基于評價指標體系的客運專線客流節點聚類分析
2010-07-13 08:57:52鄧延偉
鐵道運輸與經濟 2010年5期
關鍵詞:評價
鄧延偉
(北京交通大學 經濟管理學院,北京 100044)
我國客鐵流路節客點運間專的線關規聯模關大系,復路雜網。和因客此流,密在度制分定布旅不客均列衡車,開行方案時需要考慮客流節點的重要性,分析節點間的差異性,并對客流節點進行聚類研究。
聚類分析法是對所研究的事物按照一定標準進行分類的數學方法。其根據事物特征,定義能度量樣本間關聯程度的統計量,按照關聯程度對樣本進行分類,將關系密切的聚集到一起,成為一個分類單位。聚類分析對樣品進行分類的效果,關鍵是統計指標的選擇。在對客流節點進行聚類分析之前,首先建立綜合評價指標體系,運用層次分析法進行指標權重計算,將半定性、半定量的問題轉化為定量指標問題,得出樣本的綜合評價結果。在此基礎上,通過K-均值聚類分析得到客流節點分類標準,為制定客運專線的旅客列車開行方案提供科學依據。
1 客流節點聚類原理
節點的形成和功能定位是政治、經濟、市場需求等多種因素綜合作用的結果。因此,客流節點的聚類應保持客運專線網絡的完整性,注重節點間的相關性和聯絡性,遵循與客運專線網絡功能、客流量、客運站技術作業能力、人口數量、經濟發展水平和旅客出行需求等相適應的原則。
1.1 聚類指標體系的建立
綜合考慮與客流節點相關的運輸組織、網絡銜接、地方經濟等因素,將節點的客運需求、路網屬性、客運能力和社會屬性 4 項要素作為聚類研究的依據,并在此基礎上,將節點聚類指標層次化,得到 9 項二級指標,建立客流節點聚類綜合評價指標體系,如圖1 所示。
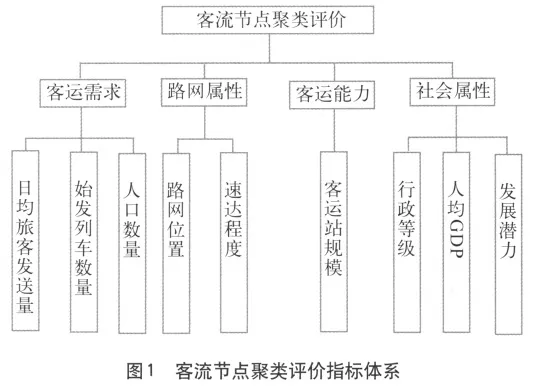
1.2 聚類指標體系的評價
應用層次分析法對客流節點聚類評價指標體系進行綜合評價。
1.2.1 構造判斷矩陣
采用 1~9 比例標度進行同層次兩兩要素之間的比較,構造判斷矩陣。比例標度的含義如下。標度 1 表示兩個元素相比,具有同等重要性。標度 2 表示兩元素重要性介于標度 1 和標度 3之間。
標度 3 表示兩個元素相比,一個元素比另一個元素稍微重要。
標度 4 表示兩元素重要性介于標度 3 和標度 5之間。
標度 5 表示兩個元素相比,一個元素比另一個元素明顯重要。
標度 6 表示兩元素重要性介于標度 5 和標度 7之間。
標度 7 表示兩個元素相比,一個元素比另一個元素強烈重要。
標度 8 表示兩元素重要性介于標度 7 和標度 9之間。
標度 9 表示兩個元素相比,一個元素比另一個元素極端重要。
1.2.2 計算各級指標權重
通過合積法求解判斷矩陣的特征根,其解即為同一層次各指標的權重系數,并對其進行一致性檢驗,其檢驗步驟如下。
(1)計算一致性指標:CI=(λmax-n)/(n-1)。式中:n 為判斷矩陣 A 的階數;λmax為判斷矩陣 A 的最大特征根。
(2)計算一致性比例:CR =CI/RI。式中:RI 為平均隨機一致性指標,是CI 的修正系數。當 CR<0.1時,一般認為判斷矩陣的一致性是可以接受的。
1.2.3 二級指標的量綱處理
在進行指標比較之前,需要定性描述指標轉化為定量指標問題,并統一數據量綱,以使評價結果更加科學、準確。建立定性指標評語集合{好:0.90~1.00;較好:0.75~0.90;一般:0.55~0.75;差:0.55 以下},根據指標特點采用相應的評價標準,如表1 所示。定量指標將指標項數據劃分為 4 個評價區段,分別為好、較好、一般、差,再對各區段內的節點進行評分。各項定量指標評價區段的劃分標準如表2 所示。
1.2.4 計算各項指標得分和綜合得分
確定客流節點因素集U,按聚類因素分為 4 個子集:客運需求U1、路網屬性U2、客運能力U3、社會屬性U4。各子集Ui={ Ui1,Ui2,…,Uin}。
對每個子集 Ui進行二級評價,Ui的單要素測評矩陣為Ri=(rij)mm,其中,rij為 Ui子集中指標 j 的評價得分。構造二級判斷矩陣得到評價指標權重 Wi,二級評價結果為:
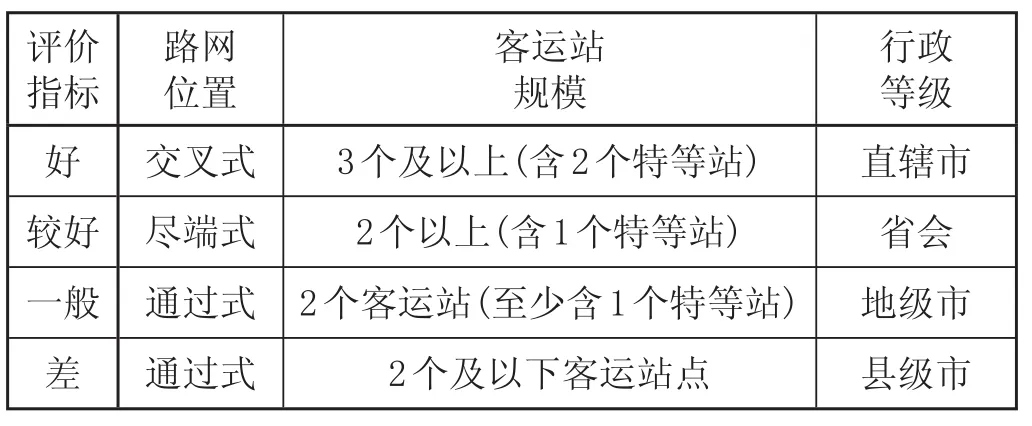
表1 定性指標評價標準
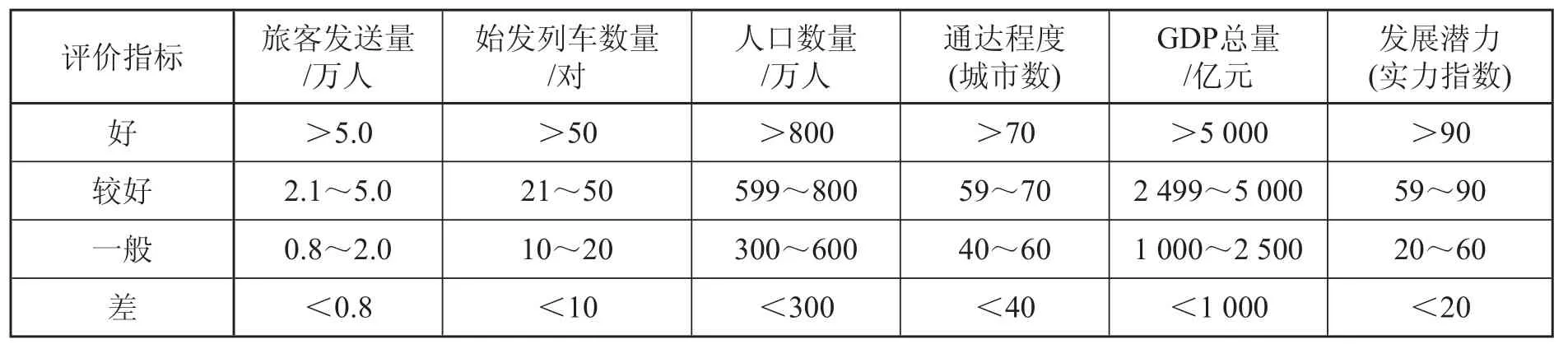
表2 定量指標評價標準
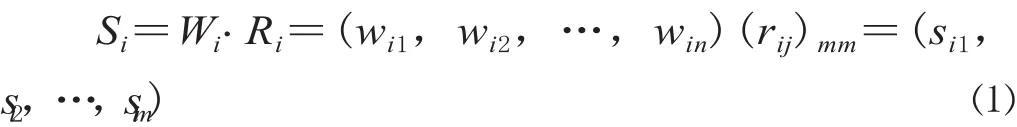
再將每個子集Ui當作一個指標,用 Si作為單因素矩陣,進行一級綜合評價。構造一級判斷矩陣的各因素子集權重W,一級綜合評價結果為:
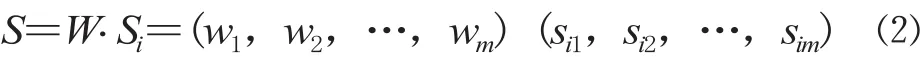
1.3 客流節點K-均值聚類統計
K-均值聚類算法是一種在無類標號數據中發現簇和簇中心的方法。以綜合評價得分為依據,對 N 個數據對象給出 K 個劃分,通過迭代把數據對象劃分到不同的簇中,使簇內部之間對象的相似性很大,而簇之間對象的相似性很小,相似的計算根據一個簇中對象的平均值進行。給定一個含有N個數據對象的數據庫,以及要生成的簇的數目K,隨即選取 K 個對象作為初始的 K 個聚類中心,然后計算剩余各個樣本到每一個聚類中心的距離,把該樣本歸到離其最近的那個聚類中心所在的類,對調整后的新類使用平均值的方法計算新的聚類中心,如果相鄰兩次的聚類中心沒有任何變化,說明樣本調整結束且聚類平均誤差準則函數 E 已經收斂。
2 實例分析
以客運專線站點所在城市為對象,選擇北京、上海、廣州、天津、武漢、大連、濟南、南京、鄭州、合肥、西安、重慶、洛陽、衡陽等 40 個城市,進行聚類研究。
(1)對準則層因素進行兩兩比較,并按照1~9 比率標度進行打分,確定準則層因素相對于目標層因素的重要度,構造一級判斷矩陣。同理,可得二級指標判斷矩陣。
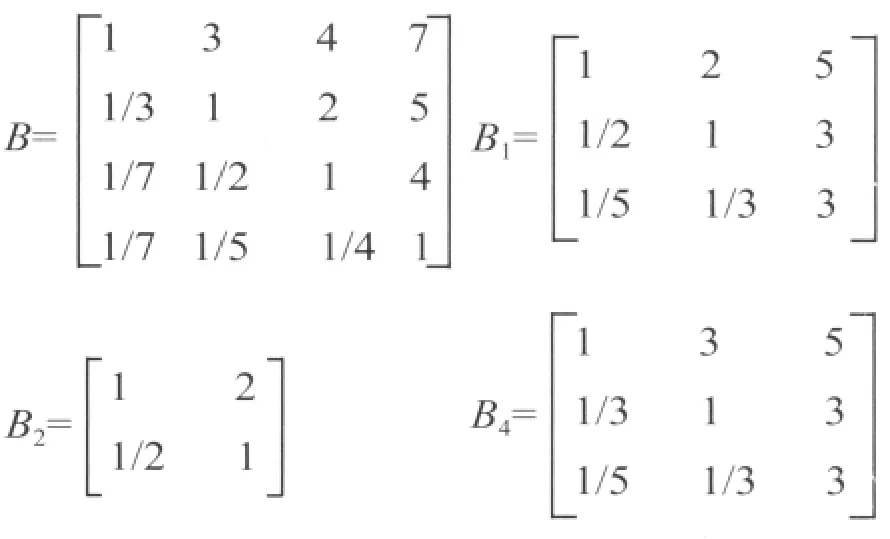
(2)按照歸一法,對判斷矩陣進行計算,求出其特征向量,即得到標準層的一級指標相對于目標層的權重W=[0.55,0.24,0.16,0.55]。同理,可得二級指標相對于一級指標的權重W1=[0.58,0.31,0.11],W2=[0.67,0.33],W4=[0.64,0.26,0.1]。
對一級指標特征向量進行一致性檢驗,先求出特征根 λmax=4.06,n=4。
CI=(4.06-n)/(n-1)=0.06/3=0.02,CR=CI/RI=0.02<0.1,故通過一致性檢驗。
同理,二級指標 4 個特征向量均通過一致性檢驗。
(3)根據客流節點所在城市的實際情況,按照指標評價標準,計算各城市的二級指標得分,并利用式 ⑴ 和式 ⑵ 計算所選城市的一級指標評價得分和綜合評價得分。評價結果如表3 所示。
(4)依據評價得分,應用 SPSS 軟件對所選城市的評價得分進行K—均值聚類運算,統計結果如表4 所示。
綜合 SPSS 統計軟件計算結果,結合鐵路客運專線生產力布局規劃,根據最終得分將客流節點所在城市劃分為 4 類:①綜合得分在 0.91~1.00 之間;②綜合得分在 0.79~0.90 之間;③綜合得分在0.70~0.78 之間;④綜合得分低于 0.70。
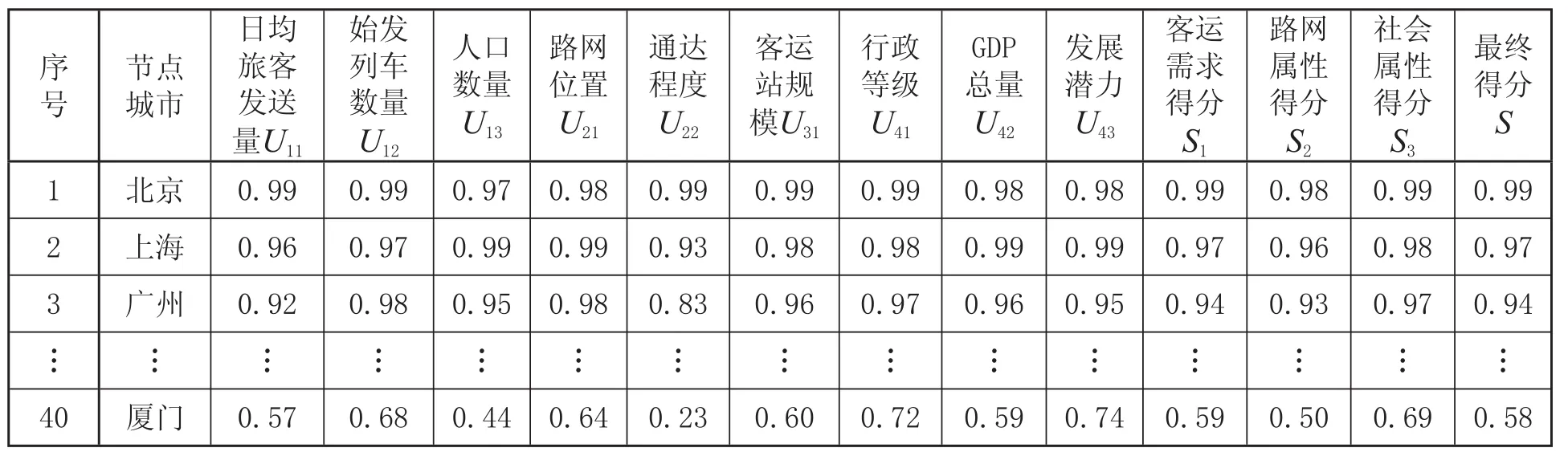
表3 客流節點指標綜合評分結果
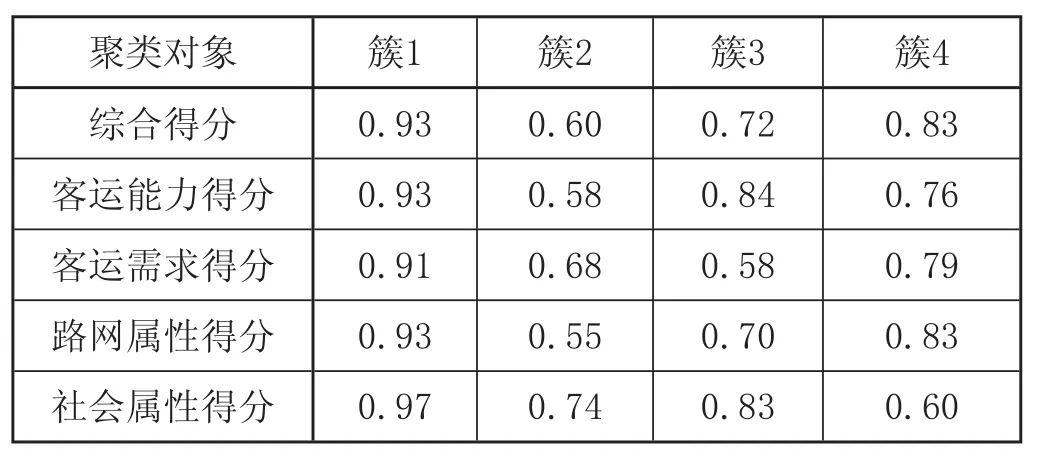
表4 客流節點得分聚類結果
3 聚類統計結果分析
由以上聚類統計結果可知,我國客運專線的客流節點所在城市的層次結構有以下 4 大類。
第一類包括北京、上海、廣州、武漢等城市。這些城市一般位于鐵路網中多條干線縱橫交錯的位置,同時擔負著南北與東西通道的鐵路運輸任務,屬于整個路網的神經中樞。同時,此類客流節點多位于人口規模較大、經濟高度發達的中心城市,對全國政治、經濟、文化的發展有至關重要的影響。另外,此類節點城市還是最重要的始發終到站點,其始發終到客流占有很大的比例。
第二類包括西安、成都、濟南、沈陽等城市。這些城市一般位于幾條鐵路主干道的交叉處,同時也是區域內多條次要通道的匯集中心,在客運專線網中起到承上啟下的中轉過渡功能。這些城市多為省會城市,人口集中、經濟較發達,與周邊地區和城市有著密切聯系,對區域經濟的形成和發展有舉足輕重的影響。該類節點客流呈現多樣性,流向較為分散,跨線客流所占比例較大。
第三類包括大連、太原、蘭州、合肥等城市。這些城市一般位于客運專線各條干道盡端或通過之處,屬于區域內交通的必要節點,主要完成區域內相應地方性節點間的聯絡,并為上層區域輸送客源。此類城市的人口規模和經濟水平均為中上水平,人口出行數量和方向較為穩定。這些節點的運輸組織以中短途客流為主,主要開行區域列車。
第四類包括唐山、溫州、新鄉、信陽等城市。此類城市多屬于直達列車的停站服務范圍,在路網中不具有突出的地位,客流吸引和集散能力較弱。
4 結束語
采用層次分析法對客流節點進行綜合評價,選取具有代表性的評價指標,合理統一量綱,對客流節點的評價得分進行K-均值聚類分析,能方便且較準確地得出聚類結果,有助于鐵路客運部門準確把握客流節點的重要性,對制定列車開行方案和運輸組織工作具有一定的指導意義。
[1]任若思,王惠文. 多元統計數據分析——理論、方法、實例[M]. 北京:國防工業出版社,1997.
[2]李永文. 關于鐵路旅客滿意度的調查分析[J]. 鐵道經濟研究,2002 (5):33-35.
[3]王志華,趙 冬,余永華. 基于模糊 C 均值聚類的柴油機故障診斷[J]. 船海工程,2007 (4):56-57.
[4]戴 賓. 改革開放以來四川區域發展戰略的回顧與思考[J].經濟體制改革,2009 (1):140-142.
[5]李永文. 關于鐵路旅客滿意度的調查分析[J]. 鐵道經濟研究,2002 (5):33-35.
猜你喜歡
石油瀝青(2021年4期)2021-10-14 08:50:44
世界科學技術-中醫藥現代化(2021年10期)2021-03-02 05:52:06
現代檢驗醫學雜志(2016年3期)2016-11-15 01:59:56
中學語文(2015年21期)2015-03-01 03:52:11
中國教育技術裝備(2015年19期)2015-03-01 02:43:07
中國工程咨詢(2015年2期)2015-02-14 02:59:26
西南軍醫(2015年1期)2015-01-22 09:08:16
中國音樂教育(2014年9期)2014-05-20 10:26:24
治淮(2013年1期)2013-03-11 20:05:18
俄羅斯問題研究(2012年1期)2012-03-25 09:54:51
