基于融合樹的事件區(qū)域檢測(cè)容錯(cuò)算法
2010-08-06 13:15:44張書奎王宜懷崔志明樊建席
通信學(xué)報(bào) 2010年9期
張書奎,王宜懷,崔志明,樊建席
(1. 蘇州大學(xué) 計(jì)算機(jī)科學(xué)與技術(shù)學(xué)院,江蘇 蘇州 215006;2. 江蘇省現(xiàn)代企業(yè)信息化應(yīng)用支撐軟件工程技術(shù)研發(fā)中心,江蘇 蘇州 215104)
1 引言
部署在檢測(cè)區(qū)域中由大量節(jié)點(diǎn)組成的無(wú)線傳感器網(wǎng)絡(luò),每個(gè)節(jié)點(diǎn)都具有一定的計(jì)算、感知能力以及有限的能量,目的是協(xié)作地感知、采集和處理網(wǎng)絡(luò)覆蓋區(qū)域中感興趣事件發(fā)生的信息,并發(fā)送給觀察者。某事件的發(fā)生認(rèn)為是環(huán)境狀態(tài)的異常改變,它可能以多種方式出現(xiàn)。隨著時(shí)間的推移,若傳感器讀數(shù)保持平穩(wěn),則認(rèn)為此環(huán)境對(duì)傳感器檢測(cè)來說是時(shí)空關(guān)聯(lián)的[1],可見,位于同一區(qū)域中鄰近傳感器的讀數(shù)關(guān)系密切。當(dāng)某時(shí)段傳感器感知的讀數(shù)偏離了正常值,或者鄰居節(jié)點(diǎn)的讀數(shù)大大超過了預(yù)定義的閾值,則可能是某事件發(fā)生或是傳感器產(chǎn)生了故障[2,3]。但是,傳感器節(jié)點(diǎn)報(bào)告錯(cuò)誤讀數(shù)的原因是多方面的(如與鄰居傳感器的讀數(shù)不同或雖然沒有超過預(yù)先設(shè)定的閾值但卻與它在上一時(shí)間間隔感知讀數(shù)不同等)。若發(fā)生了通信或硬件故障,這些錯(cuò)誤會(huì)導(dǎo)致節(jié)點(diǎn)無(wú)效,意外破壞或惡意通信線路的改變也會(huì)導(dǎo)致無(wú)效節(jié)點(diǎn)的產(chǎn)生。環(huán)境受其他因素的影響,傳感器也可能產(chǎn)生瞬時(shí)的錯(cuò)誤讀數(shù)。特別是部署在粗糙環(huán)境中的動(dòng)態(tài)傳感器網(wǎng)絡(luò)進(jìn)行感興趣事件的檢測(cè),由于網(wǎng)絡(luò)拓?fù)浣Y(jié)構(gòu)發(fā)生變化,也會(huì)導(dǎo)致錯(cuò)誤讀數(shù)的產(chǎn)生。一般來說,傳感器的錯(cuò)誤一般可分為兩類[2]:一類是誤判錯(cuò)誤,即當(dāng)環(huán)境處于正常狀況時(shí),傳感器卻報(bào)告有事件發(fā)生;另一類是失判錯(cuò)誤,即當(dāng)有特定的事件發(fā)生時(shí),傳感器卻沒有報(bào)告事件的發(fā)生。所以,在無(wú)線傳感器網(wǎng)絡(luò)中,保證原始數(shù)據(jù)的可信性,消除錯(cuò)誤讀數(shù)的影響,是事件區(qū)域檢測(cè)需要解決的關(guān)鍵問題之一。
文獻(xiàn)[4]提出了事件區(qū)域檢測(cè)的一種局部分布式算法。該算法假設(shè)事件是空間相關(guān)而錯(cuò)誤是空間不相關(guān)的,且每個(gè)傳感器發(fā)生錯(cuò)誤的概率相同。作為一種局部算法,它僅需要每個(gè)傳感器與自己的鄰居交換讀數(shù),從而獲得鄰居節(jié)點(diǎn)檢測(cè)事件發(fā)生的統(tǒng)計(jì)概率,利用Bayesian分析,判定發(fā)生的是故障還是事件。文獻(xiàn)[5]則改進(jìn)了文獻(xiàn)[4]的算法,考慮了傳感器誤差和錯(cuò)誤引起的對(duì)事件判斷的影響以及如何選擇合適的鄰居數(shù)目,達(dá)到容錯(cuò)的同時(shí)減少數(shù)據(jù)交換的目的。文獻(xiàn)[4~8]都是基于概率分析的方法,而且需要傳感器進(jìn)行復(fù)雜的運(yùn)算。文獻(xiàn)[9]提出了一種相對(duì)簡(jiǎn)單非概率的檢測(cè)算法,通過兩輪投票以及少數(shù)服從多數(shù)原則,確定發(fā)生的是故障還是事件。
關(guān)于事件邊界檢測(cè)的研究,文獻(xiàn)[10,11]認(rèn)為,事件的邊界是指事件區(qū)域與正常區(qū)域的分界線。如果一個(gè)傳感器的鄰居中既有異常的讀數(shù),又有正常的讀數(shù),那么就認(rèn)為該傳感器位于事件區(qū)域的邊界。已有的事件邊界檢測(cè)算法依然是基于事件是空間相關(guān)的假設(shè),同時(shí)采用概率分析的方法。還有一類工作關(guān)注于錯(cuò)誤診斷[12],這類工作關(guān)注的是如何確定錯(cuò)誤發(fā)生的范圍或者引發(fā)錯(cuò)誤的錯(cuò)誤源,而不是事件發(fā)生的范圍。文獻(xiàn)[13]介紹了一種基于簇頭構(gòu)建四叉樹的方法進(jìn)行邊界檢測(cè),每片葉子與長(zhǎng)方形區(qū)域相對(duì)應(yīng)。與四叉樹的聚類方法不同,本文構(gòu)建了一種易擴(kuò)展的二叉查詢樹,該查詢樹可以覆蓋整個(gè)感興趣的區(qū)域,能快速將事件發(fā)生的信息從感知節(jié)點(diǎn)傳輸?shù)絊ink。文獻(xiàn)[14]是使用一種基于分類的邊緣檢測(cè)機(jī)制,由線性多項(xiàng)式描述事件邊界,由此判定事件是在檢測(cè)區(qū)域的里面還是外面。然而,一個(gè)線性多項(xiàng)式不可能獲取事件發(fā)生的精確細(xì)節(jié)。而本文是通過構(gòu)建多元回歸模型來近似檢測(cè)區(qū)域的感知值,沒有洪泛而是使用融合樹進(jìn)行事件邊界檢測(cè),以事件的時(shí)空關(guān)聯(lián)特性檢測(cè)整個(gè)區(qū)域,而不是通過2個(gè)事件之間的邊界來判定事件的發(fā)生。
分布式核回歸文獻(xiàn)[15]與本文的算法有相似之處,但也存在著較大不同。前者,任何一個(gè)節(jié)點(diǎn)都含有它局部區(qū)域范圍內(nèi)的近似參數(shù),因而,它不能正確回答自己局部區(qū)域之外的查詢, 每個(gè)節(jié)點(diǎn)發(fā)送含有一個(gè)向量(向量用來描述覆蓋它的局部區(qū)域)的信息,這個(gè)向量的大小隨著大量的和它共享核變量的鄰居節(jié)點(diǎn)的增加而增長(zhǎng),這對(duì)于資源受限的傳感器節(jié)點(diǎn)來說,是難以忍受的。
針對(duì)目前在上述方面研究的不足,本文提出了一種基于融合樹的事件區(qū)域檢測(cè)容錯(cuò)算法,改算法分為2個(gè)階段。首先,構(gòu)建分布式融合樹,每個(gè)感知節(jié)點(diǎn)僅報(bào)告自己的感知數(shù)據(jù)到最鄰近的樹節(jié)點(diǎn),樹節(jié)點(diǎn)執(zhí)行多元線性回歸,獲得事件區(qū)域檢測(cè)的估計(jì)值,傳輸?shù)氖敲枋鍪录^(qū)域檢測(cè)的多元回歸模型的系數(shù),而不是實(shí)際的感知數(shù)據(jù),Sink通過直接查詢根節(jié)點(diǎn)就可獲的感興趣區(qū)域內(nèi)任一位置的感知值,減少了事件區(qū)域檢測(cè)的通信代價(jià)和復(fù)雜性。其次,在所構(gòu)建融合樹的基礎(chǔ)上,可以對(duì)單個(gè)或多個(gè)同時(shí)發(fā)生的事件進(jìn)行容錯(cuò)檢測(cè),識(shí)別有故障的傳感器節(jié)點(diǎn)和發(fā)生在邊界區(qū)域的事件,快速把檢測(cè)讀數(shù)傳給基站,減少數(shù)據(jù)傳輸?shù)哪芰肯暮脱舆t。
2 融合樹的構(gòu)建
融合樹(AT, aggregation tree)的構(gòu)建是事件區(qū)域檢測(cè)過程的基礎(chǔ)。其目標(biāo)是減少數(shù)據(jù)傳輸量,提高檢測(cè)精度。對(duì)數(shù)據(jù)融合算法的理論分析表明[16],在完全融合的情況下,尋找最優(yōu)融合樹的問題等同于求解最小Steiner樹的NP完全問題。為此,需要在計(jì)算處理能耗與傳輸能耗之間進(jìn)行權(quán)衡。下面討論融合樹的構(gòu)建過程。
2.1 網(wǎng)絡(luò)模型
設(shè)N個(gè)資源受限的靜態(tài)傳感器節(jié)點(diǎn)隨機(jī)地部署在檢測(cè)區(qū)域R=(r×r)內(nèi),用集合S=(s1,s2,…,sn)描述,其中si表示第i個(gè)傳感器,如圖1所示。每個(gè)節(jié)點(diǎn)通過三角剖分[14]都有它的位置信息,節(jié)點(diǎn)si位置用(xi,yi)表示,且每個(gè)節(jié)點(diǎn)具有唯一的ID、相同的計(jì)算通信能力和能量資源。節(jié)點(diǎn)通過時(shí)間同步服務(wù)[15]達(dá)到寬松的時(shí)間同步,通信接入采用CSMA/CA以減小信道沖突。本文的目標(biāo)是在此N個(gè)節(jié)點(diǎn)的網(wǎng)絡(luò)中構(gòu)建融合樹,AT由Nt個(gè)節(jié)點(diǎn)組成,叫作樹節(jié)點(diǎn),樹節(jié)點(diǎn)用于接收并融合數(shù)據(jù),其余(N-Nt)個(gè)節(jié)點(diǎn)叫作非樹節(jié)點(diǎn)(NT, not tree node),每個(gè)NT節(jié)點(diǎn)感知指定區(qū)域事件屬性的變化,并將感知數(shù)據(jù)傳輸?shù)剿钹徑臉涔?jié)點(diǎn)。構(gòu)建的AT擴(kuò)展到整個(gè)網(wǎng)絡(luò),以便Nt個(gè)樹節(jié)點(diǎn)均勻一致地分布在網(wǎng)絡(luò)中,這樣,可以確保檢測(cè)屬性值以盡可能小的跳數(shù)由NT節(jié)點(diǎn)傳送到對(duì)應(yīng)的樹節(jié)點(diǎn),從而延長(zhǎng)網(wǎng)絡(luò)的壽命。為簡(jiǎn)便起見,Pevent(在圖1中矩形框里的虛線表示)代表事件,Revent表示事件區(qū)域且ReventR?。正常情況下,AT覆蓋檢測(cè)區(qū)域里所有的事件。R'定義為R中沒有被覆蓋的部分,即R′= R-Revent。
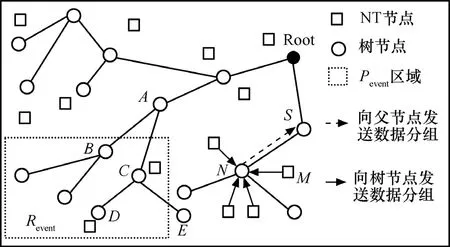
圖1 網(wǎng)絡(luò)模型
2.2 樹的生成
某事件的發(fā)生會(huì)觸發(fā)網(wǎng)絡(luò)中的部分節(jié)點(diǎn)使其讀數(shù)異常,這可能是一個(gè)孤立點(diǎn),也可能是多個(gè)。為確保AT擴(kuò)散到整個(gè)網(wǎng)絡(luò),感知值由傳感節(jié)點(diǎn)通過較小的跳數(shù)傳輸?shù)较鄳?yīng)的樹節(jié)點(diǎn),盡可能保持分散節(jié)點(diǎn)的拓?fù)浞€(wěn)定性以維持原有較好的感知覆蓋范圍,為此引入了Voronoi圖以及相關(guān)Delaunay三角網(wǎng)絡(luò)來描述感知網(wǎng)絡(luò)拓?fù)鋄17],并基于 Delaunay三角定義,構(gòu)建以事件中心節(jié)點(diǎn)為根的感知網(wǎng)絡(luò)融合樹——伸展樹。伸展樹是一種二叉樹,其優(yōu)點(diǎn)在于不需要記錄用于平衡樹的冗余信息。設(shè)e為平面上的點(diǎn),則
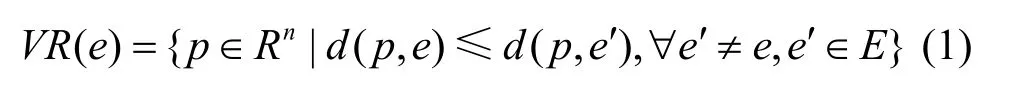
稱為Voronoi多邊形。則Voronoi圖定義為
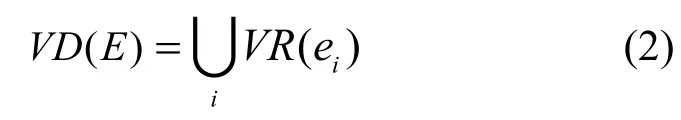
即平面上所有Voronoi多邊形的集合,而Delaunay三角網(wǎng)絡(luò)則為連接所有相鄰的 V-多邊形的生長(zhǎng)中心所形成。Delaunay 三角網(wǎng)具有很多重要的性質(zhì)[17],通過Delaunay 表達(dá)不僅可以獲得每個(gè)節(jié)點(diǎn)的鄰節(jié)點(diǎn)信息,而且可以用來查找最接近的節(jié)點(diǎn)。基于傳感器網(wǎng)絡(luò)的 Delaunay 描述,構(gòu)建以事件中心節(jié)點(diǎn)為根的伸展樹。設(shè)目標(biāo)區(qū)域?yàn)锳,區(qū)域中的感知節(jié)點(diǎn)集為
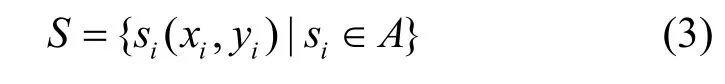
其中,(xi,yi)為節(jié)點(diǎn)si的位置坐標(biāo)。由節(jié)點(diǎn)集S構(gòu)成網(wǎng)絡(luò)對(duì)應(yīng)的加權(quán)無(wú)向圖為G,各邊所對(duì)應(yīng)的權(quán)值為節(jié)點(diǎn)間距離。并設(shè)感知區(qū)域外存在點(diǎn)集K={ki(xi,yi) | ki?A},則目標(biāo)區(qū)域中以節(jié)點(diǎn)si為中心相對(duì)于點(diǎn)集K的節(jié)點(diǎn)伸展樹定義為T,有:
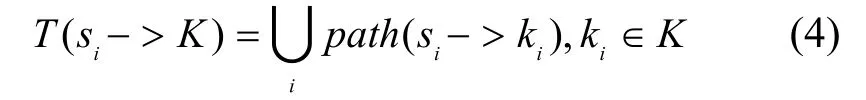
其中, p ath( si-> ki)為無(wú)向圖G中從si到ki的節(jié)點(diǎn)間的最大跨度路徑,其長(zhǎng)度為l。在此路徑上,各節(jié)點(diǎn)間的最小距離大于或等于G中任何其他從si到ki路徑上節(jié)點(diǎn)間的最小距離。最大跨度路徑反映了兩節(jié)點(diǎn)之間具有伸展性的一條通路。需要指出的是,在一個(gè)特定的無(wú)向圖G 中,兩點(diǎn)間的最大跨度路徑并不唯一,可能存在多條。而對(duì)于不同的域外節(jié)點(diǎn)集,相應(yīng)的以根節(jié)點(diǎn)為中心的伸展樹也并不唯一。
設(shè)樹的深度為p,樹節(jié)點(diǎn)存儲(chǔ)感知的屬性值, 這樣的樹被認(rèn)為是平衡的,它減少了數(shù)據(jù)丟失增加了數(shù)據(jù)融合的精確性[15]。算法Form_AT是由給定的深度創(chuàng)建伸展樹。每當(dāng)一個(gè)節(jié)點(diǎn)要選擇它的2個(gè)孩子時(shí),就選擇跨度最大的2個(gè)節(jié)點(diǎn),可確保樹在擴(kuò)散時(shí)覆蓋盡可能多的感興趣區(qū)域,伸展樹形成后,各子區(qū)域中所有剩余節(jié)點(diǎn)向距離自己最近的樹節(jié)點(diǎn)發(fā)送數(shù)據(jù)。本文通過3種消息即Beacon、Probe和Join實(shí)現(xiàn)樹的構(gòu)建。圖2描述了消息交換構(gòu)建融合樹的過程。
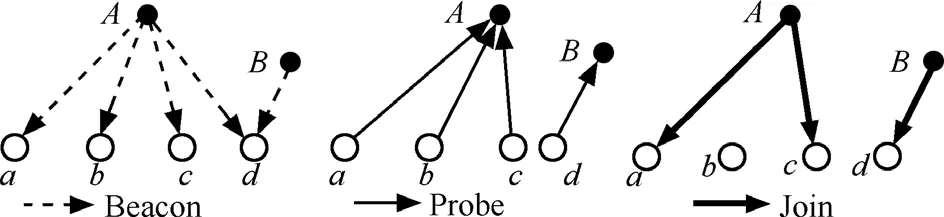
圖2 消息交換構(gòu)建融合樹
1) Beacon消息。
在d-跳鄰居發(fā)現(xiàn)過程中每個(gè)節(jié)點(diǎn)u在d-跳范圍內(nèi)廣播Beacon消息NMu={Message,u,Hop},其中 Message為消息類型, u為節(jié)點(diǎn) ID,Hop字段為消息跳數(shù)計(jì)數(shù),初始為0,接收到NMu的節(jié)點(diǎn)v將u加入自己的d-跳鄰居列表對(duì)接收到的一份或多份冗余 NMu,v選擇 Hop值最小的NMu, 將其Hop字段加1并更新Hopu,v=Hop,如果Hop<d則繼續(xù)向鄰居廣播,然后v進(jìn)入等待狀態(tài)。如果v在等待狀態(tài)時(shí)又偵聽到Hop+1<Hopu,v的NMu,則記錄該消息并將Hop字段加1重復(fù)上述過程;否則v不作任何動(dòng)作直到計(jì)時(shí)器超時(shí)。這里計(jì)時(shí)器時(shí)長(zhǎng)可以設(shè)為網(wǎng)絡(luò)初始化階段時(shí)長(zhǎng)。
對(duì)于來自不同節(jié)點(diǎn)的Beacon消息,接收節(jié)點(diǎn)v都執(zhí)行相同的過程。圖3是Beacon消息處理過程的自動(dòng)機(jī)表示。通過Beacon消息廣播每個(gè)節(jié)點(diǎn)v可以獲得 d-跳范圍內(nèi)節(jié)點(diǎn)集合,Hopu,v表示由這種帶跳數(shù)更新的廣播重傳過程所得到的節(jié)點(diǎn)u,v之間的近似最短路徑跳數(shù)。由于傳感器網(wǎng)絡(luò)靜態(tài)部署,對(duì)每個(gè)節(jié)點(diǎn)u,是穩(wěn)定的。這里即為所有可能樹節(jié)點(diǎn)成員的集合。在 j層的每一個(gè)節(jié)點(diǎn)向它所有的下一跳鄰居廣播一個(gè)Beacon包,這樣,j+1層的節(jié)點(diǎn)從j層接收到多個(gè)Beacon包,從中隨機(jī)選取一個(gè)概率值p′ > p′的節(jié)點(diǎn)作為它們的父節(jié)點(diǎn),并向它發(fā)送一個(gè)Probe包。
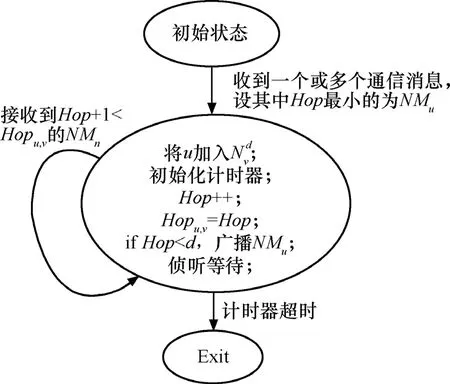
圖3 節(jié)點(diǎn)的Beacon通知消息處理過程
從圖2可以看出,節(jié)點(diǎn)d從A和B接收Beacon,p′(該算法的一個(gè)輸入)的值按如下方法優(yōu)化。
設(shè)父節(jié)點(diǎn)i以通信半徑 r,向圓心角為120°的扇形區(qū)域廣播它的 Beacon消息,該扇形區(qū)的面積為
這個(gè)區(qū)域的節(jié)點(diǎn)數(shù)為
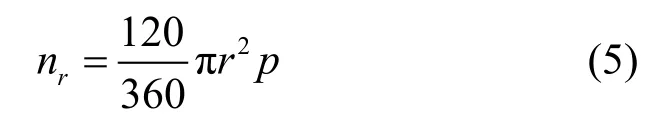
其中,p為樹的深度。按如下的二項(xiàng)式分布,選擇區(qū)域內(nèi)概率為p′的2個(gè)節(jié)點(diǎn)作為它們的父節(jié)點(diǎn)。
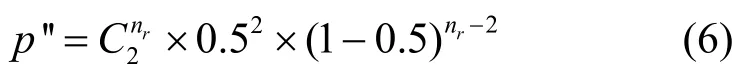
如果一個(gè)節(jié)點(diǎn)從預(yù)期的父節(jié)點(diǎn)那里接收到了多個(gè)Beacon消息,那么它們的ID將會(huì)被新選擇的父節(jié)點(diǎn)所保存,以便于在節(jié)點(diǎn)失敗的情況下快速恢復(fù)。
2) Probe消息。
選定的父節(jié)點(diǎn)等待從它的孩子節(jié)點(diǎn)處接收Probe分組,之后,決定選擇哪2個(gè)作為它的孩子節(jié)點(diǎn)。一旦它收到了它的下一跳j+1層所有節(jié)點(diǎn)的消息,就會(huì)選擇離它最遠(yuǎn)的2個(gè)節(jié)點(diǎn)作為它的孩子。那些沒有被任何父節(jié)點(diǎn)所選擇的節(jié)點(diǎn)將不再嘗試成為AT的成員而轉(zhuǎn)化為感知節(jié)點(diǎn),這樣,樹(因?yàn)閭鞲型ㄐ诺拇鷥r(jià)遠(yuǎn)大于存儲(chǔ)的代價(jià))的大小能適當(dāng)減小。從圖2可以看出,節(jié)點(diǎn)d選擇B作為它的父節(jié)點(diǎn),并向它發(fā)送一個(gè)Probe分組,而后,節(jié)點(diǎn)A向節(jié)點(diǎn)a、b、c和d發(fā)送Beacon消息但是僅從節(jié)點(diǎn)a、b和c接收到Probe分組。
3) Join 消息
父節(jié)點(diǎn)在選擇了孩子之后,向它們發(fā)送一個(gè)Join消息,宣布將它們加入該樹。從圖2可以看出,A選擇節(jié)點(diǎn)a和c作為它們的孩子,而a和c距離A比a和b或者b和c都遠(yuǎn)。
融合樹構(gòu)建算法Form_AT(p,p")描述如下。
輸入:樹的深度p和父節(jié)點(diǎn)選擇概率。
輸出:深度為p的二叉樹Tc且每一個(gè)節(jié)點(diǎn)分配唯一的ID
1) 對(duì)于第j層,深度從0到p-1的每一個(gè)節(jié)點(diǎn)i從 1到2j;
2) Mi是j +1層的一個(gè)節(jié)點(diǎn);
3) ni是在j層上的一個(gè)節(jié)點(diǎn);
4) 在Mi的通信范圍內(nèi)的節(jié)點(diǎn)ni(Mi< r),發(fā)送包含其ID 的Beacon包到Mi;/* r為通信半徑 */
5) 對(duì)于大于p"且跨越路徑長(zhǎng)度最大的節(jié)點(diǎn)ni,Mi選擇它作為其父節(jié)點(diǎn);
6) Mi發(fā)送 Probe 包到 ni;
7) ni等待 NWAIT 時(shí)刻(恰當(dāng)?shù)臅r(shí)間周期)從選擇ni作為父節(jié)點(diǎn)的Mi接受Probe包。
對(duì)于傳感器網(wǎng)絡(luò)來說,在最大跨度路徑上的節(jié)點(diǎn)具有較好的分散性,減少了由于覆蓋重疊而對(duì)網(wǎng)絡(luò)感知能力所造成的影響,因此這些分散性好的節(jié)點(diǎn)需要保持。通過節(jié)點(diǎn)伸展樹的定義,確定了傳感器網(wǎng)絡(luò)中需要保持的節(jié)點(diǎn)集。基于此節(jié)點(diǎn)集,對(duì)于覆蓋重疊節(jié)點(diǎn)也可有效地提高網(wǎng)絡(luò)整體的感知能力。
2.3 數(shù)據(jù)融合
基于伸展樹的數(shù)據(jù)融合算法的主要思想是采用傳輸能夠擬合較多的檢測(cè)數(shù)據(jù)的模型 M 來代替?zhèn)鬏敼?jié)點(diǎn)的檢測(cè)數(shù)據(jù),其目的是為了減少數(shù)據(jù)傳輸量,從而節(jié)省傳感器節(jié)點(diǎn)的能量。因此需要考慮回傳以參數(shù)表示的模型的代價(jià)和其可擬合的數(shù)據(jù)量之間的關(guān)系。傳輸模型的代價(jià)越小其能夠表示的數(shù)據(jù)越多,節(jié)點(diǎn)就越節(jié)省能量。由于節(jié)點(diǎn)檢測(cè)值往往要受多個(gè)因素的影響,期望用最小代價(jià)模型擬合最多的數(shù)據(jù),且計(jì)算簡(jiǎn)單,而多元線性回歸模型恰好符合這一目標(biāo)。
融合樹中的每個(gè)節(jié)點(diǎn)接收并存儲(chǔ)由最近的非樹節(jié)點(diǎn)周期性報(bào)告給它的數(shù)據(jù),即NT節(jié)點(diǎn)負(fù)責(zé)感知而AT節(jié)點(diǎn)負(fù)責(zé)存儲(chǔ),將存儲(chǔ)在AT節(jié)點(diǎn)里的值看作是輸入x-y坐標(biāo)的函數(shù)值,此過程由三元組(f,x,y)描述,這里 f為位于(x,y)處節(jié)點(diǎn)的感知估計(jì)值,由AT中存儲(chǔ)在節(jié)點(diǎn)i的數(shù)據(jù)及其子節(jié)點(diǎn)發(fā)送的多元回歸模型的系數(shù)執(zhí)行多元線性函數(shù)回歸生成。下面討論這種數(shù)據(jù)融合過程。
設(shè)多元線性回歸模型形式如下[18]:
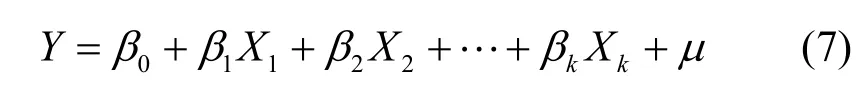
其中,Y為感知估計(jì)值,Xj(j=1, 2, …,k)為對(duì)感知估計(jì)值Y發(fā)生作用的影響因子,βj(j=0, 1, 2, …, k)為k+1個(gè)未知回歸參數(shù),μ為隨機(jī)誤差項(xiàng)。由于參數(shù)βj(j=0, 1, 2, …, k)都是未知的,可以利用樣本觀測(cè)值(x1i, x2i, …, xki;Yi)對(duì)它們進(jìn)行估計(jì),由此得到的參數(shù)估計(jì)值為用參數(shù)估計(jì)值替代回歸模型的未知參數(shù)βj(j=0, 1, 2,…, k),則得到多元線性樣本回歸方程為
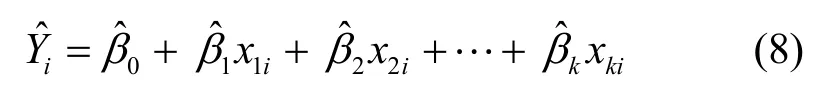
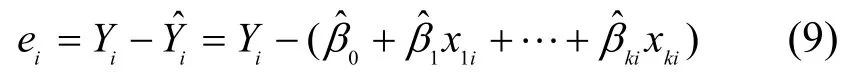
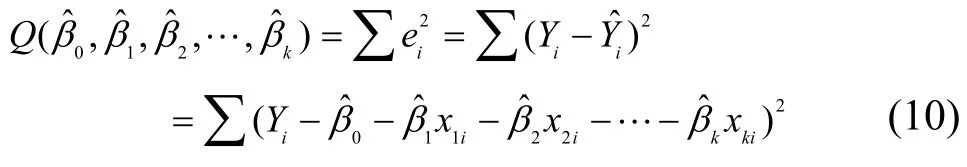
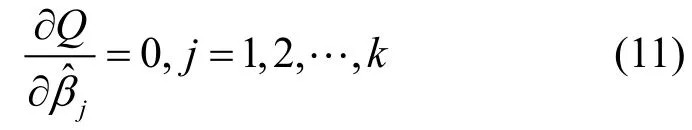
將上述k+1個(gè)方程化簡(jiǎn)得下列方程組:
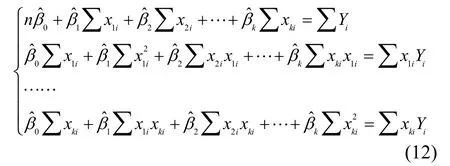
其矩陣形式為
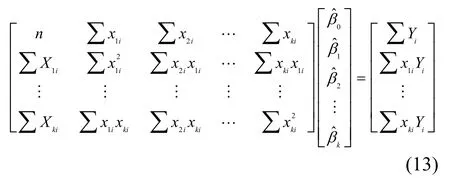
經(jīng)化簡(jiǎn)得如下方程:
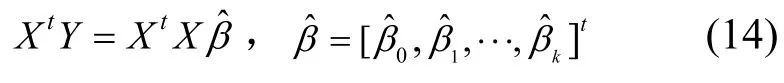
設(shè)R(X)=K+1, XtX為(K+1)階方陣,則 XtX滿秩,其逆矩陣存在,所以β的最小二乘估計(jì)向量為
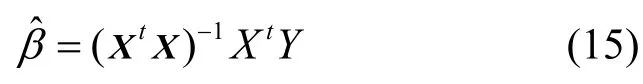
運(yùn)用多項(xiàng)式回歸,得到如下方程:
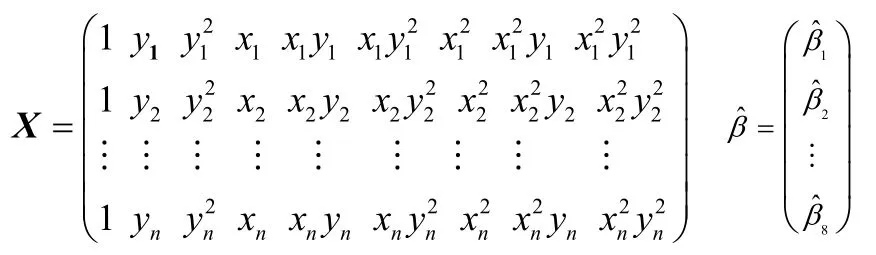
其中,

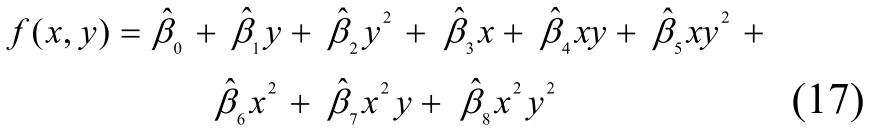
數(shù)據(jù)融合算法SPAT(p, ns)描述如下:/* ns為感知節(jié)點(diǎn)向樹節(jié)點(diǎn)報(bào)告的平均數(shù)*/
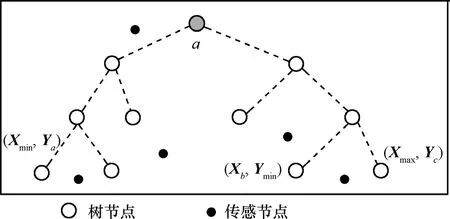
圖4 融合過程中邊界區(qū)域的計(jì)算
1) 對(duì)于樹中的每一個(gè)葉節(jié)點(diǎn)i
其節(jié)點(diǎn)的數(shù)據(jù)被讀取;
執(zhí)行多元線性回歸,其系數(shù) β0,β1,…,β8被存儲(chǔ);
2) 初始樹的深度為2p
While 當(dāng) p >0 時(shí)
sum = level + 2p-1
k = level
while k < sum
3) 對(duì)于樹中的每個(gè)非葉節(jié)點(diǎn) k,在(xmin, ymin)和(xmax, ymax)的范圍內(nèi)計(jì)算其位置x-y點(diǎn)報(bào)告給它的2個(gè)孩子節(jié)點(diǎn)i 和i+l;
4) 計(jì)算新的(βi0, βi1,…,βi8)和(β(i+1)0,β(i+1)1,…,β(i+1)8) ,添加到節(jié)點(diǎn)k的信息中,然后調(diào)用回歸函數(shù)計(jì)算(βk0,…,βk8) ,傳輸?shù)剿母腹?jié)點(diǎn);
5) 轉(zhuǎn)到下一級(jí)深度繼續(xù)。
相對(duì)于傳輸原始數(shù)據(jù)到 Sink節(jié)點(diǎn)的能量消耗和時(shí)延,通過SPAT融合過程報(bào)告數(shù)據(jù)更為有效。在AT中,設(shè)壓縮比定義為將原始數(shù)據(jù)壓縮之后再傳送的字節(jié)數(shù)與原始數(shù)據(jù)之比。設(shè)深度為 p的AT共有 t = 2(p+1)- 1個(gè)樹節(jié)點(diǎn),每個(gè)大小為wi字節(jié)的數(shù)據(jù)分組包含感知讀數(shù)和該讀數(shù)所對(duì)應(yīng)的位置坐標(biāo)。這樣,輸入到每個(gè)葉子節(jié)點(diǎn)的字節(jié)數(shù)大小為nswi,其中ns為感知節(jié)點(diǎn)向樹節(jié)點(diǎn)報(bào)告的平均數(shù)。所以,傳輸?shù)饺~節(jié)點(diǎn)的字節(jié)數(shù)
除了從感知節(jié)點(diǎn)讀取檢測(cè)值以外,每個(gè)非葉節(jié)點(diǎn)用從它的2個(gè)孩子那里得到值作為輸入來更新系數(shù)和區(qū)域邊界的x-y值。所以,輸入到非葉子節(jié)點(diǎn)的字節(jié)總數(shù)Tnl為
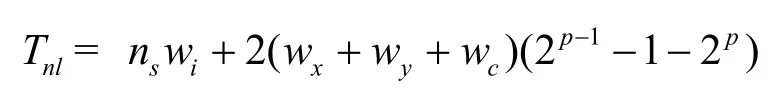
從樹節(jié)點(diǎn)獲得大小為(wx+ wy+ wc)字節(jié)的輸出分組(包括系數(shù)和x-y的范圍)。
從所有節(jié)點(diǎn)輸出的字節(jié)總數(shù) T0= ( wx+ wy+wc)× (2p-1- 1 )s,那么壓縮比為
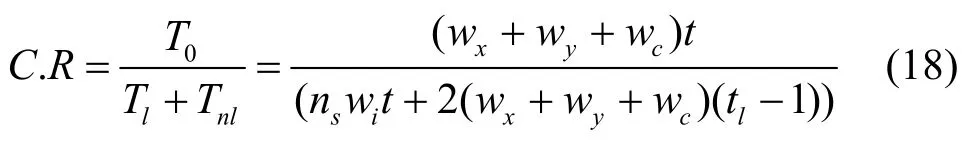
其中,t為樹節(jié)點(diǎn)總數(shù),lt為葉子節(jié)點(diǎn)數(shù)。
3 事件區(qū)域檢測(cè)
在許多應(yīng)用中,使用函數(shù) σ (i, t)=F (v1, v2,…,vk)來描述檢測(cè)區(qū)域的狀態(tài)信息(如溫度,濕氣等),這些信息由感知傳感器 i∈N在時(shí)刻 t獲得,其中 vk是影響傳感器讀數(shù)的參數(shù)。一般來說,由于已知或未知因素的影響,很難得到準(zhǔn)確的函數(shù)表達(dá)形式。除一些特例外,時(shí)間變化以及線性或非線性的其他因素也可能會(huì)影響檢測(cè)讀數(shù),而這些因素很難形式化表示。例如,一個(gè)溫度傳感器的讀數(shù)受很多因素的影響,如地點(diǎn)、天氣、時(shí)間等。本文不是設(shè)法得到一個(gè)確切的函數(shù)表示,而是形式化函數(shù)F的基本屬性,從而分析傳感器的讀數(shù)σ(i,t) 。
3.1 事件區(qū)域檢測(cè)的性質(zhì)
設(shè)傳感器節(jié)點(diǎn)對(duì)某一區(qū)域的檢測(cè)讀數(shù),有以下性質(zhì):
1) 每個(gè)傳感器節(jié)點(diǎn)是獨(dú)立的;
2) 存在 2個(gè)常量 Cmin和 Cmax(Cmin≤σ(i, t)≤ Cmax),分別是傳感器檢測(cè)獲得讀數(shù)的最小和最大值;
3) 在[Cmin, Cmax]內(nèi),σ(i, t)連續(xù)且服從密度函數(shù)為φ(i)的正態(tài)分布,期望值為
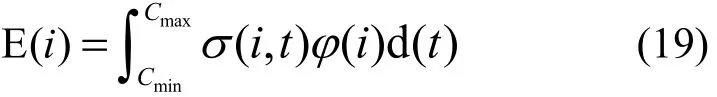
性質(zhì) 1)說明傳感器獨(dú)立地檢測(cè)環(huán)境變化,性質(zhì) 2)說明正常傳感器讀數(shù)的變化范圍,性質(zhì) 3)說明,傳感器檢測(cè)讀數(shù)的變化空間,由適合正態(tài)分布的應(yīng)用事例確定,如每日氣溫、風(fēng)速等。本文對(duì)正常與錯(cuò)誤讀數(shù)的判定條件如下。
正常讀數(shù):通常情況下,檢測(cè)讀數(shù)σ(i, t)在[Cmin,Cmax]內(nèi)且服從正態(tài)分布φ(i),若存在τ1>0,使得檢測(cè)讀數(shù)滿足 |σ (i, t) - E (i )|≥τ1,說明傳感器讀數(shù)超出了正常范圍。滿足該條件的節(jié)點(diǎn)越多,事件發(fā)生的可能性就越大。
錯(cuò)誤讀數(shù):對(duì)于傳感器i,φ(i)滿足以下3個(gè)條件中的任一個(gè),該傳感器可能為故障傳感器,其檢測(cè)產(chǎn)生的讀數(shù)為錯(cuò)誤讀數(shù)。
1) 若存在τ1,τth且τth>τ1>0,對(duì)于? t, | σ(i, t)-E(i)|≥τth,說明傳感器的讀數(shù)超出了正常范圍,它很可能是有故障的。如果傳感器頻繁或者持續(xù)報(bào)告這樣的讀數(shù),那么認(rèn)為這個(gè)傳感器是有故障的。
2) 在事件報(bào)告的幾個(gè)連續(xù)時(shí)期,有|σ(i,( t+1)-σ( i, t )|≈ 0 ,若存在常數(shù)c,使得節(jié)點(diǎn)i的鄰居傳感器 i′滿足|σ(i′,(t+1 ) - σ (i′, t )|>c,即鄰居傳感器 i′讀數(shù)隨著時(shí)間的推移發(fā)生變化,而傳感器i的讀數(shù)卻是恒定的,那么傳感器i是有故障的。同理,在一個(gè)特定的階段,有|σ(i',(t+1 )-σ (i', t )|≈ 0 ,如果一個(gè)傳感器 i的鄰居傳感器 i'檢測(cè)到一個(gè)很小的讀數(shù)變化,傳感器i的讀數(shù)卻有很大的變化,那么這個(gè)傳感器i是有故障的。
3) ?t ,Cmin< σ (i, t) < Cmax, σ( i,t+1) > τ2,Cmin<σ( i, t + 2 )<Cmax, σ(i, t + 3 ) >τ2,這個(gè)條件表明傳感器的讀數(shù)呈不規(guī)則變化,那么傳感器i是有故障的。例如,傳感器的讀數(shù)周期性地或間歇地從正常讀數(shù)變化到事件讀數(shù),再變化到正常讀數(shù)。
為提高檢測(cè)讀數(shù)的準(zhǔn)確性,首先要識(shí)別有故障的傳感器。由性質(zhì)1)可知,通過對(duì)當(dāng)前讀數(shù)σ(i, t)與期望值E(i)進(jìn)行比較判定i是否發(fā)生了故障,設(shè)樹節(jié)點(diǎn)的數(shù)量 nt總是滿足條件 nt? 3 nnmax+1,其中ntmax表示故障樹節(jié)點(diǎn)的最大數(shù)量,該條件確保有故障的傳感器能被有效識(shí)別[10]。另一方面,為增加有故障節(jié)點(diǎn)事件檢測(cè)的置信度,每隔一個(gè)時(shí)間間隔,對(duì)可疑傳感器是否為故障點(diǎn)進(jìn)行判斷,一旦檢測(cè)到故障節(jié)點(diǎn),立即隔離。設(shè)ri是函數(shù)σ(i, t)的一個(gè)實(shí)例,這里σ(i, t)表示在一個(gè)特定時(shí)刻傳感器的讀數(shù)(如溫度、聲音,氧氣密度等)。在沒有錯(cuò)誤的檢測(cè)數(shù)據(jù)時(shí),事件定義為傳感器的異常讀數(shù),有如下定理。
定理 1 當(dāng)事件發(fā)生時(shí),存在σ> 0,使|ri- E (rr) |> σ 。
證明 (反證法)如果|ri- E (rr)|= 0,那么傳感器的讀數(shù)與期望值相同。這表明在沒有事件發(fā)生的時(shí),ri不變,這與事件的定義矛盾。
為了使樹節(jié)點(diǎn)獲取它周圍NT節(jié)點(diǎn)讀數(shù)的特征值,定義di作為樹節(jié)點(diǎn)在時(shí)刻t從它周圍的NT節(jié)點(diǎn)獲得讀數(shù)的平均值。由性質(zhì) 1)知,每個(gè)傳感器的讀數(shù)不依賴于其他節(jié)點(diǎn),由性質(zhì) 3)知傳感器讀數(shù)服從正態(tài)分布,如事件沒有發(fā)生,檢測(cè)讀數(shù)di仍然服從正態(tài)分布 φ ( di),這樣, φ ( di)的期望值其中是向樹節(jié)點(diǎn)發(fā)送報(bào)告的平均數(shù)。
定理2 當(dāng)事件發(fā)生時(shí),存在τ1≥0,有|di-E(di)|≥τ1,且隨著τ1的增加,事件發(fā)生的概率也增加。
證明 根據(jù)正態(tài)分布,當(dāng)|ri- E (ri)|=0時(shí),事件ri發(fā)生的概率很低,當(dāng)φ(i)遠(yuǎn)離E(ri)時(shí)ri發(fā)生的概率很高。有 ns個(gè)傳感器時(shí),有這樣,當(dāng)τ1= 0時(shí),事件發(fā)生的概率最低,且隨τ1的增加而增加。
從理論上說,通過概率分布函數(shù)(φ(i)或φ( di)),可以計(jì)算期望值。然而,在現(xiàn)實(shí)世界中,一個(gè)傳感器事先獲知參數(shù)φ(i)或φ( di)是不現(xiàn)實(shí)的。當(dāng)沒有事件發(fā)生時(shí),讀數(shù)di在一定范圍之內(nèi)是隨機(jī)分布的。所以,di可以從隨機(jī)選擇事例的讀數(shù)中抽樣。從抽樣讀數(shù)集合中計(jì)算漸進(jìn)的 E(di),E(di) =(d1+d2+…+dn)/N,其中N是歷史數(shù)據(jù)樣本的大小。這樣,將錯(cuò)誤讀數(shù)的條件1)也可改為 |σ (i, t) - E (di)|>τ2,在條件2),用di替換σ(i, t)。通過比較當(dāng)前讀數(shù)di與期望數(shù)據(jù) E(di)檢測(cè)事件的發(fā)生。注意到,在|di-E(di)|>τ1且τ1>0的情況下,即使沒有事件發(fā)生,| di- E (di)|> τ1也可以被滿足,但不能說明某事件已經(jīng)發(fā)生。然而,如定理2所述,如果增加τ1的值,以該值為閾值,事件發(fā)生的概率增加到接近100%。
3.2 單事件檢測(cè)
當(dāng)一個(gè)葉節(jié)點(diǎn)從它周圍的 NT節(jié)點(diǎn)接收讀數(shù)時(shí),依賴于thτ是否超界來計(jì)算事件的多元回歸方程fevent或正常現(xiàn)象的多元回歸方程f。當(dāng)一個(gè)父節(jié)點(diǎn)從它的孩子節(jié)點(diǎn)處接收讀數(shù)時(shí),同時(shí)也從它自己的NT節(jié)點(diǎn)周圍采集數(shù)據(jù)并確定在它的區(qū)域范圍內(nèi)是否有事件發(fā)生。多項(xiàng)式可以是fevent或f,取決于父節(jié)點(diǎn)是否位于該事件區(qū)域,如果父節(jié)點(diǎn)同它的孩子節(jié)點(diǎn)位于同一區(qū)域,那么它將更新孩子節(jié)點(diǎn)的數(shù)據(jù),并用它自己的接收數(shù)據(jù)計(jì)算一個(gè)新的多項(xiàng)式;如果父節(jié)點(diǎn)和相應(yīng)的孩子節(jié)點(diǎn)處于不同的事件區(qū)域,那么孩子節(jié)點(diǎn)的數(shù)據(jù)不改變。這個(gè)過程一直繼續(xù),直到根節(jié)點(diǎn)接收到2個(gè)多項(xiàng)式和相對(duì)應(yīng)的范圍信息。按照從孩子節(jié)點(diǎn)接收的fevent和相對(duì)應(yīng)的范圍,根節(jié)點(diǎn)就可以根據(jù)事件位置信息估計(jì)事件的邊界及Pevent的覆蓋范圍。
圖1顯示了通過融合樹 AT檢測(cè) Pevent的一部分,Pevent發(fā)生在Revent的內(nèi)部,在R的一個(gè)角落,父節(jié)點(diǎn)A和它的2個(gè)孩子節(jié)點(diǎn)B與C所在子樹位于Revent事件區(qū)域內(nèi),此時(shí),B和C從NT節(jié)點(diǎn)那里接收到的讀數(shù)其偏差遠(yuǎn)大于τth(即|di- E ( di)|> τth)。另外,B的孩子節(jié)點(diǎn)也在Revent中。因此,B節(jié)點(diǎn)從它的2個(gè)孩子節(jié)點(diǎn)處接收到了回歸方程的系數(shù)。因?yàn)锽節(jié)點(diǎn)本身也從最近的NT節(jié)點(diǎn)接收到了偏差遠(yuǎn)大于邊界的數(shù)據(jù),所以它產(chǎn)生了一個(gè)自己的報(bào)告和更新數(shù)據(jù)后的新fevent,然后把新的fevent和相應(yīng)的范圍值傳給它的父節(jié)點(diǎn)A。在父節(jié)點(diǎn)為C的子樹中,其中一個(gè)孩子D在Revent中,而另一個(gè)孩子E卻在R中。C接收多項(xiàng)式 fevent(從節(jié)點(diǎn) D)、f(從節(jié)點(diǎn) E)及相應(yīng)的坐標(biāo)范圍{xdmin,ydmin,xdmax,ydmax}和{xemin,yemin,xemax,yemax}。通過觀察由它本身和它的2個(gè)孩子傳送數(shù)據(jù)的近似區(qū)域,C得出這樣一個(gè)結(jié)論:D和它位于同一個(gè)區(qū)域內(nèi)。因此,D節(jié)點(diǎn)更新數(shù)據(jù)再結(jié)合它自己的檢測(cè)數(shù)據(jù)產(chǎn)生一個(gè)新的fevent,然后C把fevent及D的坐標(biāo)范圍、未變化的f及E的坐標(biāo)范圍傳送給A。這樣當(dāng)它沿著AT映射到Revent中包含多個(gè)樹節(jié)點(diǎn)的區(qū)域時(shí),這些范圍不斷被更新。當(dāng)根節(jié)點(diǎn)接收一個(gè)子節(jié)點(diǎn)處的范圍和fevent,根據(jù)事件Pevent和它的域范圍得到一個(gè)估計(jì)值。
3.3 多事件檢測(cè)
相對(duì)單事件而言,多事件發(fā)生時(shí)樹節(jié)點(diǎn)之間交換的數(shù)據(jù)分組、計(jì)算復(fù)雜性都將提高,隨著事件源的增加,每個(gè)事件影響程度卻會(huì)減小[17]。考慮到這種現(xiàn)象,本文設(shè)計(jì)的檢測(cè)方法其基本思路如下:當(dāng)數(shù)據(jù)分組被傳輸?shù)綐涔?jié)點(diǎn)時(shí),如果其中一個(gè)子節(jié)點(diǎn)有與父節(jié)點(diǎn)相同或相近的數(shù)據(jù)集,則結(jié)合2個(gè)數(shù)據(jù)集形成一個(gè)新的多項(xiàng)式;如果沒有子節(jié)點(diǎn)同父節(jié)點(diǎn)相同的數(shù)據(jù)集,則通過數(shù)據(jù)變換以及范圍變換來構(gòu)建融合樹;如果2個(gè)子節(jié)點(diǎn)數(shù)值接近,則合并它們的檢測(cè)范圍得到一個(gè)更大的區(qū)域。
設(shè)在某矩形區(qū)域里,存在2個(gè)異常事件和一種正常現(xiàn)象。如圖5所示,在區(qū)域R里發(fā)生了2個(gè)事件 Pevent1和Pevent2。B檢測(cè)事件Pevent2,而它的孩子節(jié)點(diǎn)C和D分別檢測(cè)Pevent1和一種正常現(xiàn)象,在這種情況下,C和D把它們各自的多項(xiàng)式與坐標(biāo)范圍{xcmin,ycmin,ycmax}以及{xdmin,ydmin,xdmax,ydmax}一起傳輸?shù)紹。B計(jì)算2個(gè)節(jié)點(diǎn)接收數(shù)據(jù)的最小值和最大值,得到它們的數(shù)據(jù)范圍。B將Scmax,Scmin,(Scmin,Scmax分別表示最小和最大的事件屬性值)C的坐標(biāo)范圍以及 Sdmin,Sdmax,D的坐標(biāo)范圍一起變換到 A。如果使用單一事件檢測(cè)方法,則需要6個(gè)數(shù)據(jù)分組,其中3個(gè)與3個(gè)多項(xiàng)式相對(duì)應(yīng),另外3個(gè)與3個(gè)區(qū)域范圍對(duì)應(yīng)。此外,A的其他孩子節(jié)點(diǎn)G和D的讀數(shù)比較接近,所以,A把它們的范圍結(jié)合在一起,感知同一個(gè)事件Pevent2。然后,A創(chuàng)建新的多項(xiàng)式,將它的系數(shù)、區(qū)域范圍和事件屬性的最大最小值傳輸?shù)剿母腹?jié)點(diǎn)H,M的估計(jì)值同A發(fā)送的也一樣,結(jié)合N產(chǎn)生的數(shù)據(jù)之后,發(fā)送它的系數(shù)到根。由于H和I在R內(nèi),H沒有修改Pevent2事件的區(qū)域范圍且不加修改地傳送到根,由此確定了事件區(qū)域及其邊界。這樣,事件Pevent1和Pevent2都通過有限的計(jì)算檢測(cè)到了,且每棵樹僅執(zhí)行了一次多項(xiàng)式回歸。
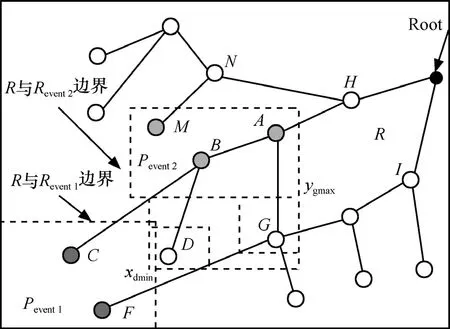
圖5 2個(gè)事件發(fā)生的檢測(cè)
3.4 故障節(jié)點(diǎn)檢測(cè)及錯(cuò)誤讀數(shù)的控制
前面討論了基于融合樹方法完成事件區(qū)域檢測(cè)過程。但是,這個(gè)過程忽略了某些隱藏在事件區(qū)域內(nèi)的故障傳感器產(chǎn)生的錯(cuò)誤讀數(shù)。由于傳感器的讀數(shù)在計(jì)算最后的多項(xiàng)式fevent時(shí)被樹節(jié)點(diǎn)結(jié)合成一體并代表事件的特征,錯(cuò)誤讀數(shù)必定影響這個(gè)結(jié)果的準(zhǔn)確性。這一部分,分析在網(wǎng)絡(luò)模型里如何檢測(cè)故障傳感器節(jié)點(diǎn)。
由融合樹的構(gòu)造過程可以看出,R中的AT分布廣泛,以至于從網(wǎng)絡(luò)的所有角落都能夠接收數(shù)據(jù),這樣可確保更好的空間逼近,因?yàn)闃渲械拿總€(gè)節(jié)點(diǎn)選擇2個(gè)離它最遠(yuǎn)的節(jié)點(diǎn)作為孩子,對(duì)密度較大的網(wǎng)絡(luò)而言,如果NT節(jié)點(diǎn)是有故障的,將向最近的樹節(jié)點(diǎn)報(bào)告錯(cuò)誤讀數(shù)。從文獻(xiàn)[6]獲知,除非傳感器位于事件的邊界,否則節(jié)點(diǎn)k的鄰居節(jié)點(diǎn)的讀數(shù)與節(jié)點(diǎn)k的讀數(shù)近似。圖6描述了故障傳感器的檢測(cè)過程,圓形表示節(jié)點(diǎn)的傳感區(qū)域,此方法可以被擴(kuò)展到檢測(cè)多個(gè)故障點(diǎn)。
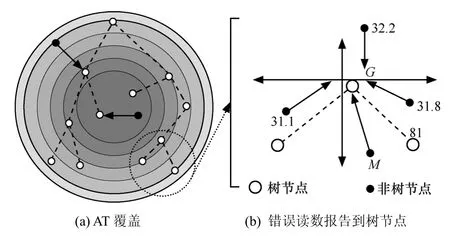
圖6 故障節(jié)點(diǎn)的檢測(cè)與報(bào)告
設(shè)M是有故障的NT節(jié)點(diǎn),將讀數(shù)傳輸?shù)诫x它最近的樹節(jié)點(diǎn)G,如圖6(b)所示。M四周的傳感節(jié)點(diǎn)正在傳送正確的溫度,節(jié)點(diǎn)M的異常讀數(shù)81,此時(shí)|σ(i, t) - E(di)|>τth。由于M 4個(gè)方向的鄰節(jié)點(diǎn)傳送正確的可接受的讀數(shù)(除了M),因此M被看成是有故障的節(jié)點(diǎn)。如果M在接下來的幾次連續(xù)報(bào)告讀數(shù),滿足|σ(i, t) - E(di)|>τth時(shí),它將被禁止傳輸數(shù)據(jù)。因此,為了預(yù)防錯(cuò)誤數(shù)據(jù)影響最終多項(xiàng)式構(gòu)建,M發(fā)出的讀數(shù)將在檢測(cè)進(jìn)程中被剔除。
需要說明的是,樹節(jié)點(diǎn)本身不能做出正確的判定,判定是通過每一個(gè)樹節(jié)點(diǎn)傳播它的位置(x, y)及其函數(shù)值f(x,y)到AT中的其他節(jié)點(diǎn)經(jīng)計(jì)算形成的。為保證傳輸信息量可控,按以下步驟交換故障 NT節(jié)點(diǎn)信息。
1) 從Sink開始,以Sink為中心,fevent被發(fā)送到所有的樹節(jié)點(diǎn),最壞情況下需要(nt-1)次的數(shù)據(jù)分組傳送。
2) 對(duì)當(dāng)前的樹節(jié)點(diǎn)j,接收M發(fā)送的數(shù)據(jù)并且驗(yàn)證M是否是故障節(jié)點(diǎn),正向路徑轉(zhuǎn)發(fā)(x, y)和f(x,y)到所有j在樹中的鄰節(jié)點(diǎn)。
3) 當(dāng)收到這樣一個(gè)數(shù)據(jù)分組時(shí),節(jié)點(diǎn)i首先轉(zhuǎn)發(fā)該數(shù)據(jù)分組到它的鄰節(jié)點(diǎn),發(fā)送分組的節(jié)點(diǎn)除外。接著,節(jié)點(diǎn)i更新M在4個(gè)方向上的鄰節(jié)點(diǎn)位置,并且使用它們的多項(xiàng)式重新生成在這些位置上的數(shù)據(jù)值。使用這些數(shù)據(jù)值,通過檢查是否滿足判定錯(cuò)誤讀數(shù)的3個(gè)條件之一,i作出M是有故障的還是正常的判斷。當(dāng)M落在2個(gè)事件區(qū)域邊界時(shí),存在2種不同的讀數(shù),雖然正常但還是被拒絕。
4) 相對(duì)以前的正向路徑,以反方向通過節(jié)點(diǎn)i傳播M是故障節(jié)點(diǎn)或是正常節(jié)點(diǎn)的消息。每一個(gè)節(jié)點(diǎn)接收到M的消息后,作為主要依據(jù)更新自身的判定。然后,它再一次以反方向轉(zhuǎn)發(fā)它的判定,最后,節(jié)點(diǎn)j作出拒絕或接受M節(jié)點(diǎn)讀數(shù)的決定。
如圖1所示,一個(gè)故障NT節(jié)點(diǎn)M發(fā)送它的讀數(shù)到它最鄰近的節(jié)點(diǎn)N,N認(rèn)為M是有故障的,則發(fā)送它的位置和讀數(shù)f(x,y)到它所有的鄰居節(jié)點(diǎn)。每一個(gè)鄰居節(jié)點(diǎn)收到消息后,產(chǎn)生一些與M近似的位置信息,同時(shí)通過它的多項(xiàng)式產(chǎn)生在這些位置的讀數(shù)。然后,把M的f(x,y)值與這些新產(chǎn)生的值比較,檢查是否滿足傳感器故障判定條件。接下來,它向在相反路徑中的所有節(jié)點(diǎn)廣播它的檢測(cè)報(bào)告,每一個(gè)樹節(jié)點(diǎn)接收它的鄰居節(jié)點(diǎn)發(fā)送的讀數(shù),在收到大多數(shù)判定的基礎(chǔ)上,M被歸類為有故障的還是正常的。最后,在大多數(shù)來自鄰接樹節(jié)點(diǎn)讀數(shù)的基礎(chǔ)上,N作出關(guān)于M為故障節(jié)點(diǎn)的正確判定。
4 影響性能的因素
1) 構(gòu)建AT的影響。
當(dāng)增加融合樹AT的深度時(shí),執(zhí)行回歸次數(shù)增加,多項(xiàng)式可能偏離原始數(shù)據(jù)更多。為了避免這些影響,AT的孩子節(jié)點(diǎn)數(shù)量可進(jìn)一步增加,而不增加樹的深度,使得AT度高而深度小。然而,由于孩子節(jié)點(diǎn)數(shù)量的增加也使每個(gè)父節(jié)點(diǎn)的計(jì)算時(shí)間增加,因此,事件檢測(cè)應(yīng)該在AT的基礎(chǔ)上進(jìn)行,這樣可在精確度和計(jì)算延遲之間達(dá)到平衡。由于每個(gè)樹節(jié)點(diǎn)融合了傳感器的讀數(shù),計(jì)算開銷是O(n/nt),這里,nt是樹節(jié)點(diǎn)的數(shù)量,如果nt與n同步增長(zhǎng),計(jì)算的開銷就可以保持不變[17~19]。
2) 多項(xiàng)式次數(shù)的影響。
多項(xiàng)式的次數(shù)對(duì)獲得的事件的邊界和區(qū)域信息有一定的影響。在某區(qū)域內(nèi),如果大量的傳感器(?20)向單一樹節(jié)點(diǎn)發(fā)送報(bào)告,就需要一個(gè)三次多項(xiàng)式來提高事件邊界的精確度。三次多項(xiàng)式將會(huì)有27個(gè)系數(shù)。具有27個(gè)系數(shù)的三次多項(xiàng)式與二次多項(xiàng)式的9個(gè)系數(shù)比較[18],增大了樹節(jié)點(diǎn)向其父節(jié)點(diǎn)發(fā)送的數(shù)據(jù)分組的大小。然而,與大量的傳感器讀數(shù)相比較,27個(gè)系數(shù)是非常少的,因?yàn)閭鞲衅髯x數(shù)都被融合到若干系數(shù)中了。
3) 故障傳感器的影響。
在第4節(jié)用τ2表示故障傳感器檢測(cè)的閾值。如果錯(cuò)誤的讀數(shù)沒有使|di-E(di)|超過τ2的定義值,樹節(jié)點(diǎn)就不會(huì)報(bào)告任何錯(cuò)誤讀數(shù),隱藏了故障傳感器的存在,將影響事件檢測(cè)的準(zhǔn)確性。
4)τth的影響。
在事件區(qū)域檢測(cè)中,為事件檢測(cè)尋找一個(gè)合適的閾值是重要的。根據(jù)定理2,即使沒有事件發(fā)生,τth較小會(huì)導(dǎo)致頻繁的發(fā)送事件報(bào)告。相反,τth較大可能忽略事件的發(fā)生。在設(shè)置τth時(shí)應(yīng)該考慮2個(gè)因素,一是正態(tài)分布密度函數(shù) φ ( di),一是樹節(jié)點(diǎn)樣本的大小nt。如第3節(jié)所述,σ(i, t)的最大和最小分別為Cmax和Cmin,樹節(jié)點(diǎn)從它周圍的傳感器收集數(shù)據(jù)時(shí),di的最大值和最小值分別用 Cm′in和Cm′ax表示,沒有事件發(fā)生時(shí),依照φ ( di),di在限定范圍內(nèi)服從正態(tài)分布,有 E(di)- Cm′in= Cm′ax-E(di)。設(shè)τth=E(di)-Cm′in。對(duì)任何給定的di,如果di>τth,并且在nt個(gè)傳感器之中至少有一個(gè)傳感器是在邊界范圍之外,排除了故障傳感器,可以說事件發(fā)生了。
5 仿真實(shí)驗(yàn)與討論
本文采用離散事件仿真平臺(tái) NS2進(jìn)行模擬實(shí)驗(yàn),通信接入采用CSMA/CA協(xié)議,選擇溫度屬性評(píng)估所提出方案的有效性,表1定義了所使用的參變量。設(shè)區(qū)域 A中節(jié)點(diǎn)總數(shù)為 D,則節(jié)點(diǎn)密度ρ=D/A,As是包含單一融合樹Tc的子區(qū)域,因此在子區(qū)域里節(jié)點(diǎn)的平均數(shù)U由As確定,對(duì)于二叉樹,節(jié)點(diǎn)總數(shù)為 t = 2(p+1)- 1 。
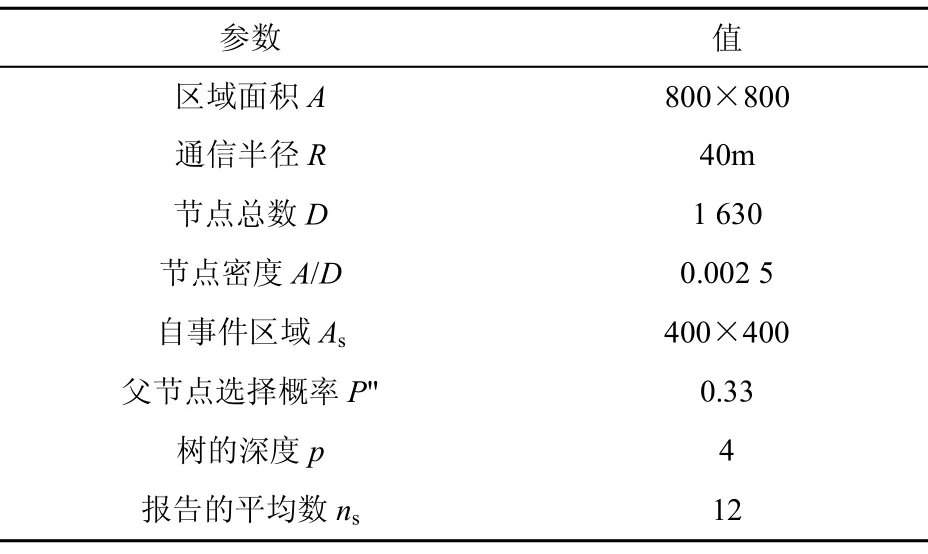
表1 仿真實(shí)驗(yàn)參數(shù)設(shè)置
此外,ns由前面設(shè)定,即感知節(jié)點(diǎn)向樹節(jié)點(diǎn)報(bào)告的平均數(shù),子區(qū)域里節(jié)點(diǎn)數(shù)U的上界為[15]
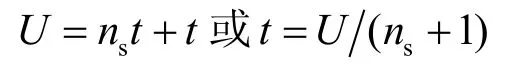
利用式(1)替換t,得AT深度的一個(gè)最優(yōu)解:
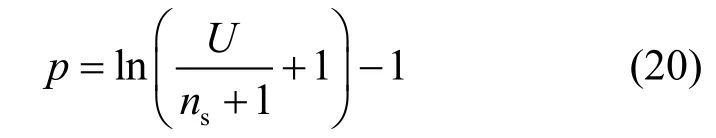
設(shè) D=1 630,A=800×800。有 ρ =1630/8002=0.0025,As= 4 00 × 4 00,則該區(qū)域內(nèi)節(jié)點(diǎn)平均數(shù)為:U=0.002 469×400+400=408。設(shè)樹的深度p=4,則節(jié)點(diǎn)數(shù) Tc=t=2(4+1)-1=31,ns=12。此區(qū)域傳感節(jié)點(diǎn)總數(shù)=31×12=372。事實(shí)上,該區(qū)域內(nèi)的節(jié)點(diǎn)總數(shù) U=31+372=403<408。因此,上面所定義的參數(shù)是有效的。
5.1 性能評(píng)估測(cè)度
在800×800平方單元區(qū)域R內(nèi),隨機(jī)部署250個(gè)節(jié)點(diǎn),溫度變化 30℃~35℃是正常現(xiàn)象,溫度變化在 39℃~49℃時(shí)為異常,可能是該區(qū)域發(fā)生了火災(zāi)。樹的深度設(shè)置為 4。在無(wú)事件發(fā)生時(shí),檢測(cè)的溫度值服從正態(tài)分布φ(i)。Cmin、Cmax和E(i)分別為30、35和32.5,φ(i)的變化是1.2。單個(gè)事件Pevernt1在中心發(fā)生,事件區(qū)域稱為Revent,E(di)- Cmin= Cmax-E(di)=2.5,τ1為2.5,E(σ( i, t) ) - Cmin= Cmax-E(σ(i,t))=2.5且τ2=τth=4.5。當(dāng)事件發(fā)生時(shí),讀取的數(shù)據(jù)通過NT節(jié)點(diǎn)傳輸?shù)阶罱臉涔?jié)點(diǎn),通過10輪實(shí)驗(yàn)評(píng)估以下性能指標(biāo)。前提是假設(shè)查詢已經(jīng)廣播到融合樹的所有葉節(jié)點(diǎn)。
1) 壓縮比(compress ratio)。2) 根節(jié)點(diǎn)輸出數(shù)據(jù)分組的大小。3) 事件邊界(event boundary):將實(shí)際事件邊界(不同的形狀)和檢測(cè)到的事件邊界進(jìn)行比較。4) 錯(cuò)誤率(percentage error):AT中根節(jié)點(diǎn)獲得的讀數(shù)與實(shí)際傳感器讀數(shù)的近似程度。由事件區(qū)域檢測(cè)的讀數(shù)與實(shí)際讀數(shù)產(chǎn)生的偏差E表示,其中εth=10%是指定的錯(cuò)誤閾值,nb是在邊界傳感器的數(shù)量,為近似讀數(shù),z為實(shí)際讀數(shù)。5) 事件識(shí)別延遲(event recognition delay):事件發(fā)生的時(shí)間與在根節(jié)點(diǎn)計(jì)算的近似時(shí)間之間的間隔。6)通信代價(jià)(communication cost):事件區(qū)域檢測(cè)傳輸數(shù)據(jù)分組的平均數(shù)。7) 故障點(diǎn)識(shí)別延遲(faulty sensor recognition delay):從故障節(jié)點(diǎn)發(fā)送讀數(shù)到錯(cuò)誤讀數(shù)在融合過程中被消除的時(shí)間,通過平均延遲和故障傳感器的百分率之比表示。8) 包負(fù)載(packet overhead):檢測(cè)到故障節(jié)點(diǎn)時(shí),樹節(jié)點(diǎn)向鄰近節(jié)點(diǎn)發(fā)送數(shù)據(jù)分組的總數(shù)。9) 讀數(shù)誤差(variance of sensor reading):通過NT節(jié)點(diǎn)集(包括故障節(jié)點(diǎn))報(bào)告的數(shù)據(jù)di與它們的平均值E(di)的差異來評(píng)估。10) 故障傳感器檢測(cè)命中率(faulty sensor detection hit ratio):設(shè)nft表示網(wǎng)絡(luò)中發(fā)送數(shù)據(jù)到樹節(jié)點(diǎn)的故障傳感器數(shù),nf表示網(wǎng)絡(luò)中故障傳感器的實(shí)際數(shù)目,檢測(cè)命中率為
5.2 仿真結(jié)果與討論
5.2.1 壓縮比
圖 7顯示了壓縮比隨著樹的深度而變化的情況,正如所期望的那樣,幾乎為常量0.02。曲線的下降說明隨著深度的增加,壓縮比減小,樹的深度越深,壓縮程度越好,而且輸出量大大減少。高壓縮比減小了整體的信息量,因而節(jié)省了通信帶寬和總的能量。
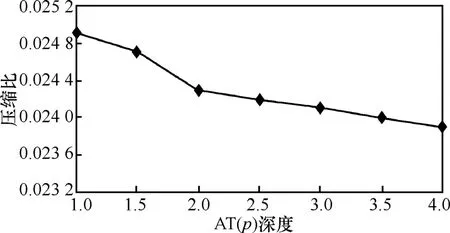
圖7 壓縮比與樹深度的關(guān)系
5.2.2 根節(jié)點(diǎn)輸出數(shù)據(jù)分組的大小
圖8顯示了在根節(jié)點(diǎn)處通過SPAT算法進(jìn)行數(shù)據(jù)融合之后的數(shù)據(jù)通信量以及根節(jié)點(diǎn)收到未融合數(shù)據(jù)而進(jìn)行正常的一對(duì)多通信的情況。盡管樹的深度不同,但當(dāng)融合樹中所有節(jié)點(diǎn)執(zhí)行數(shù)據(jù)壓縮時(shí),數(shù)據(jù)分組通過根節(jié)點(diǎn)傳送到 Sink的大小是恒定不變的,即固定(wx+wy+wc)個(gè)字節(jié)。從一個(gè)樹節(jié)點(diǎn)到另一個(gè)樹節(jié)點(diǎn)所傳送的數(shù)據(jù)分組大小幾乎是恒定的,且與網(wǎng)絡(luò)規(guī)模的大小無(wú)關(guān),使得數(shù)據(jù)傳輸?shù)目偰芰烤S持在合理的范圍。這印證了上面的假設(shè),即每個(gè)樹節(jié)點(diǎn)傳送的數(shù)據(jù)分組僅包含系數(shù)和x-y坐標(biāo)值到它的父節(jié)點(diǎn),數(shù)據(jù)分組的大小獨(dú)立于樹中節(jié)點(diǎn)的數(shù)目。而傳統(tǒng)的多對(duì)一通信,所有的葉子節(jié)點(diǎn)都要向根節(jié)點(diǎn)發(fā)送數(shù)據(jù),所以,當(dāng)網(wǎng)絡(luò)節(jié)點(diǎn)增加時(shí),通過根節(jié)點(diǎn)傳送的數(shù)據(jù)分組大小的增長(zhǎng)不受限制。通過本算法執(zhí)行數(shù)據(jù)壓縮時(shí),與文獻(xiàn)[8]相比較,最大數(shù)據(jù)通信量減少85%。
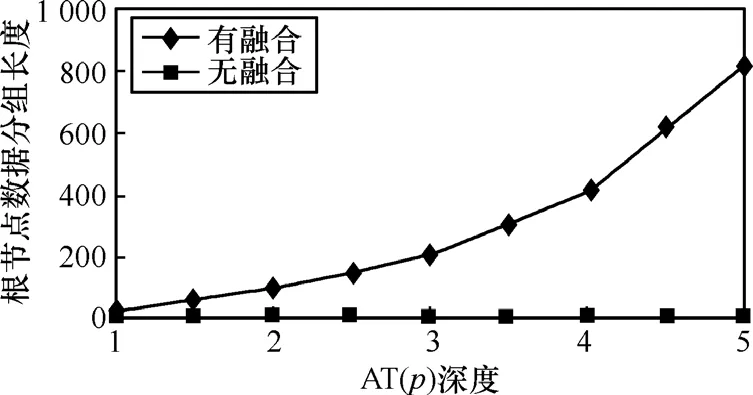
圖8 數(shù)據(jù)融合與未融合的通信量對(duì)比
5.2.3 邊界檢測(cè)
當(dāng)具有不同邊界的多事件同時(shí)發(fā)生時(shí),為了討論基于融合樹的事件區(qū)域檢測(cè)性能,在R的角落里5℃~10℃變化范圍內(nèi)引入第二個(gè)事件 Pevent2,圖 9所示。邊界檢測(cè)由虛邊矩形描述,圖中的黑色小圓點(diǎn)表示融合樹的樹節(jié)點(diǎn)。實(shí)驗(yàn)結(jié)果表明,Pevent1與Pevent2的錯(cuò)誤率分別為7.8%和8.5%。可以看出,通過檢測(cè)計(jì)算的事件區(qū)域(即虛邊矩形)與實(shí)際事件區(qū)域(即粗邊矩形和粗邊橢圓)是匹配的,這證實(shí)ATERD是有效的。然而,由于ATERD得出的事件區(qū)域總是一個(gè)矩形(由于事件區(qū)域是利用無(wú)數(shù)個(gè)小矩形迭代構(gòu)建而成),若事件自身就是矩形的,其近似效果要比利用其他形狀(如橢圓)更接近原型。
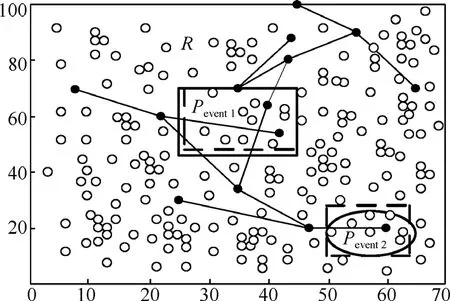
圖9 ATERD檢測(cè)的事件邊界
5.2.4 錯(cuò)誤率
圖 10顯示了融合樹的深度與錯(cuò)誤率的關(guān)系。可以看出,隨著融合樹深度的增加,樹節(jié)點(diǎn)覆蓋的范圍會(huì)更大,從而使得整個(gè)區(qū)域能被更好地感知檢測(cè),同時(shí)近似數(shù)據(jù)的平均誤差及錯(cuò)誤率也穩(wěn)步下降,這正是所期望的。樹深度為1時(shí),錯(cuò)誤率達(dá)到最大值,是由于這棵樹僅有3個(gè)節(jié)點(diǎn)(區(qū)域內(nèi)的大多數(shù)傳感節(jié)點(diǎn)被分散,不在樹節(jié)點(diǎn)的感知范圍內(nèi),因此無(wú)法向AT傳送)檢測(cè)該區(qū)域范圍。圖11顯示樹的深度為4時(shí),錯(cuò)誤率漸進(jìn)增大達(dá)到最大值5.64。選取381個(gè)讀數(shù),發(fā)現(xiàn)最初部分集中了接近估值的最大數(shù)目點(diǎn)。當(dāng)樹的深度為4時(shí),錯(cuò)誤率最大值為5.64%,大部分節(jié)點(diǎn)都有它們各自的誤差但限于一個(gè)較小的范圍0%~1.68%。
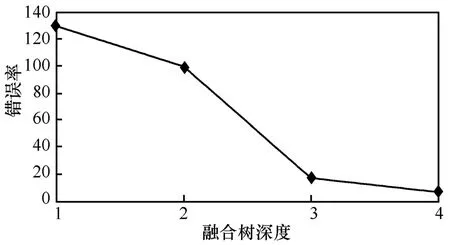
圖10 錯(cuò)誤率與樹深度的關(guān)系
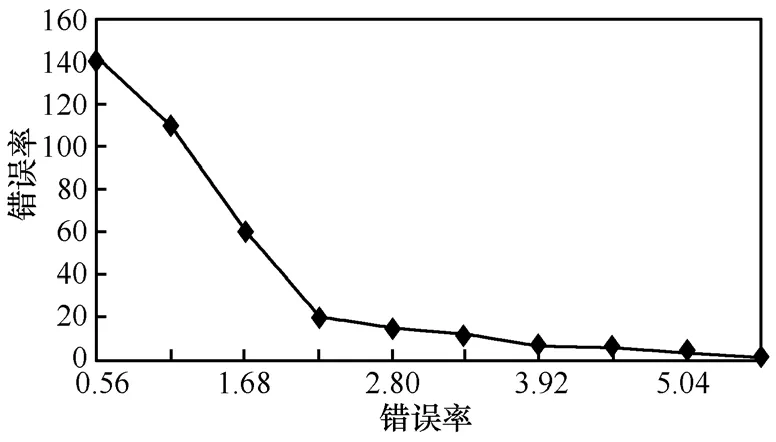
圖11 樹的深度為4時(shí)的錯(cuò)誤率
當(dāng)通信范圍變化時(shí),對(duì)ATERD完成事件檢測(cè)的準(zhǔn)確性進(jìn)行分析,如圖12所示,兩事件ATERD的誤差率不足10%,采用多事件ATERD進(jìn)行事件檢測(cè)(誤差范圍為6.8~8.9)比單ATERD 進(jìn)行事件檢測(cè)(誤差范圍為 6.4~7.6)高出 6%,單事件檢測(cè)出現(xiàn)較小的誤差范圍,是由于近似邊界可以通過最后生成的fevent較好定位,而在多事件ATERD方法中是無(wú)法實(shí)現(xiàn)的。由圖 12可以看出,被檢測(cè)事件的錯(cuò)誤級(jí)別隨通信范圍的增長(zhǎng)呈不顯著變化,而文獻(xiàn)[11]中,隨著通信范圍的增加,在區(qū)域Reven里有更多的傳感器讀數(shù)被傳送到樹,錯(cuò)誤級(jí)別卻隨通信范圍的增長(zhǎng)急劇增加,在ATERD中,不同的讀數(shù)與不同的事件相對(duì)應(yīng),樹節(jié)點(diǎn)會(huì)生成不同的多項(xiàng)式,總體誤差率是獨(dú)立于各個(gè)傳感器的通信范圍的。從圖12還可以看出,隨著NT節(jié)點(diǎn)的增加,錯(cuò)誤率緩慢增加,樹節(jié)點(diǎn)、NT節(jié)點(diǎn)位于事件邊界的可能性也會(huì)增加,回歸多項(xiàng)式的準(zhǔn)確性也會(huì)增加,進(jìn)而覆蓋到相對(duì)大的范圍和提供更加準(zhǔn)確的傳感參數(shù),錯(cuò)誤率被控制在一個(gè)合適的范圍內(nèi)。
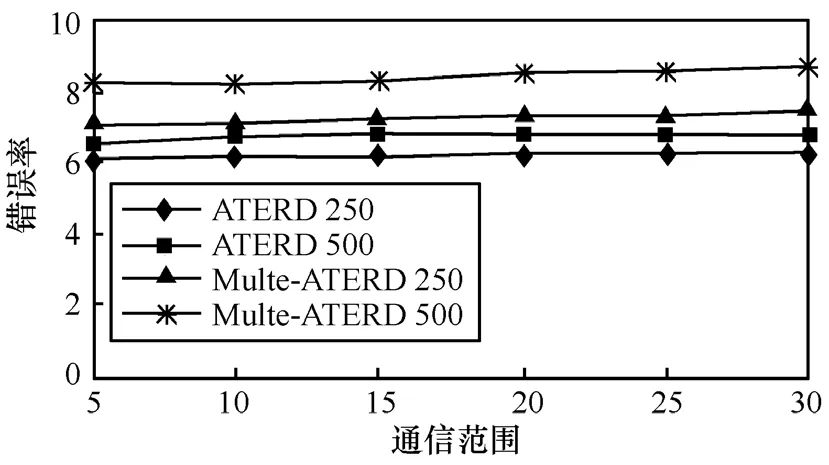
圖12 通信范圍、節(jié)點(diǎn)密度與錯(cuò)誤率的關(guān)系
5.2.5 檢測(cè)延遲
圖 13表明,事件檢測(cè)延遲隨節(jié)點(diǎn)密度的增加幾乎保持不變。導(dǎo)致事件檢測(cè)延遲的主要因素有 3個(gè)方面:事件識(shí)別延遲、多項(xiàng)式計(jì)算延遲和事件報(bào)告的傳輸延遲(稱為通信延遲)。從圖13可以看出,事件識(shí)別和多項(xiàng)式計(jì)算延遲遠(yuǎn)遠(yuǎn)小于通信延遲,通信延遲占總延遲的近77%。一旦融合樹確定,用于通信的延遲保持恒定并且獨(dú)立于NT節(jié)點(diǎn)的密度。當(dāng)節(jié)點(diǎn)密度增加,圍繞每棵樹的NT節(jié)點(diǎn)數(shù)目也隨之增加。實(shí)驗(yàn)結(jié)果表明,當(dāng)節(jié)點(diǎn)數(shù)目 nnt增加時(shí),事件識(shí)別、計(jì)算負(fù)載和多項(xiàng)式構(gòu)造也維持恒定,這是由于節(jié)點(diǎn)數(shù)目的增加對(duì) ns的影響不大。ATERD之所以能夠降低事件識(shí)別和事件報(bào)告的復(fù)雜度是由基于以下原因:首先,在ATERD中,事件識(shí)別和基于多項(xiàng)式的數(shù)據(jù)融合不含有任何復(fù)雜計(jì)算;其次,基于樹的網(wǎng)絡(luò)結(jié)構(gòu)對(duì)事件識(shí)別進(jìn)行了局部處理;再者,當(dāng)網(wǎng)絡(luò)規(guī)模增加時(shí),樹節(jié)點(diǎn)的數(shù)目也相應(yīng)增加,因此ATERD是可擴(kuò)展的。
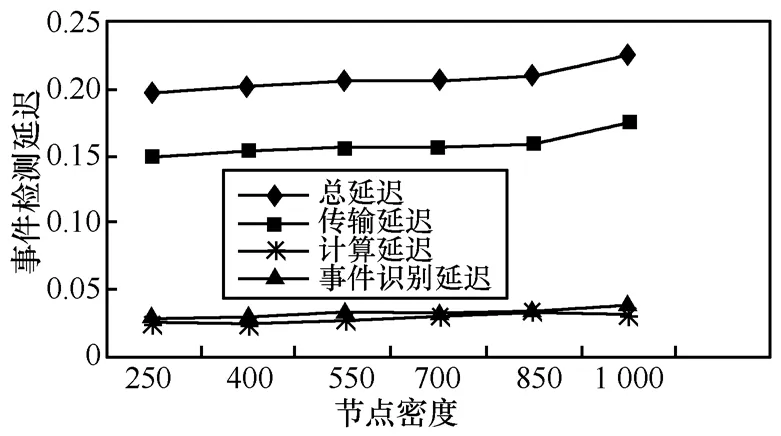
圖13 事件檢測(cè)、節(jié)點(diǎn)密度對(duì)延遲的影響
5.2.6 識(shí)別延遲
從圖 14可以看出,隨著故障傳感器所占百分比的增加,檢測(cè)時(shí)延也會(huì)緩慢增加。盡管由于密度的加大,傳遞給每個(gè)樹節(jié)點(diǎn)的NT節(jié)點(diǎn)數(shù)會(huì)增多,但是檢測(cè)故障傳感器所花費(fèi)的計(jì)算時(shí)長(zhǎng)卻是一個(gè)常量,同時(shí)增加的時(shí)延與每個(gè)樹節(jié)點(diǎn)之間傳遞數(shù)據(jù)的傳輸時(shí)延相比是可以忽略的,從下面的關(guān)系式可以明顯地看出:

其中,T表示總的時(shí)延,Ttrans表示傳輸時(shí)延,Tcalc表示計(jì)算時(shí)延。因此,故障節(jié)點(diǎn)增加所帶來的計(jì)算時(shí)延同傳輸時(shí)延相比是可以忽略的,這里的傳輸時(shí)延同NT節(jié)點(diǎn)以及樹節(jié)點(diǎn)的密度有關(guān),也與故障傳感器的數(shù)量有關(guān)。這使得隨著故障節(jié)點(diǎn)所占百分比的增加,T呈線性增加。在文獻(xiàn)[14]中,計(jì)算時(shí)延主要發(fā)生在傳感器正在移動(dòng)以及最優(yōu)線性規(guī)劃 LP的計(jì)算過程中。在文獻(xiàn)[11]中,隨著故障節(jié)點(diǎn)的增加,鄰接點(diǎn)數(shù)據(jù)計(jì)算的平均值也將成比例的增加,在文獻(xiàn)[11]和文獻(xiàn)[14]中,這種時(shí)延的增加超過50%。
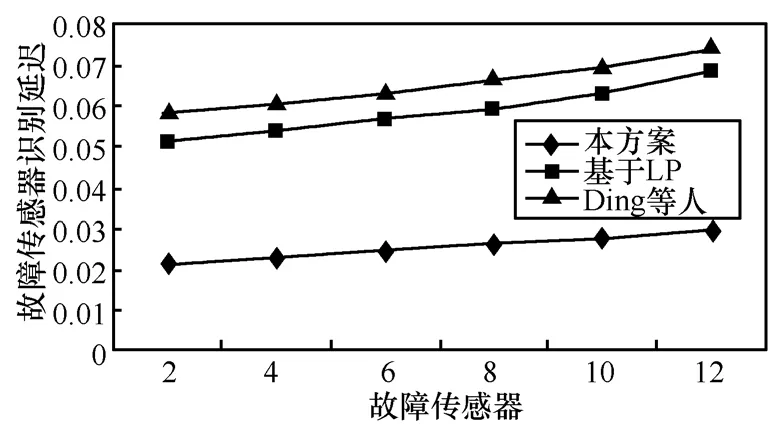
圖14 故障傳感器識(shí)別延遲
5.2.7 負(fù)載
隨著節(jié)點(diǎn)密度的變化,將本文提出的算法與文獻(xiàn)[8]的方法進(jìn)行比較,如圖15所示。可以看出,隨著節(jié)點(diǎn)密度的增加(假設(shè)故障節(jié)點(diǎn)的數(shù)目保持不變)對(duì)本文所提出的算法幾乎沒有影響,這是由于,融合樹算法識(shí)別故障傳感器節(jié)點(diǎn)數(shù)目保持不變,每個(gè)節(jié)點(diǎn)只發(fā)送故障傳感器的值(x, y, f(x, y))到其他樹節(jié)點(diǎn),與節(jié)點(diǎn)密度的增加無(wú)關(guān)。與此相反,在文獻(xiàn)[8],隨著節(jié)點(diǎn)密度的增加,每一故障傳感器的鄰接節(jié)點(diǎn)數(shù)目增加,識(shí)別故障傳感器的分組交換增多。另外,故障傳感器在源頭沒有被檢測(cè)到,并且會(huì)傳播給BS,同時(shí)還會(huì)導(dǎo)致數(shù)據(jù)負(fù)載的增加。
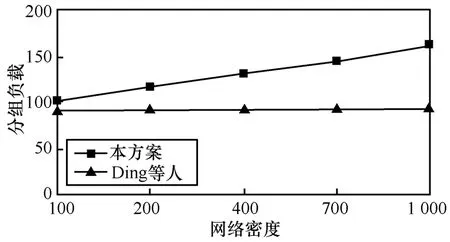
圖15 分組負(fù)載與網(wǎng)絡(luò)密度的關(guān)系
5.2.8 命中率
圖 16顯示了本文算法在檢測(cè)故障傳感器時(shí)的準(zhǔn)確性。可以看出,隨著節(jié)點(diǎn)密度的增加,命中率平穩(wěn)遞增,構(gòu)建AT的速度更快,覆蓋的范圍更大,使得大部分NT節(jié)點(diǎn)都是可達(dá)的。因此,故障傳感器數(shù)量的增加(NT節(jié)點(diǎn)中的小部分)仍然可以確保大部分NT節(jié)點(diǎn)發(fā)送數(shù)據(jù)到最鄰近的樹節(jié)點(diǎn),同時(shí)在早期就可以檢測(cè)故障節(jié)點(diǎn)。命中率可以達(dá)到94%。而文獻(xiàn)[8]的命中率只有62%。
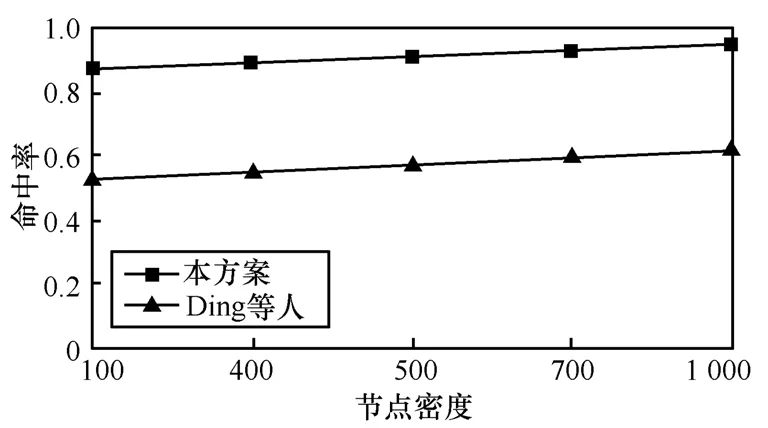
圖16 節(jié)點(diǎn)密度與命中率的關(guān)系
6 結(jié)束語(yǔ)
本文針對(duì)無(wú)線傳感器網(wǎng)絡(luò)中容錯(cuò)事件區(qū)域檢測(cè)問題,提出了一種新的分布式容錯(cuò)檢測(cè)算法.首先,構(gòu)建的融合樹,使得在缺少傳感節(jié)點(diǎn)的位置,利用被檢測(cè)事件的時(shí)空相關(guān)性,也能獲得事件檢測(cè)的屬性值,其錯(cuò)誤率控制在可接受的范圍內(nèi)。在此基礎(chǔ)上,提出一種基于融合樹的事件區(qū)域檢測(cè)容錯(cuò)算法,該算法可以對(duì)多個(gè)事件進(jìn)行檢測(cè),識(shí)別發(fā)生在邊界區(qū)域的事件和有故障的傳感器節(jié)點(diǎn),把檢測(cè)讀數(shù)傳給基站。另外,強(qiáng)調(diào)異常事件發(fā)生節(jié)點(diǎn)的重要性,使得事件區(qū)域檢測(cè)問題,以及事件區(qū)域邊界節(jié)點(diǎn)的錯(cuò)誤修正問題得到較好的改善。
[1] 李建中, 李金寶, 石勝飛.傳感器網(wǎng)絡(luò)及其數(shù)據(jù)管理的概念問題與進(jìn)展[J]. 軟件學(xué)報(bào),2003,14(10)∶ 1717-1727.LI J Z, LI J B,SHI S F. Concepts, issues and advance of sensor networks and data management of sensor networks[J].Journal of Software,2003,14(10)∶1717-1727.
[2] 曹冬磊, 曹建農(nóng), 金蓓弘.一種無(wú)線傳感器網(wǎng)絡(luò)中事件區(qū)域檢測(cè)的容錯(cuò)算法[J].計(jì)算機(jī)學(xué)報(bào),2007,30(10)∶1770-1776.CAO D L,CAO J N,JIN B H.A fault-tolerant algorithm for event region detection in wireless sensor networks[J].Journal of Computer,2007,30(10)∶1770-1776.
[3] 任豐原,黃海寧,林闖.無(wú)線傳感器網(wǎng)絡(luò)[J].軟件學(xué)報(bào),2003,14(7)∶1282-1291.REN F Y,HUANG H N,LIN C. Wireless sensor networks[J].Journal of Software, 2003,14(7)∶1282-1291.
[4] KRISHNAMACHARI B, IYENGAR S S. Distributed Bayesian algorithms for fault-tolerant event region detection in wireless sensor networks[J]. IEEE Trans on Computers, 2004,53(3)∶241-250.
[5] CHEN Q, LAM K Y, FAN P. Comments on, distributed Bayesian algorithms for fault tolerant event region detection in wireless sensor networks[J]. IEEE Transactions on Computers, 2005, 54(9)∶ 1182-1183.
[6] LUO X, DONG M, HUANG Y. On distributed fault-tolerant detection in wireless sensor networks[J]. IEEE Trans on Computers, 2006,55(1)∶58-70.
[7] KOUSHANFAR F, POTKONJAK M, SANGIOVANNI- VINCENTELLI A. On-line fault detection of sensor measurements[A]. Proc of the IEEE Sensors[C]. 2003.974-979.
[8] DING M, CHEN D, et al. Localized fault tolerant event boundary detection in sensor networks[A]. Proceedings of the Annual IEEE Conference on Computer Communications (INFOCOM)[C]. Miami,2005.902-913.
[9] KOUSHANFAR F, POTKONJAK M, SANGIOVANNI-VINCENTELLI A. Fault-Tolerance in Sensor Networks[M]. Handbook of Sensor Networks, CRC Press, 2004.
[10] REN K, ZENG K, LOU W J. Secure and fault-tolerant event boundary detection in wireless sensor networks[J]. IEEE Transactions on Wireless Communications, 2008, 7(1)∶ 354-363.
[11] CHEN J, KHER S, SOMANI A. Distributed fault detection of wireless sensor networks[A]. Proc of the 2006 Workshop on Dependability Issues in Wireless Ad Hoc Networks and Sensor Networks (DIWANS 2006)[C]. 2006.65-72.
[12] KOUSHANFAR F, POTKONJAK M, SANGIOVANNI- VINCENTELLI A. Error models for light sensors by statistical analysis of raw sensor measurements[A]. Proc of the IEEE Sensors[C]. 2004.1472-1475.
[13] NOWAK R, MITRA U. Boundary estimation in sensor networks∶theory and methods[A]. Proc of 2nd International Workshop on IPSN[C]. 2003.86-95.
[14] CHINTALAPUDI K K, GOVINDAN R. Localized edge detection in sensor fields[A]. Proc IEEE Workshop on Sensor Network Protocols and Applications[C]. Los Angeles, 2003.59-70.
[15] GUESTRIN C, BODI P, THIBAU R, et al. Distributed Regression∶ an Efficient Framework for Modeling Sensor Network Data[M]. IPSN New York, ACM Press, 2004.
[16] SHARAF A, BEAVER J, LABRINIDIS A, et al. Balancing energy efficiency and quality of aggregate data in sensor networks[J]. The VLDB Journal, 2004, 13(4)∶384-403.
[17] AURENHAMMERF, KLEIN R. Handbook of Computational Geometry[M]. Amsterdam, Netherlands∶ North-Holland, 2000.201-290.
[18] BERTHOLD M. Intelligent Data Analysis[M]. Springer Press,2nd Edition, 2007.
[19] VURAN M C, AKAN O B, AKYILDIZ I F. Spatio-temporal correlation∶ theory and application for wireless sensor networks[J]. Computer Networks, 2004,45∶245-259.
猜你喜歡
今日農(nóng)業(yè)(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
中學(xué)生數(shù)理化(高中版.高考數(shù)學(xué))(2021年1期)2021-03-19 08:28:38
現(xiàn)代出版(2020年3期)2020-06-20 07:10:34
汽車維修與保養(yǎng)(2019年7期)2020-01-06 03:30:42
汽車維護(hù)與修理(2016年10期)2016-07-10 08:17:41
中國(guó)科技博覽(2016年2期)2016-04-25 20:32:39
小學(xué)生導(dǎo)刊(2016年34期)2016-04-11 00:49:44
汽車維修與保養(yǎng)(2015年6期)2015-04-17 03:31:50
電測(cè)與儀表(2015年5期)2015-04-09 11:30:52
