基于CSLS-CycleGAN的側掃聲納水下目標圖像樣本擴增法
2024-11-22 00:00:00湯寓麟王黎明余德熒李厚樸劉敏張衛東
系統工程與電子技術 2024年5期




摘 要:
針對側掃聲納水下目標圖像稀缺,獲取難度大、成本高,導致基于深度學習的目標檢測模型性能差的問題,結合光學域類目標數據集豐富的現狀,提出一種基于通道和空間注意力(channel and spatial attention, CSA)模塊、最小二乘生成對抗生成網絡(least squares generative adversarial networks, LSGAN)及循環對抗生成網絡(cycle generative adversarial networks, CycleGAN)的側掃聲納水下目標圖像樣本擴增方法。首先,受CycleGAN的啟發,設計基于循環一致性的單循環網絡結構,保證模型的訓練效率。然后,在生成器中融合CSA模塊,減少信息彌散的同時增強跨緯度交互。最后,設計了基于LSGAN的損失函數,提高生成圖像質量的同時提高訓練穩定性。在船舶光學域數據集與側掃聲納沉船數據集上進行實驗,所提方法實現了光學-側掃聲納樣本間信息的高效、穩健轉換以及大量側掃聲納目標樣本的擴增。同時,基于本文生成樣本訓練后的檢測模型進行了水下目標檢測,結果表明,使用本文樣本擴增數據訓練后的模型在少樣本沉船目標檢測的平均準確率達到了84.71%,證明了所提方法實現了零樣本和小樣本水下強代表性目標樣本的高質量擴增,并為高性能水下目標檢測模型構建提供了一種新的途徑。
關鍵詞:
樣本擴增; 側掃聲納; 循環生成對抗網絡; 通道和空間注意力模塊; 最小二乘生成對抗網絡
中圖分類號:
P 227
文獻標志碼: A""" DOI:10.12305/j.issn.1001-506X.2024.05.06
CSLS-CycleGAN based side-scan sonar sample augmentation
method for underwater target image
TANG Yulin1, WANG Liming1,*, YU Deying1, LI Houpu1, LIU Min2, ZHANG Weidong3
(1. College of Electrical Engineering, Naval University of Engineering, Wuhan 430033, China;
2. Unit 91001 of the PLA, Beijing 100841, China; 3. Unit 31016 of the PLA, Beijing 100088, China)
Abstract:
In view of the scarcity, difficulty and high cost of side-scan sonar underwater target images, and the poor performance of deep-learning based target detection model, combined with the abundant target data set in optical domain, a sample augmentation method for underwater target side-scan sonar images based on channel and spatial attention(CSA) module and least squares generative adversarial networks(LSGAN) and cycle generative adversarial networks(CycleGAN) is propesed. Firstly, inspired by CycleGAN, a single cycle network structure based on cycle consistency is designed to ensure the training efficiency of the model. Then, the CSA module is integrated into the generator to reduce information dispersion while enhancing cross-latitude interaction. Finally, a loss function based on LSGAN is designed to improve the quality of the generated image while improving the training stability. Experiments are carried out on ship optical domain data set and side-scan sonar shipwreck data set. The results show that the proposed method achieves efficient and robust conversion of information between optical and side-scan sonar samples and augmentation of a large number of side-scan sonar target samples. At the same time, the underwater target detection is carried out based on the detection model generated after sample training in this paper. The results show that the average precision value of the model after training with sample augmentation data in this paper reachs 84.71% in detecting shipwreck targets with few samples, which proves that the method in this paper achieves high-quality amplification of highly representative underwater target samples with zero samples and small samples. It also provides a new way to construct high-performance underwater target detection model.
Keywords:
sample augmentation; side-scan sonar; cycle generative adversarial networks (CycleGAN); channel and spatial attention (CSA) module; least squares generative adversarial networks (LSGAN)
0 引 言
水下目標探測在航行安全、海洋調查、海上搜救、軍事任務等領域具有非常重要的作用[1]。目前,水下目標探測的方法主要包括聲探、磁探、光探、電探等,其中聲波因其水中成像條件、傳播距離以及范圍的優勢成為目前主流的水下目標探測方式[2-4]。側掃聲納較其他聲學設備擁有更寬的掃幅和更高的成像分辨率,且體積小、價格低廉,在水下目標探測中應用廣泛[5-9]。
目前,基于側掃聲納圖像的水下目標檢測多基于人工目視判讀,存在效率低、耗時長、主觀依賴性強等問題[10]。因此,針對側掃聲納圖像的水下目標自動探測方法研究十分必要[11]。
部分學者采用機器學習方法,聯合人工特征和分類器實現水下目標的自動探測,在一定條件下取得了較好的探測效果[12-13]。但受復雜海底環境和測量條件的影響,側掃聲納圖像通常存在低分辨率、特征貧瘠、噪聲復雜以及畸變嚴重等特點,使傳統的機器學習方法探測精度受到限制[14-16]。近年來,計算機視覺領域發展迅速,基于深度學習的目標檢測方法性能遠超傳統機器學習方法,引起了水下探測領域的廣泛關注[17-24]。然而,基于深度卷積神經網絡(deep convolutional neural network, DCNN)的目標探測模型需要大量訓練樣本,高代表性樣本是實現高性能探測的關鍵[25]。而側掃聲納圖像因數據采集成本高、耗時長、目標較少等問題導致數量嚴重匱乏,樣本代表性不足[26]。因此,急需開展小樣本水下目標側掃聲納圖像的樣本擴增。
受光學影像中樣本擴增技術的啟發,側掃聲納水下目標樣本擴增方法主要通過遷移學習[27-30]方法獲得,但是在遷移轉換模型訓練時無法全面顧及聲波發射單元、聲波傳播介質、聲波反射目標、聲波反射背景場、聲波接收單元、噪聲和數據后處理等七大類要素的影響[31-32],生成樣本代表性弱,對基于DCNN的目標探測網絡泛化能力和精度提升有限。
近年來,隨著生成對抗網絡(generate adversarial networks, GAN)的迅速發展,其被廣泛地應用于利用外源圖像進行風格遷移的任務中,其核心邏輯是通過生成網絡和判別網絡相互對抗、博弈最終生成判別網絡無法判別真偽的高質量圖像,具有比傳統機器學習更強、更全面的特征學習和表達能力。Isola等[33]提出了Pix2Pix模型,首次實現了基于GAN的圖像遷移任務,但該網絡要求的輸入必須是成對圖像,不適用于側掃聲納圖像的樣本擴增。為解決成對數據的限制,Zhu等[34]設計了循環GAN(cycle GAN, CycleGAN),通過非成對數據的非監督學習實現風格遷移任務。受CycleGAN啟發,李寶奇等[35]通過基于循環一致性的改進CycleGAN實現水下小目標光學圖像到合成孔徑聲納圖像的遷移生成。但是,由于側掃聲納水下目標圖像的高噪聲、不同環境下差異大的特點,在使用非配對光學-側掃聲納圖像訓練時,生成器難以提取圖像特征從而生成與目標域相似的圖像來“欺騙”判別器,進而造成模型振蕩或生成器和判別器之間的不平衡,從而導致模型過擬合或模式崩潰。另外,側掃聲納圖像特征貧瘠、輻射畸變大的特點導致模型在轉換過程中容易混淆背景與目標特征,丟失目標輪廓、紋理和噪聲,而這些恰恰是側掃聲納圖像的關鍵。
綜上,本文提出了一種基于通道和空間注意力(channel and spatial attention, CSA)模塊、最小二乘GAN(least squares GAN, LSGAN)及CycleGAN(簡稱為CSLS-CycleGAN)的水下目標側掃聲納圖像樣本擴增方法。首先,設計基于循環一致性的單循環網絡結構,保證模型的訓練效率以及任務的專注度。其次,在生成器中融合CSA模塊,減少信息彌散的同時增強跨緯度交互,在學習全局特征的同時關注目標的細粒度特征。然后,設計了基于LSGAN的損失函數,提高生成圖像質量的同時提高訓練穩定性,避免模式崩潰的情況。最后,基于該轉換模型,將船舶目標光學圖像轉換為側掃聲納圖像,實現樣本高質量擴增,以期解決側掃聲納水下目標圖像稀缺,為小樣本水下強代表性目標樣本擴增以及高性能水下目標檢測模型構建提供了一種新的途徑。
1 CSLS-CycleGAN
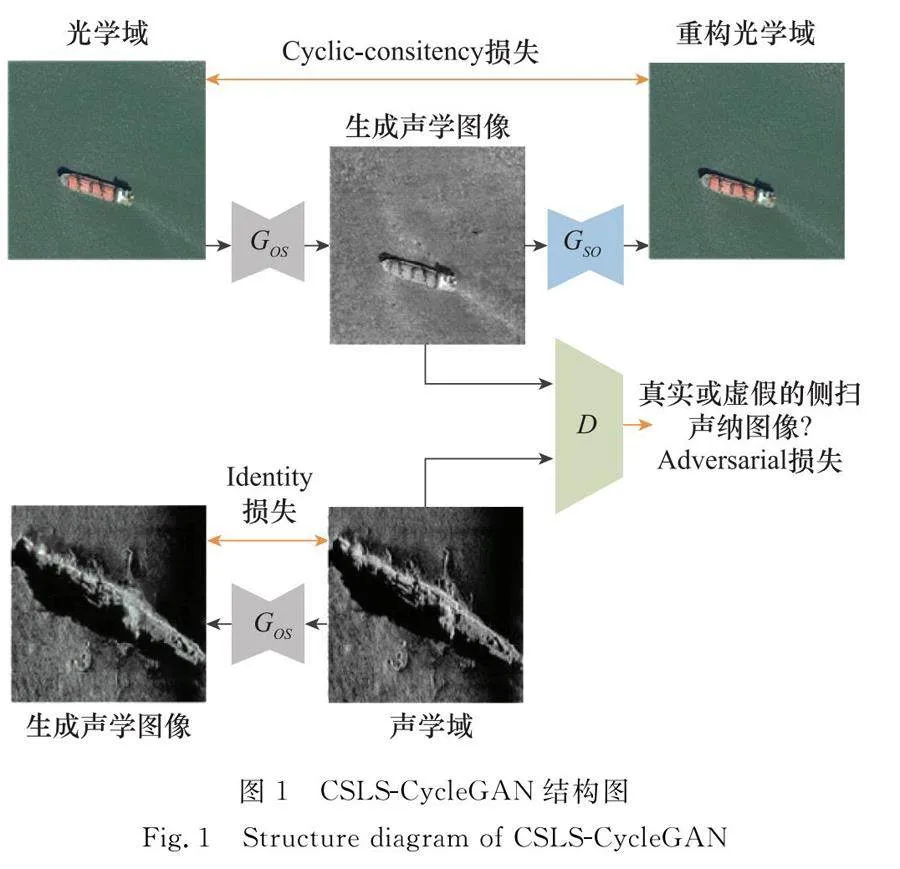
足夠數量的強代表性樣本是訓練高性能探測模型的前提,是最終形成高性能智能探測模型的關鍵組成。使用GAN實現水下目標雙域轉換以及側掃聲納水下目標圖像樣本擴增是本文的重要組成,網絡的使用是實現高質量樣本擴增的關鍵。針對光學圖像與側掃聲納圖像風格差異較大的問題,傳統的GAN存在生成數據質量較差,甚至兩個域的圖像沒有任何匹配關系的問題。為了讓生成圖片與輸出圖像產生強關聯,本文使用基于單循環一致性的GAN,在保證訓練效率的同時重點關注光學域向聲學域的轉換任務。同時,在生成器中融合CSA模塊,減少信息彌散的同時增強跨緯度交互。最后,設計了基于LSGAN的組合損失函數,提高生成圖像質量的同時提高模型訓練的穩定性。本文提出網絡的具體結構圖如圖1所示。
1.1 網絡結構
本文模型主體由兩個生成器Gos、Gso和一個判別器D組成,將從光學域中的圖像轉換成聲學域的圖像的生成器稱為Gos,從聲學域中的圖像轉換成光學域的圖像生成器稱為Gso,將判別圖像屬于聲學域或虛假的判別器稱為D。
原始輸入光學圖像通過生成器Gos獲得側掃聲納圖像S后,將生成的側掃聲納圖像作為輸入通過生成器Gso獲得與光學圖像相同域的圖像重構光學圖像,最終保持光學圖像與重構光學圖像一致,讓圖像循環了一周回到起點并保持一致。生成器結構如圖2所示。
首先,使用3個卷積層對輸入圖像進行特征提取,每個卷積層后使用實例歸一化(instance normalization, IN)操作以及ReLU激活函數,IN操作僅對單張圖像的像素進行均值和標準差的計算,避免了批量歸一化(batch normalization, BN)中一批圖像之間的相互影響,且擁有更高的效率。其次,使用注意力機制CSA模塊對圖像通道和空間特征進行全局學習,建立局部細節特征與全局特征的交互關系,并通過跳躍連接實現多尺度特征融合。然后,使用6個殘差網絡在進一步提取圖像信息的同時對輸入數據特征進行保留。接著,使用2個轉置卷積進行上采樣操作。最后,再連接一個卷積層,獲取的圖像矩陣經函數激活Tanh獲得最后的輸出圖像。
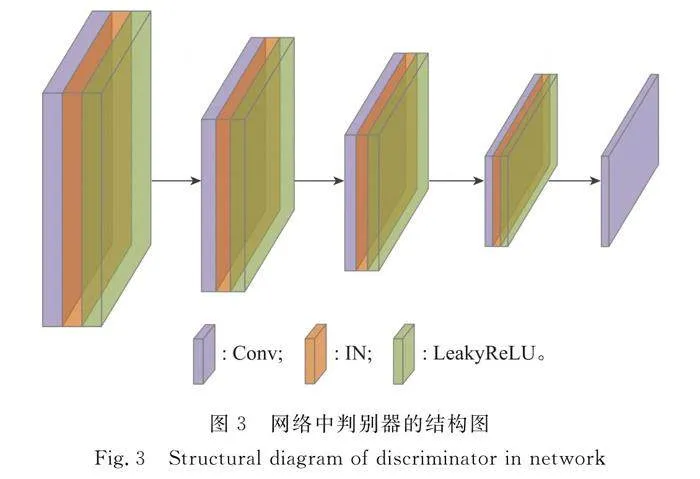
為加強輸入數據與輸出數據之間的關系,采用殘差網絡代替深層的卷積網絡。通過特征提取層提取特征,再將特征數據傳遞給輸出層,避免生成器損失輸入層的一些基本信息,保留輸入數據的部分特征,更好地保護原始圖像信息的完整性,解決傳統神經網絡隨網絡深度的增加而梯度消失明顯的問題,加快模型的訓練速度,改善模型的訓練效果。判別器結構如圖3所示。
判別器使用5個卷積層對輸入圖像進行特征提取,每個卷積層后使用IN操作以及LeakyReLU激活函數,其中最后一層卷積層直接返回線性操作結果。
1.2 CSA模塊
對側掃聲納圖像的目標細節特征與背景特征充分學習是生成高質量圖像的關鍵,為了更好地對輸入圖像的全局信息以及局部特征進行學習,增強通道與空間的相互作用,本文設計了一種跨越通道和空間緯度的CSA模塊,通過減少信息彌散的同時放大全局的跨緯度交互以提高網絡性能。CSA模塊由通道注意力和空間注意力組成,具體結構如圖4所示。
本文通道注意力和空間注意力模塊采用并行計算,將各自輸出的權重系數與初始輸入特征圖進行元素相乘后,再進行兩者特征信息的逐元素相加,在提高效率的同時放大跨緯度的感受域。
Ioutput=(Mc(I)·I)+(Ms(I)·I)(1)
式中:Mc(I)和Ms(I)分別為通道注意力和空間注意力模塊的特征輸出,對各模塊的具體描述如下。
1.2.1 通道注意力
通道注意力強調模型應該關注什么特征,其每個通道都包含一個特定的特征響應。首先,將輸入的特征I(H×W×C)分別經過基于寬和高的全局最大池化和全局平均池化,得到兩個1×1×C的特征圖。其次,再將其分別送入一個兩層感知器(multilayer perceptron, MLP),第1層神經元個數為C/r(r為減少率),激活函數為ReLU,第2層神經元個數為C,這個兩層的神經網絡是共享的。然后,將MLP輸出的特征進行基于逐元素的加和操作后經過Sigmoid激活函數,生成最終的通道注意力特征,即Mc。最后,將Mc和特征I做逐元素乘法操作可得到縮放后的新特征:
Mc(I)=σ(MLP(AvgPool(I))+MLP(MaxPool(I)))=
σ(W1(W0(ICAvg))+W1(W0(ICMax)))(2)
式中:σ為Sigmoid激活函數;W0∈RCr×C,W1∈RC×Cr,兩者為MLP共享網絡的權重。
1.2.2 空間注意力
空間注意力強調模型關注的特征在哪里,即增強或抑制不同空間位置的特征。首先將輸入的特征I(H×W×C)做一個基于通道的全局最大池化和全局平均池化,得到兩個H×W×1的特征圖后進行基于通道的拼接操作。其次,通過一個7×7卷積核的卷積操作將圖像降維為1個通道。然后,通過Sigmoid激活函數生成空間注意力特征,即Ms。最后,將Ms和特征I做逐元素點乘乘法,得到最終生成的特征。
Ms(I)=σ(f7×7([AvgPool(I),MaxPool(I)]))=
σ(f7×7([ISAvg,ISMax]))(3)
式中:σ為Sigmoid激活函數;f7×7為卷積核為7×7的卷積操作。
圖像初始特征學習熱力圖如圖5所示,可以看出CSA模塊能動態地抑制或強調特征的映射,有效避免了關鍵目標特征變成背景特征的情況。
1.3 損失函數
合適的損失函數對GAN生成圖像的質量提升起到了至關重要的作用。從提出的網絡架構圖可以看出,其損失函數由LSGAN損失、Cyclic-consitency損失以及Identity損失3部分組成。LSGAN損失指導生成器生成更加逼真目標域的圖像;Cyclic-consitency損失指導生成器生成的圖像與輸入圖像盡可能的接近;Identity損失限制生成器無視輸入數據。
1.3.1 LSGAN損失
傳統GAN使用交叉熵作為損失函數,該函數不優化被判別器判定為真實圖像的圖像,即使這些圖像與判別器的決策邊界仍然很遠,導致生成器生成的圖像質量不高以及模型訓練不穩定。為此,本文采用了LSGAN中目標函數作為模型的損失函數,即采用最小二乘作為損失函數。
minD VLSGAN(D)=12Es~Pdata(s)[(D(s)-b)2]+
12Ez~Pz(z)[(D(G(z))-a)2](4)
minG VLSGAN(G)=12Ez~Pz(z)[(D(G(z))-c)2](5)
式中:Pdata(s)表示真實數據分布;s表示生成的數據與真實數據之間的誤差;G表示生成器;Pz(z)表示輸入噪聲的先驗分布。
在判別器D的目標函數中,給真實數據和生成數據賦予編碼b與a,b=1表示為真實數據,a=0表示為生成數據,通過最小化判別器判別生成數據與0的誤差以及真實數據s與1的誤差,實現判別器的最優化。在生成器Gos的目標函數中,給生成數據賦予編碼c,通過最小化生成器生成數據z與1的誤差,指導生成器成功欺騙判別器從而獲得高分,此時c=1。因此,將式(4)和式(5)分別轉化為
minD VLSGAN(D)=12Es~Pdata(s)[(D(s)-1)2]+
12Ez~Pz(z)[(D(G(z)))2](6)
minG VLSGAN(Gos)=12Ez~Pz(z)[(Dos(G(z))-1)2](7)
1.3.2 Cyclic-consitency損失
為實現循環一致性,即要求從光學域轉換為聲學域時滿足
xGos(x)Gso(Gos(x))≈x(8)
數學公式表達如下:
Lcyc(Gos,Gso)=Ex~Pdata(x)[Gso(Gos(x))-x1](9)
式中:1-范數為矩陣1-范數,表示所有矩陣的列向量中元素絕對值之和最大的值。
X1=maxj∑mi=1|ai,j|(10)
1.3.3 Identity損失
Identity損失用于限制生成器無視輸入數據而去自主修改圖像顏色的情況,表示若將聲學域圖像送入生成器Gos中,那么應盡可能得到本身,具體損失函數如下:
LIdentity(Gos)=Es~Pdata(s)[(Gos(s)-s)1](11)
因此,網絡的總損失函數如下:
Losscyc=minD VLSGAN(D)+minG VLSGAN(Gos)+
λ1Lcyc(Gos,Gso)+λ2LIdentity(Gos)(12)
式中:λ1和λ2為非負超參數,用于調整損失對整體效果的不同影響。衡量每一個損失,以平衡每一個組成部分的重要性。
2 實 驗
基于CSLS-CycleGAN的側掃聲納圖像樣本擴增是本文方法的重要組成,為評估本文方法的可行性和有效性,本實驗對提出的GAN性能進行評估。通過外源光學船舶圖像和側掃聲納沉船圖像雙域轉換的性能對提出模型進行評估,包括與主流GAN進行比對,并對生成的圖像的質量進行定性定量的分析;生成圖像對YOLOv5目標檢測模型的檢測性能提升的作用;以及通過消融實驗對GAN中使用策略的有效性進行定性與定量的分析。
2.1 數據集
本文用于實驗的數據集主要由側掃聲納沉船圖像以及衛星光學船舶數據組成。側掃聲納沉船數據集由各海道測量部門和國內外主流側掃聲納儀器設備,在多區域實測獲得的600張側掃聲納沉船圖像組成,部分樣本如圖6(a)所示。衛星光學船舶數據集由部分HRSC2016組成,本實驗挑選其中代表性強的數據共5 000張,部分樣本如圖6(b)所示。
2.2 評價指標
根據文獻[36]的研究,FID(Frechet inception distance)、最大平均差異(maximum mean discrepancy, MMD)和1-最近鄰分類器(1-nearest-neighbor, 1-NN)相比其他指標可以更好地評價生成樣本的清晰度、特征的多樣性和圖片的真實性。
FID是計算真實圖像與生成圖像的特征向量之間距離的度量,用于度量兩組圖像的相似度,FID的計算方法為
FID=μr-μg2+tr(Σr+Σg-2ΣrΣg)(13)
式中:μr和μg分別為兩個分布的均值向量;Σr和Σg為其協方差矩陣;·為向量的范數。FID值越小,圖像增強效果越好。
MMD基于最大均方差的統計檢驗來度量兩個特征分布之間的相似性,將真實集和生成集映射到具有固定核函數的核空間,然后計算兩個分布之間的平均差。MMD的計算公式為
MMD2(X,Y)=E[K(Xi,Xj)-2K(Xi,Yj)+K(Yi,Yj)](14)
式中:X代表真實圖像集;Xi和Xj是從X中提取的樣本;Y代表生成的圖像集;Yi和Yj是從Y中提取的采樣;E代表期望值;K是高斯核。較低的MMD值表示更有效的圖像增強。
1-NN使用二值分類器將n個實數集(標記為1)與n個生成集(標記為0)混合,然后隨機分為訓練集T1(編號為2n-1)和測試集T2(編號為1),用T1訓練分類器,用T2獲得分類精度,以此來計算兩個圖像集之間的相似性。以上步驟循環2n次,每次選擇不同的T2,最后計算平均分類準確率。精確度越接近0.5越好。
同時,考慮到本文的目的是對匱乏的側掃聲納水下目標圖像進行樣本擴增,來提高基于深度學習的目標檢測模型的性能,因此接下來本文使用基于深度學習的目標檢測模型進行對比實驗。目前,目標檢測模型非常多,由于本文的目的在于驗證擴增樣本的有效性,因此本文最終采用高速、輕量、易于部署的YOLOv5模型進行評價實驗。將GAN模型生成的圖像作為訓練集輸入YOLOv5網絡,將真實圖像作為驗證集,通過召回率、精度和平均精度來評估生成的圖像在檢測網絡中的有效性。
2.3 實驗設計
模型訓練均基于Pytorch框架用Python語言實現,硬件環境為:Windows10操作系統;CPU為Intel(R) Core(TM) i9-10900X@3.70 GHz; GPU為2塊NVIDIA GeForce RTX 3090,并行內存48 GB。
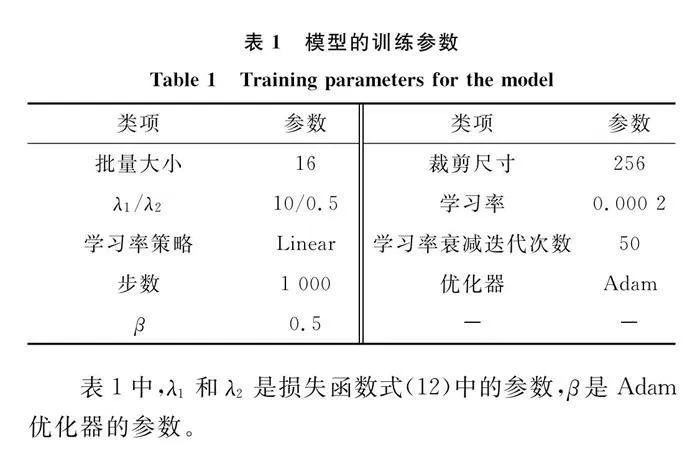
HRSC2016數據集由于原始圖像像素過大且大部分均為背景,在訓練模型時反而是一種負擔,因此所有光學圖像數據均在保留目標的基礎上統一設置為250×250。將側掃聲納沉船圖像按5∶1劃分訓練集和評估集,船舶光學圖像按9∶1劃分為訓練集和轉換集。側掃聲納圖像的評估集和光學圖像的轉換集用以進行生成圖像質量的定量分析。為減少訓練時的震蕩,讓模型訓練更加的穩定,本實驗在訓練時引入緩存歷史數據的方式。使用list存儲之前10張圖像,每次訓練判別器時從list中隨機抽取一張進行判別,讓判別器可以持有判別任意時間點生成器生成圖像的能力。模型訓練的參數如表1所示。
表1中,λ1和λ2是損失函數式(12)中的參數,β是Adam優化器的參數。
2.4 實驗與分析
2.4.1 定量分析
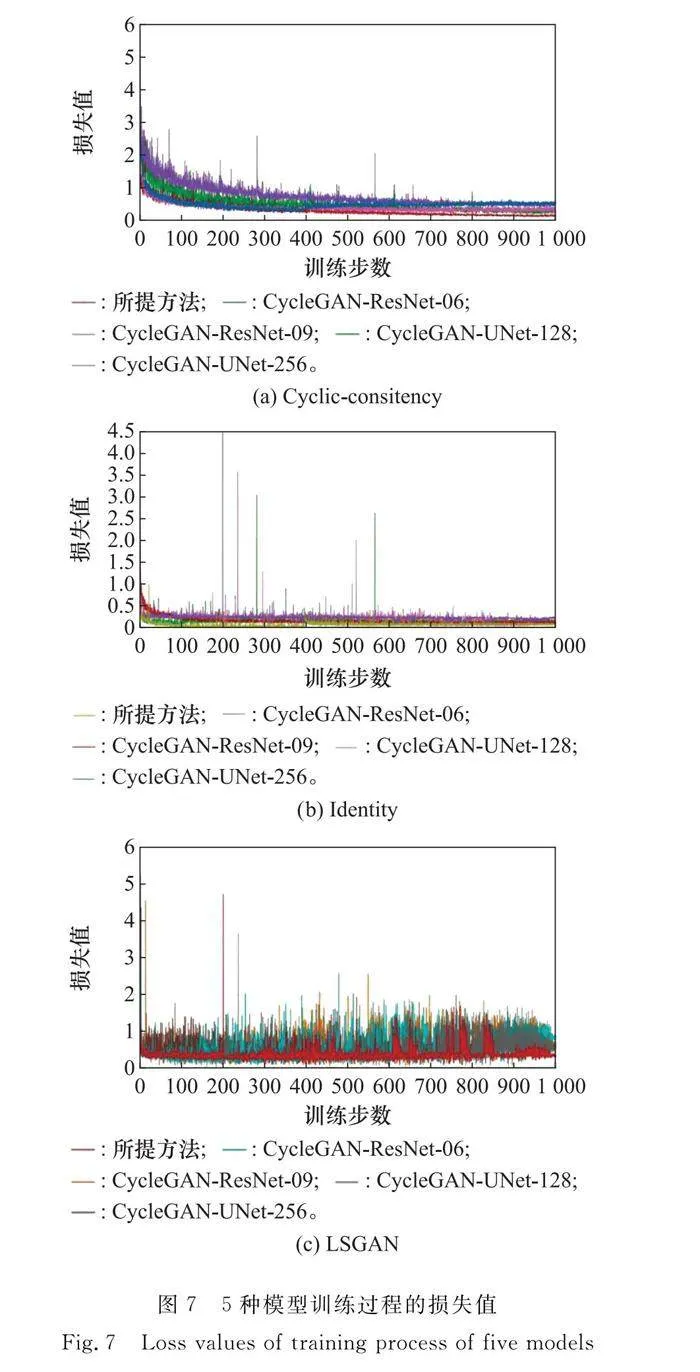
本節首先對模型的訓練過程以及性能進行分析和評估。本文提出的網絡最初受CycleGAN啟發,將本文提出的模型與不同結構的CycleGAN模型(即生成器采用ResNet-06、ResNet-09、UNet-128、UNet-256基礎網絡)進行比較,結果如圖7所示。
從圖7可以看出,5種模型的損失值均隨著訓練步數的增加而不斷減小并最終趨于穩定,達到擬合狀態。其中,本文提出的網絡在Cyclic-consitency損失、LSGAN損失以及Identity損失中均最低,同時在整個訓練過程中最為穩定,不存在其他幾個網絡在訓練過程中出現較大的振幅變化的情況。
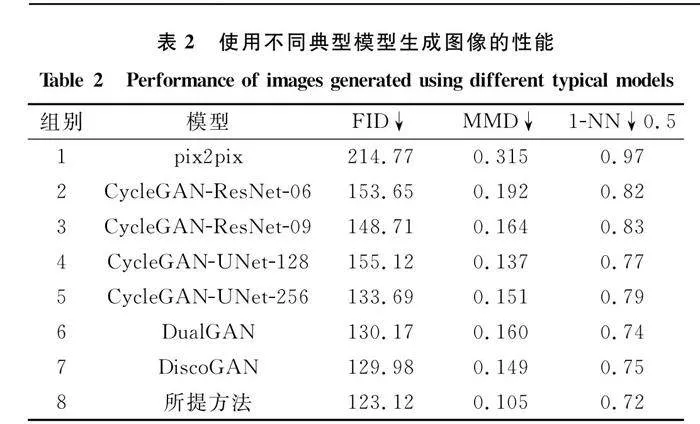
因為本文模型屬于無監督學習的雙域圖像的風格遷移,因此將上述模型與該領域主流的pix2pix、DualGAN[37]以及DiscoGAN[38]進行生成圖像的對比,比較對象為將HRSC2016轉換集中的500張光學圖像轉換生成的側掃聲納沉船圖像與真實側掃聲納評估集中的100張圖像進行定量分析,分別計算FID、MMD和K-NN,其中K設置為1。最終定量試驗結果如表2所示。
對比組別2~5可以看出,模型結構并不是越復雜,參數越多效果越好,相反由于側掃聲納圖像低分辨率、特征貧瘠等特征,在圖像的生成上越復雜的模型結構不一定帶來更好的生成效果。組別1證明pix2pix模型生成圖像的質量最不理想,可能是由于該模型需要成對的數據集作為訓練的輸入,本實驗雖然擁有同一目標的不同域圖像,但是除了在背景上的差異外,還存在目標的尺寸、方位、紋理、分辨率等多維度的差異,不能理解為理想的成對圖像。而組別2~8由于采用無監督學習,不需要成對的雙域圖像即可完成高質量的圖像生成,因此均取得優于組別1的效果。從組別6和組別7可以看出,DualGAN和DiscoGAN網絡與CycleGAN網絡在沉船目標光學與側掃聲納雙域圖像轉換任務上性能差距不大,均能很好地達到目的。組別8對比其他組別可以看出,使用本文模型結構的FID和MMD值均最低,1-NN值與0.5最為接近,證明和上述模型相比,本文模型生成的圖像與真實側掃聲納沉船圖像擬合程度更高,擁有更好的清晰度、細節度和真實度以及更低的模式崩潰概率。
2.4.2 定性分析
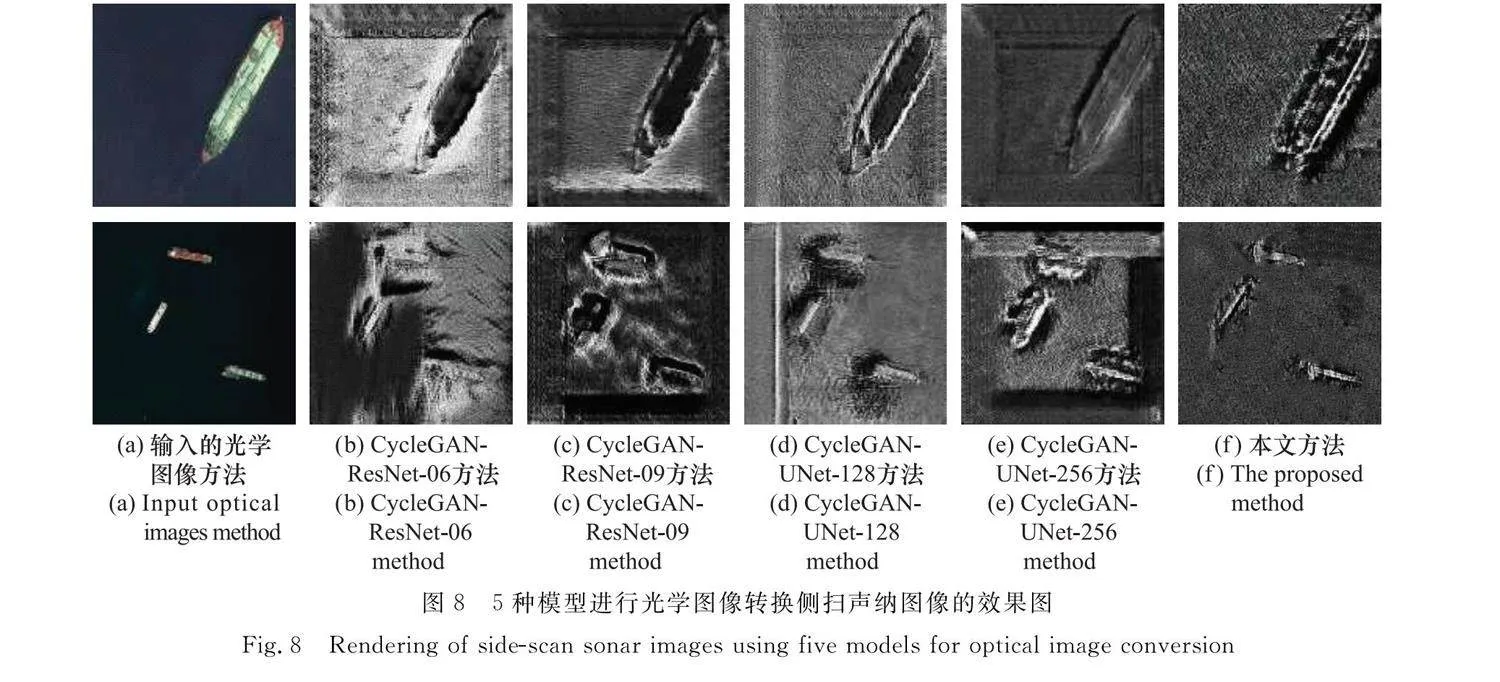
圖8為5種模型對大尺寸、多數量和小尺寸3種具有典型代表的光學圖像的轉化圖。
從圖8可以看出5種模型均基本實現了光學到聲學的跨域轉化,完成了樣本擴增。其中,圖8(b)和圖8(c)均不能很好地生成沉船的紋理特征以及背景出現了黑洞的情況;圖8(d)雖然較好地生成了背景但是依然存在白條以及方框背景等情況;圖8(e)在多目標和小尺寸目標紋理特征的生成中較前面幾個模型有了提高,但是卻出現了邊界的黑框,可能是錯把沉船目標的陰影特征學習成了背景信息;再看本文方法,相較于前面4種模型,無論是在模型的紋理特征生成上還是背景特征生成上,均取得了不錯的效果。
2.4.3 目標探測模型上的性能
考慮到本文的目的是對匱乏的側掃聲納水下目標圖像進行樣本擴增,以期提高基于深度學習的目標檢測模型的性能,因此接下來本文使用基于深度學習的目標檢測模型進行對比實驗。目前目標檢測模型非常多,由于本文的目的在于驗證擴增樣本的有效性,因此采用高速、輕量、易于部署的YOLOv5模型進行實驗。
以沉船目標為對象,設計了3組數據集分別對YOLOv5模型進行訓練,具體如表3所示。數據集分別是只包含真實側掃聲納數據、只包含本文模型生成的數據,以及包含真實數據與生成數據,并挑選100張真實的側掃聲納圖像對訓練后的模型進行性能評估。其中,生成的沉船數據均經過數據篩選,剔除了擴增失敗的圖像。
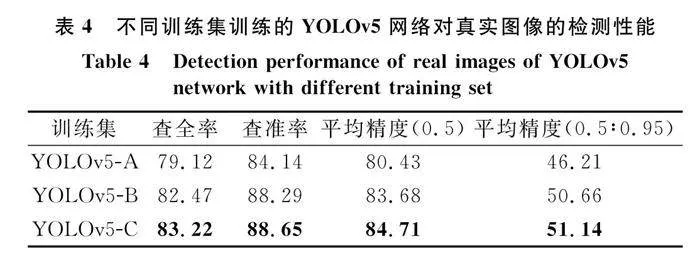
使用100張真實的側掃聲納圖像對訓練完成的模型進行驗證,采用在目標檢測評估領域廣泛應用的查全率、查準率和平均精度來評價模型,結果如表4所示。從表4可以看出,使用本文方法生成圖像進行訓練的模型在查全率、查準率和平均精度值均高于僅使用真實側掃聲納數據訓練的模型,證明了生成數據在模型性能提升中的起到了關鍵作用。使用了真實數據和生成數據訓練的YOLOv5-C和僅僅使用生成數據訓練的YOLOv5-B在各項評價指標差距不大,證明了模型性能的提升原因主要是由于使用了本文方法生成數據,或者說本文方法生成的圖像滿足了在真實度、多樣性上要求。
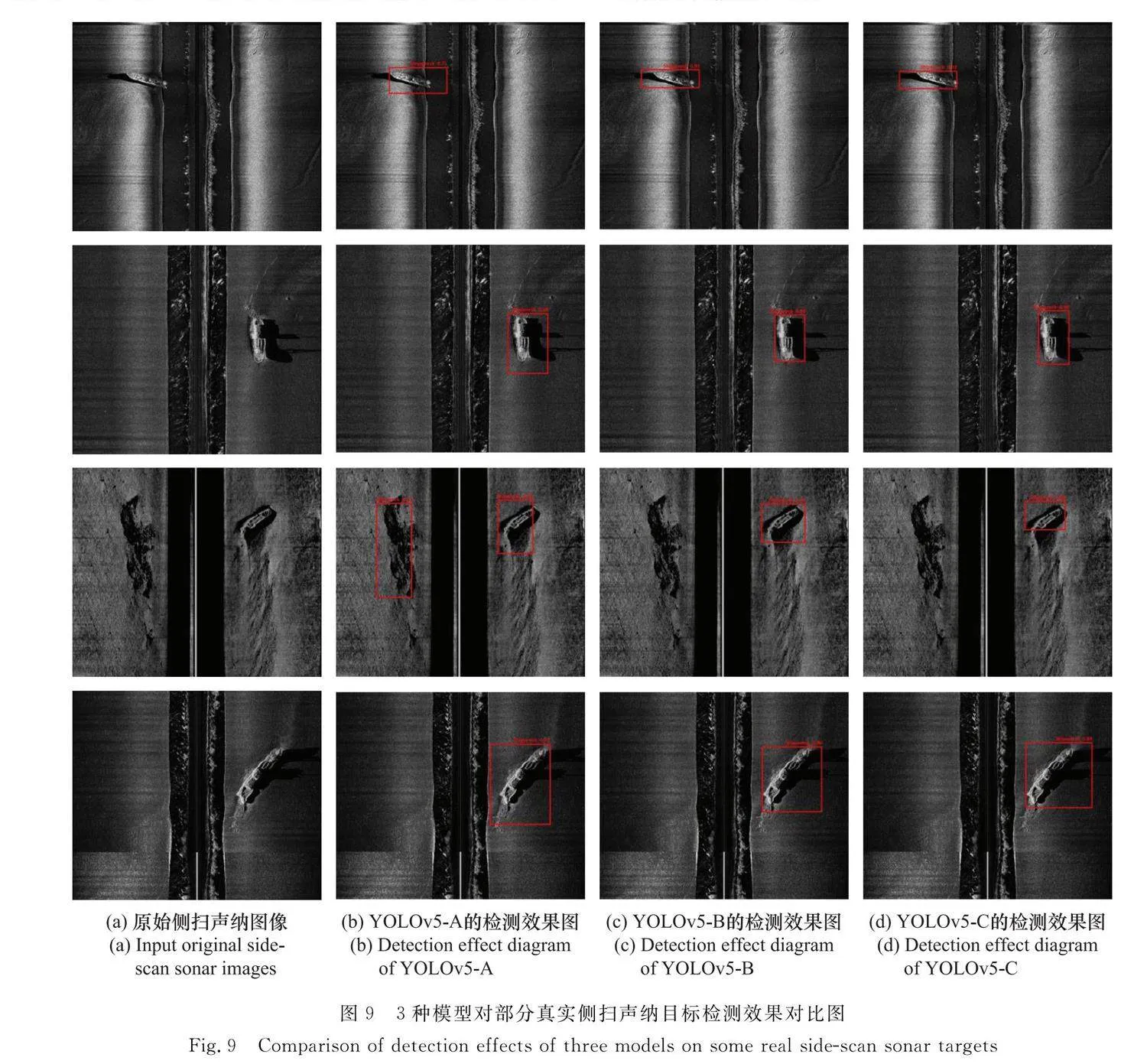
使用訓練好的3個模型對真實沉船側掃聲納圖像進行目標檢測,部分效果對比圖如圖9所示。
從圖9可以看出,使用A、B、C 3組數據集訓練后的YOLOv5模型均可以實現真實海底沉船目標的識別。但是對比圖9(b)、圖9(c)和圖9(d)可以發現,僅僅使用數據集A進行訓練的模型在沉船目標識別的置信度平均在65%,且在定位精度上有待加強,沒有對沉船的陰影進行很好的識別,在識別準確率上,將3組圖像中礁石目標錯誤地識別為沉船目標。而使用了本文擴增數據集B和C進行訓練的模型在沉船目標陰影識別上效果更好,且無論是在定位精度還是在置信度上均明顯高于僅僅使用真實數據集進行訓練的模型,平均置信度均達到了90%。
以上實驗證明了使用本文方法進行樣本擴增的圖像與真實側掃聲納圖像具有更貼近的真實度、細節度與完整度,且實現了提升基于深度學習的目標探測模型探測性能的目的。
2.4.4 消融實驗與評估
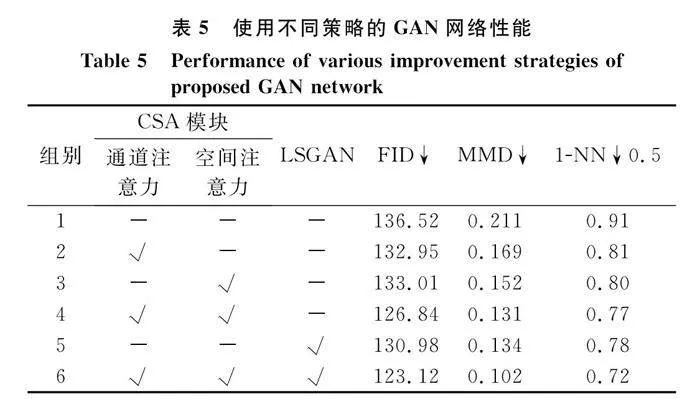
為了驗證各個模塊在本文模型性能中的作用,采用控制變量法分別對CSA模塊和LSGAN損失函數進行消融實驗,評價指標依舊采用FID、MMD和1-NN。設計了6組對照實驗,實驗配置、訓練數據集以及評估數據和第2.3節一致,實驗結果如表5所示。
對比組別1~4可以看出,融入了注意力機制后模型生成圖像的質量更高,其中融合了通道注意力和空間注意力機制的組別4較僅使用了通道和空間注意力模塊的組別2和3擁有更高的性能,證明了本文提出的CSA模塊對模型的有效性。對比組別5和組別1可以看出,本文提出的LSGAN損失函數的優越性。對比組別6和組別4、組別5可以看出,融合了CSA模塊和LSGAN損失函數后模型的性能比僅使用單一策略的效果更佳,對模型的整體性能提升起到了至關重要的作用,體現了本文提出的方法的有效性。
使用不同策略訓練的6組模型對部分光學圖像的轉化效果如圖10所示。
從圖10可以看出,組別1生成的數據真實度最低,對比組別2和組別1可以看出,增加了通道注意力模塊的模型在生成目標時能夠挖掘更多的細節特征,但是在背景特征生成上有待加強。對比組別3和組別1可以看出,增加了空間注意力模塊的模型在生成圖像的背景時效果更優,但是仍然存在背景黑洞的情況,并且在目標細節特征的生成上效果一般。對比組別4和組別1可以看出,采用了CSA模塊的模型在目標細節特征以及背景特征生成上能力提升明顯。對比組別5和組別1可以看出,采用了LSGAN目標函數的模型較好地實現了目標圖像的生成,但是在背景的邊緣仍然存在明顯的方框,顯得不是特別的自然。對比組別6和組別1可以看出,融合CSA模塊和LSGAN目標函數的模型無論是在沉船目標的紋理、邊緣等細節特征,還是在背景特征上均表現良好,生成了清晰度高、細節特征完整、真實感強的目標圖像,證明了本文方法的有效性。
3 結 論
針對側掃聲納水下目標圖像稀缺、獲取難度大、成本高導致基于深度學習的目標檢測模型性能差的問題,本文結合光學域類目標數據集豐富的優勢,提出了一種基于CSLS-CycleGAN的水下目標側掃聲納圖像樣本擴增方法,設計了單循環一致性的網絡結構,保證模型的訓練效率以及任務的專注度;在生成器中融合CSA模塊,減少信息彌散的同時增強跨緯度交互,在學習全局特征的同時關注目標的細粒度特征;設計了基于LSGAN的損失函數,提高生成圖像質量的同時提高訓練穩定性,避免模式崩潰的情況。通過光學域船舶圖像與側掃聲納圖像進行實驗,實現了目標光學圖像與側掃聲納圖像的雙域轉化,生成的側掃聲納水下目標圖像清晰度高、細節特征完整、真實感強,達到了少樣本的樣本高質量擴增的目的,很大程度上解決了基于深度學習的水下目標檢測模型數據匱乏的問題,提升了模型的檢測精度,為水下強代表性目標樣本擴增以及高性能水下目標檢測模型構建提供了一種新的思路。
參考文獻
[1] HENRIKSE L. Real-time underwater object detection based on an electrically scanned high-resolution sonar[C]∥Proc.of the IEEE Symposium on Autonomous Underwater Vehicle Techno-logy, 2002.
[2] ARSHAD M R. Recent advancement in sensor technology for underwater applications[J]. Indian Journal of Marine Sciences, 2009, 38(3): 267-273.
[3] GREENE A, RAHMAN A F, KLINE R, et al. Side scan sonar: a cost-efficient alternative method for measuring seagrass cover in shallow environments[J]. Estuarine, Coastal and Shelf Science, 2018. DOI:10.1016/j.ecss, 2018.04.017.
[4] HURTOS N, PALOMERAS N, CARRERA A, et al. Autonomous detection, following and mapping of an underwater chain using sonar[J]. Ocean Engineering, 2017, 130(1): 336-350.
[5] BUSCOMBE D. Shallow water benthic imaging and substrate characterization using recreational-grade side scan-sonar[J]. Environmental Modelling amp; Software, 2017, 89: 1-18.
[6] FLOWERS H J, HIGHTOWER J E. A novel approach to surveying sturgeon using side-scan sonar and occupancy modeling[J]. Marine amp; Coastal Fisheries, 2013, 5(1): 211-223.
[7] JOHNSON S G, DEAETT M A. The application of automated recognition techniques to side-scan sonar imagery[J]. IEEE Journal of Oceanic Engineering: a Journal Devoted to the Application of Electrical and Electronics Engineering to the Oceanic Environment, 1994, 19(1): 138-144.
[8] BURGUERA A, BONIN-FONT F. On-line multi-class segmentation of side-scan sonar imagery using an autonomous underwater vehicle[J]. Journal of Marine Science and Engineering, 2020, 8(8): 557.
[9] CHEN E, GUO J. Real time map generation using sidescan sonar scanlines for unmanned underwater vehicles[J]. Ocean Engineering, 2014, 91: 252-262.
[10] ZHU B Y, WANG X, CHU Z W, et al. Active learning for recognition of shipwreck target in side-scan sonar image[J]. Remote Sensing, 2019, 11(3): 243.
[11] 陽凡林, 獨知行,吳自銀, 等. 基于灰度直方圖和幾何特征的聲納圖像目標識別[J]. 海洋通報, 2006, 25(5): 64-69.
YANG F L, DU Z X, WU Z Y, et al. Object recognizing on sonar image based on histogram and geometric feature[J]. Marine Science Bulletin, 2006, 25(5): 64-69.
[12] LANGNER F, KNAUER C, JANS W, et al. Side scan sonar image resolution and automatic object detection, classification and identification[C]∥Proc.of the Oceans-Europe Conference, 2009.
[13] ISAACS J C. Sonar automatic target recognition for underwater UXO remediation[C]∥Proc.of the Computer Vision amp; Pattern Recognition Workshops, 2015.
[14] YUAN F, XIAO F Q, ZHANG K H, et al. Noise reduction for sonar images by statistical analysis and fields of experts[J]. Journal of Visual Communication and Image Representation, 2021, 74: 102995.
[15] REED S, PETILLOT Y, BELL J.Automated approach to classification of mine-like objects in sidescan sonar using highlight and shadow information[J]. IEE Proceedings—Radar, Sonar and Navigation, 2004, 151(1): 48-56.
[16] KUMAR N, MITRA U, NARAYANAN S S. Robust object classification in underwater sidescan sonar images by using reliability-aware fusion of shadow features[J]. IEEE Journal of Oceanic Engineering, 2015, 40(3): 592-606.
[17] ZHU P P, ISAACS J, FU B, et al. Deep learning feature extraction for target recognition and classification in underwater sonar images[C]∥Proc.of the IEEE 56th Annual Conference on Decision and Control, 2017.
[18] NEUPANE D, SEOK J. A review on deep learning-based approaches for automatic sonar target recognition[J]. Electronics, 2020, 9(11): 1972.
[19] TOPPLE J M, FAWCETT J A. MiNet: efficient deep learning automatic target recognition for small autonomous vehicles[J]. IEEE Geoscience and Remote Sensing Letters, 2021, 18(6): 1014-1018.
[20] HUO G Y, YANG S X, LI Q, et al. A robust and fast method for sidescan sonar image segmentation using nonlocal despeckling and active contour model[J]. IEEE Trans.on Cybernetics, 2016, 47(4): 855-872.
[21] FELDENS P, DARR A, FELDENS A, et al. Detection of boulders in side scan sonar mosaics by a neural network[J]. Geosciences, 2019, 9(4): 159.
[22] TANG Y L, JIN S H, BIAN G, et al. Shipwreck target recognition in side-scan sonar images by improved YOLOv3 model based on transfer learning[J]. IEEE Access, 2020, 8: 173450-173460.
[23] 湯寓麟, 李厚樸, 張衛東, 等. 側掃聲納檢測沉船目標的輕量化DETR-YOLO法[J]. 系統工程與電子技術, 2022, 44(8): 2427-2436.
TANG Y L, LI H P, ZHANG W D, et al. Lightweight DETR-YOLO method for detecting shipwreck target in side-scan sonar[J]. Systems Engineering and Electronics, 2022, 44(8): 2427-2436.
[24] NGUYEN H T, LEE E H, LEE S, et al. Study on the classification performance of underwater sonar image classification based on convolutional neural networks for detecting a submerged human body[J]. Sensors, 2019, 20(1): 94.
[25] LI A C, YE A X, CAO B D, et al. Zero shot objects classification method of side scan sonar image based on synthesis of pseudo samples-ScienceDirect[J]. Applied Acoustics, 2021, 173: 107691.
[26] COIRAS E, MIGNOTTE P Y, PETILLOT Y, et al. Supervised target detection and classification by training on augmented reality data[J]. IET Radar, Sonar amp; Navigation, 2007, 1(1): 83-90.
[27] KAPETANOVI N, MIKOVI N, TAHIROVI A. Saliency and anomaly: transition of concepts from natural images to side-scan sonar images[J]. IFAC-Papers OnLine, 2020, 53(2): 14558-14563.
[28] LEE S J, PARK B, KIM A. Deep learning from shallow dives: sonar image generation and training for underwater object detection[EB/OL]. [2023-03-10]. arxiv.org/pdf/1810.07990.pdf.
[29] HUO G Y, WU Z Y, LI J B. Underwater object classification in sidescan sonar images using deep transfer learning and semisynthetic training data[J]. IEEE Access, 2020, 8: 47407-47418.
[30] HUANG C, ZHAO J H, YU Y C, et al. Comprehensive sample augmentation by fully considering side-scan imaging mechanism and environment for shipwreck detection under zero real samples[J]. IEEE Trans.on Geoscience and Remote Sensing, 2021, 60: 5906814.
[31] CHAVEZ P S, ISBRECHT J A, GALANIS P, et al. Processing, mosaicking and management of the monterey bay digital sidescan-sonar images[J]. Marine Geology, 2002, 181(1/3): 305-315.
[32] BLONDEL P. The handbook of sidescan sonar[M]. Berlin: Springer, 2010.
[33] ISOLA P, ZHU J Y, ZHOU T, et al. Image-to-image translation with conditional adversarial networks[C]∥Proc.of the IEEE Conference on Computer Vision and Pattern Recognition, 2017: 5967-5976.
[34] ZHU J Y, PARK T, ISOLA P, et al. Unpaired image-to-image translation using cycle-consistent adversarial networks[C]∥Proc.of the IEEE International Conference on Computer Vision, 2017: 2242-2251.
[35] 李寶奇, 黃海寧, 劉紀元, 等. 基于改進CycleGAN的光學圖像遷移生成水下小目標合成孔徑聲納圖像算法研究[J]. 電子學報, 2021, 49(9): 1746-1753.
LI B Q, HUANG H N, LIU J Y, et al. Optical image-to-underwater small target synthetic aperture sonar image translation algorithm based on improved CycleGAN[J]. Acta Electronica Sinica, 2021, 49(9): 1746-1753.
[36] ALFARRA M, JUAN C, ANNA F, et al. On the robustness of quality measures for GANs[C]∥Proc.of the 17th European Conference on Computer Vision, 2022: 18-33.
[37] YI Z L, ZHANG H, TAN P L, et al. DualGAN: unsupervised dual learning for image-to-image translation[C]∥Proc.of the IEEE International Conference on Computer Vision, 2017: 2868-2876.
[38] KIM T, CHA M. Learning to discover cross-domain relations with generative adversarial networks[C]∥Proc.of the 34th International Conference on Machine Learning, 2017: 1857-1865.
作者簡介
湯寓麟(1996—),男,博士研究生,主要研究方向為智能感知與智能系統、水下目標檢測和計算機視覺。
王黎明(1978—),男,副教授,博士,主要研究方向為無人裝備智能感知與自主控制。
余德熒(1998—),男,博士研究生,主要研究方向為北斗/GNSS精密定位算法、海洋應用。
李厚樸(1985—),男,教授,博士,主要研究方向為大地測量數學分析。
劉 敏(1980—),男,高級工程師,博士,主要研究方向為大地測量海空重力測量與數據處理技術、海洋測繪及海洋地理信息應用。
張衛東(1981—),男,工程師,主要研究方向為地理信息系統。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
