一種基于模擬域特征提取的語音活動檢測電路
2025-03-04 00:00:00何建平楊兵張靜喬飛賈凱歌
物聯網技術 2025年5期
關鍵詞:人工智能


摘 要:隨著人工智能的發展,智能終端設備中集成的常開型傳感器的數量逐漸增加。然而,這些傳感器無法對無用信息進行有效的處理,浪費了大量資源且會嚴重影響后續數據處理的精度。為了應對邊緣終端聲學傳感設備在追求高精度和低功耗方面所面臨的挑戰,提出了一種基于語音時域特征的混合信號域語音活動檢測架構。該架構能夠集成于高精度聲學處理系統,如關鍵詞識別系統等,并與其組成逐級喚醒的邊緣聲學傳感系統,從而降低邊緣設備的部署成本。在具體實現上,該架構采用了基于短時能量和短時過零率的雙門限語音活動檢測算法,并通過將模擬域的特征提取與數字域的特征分類相結合,巧妙地規避了在邊緣設備中使用功耗占比較高的ADC模塊,顯著降低了系統功耗。該設計采用TSMC 180 nm CMOS工藝實現,芯片面積僅為0.029 mm2。仿真結果表明,該電路的功耗低至14.4 μW,語音檢測準確率高達97%,實現了低功耗與高性能的完美平衡,為邊緣終端聲學傳感設備提供了高效、可靠的語音活動檢測方案。
關鍵詞:人工智能;邊緣終端聲學傳感設備;語音活動檢測;短時能量;短時過零率;混合信號域
中圖分類號:TP39;TN453 文獻標識碼:A 文章編號:2095-1302(2025)05-00-05
0 引 言
隨著AI技術的蓬勃發展,人機交互的方式正在發生顛覆性的變革,從早期效率低下的CLI(命令行界面)、GUI(圖形用戶界面),逐漸向NUI(自然用戶界面)轉變。NUI是指一類無形的用戶界面,例如語音、腦機接口等。而語音交互作為最自然、直觀的NUI交互方式,是人機交互領域的首選方案。
為了實現高效的人機交互,智能終端感知設備中需要集成大量常開型(always on)傳感器,如麥克風、攝像頭等。這些傳感器需要采集并處理海量的信息,其中也包括了無用信息,如噪聲。這些無用信息不僅增加了設備的功耗,還會影響后續數據處理的精度。因此,如何降低邊緣終端聲學設備的功耗,逐漸成為當前研究的熱點。
針對常開型傳感器的功耗問題,學術界提出了兩種解決方案:一種是采用周期供電的方式;另一種是采用分層傳感的方式。周期供電方案僅具備開啟和關閉兩種狀態,無法滿足常開型傳感器的需求。而分層傳感技術則通過逐級喚醒模式,使傳感器僅在探測到有效信息時才進行處理,從而顯著降低了能耗并提高了處理精度。例如在KWS關鍵詞識別系統中,所需處理的有用信息為人聲,而不是所有的聲音信號。通過采用分層傳感的方式,能夠極大地降低系統功耗,實現近乎無限的待機時長。
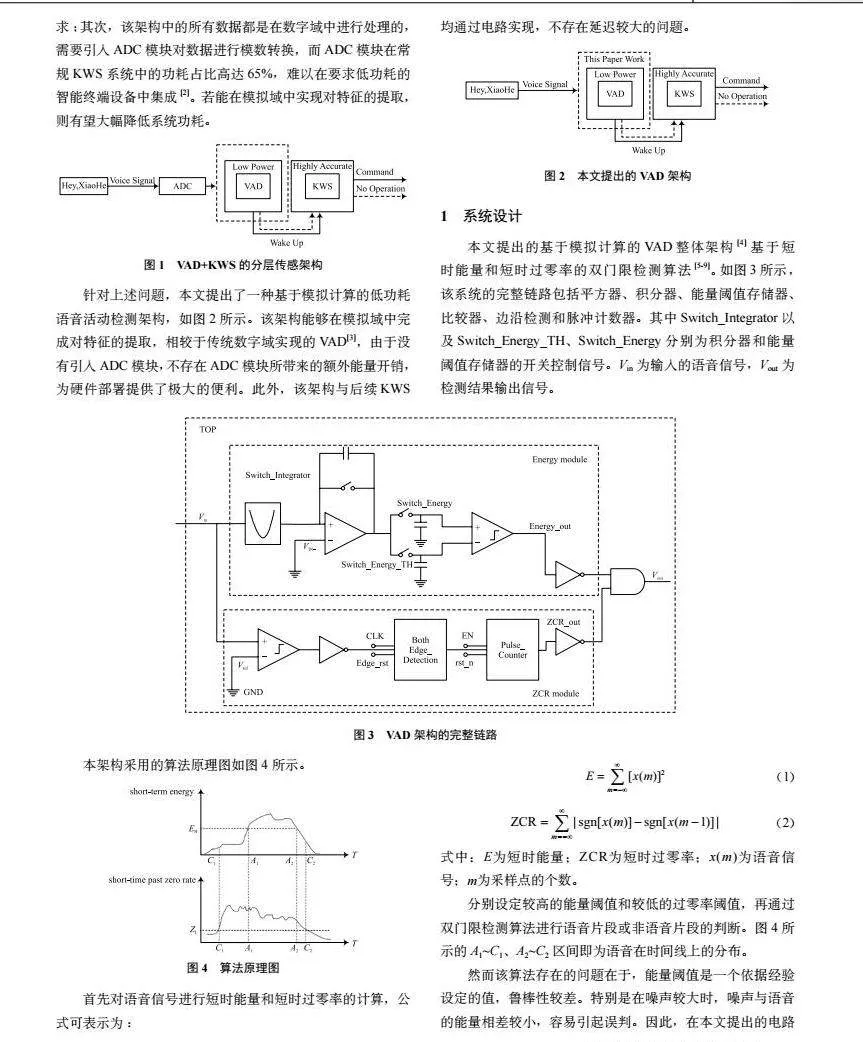
谷歌在2016年I/O開發者大會[1]中提出了一種VAD+ KWS的聲學系統架構,如圖1所示,該架構是一種云端和邊緣端協同的語音處理方案。在該架構中,VAD(Voice Activity Detection)和KWS(Keyword Spotting)被分為兩個不同的層次進行處理。首先,VAD層在邊緣終端設備上執行,用于檢測輸入音頻流中的語音活動,只有在檢測到語音時才會將數據發送到云端進行進一步處理。隨后,KWS層在云端對接收到的語音數據進行處理,并進行語音識別和關鍵詞檢測,以確定用戶是否說出了預定義的關鍵詞或短語。在識別到關鍵詞或短語后,云端將指令發送回邊緣終端設備,并執行相應的操作。這種分層傳感架構結合了邊緣計算和云計算的優勢,既可以實現高性能的語音處理,又可以減少網絡帶寬的占用和云端計算的負擔。谷歌在其智能音箱Google Home中采用了這種架構,取得了良好的效果,同時也在邊緣計算和語音處理領域推動了該技術的應用。
然而,該架構也存在一些缺點:首先,由于需要將數據發送到云端,導致延遲較大,難以滿足語音交互的實時性需求;其次,該架構中的所有數據都是在數字域中進行處理的,需要引入ADC模塊對數據進行模數轉換,而ADC模塊在常規KWS系統中的功耗占比高達65%,難以在要求低功耗的智能終端設備中集成[2]。若能在模擬域中實現對特征的提取,則有望大幅降低系統功耗。
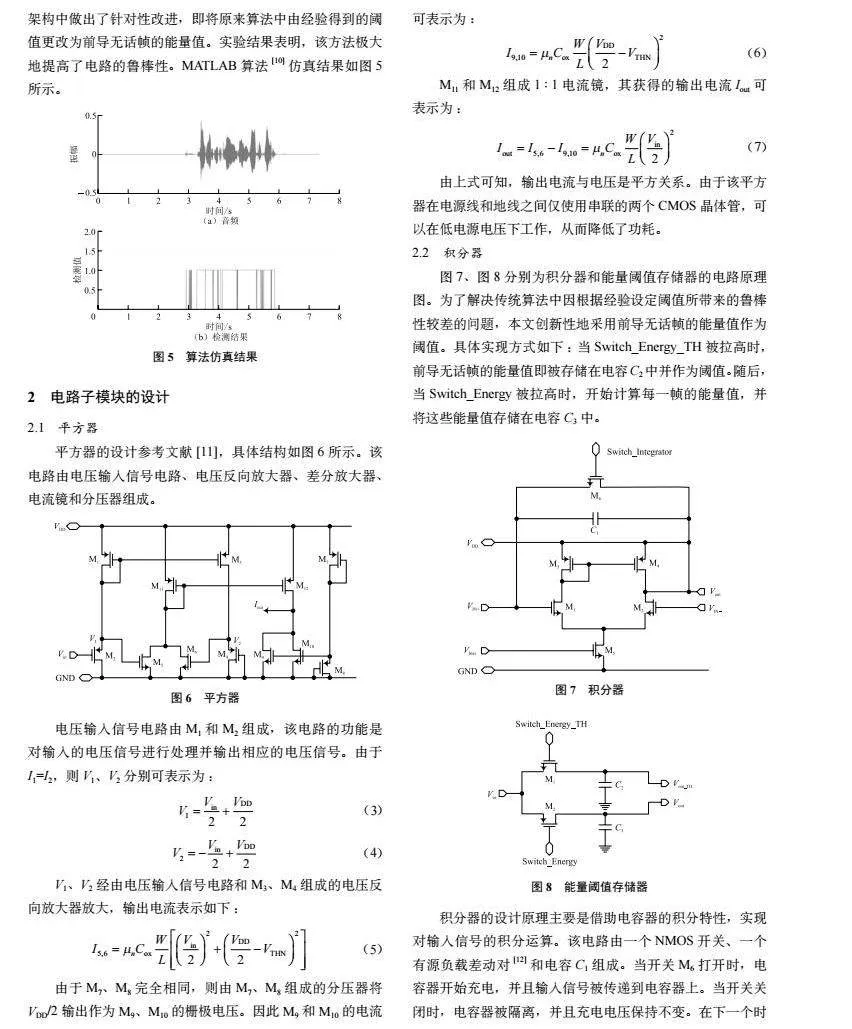
針對上述問題,本文提出了一種基于模擬計算的低功耗語音活動檢測架構,如圖2所示。該架構能夠在模擬域中完成對特征的提取,相較于傳統數字域實現的VAD[3],由于沒有引入ADC模塊,不存在ADC模塊所帶來的額外能量開銷,為硬件部署提供了極大的便利。此外,該架構與后續KWS均通過電路實現,不存在延遲較大的問題。
1 系統設計
本文提出的基于模擬計算的VAD整體架構[4]基于短時能量和短時過零率的雙門限檢測算法[5-9]。如圖3所示,該系統的完整鏈路包括平方器、積分器、能量閾值存儲器、比較器、邊沿檢測和脈沖計數器。其中Switch_Integrator以及Switch_Energy_TH、Switch_Energy分別為積分器和能量閾值存儲器的開關控制信號。Vin為輸入的語音信號,Vout為檢測結果輸出信號。
分別設定較高的能量閾值和較低的過零率閾值,再通過雙門限檢測算法進行語音片段或非語音片段的判斷。圖4所示的A1~C1、A2~C2區間即為語音在時間線上的分布。
然而該算法存在的問題在于,能量閾值是一個依據經驗設定的值,魯棒性較差。特別是在噪聲較大時,噪聲與語音的能量相差較小,容易引起誤判。因此,在本文提出的電路架構中做出了針對性改進,即將原來算法中由經驗得到的閾值更改為前導無話幀的能量值。實驗結果表明,該方法極大地提高了電路的魯棒性。MATLAB算法[10]仿真結果如圖5所示。
2 電路子模塊的設計
2.1 平方器
平方器的設計參考文獻[11],具體結構如圖6所示。該電路由電壓輸入信號電路、電壓反向放大器、差分放大器、電流鏡和分壓器組成。
2.2 積分器
圖7、圖8分別為積分器和能量閾值存儲器的電路原理圖。為了解決傳統算法中因根據經驗設定閾值所帶來的魯棒性較差的問題,本文創新性地采用前導無話幀的能量值作為閾值。具體實現方式如下:當Switch_Energy_TH被拉高時,前導無話幀的能量值即被存儲在電容C2中并作為閾值。隨后,當Switch_Energy被拉高時,開始計算每一幀的能量值,并將這些能量值存儲在電容C3中。
積分器的設計原理主要是借助電容器的積分特性,實現對輸入信號的積分運算。該電路由一個NMOS開關、一個有源負載差動對[12]和電容C1組成。當開關M6打開時,電容器開始充電,并且輸入信號被傳遞到電容器上。當開關關閉時,電容器被隔離,并且充電電壓保持不變。在下一個時鐘周期內,再次打開開關,電容器會繼續接收輸入信號并繼續充電,這樣就可以將多個時鐘周期內的輸入信號進行積分運算。開關電容積分器的積分計算公式如下:
能量閾值存儲器的實現是基于電容能夠存儲電荷并在電路中釋放或吸收電荷的原理。通過控制對應的開關,將閾值和能量分別存儲在電容C2和C3中,并以電容C2存儲的值作為比較器的參考電壓Vref、電容C3的值作為比較器的輸入電壓。
2.3 比較器
比較器的電路原理如圖9所示。待比較的兩個電容C2、C3上的Vout、Vout_TH被分別連接到模擬比較器的M1和M2的柵極。當比較器開始工作時,開關管M3、M4首先被拉低,開關管M7和M10被拉高。此時,電路輸出電壓被拉高至VDD。隨后,開關管M3、M4被拉高,開關管M7、M10被拉低。此時,整個電路導通,由于兩個待比較的輸入電壓是不同的,因此M1和M2兩條支路中的電流I1、I2不同,而電流的不同則會導致上半部分首尾相接的兩個反相器M5-M8、M6-M10結構失衡。最終在正反饋的作用下,電流較大支路中的反相器的輸出端電壓會被拉低,電流較小支路中的反相器的輸出端的電壓則會被抬高到VDD。由于在整個比較器工作的過程中,兩條比較支路只在SWcom信號跳變的一瞬間產生電流I1和I2,比較完成后這兩條支路將不再導通,因此整個比較器結構可以實現很低的功耗。
2.4 數字邏輯及開關時序
2.4.1 數字邏輯
短時過零率模塊中的數字邏輯如圖10所示。該電路由雙邊沿檢測和計數器[13-14]組成。雙邊沿檢測主要是為了檢測前級比較器輸出的高低電平穿越時間軸的情況,并以此來計算短時過零率的值。為了解決亞穩態的潛在風險,本文采用了異步信號同步化的設計方法來降低亞穩態出現的概率,避免了電路出現崩潰的局面。雙邊沿檢測的時序圖如圖11所示。
計數器通過對時間T內異或門輸出為“1”的次數進行計數,來判斷短時過零率的值是否超過了語音的閾值。若在T內,異或門輸出為“1”的次數超過設定的計數閾值,則識別該語音信號為“清音段”;否則,識別為“濁音段”。語音是由清音和濁音組成,而短時能量可以實現對濁音的檢測,因此,結合短時能量模塊和短時過零率模塊,便可對一段語音信號中的語音片段和非語音片段進行辨別。
2.4.2 開關時序
積分器和能量閾值存儲器的開關時序如圖12所示。其中Switch_Integrator是積分器模塊中的必要組成部分,通過該開關不斷地對電容C1進行充放電來實現對輸入信號的積分運算。Switch_Energy_TH控制著閾值電容C2的充放電,負責存儲前導無話幀的能量值并以此作為閾值。Switch_Energy控制著能量電容C3的充放電,將閾值確定后的每一幀的能量值存儲在電容C3上。
3 仿真結果
本文設計了一種低功耗VAD電路,可以將輸入的一段語音信號輸出為語音片段或非語音片段的高或低電平。將本文方法與其他方法進行對比,具體性能指標見表1。本文方法采用了模擬域特征提取的方法,有效降低了VAD電路的功耗。仿真結果表明,該電路功耗為14.4 μW,準確率為97%,延時為20 ms,可滿足KWS應用的需求。仿真結果如圖13所示,其中Vin為輸入的語音信號,為了便于分析計算結果的準確性,仿真時設置的語音信號為方波信號,Energy_out為短時能量模塊的仿真結果,ZCR_out為短時過零率的仿真結果,VADout為VAD電路模塊的檢測結果。
4 結 語
相較于其他傳統方法,本文所設計的基于語音時域特征的混合信號域語音活動檢測架構在功耗方面還有進一步降低的空間。同時,為了初步驗證本文架構的可行性,當前工作階段采用了外部提供的開關時序,暫未設計相應的時鐘生成器。待后續的回片測試驗證成功后,將在下一個版本中開展時鐘生成器和VAD功能模塊的集成工作。
參考文獻
[1]佚名. 黑科技滿滿的盛會 Google I/O 2016開發者大會[J].電腦愛好者,2016(12):74-76.
[2] LI Q, LIU C L, DONG P Y, et al. NS-FDN: near-sensor processing architecture of feature-configurable distributed network for beyond-real-time always-on keyword spotting [J]. IEEE transactions on circuits and systems I: regular papers, 2021, 68(5): 1892-1905.
[3] RAYCHOWDHURY A, TOKUNAGA C, BELTMAN W, et al. A 2.3 nJ/ frame voice activity detector-based audio front-end for context-aware system-on-chip applications in 32 nm CMOS [J]. IEEE journal of solid-state circuits, 2013, 48(8): 1963-1969.
[4] CROCE M, FRIEND B, NESTA F, et al. A 760 nW, 180 nm CMOS analog voice activity detection system for domestic environment [J]. IEEE journal of solid-state circuits, 2021, 56(3): 778-787.
[5]趙力. 語音信號處理[M]. 北京:機械工業出版社,2003.
[6]劉華平,李昕,徐柏齡,等. 語音信號端點檢測方法綜述及展望[J]. 計算機應用研究,2008,25(8):2278-2283.
[7]李樂.語音端點檢測算法的研究及應用[D]. 西安:西安建筑科技大學,2016.
[8]呂海玉,嚴路昊,張郡夫,等.基于單片機的老年健康管家[J].物聯網技術,2021,11(5):104-105.
[9]張超.語音端點檢測方法研究[D]. 大連:大連理工大學,2016.
[10]宋知用. MATLAB在語音信號分析與合成中的應用[M]. 北京:北京航空航天大學出版社,2013.
[11] CHAISAYUN I, PIANGPRANTONG S, DEJHAN K. Versatile analog squarer and multiplier free from body effect [J]. Analog integrated circuits and signal processing, 2012, 71(3): 539-547.
[12]畢查德·拉扎維. 模擬CMOS集成電路設計[M]. 西安:西安交通大學出版社,2002.
[13]簡· M.拉貝艾,周潤德. 數字集成電路—電路、系統與設計[M].北京:電子工業出版社,2004.
[14]夏宇聞. Verilog數字系統設計教程[M]. 北京:北京航空航天大學出版社,2008.
猜你喜歡
西安航空學院學報(2022年2期)2022-07-04 07:45:42
汽車零部件(2020年3期)2020-03-27 05:30:20
表面工程與再制造(2019年1期)2019-05-11 08:52:04
商界(2019年12期)2019-01-03 06:59:05
家庭影院技術(2018年9期)2018-11-02 05:31:34
IT經理世界(2018年20期)2018-10-24 02:38:24
通信電源技術(2018年3期)2018-06-26 06:33:30
軍營文化天地(2018年1期)2018-02-10 05:19:25
小康(2017年16期)2017-06-07 09:00:59
學與玩(2017年12期)2017-02-16 06:51:12
