基于數據挖掘算法的圖書館讀者行為分析與應用研究
2025-03-05 00:00:00劉潤嘉陳浩宇
電腦知識與技術 2025年2期

摘要:隨著信息技術的發展,圖書館積累了大量用戶數據,傳統管理方法難以應對其復雜性與多樣性。為此,文章采用K-means聚類算法和Apriori關聯規則算法對圖書館讀者行為進行深入分析。研究結果表明,通過聚類分析,讀者群體被劃分為五類,不同群體在借閱頻率和書籍偏好上表現出顯著差異。關聯規則分析揭示了不同書籍之間的潛在關聯,尤其是在同一學科或興趣領域內。通過數據挖掘技術,圖書館能夠預測讀者的潛在需求,優化館藏布局,提升資源利用效率,并為個性化服務提供決策支持。結論表明,數據挖掘算法對圖書館管理具有重要的應用價值,能夠幫助優化資源配置,提升讀者滿意度。
關鍵詞:數據挖掘;圖書館;行為分析;應用
中圖分類號:TP311 文獻標識碼:A
文章編號:1009-3044(2025)02-0064-03 開放科學(資源服務) 標識碼(OSID) :
0 引言
隨著信息技術的飛速發展,圖書館積累了大量的用戶數據,包括借閱記錄和個人資料。這些數據的體量和復雜性促使圖書館管理者尋找更為有效的方法來分析和利用這些信息。傳統的圖書館數據管理往往局限于基本的統計和檢索功能,無法深層次揭示用戶行為背后的規律和潛在需求。數據挖掘技術作為一種強大的信息處理工具應運而生,特別是在高校圖書館中,通過對用戶行為數據的深度挖掘,可以發現借閱模式和用戶偏好,為個性化服務提供有力支持。這不僅有助于優化館藏資源的配置,還能提高圖書館的服務質量和資源利用效率。
關于數據挖掘在圖書館讀者行為分析中的應用,學者們展開了相關研究。蔣一鋤[1]通過采集讀者的歷史行為數據,利用數據庫、網絡數據、讀者流、讀者行為感知四個維度,深入挖掘讀者的真實需求。賈彥玲[2]通過對圖書館借閱記錄的深度挖掘,發現讀者的借閱行為、圖書分類、學科特點以及讀者類型之間存在一定的關聯性。但是,現有研究缺乏不同方法的整合與學科交叉規律的分析。
為此,在前人工作的基礎上,本研究采用Kmeans聚類算法和Apriori關聯規則算法,對圖書館讀者行為進行更加細致的分析和應用探索。與以往研究相比,本研究的創新點在于:通過聚類分析,不僅細分了讀者群體,揭示了各類群體在借閱頻率和書籍偏好上的差異;還通過關聯規則挖掘,發現了不同書籍之間的潛在關聯,尤其是在學科交叉和特定領域內的借閱規律。這不僅能夠提升圖書館資源利用效率,還為未來智能化推薦系統的設計提供了理論支持,具有重要的實踐意義。
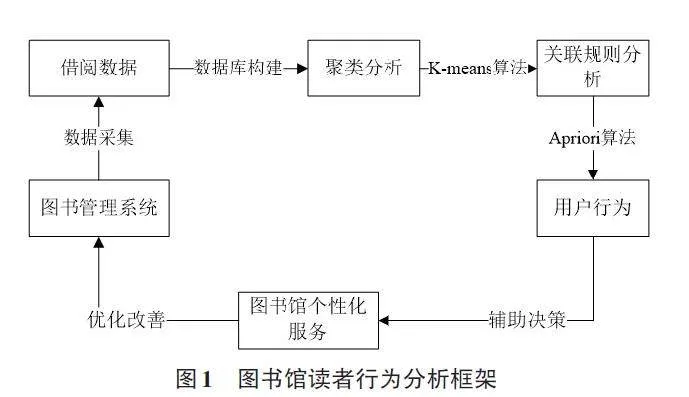
1 圖書館讀者行為分析框架
圖書館讀者行為分析的數據收集過程包括多個步驟。首先,通過圖書館信息管理系統,收集讀者的個人資料、借閱記錄、查詢關鍵詞等數據。個人資料包括姓名、學號、年級和專業等基本信息;借閱記錄涵蓋書籍的借閱時間、歸還時間、圖書類別和編號等信息;查詢關鍵詞記錄用戶在系統中的檢索行為。接著,對采集到的原始數據進行清洗,刪除重復和無效數據,并處理缺失值。隨后,通過唯一標識符(如讀者條碼) ,將個人信息、借閱記錄和查詢行為進行整合,構建一個標準化的用戶行為數據庫,確保數據結構的完整性和規范性。
在讀者行為分析中,聚類分析是核心步驟之一。K-means算法以其高效性和適應性廣泛應用于大數據環境,特別適合處理圖書館讀者行為的多維數據。因此,通過K-means算法,根據用戶的借閱書籍類型、數量和頻率等信息,將用戶劃分為不同的群體,不同群體的用戶表現出不同的借閱偏好[3]。在此基礎上,Apriori算法專門用于挖掘大數據中的頻繁項集和關聯規則,非常適合分析圖書借閱記錄中的書籍關聯關系。通過應用Apriori算法進行關聯規則分析,挖掘用戶借閱記錄中的關聯關系,揭示不同書籍之間的聯系[4]。圖書館讀者行為分析框架如圖1所示。
通過數據挖掘,圖書館能夠預測讀者的潛在需求,既可以描述用戶當前行為,也預測未來借閱趨勢,從而實現個性化圖書推薦。
2 圖書館讀者行為分析實踐應用
2.1 數據采集
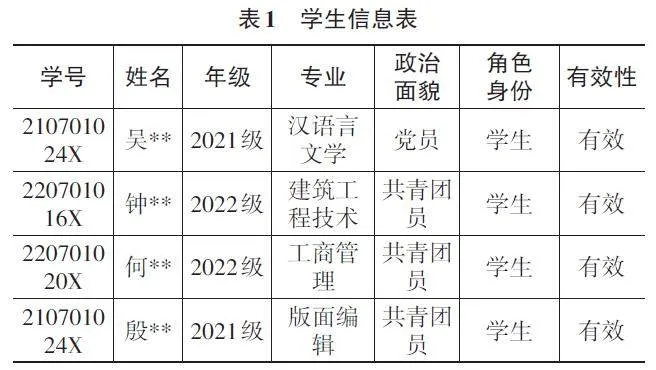
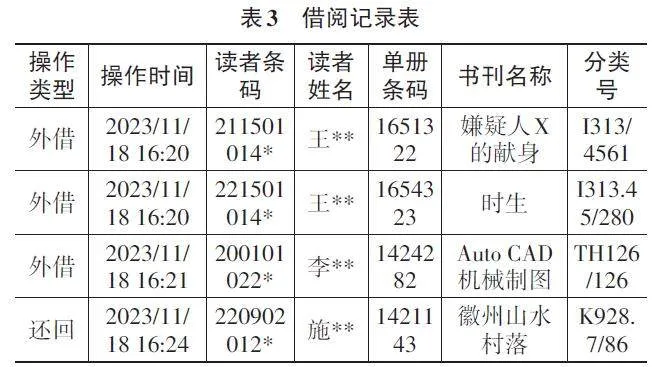
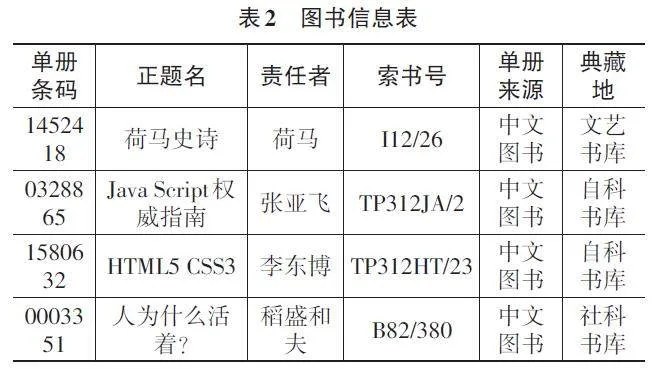
通過XX學院圖書館信息管理系統數據庫抽取2023年10—12月的數據,主要包括學生信息、圖書信息和借閱記錄。最終獲得原始學生信息4 897條,圖書信息9 464條,借閱記錄10 144條,部分信息如下。
2.2 數據預處理
數據清洗是數據挖掘前的關鍵步驟,旨在確保數據的完整性、準確性和一致性。首先,對缺失值進行處理,使用空值校驗刪除關鍵字段(如條碼等) 為空的記錄。對于部分字段缺失但能夠推斷出的數據,如根據讀者條碼補全分類號信息,則進行相應的填充。其次,剔除無用或失效的數據,如不相關的教職工、臨時人員等信息。最后,進行異常值校驗,篩選并刪除明顯不合理的記錄。通過這些步驟,確保數據的準確性,以便后續的分析和挖掘工作順利進行。
在學生信息表的處理過程中,原本包含的7個屬性經過篩選后,保留了對數據挖掘有用的“讀者條形碼”和“專業”字段,刪除了姓名、年級、政治面貌等與數據挖掘無關的屬性,以簡化數據結構并提升后續處理的效率。同時,在借閱記錄表中,刪除姓名字段,并通過篩選“外借”和“還回”記錄,分別生成兩張表。利用讀者條形碼和單冊條形碼,對借還周期在一個月以內的記錄進行內連接,合并成同一條記錄,確保每本書的完整借還行為都體現在同一條數據中。
在數據集成過程中,將讀者借閱記錄表與學生信息表通過學生條碼字段進行內連接,確保集成后的表中包含學生條碼、學生專業等關鍵信息。此時,表格中已經包含讀者所借圖書的單冊條碼,但缺少索書號信息。因此,將生成的表格與圖書信息表通過單冊條碼進行內連接,以此獲取圖書的索書號和分類號等信息。通過兩次內連接操作,最終集成的表格將包含學生條碼、學生專業、書籍條碼以及書籍分類號等關鍵字段,為后續的數據挖掘操作提供便利。
2.3 讀者群體聚類分析
采用K-means算法進行讀者群體聚類分析,主要步驟如下所示。
1) 初始中心選擇。從用戶數據中隨機選取5個用戶作為初始聚類中心。
2) 距離計算與群體分配。對于每個用戶,計算其到所有5個聚類中心的歐幾里得距離,并根據距離將其分配到最近的聚類中心。
3) 更新聚類中心。計算每個群體內用戶的均值,即通過所有分配到該群體的用戶的借閱數據計算出新的聚類中心。
4) 重復迭代。重新計算各用戶與各中心的距離,再次進行群體分配。直到所有聚類中心穩定不再發生明顯變化,或達到預設的最大迭代次數[5]。
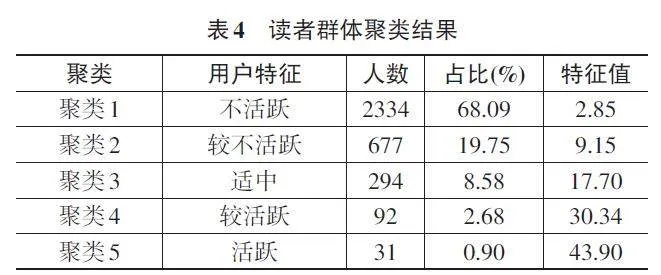
讀者群體聚類分析結果如表4所示。
根據讀者群體聚類結果,用戶可以被分為以下五類群體:
第一類是不活躍用戶群體,其借閱次數最少。這類用戶人數最多,占總人數的68.09%,顯示出他們的借書行為極為不活躍。這部分用戶對閱讀的興趣不大,或者受到課業等其他因素的限制。
第二類是較不活躍用戶群體,占比19.75%。雖然他們的借閱行為比第一類用戶稍微頻繁一些,但整體上仍然不算活躍。
第三類是適中用戶群體,其借閱次數居中,占比8.58%。這類用戶有一定的閱讀需求和興趣,但借閱量仍有較大的提升空間。
第四類是較活躍用戶群體,其借閱次數較多,占比2.68%。這類用戶表現出較高的閱讀欲望,頻繁地使用圖書館的館藏資源。
第五類是活躍用戶群體,其借閱次數最多,占比0.90%。這類用戶的借閱行為最為頻繁,是圖書館的核心讀者群體。
2.4 讀者行為關聯分析
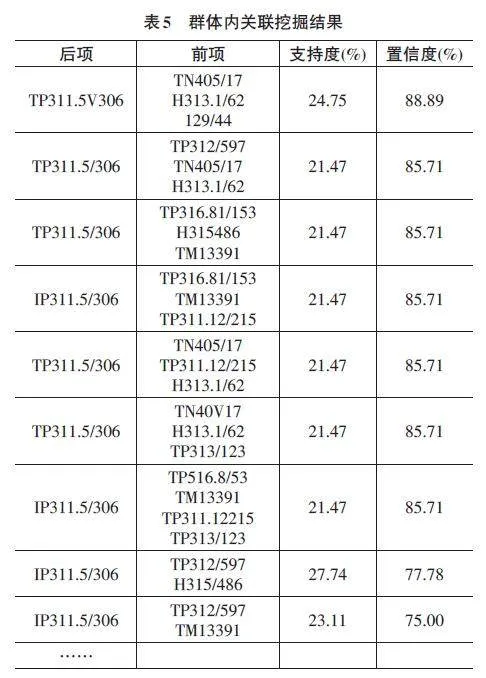
Apriori算法是一種經典的關聯規則挖掘算法,常用于發現數據庫中的頻繁項集以及由此產生的關聯規則。其基本原理是通過逐步擴展項集,篩選出滿足支持度和置信度要求的頻繁項集,再通過這些頻繁項集生成關聯規則。借鑒前人研究成果,我們設定支持度閾值為0.2,置信度閾值為0.15[6],利用Apriori算法對圖書借閱記錄進行關聯規則挖掘。這樣能夠有效篩選出在圖書借閱數據中具有較高頻率和可靠性的重要關聯規則,具體結果見表5。
可以看出,在具有相似閱讀興趣的讀者群體中,關聯規則的挖掘效果相當理想。在所有讀者的借閱記錄中,不同書籍之間展現出較強的關聯性,尤其是在同一專業或興趣領域內。當讀者借閱某類圖書時,系統可以依據挖掘出的規則集,推薦與其相關聯的其他圖書。關聯規則的分析結果為圖書館工作人員采購書籍提供了重要的參考依據,有助于優化館藏結構,確保館藏資源的合理配置,以更好地滿足讀者的需求。
3 結束語
基于數據挖掘算法,本文對圖書館讀者的行為特征進行了深入分析。通過聚類分析,讀者被劃分為不同的群體,這有助于揭示各群體的借閱偏好,特別是在書籍類型、借閱頻率等方面。Apriori算法則進一步挖掘了不同書籍之間的關聯關系,揭示了讀者在借閱某類書籍時傾向于借閱相關書籍的規律。借助數據挖掘的結果,圖書館能夠更準確地預測用戶需求,優化書籍的布局和推薦系統,從而提升資源的利用效率和用戶體驗。數據挖掘算法的應用具有重要的實踐價值,它不僅幫助圖書館管理者更好地理解讀者需求,還為個性化服務和資源配置提供了有力依據。
參考文獻:
[1] 蔣一鋤,曾德良.大數據挖掘背景下智慧圖書館讀者行為數據分析模式研究[J].衡陽師范學院學報,2020,41(3):49-53.
[2] 賈彥玲,楊柳,宋志陽.數據挖掘在圖書館大數據利用中的應用[J].科技資訊,2024,22(6):224-226.
[3] 金國峰,潘英杰.基于K-Means與Apriori算法的資源利用率研究:以高校圖書館為例[J].圖書館學刊,2024,46(4):62-68.
[4] 陳添源.高校讀者借閱行為的關聯分析及應用實踐[J].情報探索,2018(12):97-102.
[5] 劉璐璐,陳志飚,黃勇,等.基于Apriori算法的圖書館用戶行為模式分析研究[J].現代信息科技,2022,6(2):9-11,16.
[6] 李華群.基于改進Apriori算法在圖書館數據挖掘中應用分析[J].內蒙古科技與經濟,2021(24):66-68,73.
【通聯編輯:代影】
猜你喜歡
大眾投資指南(2021年35期)2021-02-16 01:06:26
小太陽畫報(2018年1期)2018-05-14 17:19:25
電力與能源(2017年6期)2017-05-14 06:19:37
少年博覽·小學低年級(2016年10期)2016-11-24 06:48:23
科技視界(2016年20期)2016-09-29 12:03:12
科技視界(2016年20期)2016-09-29 11:47:01
科技視界(2016年20期)2016-09-29 11:02:20
大眾理財顧問(2016年8期)2016-09-28 13:45:18
信息通信技術(2015年6期)2015-12-26 01:16:46
小天使·一年級語數英綜合(2014年8期)2014-06-26 14:42:04
