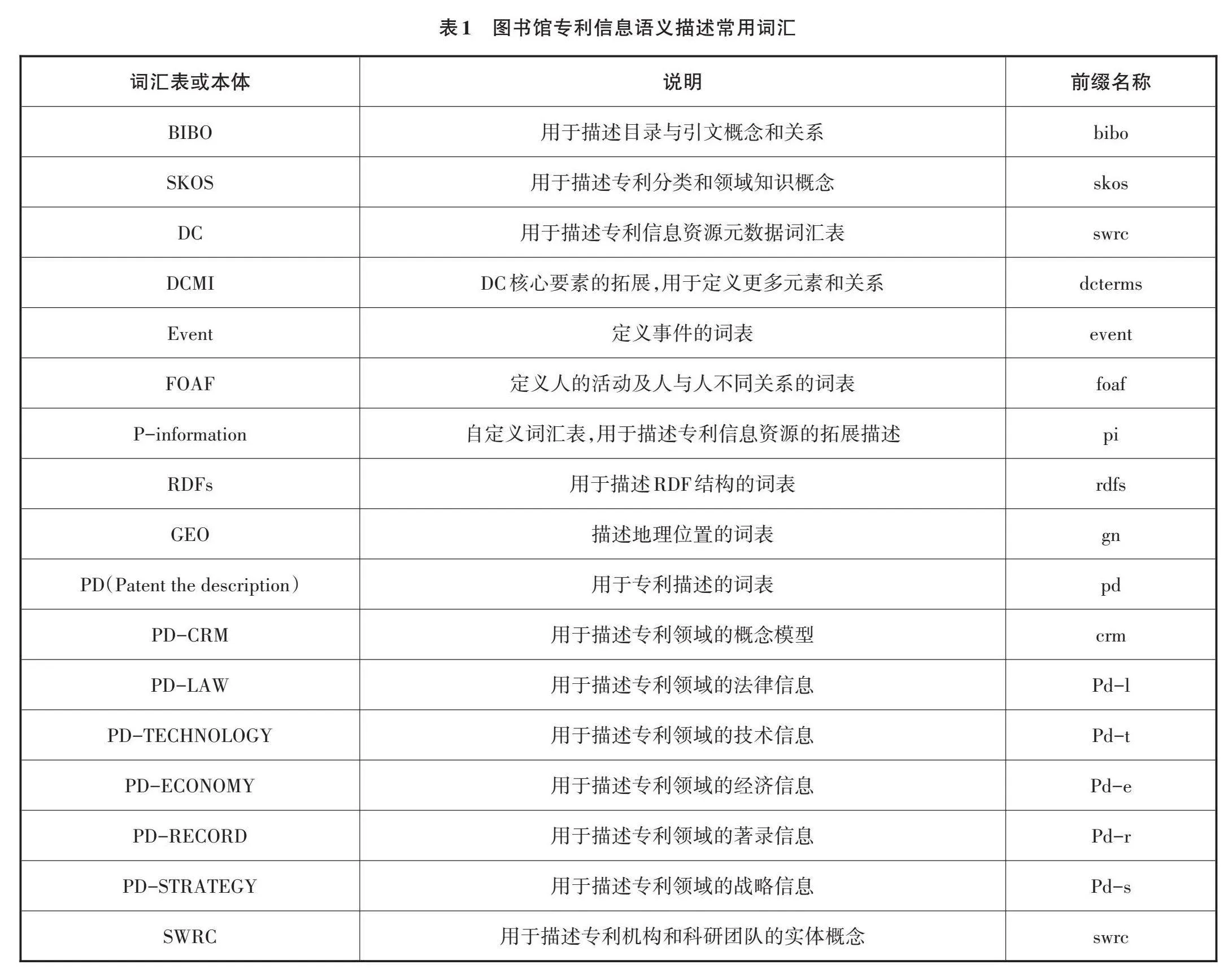
在語義融合模型構建中,可能用到的詞匯表如表1所示,其中P-information(the Patent Information)是自定義詞匯表,用來擴展現有詞匯表與本體無法滿足的圖書館專利信息詞匯。
將圖書館專利信息劃分為專利實體類(cr:Patent)、機構類(foaf:Organization)、人員類(foaf:Person)、事件類(event:Event)和內容類(pi:Patent content)。根據圖書館專利信息類別的不同,通過構建圖書館各類專利信息的屬性對應,最大程度應用詞匯表中的詞匯與本體,從而構建圖書館專利信息語義融合模型。
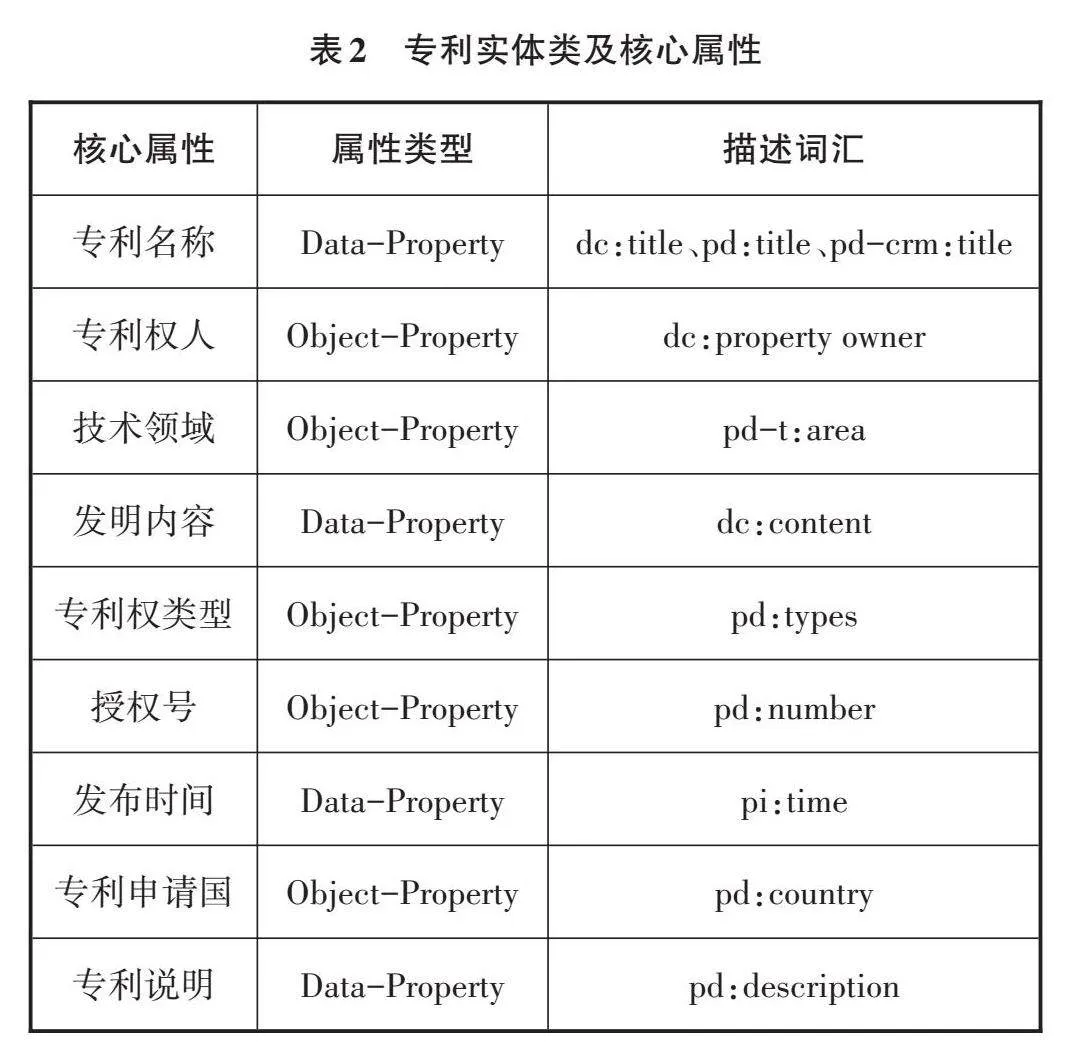
(1)專利實體類及核心屬性
專利實體是圖書館專利信息的基本構成內容,也是對專利實體特征的描述,可以建立與其他類的關聯關系。專利實體類的主要屬性包括專利名稱、專利權人、技術領域、發明內容、專利權類型、授權號、發布時間、專利申請國、專利說明9個核心屬性,如表2所示。
(2)機構類及核心屬性
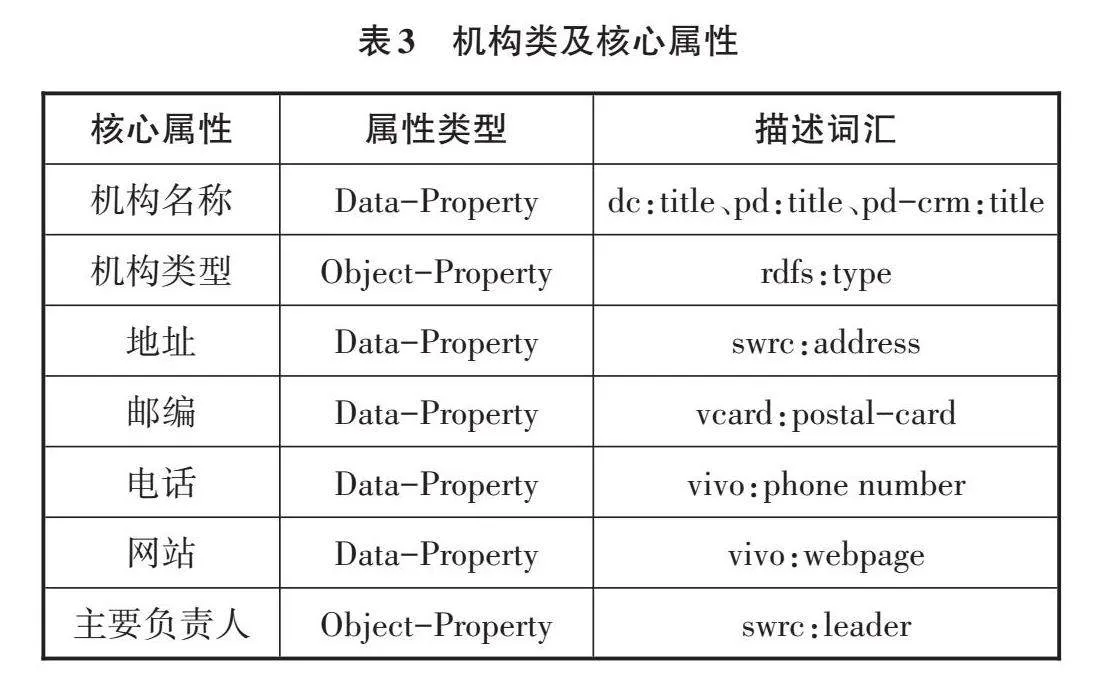
我國專利機構按照性質和類別的不同,主要分為專利代理機構、科研院所機構、科技成果轉化機構、科技企業等。根據專利來源機構名錄編制細則,專利機構的核心屬性包括機構名稱、機構類型、地址、郵編、電話、網站、主要負責人7個核心屬性,如表3所示。
(3)人員類及核心屬性
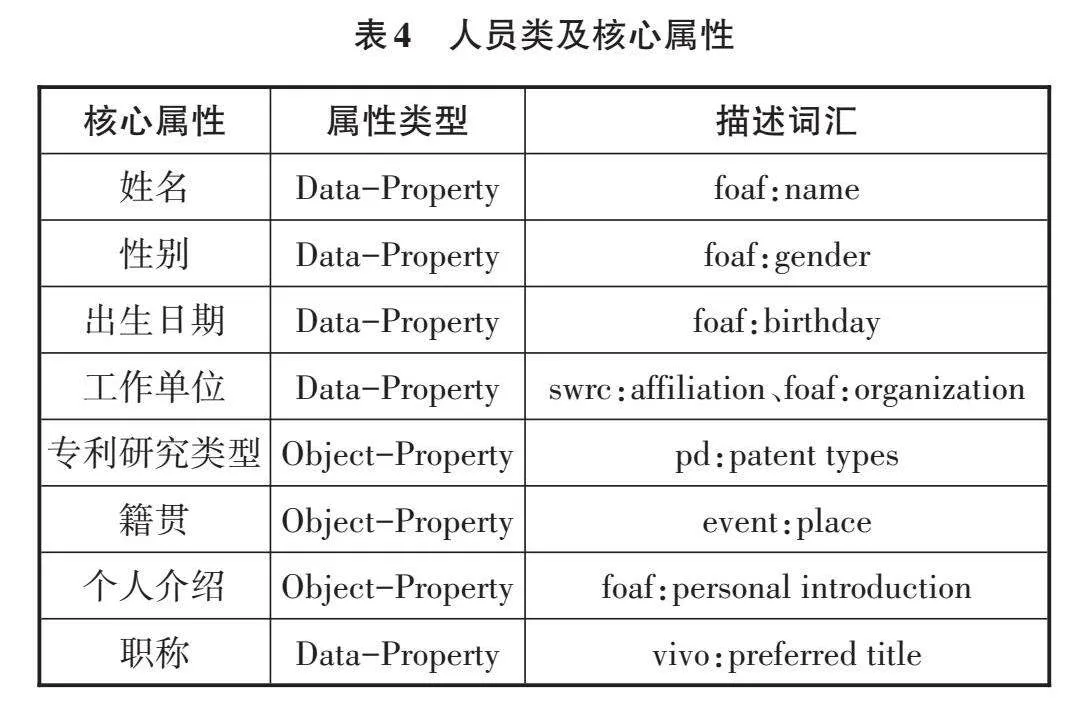
專利領域相關人員分為3類:一是專利發明者和相關專利權人、繼承者等;二是專利的研究人員、科研學者和技術專家;三是圖書館等信息機構從事專利信息領域的工作人員。這些與圖書館專利信息相關的人員包括姓名、性別、出生日期、工作單位、專利研究類型、籍貫、個人介紹、職稱8個核心屬性,如表4所示。
(4)事件類及核心屬性
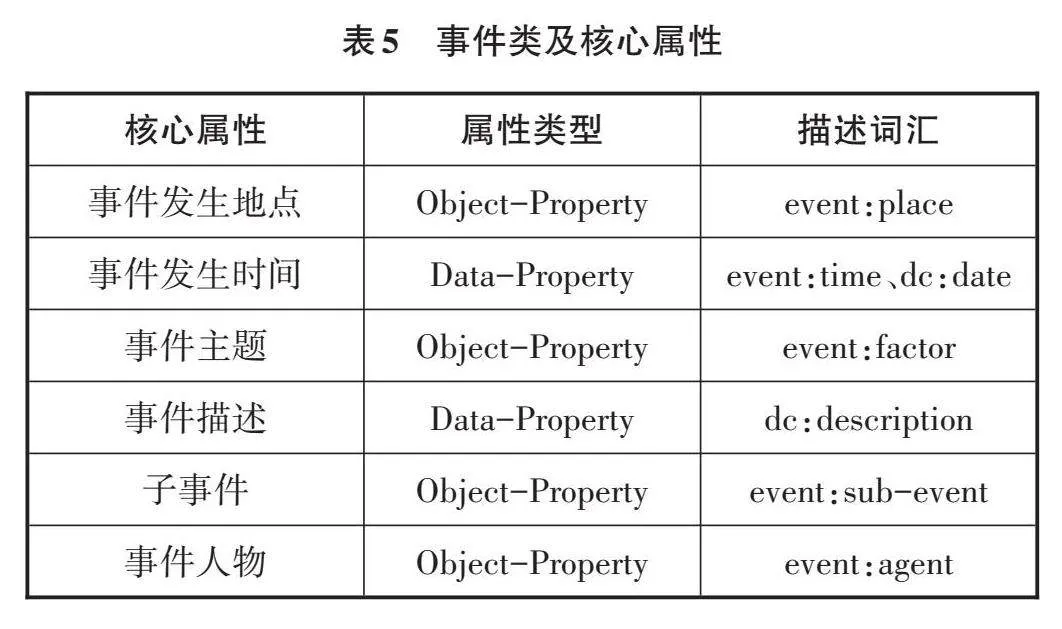
事件類是指與專利相關事件及專利使用等各種活動具有密切關聯的事件,包括事件產生地點、事件發生時間、事件主題、事件描述、子事件、事件人物6個核心屬性,如表5所示。在圖書館專利信息語義融合中可以使用event表示事件及相關屬性,表示為event:Event類。
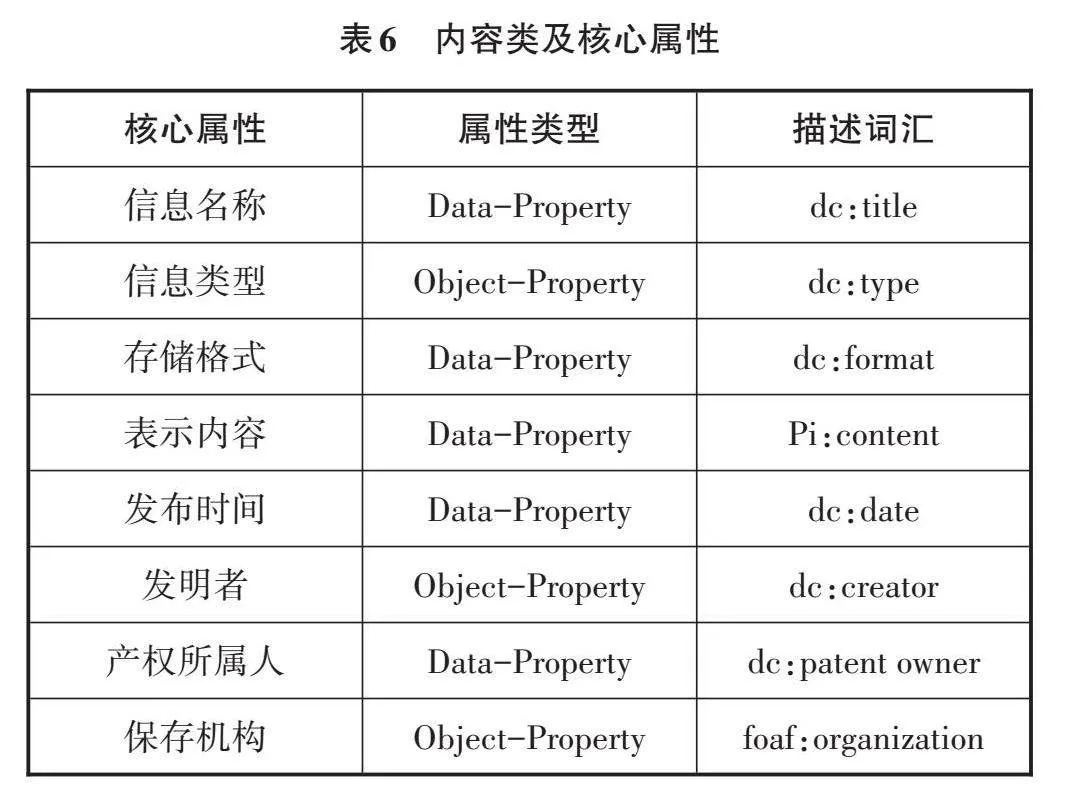
(5)內容類及其核心屬性
圖書館專利信息內容主要由技術信息、法律信息、經濟信息、著錄信息、戰略信息組成,并且每種專利信息包括文本說明、演示圖片、展示視頻、數字模型和音頻資料等。因此,每類專利信息內容的核心屬性類型可以劃分為信息名稱、信息類型、存儲格式、表示內容、發布時間、發明者、產權所屬人、保存機構8個核心屬性,通過專利信息內容屬性與專利實體進行意義融合,如表6所示。
在對圖書館專利信息類和核心屬性定義后,可以根據類與核心屬性間的關聯關系建立語義融合模型。考慮到圖書館專利信息是由技術信息、經濟信息、著錄信息、法律信息組成,則專利信息內容類還包括4個子類,分別是技術信息類(pd:Patent" Technology)、經濟信息類(pd:Patent Economy)、著錄信息類(pd:Patent Record)、法律信息類(pd:Patent law)。其中對象屬性swrc:affiliation和swrc:leader建立了機構類和人員類的語義關聯;實體屬性foaf:organization和dc:patent release建立了專利機構和專利實體間的語義關聯;實體屬性Pi:content建立了專利實體類和專利內容類間的語義關聯;核心屬性event:agent建立起事件類、人員類和機構類間的語義關聯;屬性dc:creator建立起人員類和專利實體類間的語義關聯。類間的語義關聯是建立圖書館專利信息語義融合模型的基礎。本研究所涉及的5個實體類可以通過Place地點本體、Time時間本體和Patent information信息集與這5類之外的其他類融合,通過核心屬性event:place和swrc:address和地點(Place)建立語義關聯;通過dc:Patent type與Patent information信息集建立語義關聯;通過屬性event:time、dc:time和foaf:birthday與時間Time進行語義融合,形成更為豐富的語義融合模型,并將專利信息中的語義實體與關系映射到低維向量空間進行表示,由語義測量工具測量實體間的距離,展示語義相似度。智能系統學習實體與關系的分布表示方式,形成專利信息語義檢索圖譜,為用戶提供專業的專利信息語義檢索服務,如圖1所示。
4 結語
筆者立足國內圖書館專利信息語義融合建設及檢索的現實需求,概述表示學習、圖書館專利信息類型、圖書館專利信息語義融合、表示學習應用于圖書館專利信息語義融合的相關研究,辨析表示學習應用于圖書館專利信息語義融合的優勢作用,通過對圖書館專利信息進行語義描述、構建語義實體、挖掘核心屬性的方法建立了基于表示學習的圖書館專利信息語義融合模型。在理論和技術層面初步實現了基于表示學習的較為完整的專利信息語義融合,為圖書館解決專利信息語義融合及檢索問題,實現更便捷高效的專利信息語義檢索服務提供了思路。
參考文獻:
[1] 王慧妍,于明鶴,于戈.基于深度學習的異質信息網絡表示學習方法綜述[J].計算機科學,2023(5):103-114.
[2] 李松,等.融合文本描述和層次類型的知識表示學習方法[J].浙江大學學報:工學版,2023(5):911-920.
[3] 李雅婷,等.面向視覺數據處理與分析的解耦表示學習綜述[J].中國圖象圖形學報,2023(4):903-934.
[4] 李志飛,趙月,張龑.基于表示學習的知識圖譜推理研究綜述[J].計算機科學,2023(3):94-113.
[5] 常改.“雙一流”高校圖書館專利信息服務現狀及對策[J].四川圖書館學報,2022(5):79-83.
[6] 張更平,等.高校圖書館專利信息服務能力影響因素研究[J].圖書館學研究,2022(3):41-51.
[7] Yun S,et al.Technological trend mining: identifying new technology opportunities using patent semantic analysis[J]. Information Processing and Management,2022(4):102993.
[8] Zhipeng Q,Zheng W. Technology Forecasting Based on Semantic and Citation Analysis of Patents:A Case of Robotics Domain[J]. IEEE Transactions on Engineering Management,2022(4):1216-1236.
[9] Orions Digital Systems Inc. Patent Issued for Tagonomy-A System And Method Of Semantic Web Tagging (USPTO 10146865)[J]. Information Technology Newsweekly,2018.
[10] 藺艷艷.面向專利信息處理的語義分析方法研究[D].鎮江:江蘇科技大學,2019.
[11] 翟東升,等.基于圖形數據庫的專利語義知識庫構建技術研究[J].現代圖書情報技術,2016(12):66-75.
[12] 楊宏章,付靜.利用專利文本結構化特征構建專利信息智能語義檢索系統的方法[J].情報理論與實踐,2015(4):136-138,98.
[13] 周雷,李穎,石崇德.面向技術機會發現TOD的專利信息抽取——韓國科學技術信息研究院KISTI語義服務[J].情報工程,2015(2):31-37.
[14] 梁艷琪.基于關聯數據的文物數字資源語義融合與服務研究[D].武漢:華中師范大學,2017.
[15] 王萍,黃新平.基于關聯開放數據的數字文化資源語義融合方法研究——歐洲數字圖書館案例分析[J].圖書情報工作,2016(12):29-37.
[16] 曹志鵬,潘定,潘啟亮.基于表示學習的雙層知識網絡鏈路預測[J].情報學報,2021(2):135-144.
[17] 劉菁婕.基于表示學習的跨語言相關專利推薦研究[D].南京:南京理工大學,2020.
陳隆葵 男,1973年生。本科學歷,副研究館員。研究方向:圖書館管理與服務。
(收稿日期:2023-06-26;責編:劉清揚。)
