基于PPO算法的自動駕駛人機交互式強化學習方法
2024-11-04 00:00:00時高松趙清海董鑫賀家豪劉佳源
計算機應用研究 2024年9期


摘 要:針對當前自動駕駛領域中深度強化學習(deep reinforcement learning,DRL)所面臨的高計算性能需求和收斂速度慢的問題,將變分自編碼器(variational autoencoder,VAE)和近端策略優化算法(proximal policy optimization,PPO)相結合。通過采用VAE的特征編碼技術,將Carla模擬器獲取的語義圖像有效轉換為狀態輸入,以此應對DRL在處理復雜自動駕駛任務時的高計算負擔。為了解決DRL訓練中出現的局部最優和收斂速度慢的問題,引入了駕駛干預機制和基于駕駛員引導的經驗回放機制,在訓練初期和模型陷入局部最優時進行駕駛干預,以提升模型的學習效率和泛化能力。通過在交通路口左轉場景進行的實驗驗證,結果表明,在駕駛干預機制的幫助下,訓練初期模型的性能提升加快,且模型陷入局部最優時通過駕駛干預,模型的性能進一步提升,且在復雜場景下提升更為明顯。
關鍵詞:自動駕駛;深度強化學習;特征編碼;駕駛干預;經驗回放
中圖分類號:TP181 文獻標志碼:A 文章編號:1001-3695(2024)09-023-2732-05
doi:10.19734/j.issn.1001-3695.2024.01.0018
Human-machine interactive reinforcement learning method for autonomous driving based on PPO algorithm
Shi Gaosong,Zhao Qinghai,Dong Xin,He Jiahao,Liu Jiayuan
(College of Mechanical & Electrical Engineering,Qingdao University,Qingdao Shandong 266071,China)
Abstract:To address the high computational demands and slow convergence faced by DRL in the field of autonomous driving,this paper integrated VAE with PPO algorithm.By adopting VAE’s feature encoding technology,it effectively transformed semantic images obtained from the Carla simulator into state inputs,thus tackling the high computational load of DRL in handling complex autonomous driving tasks.To solve the issues of local optima and slow convergence in DRL training,it introduced a driving intervention mechanism and a driver-guided experience replay mechanism.These mechanisms applied driving interventions during the initial training phase and when the model encounters local optima,so as to enhance the model’s learning efficiency and generalization capability.Experimental validation,conducted in left-turn scenarios at intersections,shows that with the aid of the driving intervention mechanism,the model’s performance improves more rapidly in the initial training phase.Moreover,driving interventions when encountering local optima further enhance the model’s performance,with even more significant improvements observed in complex scenarios.
Key words:autonomous driving;deep reinforcement learning;feature encoding;driving intervention;experience replay
0 引言
DRL作為集深度學習與強化學習于一體的前沿技術,在自動駕駛領域引起了廣泛的關注和應用[1,2]。通過自動駕駛汽車與環境之間的交互學習,使得自動駕駛汽車能夠自主優化駕駛策略,從而在復雜、未知的交通環境中高效安全地駕駛[3,4]。
DRL通過智能體與環境的交互學習,最大化累積獎勵以從經驗中優化駕駛策略[5]。Cui等人[6]使用改進的雙偏差經驗回放方法,使汽車能夠選擇駕駛學習傾向,提升了自動駕駛的魯棒性。Yi等人[7]通過DQN方法實現了自動駕駛車輛的換道,提高了車輛在一定條件下自動駕駛模式的速度和穩定性,但難以應對復雜的環境。Tseng等人[8]使用自適應的DDPG算法,以減少狀態行為值的過度估計,提高了駕駛經驗的利用率。盡管DRL在處理復雜任務方面取得了良好的性能,但其與環境的交互效率相對較低[9]。使用強化學習來解決問題需要熟練的定義和設置,并消耗大量的計算資源[10]。鑒于人類在上下文理解和基于知識推理方面表現出的魯棒性和高適應性,將人工指導與強化學習相結合是緩解上述缺點的一種方法[11,12]。
Li等人[13]提出了一種人在環強化學習方法下實現不需要獎勵功能的自動駕駛車輛控制。Huang等人[14]利用神經網絡模型模仿人類行為,并對actor-critic網絡進行了模仿學習約束,該方法在無獎勵交通場景下的自動駕駛任務中表現出色。Wu等人[15]通過評估人類指導相對于RL策略的優勢,實現了從不完善的人類指導中學習的RL。然而,基于人類指導的方法需要處理大量來自自我探索的數據,而現有方法尚未充分優化人工指導數據的利用,仍需要大量人工工作來防止指導在探索數據中失效。
為解決上述問題,在DRL訓練過程中動態地將駕駛員駕駛經驗融入模型學習中。在模型學習階段,通過實時監測模型學習效果并進行干預調整,利用駕駛員經驗建立基于駕駛員引導的經驗回放機制,使模型向理想狀態持續優化。提高模型與環境的交互效率,同時保持DRL的探索功能,使模型不過分依賴專家駕駛經驗,從而增強模型的可靠性和泛化性能。
1 算法實現
首先在Carla環境中收集語義圖像以訓練VAE編碼器和解碼器。在模型訓練過程中,將相機獲取的語義圖像經過VAE編碼器特征編碼后和車輛的狀態信息作為模型的輸入。在訓練過程中,通過監測選取合適的人為干預時機,并將訓練經驗分開存儲。算法流程如圖1所示。
1.1 VAE算法
VAE算法是一種圖像特征編碼技術[15]。通過將高維輸入數據映射到潛在空間,并利用隨機采樣實現圖像的壓縮編碼。VAE結構由編碼器和解碼器兩部分構成。將語義圖像輸入編碼器,獲得其潛在表示z,通過解碼器將z轉換為重構圖像。實現對圖像的編碼與解碼,降低語義信息狀態特征的空間維度。其數學表達式為
2 實驗驗證
駕駛干預通過外接駕駛設備實現,實驗設備如表1所示。
通過對自動駕駛路口左轉場景的訓練,并與表2算法對比,驗證提出算法的可行性和有效性。實驗地圖為Town07,為使模型能夠適應多樣化的場景,在路口兩側分別隨機添加0~6個車輛,前后車輛間隔16 m放置,且車輛位于所在車道道路中心線位置,并將其設定為Carla的自動駕駛模式。
為使模型成功完成任務,每個訓練回合自車需要從起始位置出發,保持在道路上,避免與任何障礙物碰撞,最終到達終點線(自車的橫坐標達到目標位置的橫坐標)。如果自車與道路邊界或其他交通參與者發生碰撞,則立即終止該回合,并重置環境生成障礙車輛,訓練場景如圖2所示,紅色車輛為自車。將訓練好的模型在圖3所示的6個左轉場景進行測試。
2.1 圖像獲取與預處理
在訓練自動駕駛左轉任務前,需要先訓練VAE編碼器和解碼器。手動駕駛汽車分別采樣10 000和2 000張語義圖像作為訓練集和測試集。訓練過程學習率調整規則如下:
τ=ξ(lold-l)(15)
其中:l和lold分別為當前時刻的損失函數和上一時期的損失函數,設定10個訓練回合為1個時期;ξ表示閾值系數;τ為閾值。當τ大于學習率lr時,表明在當前學習率下模型沒有顯著改善。此時更新學習率為
lnewr=δlr(16)
VAE算法訓練結果如圖4所示,根據學習率衰減規則,學習率表現出梯形下降的趨勢。隨著學習率的衰減,訓練損失和測試損失也表現出相應的減小趨勢,隨著學習率的降低這種趨勢逐漸減緩,且當學習率更新時損失值再次下降。隨著訓練次數的增加,模型逐漸學習到訓練數據的特征和分布,從而使得訓練損失逐漸減小。在測試數據上進行驗證時,模型面臨著未曾見過的樣本,測試損失會高于訓練損失。
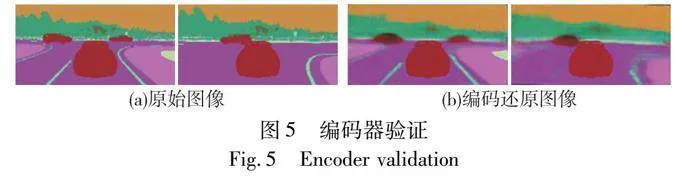
在仿真環境中采集新的圖片,驗證編碼器的性能,如圖5所示。將圖像傳遞給編碼器進行壓縮編碼后,還原圖像的清晰度有所下降,但保留了環境的關鍵信息,如車道線和障礙物等重要元素。
2.2 對比實驗
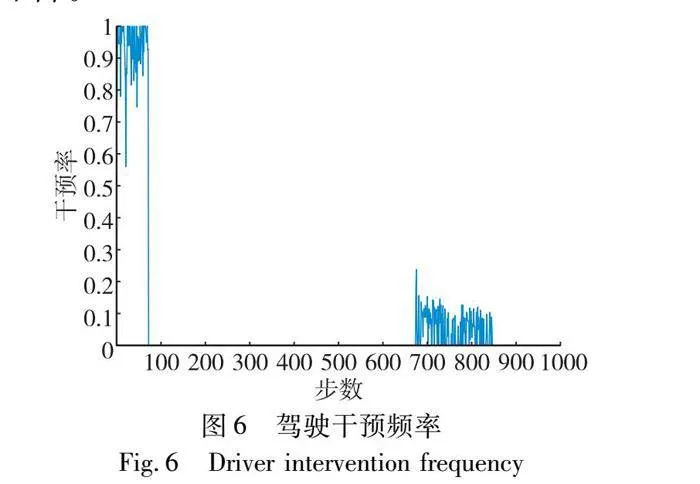
訓練初始階段,持續性干預80個回合,收集足夠的駕駛數據,使模型在訓練初期具有較好的學習經驗。當模型性能接近駕駛員駕駛時(獎勵值達到設定的臨界條件),進行間歇性干預。當外接設備的輸入不全為0時視為駕駛干預,否則為模型駕駛。訓練過程的干預頻率如圖6所示。根據設定的駕駛規則,前80次的干預頻率接近1。當訓練次數達到663時,模型的性能達到設定的臨界值,這時僅依靠起始給定的駕駛干預經驗難以繼續提升模型的性能。一些極端的情況下,如路口多輛車正在通行,模型難以學習到最優決策。此時,依賴駕駛員的經驗指導,使模型能夠作出更優的決策。隨著訓練次數的增加,模型的性能逐步提升,對駕駛員的依賴逐漸下降。
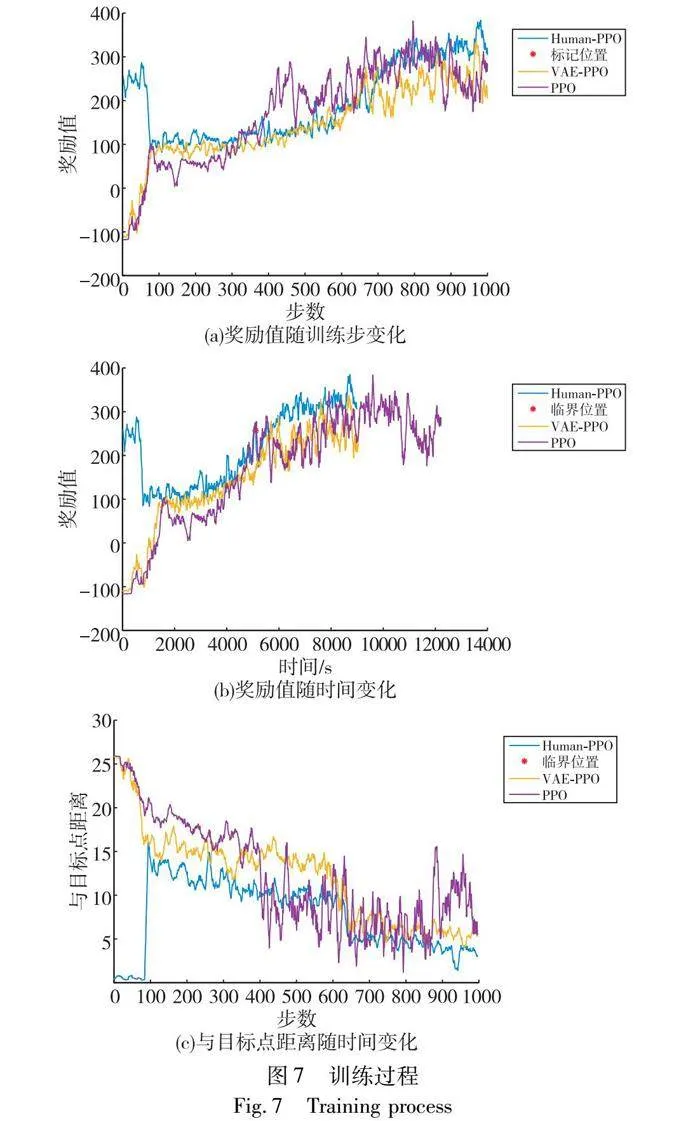
訓練初期,Human-PPO模型處于駕駛干預狀態時具有較高的獎勵值(如圖7(a)所示)。當撤回干預時,由于Human-PPO具備優質的學習數據,其獎勵值依然高于VAE-PPO和PPO模型。當Human-PPO模型的獎勵值達到設定的臨界位置時,進行間歇性干預,模型的獎勵值繼續提高,最終達到高于駕駛員駕駛時的獎勵值,且高于VAE-PPO和PPO模型的獎勵值,表明人機交互式學習策略在自動駕駛強化學習中克服局部最優的有效性。
VAE-PPO算法訓練初期需要不斷探索收集駕駛經驗,因此獎勵值初始狀態較低。隨著訓練的進行,獎勵值不斷提高,當獎勵值達到280左右時,模型滿足于當前的狀態,難以探索到更好的狀態,獎勵值持續穩定在280附近。PPO模型在420步時達到相對較好的性能,之后獎勵值在200~400波動。訓練過程中,由于每回合場景的隨機性,若當前訓練回合為圖3(a)所示場景,不存在干擾車輛,自車可以獲得最大的安全獎勵并保持目標車速行駛,若當前訓練回合是圖3(b)~(e)場景時,由于場景中干擾車輛的復雜性不同,處于不同場景時獎勵值也波動較大,最終模型的獎勵值波動范圍較大。
當使用PPO算法時,模型在420步的獎勵值高于Human-PPO和VAE-PPO模型。由于使用原始圖像(160×80×3)相較于編碼后的圖像(95×1)內存占用擴大了384倍,增加了計算資源的消耗,延長了模型的學習周期。如圖7(b)所示,從訓練時間上看,PPO模型的訓練進程顯著緩慢。對比而言,Human-PPO模型展現了最短的訓練時間,表明將人工干預機制與VAE和PPO算法結合使用,在降低狀態空間維度、減少計算負擔、提升模型學習效率方面具有顯著優勢。
Human-PPO模型駕駛干預初期,駕駛員能夠準確地找尋到目標位置,回合結束時距離目標位置的距離接近于0(圖7(c))。當撤回駕駛干預,回合結束時,模型與目標點的距離迅速增加,但仍然低于無干預時與目標點的距離。當訓練達到臨界條件實施間歇性干預,隨著模型的訓練,回合結束時,與目標點的距離呈減小的趨勢,Human-PPO模型距離目標點的距離穩定在3附近,VAE-PPO穩定在5附近。相較于編碼后的圖像作為輸入,由于PPO模型使用原始圖像作為輸入,對復雜場景的泛化性差,離目標點的距離波動較大。
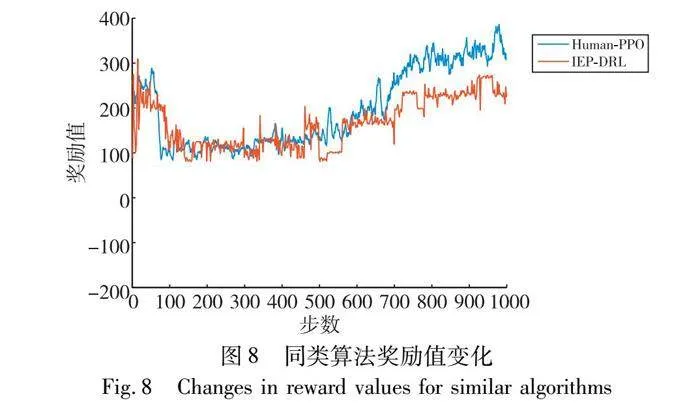
圖8所示為模仿專家先驗的強化學習(imitative expert priors)與IEP-DRL[14]的對比,撤回持續性干預后IEP-DRL的獎勵值與Human-PPO接近,隨著訓練的進行,Human-PPO算法的獎勵值逐漸高于IEP-DRL。由于訓練前期模型的探索率比較高,難以比較出兩種算法的優越性,隨著訓練的進行,模型探索率下降,此時的獎勵值能夠準確反映兩種算法的訓練情況。
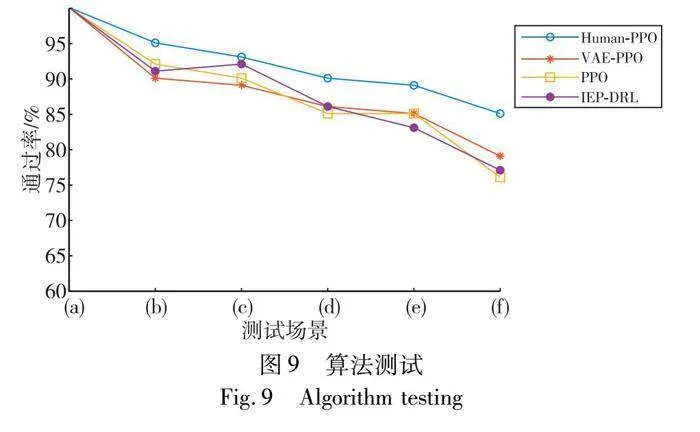
圖9為模型在圖3測試場景中測試100回合的結果。當沒有其他交通參與者的情況下,各模型均能夠順利完成左轉任務。在復雜場景時,VAE-PPO模型的表現能力明顯下降,這主要是因為在復雜環境中,相比于模型自主探索而言,依賴駕駛員的引導來獲得最優決策能夠取得更好的效果。PPO模型的成功率隨著場景復雜度的提高迅速下降,這表明經VAE編碼后的圖像特征轉換對于提升模型的泛化性和魯棒性具有顯著作用。IEP-DRL算法在場景(f)下性能急劇下滑,表明模仿的專家策略在面對全新場景時魯棒性較差。
3 結束語
在自動駕駛模型的訓練過程中加入駕駛干預,使用了兩種不同的干預模式。在初始階段,采用手動駕駛方式積累的駕駛經驗,能夠更快地將模型引導到正確的駕駛決策,避免了訓練初期長時間的靜止狀態。這有助于模型更快地掌握有效的駕駛技能,對于模型的性能提升具有顯著作用,使模型在訓練初期就具備較好的駕駛決策能力,從而加速學習過程。在模型接近駕駛員駕駛水平時,模型在一定程度上難以進一步提升性能。采用間歇性的干預調整策略,在必要時糾正模型的錯誤決策,幫助模型更好地適應復雜的駕駛場景,模型的性能進一步提升。這表明駕駛干預對于克服性能瓶頸具有積極的作用。通過在DRL中引入駕駛干預機制,自動駕駛模型在訓練過程中能夠更快、更有效地學習駕駛技能,提高在復雜駕駛情境下的性能表現。盡管駕駛干預在訓練中有積極的影響,仍然需要注意一些潛在的挑戰,例如,訓練過程中實時的駕駛干預依賴于駕駛員的專業度,且連續的駕駛干預對駕駛員的靜力和體力也是一項挑戰。如何保留駕駛干預機制,而又不過于依賴駕駛員,將是后續研究的重點。
參考文獻:
[1]Isele D,Rahimi R,Cosgun A,et al.Navigating occluded intersections with autonomous vehicles using deep reinforcement learning[C]//Proc of IEEE International Conference on Robotics and Automation.Piscataway,NJ:IEEE Press 2018:2034-2039.
[2]許宏鑫,吳志周,梁韻逸.基于強化學習的自動駕駛汽車路徑規劃方法研究綜述[J].計算機應用研究,2023,40(11):3211-3217.(Xu Hongxin,Wu Zhizhou,Liang Yunyi.Reinforcement learning auto drive system based on visual feature extraction[J].Application Research of Computers,2023,40(11):3211-3217.)
[3]陳越,焦朋朋,白如玉,等.基于深度強化學習的自動駕駛車輛跟馳行為建模[J].交通信息與安全,2023,41(2):67-75,102.(Chen Yue,Jiao Pengpeng,Bai Ruyu,et al.Modeling of car following behavior in autonomous vehicles based on deep reinforcement learning[J].Traffic Information and Safety,2023,41(2):67-75,102.)
[4]段續庭,周宇康,田大新,等.深度學習在自動駕駛領域應用綜述[J].無人系統技術,2021,4(6):1-27.(Duan Xuting,Zhou Yukang,Tian Daxin,et al.A review of the application of deep learning in the field of autonomous driving[J].Unmanned Systems Technology,2021,4(6):1-27.)
[5]趙星宇,丁世飛.深度強化學習研究綜述[J].計算機科學,2018,45(7):1-6.(Zhao Xingyu,Ding Shifei.A review of research on deep reinforcement learning[J].Computer Science,2018,45(7):1-6.)
[6]Cui Jianping,Yuan Liang,He Li,et al.Multi-input autonomous driving based on deep reinforcement learning with double bias experience replay[J].IEEE Sensors Journal,2023,23(11):11253-11261.
[7]Yi Liming.Lane change of vehicles based on DQN[C]//Proc of the 5th International Conference on Information Science,Computer Technology and Transportation.Piscataway,NJ:IEEE Press,2020:593-597.
[8]Tseng K K,Yang Hong,Wang Haoyang,et al.Autonomous driving for natural paths using an improved deep reinforcement learning algorithm[J].IEEE Trans on Aerospace and Electronic Systems,2022,58(6):5118-5128.
[9]Neftci E O,Averbeck B B.Reinforcement learning in artificial and biological systems[J].Nature Machine Intelligence,2019,1(3):133-143.
[10]Littman M L.Reinforcement learning improves behaviour from evalua-tive feedback[J].Nature,2015,521(7553):445-451.
[11]Vecerik M,Hester T,Scholz J,et al.Leveraging demonstrations for deep reinforcement learning on robotics problems with sparse rewards[EB/OL].(2017-07-27)[2023-10-11].https://arxiv.org/abs/1707.08817.
[12]馮忠祥,李靖宇,張衛華,等.面向人機共駕車輛的駕駛人風險感知研究綜述[J].交通信息與安全,2022,40(2):1-10.(Feng Zhongxiang,Li Jingyu,Zhang Weihua,et al.A review of research on driver risk perception for human-machine co driving vehicles[J].Traffic Information and Safety,2022,40(2):1-10.
[13]Li Quanyi,Peng Zhenghao,Zhou Bolei.Efficient learning of safe dri-ving policy via human-AI copilot optimization[EB/OL].(2022-02-17)[2023-10-11].https://arxiv.org/abs/2202.10341
[14]Huang Zhiyu,Wu Jingda,Lyu Chen.Efficient deep reinforcement learning with imitative expert priors for autonomous driving[J].IEEE Trans on Neural Networks and Learning Systems,2022,34(10):7391-7403.
[15]Wu Jingda,Huang Zhiyu,Huang Wenhui,et al.Prioritized experience-based reinforcement learning with human guidance for autonomous driving[J].IEEE Trans on Neural Networks and Learning Systems,2024,35(1):855-869.
[16]Ramachandran S,Horgan J,Sistu G,et al.Fast and efficient scene categorization for autonomous driving using VAEs[EB/OL].(2022-10-26)[2023-10-11].https://arxiv.org/abs/2210.14981.
[17]Schulman J,Wolski F,Dhariwal P,et al.Proximal policy optimization algorithms[EB/OL].(2017-07-20)[2023-10-11].https://arxiv.org/abs/1707.06347.
[18]Schaul T,Quan J,Antonoglou I,et al.Prioritized experience replay[EB/OL].(2015-11-18)[2023-10-11].https://arxiv.org/abs/1511.05952.
收稿日期:2024-01-03
修回日期:2024-03-14
基金項目:國家自然科學基金資助項目(52175236)
作者簡介:時高松(1998—),男,河南南陽人,碩士研究生,CCF會員,主要研究方向為自動駕駛路徑規劃(2022020464@qdu.edu.cn);趙清海(1985—),男,山東濰坊人,副教授,碩導,博士,主要研究方向為輕量化車輛結構設計;董鑫(1999—),男,山東濱州人,碩士研究生,主要研究方向為自動駕駛路徑規劃;賀家豪(2003—),男,濟寧嘉祥人,本科生,主要研究方向為自動駕駛路徑規劃;劉佳源(2004—),男,山東濰坊人,本科生,主要研究方向為自動駕駛路徑規劃.
