基于MMD與CORAL度量的域適應(yīng)旋轉(zhuǎn)機(jī)械故障診斷方法
2024-12-14 00:00:00林峰平許力
今日自動化 2024年11期
關(guān)鍵詞:故障診斷



[關(guān)鍵詞]遷移學(xué)習(xí);域適應(yīng);聯(lián)合分布;故障診斷
[中圖分類號]TH17 ;TP18 [文獻(xiàn)標(biāo)志碼]A [文章編號]2095–6487(2024)11–0131–04
軸承故障會直接影響旋轉(zhuǎn)機(jī)械的性能,處理不當(dāng)甚至?xí)<安僮魅藛T的生命。因此,診斷軸承健康狀況非常重要。近年來,隨著機(jī)器學(xué)習(xí)的蓬勃發(fā)展,基于深度學(xué)習(xí)的旋轉(zhuǎn)機(jī)械故障診斷逐漸用于工業(yè)領(lǐng)域并取得了良好的效果[1]。在實(shí)際工業(yè)生產(chǎn)環(huán)境中,由于旋轉(zhuǎn)機(jī)械設(shè)備運(yùn)行工況復(fù)雜多變,使得原始的振動信號具有不同的特征分布并且部分工況數(shù)據(jù)采集困難,這無法滿足深度學(xué)習(xí)中要求特征獨(dú)立同分布且標(biāo)簽數(shù)據(jù)要充足的要求[2]。遷移學(xué)習(xí)可以從其他相關(guān)數(shù)據(jù)集(即有足夠的標(biāo)記樣本但不同的分布)中學(xué)習(xí)知識來構(gòu)建當(dāng)前故障分類任務(wù)的診斷模型,并且它可以有效地解決數(shù)據(jù)缺失狀況下的故障診斷問題[3]。無監(jiān)督域自適應(yīng)作為遷移學(xué)習(xí)的一個(gè)子域,使用度量函數(shù)測量和減少域之間的分布差異,通過學(xué)習(xí)有標(biāo)記的訓(xùn)練樣本和無標(biāo)記的測試樣本的共享特征,緩解樣本分布不一致的問題。但大多數(shù)模型關(guān)注的是域間整體邊緣分布的對齊,而沒有考慮到故障類別之間的不匹配。
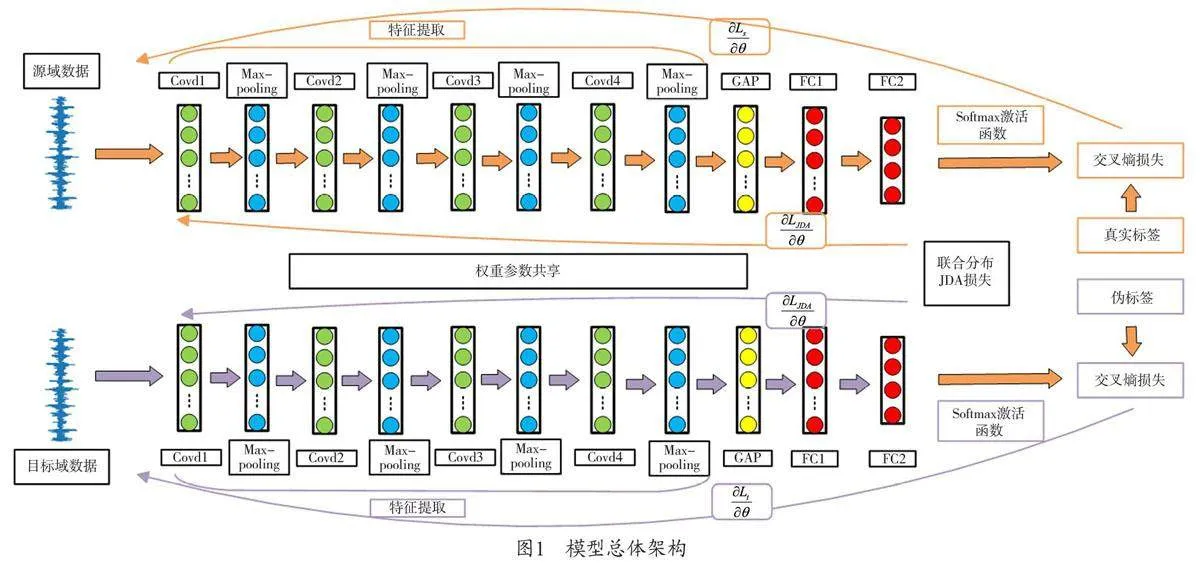
因此,本文結(jié)合邊緣分布與條件分布對齊方法,構(gòu)建聯(lián)合分布域適應(yīng)診斷模型,考慮到單一度量準(zhǔn)則對指導(dǎo)提取域不變特征不足的問題,將最大均值差異度量(MMD)與相關(guān)對齊準(zhǔn)則(CORAL)結(jié)合成新的度量準(zhǔn)則,充分提取域不變特征,該模型通過模型迭代收集源域和目標(biāo)域數(shù)據(jù)的可遷移特征,達(dá)到對無標(biāo)簽?zāi)繕?biāo)域數(shù)據(jù)的健康狀況識別目的。
3實(shí)驗(yàn)研究
3.1數(shù)據(jù)集介紹
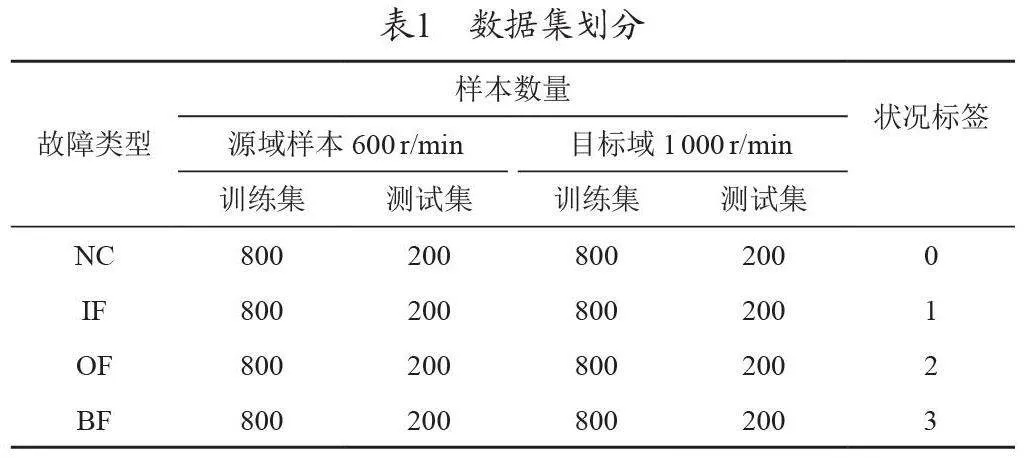
JNU軸承故障數(shù)據(jù)集共有4 種健康狀態(tài)類型:正常狀態(tài)(N)、內(nèi)圈故障(IF)外圈故障(OF)、滾動體故障(BF),每種故障類型有3 種不同的轉(zhuǎn)速,即3種工況,分別為600 r/min,800 r/min 和1 000 r/min 下采集的滾動軸承故障數(shù)據(jù),采樣頻率為50kHz,采樣時(shí)間為20 s。本文選取其中兩種轉(zhuǎn)速做遷移域適應(yīng)實(shí)驗(yàn)數(shù)據(jù),具體劃分如表1所示。
源域和目標(biāo)域中每個(gè)類別的樣本數(shù)為1000,則源域和目標(biāo)域各有4000個(gè)樣本。考慮到實(shí)際中故障樣本較少,采用滑動采樣技術(shù)對原始數(shù)據(jù)進(jìn)行分割,對故障樣本進(jìn)行擴(kuò)充,以獲得足夠的故障信息,樣本長度為3072,滑動步數(shù)為256。本文直接使用原始振動樣本作為故障診斷模型的輸入。
3.2實(shí)驗(yàn)結(jié)果及分析
所有實(shí)驗(yàn)均采用均方根Prop(RMSProp)優(yōu)化器對網(wǎng)絡(luò)結(jié)構(gòu)進(jìn)行訓(xùn)練,交叉熵?fù)p失函數(shù)作為目標(biāo)函數(shù),網(wǎng)絡(luò)模型設(shè)置學(xué)習(xí)率設(shè)為0.001。訓(xùn)練epoch 設(shè)置為300,訓(xùn)練批次batchsize 設(shè)置為256。權(quán)衡參數(shù)設(shè)置為μ=0.1,λ=0.01。當(dāng)網(wǎng)絡(luò)的損失值不再下降或訓(xùn)練次數(shù)達(dá)到300 時(shí),保存網(wǎng)絡(luò)參數(shù),使用無標(biāo)簽的目標(biāo)域數(shù)據(jù)進(jìn)行測試。
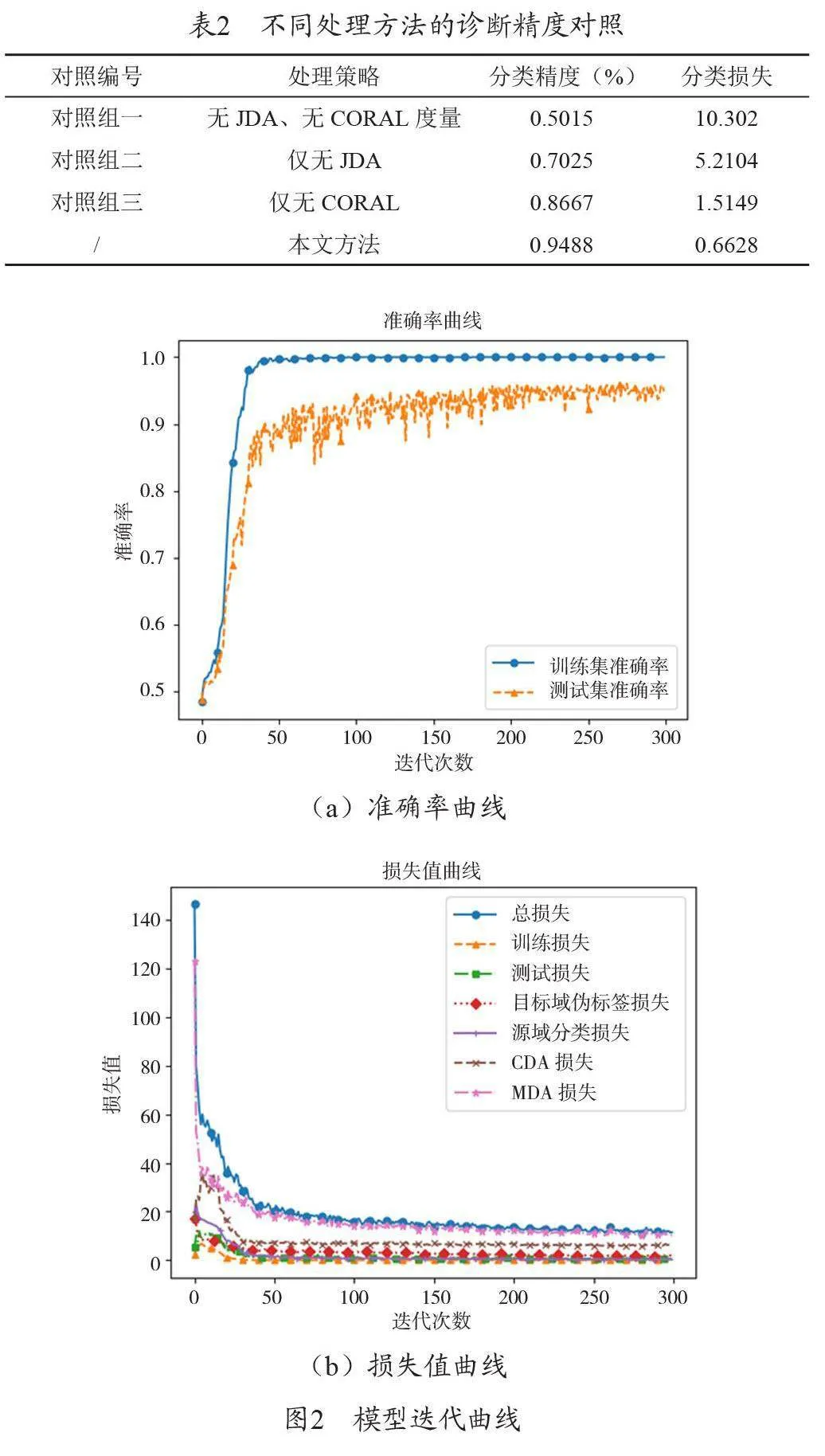
為驗(yàn)證本文聯(lián)合分布遷移域適應(yīng)故障診斷方法對診斷精度的影響,設(shè)計(jì)3組對比實(shí)驗(yàn),分別為①無JDA、無CORAL 度量;② 僅無JDA ;③ 僅無CORAL,每次結(jié)果為5 次實(shí)驗(yàn)結(jié)果的平均值,結(jié)果如表2 所示。
分析表2 可知,本文方法相較于對照組,在診斷準(zhǔn)確率上與分類損失方面有較大的提升,本文模型準(zhǔn)確率曲線與損失值迭代曲線如圖2(a)、(b)所示。
4結(jié)論與展望
針對基于統(tǒng)計(jì)度量的的域適應(yīng)法中的的度量準(zhǔn)則進(jìn)行改進(jìn),將最大均值差異與相關(guān)對齊準(zhǔn)則相結(jié)合組成新的度量準(zhǔn)則,提高網(wǎng)絡(luò)模型的提取域不變特征的能力。在遷移域適應(yīng)中,使用聯(lián)合分布自適應(yīng)方法,在使得域間邊緣分布對齊的同時(shí),考慮到類間的條件分布對齊,充分減小源域與目標(biāo)域數(shù)據(jù)的分布差異,提高診斷的精度。通過實(shí)驗(yàn)證明了本文方法的有效性。
在實(shí)際生產(chǎn)環(huán)境中,對滾動軸承振動信號的采集越來越多,數(shù)據(jù)分布差異也越來越大,這對域適應(yīng)方法提出了更高的挑戰(zhàn)。本文并未對聯(lián)合分布中邊緣分布與條件分布做動態(tài)適應(yīng)工作,以適應(yīng)更對復(fù)雜多變的數(shù)據(jù)分布,后續(xù)會繼續(xù)對動態(tài)域適應(yīng)的領(lǐng)域做進(jìn)一步研究工作。
猜你喜歡
一重技術(shù)(2021年5期)2022-01-18 05:42:10
水泵技術(shù)(2021年3期)2021-08-14 02:09:20
裝備制造技術(shù)(2020年3期)2020-12-25 05:22:30
制造技術(shù)與機(jī)床(2018年11期)2018-11-23 01:07:42
電子制作(2018年10期)2018-08-04 03:24:46
制造技術(shù)與機(jī)床(2017年10期)2017-11-28 05:20:43
重慶工商大學(xué)學(xué)報(bào)(自然科學(xué)版)(2015年10期)2015-12-28 07:43:58
振動工程學(xué)報(bào)(2014年2期)2014-03-01 01:15:22
振動、測試與診斷(2014年5期)2014-03-01 01:14:21
振動、測試與診斷(2014年4期)2014-03-01 01:14:00
