基于高校圖書館Web日志挖掘的分析與研究*
2010-05-03 07:40:56程思祥雷
圖書館學(xué)刊 2010年5期
程思祥雷 鳴
(1.長江大學(xué)圖書館;2.長江大學(xué)計(jì)算機(jī)科學(xué)學(xué)院,湖北 荊州 434023)
1 引言
隨著Internet技術(shù)的發(fā)展,網(wǎng)絡(luò)資源飛速增長,如何有效利用這些豐富的資源成為人們普遍關(guān)注的問題。數(shù)據(jù)挖掘技術(shù)和Internet應(yīng)用研究的結(jié)合構(gòu)成了當(dāng)今比較活躍的一個(gè)研究領(lǐng)域——Web數(shù)據(jù)挖掘。要從海量的Web數(shù)據(jù)中獲取有價(jià)值的潛在模式和隱含信息必須依靠Web數(shù)據(jù)挖掘技術(shù)。
與Web數(shù)據(jù)異質(zhì)、分布、動(dòng)態(tài)、無統(tǒng)一結(jié)構(gòu)的特點(diǎn)不同,Web服務(wù)器日志結(jié)構(gòu)比較完善,用戶訪問Web站點(diǎn)后會(huì)留下完整的記錄。Web日志挖掘通過挖掘Web日志記錄來發(fā)現(xiàn)用戶訪問Web頁面的模式、挖掘有用模式和預(yù)測(cè)用戶瀏覽行為[1]。
目前Web日志挖掘可分為兩種方法[2]:①將Web服務(wù)器上的數(shù)據(jù)映射到關(guān)系數(shù)據(jù)庫,選擇合適的數(shù)據(jù)挖掘技術(shù)處理;②利用特殊的預(yù)處理技術(shù)直接處理日志數(shù)據(jù),采用標(biāo)準(zhǔn)的數(shù)據(jù)挖掘技術(shù)來進(jìn)行訪問數(shù)據(jù)的挖掘。
2 W eb日志分析流程
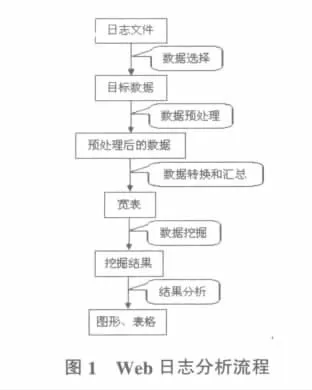
2.1 數(shù)據(jù)選擇
分析對(duì)象是長江大學(xué)圖書館的主頁服務(wù)器日志數(shù)據(jù),自2009年10月26日到2009年11月19日,日志文件共25個(gè),大小為262M,共有1619085條記錄。
Web服務(wù)器日志文件(Web Server Log File)記錄了用戶訪問該站點(diǎn)時(shí)每個(gè)頁面的請(qǐng)求信息。日志記錄的格式主要分為兩種[3]:通用型日志格式(Common Log Format,CLF)和擴(kuò)展型日志格式(Extended Log Format,ELF)。筆者使用的數(shù)據(jù)屬于W3C擴(kuò)展日志格式,ELF日志文件包括兩種記錄類型:指令型記錄(以“#”開頭)和數(shù)據(jù)記錄。
ELF確定的日志格式被定義為一個(gè)域的集合,而不是定義一種固定的格式。很多域前面需要加上前綴。下面列出W3C擴(kuò)展日志格式的可用域前綴[4]:
c-:客戶端;s-:服務(wù)器端;r-:遠(yuǎn)程服務(wù)器端;cs-:客戶端到服務(wù)器端;sc-:服務(wù)器端到客戶端;sr-:服務(wù)器端到遠(yuǎn)程服務(wù)器端;rs-:遠(yuǎn)程服務(wù)器端到服務(wù)器端;x-:應(yīng)用。這些前綴與域指令行中的域標(biāo)識(shí)符相結(jié)合,用于說明何種數(shù)據(jù)將寫入日志。
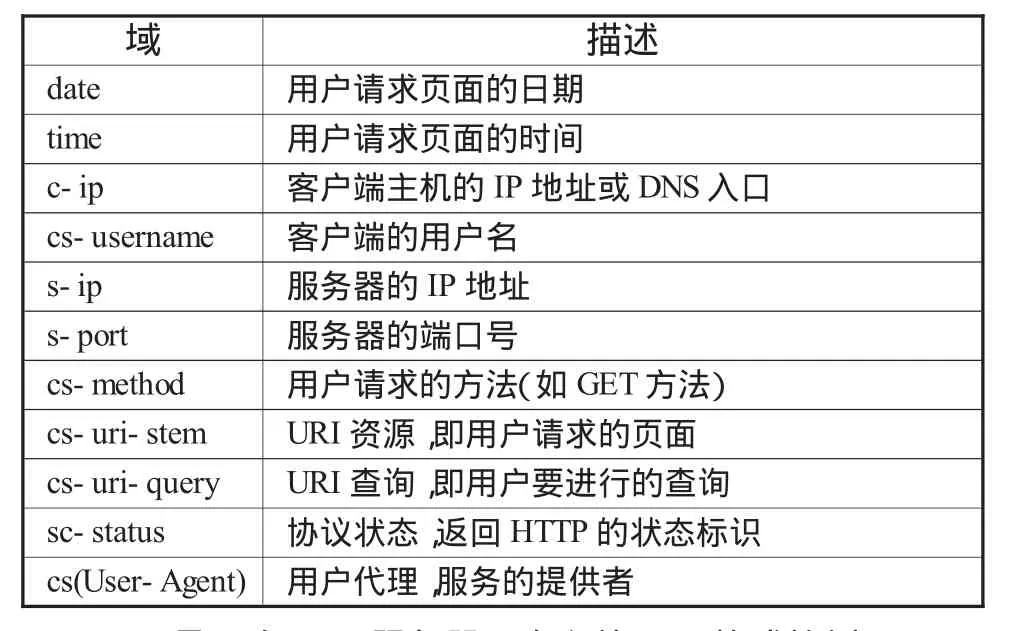
表1 W eb日志記錄的部分主要信息
下面是一個(gè)Web服務(wù)器日志文件ELF格式的例子:
#Software:Microsoft Internet Information Services 5.0
#Version:1.0
#Date:2009-10-26 00:00:49
#Fields:date time c-ip cs-username s-ip s-port cs-method cs-uri-stem cs-uri-query sc-status cs(User-Agent)2009-10-26 00:00:49 10.10.90.29-10.203.1.13 80 GET/index.asp-200 Mozilla/4.0+(compatible;+MSIE+6.0;+Windows+NT+5.1;+SV1)
2.2 數(shù)據(jù)預(yù)處理
數(shù)據(jù)預(yù)處理是數(shù)據(jù)挖掘前期很重要的工作,其結(jié)果的好壞直接影響了挖掘結(jié)果。數(shù)據(jù)預(yù)處理的工作量占整個(gè)數(shù)據(jù)挖掘過程的50%左右[5]。Web日志預(yù)處理的目的是針對(duì)上一階段產(chǎn)生的數(shù)據(jù)進(jìn)行初步整理,剔除日志中對(duì)挖掘過程無用的屬性和數(shù)據(jù),并將Web日志中的數(shù)據(jù)轉(zhuǎn)換為挖掘算法可識(shí)別的形式。
數(shù)據(jù)清理可采用以下3種方式:①根據(jù)日志文件的時(shí)間,如只需要對(duì)上周日志文件進(jìn)行挖掘;②根據(jù)所訪問的文件類型,如只需要對(duì).asp文件進(jìn)行挖掘;③根據(jù)使用者請(qǐng)求和算法類型選取屬性列,如只需要對(duì)訪問路徑進(jìn)行挖掘。
數(shù)據(jù)縮減可采用以下兩種方式:縱向縮減(行縮減)和橫向縮減(列縮減)。對(duì)于不同的挖掘需求可采用不同的縮減方式,如縱向縮減可通過URI資源的擴(kuò)展名、用戶動(dòng)作、狀態(tài)碼進(jìn)行縮減。進(jìn)行流量分析時(shí),可采用橫向縮減的方式,如保留用戶訪問時(shí)間、用戶請(qǐng)求的URI資源等字段,這里必須保留URL為圖形文件的記錄。進(jìn)行聚類分析時(shí),可保留用戶訪問時(shí)間、用戶IP、用戶請(qǐng)求訪問的URL、用戶所使用的代理等字段。縱向縮減可減少記錄條數(shù),橫向縮減僅減少屬性列,對(duì)記錄條數(shù)無影響,這兩種縮減方式都不會(huì)降低日志清理的精度。進(jìn)行數(shù)據(jù)縮減可減少算法掃描日志的時(shí)間,提高挖掘效率。
目前較為有效的用戶識(shí)別方法有:①基于用戶瀏覽器和操作系統(tǒng)的差異。②基于引用頁進(jìn)行判斷[6]。這里我們認(rèn)為不同IP地址代表不同用戶;若IP地址相同,用戶瀏覽器或操作系統(tǒng)不同,也認(rèn)為是相同的用戶;若用戶請(qǐng)求的某頁面沒有請(qǐng)求過也認(rèn)為這是一個(gè)新的用戶。
進(jìn)行會(huì)話識(shí)別最簡單的方法是使用時(shí)間戳(timeout),常用的是30分鐘,L.Catledge和J.Pitkow由實(shí)驗(yàn)得出timeout值設(shè)為25.5分鐘更好[3]。如果用戶訪問頁面時(shí)間差超過了timeout,則認(rèn)為用戶開始了一個(gè)新的會(huì)話。
2.3 數(shù)據(jù)轉(zhuǎn)換
根據(jù)挖掘目標(biāo)和數(shù)據(jù)特征,選擇合適的挖掘算法模型。Web日志數(shù)據(jù)挖掘中常用的技術(shù)有:統(tǒng)計(jì)分析、路徑分析、關(guān)聯(lián)規(guī)則挖掘、序列模式挖掘、聚類分析、分類學(xué)習(xí)等。
2.4 數(shù)據(jù)挖掘
根據(jù)應(yīng)用的要求,選擇合適的數(shù)據(jù)挖掘算法及模型參數(shù),建立數(shù)據(jù)挖掘模型,從數(shù)據(jù)中提取所需的知識(shí),并以一定的形式展現(xiàn)出來。如決策樹結(jié)構(gòu)、關(guān)聯(lián)規(guī)則集等。
2.5 結(jié)果分析
對(duì)挖掘結(jié)果進(jìn)行解釋與評(píng)估。將挖掘的知識(shí)以用戶可以理解的方式(如圖表)呈現(xiàn)給用戶,并對(duì)所得的結(jié)構(gòu)進(jìn)行解釋,包括對(duì)知識(shí)的一致性檢查,模型的驗(yàn)證,識(shí)別知識(shí)的真正有趣模式。進(jìn)行Web站點(diǎn)流量統(tǒng)計(jì),需要對(duì)源數(shù)據(jù)進(jìn)行分析,統(tǒng)計(jì)網(wǎng)站響應(yīng)狀態(tài)、請(qǐng)求成功的IP地址、具體頁面的訪問流量、訪問成功的頁面、訪問出錯(cuò)的頁面等,可畫出訪問時(shí)間——訪問人數(shù)折線圖,初步了解用戶訪問的時(shí)間分布情況,按照用戶訪問方式統(tǒng)計(jì),了解用戶大多會(huì)進(jìn)行什么操作。
3 結(jié)果分析
根據(jù)原始數(shù)據(jù)可統(tǒng)計(jì)出以下部分結(jié)果:
3.1 根據(jù)網(wǎng)站響應(yīng)狀態(tài)
分布圖如圖2所示。

3.2 根據(jù)用戶訪問方式
分布圖如圖3所示。

3.3 請(qǐng)求成功的IP地址統(tǒng)計(jì)
請(qǐng)求成功的記錄數(shù)為1403516條,請(qǐng)求成功的IP地址數(shù)有10475條。圖4中僅列出訪問量前10位的請(qǐng)求成功的IP地址。

以縱向縮減為例,原始數(shù)據(jù)大小為262M,共有1619085條記錄。
對(duì).gif、.jpg、.jpeg、.ico、.cgi、.css、.js這 7 種擴(kuò)展名篩選后,記錄條數(shù)縮減為211146條。按GET請(qǐng)求記錄縮減后,記錄條數(shù)為210043條。將狀態(tài)碼為4和5開頭的記錄刪除后,記錄條數(shù)為185291條。按下載文件篩選后有1727條記錄。
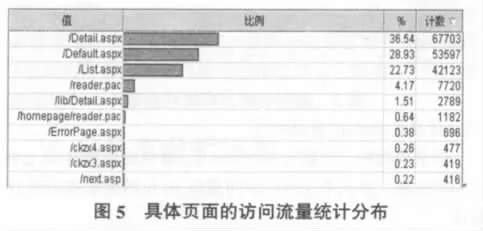
圖5中僅列出訪問量前10位的頁面。
4 結(jié)語
以長江大學(xué)圖書館主頁服務(wù)器Web日志文件為例,分析了Web日志挖掘中的關(guān)鍵步驟——數(shù)據(jù)預(yù)處理技術(shù),并針對(duì)數(shù)據(jù)清理、數(shù)據(jù)縮減、用戶識(shí)別進(jìn)行闡述。Web日志分析可進(jìn)行時(shí)段分析,統(tǒng)計(jì)出一天中哪些時(shí)段、每周哪天、每月哪天甚至每年哪個(gè)時(shí)段的訪問人數(shù)及具體停留時(shí)間,進(jìn)而分析出訪問人群的上網(wǎng)習(xí)慣等相關(guān)信息;可進(jìn)行來源統(tǒng)計(jì),統(tǒng)計(jì)出用戶到達(dá)目標(biāo)網(wǎng)頁所經(jīng)過的路徑,幫助管理者修改、縮短訪問路徑,提高訪問效率;可進(jìn)行客戶端分析,網(wǎng)站設(shè)計(jì)者可根據(jù)統(tǒng)計(jì)出的訪問群瀏覽器和操作系統(tǒng)使用情況,有針對(duì)性地對(duì)某種瀏覽器或操作系統(tǒng)進(jìn)行開發(fā);可進(jìn)行受訪頁分析,統(tǒng)計(jì)第一個(gè)被訪問的網(wǎng)頁和最后離開網(wǎng)站的網(wǎng)頁,分析通常訪問者從哪個(gè)頁面進(jìn)入網(wǎng)站,從哪個(gè)頁面退出網(wǎng)站,設(shè)計(jì)者可通過這些數(shù)據(jù)改善網(wǎng)站結(jié)構(gòu)。
Web日志挖掘是Web挖掘領(lǐng)域一個(gè)重要的研究方向。它對(duì)于發(fā)現(xiàn)用戶瀏覽網(wǎng)站的行為規(guī)律,改善頁面之間的超鏈接結(jié)構(gòu),提高整個(gè)Web系統(tǒng)性能等方面都具有十分重要的意義。
[1] Pitkow J.Insearch of reliable usage data on the WWW[C].In:Proc of 6th Int’T WorldWideWeb Conf.SantaClara.California,1997.
[2] 王麗娜.Web日志挖掘的研究和實(shí)現(xiàn)[C].鄭州大學(xué),2005.
[3] 童恒慶,梅清.Web日志挖掘數(shù)據(jù)預(yù)處理研究.現(xiàn)代計(jì)算機(jī):專業(yè)版,2004(3).
[4] 夏成文,韓堅(jiān)華,梁乘銘.Web日志挖掘數(shù)據(jù)預(yù)處理研究.微型電腦應(yīng)用,2007(10).
[5] Doru Tanasa,Brigitte Trousse.Advanced Data Preprocessing for Intersites Web Usage Mining[J].IEEE Intelligent Systems,March/April 2004:59-65.
[6] 趙紅玲,宋瀚濤.Web日志挖掘中數(shù)據(jù)預(yù)處理的研究[J].計(jì)算機(jī)應(yīng)用研究,2004.
猜你喜歡
大灰狼畫報(bào)·益智版(2024年3期)2024-12-09 00:00:00
保健醫(yī)苑(2022年1期)2022-08-30 08:39:14
大眾投資指南(2021年35期)2021-02-16 01:06:26
電力與能源(2017年6期)2017-05-14 06:19:37
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
信息通信技術(shù)(2015年6期)2015-12-26 01:16:46
創(chuàng)業(yè)家(2015年5期)2015-02-27 07:53:25
電子設(shè)計(jì)工程(2014年18期)2014-02-27 12:00:13
