DAResNet:基于動態卷積與注意力的魚類分類算法
2025-02-23 00:00:00尚浩然俞洋
物聯網技術 2025年4期




摘 要:針對現有水下魚類分類準確率低,抗干擾能力和泛化能力差等問題,本研究在ResNet-D模型的基礎上,設計了一種名為DAResNet的模型。首先,將主干網絡中的部分卷積替換為全維動態卷積模塊,以提高網絡模型的特征提取能力及網絡準確率;接著,通過引入高效多尺度注意力機制進一步增強模型對關鍵特征的識別和響應能力,以提升模型的抗干擾性;最后,在下采樣階段,引入高斯模糊和擠壓激勵注意力平滑特征并強化模型對關鍵信息的提取,以提升泛化能力。相比原始算法,DAResNet在水下魚類識別任務中準確率提升了3.05%,性能提升明顯,證明了所提方法的有效性。
關鍵詞:全維動態卷積;注意力機制;深度學習;特征提取;高斯模糊;擠壓激勵注意力
中圖分類號:TP183 文獻標識碼:A 文章編號:2095-1302(2025)04-0-05
0 引 言
近年來,隨著我國城市化進程的持續推進,取得了許多令人矚目的成績。然而,也衍生出一系列不容忽視的問題。其中,水域污染問題和濫捕現象日益嚴重,已經成為人們關注的焦點[1-2]。為更好地保護水下魚類,同時確保水域生態系統的安全,水下魚類鑒定識別尤為關鍵。
以卷積神經網絡為代表的深度學習算法取得了顯著進展,顯示出解決水下魚類分類等復雜視覺分類問題的巨大潛力。例如,文獻[3]通過改進Res2Net模型的網絡結構,結合注意力機制、數據增強方法和CELU激活函數實現了10種淡水魚的分類。文獻[4]通過在EfficientNetV2上引入混合空洞卷積和加裝坐標注意力機制的方法,實現了對7種水下魚類的圖像分類。文獻[5]提出的ResNet-D模型,通過修改模型結構,改進訓練策略,在ImageNet數據集上展現出了卓越的性能。這一進展證明了深度學習在圖像識別領域的強大能力,同時也為水下魚類識別等專項任務提供了新的思路[6]。然而,現有的網絡針對水下魚類的準確識別還存在一些挑戰。水下環境的復雜性和多變性問題:光照、水質等因素會對網絡造成干擾;圖像采集問題:在圖像采集過程中,魚類姿態、方向和角度可能發生變化,導致同一種魚在不同姿態下呈現出截然不同的外觀,從而影響模型的泛化能力[7]。
為解決這些涉及水下魚類分類任務的問題,本研究基于ResNet-D深度學習模型[8],提出了改進的DAResNet模型,在訓練時采用余弦退火學習率調度策略與標簽平滑對模型中的超參數進行優化,用以提高水下魚類分類任務的準確率和工作效率,并能夠適應不同水域場景下的水下魚類識別場景。
1 模型架構
1.1 DAResNet模型簡介
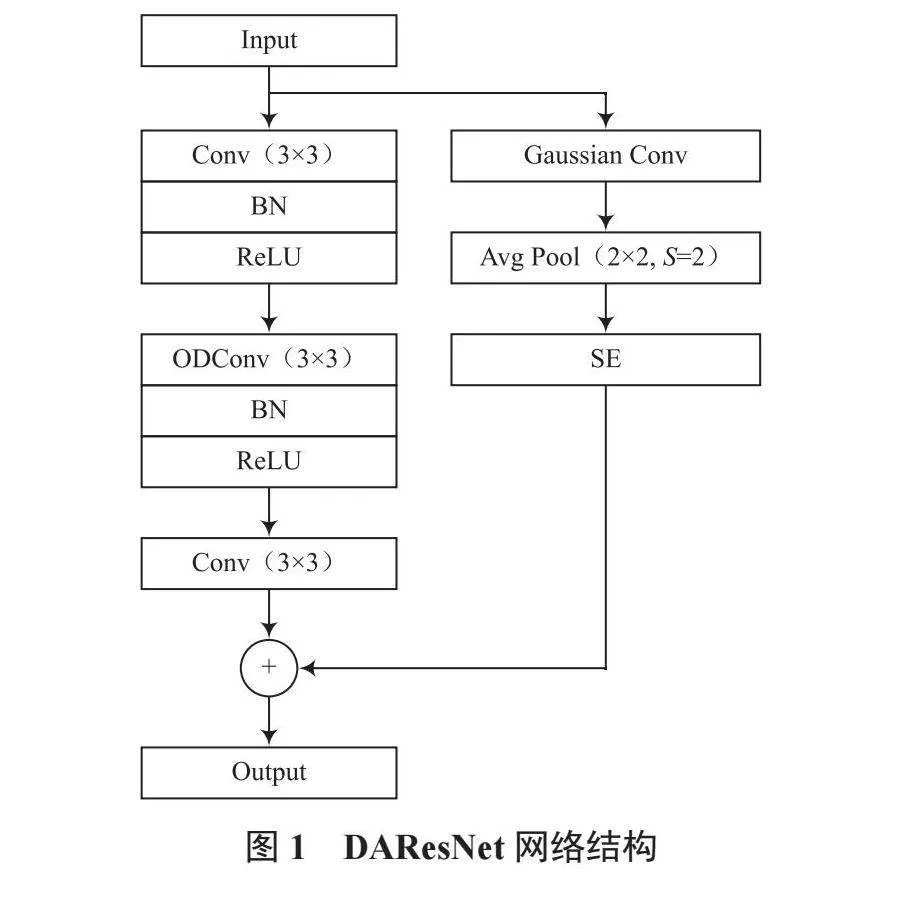
為解決水下魚類分類問題,本文提出了DAResNet網絡,該網絡在ResNet-34D網絡的基礎上進行了三處改進。鑒于水下環境復雜多變,魚類圖像特征難以準確提取,本文使用全維動態卷積(Omni-Dimensional Dynamic Convolution, ODConv)替換原模型主干網絡中的部分卷積,以強化模型的特征提取能力[9];為更好地適應魚類姿態的多樣性以及隨之變化的外觀特征,本研究引入了高效多尺度注意力(Efficient Multi-Scale Attention, EMA)[10],通過多尺度捕獲魚類特征,增強模型對魚類形態多變性的理解以及在復雜環境中的抗干擾能力;為減輕水下噪聲對于模型的干擾,在下采樣階段引入高斯模糊和擠壓激勵注意力(Squeeze-and-Excitation, SE)對信息進行平滑處理[11],提升模型的泛化能力。DAResNet網絡結構如圖1所示。
1.2 DAResNet模型改進策略
1.2.1 全維動態卷積
傳統的卷積神經網絡模型(Convolutional Neural Networks, CNN)訓練完成后,會生成一套固定的卷積參數。在模型推理階段,對于不同的輸入數據,模型均使用相同的參數進行推理,忽略了不同輸入樣本之間的特征差異。
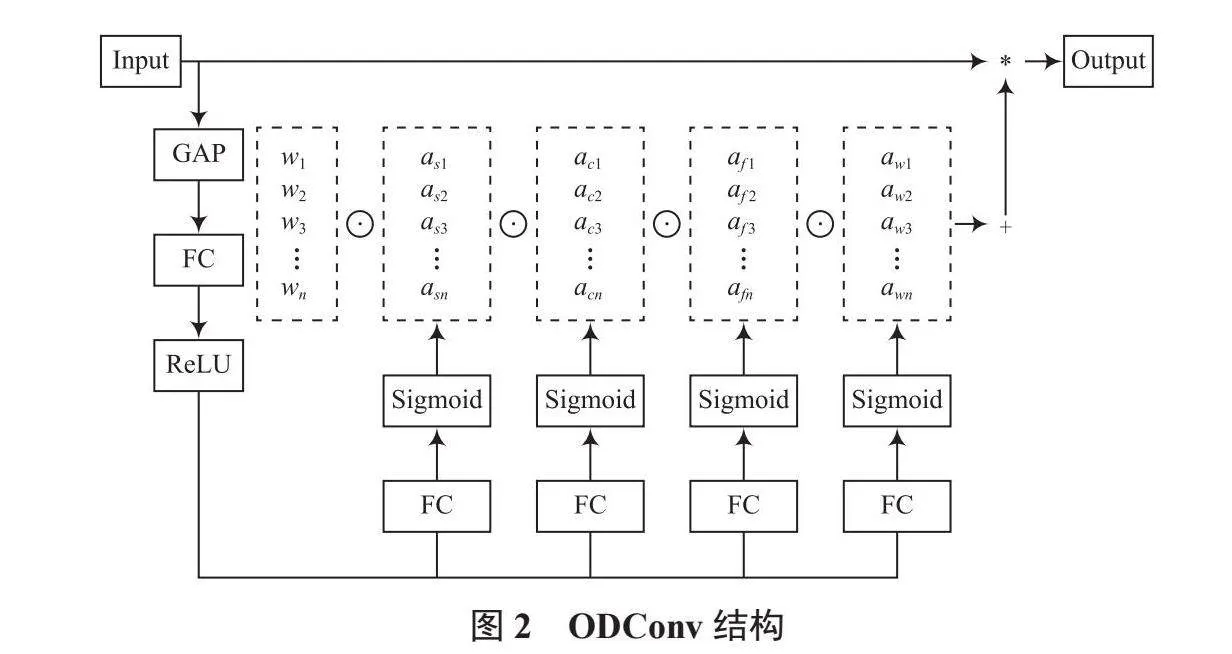
為解決上述問題,文獻[12]提出了全維動態卷積,該卷積對卷積核的四個維度進行注意力加權,可以根據輸入數據的不同而動態調整,使卷積核更好地適應輸入數據的特征,形成更強的特征提取能力。為提升水下魚類分類任務的準確率,本文在算法中引入全維動態卷積ODConv。在利用ODConv提取特征時,首先對輸入圖像應用全局平均池化(Global Avgrage Pooling, GAP)進行處理,隨后通過全連接(Fully Connected, FC)層和ReLU激活函數獲取初步的特征表示。引入一種多維注意力機制,對卷積核的四個維度(卷積核、空間維度、輸入通道維度、輸出通道維度)進行相關計算。ODConv結構如圖2所示。
上述四個通道的參數通過多頭注意力計算得到。借助這種方式,ODConv卷積可以根據輸入數據動態調整卷積,從而提升模型的性能。ODConv卷積的計算如下所示:
(1)
(2)
式中:awi表示卷積核Wi的注意力;asi表示卷積核空間維度的注意力;aci表示輸入通道的注意力;afi表述輸出通道的注意力;Ai表示經過多個注意力權重加權處理后的卷積核;表示不同維度的乘法計算。上述四種注意力相互補充,因此多維度并行處理的策略允許模型更細致地捕捉和調整卷積核的權重,以滿足不同的特征表示需求。使用ODConv可以增強模型的特征提取能力,提高模型的識別準確率。
1.2.2 EMA注意力模塊
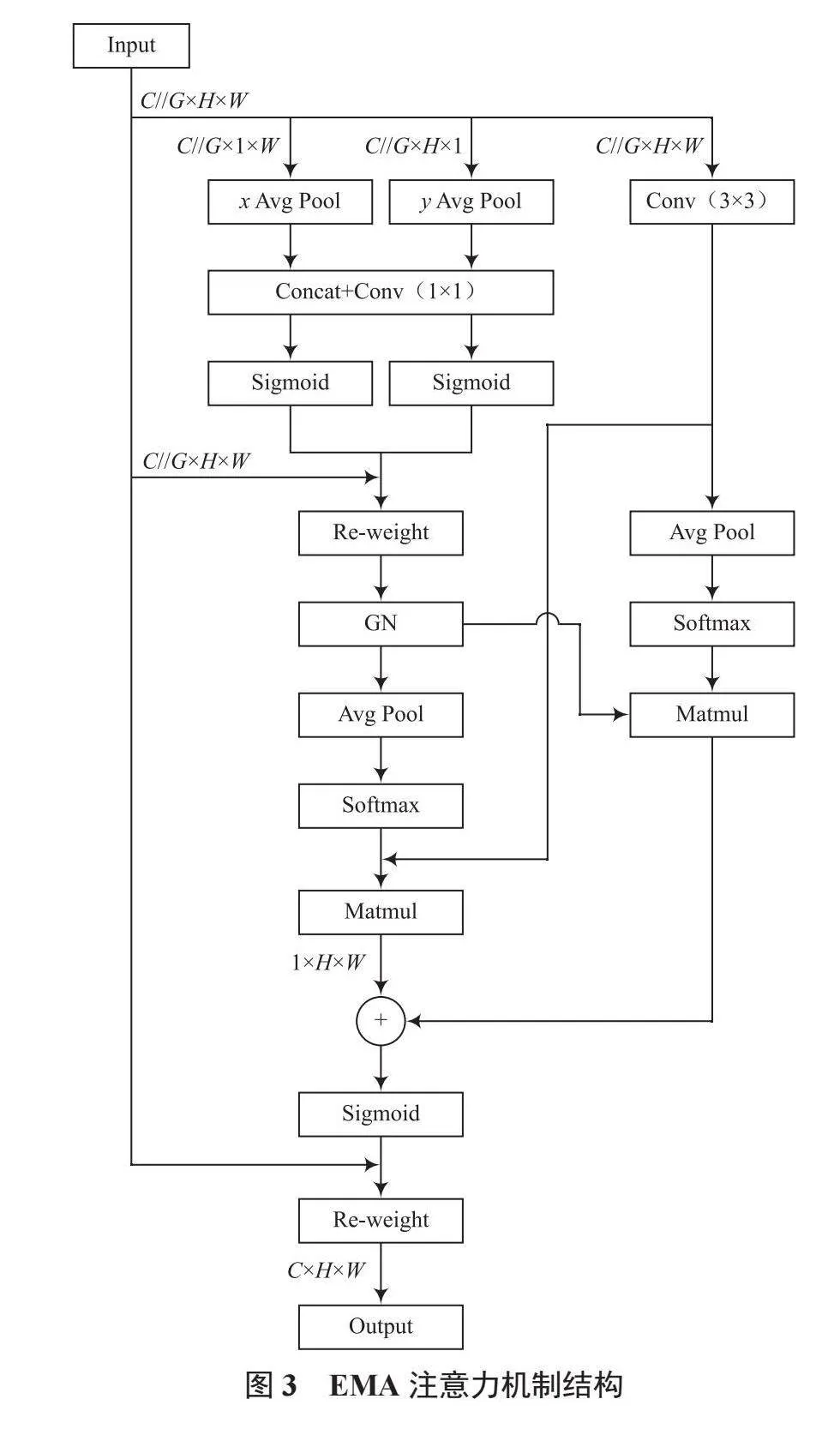
在水下魚類分類任務中,研究人員面臨的一大挑戰是魚類圖像的大小和比例不一致。由于水下環境的不可預測性和拍攝條件的多樣性,魚類可能以不同的尺度和角度出現在圖像中,因此難以全面捕捉魚類特征。為此,本文引入EMA注意力機制來解決這一問題。EMA注意力機制使用并行結構,通過并行子網絡的設計,EMA機制實現了對多尺度特征的提取。左側的分支結構借鑒坐標注意力(Coordinate Attention, CA)機制[13],對輸入特征從高度和寬度兩個方向進行平均池化,捕捉跨通道的特征信息;右側的分支結構則通過3×3卷積強化對局部空間特征的捕獲能力。最終,通過矩陣乘法整合兩個分支的輸出,實現對多尺度特征的提取。這種并行子網絡結構的設計使EMA能夠有效提取和融合全局和局部特征,從而增強模型對水下魚類圖像中的尺度和形態多樣性的識別能力。EMA注意力機制結構如圖3所示。
1.2.3 池化方法
在處理水下魚類分類任務時,為減少噪聲干擾,本研究在池化前使用高斯卷積核對圖像進行預處理[14]。高斯卷積核通過其特有的權重分布實現圖像的平滑處理,降低圖像中的高頻噪聲,同時保留重要的低頻信息。
(3)
式中:σ為標準差,決定權重分布的寬度;x和y表示距離中心點的水平和垂直距離。
在上述改進的基礎上,本文額外引入了SE注意力機制,SE注意力機制通過重塑通道間的權重值,強化對當前任務有益的特征通道的影響力,同時降低對當前任務貢獻較小的特征通道的影響力,以進一步提升模型對重要特征的識別能力,從而提高模型的泛化能力。
2 實驗方法與結果
2.1 數據預處理
本研究的數據集通過整理Kaggle網站公開的海洋魚類數據集得到,數據集包括22種魚類圖片,每類有500張圖片,共計11 000張圖片。本文數據集的特點如下:
(1)類別間差異相對較小,不同魚類圖像存在相似之處,因此容易出現誤識別;
(2)數據圖像分辨率差異較大,且圖像大小不一;
(3)樣本圖像中干擾項較多,如不同的背景和光線變化,將進一步增加魚類識別的難度。
針對數據集中存在的問題,本文在將數據進行訓練前通過數據增強方法對數據進行預處理[15],以期提升模型的性能和泛化能力。本研究主要采用的數據增強策略如下:
(1)調整圖像輸入尺寸,將圖像尺寸統一縮放到224×224,以確保模型處理相同尺寸的輸入圖像;
(2)在訓練模型時,采用RandAugment數據增強策略[16],該策略隨機實施一系列預定義的圖像變換方法,如旋轉、裁剪和色彩變換等,增加數據的多樣性;
(3)對圖像進行歸一化處理,加速模型收斂并提升其穩定性。
圖4(a)為原始圖像,圖4(b)~圖4(e)為應用RandAugment數據增強方法后的圖像。
2.2 實驗配置
實驗平臺配置:CPU為Xeon? Platinum 8352V CPU @ 2.10 GHz,搭載4090型號的24 GB顯卡,操作系統為Ubuntu20.04,內存120 GB。實驗代碼均采用Python語言編寫,使用深度學習框架為1.11版本的pytorch,CUDA為11.3。
合適的超參數能夠有效保證深度學習的準確率,本實驗配置的超參數:batch-size設置為128,學習率設置為0.000 1。
損失函數為交叉熵損失函數CrossEntropyLoss[17],訓練時[18]設置標簽平滑系數為0.1。此外,為進一步提高訓練效果,本實驗還采用了余弦退火學習率調度策略以確保模型在訓練中達到更優的結果。
2.3 實驗結果與分析
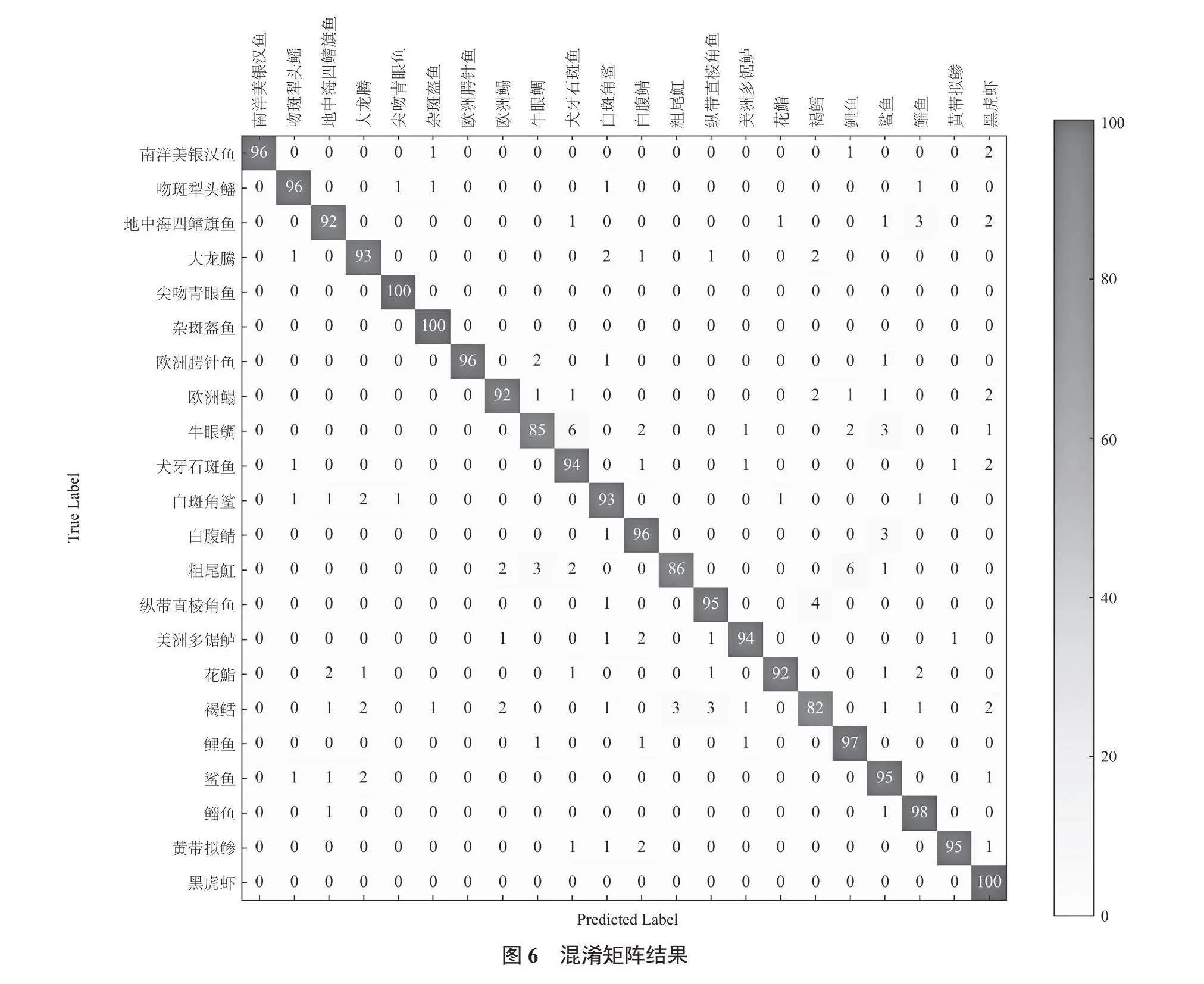
為驗證本實驗使用的網絡模型在水下進行魚類識別時的性能,本文選擇以混淆矩陣[19]為工具、以準確率為指標對實驗結果進行評價。其中,混淆矩陣是用于多分類問題的評估工具,它以表格的形式展示模型預測結果與真實標簽之間的對應關系,用于分類正確與錯誤情況。在混淆矩陣中,行代表真實的標簽,列代表預測類別,矩陣的單元格顯示模型分類到每個類別的次數。本次任務選擇準確率(Accuracy)作為衡量混淆矩陣性能的指標,公式如下所示:
(4)
式中:TP(True Positive)表示正確預測為正類的樣本數;TN(True Negative)表示正確預測為負類的樣本數;FP(False Positive)表示錯誤預測為正類的負類樣本數;FN表示(False Negative)錯誤預測為負類的樣本數。
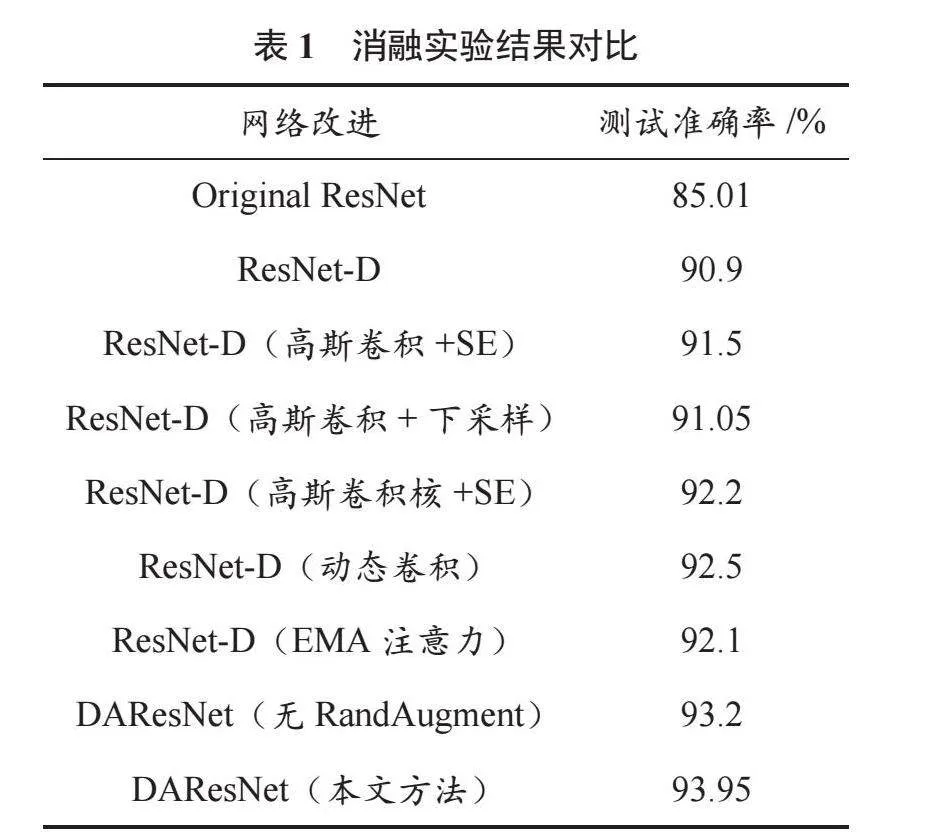
消融實驗結果對比見表1。
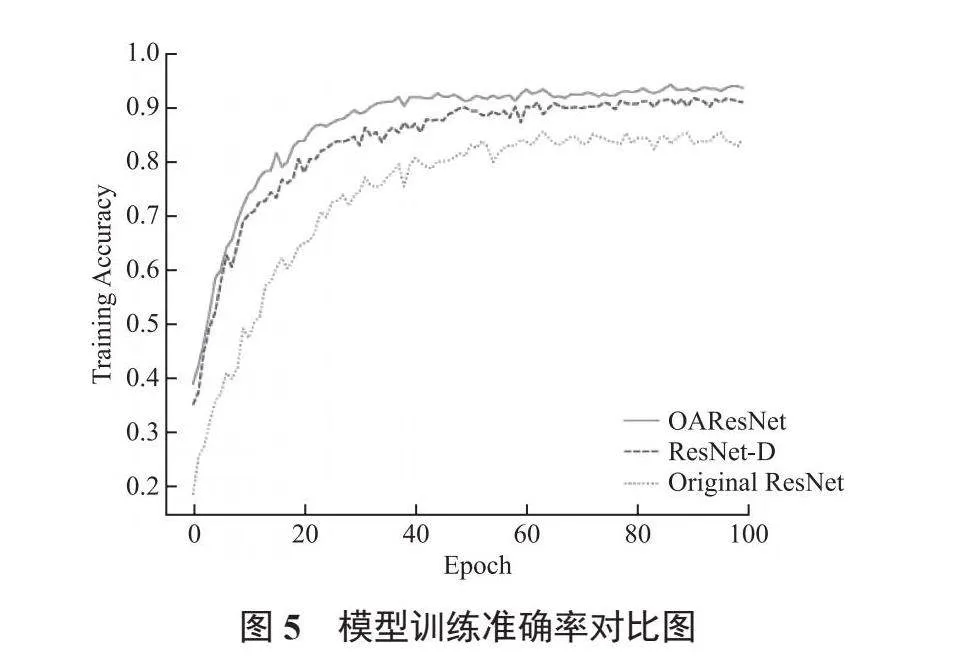
模型訓練準確率對比圖如圖5所示。混淆矩陣結果如圖6所示。
觀察表1和圖5、圖6可知,本文提出的DAResNet網絡模型在模型的收斂速度、穩定性方面均優于改進前的ResNet-D模型以及原始的ResNet網絡。
本文提出的DAResNet模型的最高預測準確率達93.95%,其他模型如加入全維動態卷積的ResNet-D模型準確率較高,為92.5%,采用高斯卷積+下采樣的ResNet-D模型準確率為91.05%,加入SE注意力后,準確率提升到92.2%。上述消融實驗的結果證明了各項技術對增強模型性能的貢獻,也佐證了本文改進方法的科學性與合理性。綜上所述,DAResNet模型表現出了卓越的能力,充分驗證了本文所提方法的有效性。
3 結 語
為解決水下環境復雜多變而影響水下魚類識別分類,導致水下魚類識別準確率較低的問題,本文設計并實現了一種名為DAResNet的深度學習模型,使用RandAugment數據增強策略優化了訓練過程。該模型的創新點主要在于以下三個方面:
(1)本研究使用全維動態卷積替換普通卷積,使模型能夠更加靈活地提取特征之間的差異;
(2)利用EMA注意力機制,模型能夠更準確地識別不同尺度和角度的魚類圖像的關鍵特征,強化抗干擾能力;
(3)在下采樣層,使用高斯卷積核的SE注意力機制提升下采樣性能,進一步增強模型的泛化能力。
經過實驗驗證,本文提出的改進方法顯著提升了模型的準確性和泛化能力,使其更適用于水下魚類的分類識別研究。
綜上所述,本文方法不僅在水下魚類分類識別任務中表現良好,更有望為海洋生態監測、生物多樣性保護以及水產養殖等領域帶來積極的推動作用。期待這一研究成果能夠在實際應用中發揮更大的價值,為相關領域的進步與發展貢獻積極的力量。
參考文獻
[1]白璐,孫園園,趙學濤,等.黃河流域水污染排放特征及污染集聚格局分析[J].環境科學研究,2020,33(12):2683-2694.
[2]王華.過度捕撈與生態環境:來自太湖的人類學個案[J].原生態民族文化學刊,2022,14(3):31-40.
[3]趙正偉,朱宏進,楊根滕,等.基于改進Res2Net模型的淡水魚類圖像分類研究[J].軟件工程,2022,25(7):28-32.
[4]龔瑞昆,趙學智,趙福生.基于EfficientNetV2-HDCA模型水下魚類圖像分類算法研究[J].電子測量技術,2022,45(22):128-134.
[5] HE T, ZHANG Z, ZHANG H, et al. Bag of tricks for image classification with convolutional neural networks [J]. Computer vision and pattern recognition, 2018(9): 558-567.
[6]曹建榮,莊園,汪明,等.基于ECA的YOLOv5水下魚類目標檢測[J].計算機系統應用,2023,32(6):204-211.
[7]呂俊霖,陳作志,李碧龍,等.基于多階段特征提取的魚類識別研究[J].南方水產科學,2024,20(1):99-109.
[8]陳清源,金帆,馮德華,等.基于雙模型集成的太陽黑子磁類型分類[J]. 天文研究與技術,2022,19(6):636-644.
[9]嚴蓬輝,陳緒兵,彭伊麗,等.基于改進YOLOv5s的激光軟釬焊焊點缺陷檢測算法[J/OL].激光與光電子學進展,1-17 [2024-02-28]. http://kns.cnki.net/kcms/detail/31.1690.TN.20230821.1429.084.html.
[10]王澤宇,徐慧英,朱信忠,等.基于YOLOv8改進的密集行人檢測算法:MER-YOLO[J/OL].計算機工程與科學,1-17 [2024-02-28]. http://kns.cnki.net/kcms/detail/43.1258.tp.20231110.1458.002.html.
[11]徐沁,梁玉蓮,王冬越,等.基于SE-Res2Net與多尺度空譜融合注意力機制的高光譜圖像分類[J].計算機輔助設計與圖形學學報,2021,33(11):1726-1734.
[12] LI C, ZHOU A, YAO A. Omni-dimensional dynamic convolution [J]. arXiv preprint arXiv: 2209.07947, 2022.
[13]牛鑫宇,毛鵬軍,段云濤,等.基于YOLOv5s室內目標檢測輕量化改進算法研究[J].計算機工程與應用,2024,60(3):109-118.
[14]張美玉,劉躍輝,侯向輝,等.基于卷積網絡的灰度圖像自動上色方法[J].計算機工程與應用,2022,58(7):229-236.
[15]苗永春,何建安,李迎松.基于YOLOv5的病媒圖像檢測實驗教學設計[J].實驗技術與管理,2023,40(10):199-205.
[16]王鑫鵬,王曉強,林浩,等.深度學習典型目標檢測算法的改進綜述[J].計算機工程與應用,2022,58(6):42-57.
[17]郭曉新,李佳慧,張寶亮. 基于高分辨率網絡的視杯和視盤的聯合分割[J]. 吉林大學學報(工學版),2023,53(8):2350-2357.
[18]劉勁,羅曉曙,徐照興.權重推斷與標簽平滑的輕量級人臉表情識別[J].計算機工程與應用,2024,60(2):254-263.
[19]高澤鋆,曹菲,何川,等.基于半監督學習網絡的雷達有源干擾識別[J].探測與控制學報,2022,44(6):93-101.
猜你喜歡
艦船科學技術(2022年15期)2022-09-14 09:21:50
電子制作(2019年15期)2019-08-27 01:12:00
電子制作(2018年19期)2018-11-14 02:37:08
自動化學報(2017年11期)2017-04-04 02:52:58
江蘇教育·中學教學版(2016年11期)2016-12-21 11:36:29
現代情報(2016年10期)2016-12-15 11:50:53
新教育時代·教師版(2016年23期)2016-12-06 06:02:38
法制與社會(2016年32期)2016-12-01 15:25:53
軟件導刊(2016年9期)2016-11-07 22:20:49
軟件工程(2016年8期)2016-10-25 15:47:34
