基于全景感知的高校圖書館智能推薦系統設計
2024-12-06 00:00:00韓來偉
中國新技術新產品 2024年15期
關鍵詞:高校圖書館


摘 要:本文針對傳統高校圖書館推薦系統疏密度較高、精度差等問題,設計了一種基于全景感知的高校圖書館智能推薦系統。首先,根據關聯規則對系統硬件進行優化,添加存儲單元以提升運行速度;其次,對系統軟件運行流程進行處理,并利用聚類算法進行相似度計算,根據相似度對書目生產關聯規則,并將推薦結果通過全景感知展示給用戶。試驗結果表明,本文系統采用的聚類算法有效解決了數據疏密度問題,與KNN算法相比,聚類算法提升了算法推薦效率與質量,同時也解決了冷啟動問題,具有較高的實用性與推廣價值。
關鍵詞:全景感知;高校圖書館;推薦系統;聚類算法
中圖分類號:TP 391" " " " 文獻標志碼:A
數字技術的發展賦予圖書館智慧化特征,使圖書館具備感知分析能力,智能推薦服務已成為圖書館發展的主要方向[1]。目前,學界對圖書館推薦系統的研究尚處于初級階段。張希平等[2]利用數據挖掘算法設計了一種高校圖書館推薦系統,可向學生精準推送書目資源,避免冗雜信息干擾;王大阜等[3]為了實現自適應平臺與用戶的互動,設計了一種基于用戶畫像的圖書館推薦系統,為用戶提供符合其需求的書目資源。雖然這些系統均具有較高的推薦性能,但是在疏密度、精度以及冷啟動等方面仍有不足。由于高校圖書館具有較強的感知性,因此利用全景感知能夠更準確地了解用戶需求。智能推薦建立在用戶情景數據多態感知基礎上,數字技術的發展為基于全景感知的智能推薦服務提供了數據支持[4]。鑒于此,本文設計了一種基于全景感知的高校圖書館智能推薦系統,利用聚類算法對簇中數據進行挖掘。該方法具有效率高、數據依賴性低等優勢,能夠提升圖書館資源利用率,實現面向用戶需求的智能推送,可為提高用戶閱讀服務體驗提供新思路。
1 整體設計
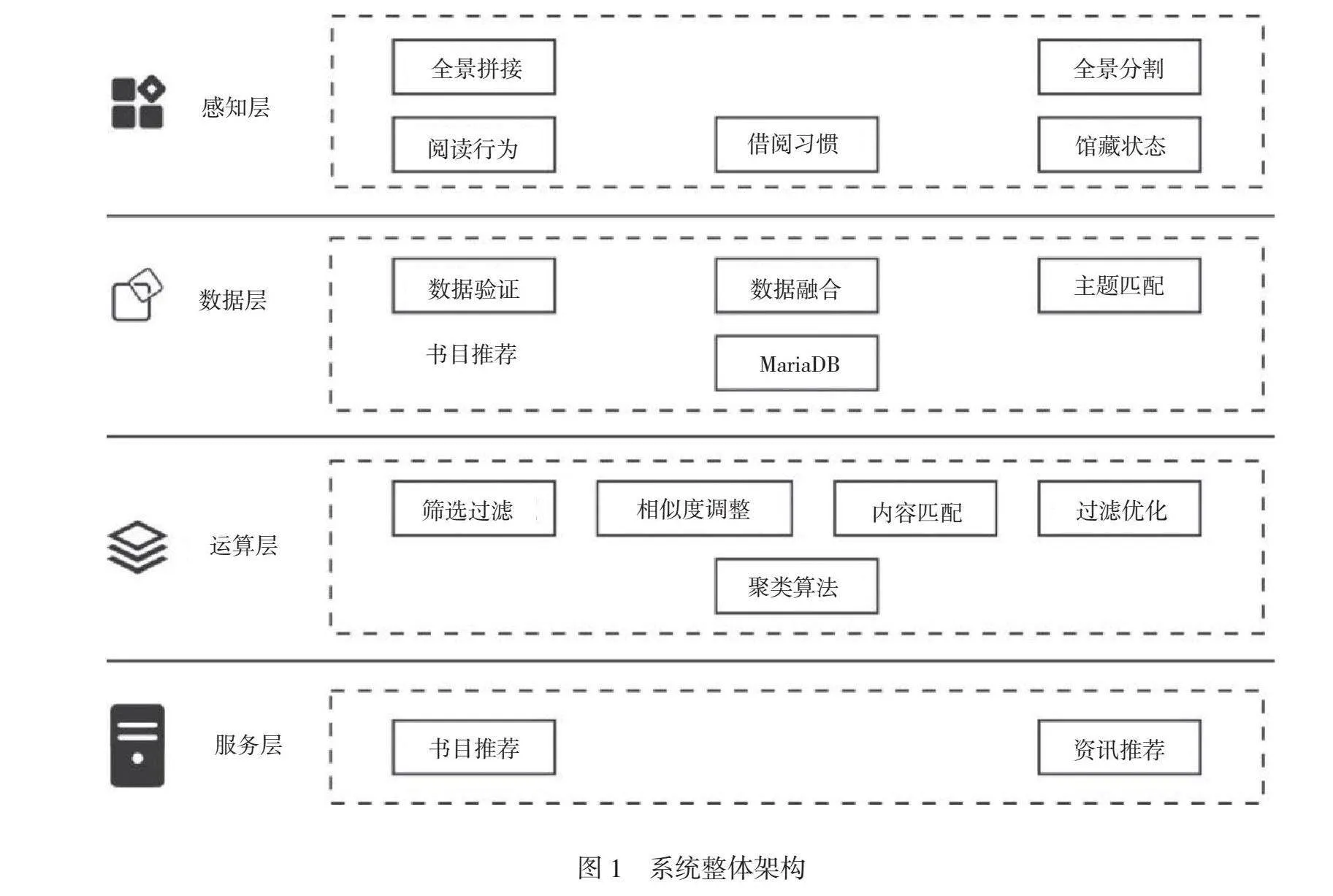
基于系統設計目標,應用全景感知與Hadoop框架進行整體架構設計。系統中的全景圖像拼接、全景分割與聚類算法可進行精準感知與捕捉,實時感知并獲取書目數據與用戶數據。全景拼接可映射全景,檢測用戶借閱特征;全景分割用于識別用戶所處環境與狀態;Hadoop框架利用聚類算法對系統各類數據進行并行計算,同時形成數據表,用于數據庫的存儲與檢索。系統由感知層、數據層、運算層和服務層構成,其中,感知層由全景圖像拼接和全景分割提供支持,可對用戶閱讀行為、借閱習慣以及館藏狀態進行全景感知;數據層可處理感知層獲取的數據,將異構化數據轉換成結構化數據;運算層采用聚類算法對各類數據進行計算,并對推薦內容進行篩選與優化;服務層可以感知用戶閱讀喜好,在預測用戶閱讀需求的基礎上為其提供智能推薦服務。系統整體架構如圖1所示。
2 硬件設計
為保證運行效果,需要對硬件進行優化。在系統中設置客戶端與瀏覽器,利用C/S架構有效管理圖書信息,并對書目特征進行充分挖掘。進一步分析用戶借閱信息,對用戶閱讀興趣進行綜合判斷,通過全景感知進行書籍智能推薦。為了使推薦效果保持最優,應繼續優化系統結構,在安防部件上增設防火墻,保障系統運行安全。
根據硬件結構挖掘書目特征,采用聚類算法進行類別分類。分類工作結束后,將收集的信息存儲到MariaDB內,深度分析項目關聯性,進一步優化硬件結構。在系統中添加AM186(一種嵌入式處理器),同時開放總線接口,從而對各類用戶信息進行統一處理。
對系統內的存儲單元進行特征數值的共享處理,確保書目特征類別信息收集和輸入(輸出)的有效性,并根據用戶需要選擇線路,存儲于特征類別的存儲模塊[5]。系統須添加124位存儲器,便于后續將信息傳輸到存儲單元,進而進行書目管理與推薦。
基于上述結構整合借閱信息,有針對性地為用戶推薦書目,同時通過感知引擎來管理圖書流通數據,以此獲取用戶借閱興趣信息并進行推薦操作。
3 軟件設計
根據上述硬件設計對軟件進一步優化,并結合書目特征關聯信息進行推薦。為使系統穩定運行,設置特征類別管理閾值,以便更好地獲取對應的支持數與最小信度。書目特征推薦數據應根據支持數與最小信度對興趣書目進行檢索與推送,同時簡化篩選過程。選擇推薦最優值與特征設備點進行連接,并合理分類特征數據,主要流程包括特征獲取和特征匹配。
3.1 特征獲取
采用聚類算法完成用戶特征信息分類,標記為顯性特征與隱性特征。收集用戶不同特征值(院系、學科和興趣),以顯性方式獲取用戶對書目的反饋信息后,再用隱性方法處理。更新數據庫后進行特征提取,對海量書目信息進行深度分類與推薦。
3.2 特征匹配
分析特征值后,對關聯信息進行判定并輸出結果,進而進行推薦描述。如果在特征匹配過程中沒有檢索到需求資源,應對類似資源進行最優化展示,同時完善檢索引擎,為用戶提供更系統化的檢索體系[6]。如果對類別判定困難,就需要根據歷史檢測對書目特征詞匯進行匹配,檢索類似資源,并根據關聯規則進行排列與推送,使用戶能夠全方位感知,并進一步篩選用戶所需特征數據,結束特征匹配工作。特征匹配整體流程如圖2所示。
將書目特征代入上述匹配流程,通過各類途徑分析關聯規則,并進行智能推薦。根據推薦信息進行綜合評價,同時根據評價調整推薦順序,從而實現書目智能服務。
4 算法流程
書目特征形成的數據具有高穩定性,能夠改進疏密情況。利用聚類算法創建關聯表,根據圖書信息提取關鍵詞,并按照頻率獲取不同關鍵詞權重,基于這類信息計算相似度,從而完成圖書推薦。
4.1 關鍵詞權重
通過算法獲取關鍵詞權重,設wf為詞頻,rf為反向詞頻,這2個參數可體現詞語普遍性。設e為關鍵詞總量,m為關鍵詞的出現頻率,詞頻wf如公式(1)所示。
(1)
設x為包括關鍵詞圖書數量,y為圖書總量,反向詞頻rf如公式(2)所示。
(2)
基于上述流程獲取關鍵詞權重h1,如公式(3)所示。
h1=wf·rf " " " " " " (3)
4.2 書目相似度
設h2為關鍵詞,構成向量空間后獲取書目相似度。設書目A與B,這2個參數擁有相同關鍵詞數量z1,書目相似度sim(A,B)如公式(4)所示。
(4)
4.3 用戶相似度
對屬性相似度與活躍相似度進行計算后統計用戶相似度。
4.3.1 屬性相似度
sim值越大,屬性相似度越高,屬性相似度如公式(5)所示。
(5)
式中:dmax為屬性差距最大值;dmin為屬性差距最小值;|dmax,dmin|為差距區間;u為根據差距區間獲取相似度。
4.3.2 活躍相似度
根據動態用戶信息獲取活躍相似度,設用戶g1與g2這2個參數擁有相同關鍵詞數量z2,當sim值越大時活躍相似度越高,活躍相似度sim(g1,g2)如公式(6)所示。
(6)
4.4 置信度
針對不同書目關聯,創建清除重復關聯規則,設v=(v1,v2,…,vn)為圖書集合,y為圖書數量,置信度con(v)如公式(7)所示。
(7)
在推薦過程中,利用聚類算法將書目聚類分為數量k,根據關聯性對各聚類內的書目生產關聯規則,對符合最小置信度的書目創建推薦書目,從而完成圖書智能推薦。
5 系統試驗
相關數據來自某高校2020—2023年的校圖書館信息,主要包括6 000冊圖書、12 382條借閱記錄以及13 692名用戶。
5.1 疏密度
采用3種方法驗證疏密度問題。1)用類別矩陣代替書目覺鎮,圖書館包括233個類別。2)將40個常用類別作為特征向量。3)組合聚類,將k(簇)設為10,最大迭代數為40,聚類情況見表1。
疏密度如公式(8)所示。
(8)
式中:d為疏密度;t為元素總量;r為元素代表。
上述3種方法的疏密度結果如圖3所示。根據試驗可知,第一種方法的疏密度為97.63%左右,與其他方法相比,方法一保持了較高水平;第二種方法使用40種常用類別,疏密度為86.35%左右;第三種方法通過聚類生成類別矩陣,將疏密度降至75.62%左右。
5.2 精確度
為進一步驗證系統有效性,使用KNN算法與本文系統采用的聚類算法進行精度比較試驗。精度是評價系統推薦性能的核心指標,精度precision如公式(9)所示。
(9)
式中:l為訓練集上實際為正例且被模型正確預測為正例的推薦書目列表;b為測試集上實際為負例但被模型錯誤預測為正例的書目列表。
結果如圖4所示。由試驗可知,當訓練集由10個增至40個時,能夠看到2種算法的精度均相應提升。閱讀數量能夠直接影響算法推薦性能。在KNN算法訓練過程中,小訓練集可能無法完全彰顯用戶興趣,大集合包包括的用戶興趣過多。本文系統使用的聚類算法有效解決了疏密度問題,既有效提升了算法推薦效率與質量,同時也解決了冷啟動問題。
6 結語
綜上所述,在數字時代,高校圖書館智能推薦系統的推廣應用能夠成為圖書館事業發展的有力推動力。本文應用全景感知技術,設計出一種高校圖書館智能推薦系統,在硬件配置上添加存儲單元,可提升運行速度,利用聚類算法進行相似度計算,根據相似度對書目生產關聯規則,并將推薦結果通過全景感知展示給用戶。試驗結果表明,本文系統有效解決了疏密度、精度和冷啟動問題,可面向用戶需求進行精準化的智能推薦。
參考文獻
[1]王曉霞,孟佳娜,江烽,等.基于多視圖的知識感知推薦系統[J].計算機與現代化,2024(2):100-107.
[2]張希平,姜華.基于數據挖掘的高校圖書館圖書推薦系統探究[J].信息記錄材料,2021,22(10):241-242.
[3]王大阜,鄧志文,賈志勇,等.基于用戶畫像的高校圖書館個性化圖書推薦研究[J].河南師范大學學報(自然科學版),2022,50(3):95-103.
[4]鄒永茂.基于互聯網的校園圖書館薦書模式分析[J].電子技術,2024,53(2):410-411.
[5]馬艷.基于語義圖譜的圖書館文獻推薦系統設計[J].信息技術,2023(10):147-151.
[6]閆俊輝.基于多維關系和用戶聚類的智慧圖書館個性化圖書推薦研究[J].現代計算機,2023,29(14):62-65,73.
猜你喜歡
現代經濟信息(2016年19期)2016-10-20 16:13:56
出版廣角(2016年15期)2016-10-18 00:19:57
科技視界(2016年21期)2016-10-17 19:32:37
科技視界(2016年21期)2016-10-17 19:25:20
商(2016年27期)2016-10-17 06:39:10
商(2016年27期)2016-10-17 06:38:27
商(2016年27期)2016-10-17 06:30:59
科學與財富(2016年28期)2016-10-14 23:43:29
科學與財富(2016年28期)2016-10-14 00:28:44
科技視界(2016年20期)2016-09-29 13:17:57
