基于語義信息和注意力機制的低光照圖像增強
2024-10-31 00:00:00李浩彬華云松
光學(xué)儀器 2024年5期








文章編號:1005-5630(2024)05-0065-10 DOI:10.3969/j.issn.1005-5630.202307230106
摘要:針對低光照條件下拍攝的圖片存在低對比度、噪聲等問題,提出了一種結(jié)合語義信息與注意力機制的低光照增強方法。首先,利用一對聯(lián)合訓(xùn)練的U-Net網(wǎng)絡(luò),通過共享特征提取器,分別得到低光照圖像的初步增強結(jié)果和語義信息分布概率圖;然后,通過注意力機制模塊把通過U-Net網(wǎng)絡(luò)得到的低光照增強特征和語義特征進行信息融合,解決低光照下圖片邊緣信息丟失和曝光不足導(dǎo)致的圖像模糊不清的問題。實驗表明,該方法在處理低光照對比度不高和曝光不均勻圖片時,可有效消除圖像偽影以及提高圖像飽和度與不同區(qū)域塊的對比度。
關(guān)鍵詞:低光照圖像增強;注意力機制;語義信息
中圖分類號:TP 311.5文獻標志碼:A
Low light image enhancement based on semantic information and attention mechanism
LI Haobin,HUA Yunsong
(School of Optical-Electrical and Computer Engineering,University of Shanghai forScience and Technology,Shanghai 200093,China)
Abstract:Aiming at the problems of low contrast and noise in low-light images,this paper proposes a low light enhancement method which combines semantic information and attention mechanism.First,a pair of jointly trained U-Net networks were used to obtain the preliminary enhancement results and the distribution probability of semantic information of low-light images by sharing feature extractors.Then,the low-light enhancement features and semantic features obtained by U-Net networks were fused through the attention mechanism module.The problem of imageeb266364daec1b2df0e0d837ca547eb4 edge information loss under low illumination and image blurring under exposure was addressed.Experiment results show that the proposed method can effectively eliminate artifacts when processing low illumination images with low contrast and uneven exposure,and improve image saturation and contrast of different regions.
Keywords:low light image enhancement;attention mechanism;semantic information
引言
針對不理想照明條件下拍攝的低光照圖片,存在能見度和對比度低,伴有大量隨機噪聲,信息傳遞不盡人意的問題,提出了低光照圖像增強技術(shù),解決低亮度、低對比度、噪聲、偽影等問題,滿足后續(xù)計算機視覺算法對圖像信息豐富度的要求。
國內(nèi)外針對低光圖像的增強算法進行了大量的相關(guān)研究,早期主要以傳統(tǒng)算法為主,如直方圖均衡算法[1-3]通過概率分布函數(shù)(probability distribution function,PDF)將原本小范圍分布的輸入灰度級映射到另一分布,使二次排列后的的灰度級分布更近似均勻分布,因此可以拉大圖像動態(tài)范圍。它的原理簡單,運行計算量小易于實現(xiàn),但輸出圖片細節(jié)丟失嚴重,且亮度分布不符合現(xiàn)實規(guī)律。小波變換方法[4],由于小波變換具有能量壓縮性,即圖像經(jīng)過小波變換后,出現(xiàn)大量數(shù)值相對較小的小波系數(shù),一般對應(yīng)著圖像中的噪聲,將這部分數(shù)值與閾值進行比較后并通過相關(guān)函數(shù)進行轉(zhuǎn)換得到新的系數(shù),從而達到圖像增強的效果。Retinex算法的思路是將圖像統(tǒng)一歸結(jié)為由亮度層L與反射層R組成,人眼感知到食物的顏色和亮度是由物體表面的反射特性決定的,而與投射到人眼的光譜特性無關(guān)。通過求解得到反射層R,而后設(shè)置更加符合人眼感官的L亮度分量,達到圖像增強的目的。如早期的單尺度Retinex(single-scale retinex,SSR)算法[5],通過高斯濾波濾出低頻照射分量,得到圖像中的高頻分量,很好地保留了原圖中的邊緣信息。從SSR算法的基礎(chǔ)上,又發(fā)展得到了多尺度帶顏色修復(fù)的Retinex(muti-scale retinex with color restoration,MSRCR)[6],其原理是將多個高斯核應(yīng)用于圖片,分配合適的權(quán)重,并加入色彩恢復(fù)因子來調(diào)節(jié)由于增強過程中帶來的顏色失真問題。總之,傳統(tǒng)算法下的低光照增強算法普遍依賴于算法構(gòu)造與正則項的設(shè)計,因此對不同場景下的應(yīng)用,需要進行參數(shù)表達式參數(shù)的調(diào)整,消耗大量的人力。且由于算法對使用者的數(shù)學(xué)要求高,也不利于算法本身的推廣。
由于傳統(tǒng)算法的局限性以及計算機硬件的發(fā)展,基于深度學(xué)習(xí)的低光照增強算法逐漸成為了主流。2017年,Lore等[7]首次提出了基于深度學(xué)習(xí)的低光照圖像增強網(wǎng)絡(luò)LLNet(Low-Light Network),由于硬件條件限制,只能將一張圖片拆分為多個圖像塊訓(xùn)練,表現(xiàn)效果不佳;2018年,Jiang等[8]提出了基于Retinex理論的深度學(xué)習(xí)模型Retinex-Net,將低光照圖片拆分為光照層與反射層后,使用BM3D算法[9]對反射層進行去噪,并對處理結(jié)果重新合成得到最終增強效果,該模型解釋性強,因此后續(xù)涌現(xiàn)了大批基于該理論的低光照增強模型;隨后,基于不同網(wǎng)絡(luò)架構(gòu)與數(shù)據(jù)類型的低光照增強方法不斷被提出。Jiang等[8]首次將生成對抗神經(jīng)網(wǎng)絡(luò)(generative adversarial network,GAN)應(yīng)用于低光照的圖像增強,由于不是利用成對的低/正常光照圖像進行訓(xùn)練,帶來了極大的靈活性,使得模型可以適應(yīng)不同場景下的增強;Guo等[9]通過設(shè)計一系列無參考的損失函數(shù),實現(xiàn)了零次學(xué)習(xí),僅需要輸入低光照圖片即可完成訓(xùn)練,極大地減少了模型參數(shù),標志著低光照增強模型設(shè)計更加輕量化,實時性強,處理效果得到明顯改善;Jin等[10]提出了無需標定的raw圖像低光照增強。Raw圖片,即未經(jīng)過圖像信號處理的圖片,由于保留了更多的圖像細節(jié)信息,故在該類型圖片上進行低光照增強時往往有更高的視覺表現(xiàn)及性能上限。該方向中基于標定的方法占據(jù)了主流,然而相機標定過程過于復(fù)雜,且不同相機間噪聲、參數(shù)各異,導(dǎo)致降噪網(wǎng)絡(luò)僅能適用于特定相機。為了解決該問題,Jin等設(shè)計了一個包含ELD中所有開源噪聲參數(shù)的空間數(shù)據(jù)集,并利用該數(shù)據(jù)集訓(xùn)練了一個U-Net網(wǎng)絡(luò),在實際標定時只需少量目標相機配對數(shù)據(jù)進行微調(diào),大大減少了標定過程的工作量,使得基于raw類型圖片的低光照增強技術(shù)可以得到更快的部署;基于Retinex理論的低光照增強方法經(jīng)常出現(xiàn)顏色嚴重失真的情況,先前的工作主要通過施加一些額外的先驗或正則化參數(shù)來解決問題,有很大的局限性。Fu等[11]提出了一種用于Retinex分解的對比學(xué)習(xí)方法和自知識提取方法,在該網(wǎng)絡(luò)中通過堆疊的transformer模塊獲得光照層分量,并引入對比學(xué)習(xí)來監(jiān)督反射層分量的估計。通過對比學(xué)習(xí)引入額外的監(jiān)督,無需增加額外的正則化參數(shù)。
如今的低光照增強深度學(xué)習(xí)模型,由于缺少圖片結(jié)構(gòu)細節(jié)信息刻畫和圖片背景信息認知,常常出現(xiàn)輪廓丟失、曝光不足的情況。為了解決以上所述問題,本文提出了一種結(jié)合語義信息與注意力機制的低光照圖像增強方法,通過兩個階段逐步由粗到細地對圖像進行恢復(fù)以及調(diào)整。
1融合語義信息與注意力機制的低光照增強
注意力機制模擬了人類對感興趣區(qū)域的注意力分配方式,能夠使模型更加集中于重要的信息。而語義信息代表圖像或視頻中可視內(nèi)容的解釋,分類出圖像中不同區(qū)域塊所代表的對象種類。在一張圖片中,同一語義下圖像塊往往有著相近的的光照分布,同時不同語義塊的交接處往往蘊含著物體的結(jié)構(gòu)信息,由此可看出,語義信息特征中的先驗信息可以輔助低光照增強進行更加合理的光照分配,邊緣信息刻畫。基于以上注意力機制以及語義信息特點,提出了一個基于語義信息與注意力機制的低光照增強網(wǎng)絡(luò),首先提取出低光照圖像以及語義信息特征,后續(xù)通過注意力機制,重分配不同區(qū)域的增強效果以達到更好的圖像增強效果。
該網(wǎng)絡(luò)完整流程方法如圖1所示。首先,利用聯(lián)合訓(xùn)練網(wǎng)絡(luò)獲得圖像初步增強結(jié)果與語義信息概率分布圖。其中聯(lián)合訓(xùn)練網(wǎng)絡(luò)如圖2所示,使用成對的U-Net網(wǎng)絡(luò)分別得到低光照圖像增強特征和語義信息特征,在下采樣階段,兩個網(wǎng)絡(luò)使用了共享的編碼器,上采樣階段,每個U-Net網(wǎng)絡(luò)的每一級解碼器輸入特征包含了另一個U-Net網(wǎng)絡(luò)的上一階段的輸出,兩個網(wǎng)絡(luò)互相利用另一網(wǎng)絡(luò)特征信息優(yōu)化自身的輸出結(jié)果。在第二階段中,將初步增強的圖像與輸入的低光照圖片進行拼接后進行特征提取,拼接后的輸入不僅包含了原有輸入低光照圖片的有效信息,同u2NuGezVZLpSYAJxVTewoA==時又帶有第一階段U-Net網(wǎng)絡(luò)多次編碼解碼后得到的增強信息特征。對輸入的拼接圖片進行多次卷積提取出主要特征后,結(jié)合語義信息分布概率圖,利用注意力機制模塊再分配不同特征間的權(quán)重信息,在考慮圖像間關(guān)系的同時,考慮不同語義信息塊間相互關(guān)系。最后,對輸出進行上采樣恢復(fù)到輸入圖片的大小,得到最終的注意力權(quán)重矩陣,并將輸出的權(quán)重矩陣與第一階段增強結(jié)果進行相乘,增強圖片中的輪廓細節(jié)信息,微調(diào)場景曝光狀態(tài),得到最終增強的結(jié)果。
2聯(lián)合訓(xùn)練的U-Net網(wǎng)絡(luò)
直接使用低光照圖片進行語義分析很難獲得理想的分割效果,而U-Net網(wǎng)絡(luò)具有很強的適用性,其在于語義分割,低光照增強等不同的圖像處理應(yīng)用上均有不俗的表現(xiàn)。因此,可以利用U-Net網(wǎng)絡(luò)架構(gòu)的適用性,設(shè)計一個共享特征的聯(lián)合U-Net網(wǎng)絡(luò),同時進行有監(jiān)督的低光照圖片的增強與語義信息獲取的聯(lián)合學(xué)習(xí),獲得語義特征的同時得到初步的低光照增強結(jié)果,減少后續(xù)網(wǎng)絡(luò)訓(xùn)練時間。
聯(lián)合訓(xùn)練網(wǎng)絡(luò)由一對U-Net網(wǎng)絡(luò)構(gòu)成,其基本模塊由堆疊的編碼器?解碼器組成,該網(wǎng)絡(luò)的輸入是RGB格式的低光照圖片,進行有監(jiān)督的低光照圖片的增強與語義信息獲取的聯(lián)合學(xué)習(xí),具體網(wǎng)絡(luò)結(jié)構(gòu)如圖2所示。兩個U-Net網(wǎng)絡(luò)并不是單獨工作的,通過將部分解碼器的輸出特征進行拼接作為下一個解碼器的輸入,使兩個網(wǎng)絡(luò)間得以通過共享特征的方式進行聯(lián)合學(xué)習(xí),從而促使低光照增強與語義信息獲取的同時進行緊密的學(xué)習(xí),同時這也是許多多任務(wù)聯(lián)合學(xué)習(xí)中常用的方法(如Baslamisli等[12],Tang等[13],Wang等[14])。
該網(wǎng)絡(luò)的輸出結(jié)果分別為低光照圖片的初步增強結(jié)果I和先驗信息語義Ψ即語義信息概率分布圖P,
Ψ=P=(P1,P2,···,Pk,···,PK)(1)
其中Pk為第k個語義類別的語義信息概率圖,其代表的是每個像素點歸屬于k類別的概率。K是所有語義類的總數(shù)。
提取特征階段編碼器卷積網(wǎng)絡(luò)使用共享的網(wǎng)絡(luò)權(quán)重,編碼器由大小為3×3,padding為1的卷積、BN層(Batch Normalization Layer)和ReLU激活函數(shù)組成。除了第1個編碼器步長為1外,其余的步長皆為2。第1個到第2個解碼器同樣由大小為3×3,padding為1的卷積、BN層和ReLU激活函數(shù)組成,其中步長都是1。后續(xù)解碼器在原來的解碼器基礎(chǔ)上多了上采樣過程。
該網(wǎng)絡(luò)的損失函數(shù)由幾個函數(shù)組成,其中圖像增強的損失函數(shù)Lenhance計算方式為
式中:I為低光照圖片的增強結(jié)果;Igt為正常照度的場景照片;Ⅱ·Ⅱ2(2)為均方差計算;SSIM對比兩個輸入圖像的結(jié)構(gòu)一致性;損失函數(shù)中的最后一項中Δ代表取梯度操作,通過對比兩個輸入圖片中的梯度保證模型的輸出與I gt的紋理一致性。
語義信息輸出的損失函數(shù)Lce為
Lce=一i(Σ)ceM(Σ)log(pi(c))(3)
式中:pi(c)代表像素i屬于類別c的概率;M為定義的類集,在本文所采用的數(shù)據(jù)庫中種類數(shù)為K=14。
整合以上兩個損失函數(shù)即為聯(lián)合訓(xùn)練網(wǎng)絡(luò)的損失函數(shù)為
通過聯(lián)合網(wǎng)絡(luò)的設(shè)計,第一階段不僅得到了語義信息分布概率圖,同時在對低光照圖片進行初步粗獷增強的過程中,實現(xiàn)對圖片全局亮度的調(diào)整,整體輪廓信息的恢復(fù)。
3注意力機制
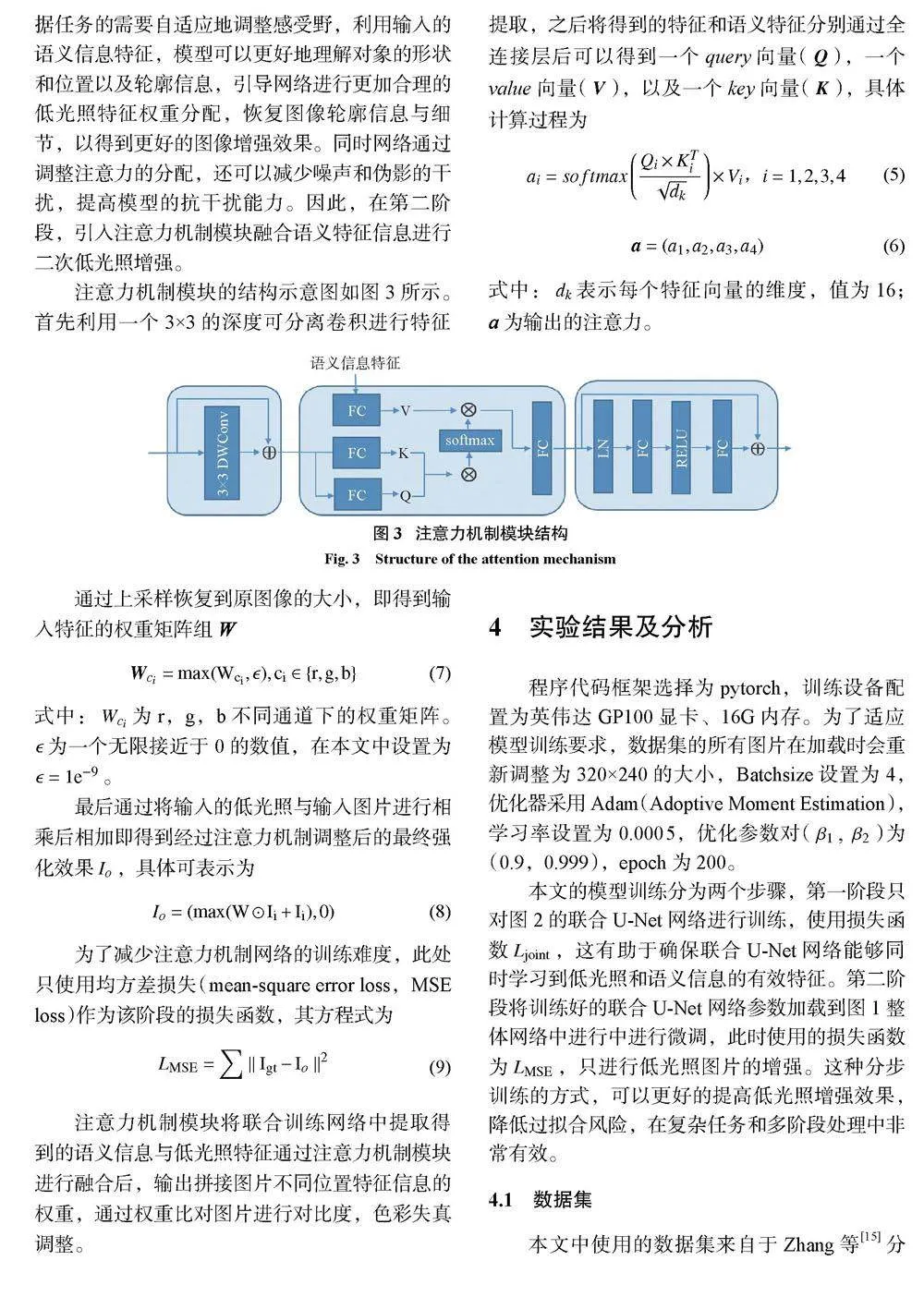
相較于U-Net網(wǎng)絡(luò),注意力機制網(wǎng)絡(luò)能夠根據(jù)任務(wù)的需要自適應(yīng)地調(diào)整感受野,利用輸入的語義信息特征,模型可以更好地理解對象的形狀和位置以及輪廓信息,引導(dǎo)網(wǎng)絡(luò)進行更加合理的低光照特征權(quán)重分配,恢復(fù)圖像輪廓信息與細節(jié),以得到更好的圖像增強效果。同時網(wǎng)絡(luò)通過調(diào)整注意力的分配,還可以減少噪聲和偽影的干擾,提高模型的抗干擾能力。因此,在第二階段,引入注意力機制模塊融合語義特征信息進行二次低光照增強。
注意力機制模塊的結(jié)構(gòu)示意圖如圖3所示。首先利用一個3×3的深度可分離卷積進行特征提取,之后將得到的特征和語義特征分別通過全連接層后可以得到一個query向量(Q),一個value向量(V),以及一個key向量(K),具體計算過程為
式中:dk表示每個特征向量的維度,值為16;a為輸出的注意力。
通過上采樣恢復(fù)到原圖像的大小,即得到輸入特征的權(quán)重矩陣組W
式中:Wc i為r,g,b不同通道下的權(quán)重矩陣。E為一個無限接近于0的數(shù)值,在本文中設(shè)置為E=1e-9。
最后通過將輸入的低光照與輸入圖片進行相乘后相加即得到經(jīng)過注意力機制調(diào)整后的最終強化效果Io,具體可表示為
Io=(max(WO Ii+Ii),0)(8)
為了減少注意力機制網(wǎng)絡(luò)的訓(xùn)練難度,此處只使用均方差損失(mean-square error loss,MSE loss)作為該階段的損失函數(shù),其方程式為
LMSE=ΣⅡIgt-IoⅡ2
注意力機制模塊將聯(lián)合訓(xùn)練網(wǎng)絡(luò)中提取得到的語義信息與低光照特征通過注意力機制模塊進行融合后,輸出拼接圖片不同位置特征信息的權(quán)重,通過權(quán)重比對圖片進行對比度,色彩失真調(diào)整。
4實驗結(jié)果及分析
程序代碼框架選擇為pytorch,訓(xùn)練設(shè)備配置為英偉達GP100顯卡、16G內(nèi)存。為了適應(yīng)模型訓(xùn)練要求,數(shù)據(jù)集的所有圖片在加載時會重新調(diào)整為320×240的大小,Batchsize設(shè)置為4,優(yōu)化器采用Adam(Adoptive Moment Estimation),學(xué)習(xí)率設(shè)置為0.000 5,優(yōu)化參數(shù)對(β1,β2)為(0.9,0.999),epoch為200。
本文的模型訓(xùn)練分為兩個步驟,第一階段只對圖2的聯(lián)合U-Net網(wǎng)絡(luò)進行訓(xùn)練,使用損失函數(shù)Ljoint,這有助于確保聯(lián)合U-Net網(wǎng)絡(luò)能夠同時學(xué)習(xí)到低光照和語義信息的有效特征。第二階段將訓(xùn)練好的聯(lián)合U-Net網(wǎng)絡(luò)參數(shù)加載到圖1整體網(wǎng)絡(luò)中進行中進行微調(diào),此時使用的損失函數(shù)為LMSE,只進行低光照圖片的增強。這種分步訓(xùn)練的方式,可以更好的提高低光照增強效果,降低過擬合風(fēng)險,在復(fù)雜任務(wù)和多階段處理中非常有效。
4.1數(shù)據(jù)集
本文中使用的數(shù)據(jù)集來自于Zhang等[15]分享的公開數(shù)據(jù)集LLRGBD-real,該數(shù)據(jù)集是在真實場景下,利用打開/關(guān)閉室內(nèi)燈后改變光照條件,只使用一個LED燈照明后通過單反相機進行拍攝后獲得。拍攝場景主要是客廳、廚房、浴室、客廳和辦公室,包括515對640×480分辨率的正常/低光圖像,其中415張圖像作為訓(xùn)練集,另外100張則為測試集。除了成對的正常/低光照圖片,該數(shù)據(jù)集還對所有的圖片進行了語義分割的標注,將語義類分割為14種。
4.2評價指標
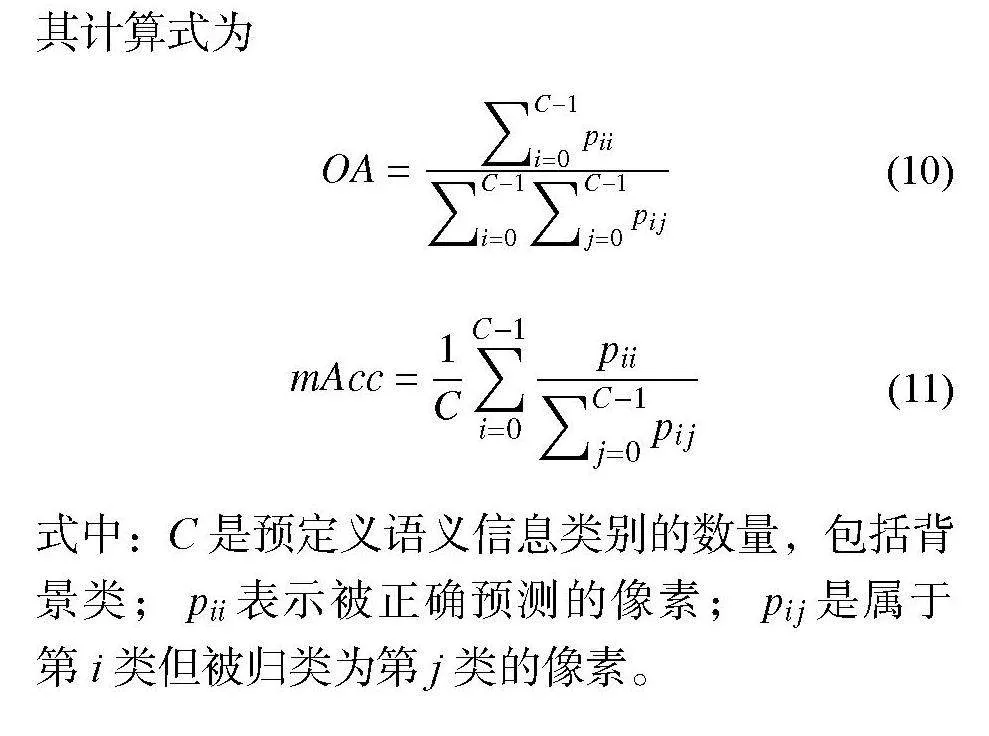
本文的訓(xùn)練中涉及到兩部分指標,分別低光照增強效果指標和語義分割指標。其中低光照增強部分的性能指標為PSNR(Peak Signal-to-Noise Ration)與結(jié)構(gòu)相似性SSIM(Structural Similarity)。語義分割的指標采用全局準確度OA(Overall Accuracy),平均準確度mAcc(Mean Accuracy),其計算式為
式中:C是預(yù)定義語義信息類別的數(shù)量,包括背景類;pii表示被正確預(yù)測的像素;pij是屬于第i類但被歸類為第j類的像素。
4.3語義分割實驗
語義分割結(jié)果如圖4所示,在驗證集上OA與mAcc指標分別達到了66.3%和60.2%,對于大多數(shù)的語義分割任務(wù)而言,這兩個數(shù)值并不是很理想的效果。這是因為在低光照的情況下,圖像中的細節(jié)和紋理很難被模型準確地捕捉到,導(dǎo)致模型難以正確地分割出不同的類別。此外,低光照條件下的圖像可能存在噪聲和陰影等問題,這些也會影響模型的表現(xiàn)。由圖4可以看出,盡管出現(xiàn)了不準確的語義分類結(jié)果,但總體而言,同樣光照強度下的圖像塊,大部分仍被劃分為同一語義塊,可以為后續(xù)的輪廓增強提供有利信息,因此語義分割部分符合后續(xù)模型要求。
4.4低光照增強對比實驗
對比實驗部分選取了深度學(xué)習(xí)低光照增強領(lǐng)域具有代表性的5種低光照增強方法,分別是EnlightenGAN[10],RetinexNet[8],KinD[16],MBLLEN[17],Zero-DCE[11],從低光照增強圖片的表現(xiàn)效果和性能指標兩個方面進行對比參考。
各方法的低光照增強效果如圖5所示,從結(jié)果中可以看出,采用RetinexNet的低光照增強圖像出現(xiàn)了嚴重的顏色失真和偽影問題。EnlightenGAN、KinD和Zero-DCE的結(jié)果中存在著不同程度的過度曝光問題,MBLLEN則相反,在部分場景中出現(xiàn)了亮度增強程度不足的情況。對比之下,采用本文方法得到的低光照增強圖片,曝光正常,也未出現(xiàn)嚴重的顏色失真,偽影等問題。全局的圖像亮度更加均勻,沒有出現(xiàn)局部過亮或者過暗的情況。不同語義下的物體間亮度有更好的區(qū)分度,這些特點說明了引入注意力機制與語義信息后,網(wǎng)絡(luò)對于全局與局部的亮度把控更加合理,證明了上述方法的有效性。
表1列出了不同方法下PSNR與SSIM的指標對比,由對比可以看出,除外視覺表現(xiàn)效果上的對比,本文方法在定量分析中也取得了最好的效果,也從另一方面說明了本文方法的有效性。
4.5消融實驗
在消融實驗部分主要通過刪除部分模塊后,對可視效果與指標數(shù)值上進行對比,探討關(guān)于引入注意力機制模塊與語義信息的必要性。
如圖6(b)U-Net輸出圖片可以看出,盡管U-Net網(wǎng)絡(luò)已經(jīng)達到了一定的圖像增強效果,提高了圖像的整體亮度,恢復(fù)了部分原本低光照圖像中難以觀察到的細節(jié)部分。然而圖像的整體仍呈現(xiàn)出亮度偏暗,邊緣信息丟失的缺點。與本文方法對比可以明顯發(fā)現(xiàn)該圖片存在飽和度不足,結(jié)構(gòu)信息嚴重丟失的問題。
圖6(c)(d)分別是刪除語義信息后模型的輸出效果與完整模型下輸出效果,盡管差別并不十分明顯,但仔細對比仍然可以發(fā)現(xiàn)失去語義信息的引導(dǎo)后,模型對于圖像整體的結(jié)構(gòu)分布信息的感知能力下降,進而導(dǎo)致輸出圖片的對比度下降,不同區(qū)域塊之間的區(qū)分度不高。為了進一步觀察該現(xiàn)象的原因,在圖7中提供了圖6中所示低光照圖片在增強過程中得到的的注意力權(quán)重分配圖,為了更好的對比注意力的分布,將三通道的輸出結(jié)果進行加權(quán)平均后進行可視化。通過對比有無引入語義信息的注意力分布可以看出,在加入語義信息后,不同區(qū)域塊,物體之間的注意力權(quán)重有了更加明顯的區(qū)分。通過在不同區(qū)域間的權(quán)重分配,避免了圖像整體曝光度過于一致化而導(dǎo)致的區(qū)分度不高的問題。進一步說明了語義信息的引入對提高模型結(jié)構(gòu)感知能力有很好的提升效果。
圖8展示了是否刪除注意力機制的增強結(jié)果對比圖。由圖中可以明顯看出,在失去了注意力機制模塊的引導(dǎo)后,由于亮度分布不均勻等因素,在低光處出現(xiàn)了大量的偽影,在對比之下,加入注意力機制模塊后的圖像的光線照度整體更加自然,這是因為有注意力機制的引導(dǎo)下,模型在對局細節(jié)進行光照增強的同時,也會考慮圖像中其他區(qū)域塊的特征,抑制其中的偽影現(xiàn)象。說明了注意力機制通過合理的權(quán)重分布,在有效增強弱光條件下的細節(jié)與紋理同時,很好地保留了圖像的全局上下文信息,證明了其有效性。
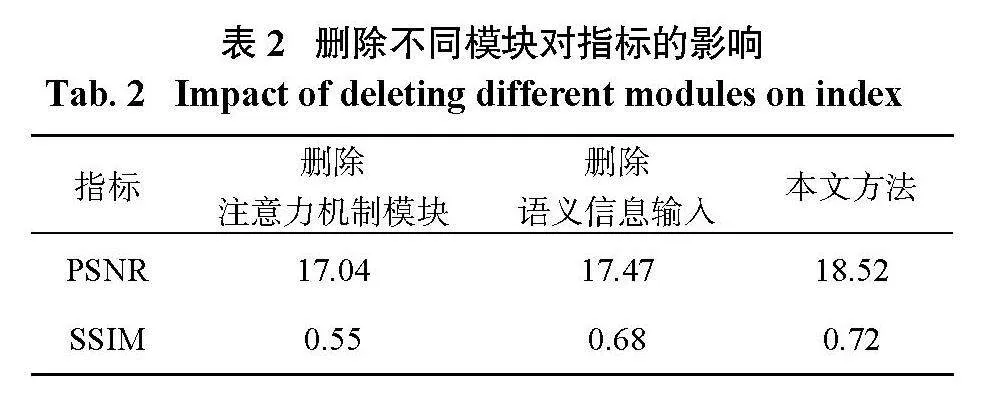
表2列出了刪除不同模塊后的模型輸出結(jié)果的性能指標,由表可以看出,加入注意力模塊與語義信息不論是PSNR,或者SSIM,都有著不同程度的提升,從指標評估方面也可以證明這些模塊的有效性。
5結(jié)論
本文提出了一種融合先驗信息,即語義信息與注意力機制進行融合的低光照增強方法,利用注意力機制模塊融合語義信息,將語義信息中所包含的全局結(jié)構(gòu)信息與低光圖像信息進行融合,消除圖像偽影的同時,提高圖像的飽和度與不同區(qū)域塊的對比度。使增強后的結(jié)果具有更加生動的顏色和真實性,通過對比實驗和消融實驗證明了本文方法的有效性。今后也將考慮將本文的框架使用其他先驗知識進行驗證,如可將深度信息作為先驗知識引入,與低光照增強進行融合,抑或使用語義信息與圖像去霧進行融合等,從而將算法推向更多的應(yīng)用場景。
參考文獻:
[1]董麗麗,丁暢,許文海.基于直方圖均衡化圖像增強的兩種改進方法[J].電子學(xué)報,2018,46(10):2367–2375.
[2]KIM J Y,KIM L S,HWANG S H.An advanced contrast enhancement using partially overlapped sub-block histogram equalization[J].IEEE Transactions on Circuits and Systems for Video Technology,2001,11(4):475–484.
[3]IQBAL K,ODETAYO M,JAMES A,et al.Enhancing the low quality images using Unsupervised Colour Correction Method[C]//Proceedings of 2010 IEEE International Conference on Systems,Man and Cybernetics.Istanbul:IEEE,2010:1703?1709.
[4]李慶忠,劉清.基于小波變換的低照度圖像自適應(yīng)增強算法[J].中國激光,2015,42(2):0209001.
[5]JOBSON D J,RAHMAN Z,WOODELL G A.Properties and performance of a center/surround retinex[J].IEEE Transactions on Image Processing,1997,6(3):451–462.
[6]JOBSON D J,RAHMAN Z,WOODELL G A.A multiscale retinex for bridging the gap between color images and the human observation of scenes[J].IEEE Transactions on Image Processing,1997,6(7):965–976.
[7]LORE K G,AKINTAYO A,SARKAR S.LLNet:a deep autoencoder approach to natural low-light image enhancement[J].Pattern Recognition,2017,61:650–662.
[8]JIANG Y F,GONG X Y,LIU D,et al.EnlightenGAN:deep light enhancement without paired supervision[J].IEEE Transactions on Image Processing,2021,30:2340–2349.
[9]GUO C L,LI C Y,GUO J C,et al.Zero-reference deep curve estimation for low-light image enhancement[C]//Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition.Seattle:IEEE,2020:1777?1786.
[10]JIN X,XIAO J W,HAN L H,et al.Lighting every darkness in two pairs:a calibration-free pipeline forRAW denoising[C]//Proceedings of 2023 IEEE/CVF International Conference on Computer Vision.Paris:IEEE,2023:13229?13238.
[11]FU H Y,ZHENG W K,MENG X Y,et al.You do not need additional priors or regularizers in retinex-based low-light image enhancement[C]//Proceedings of 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition.Vancouver:IEEE,2023:18125?18134.
[12]BASLAMISLI A S,GROENESTEGE T T,DAS P,et al.Joint learning of intrinsic images and semantic segmentation[C]//Proceedings of the 15th European Conference on Computer Vision.Munich:Springer,2018:286?302.
[13]TANG Q,CONG R M,SHENG R H,et al.BridgeNet:a joint learning network of depth map super-resolution and monocular depth estimation[C]//Proceedings of the 29th ACM International Conference on Multimedia.ACM,2021:2148?2157.
[14]WANG F Q,ZUO W M,LIN L,et al.Joint learning of single-image and cross-image representations for person re-identification[C]//Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition.Las Vegas:IEEE,2016:1288?1296.
[15]ZHANG N,NEX F,KERLE N,et al.LISU:low-light indoor scene understanding with joint learning of reflectance restoration[J].ISPRS Journal of Photogrammetry and Remote Sensing,2022,183:470–481.
[16]ZHANG Y H,ZHANG J W,GUO X J.Kindling the darkness:a practical low-light image enhancer[C]//Proceedings of the 27th ACM International Conference on Multimedia.Nice:ACM,2019:1632?1640.
[17]LV F F,LU F,WU J H,et al.MBLLEN:low-light image/video enhancement using CNNs[C]//Proceedings of British Machine Vision Conference 2018.Newcastle:BMVA,2018:220.
(編輯:張磊)
