基于網絡爬蟲技術的財務大數據采集系統設計
2024-12-08 00:00:00周瑋
中國新技術新產品 2024年3期
關鍵詞:大數據
摘 要:隨著大數據技術的發展,金融領域對大數據分析的需求不斷增加。采集大規模的財務數據是進行深度分析、建立預測模型和識別趨勢的基礎。因此,本文設計了基于網絡爬蟲技術的財務大數據采集系統,旨在從多個數據源中自動獲取、清洗、分析和存儲財務數據。該系統的設計包括網絡爬蟲采集模塊、數據處理模塊和數據存儲模塊,充分考慮了數據的多樣性和復雜性,以滿足金融市場的需求。通過對系統性能進行測試,驗證了系統的穩定性和可擴展性,并展示了該系統在實際應用中的潛力。
關鍵詞:網絡爬蟲技術;財務系統;大數據;信息采集
中圖分類號:TP 399 " " " 文獻標志碼:A
在快速發展的信息時代,將大數據技術應用于金融領域已成為必然趨勢。在各企業及金融機構中,財務數據的采集和分析對其決策至關重要[1]。然而,財務數據會隨各種原因頻繁變化,具有較強的多樣性及分布性,因此采集財務數據是一項復雜且具有挑戰性的工作[2]。為了應對這一挑戰,本文旨在設計和開發一種高效的財務大數據采集系統,利用網絡爬蟲技術從多個數據源中自動提取財務數據。本文系統的設計包括網絡爬蟲采集模塊、數據處理模塊和數據存儲模塊。網絡爬蟲采集模塊負責從不同的金融網站和數據提供商獲取數據,并根據指定的規則和模板進行解析、提取。數據處理模塊負責數據的清洗、轉換和聚合,以確保數據的質量和一致性。數據存儲模塊將處理后的數據存儲在可擴展的數據庫中,以供后續查詢和分析使用。本文對該系統進行了性能測試,以驗證系統在不同負載下的各項性能。測試結果表明,本文系統能夠有效處理大規模財務數據,并保持較高的穩定性,為金融領域的數據采集和分析提供了一種強大的工具,可更好地助力于企業的財務決策和戰略規劃。
1 財務大數據采集系統架構設計
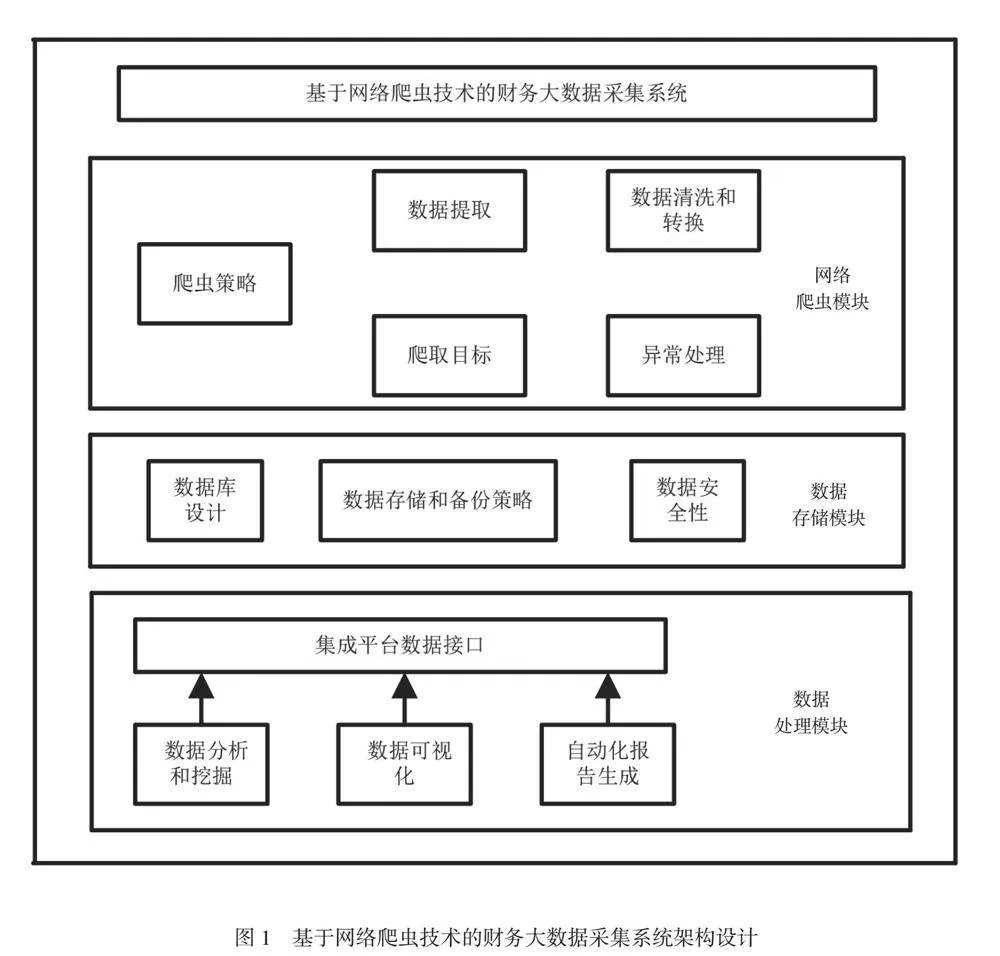
設計基于網絡爬蟲技術的財務大數據采集系統時,清晰的系統架構可以確保系統的可擴展性、性能和可維護性。系統架構如圖1所示。
系統采用分層架構,將不同的功能和責任分配到不同的層次,以提高其可維護性和可擴展性。網絡爬蟲模塊是該系統的核心,專門負責從互聯網上爬取財務數據。該模塊需要在一個獨立的子系統中運行。數據存儲模塊用于存儲采集的財務數據。系統使用PostgreSQL關系型數據庫儲存數據[3]。在基于網絡爬蟲技術的財務大數據采集系統中,數據處理模塊具有重要作用,負責清洗、轉換、分析和存儲從網絡爬蟲模塊獲取的原始數據,以使數據成為成功采集的有效數據,并以可視化形態傳達給用戶。
2 硬件設計
基于網絡爬蟲技術的財務大數據采集系統硬件設備需要根據系統規模和需求進行定制。選擇HP ProLiant DL380 Gen10服務器,該服務器多核Intel Xeon Scalable處理器的內存容量最多為3.5TB RAM(可根據需求配置),存儲容量最多為30個SFF或20個LFF硬盤/SSD插槽(支持多種硬盤/SSD配置),包括多個高速網絡接口,還包括千兆以太網和萬兆以太網。
系統的存儲設備可以選擇HPE Enterprise SAS HDD企業級硬盤,容量為4TB,以存儲大規模財務數據。讀寫性能為7200RPM,支持RAID技術,提供數據冗余、備份以及Samsung 860 PRO SSD固態硬盤,具有卓越的隨機讀寫性能,用于加速數據存取。容量為256GB~2TB,耐用性高,適用于長時間運行。
網絡設備選擇Cisco Catalyst 9000 Series交換機,進行高速網絡連接,支持千兆以太網或萬兆以太網。管理功能豐富,包括虛擬局域網(VLAN)支持等,支持負載均衡和冗余鏈路聚合(LAG)。系統選擇Cisco ISR 4000 Series路由器,安全性設置包括防火墻和虛擬專用網絡(VPN)支持。系統的爬蟲節點選擇Microsoft Azure云虛擬機執行網絡爬蟲任務,定期抓取目標網站上的財務數據,對所采集數據進行處理,然后將其傳輸到服務器并進行存儲和分析。
3 系統各模塊設計
3.1 網絡爬蟲采集模塊
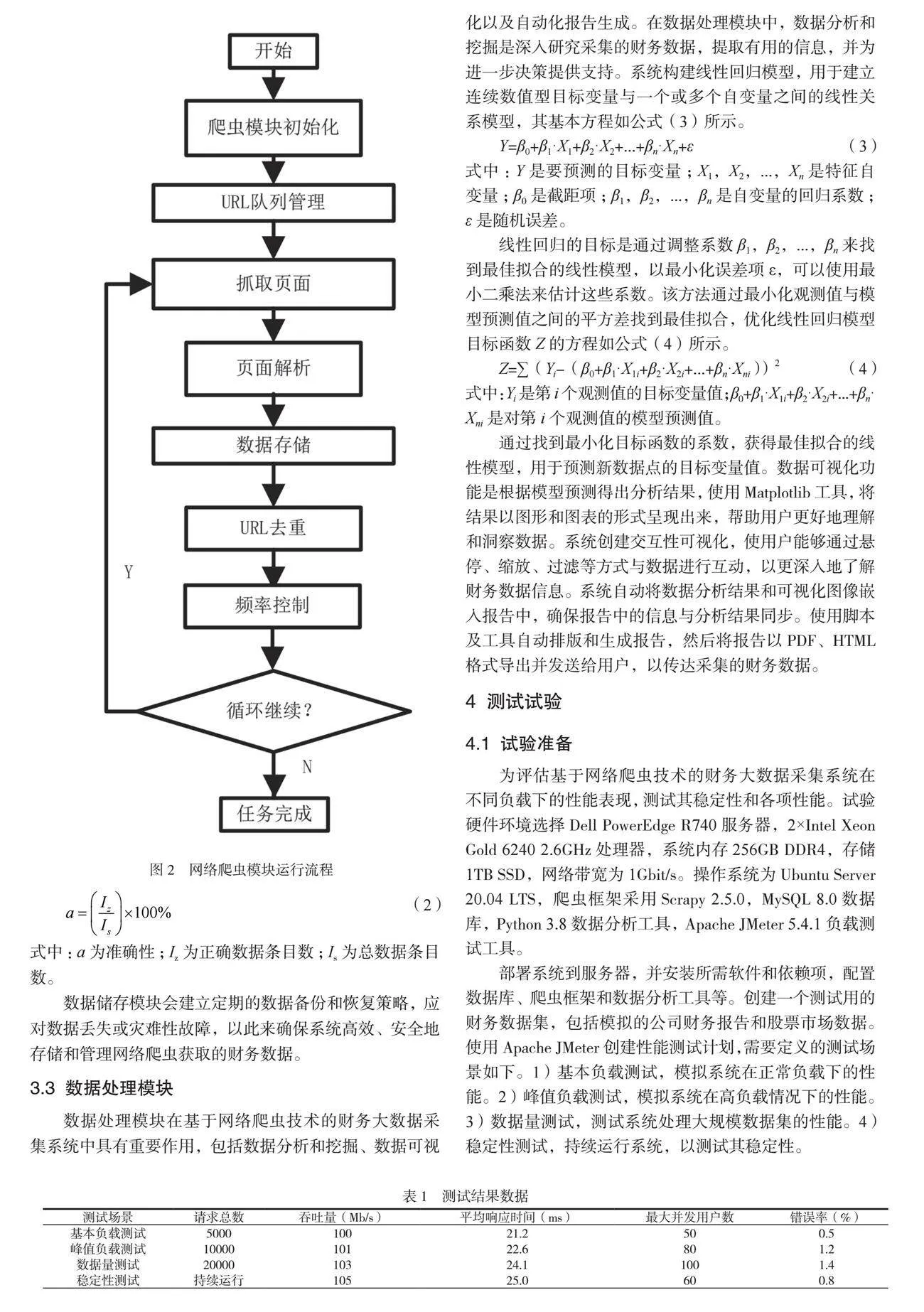
在基于網絡爬蟲技術的財務大數據采集系統中,網絡爬蟲模塊是整個系統的關鍵組成部分。該模塊的主要任務是從目標網站上抓取財務數據。網絡爬蟲模塊的具體運行流程如圖2所示。
爬蟲模塊初始化需要設置抓取策略、數據存儲方式等參數,定義爬蟲應該訪問的網頁(如特定網站的首頁或入口頁面)及如何訪問。根據一定規則生成待抓取的URL列表,再進行URL去重,確保不會重復抓取同一頁面[4]。使用SHA-256哈希函數來計算每個待抓取的URL的哈希值,將URL的內容映射為一個固定長度的哈希碼,具體流程如下。1)初始化一些常數(常量K),這些常數是SHA-256算法的一部分。2)將輸入數據分成512位(64字節)的塊。3)將512位塊擴展成64個32位字,再將中間哈希值初始化為上一塊的哈希值。進行64輪循環,每輪都對中間哈希值進行更新。4)將最后一輪的中間哈希值與上一塊的中間哈希值相加,得出最終的SHA-256哈希值。5)繼續處理下一個塊,直到所有塊處理完畢。6)處理完所有塊后,將最終結果組合成256位(32字節)的哈希值,最終的SHA-256哈希值即為輸出結果。
在上述方法中,如果新URL的哈希值已存在于集合中,說明該URL與已抓取的某個頁面相同,因此不進行抓取,從而實現了URL去重。從去重后的URL隊列中獲取下一個要抓取的頁面鏈接后,系統需要下載該頁面的內容,解析下載的頁面,提取財務數據,并根據XPath抽取規則進行數據處理。將解析后的數據存儲到數據庫或文件中,確保數據的持久性。檢查已抓取的網頁鏈接,確保不會重復抓取相同的頁面[5]。根據請求間隔公式計算下一次請求的等待時間,以避免過于頻繁的請求,具體如公式(1)所示。
t=f(RT,AP) (1)
式中:t表示下一次請求的等待時間,ms;RT表示目標網站的響應時間,ms;響應時間是上一次請求到目標網站并收到響應的時間;AP表示目標網站的訪問策略,包括最小請求間隔、最大請求頻率和請求失敗的重試策略等;f表示計算等待時間的函數。
函數f接受輸入參數RT(目標網站的響應時間)和AP(目標網站的訪問策略),并返回等待時間作為輸出。請求結束后,重復執行步驟3~6,直到所有目標頁面都被抓取完畢或達到預設的抓取數量及時間限制,爬蟲模塊完成所有任務,才可結束運行。
3.2 數據存儲模塊
數據存儲模塊在基于網絡爬蟲技術的財務大數據采集系統中具有重要作用,負責將從網絡爬蟲模塊獲取的財務數據存儲到持久化存儲介質中,以供后續分析、查詢和使用。設計數據存儲模塊時,選擇適當的數據庫系統,如PostgreSQL關系型數據庫,以滿足財務數據的存儲和查詢需求。定義數據表結構,具體如下。1)字段:包括公司名稱、日期、總收入、總支出、利潤。2)數據類型:使用整數(INT)或浮點數(DECIMAL)存儲數值數據,使用日期/時間(DATE/TIME)存儲日期和時間數據,使用文本(VARCHAR)存儲公司名稱。3)索引:公司名稱和日期。4)主鍵:公司稅號。
數據表的結構設置要適應財務數據的特性和查詢需求,如果財務數據非常龐大,則需要考慮采用數據分區策略,以提高查詢性能。采用數據質量控制策略,確保數據的準確性,如公式(2)所示。
(2)
式中:a為準確性;Iz為正確數據條目數;Is為總數據條目數。
數據儲存模塊會建立定期的數據備份和恢復策略,應對數據丟失或災難性故障,以此來確保系統高效、安全地存儲和管理網絡爬蟲獲取的財務數據。
3.3 數據處理模塊
數據處理模塊在基于網絡爬蟲技術的財務大數據采集系統中具有重要作用,包括數據分析和挖掘、數據可視化以及自動化報告生成。在數據處理模塊中,數據分析和挖掘是深入研究采集的財務數據,提取有用的信息,并為進一步決策提供支持。系統構建線性回歸模型,用于建立連續數值型目標變量與一個或多個自變量之間的線性關系模型,其基本方程如公式(3)所示。
Y=β0+β1·X1+β2·X2+...+βn·Xn+ε (3)
式中:Y是要預測的目標變量;X1,X2,...,Xn是特征自變量;β0是截距項;β1,β2,...,βn是自變量的回歸系數;ε是隨機誤差。
線性回歸的目標是通過調整系數β1,β2,...,βn來找到最佳擬合的線性模型,以最小化誤差項ε,可以使用最小二乘法來估計這些系數。該方法通過最小化觀測值與模型預測值之間的平方差找到最佳擬合,優化線性回歸模型目標函數Z的方程如公式(4)所示。
Z=∑(Yi-(β0+β1·X1i+β2·X2i+...+βn·Xni))2 (4)
式中:Yi是第i個觀測值的目標變量值;β0+β1·X1i+β2·X2i+...+βn·
Xni是對第i個觀測值的模型預測值。
通過找到最小化目標函數的系數,獲得最佳擬合的線性模型,用于預測新數據點的目標變量值。數據可視化功能是根據模型預測得出分析結果,使用Matplotlib工具,將結果以圖形和圖表的形式呈現出來,幫助用戶更好地理解和洞察數據。系統創建交互性可視化,使用戶能夠通過懸停、縮放、過濾等方式與數據進行互動,以更深入地了解財務數據信息。系統自動將數據分析結果和可視化圖像嵌入報告中,確保報告中的信息與分析結果同步。使用腳本及工具自動排版和生成報告,然后將報告以PDF、HTML格式導出并發送給用戶,以傳達采集的財務數據。
4 測試試驗
4.1 試驗準備
為評估基于網絡爬蟲技術的財務大數據采集系統在不同負載下的性能表現,測試其穩定性和各項性能。試驗硬件環境選擇Dell PowerEdge R740服務器,2×Intel Xeon Gold 6240 2.6GHz處理器,系統內存256GB DDR4,存儲1TB SSD,網絡帶寬為1Gbit/s。操作系統為Ubuntu Server 20.04 LTS,爬蟲框架采用Scrapy 2.5.0,MySQL 8.0數據庫,Python 3.8數據分析工具,Apache JMeter 5.4.1負載測試工具。
部署系統到服務器,并安裝所需軟件和依賴項,配置數據庫、爬蟲框架和數據分析工具等。創建一個測試用的財務數據集,包括模擬的公司財務報告和股票市場數據。使用Apache JMeter創建性能測試計劃,需要定義的測試場景如下。1)基本負載測試,模擬系統在正常負載下的性能。2)峰值負載測試,模擬系統在高負載情況下的性能。3)數據量測試,測試系統處理大規模數據集的性能。4)穩定性測試,持續運行系統,以測試其穩定性。
4.2 試驗結果
在每個測試場景下,模擬多個并發用戶進行數據采集和處理,運行測試試驗并記錄測試結果。具體的測試結果數據表見表1。
從表1的測試結果數據來看,基于網絡爬蟲技術的財務大數據采集系統在各種測試場景下的吞吐量都相對較高,最高為105Mbit/s,表明系統能夠有效處理大量的請求數據,獲取大量財務數據。在各測試場景下,系統均能表現出較低的平均響應時間,為21.2ms~25.0ms,用戶可以快速獲取所需數據,用戶體驗感較好。另外,系統在不同測試場景下均能支持數量較高的最大并發用戶數,表明系統具有良好的并發處理能力,能夠滿足多用戶同時訪問的需求。在各種測試場景下,系統的錯誤率均相對較低,≦1.5%,穩定性和可靠性較高,能夠有效處理各種異常情況。
綜合上述優點,基于網絡爬蟲技術的財務大數據采集系統在穩定性和可靠性方面表現良好,適用于大規模的財務數據采集和處理任務,系統能夠在不同負載和條件下保持高效運行,為用戶提供可靠的數據采集服務。
5 結語
綜上所述,本文介紹了基于網絡爬蟲技術的財務大數據采集系統的具體設計。該系統的成功設計不僅為金融領域的數據采集和分析提供了一項強大的工具,還展示了大數據技術和自動化技術在金融決策支持中的巨大潛力。試驗證明了該系統的穩定性,可為金融機構、研究機構和各企業提供較可靠的數據采集方式。未來,研究人員可以繼續改進系統,增加更多的數據源和分析功能,以適應不斷變化且復雜的金融市場。基于大數據和網絡爬蟲技術的財務數據采集系統將在金融領域發揮越來越重要的作用,為決策者提供更深入的洞察方式及更好的決策支持。
參考文獻
[1]夏瑤.基于BP-SVM算法的中大型企業財務危機預警系統[J].西安文理學院學報(自然科學版),2023,26(1):17-20.
[2]李敏.大數據視角下企業財務管理系統信息化建設探究[J].西部財會,2022(10):36-38.
[3]程承.大數據對企業財務系統管理的影響與對策探討[J].中國管理信息化,2022,25(19):105-108.
[4]方悅,趙紅,陳繼林.基于集成學習的財務信息一體化系統設計[J].九江學院學報(自然科學版),2022,37(1):54-58.
[5]閻澤群.基于網絡爬蟲技術的大數據采集系統設計[J].現代信息科技,2021,5(12):83-86.
猜你喜歡
中國市場(2016年36期)2016-10-19 04:41:16
中國市場(2016年36期)2016-10-19 03:31:48
中國市場(2016年35期)2016-10-19 01:30:59
商(2016年27期)2016-10-17 06:26:00
今傳媒(2016年9期)2016-10-15 23:35:12
今傳媒(2016年9期)2016-10-15 22:09:11
新聞世界(2016年10期)2016-10-11 20:13:53
科技視界(2016年20期)2016-09-29 10:53:22
中國記者(2016年6期)2016-08-26 12:36:20
