揭秘數字人,讓教師解放出來
2024-12-18 00:00:00倪俊杰
中國信息技術教育 2024年23期

編者按:近年來,尤其是在生成式人工智能爆火之后,數字人技術如一顆璀璨的星星在科技領域迅速崛起,正以前所未有的影響力改變多個行業的格局。從最初的概念萌芽到如今令人矚目的發展,數字人技術已經逐漸成為一種重要力量。本期文章將深入揭秘數字人技術的起源、內在原理以及在教育領域的應用,探尋數字人是如何為教師“減負”,釋放教師精力,創造更多教育價值,也關注其可能帶來的新挑戰。下期,我們將關注如何具體實現數字人,為教師所用。
摘要:數字人技術作為科技領域的新興力量,融合了多種技術實現模擬真人,能在多場景中與人類交互,應用范圍廣泛。本文闡述了數字人技術原理,并提出,大模型與數字人的結合為教育帶來新可能,其能拓展學生學習能力,增強學習交互性,提升知識共創力,為教師“減負”。同時文章也指出,數字人應用也存在安全隱憂,如引發倫理法律問題、數據隱私保護問題等,未來人類與數字人共存將面臨新挑戰。
關鍵詞:數字人;語音克隆;大模型;教師
中圖分類號:G434 文獻標識碼:A 論文編號:1674-2117(2024)23-0000-05
認識數字人
數字人(又稱虛擬數字人,本文統稱“數字人”)是一種通過計算機圖形學、深度學習等多種技術手段,高精度模擬真人外貌、聲音、動作和表情,并且能夠在一定程度上實現自主交互和智能反應的虛擬人物。它可以在眾多場景中與人類互動,提供多樣化的服務或娛樂體驗。2023年9月,杭州亞運會開幕式上的“數字人”點火儀式,引發了廣大網友的贊嘆和好奇。在主火炬點燃前,全球超過1億位“數字火炬手”組成了一個巨大數字人。這是亞運會史上第一次“數字點火”,也是裸眼3D技術、增強現實和人工智能技術的完美結合。如今,數字人幾乎進入了生活的各個角落,在刷視頻、聽音樂、看新聞的時候,你都可能邂逅數字人的“作品”。據媒體預測,到2025年中國虛擬人市場規模有望達480.6億元,用戶群體主要為中小型企業,需求主要集中在電商、衛生、社會保障和社會福利業、教育、金融和運輸業等行業,產品類型以數字員工和定制化數字人為主。
從內涵界定來看,數字人目前并沒有一個嚴格的定義。按照中國人工智能產業發展聯盟《2020虛擬數字人白皮書》中的定義,數字人需要滿足三點:一是要擁有人的外觀;二是要擁有人的行為,如語言、口型、面部表情、肢體動作等;三是要擁有人的思想,如能識別外部環境、與人交互等。按照以上標準,我們常見的一些動畫片、電影中的虛擬形象并不能算作數字人,因為它們雖然擁有人的外觀和行為,但是不能識別外部環境,更不能與人進行交互。數字人形象是由多項技術綜合集合而成的。其中,語音合成技術可以生成數字人的語音,表情生成技術可以生成數字人的表情,動作生成技術可以生成數字人的動作。隨著技術的不斷發展,數字人將變得更加逼真、自然、智能,越來越像真的“人”。
從實現效果來看,數字人可分為2D和3D兩類。2D數字人應用廣泛,如新京報貝殼財經的“AI小貝”、虛擬數字人“Ada”等。3D數字人中比較有名的是虛幻引擎的meta human,其背后涉及blendShape(混合形狀動畫)等先進技術。2024年5月17日,湖南博物院首次公開發布“辛追夫人”3D數字人形象,他們以馬王堆漢墓出土的辛追為原型,進行數字形象建立和互動智能體打造,高度還原其容貌,展示了3D數字人的高超技藝。當人工智能技術快速發展之后,數字人作為數字技術的前沿產物,正以前所未有的形態融入我們的日常生活。AIGC技術的發展,使得諸如Midjourney、Sora、騰訊智影等數字人生成的門檻越來越低,也激發了人們對數字人的強烈需求。
從應用范圍來看,數字人技術已經在各行各業發揮著重要作用。例如,虛擬主播可以應用于新聞、直播、娛樂等領域;虛擬導購在商場、超市、博物館等領域隨處可見,一些旅游景區或者博物館之類的地方,也會采用數字講解員,其服務效果比冷冰冰的語音講解器更有感染力,讓人覺得更親切;虛擬客服主要應用在銀行、電信、運營商等領域,一個具有人類形象的數字客服會讓咨詢者感覺更為溫暖,更愿意溝通交流解決問題;虛擬教師在教育、培訓等領域也有很多應用。
數字人技術的基本原理
數字人技術并非新興事物,其發展歷程可追溯至四五十年前。早在20世紀60年代,波音公司就開始試運用數字化的人體模型來研究飛機駕駛艙的人體工程學設計。當時的“波音人”具備人類的外形,能夠模仿人類的常見動作,而且還能在人們設置的場景中模擬人的動作,與環境進行交互。那么,如何理解數字人技術的原理?用一個簡單公式來說,數字人=形象生成+語音克隆+智能交互。具體而言,包括以下關鍵技術。
1.形象生成
形象生成是數字人技術的基石。它需要用計算機圖形學、計算機視覺、語音合成等技術,構建逼真的圖像、動作和聲音,以塑造擬人形象。為了創建不同的虛擬形象,數字人可以用真人的2D視頻或3D模型,也可借助生成對抗網絡(GAN)等方法。GAN是一種用兩個神經網絡(生成器和判別器)互相對抗,從噪聲中生成高質量圖像的技術。數字人的人體建模,與人工智能模型不同,專業的人體建模涉及數據采集、特征提取、模型構建、姿態估計等復雜操作。目前,短視頻制作多采用2D平面人體,僅僅是一個拍攝的視頻。真正的3D人體建模因受制于成本、終端性能和應用場景等因素而應用較少。
數字人形象生成的關鍵技術有兩個:一是面部表情捕捉,即通過高精度攝像頭和傳感器捕捉人臉的細微表情變化,并將這些數據轉化為數字信號。具體方法包括使用各種細節數據和3D面部網格技術,通過深度學習模型生成高度逼真的面部表情。二是動作捕捉,即利用動作捕捉技術記錄人類的身體動作,并將這些動作應用到數字人身上,使其表現出自然的肢體語言。兩種技術常常結合使用標記點和無標記點捕捉系統,以及機器學習算法,來精確模擬人體運動。
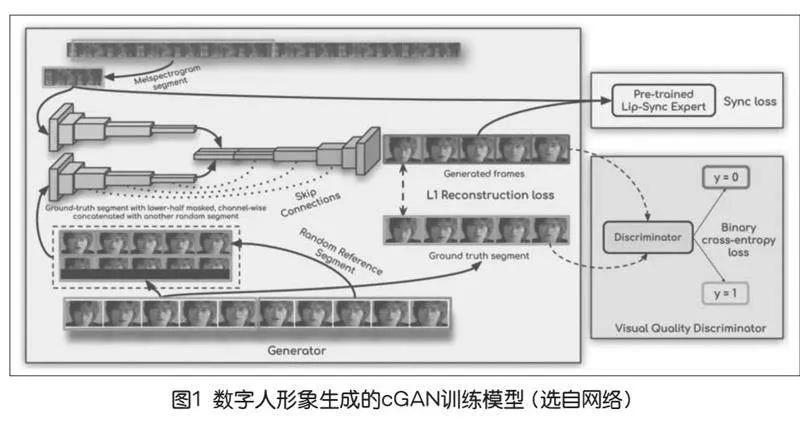
例如,K R Prajwal團隊在2020年的ACM國際多媒體會議上發表文章介紹了一款由倫敦帝國理工學院的研究團隊開發的人工智能模型——Wav2Lip,主要為了實現音頻與視頻口型的高度同步。Wav2Lip的出現可以在電影、電視劇、教育視頻等制作中,對演員的口型進行精確匹配,提高制作效率和質量,也可以結合數字人模型制作出具有高度自然感的虛擬主播,幫助那些在語言學習中用來生成具有正確口型的發音示例。Wav2Lip的核心是一個條件生成對抗網絡(Conditional Generative Adversarial Network,cGAN),通過特征提取——條件生成——對抗訓練——循環一致性,生成與條件一致的輸出。cGAN的訓練一共有一個生成器(下頁圖1左邊大框,Generator)和兩個判別器(圖1右邊兩個小框,分別是pre-trained lip-sync expert和visual quality discriminator)。[1]
設置兩個判別器是因為設計者認為之前的唇音同步效果不佳,需要一個額外的判別器來判斷唇音同步,這種做法使得唇音同步達到91%比例。講完唇音同步判別器,剩下的一個生成器和一個判別器就跟常規的GAN差不多了。生成器由身份編碼器、語音編碼器和面部解碼器三部分組成,其主要原理是通過一個專家鑒別器來訓練,從真實視頻學習的唇同步概念來強制生成器實現逼真的唇同步。[1]
2.語音克隆
語音克隆是數字人“說話”的關鍵技術,基于神經網絡的語音合成技術(如Tacotron和WaveNet),將文字轉化為自然流暢的語音,其邏輯關系為:聲音數據樣本→克隆算法→訓練模型→模型推理(文本生成語音)。在完成語音克隆后,數字人就擁有了自己的聲音模型,我們就可以輸入文字,讓模型幫你生成一段“模仿”你的語音,這個過程也叫TTS(Text To Speech,文本轉語音)。同時,為使數字人講話更真實,還需要同步口型,使語音與視頻中的人物口型匹配。
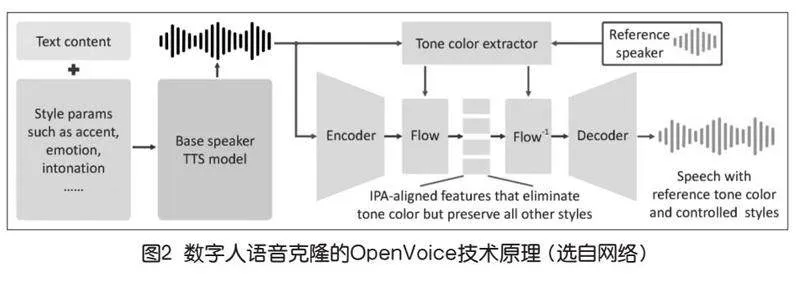
目前,許多公司的技術只需要通過參考一個小片段的音頻,就能夠精準復刻語音的情感、重音、節奏和語調,甚至能夠跨越不同國家的語言,如MyShell AI開發的開源項目OpenVoice就是其中之一。OpenVoice語音克隆原理主要用到了一個TTS()模型+音色特征提取器(如圖2),使用這種編碼器+解碼器的結構能夠控制音頻的合成,根據參考音頻,最終實現復刻音色。
3.智能交互
智能交互是數字人核心技術之一,賦予數字人“靈魂”和生命力。它深度融合了自然語言處理、語音識別、圖像識別及情感分析等尖端技術,實現了全方位、多模態的溝通體驗。智能交互是數字人與用戶進行溝通和對話的能力,它需要用自然語言處理、語音識別、圖像識別、情感分析等技術,實現多模態的交互,包括語音、文字、圖像、視頻等。以某智能公司的數字人為例,在用戶與數字人對話時通過ASR識別用戶提出的問題,然后問題被發送給數字人大腦(FAQ+大模型)獲取相應的答案,再通過TTS技術將答案轉換成音頻,經由音頻驅動數字人的唇部和面部動作,形成數字人說話視頻,從而實現真人與數字人的對話(如圖3)。
數字人可以通過構建知識系統(如知識圖譜),實現數字人的實時交互和自主學習,但在知識獲取、知識融合、知識質量等方面仍面臨著諸多挑戰。
數字人制作工具
為自己定制數字分身,也成為人們應對多重任務挑戰的一種策略:直播帶貨主播,讓數字分身接替了自己的工作;媒體也開發了數字主持人、數字記者等。目前,國內外可選的數字人制作工具也有很多。
1.國外數字人制作工具
國外數字人制作工具發展比較早,且種類豐富。英偉達(NVIDIA)的Omniverse平臺通過利用GPU技術和深度學習算法,提供了先進的AI數字人生成工具。該平臺能夠生成高度逼真的虛擬形象,廣泛應用于影視制作、虛擬現實(VR)等領域。Unity Technologies公司推出的虛擬人物生成工具主要面向游戲和影視行業,支持高精度的面部和動作捕捉技術。通過深度學習和機器學習算法,能夠生成逼真的虛擬角色,提升用戶的沉浸式體驗。Epic Games公司創立的Unreal Engine虛擬角色生成工具支持多種面部表情捕捉和語音合成功能,廣泛應用于游戲開發、虛擬現實等領域。MetaHuman-Stream作為開源實時交互流式數字人項目,能將數字人類虛擬形象與真實世界無縫融合。通過集成多種AI模型,該技術能夠實現高度逼真的聲音模擬和流暢的對話交互。用戶可以自定義數字人的外觀和聲音,無論是在線教育還是虛擬客服,都提供了一種新穎、沉浸式的互動體驗,推動了虛擬數字人在多樣化應用場景中的普及和應用。
2.國內數字人制作工具
近年來,國內數字人技術發展迅猛,涌現出眾多優秀的制作工具。阿里巴巴達摩院推出的虛擬形象生成工具,運用深度學習和計算機視覺技術,實現高精度的面部表情捕捉和語音合成,廣泛應用于電商直播、虛擬客服等領域,提高了用戶的互動體驗。騰訊AI Lab的虛擬形象生成工具,支持多語言語音識別和自然語言處理技術。通過深度學習模型生成逼真的虛擬角色,應用于游戲和社交媒體,提升了用戶的沉浸感。字節跳動的AI Lab推出了多個虛擬主播和虛擬助手應用。這些工具不僅支持高精度的面部表情捕捉,還具備強大的自然語言處理能力,廣泛應用于短視頻平臺和內容創作。此外,平民化的剪映軟件支持公模數據的數字人,也支持上傳聲音驅動,深受用戶喜愛。
大模型+數字人給教師帶來無限可能
隨著用戶需求和產品要求的不斷提升,數字人的發展面臨著一系列技術挑戰。如何在實時交互中生成高質量的虛擬形象,如何提高語音合成的自然度和表達能力,這些都是當前技術亟待解決的問題。而隨著大模型的橫空出世,數字人領域迎來前所未有的發展機遇。在大模型的加持下,數字人將能夠通過自我學習和創造,生成自己的形象、語言、知識和情感,形成自己的個性和風格。
那么問題來了,如果將大模型技術和數字人技術聯合起來,并應用于教育領域,又會給教師帶來哪些影響?在此之前,數字人已發揮一定的作用,如互動教學,提供個性化的學習內容和反饋,輔助教師教學,使學生可以在任何時間、任何地點與數字人教師互動,獲得即時的學習幫助。然而,早期的數字人還不夠“聰明”,其對復雜問題的推理和解釋能力還比較欠缺。隨著大模型技術日趨成熟,數字人的能力也顯著提升。浙江大學的翟雪松等提出數字人可以從三個方面賦能教學,分別是拓展學生學習能力、增強具身交互性、提升知識共創力。[2]陳衛東等認為數字人可以通過扮演人類的朋友、伴侶和寵物等多種角色,給用戶帶來親切感和陪伴感,減少其對陌生場景的恐懼和排斥,提供個性化情感服務,滿足其情感需求,從而提升學習者的學習效率與積極性。[3]而吳長城等研究指出,新一代生成式人工智能技術驅動的新一代教育數字人為師生教育場景創設、智慧問答、智能反饋等帶來了質的飛躍,可以讓每位教師和學習者打造個人的數字分身,生成自己的個性化教育數字人。能夠模擬真人教師,與學習者進行互動,提供個性化的學習資源,有效提高學習者的學習體驗、學習興趣、社會存在感和學習成績。[4]“大模型+數字人”的組合能夠充分發揮兩者優勢,大模型提供數據驅動的內容創作,給數字人“裝”上智慧的大腦,使其能夠模擬人類行為和思維,實現智能化交互,給學習者提供實時的反饋與互動,有利于實現個性化教育、自適應學習,積極賦能學生自主學習。當大模型+數字人技術的疊加應用后,將會給教師帶來無限可能,為教師“減負”,成為其得力的教學助手。
數字人技術的潛在隱憂
數字人應用的盛行,也引發了諸多擔憂。人們不禁要問,當數字人脫離了真人控制,人們應如何對待其分身?每個人都可能因各種需要產生自己的數字分身,人們是否真的愿意他人任意處置自己的數字分身?
數字人將與人類形成更深層次的互動和共生,引發新的倫理和法律問題。目前,數字人主要以一種工具或玩具的角色與人類交往,受到人類的控制和約束;未來,數字人將以一種伙伴或同伴的角色與人類相處,享有人類的權利和義務。數字人將不僅僅是一種機器或玩偶,還是一種“生命”,這將需要更多的信任和尊重、更多的理解和溝通、更多的規范和保護。值得注意的是,數字人在使用過程中會涉及大量用戶數據,如面部表情、語音信息等。如何保護用戶數據隱私,防止數據泄露和濫用,是一個重要的挑戰。同時,數字人的廣泛應用可能引發一系列倫理和法律問題,如虛擬形象的濫用、虛假信息的傳播等,這些問題都是不可回避的,需要各方共同努力,確保數字人技術的健康發展。
結語
未來,人類與數字人必將共存共生,數字人將繼續推動科技與藝術的融合,成為人類生活中不可或缺的一部分。技術的飛速發展和應用拓展,將會使數字人為社會帶來更多的創新和價值,引領我們進入一個全新的智能時代。隨著AIGC和數字人技術的不斷發展,數字人員工將成為人類的親密伙伴。那么,我們該如何與數字人共存?數字人會如何改變人們的生存與社會交往?這將是智能時代生存的新命題,我們拭目以待。
參考文獻:
[1] Prajwal K R, Mukhopadhyay R, Namboodiri V P, et al. A lip sync expert is all you need for speech to lip generation in the wild[C]//Proceedings of the 28th ACM International Conference on Multimedia. New York: ACM,2020:484-492.
[2]翟雪松,吳庭輝,李翠欣,等.數字人教育應用的演進、趨勢與挑戰[J].現代遠程教育研究,2023,35(06):41-50.
[3]陳衛東,鄭巧蕓,褚樂陽,等.智情雙驅:數字人的教育價值與應用研究[J].遠程教育雜志,2023,41(03):42-54.
[4]吳長城,胡雙武,蔣雨江,等.GenAI驅動的教育數字人架構設計與實證研究[J].現代教育技術,2024,34(09):26-36.
