用XEduHub實現零樣本圖像分類
2024-12-18 00:00:00謝作如
中國信息技術教育 2024年23期

摘要:用AI解決問題的核心工作是訓練模型,而訓練模型往往受制于數據的匱乏。因此,借助常見的預訓練模型,用零樣本訓練方式成為一種重要的技術解決方案。本文借助XEduHub中的CLIP模型,使用簡潔的代碼設計了一個零樣本圖像分類的實驗,為青少年AI科創活動設計提供了一個新思路,并有效簡化工作量和復雜度。
關鍵詞:XEduHub;深度學習;零樣本圖像分類
中圖分類號:G434 文獻標識碼:A 論文編號:1674-2117(2024)23-0000-03
要用AI解決問題,訓練一個人工智能模型是核心工作。在帶領學生做AI科創活動時,往往受制于數據的匱乏而無能為力。例如,在某教學案例交流活動中,有教師提出想訓練一個用于環境保護的模型,對水面的各種漂浮物進行識別,卻苦于找不到“死魚”的數據。即使借助了網絡,也因為角度、位置等問題,導致訓練出來的模型精度很低。
考慮到XEduHub內置了CLIP模型,又同時具備了文本和圖像的特征提取功能,筆者提出了一個假設:能否利用CLIP模型的多模態特征提取能力,來設計“零樣本圖像分類”的實驗,進而解決類似的數據匱乏難題。
零樣本圖像分類技術簡介
零樣本圖像分類(Zero-shot image classification)是一種圖像分類方法,指模型能夠對以前未見過的圖片類別進行分類。也就是說,零樣本圖像分類要求模型能夠在沒有看到特定類別樣本的情況下,也能夠對這些類別數據進行分類。要實現這一能力,通常需要多模態模型(指同時支持多種類型的數據,如文本、圖像、音頻等),并且這一模型已經在大量的圖像和描述數據集上進行了訓練。只需要給模型一些數據相關的額外信息(這被稱為輔助信息,可以是描述或屬性),模型就能夠預測未見過的分類。在一些特定的場景中,如只有少量標記數據,或者想要快速將圖像分類功能整合到應用程序中,就很需要用到這種技術。
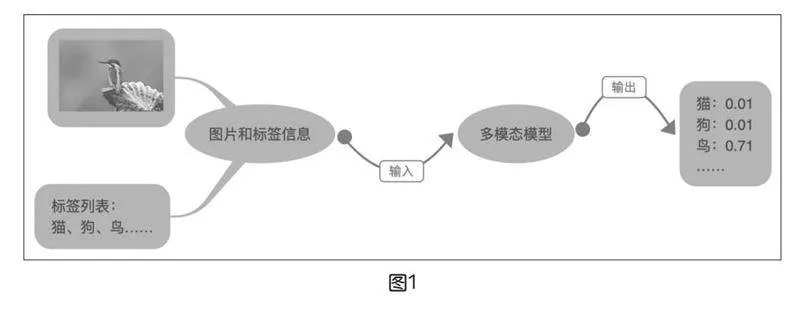
零樣本圖像分類任務應用很簡單,一般會在推理圖像時給出可能的標簽列表。例如,在推理圖像時,同時傳遞一個標簽列表,如飛機、汽車、狗、鳥,模型將會在標簽中挑選出可能性最大的標簽。如圖1所示,即使從來沒有訓練過“翠鳥”的數據,多模態模型依然能根據描述判斷出“鳥”的概率最大。
XEduHub中的CLIP特征向量提取功能
XEduHub中提供了文本特征提取和圖像特征提取任務,其實是借助內置的CLIP模型來實現的。CLIP模型(Contrastive Language-Image Pre-training)是基于文本圖像對比的預訓練模型,也是多模態領域的經典之作,可以同時處理文本和圖像。它能將不同模態的原始數據映射到統一或相似的語義空間,實現不同模態信號間的相互理解,基于此實現不同模態數據間的轉化與生成。
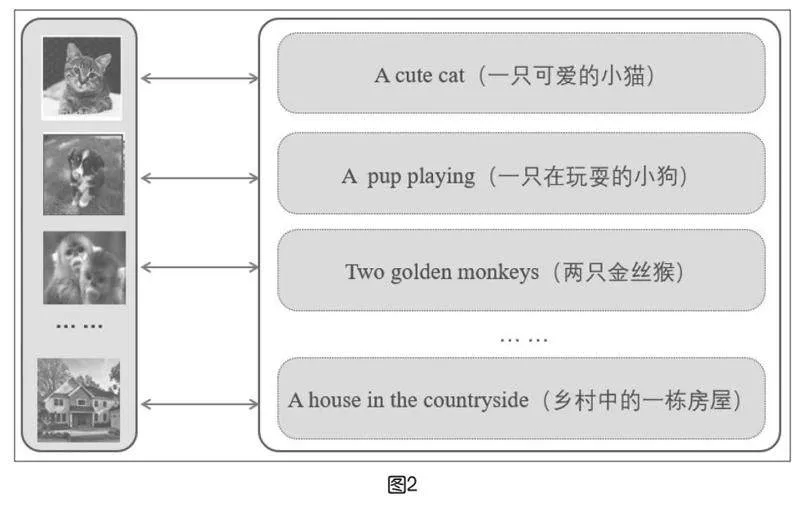
CLIP模型與以往的圖像分類模型不同,它并沒有使用大規模的帶有標注的圖像數據集,而是利用互聯網上的未經人工標注的“圖像-文本”數據對進行訓練。如圖2所示,第一張圖像是一只小貓,與其配對的文字是“A cute cat”……CLIP模型一共收集了4億個“圖像-文本”的數據對,可見數據集規模相當大。
將圖像或者文本輸入到XEduHub中,即可得到512維的向量特征。CLIP模型采用的是嵌入(Embedding)技術,意義相近的文本或者圖像,得到的向量特征也接近。例如,翠鳥圖像和“鳥”這一文本的向量距離(一般使用余弦向量)比和“貓”“狗”會更加接近。按照這樣的原理,就能實現零樣本圖像分類。
零樣本圖像分類實驗的設計
XEduHub內置了CLIP模型,并且在“Workflow”模塊中設計了兩個任務名稱進行調用,分別為“embedding_image”和“embedding_text”。傳入一個或者一組圖像或者文本,即可輸出相應的向量特征。為了方便使用,XEdu提供了幾個常用的函數,如get_similarity用于計算相似度矩陣、visualize_probability用于概率分布的可視化。
實驗的參考代碼如圖3所示,其中“image_data/bird.png”為“翠鳥”的圖片。對于“cifar10_classes”,筆者選擇了常見的圖像分類數據集“CIFAR10”的分類信息。
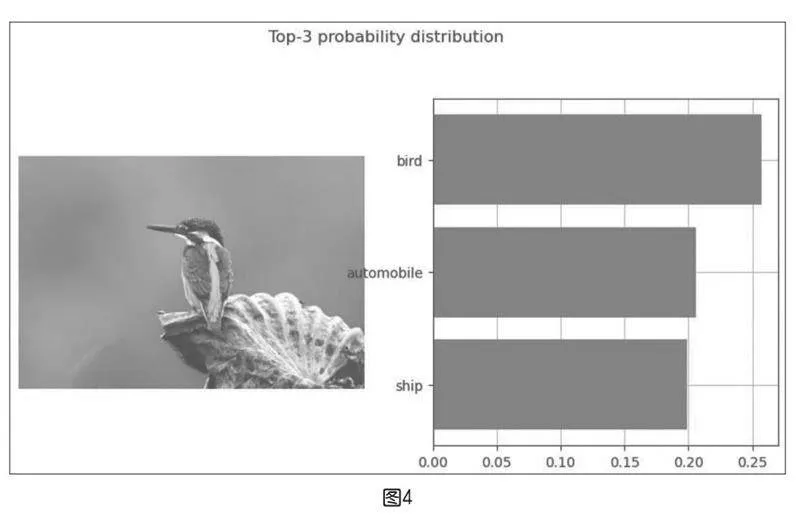
從運行結果(如下頁圖4)可以看出,CLIP模型準確地識別出“Bird”是概率最大的類別。
零樣本圖像分類技術的應用與拓展
按照上述實驗,只要修改類別標簽,就能解決一些常見的分類任務。如果使用更加復雜的分類標簽信息,如CIFAR100(100個類別)或者ImageNet(1000個類別),能解決的任務會更多。從原理上看,無非是先提取數據的向量特征,然后在類別標簽中找出最接近的。
在CLIP模型發布之后,越來越多的類似模型不斷發布。選擇一些功能更加強大的多模態模型,還可以解決更多的任務:
①文本分類和知識庫。因為大模型容易“胡說八道”,為了確保準確率,目前很多知識庫的系統就采用向量特征匹配的方式來實現,如浦育平臺中的“文本分類”體驗活動,就是采用了阿里達摩院發布的GTE模型來提取向量特征。
②音頻分類。一些新發布的多模態模型已經同時支持文本、圖像和音頻的對應關系。不用做語音識別,也不用訓練語音數據,能對常見的語音進行分類。
③圖像搜索。先用模型對電腦中的圖像進行向量特征提取(可以理解為編碼),然后用關鍵字來搜索圖像,是不是很酷?
④景點匹配。看看某段文本對應的是某個景點,當然,這需要在向量數據的基礎上繼續訓練出一個簡單的全連接神經網絡或者SVM模型。
……
總結
常見的圖像分類任務一般都采用監督學習方式,需要準備大量帶有標簽的圖像數據集進行訓練。當遇到新的類別時,需要重新訓練模型。例如,已經訓練了一個貓狗分類器,但是如果又想要區分寵物豬,這個已有的貓狗分類器就不能用了,需要再訓練一個包含貓狗和寵物豬的分類器。通過本文中的實驗,可以看到零樣本圖像分類技術將大大簡化青少年AI科創活動的工作量。但也要認識到,監督學習方式的圖像分類技術依然非常重要。相對來說,使用CLIP模型做圖像分類,對邊緣硬件的算力要求較高,而且不適合做對精度要求較高的任務。同樣,除了多模態模型外,單模態的模型也采用類似方式來解決一些問題。因為對很多模型來說,核心的工作都是做數據的向量特征編碼,也可以理解為向量化。因此,中小學要開展人工智能教育,“向量”這一知識點需要早點學習。
