基于實體級聯類型的中文關系抽取管道模型
2024-11-04 00:00:00饒東寧吳倩梅黃觀琚
計算機應用研究 2024年9期



摘 要:
端到端實體關系抽取任務可以被分解成命名實體識別和關系抽取兩個子任務,最近的工作多將這兩個子任務聯合建模。現有的流水線方法驗證了在關系模型中融合實體類型信息的重要性和管道模型的潛力,但是它們忽略了文本中的某些實體可能同時具有多個類型,這種多義性的情況在中文數據集中尤為常見。為解決上述問題,提出了一種實體級聯類型機制,并在此基礎上開發了一個更適合中文關系抽取的管道模型,取名為CENTRELINE。這一流水線方法的實體模塊是一個詞-詞關系分類模型,它以BERT和雙向LSTM作為編碼器、經過條件層歸一化后引入空洞卷積,最后通過級聯類型預測器輸出實體及其級聯類型。關系模塊的輸入僅由實體模塊構建。該方法在DuIE1.0、DuIE2.0和CMeIE-V2數據集上的F1值分別比基線方法提高7.23%、6.93%和8.51%,并在DuIE1.0和DuIE2.0數據集上都實現了最先進的性能。消融實驗表明,提出的級聯類型機制和根據中文語言特征改進的管道模型,均對關系抽取性能具有明顯的促進作用。
關鍵詞:中文關系抽取;管道模型;空洞卷積;實體級聯類型
中圖分類號:TP391 文獻標志碼:A 文章編號:1001-3695(2024)09-017-2685-05
doi:10.19734/j.issn.1001-3695.2023.12.0621
Chinese relation extraction pipeline model based on entity cascading types
Rao Dongning, Wu Qianmei, Huang Guanju
(School of Computers, Guangdong University of Technology, Guangzhou 510006, China)
Abstract:
End-to-end entity relation extraction can be decomposed into named entity recognition and relation extraction, most recent works model these two subtasks jointly. Existing pipelined approaches validate the importance of fusing entity type information in the relation model and the potential of pipeline models, but they ignore the possibility that certain entities in the text may have multiple types at the same time, which is particularly common in Chinese datasets. This paper proposed an entity cascading type mechanism to address the aforementioned issues and developed a pipeline model named CENTRELINE, which was more suitable for Chinese relation extraction. This pipelined approach incorporated an entity module, which was a word-word relation classification model. It employed BERT and bi-directional LSTM as encoders, introduced dilated convolution after conditional layer normalization, and finally generated outputs for entities and their cascading types using a cascading type predictor. The input of the relation module was only constructed by the entity module. Surpassing the baseline by 7.23%, 6.93%, and 8.51% on DuIE1.0, DuIE2.0, and CMeIE-V2 datasets, respectively. This method demonstrates improvements in F1 values and achieves state-of-the-art performance on both DuIE1.0 and DuIE2.0 datasets. The results of ablation experiments indicate that both the proposed cascading type mechanism and the pipeline model refined based on Chinese language characteristics can enhance the performance of relation extraction.
Key words:Chinese relation extraction; pipeline model; dilated convolution; entity cascading type
0 引言
實體關系抽取是信息抽取的關鍵任務之一,它對于知識圖譜、智能問答等自然語言處理應用都十分重要[1]。它是指在文本中找出主體與客體之間存在的關系,并將其表示為實體關系三元組,即(主體,關系,客體)。實體關系抽取可以分為流水線方法和聯合式方法,對應管道模型和聯合模型。管道模型存在交互缺失和誤差累積的問題,而聯合模型可以充分利用實體和關系之間的交互信息[2],所以目前的研究大多采用聯合模型。然而Zhong等人[3]提出使用簡單的管道模型也可以獲得比聯合模型更好的效果,這一實驗證明了管道模型具有潛在的優越性。具體來說,通過在實體識別階段取得足夠好的效果,可以減少誤差累積對管道模型性能的影響,從而提高模型的整體性能。
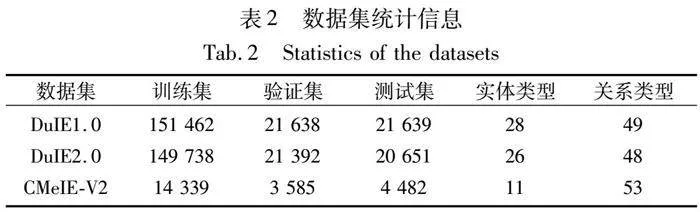
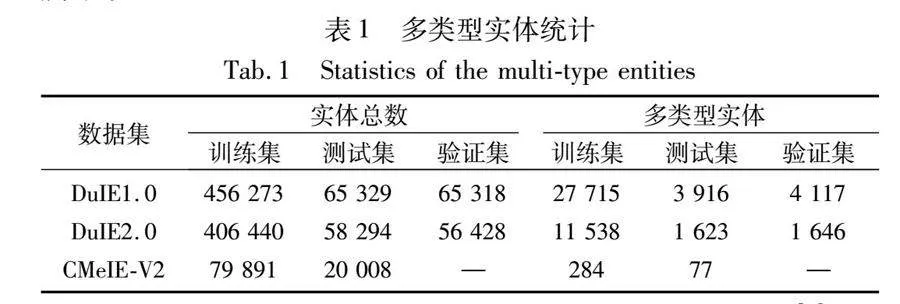
現有的一種提升流水線方法性能的方式是引入實體的類型信息作為輸入。例如,Zhong等人[3]在句子中顯式插入實體類型標記。Ye等人[4]提出了一種基于懸浮標記的片段表示方法。但是它們都默認一個句子中的某個實體只對應一個實體類型,忽略了同一個實體在不同的三元組中可能有不同的實體類型,尤其是中文數據集中存在實體多義性的情況,如表1所示。
由于實體類型在關系抽取階段扮演著重要的角色[3],單一而固定的實體類型可能對關系的準確預測產生限制,所以給模型提供更豐富、完整的實體類型信息將有助于優化三元組的抽取過程。
受文獻[3,5]的啟發,本文在管道模型上預測和應用更詳盡的實體類型,并提出了基于實體級聯類型的中文關系抽取管道模型(Chinese relation extraction pipeline model based on entity cascading types,CENTRELINE)。具體而言,本文方法首先在實體識別階段使用了根據中文數據集的特點改進的命名實體識別模型,它以BERT[6]和雙向LSTM[7]作為編碼器、經過條件層歸一化(CLN)[8]后引入空洞卷積[9],最后通過級聯類型預測器輸出實體及其級聯類型。隨后在關系抽取階段,將級聯類型作為關鍵輸入以預測文本的三元組集合。這一流水線方法的設計充分考慮了中文語境下的實體識別特征和實體類型的多樣性,為關系抽取任務提供了更為精準和全面的信息支持。
本文的主要貢獻是提出了一種實體級聯類型機制,并把它應用到根據中文數據集特點改進的實體識別模塊上,在DuIE1.0、DuIE2.0和CMeIE-V2數據集上取得了優于基線PURE[3]、ChatIE[10]和BiTT-BERT[11]的抽取結果,其中在DuIE1.0、DuIE2.0數據集上可以實現最先進的性能。
1 相關研究
實體關系抽取是構建知識庫的重要步驟,也是許多自然語言處理下游任務的基礎。經典的實體抽取方法主要分為有監督、半監督和無監督這三類[12],隨著近年深度學習的崛起,關系抽取任務研究的重點轉向了使用深度學習方法[13]。基于深度學習實體關系抽取主要分為有監督和遠程監督兩類,其中有監督實體抽取根據實體識別(NER)和關系抽取(RE)兩個子任務完成順序的不同,可細分為流水線方法和聯合抽取方法[13]。
聯合抽取方法指建立統一的模型使得兩個子任務彼此交互,它可以分為共享參數的聯合抽取模型和聯合解碼的聯合抽取模型。例如,王景慧等人[14]提出融合了依存句法信息的關系導向實體抽取的策略,先確定關系,再確定關系相關的實體對。Zhao等人[15]提出融合兩階段的流水線方法,同時進行聚類學習和關系標注。Luo等人[11]受醫學文本中樹狀關系結構的啟發,提出了一種稱為BiTT的新方案并建立了一個聯合關系提取模型,將醫學關系三元組形成兩個二叉樹,并將樹轉換為詞級標簽序列。最近,大型語言模型如GPT-3[16]、ChatGPT在信息抽取任務上展現了卓越性能。因此,Wei等人[10]通過直接提示大型語言模型來構建強大的信息抽取模型ChatIE,它將信息抽取任務轉換為一個多回合的問答問題。然而,共享參數的聯合抽取模型學習過程仍然類似流水線方法,并沒有實現真正的聯合;聯合解碼的聯合抽取模型需要設計復雜的標簽或者解碼過程,而且它對重疊的關系三元組的識別效果不是很好。
流水線方法指先抽取實體,再抽取關系,近幾年已有實驗證明了流水線方法取得了比聯合方法更好的結果。例如,Zhong等人[3]提出了PURE,它將兩個獨立的編碼器分別用于實體抽取和關系識別,關系模型只依賴實體模型來提供輸入特征。盡管它的設計和訓練模式很簡單,但實驗證明這個管道模型在其實驗數據集上優于所有以前的聯合模型。Ye等人[4]提出了一種基于懸浮標記的片段表示方法,在編碼過程中通過特定策略打包標記來考慮片段之間的相互關系。在命名實體識別任務上,Li等人[5]提出了W2NER,通過將命名實體識別任務建模為詞-詞關系分類解決了統一NER的內核瓶頸,在14個廣泛使用的基準數據集上超越了所有當前表現最好的基線模型。
中文實體關系抽取研究相對于英文研究起步更晚,且進展有限,這可能是因為中文語境下的語言特點不同[17]。關系抽取領域中,中文與英文的不同主要體現在三個方面[18]:首先,中文字符之間通常沒有明確的邊界[17],這使得識別實體邊界變得更為困難;其次,中文句法結構與英文存在顯著差異,這增加了在分析中文文本時的復雜性;最后,中文中句子成分之間的關系通常缺乏顯性的語法標記,需要深入理解上下文語境以正確捕捉實體之間的聯系。近年來一些學者開始致力于構建更多樣化且貼近實際應用場景的中文關系抽取數據集,以促進該領域的研究和發展。例如,Li等人[19]構建了第一個大規模的高質量數據集DuIE1.0,其中的數據均來源于百度百科和百度新聞摘要。為了進一步推動中文關系抽取的發展,Li等人[19]隨后推出了DuIE2.0,擴展了數據集的規模、多樣性和復雜性。Guan等人[20]提出了中文醫學信息抽取數據集CMeIE,數據來自醫學教科書和臨床實踐,經過多輪手動注釋構建。綜合來看,中文關系抽取領域展現出廣闊的發展前景。
2 CENTRELINE
本文提出一種基于實體級聯類型的中文關系抽取管道模型,該模型主要由NER模塊和RE模塊組成。其中,NER模塊接受輸入句子并為每個片段預測實體級聯類,見圖1上NER部分。對NER模塊預測出的所有實體進行兩兩配對并在句子中插入實體對的級聯類型信息之后,RE模塊將會獨立處理每一對候選實體,為每對實體對預測關系類型,見圖1下RE部分。
之前的工作中在訓練實體模型的時候每個片段的訓練目標類型只有一個,本文考慮到實體的多類型情況,所以在NER模塊的訓練階段和預測階段將實體類型的數量擴展到了兩個。具體來說,如果實體的標注類型只有一個,則復制為兩個一樣的類型進行訓練;如果預測出兩個類型是一樣的,解碼的時候則合并為一個。過去的工作在訓練關系模型時,模型輸入所攜帶的實體類型信息也只有其中一個,而本文在RE模塊的訓練階段把實體的所有類型信息都插入到了輸入序列中。此外,在訓練RE模塊時,選擇將模塊的輸入設定為訓練集中的所有標注實體,而在驗證和測試階段則采用NER模塊預測出的實體。這一設計決策試圖最小化管道模型中兩個子任務順序執行帶來的誤差傳播。在訓練階段使用訓練集中的真實標注實體作為輸入,模型可以更好地適應已知實體關系,提高模型在訓練數據上的擬合效果。在驗證和測試階段使用NER模塊預測的實體是出于對模型在真實場景中的泛化能力的關注,使用NER模塊預測的實體可以更好地模擬實際應用環境,提高模型對未知實體的處理能力。
3 實驗結果及分析
3.1 數據集
本文實驗在DuIE1.0、DuIE2.0、CMeIE-V2三個中文數據集上進行,表2顯示了每個數據集的數據統計信息。DuIE1.0和DuIE2.0是來自2021年百度舉辦的語言與智能技術競賽信息抽取賽道的公開數據集[19],為了方便與其他模型對比并測試最新的數據集,本文使用了兩個版本的DuIE數據集。CMeIE-V2數據集是中文醫療信息處理挑戰榜CBLUE發布的醫療數據集[20],包含兒科訓練語料和百種常見疾病訓練語料。
3.2 實驗設置
本文使用BERT-base-Chinese作為基本編碼器。在NER模塊上不設置句子最大長度限制;在RE模塊上,設置DuIE1.0、DuIE2.0數據集句子最大長度為256,CMeIE-V2數據集句子最大長度為300。實驗在顯卡設備RTX3090上進行,用PyTorch作為編碼框架。
本文采用F1值、查準率precision和查全率recall作為評價標準。對于命名實體識別子任務,如果預測實體的邊界和預測實體類型都正確,則認為預測實體是正確的;對于關系抽取子任務,如果兩個片段的邊界正確且預測關系類型正確,則認為預測關系是正確的。
3.3 實驗結果分析
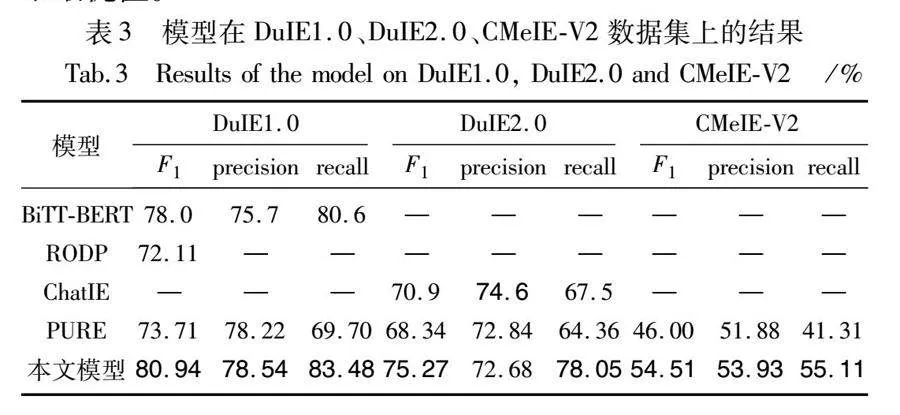
為了評估本文模型在流水線方式上的提升效果,將同為流水線模型的PURE作為基線模型之一。除此之外,本文還將在各個數據集上表現突出的模型作為基線進行比較。本文基線模型如下:a)BiTT-BERT[11],使用雙向樹標記的關系抽取聯合模型;b)RODP[14],融合了依存句法信息的關系導向實體抽取的策略;c)ChatIE[10],通過與ChatGPT對話進行信息抽取;d)PURE[3]。本文方法與基線模型的實驗結果對比如表3所示,表中部分數據直接來自原文,所以有空缺值。
本文在三個不同的數據集上進行了實驗驗證,其中DuIE2.0比DuIE1.0更傾向于口語,并進一步引入了復雜的關系。實驗在沒有標注的測試集上得到的結果如表3所示,本文方法在三個數據集上的F1值均有顯著提升。其中,本文方法較PURE在三個數據集上分別提升了7.23%、6.93%和8.51%。相較于在DuIE1.0和DuIE2.0數據集表現突出的基線模型,本文方法在DuIE1.0和DuIE2.0數據集上的F1值提升了2.94%和4.37%。這表明本文模型在不同領域的數據集上都表現良好,具有出色的泛化能力。尤其值得注意的是在兩個DuIE數據集上,本文模型表現明顯超越了當前處于領先地位的模型,進一步突顯了其卓越的性能和優越性。
3.4 消融實驗
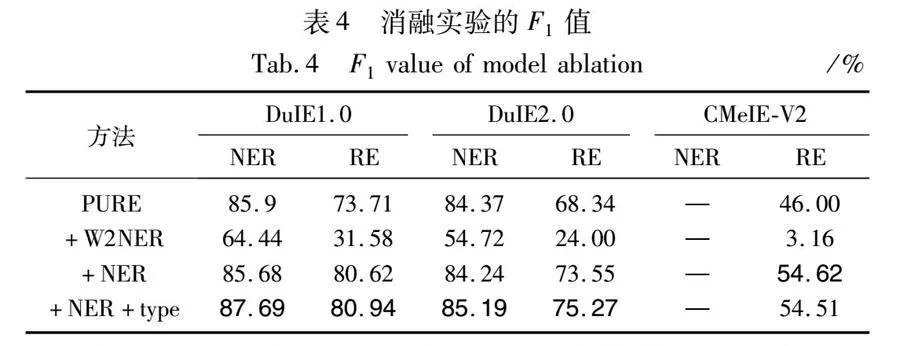
本文以PURE為基線模型,對本文方法進行消融實驗,結果如表4所示。表4的第1行是基線模型的結果,第2行是將基線模型的實體模型替換成W2NER命名實體識別模型后的實驗結果,第3行是將基線模型的實體模型替換成本文改進過后的命名實體識別模型(即NER模塊)后的實驗結果,第4行是在第3行的基礎上加上級聯類型機制的實驗結果。
如表4所示,如果只是將PURE的實體模型部分替換成W2NER命名實體識別模型,那么實體識別子任務的結果將明顯下降,而關系抽取子任務的結果下降更顯著。但是如果將PURE的實體模型部分替換成本文的NER模塊,關系模型的結果將會提升6.91%、5.21%和8.62%,這表明本文對命名實體識別模型的改進是十分關鍵的。此時NER模塊的結果與基線模型實體模型結果相近,但是關系抽取的結果卻提升了,可能是因為改進后的NER模塊提供了更準確的實體類型信息給RE模塊。
改進后的NER模塊加上級聯類型機制后,實體識別子任務在DuIE1.0、DuIE2.0數據集上的結果較未加上級聯類型機制時提升了2.01%和0.95%;關系抽取子任務在DuIE1.0和DuIE2.0數據集上的結果提升了0.32%和1.72%。表明本文提出的級聯關系機制在DuIE1.0和DuIE2.0數據集上可有效提升三元組抽取性能。關系抽取子任務在CMeIE-V2數據集上的結果略微下降了0.11%,可能是因為醫學數據集的結構復雜,所以性能不能取得提升。
3.5 RE模塊對標記進行預處理的方法對比
在本文的NER模塊中,最終會輸出預測實體及其級聯類型給RE模塊,然而如何在RE模塊通過預處理數據把級聯類型融合到數據中是一個問題。本文嘗試了三種方式,如圖2所示。圖2(a)是預處理前的句子,(b)到(d)是三種預處理方式后的句子。
第一種預處理方式是擴展RE模塊生成的例子, 如圖2(b)所示。NER模塊輸出實體及其級聯類型后,把同一實體的不同類型當成各自只有一個類型的多個同名實體,然后將這些同名實體與其他實體一起進行兩兩配對輸入到關系模型。示例句子預測出的實體“千夢輪回”有兩個類型“網絡小說”和“圖書作品”,這個實體在關系抽取階段將會被當成兩個實體,一個是類型為“網絡小說”的實體“千夢輪回”,另一個是類型為“圖書作品”的實體“千夢輪回”。這兩個同名不同類型的實體分別和另一個實體配對,最終生成兩個例子。
第二種和第三種預處理方式都是在句子上聯合標記實體對的所有類型。第一種聯合標記方式是交叉標記,即實體的類型1與類型2的頭尾標記彼此交叉,生成實例如圖2(c)所示。第二種聯合標記方式是包含標記,即實體的一個類型的頭尾標記包含另一個類型的頭尾標記,生成實例如圖2(d)所示。
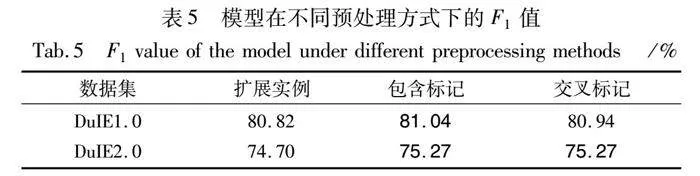
不同預處理方式下的實驗結果如表5所示。在關系模型只生成一個例子的預處理方式比擴展例子的方式能取得更好的結果,分析其原因是擴展例子使得管道模型的實體冗余缺陷更加明顯,從而降低了模型的性能。另外在兩種不同的聯合標記方式中,DuIE1.0數據集上的包含標記方式比交叉標記方式提升了0.2%,而DuIE2.0數據集上并無差別。這說明了不同的聯合方式對不同數據集的效果不一樣,而且兩種聯合標記方式的效果相差不大。
4 結束語
針對中文實體關系抽取任務,提出了一種基于實體級聯類型的中文關系抽取管道模型。它的RE模塊是一個基于卷積神經網絡的把命名實體識別任務轉換為詞-詞關系分類任務的模型,并生成了預測實體及其級聯類作為關系模型的輸入,最終由RE模塊生成三元組。實驗表明,它在DuIE1.0、DuIE2.0、CMeIE-V2三個數據集上取得了比基線模型更好的結果,其中在DuIE1.0和DuIE2.0數據集上可以達到最好的性能。實驗表明了管道模型具有不遜于聯合模型的良好性能和潛力。下一步將深入研究預處理級聯類型的方式,以更好地發揮豐富后的實體類型信息的作用。
參考文獻:
[1]Xia Zhentao,Qu Weiguang,Gu Yanhui,et al. Review of entity relation extraction based on deep learning [C]// Proc of the 19th Chinese National Conference on Computational Linguistics. Haikou,China: Chinese Information Processing Society of China,2020: 349-362.
[2]王傳棟,徐嬌,張永. 實體關系抽取綜述 [J]. 計算機工程與應用,2020,56(12): 25-36. (Wang Chuandong,Xu Jiao,Zhang Yong. Survey of entity relation extraction [J]. Computer Engineering and Applications,2020,56(12): 25-36.)
[3]Zhong Zexuan,Chen Danqi. A frustratingly easy approach for entity and relation extraction [C]// Proc of Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg,PA: Association for Computational Linguistics,2021: 50-61.
[4]Ye Deming,Lin Yankai,Li Peng,et al. Packed levitated marker for entity and relation extraction [C]// Proc of the 60th Annual Meeting of the Association for Computational Linguistics. Stroudsburg,PA: Association for Computational Linguistics,2022: 4904-4917.
[5]Li Jingye,Fei Hao,Liu Jiang,et al. Unified named entity recognition as word-word relation classification [C]// Proc of AAAI Conference on Artificial Intelligence,2022: 10965-10973.
[6]Devlin J,Chang M W,Lee K,et al. BERT: pre-training of deep bidirectional transformers for language understanding [C]// Proc of Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg,PA: Association for Computational Linguistics,2019: 4171-4186.
[7]Lample G,Ballesteros M,Subramanian S,et al. Neural architectures for named entity recognition [C]// Proc of Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg,PA: Association for Computational Linguistics,2016: 260-270.
[8]Liu Ruibo,Wei J,Jia Chenyan,et al. Modulating language models with emotions [C]//Proc of Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021. Stroudsburg,PA: Association for Computational Linguistics,2021: 4332-4339.
[9]Yu F,Koltun V. Multi-scale context aggregation by dilated convolutions [C]// Proc of the 4th International Conference on Learning Representations. Piscataway,NJ:IEEE Press,2016.
[10]Wei Xiang,Cui Xingyu,Cheng Ning,et al. Zero-shot information extraction via chatting with ChatGPT [EB/OL]. (2024-05-27). https://arxiv.org/abs/2302.10205.
[11]Luo Xukun,Liu Weijie,Ma Meng,et al. A bidirectional tree tagging scheme for joint medical relation extraction [C]// Proc of International Joint Conference on Neural Networks. Piscataway,NJ: IEEE Press,2023: 1-8.
[12]Zhou Zhihua. A brief introduction to weakly supervised learning [J]. National Science Review,2018,5(1): 44-53.
[13]鄂海紅,張文靜,肖思琪,等. 深度學習實體關系抽取研究綜述 [J]. 軟件學報,2019,30(6): 1793-1818. (E Haihong,Zhang Wenjing,Xiao Siqi,et al. Survey of entity relationship extraction based on deep learning [J]. Journal of Software,2019,30(6): 1793-1818.)
[14]王景慧,盧玲,段志麗,等. 融合依存信息的關系導向型實體關系抽取方法 [J]. 計算機應用與研究,2023,40(5): 1410-1415,1440. (Wang Jinghui,Lu Ling,Duan Zhili,et al. Relationship-oriented entity relationship extraction method combining dependent information [J]. Application Research of Computers,2023,40(5): 1410-1415,1440.)
[15]Zhao Jun,Zhang Yongxin,Zhang Qi,et al. Actively supervised clustering for open relation extraction [C]// Proc of the 61st Annual Meeting of the Association for Computational Linguistics. Stroudsburg,PA: Association for Computational Linguistics,2023: 4985-4997.
[16]Brown T B,Mann B,Ryder N,et al. Language models are few-shot learners [C]// Proc of the 34th International Conference on Neural Information Processing Systems. Red Hook,NY: Curran Associates Inc. 2020: 1877-1901.
[17]Li Wenjie,Zhang Peng,Wei Furu,et al. A novel feature-based app-roach to chinese entity relation extraction [C]// Proc of ACL-08: HLT,Short Papers. Stroudsburg,PA: Association for Computational Linguistics,2008: 89-92.
[18]邢百西,趙繼舜,劉鵬遠. 中文關系抽取的句級語言學特征探究[C]// 第二十屆全國計算語言學會議論文集. 北京:中國中文信息學會,2021: 643-654. (Xing Baixi,Zhao Jishun,Liu Pengyuan. A probe into the sentence-level linguistic features of chinese relation extraction [C]// Proc of the 20th Chinese National Conference on Computational Linguistics. Beijing: Chinese Information Processing Society of China,2021: 643-654.)
[19]Li Shuangjie,He Wei,Shi Yabing,et al. DuIE: a large-scale Chinese dataset for information extraction [C]// Proc of the 8th CCF International Conference on Natural Language Processing and Chinese Computing. Berlin: Springer-Verlag,2019: 791-800.
[20]Guan Tongfeng,Zan Hongying,Zhou Xiabing,et al. CMeIE: construction and evaluation of Chinese medical information extraction dataset [C]//Proc of Natural Language Processing and Chinese Computing. Cham: Springer,2020: 270-282.
收稿日期:2023-12-10;修回日期:2024-02-04 基金項目:廣東省自然科學基金面上項目(2021A1515012556)
作者簡介:饒東寧(1977—),男,廣東興寧人,副教授,碩導,博士,主要研究方向為智能規劃、自然語言處理(raodn@gdut.edu.cn);吳倩梅(1998—),女,江西贛州人,碩士研究生,主要研究方向為自然語言處理;黃觀琚(1996—),男,廣東湛江人,碩士研究生,主要研究方向為自然語言處理.
