分布式任務調度與副本復制集成策略研究
2010-08-06 13:15:52易侃王汝傳
通信學報 2010年9期
關鍵詞:策略
易侃,王汝傳
(1. 南京郵電大學 計算機學院,江蘇 南京 210003;2. 中國電子科技集團第28研究所 C4ISR國防科技重點實驗室,江蘇 南京 210007)
1 引言
數據網格[1]為各種數據密集型的應用提供了一個高性能、大容量、高速傳輸的并行、分布、廣域的計算平臺。在數據網格環境下, 任務根據任務調度的結果被提交給計算資源執行,而任務所需要的數據首先通過檢索元數據服務和目錄服務獲取數據副本的位置,然后通過副本選擇服務和傳輸服務獲取數據。對于數據敏感的任務,數據的傳輸時間是任務完成時間的重要組成部分,因此需要副本復制管理動態的調整副本的位置分布,使數據更接近任務所在的計算資源, 從而可以在更短的時間內訪問數據,更快地執行任務。
對于數據敏感任務的調度,已有很多將數據相關的因素結合到任務調度中的策略,可以將其分為3個階段:第1階段是在資源的選擇過程中考慮網絡的帶寬因素,如文獻[2~4],但是此時任務所需的數據規模較小,任務仍屬計算密集型;第2階段是采用數據驅動的任務調度策略,如文獻[5~7],將數據的大小和數據的位置因素考慮到資源的選擇過程中,但這些方法中的數據是固定在某個資源上的單一數據;第3個階段是集中式的任務調度和數據復制管理集成策略,在任務調度考慮網絡帶寬和副本位置的同時,通過引入集中式的副本管理機制,動態的創建數據的副本和調整副本的位置,使得任務所需要的數據更靠近它所執行的資源,如文獻[8~10]所述,但是在跨多個組織域的實際的網格系統中,集中式的任務調度和數據管理,在可操作性、可靠性和性能上都存在問題,因此有必要研究分布式的任務調度和副本復制管理策略。
為此論文首先提出了數據網格的三層邏輯視圖,并基于此視圖引出了分布式任務調度與副本復制策略集成的中間件體系結構,然后重點研究了在此分布式架構下,基于博弈論的分布式副本復制策略,最后通過仿真試驗驗證分布式在線任務調度和副本復制集成策略的有效性和優越性。
2 分布式任務調度和副本復制集成體系結構
類比于 J2EE的三層體系結構,數據網格邏輯上也可以分為3層,圖1是數據網格三層的邏輯視圖,其中,用戶層中的用戶是任務的發起者,計算資源層中的計算資源是應用邏輯的執行者,而存儲資源層中的存儲資源是應用所需數據的管理者。雖然邏輯上是分層的,但是實際上各層之間資源在物理位置上可能是重疊的,比如用戶操作的資源可能就是一個計算資源,同樣一個計算資源也可以附帶一個海量的存儲資源。

圖1 數據網格系統三層邏輯視圖
計算網格研究的范疇對應于圖1第2層,應用邏輯將會通過資源代理透明地在分布的、高性能的計算資源上執行。當應用需要海量數據時,第3層的存儲資源將會為它提供數據支持,數據的檢索、傳輸、可靠性、一致性等都由該層的數據管理功能提供。數據網格需要第2層和第3層的有機集成共同為用戶透明地提供高性能的計算和存儲資源,其中,第2層與第3層集成的關鍵是任務調度和副本復制策略的集成。
圖2給出了數據網格中分布式的任務調度和副本復制集成體系結構。用戶層有多個區域調度器(RS)接收用戶提交的任務,每個調度器負責一片自治域的任務請求。多個RS解決了集中式調度器的單點失效問題。當某個 RS的負載過重,那么可以增加新的 RS來分流任務請求,也可以將部分請求分流到其他RS,因此該體系結構有很好的擴展性。
在計算資源層,計算資源收到用戶任務請求后,本地調度器(LS)根據本地調度策略為任務分配計算單元,當有任務包含對數據的請求時,本地調度器向本地副本管理器(LRM)請求數據,LRM判斷本地存儲Cache中是否包含所需數據,如果沒有則向遠程存儲資源廣播數據請求,并根據確認請求的返回的信息估算計算資源與存儲資源之間的帶寬,最后選擇訪問帶寬最大的存儲資源獲取數據。
在存儲資源層,存儲資源接收數據請求,如果包含請求的數據則確認該請求。此外,每個存儲資源都包含有一個副本管理器(RM),副本管理器能夠根據數據的請求情況自主的運行數據副本的復制和刪除策略。
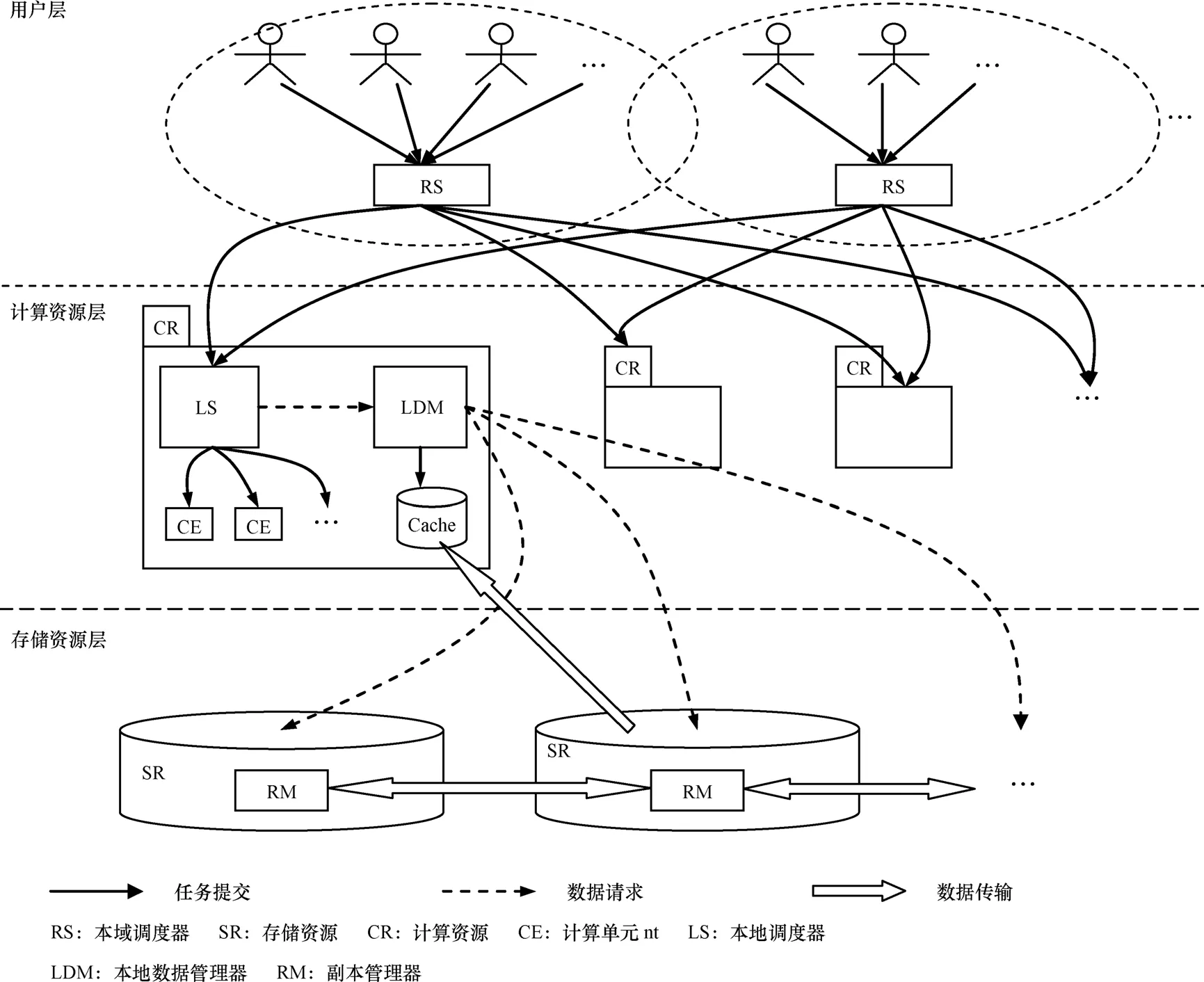
圖2 分布式的任務和副本復制集成體系結構
3 在線任務調度策略
網格中任務調度分為在線調度方式和批處理調度方式。批處理方式的任務調度算法需要較準確估計任務完成時間,但是對于數據敏感的任務,由于存儲資源的傳輸能力的不確定,網絡帶寬的不確定等因素,使得副本選擇策略運行困難,進而副本的傳輸時間難以通過啟發式的方法估計,另外,由于每個RS只負責部分區域用戶的任務請求,在單位時間內接收的任務請求比較少,因此任務調度算法采用在線調度方式[11]即可,即根據當前網格系統的性能、數據的分布情況,為每個到來的任務立刻分配資源。
數據網格中,在線調度方式的任務調度算法的目標是:將任務 ti調度到使其完成時間最短的資源上,即 ? mj∈ M , Min(Cij),其中, Cij表示任務 ti在資源 mj上的完成時間。 Cij= eij+ rj, eij代表任務ti在計算資源 mj上的執行時間, eij= c puij+ n etij,即任務的執行時間為任務所花費的 CPU時間與任務所需數據的傳輸時間之和,其中,任務 ti數據在計算資源 mj上的準備時間是任務ti所需的數據集合;在以完成時間為指標的任務調度策略中,由于網絡帶寬的不確定性,通常對數據傳輸時間的估計采用數據傳輸的平均帶寬,因此Δkj是傳輸數據 fk到計算資源 mj的平均帶寬,但如果任務所需要的數據就在計算資源 mj內,那么傳輸該數據的時間為0。而 rj代表任務在計算資源 mj上的等待時間,即該資源上等待隊列中所有任務的執行時間之和。
4 副本復制的博弈模型
每個存儲資源中的副本管理器確定在何時,對哪一個副本進行復制。對于前一個問題,由于計算資源的數據管理器廣播數據請求,因此每個存儲資源的副本管理器能夠統計固定周期內每個數據的請求次數,進而可以獲得每個數據的請求頻率,其中具有最高請求頻率的數據,被稱為熱點數據,它是被存儲資源復制的候選。當同時滿足如下2個條件時存儲資源將啟動數據復制程序:
1) 存儲資源中不存在該候選數據;
2) 候選數據請求頻率滿足某個閾值。
對于后一個問題,實際上是多個存儲資源之間競爭復制熱點數據的策略選擇問題,而博弈論[12]為解決此類非協作競爭實體的策略選擇提供了很好的思路。現以2個存儲資源 s1、 s2競爭一個熱點數據為例,給出該2人博弈的正則形式:存儲資源s1、 s2的策略空間都是{0,1},其中,1代表復制,0代表不復制。采用不同策略組合的 s1、 s2的效益顯示在圖3的括號內,依據剔除嚴格劣策略的方法可知,當 s1選擇0,而 s2選擇1時,該博弈獲得Nash均衡解。當博弈的參與者從2個存儲資源擴展為m個時,可以定義這m個存儲資源數據復制的 Nash均衡。現假設:
1) 存儲資源集合為 S = { s1, s2,… ,sm},它是博弈的參與者,每個參與者的策略空間都是{0,1},其中,1代表復制,0代表不復制;
2) 計算資源集合為 M = { m1, m2,… ,mn};
3) 數據集合為 F = { f1, f2, … , fh};
4) 數據 fk在存儲資源 si的狀態為 rik∈ { 0,1},其中,0代表不存在,1代表存在。
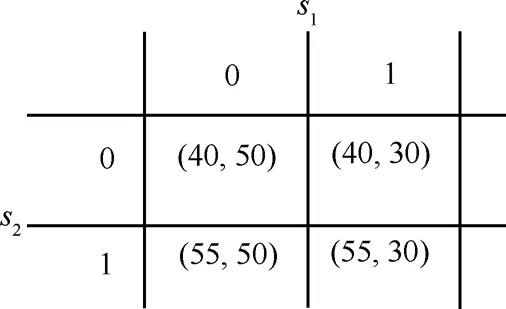
圖3 2人博弈的正則形式
定義1 數據復制的Nash均衡。
設 m個存儲資源競爭熱點數據 fk的博弈的標準式G = { s1, … , sm;u1,… ,um},如果策略組合 { r *1k,…,r *mk}滿足對每一個存儲資源 si,r *ik是它針對其他m- 1 個存儲資源所選策略 { r *1k,… ,r *i-1k,r *i+1k,… ,r *mk}的最優反應策略,則稱該策略組合{r*1k,… ,r*mk}是該博弈的一個Nash均衡解。即
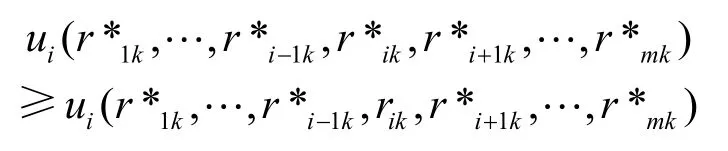
上述定義中效益函數iu并沒有確定。通常資源以獲取最大的資源利用率為目標,因此每個存儲資源都希望計算資源盡可能從它這里訪問數據。假設計算資源im從存儲資源js訪問數據kf的概率為
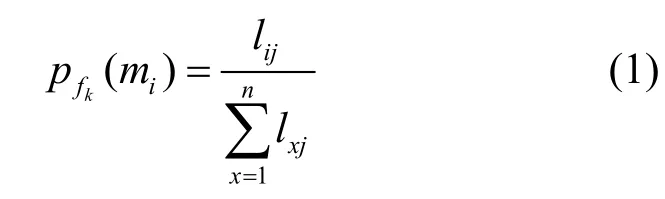
其中,lij表示計算資源mi與存儲資源sj之間的帶寬,因此從存儲資源sj訪問數據fk的平均時延為上述概率的期望:
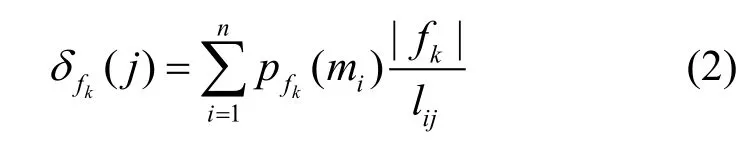
根據此定義可假設如果計算資源從某個存儲資源訪問數據 fk的時延越小,那么計算資源選擇該存儲資源訪問數據 fk的可能性越大。由于在博弈的策略選擇中,通常如果一個策略的效益越大那么該策略越好,因此取式(2)中| fk| /lij的倒數,即從存儲資源 sj訪問數據 fk的平均時延重新定義為
令Rj= { rj1, rj2,… rjk, … ,rjh}代表存儲資源 sj中副本的狀態,若 rjl= 1 ,表示數據 fl已存儲在 sj中,而 rjl= 0 表示不存在。由于存儲資源 sj的效益只與其存儲狀態 Rj相關,因此存儲資源 sj的效益函數uj定義為
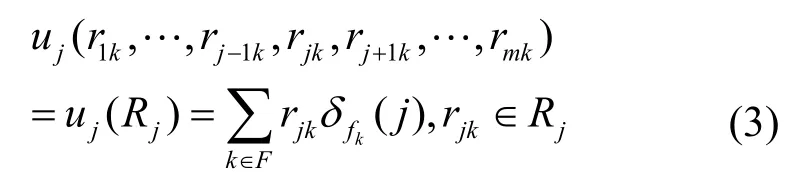
根據納什定理,若m是有限的,那么該博弈至少純在一個 Nash均衡,均衡可能包含混合策略。對于m個人,m大于2的博弈,尋找納什均衡問題不再是一個線性復雜度的問題[13]。
5 Best-Rely算法
由于每個存儲資源的空間都是有限的,因此每個存儲資源在復制熱點數據之前都必須檢查其存儲空間是否已滿。如果其存儲空間已滿,那么數據替換算法如 LRU算法將被執行以獲得足夠的存儲空間。根據式(3),顯然如果每個存儲資源的空間都是無限的,那么當它們復制所有的數據將獲得最大的效益。然而,存儲空間的有限性假設使得復制一個新的副本需要滿足:
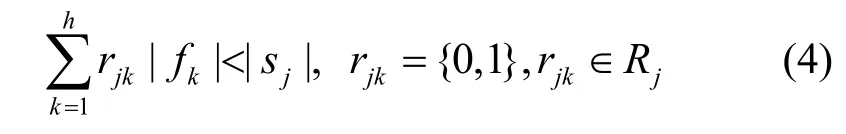
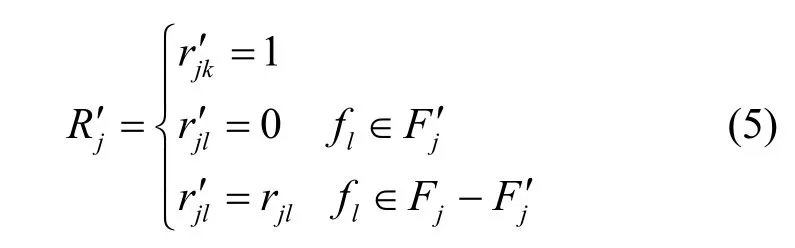
每個存儲資源在復制數據前,可以計算復制前后的存儲資源效益,如果存儲資源復制數據后的效益高于復制前的效益,那么該存儲資源就復制該數據否則不復制,稱存儲資源單方面選擇效益高的策略為最優反應(Best-Reply)策略。可以證明當每個存儲資源都采用最優反應策略,那么該策略組合是上述博弈的均衡解。
證明 對于m個存儲資源 { s1, …,si,…,sm},每個存儲資源中副本的狀態為 { R1, … ,Ri,…,Rm},假設在復制數據 fk以及刪除一些數據后,副本的狀態變為 { R1′, …,Ri′ ,…,Rm′}。由 Best-Reply算法的定義可知:
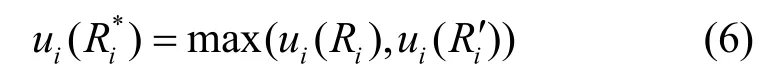
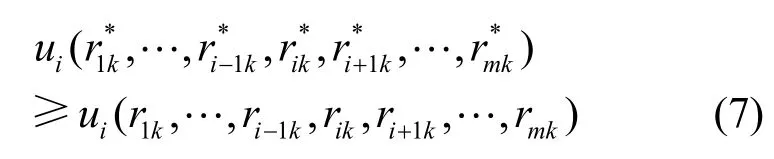
每個存儲資源的 RPM 將自動運行 Best-Reply算法以確定是否復制新的數據文件,算法描述見算法1。第2)~6)步統計所有文件的訪問頻率,并選擇訪問頻率最高的文件kf;第7)~10)步設置存儲資源的狀態 Rj;第11)步計算存儲資源當前的效益函數;第 13)~20)步假設復制文件 fk,存儲資源的狀態從Rj轉到 R'j,并計算新狀態下存儲資源的效益函數;第21)~24)步如果存儲資源復制文件 fk后能夠提升效益,那么就復制該文件,并刪除被替換的文件。算法Best-Reply描述如下。
算法1 存儲資源sj的Best-Reply算法

6 仿真實驗
6.1 仿真平臺
為驗證不同任務調度算法和副本復制集成策略的對任務執行性能的影響,擬對如下的算法組合進行仿真實驗:
1) 在線任務調度算法,但無副本復制算法,簡記為OTS;
2) 集中式任務調度和副本復制集成策略[9],簡記為OTS+CDR;
3) 分布式的在線任務調度算法與總復制(AR,always replica)副本復制集成策略,簡記為OTS+AR;
4)分布式在線任務調度算法與Best-Reply(BR)算法的集成策略,簡記為OTS+BR。
為此,設計并開發了一個基于GridSim[14]的網格任務調度仿真平臺(GJSSP, grid job scheduler simulation platform),GJSSP能夠可視化地創建、改變和保存網格仿真環境,其內建的用戶系統,任務調度系統和副本復制管理系統能夠使算法的設計人員只需關心算法設計本身。GJSSP的主界面如圖4所示,其中,圓形代表一個資源,長方形代表一個路由器,每條線代表一條鏈路。這3個組件都能夠被隨意拖動并且可以修改其屬性。在點擊“generator”按鈕后,GJSSP將產生一系列配置文件,這些配置文件將在仿真執行前被解析并創建相應的GridSim實體對象。
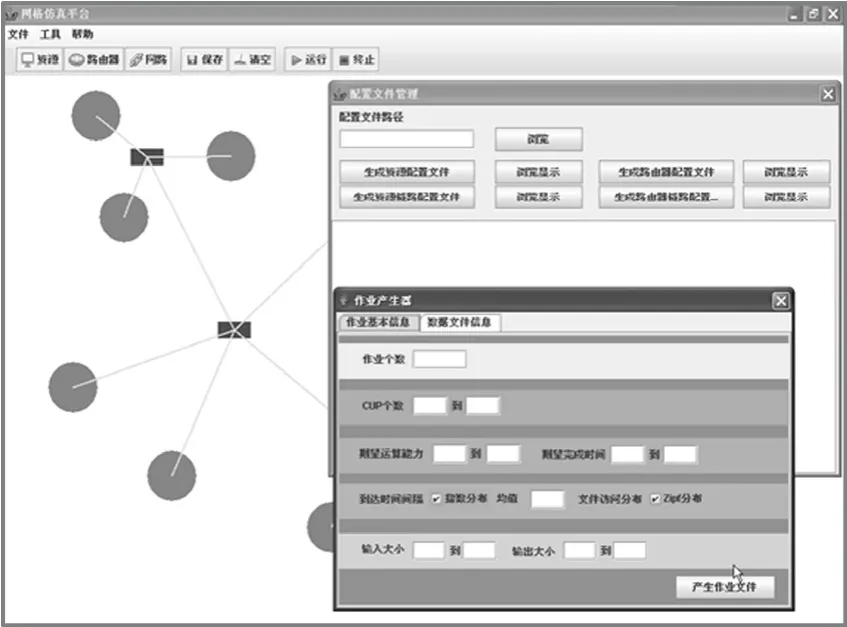
圖4 GJSSP主界面
仿真所需主要的配置文件及其屬性,如表1所示,其中,1代表只有一個配置文件,*表示可以由1個或多個配置文件,表中的作業屬性配置文件和文件屬性配置文件是通過工具自動生成,主要參數如表中所示,其他配置文件是通過GJSSP的可視化界面配置。

表1 配置文件及其屬性
6.2 仿真結果
在任務的計算量和數據量都是海量的情況下,對數據復制策略影響最大的是數據文件總量與存儲空間總量的比例。因此,擬對該比例λ為1/10和1/100的2種情況,前者存儲空間相對與數據總量較小,而后者則相對較大,在如下2個指標上進行討論:
根據圖5和圖6,由于OTS沒有采用副本的復制策略,數據總是從某些固定存儲資源獲取,需要過多的數據請求時間,因此無論存儲資源是否充裕,它的平均任務用時最多。當λ=1/100時,OTS+AR的用時最少,這主要因為計算資源所需要的數據總是被復制到離它最近的存儲資源上,在存儲空間充裕時能夠顯著的減少數據請求時間,但當λ=1/10時,總復制策略對任務的執行起到反作用,平均完成作業時間顯著增長。另外,利用OTS+BR算法的平均任務完成時間始終比利用OTS+CDR算法多,這主要是因為在仿真環境下集中式副本復制策略在估算計算資源和網絡資源的性能較為精確,因此副本位置的優化比較準確,而分布式的副本復制策略只根據有限信息優化副本位置,與全局優化策略相比效果較差。

圖5 當λ=1/10時的任務平均完成時間
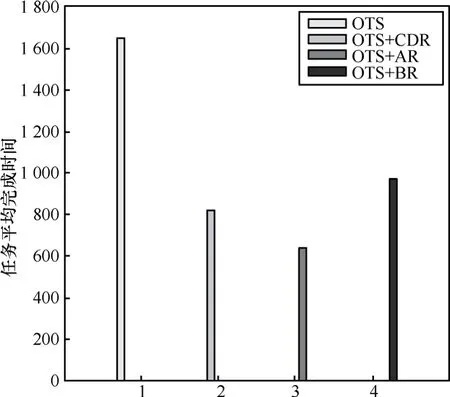
圖6 當λ=1/100時的任務平均完成時間
由于平均網絡負載越小、越穩定,那么算法越好。根據圖7,當λ=1/100時,OTS算法的平均網絡負載較高,且呈緩慢下降態勢,但是其負載仍然要優于OTS+CDR算法和OTS+BR算法。利用OTS+BR算法的平均網絡負載較低但不夠穩定。當λ=1/10時,利用 OTS算法的平均網絡負載形狀變化不大,相反利用 OTS+AR算法的平均網絡負載形狀變化很大,即 OTS+AR算法對存儲資源的空間大小較為敏感,而圖7所示利用OTS+CDR與OTS+BR算法的平均網絡負載對于存儲資源空間的大小較不敏感。因此OTS+BR算法與OTS+CDR算法相比,雖然增加了一定任務平均完成時間,但是它具有更好的擴展性,仿真結果表明它完全可以取代OTS+CDR算法。
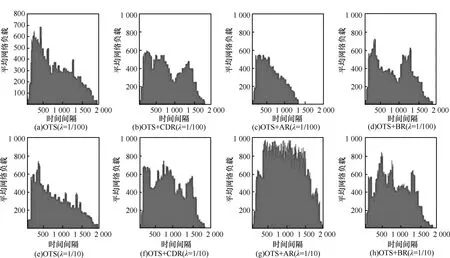
圖7 平均網絡負載比較
7 結束語
論文首先提出了3層的分布式任務調度和數據管理體系結構,在此分布式體系結構下,對在線任務調度算法和基于博弈論的副本復制的集成策略在自行研發的網格仿真平臺上進行仿真實驗,并同其他3類算法組合在平均任務完成時間和平均網絡負載2個指標上進行了比較。結果表明:1)僅僅在線任務調度算法不能滿足數據密集型任務對執行性能的要求,其平均任務完成時間最高,網絡負載不平衡;2)總復制的副本復制算法雖然在存儲空間充分時具有最少的平均任務完成時間和最低的網絡負載,但是當存儲空間較小時,上述指標均呈現明顯的增長;3)分布式的 OTS+BR算法在調度效果上比集中式的OTS+CDR稍差,但其平均網絡負載對存儲空間大小不敏感,而且算法的擴展性更好,因此完全可以替代集中式的OTS+CDR算法。
[1] SRIKUMAR V, BUYYA R, RAMAMOHANARAO K. A taxonomy of data grids for distributed data sharing, management, and processing[J].ACM Computing Surveys, 2006,38(1)∶ 3-13.
[2] BEAUMONT O, CARTER L, FERRANTE J, et al. Bandwidth-centric allocation of independent tasks on heterogeneous platforms[A]. International Parallel and Distributed Processing Symposium[C]. Marriott Marina, Fort Lauderdale, Florida, 2002. 79-88.
[3] LARS-OLOF B, HANS-ULRICH H, CESAR A. Performance issues of bandwidth reservations for grid computing[A]. 15th Symposium on Computer Architecture and High Performance Computing(SBAC-PAD'03)[C]. Sao Paulo, Brazil, 2003. 82-91.
[4] 季一木, 王汝傳. 基于粒子群的網格任務調度算法研究[J].通信學報,2007,28(10)∶ 60-67.JI Y M, WANG R C. Study on PSO algorithm in solving grid task scheduling[J]. Journal on Communications, 2007,28(10)∶ 60-67.
[5] SIVARAMAKRISHNAN N, TAHSIN K, UMIT C, et al. Database support for data-driven scientific applications in the grid[J]. Parallel Processing Letters, 2003,13(2)∶ 245 -271.
[6] LE H. CODDINGTON P, WENDELBORN A. A data-aware resource broker for data grid[J]. Lecture Notes in Computer Science, 2004,32(22)∶ 73-82.
[7] KOSAR T. A new paradigm in data intensive computing∶ stork and the data-aware schedulers[J]. Challenges of Large Applications in Distributed Environments, 2006, 25(4)∶ 5-12.
[8] NHAN N, SANG B. Combination of replication and scheduling in data grids[J]. IJCSNS International Journal of Computer Science and Network Security, 2007,7(3)∶ 304-308.
[9] CHAKRABARTI A, SHUBHASHIS S. Scalable and distributed mechanisms for integrated scheduling and replication in data grids[J].Distributed Computing and Networking, 2008,8(2)∶ 227-238.
[10] NHAN N, DANG H, LIM S. Improvement of data grid's performance by combining job scheduling with dynamic replication strategy[A].Grid and Cooperative Computing 2007(GCC 2007)[C]. Urumchi, Xinjiang, China, 2007.513-520.
[11] MAHESWARAM M, ALI S, SIEGEL H, et al. Dynamic matching and scheduling of a class of independent tasks onto heterogeneous computing systems[A]. Heterogeneous Computing Workshop(HCW99)[C].1999.30-44.
[12] 施錫銓. 博弈論[M]. 上海∶ 上海財經大學出版社, 2000.SHI X Q. Game Theory[M]. Shanghai∶ Shanghai Finance University Press,2000.
[13] CONSTANTINOS D, PAUL W, CHRISTOS H. The complexity of computing a nash equilibrium[A]. Proceedings of STOC (2006)[C].Seattle, WA, USA, 2005. 89-97.
[14] MURSHED, RAJKUMAR B, MANZUR. Gridsim∶ a toolkit for the modeling and simulation of distributed resource management and scheduling for grid computing[J]. Concurrency and Computation∶Practice and Experience (CCPE), 2002,14∶ 13-15.
猜你喜歡
教學考試(高考化學)(2021年2期)2021-05-30 06:15:52
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:42
中學生數理化·高一版(2020年3期)2020-04-21 08:03:20
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:32:50
小學生作文(低年級適用)(2019年9期)2019-10-08 08:37:10
小學生作文(低年級適用)(2018年9期)2018-10-08 02:29:48
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:10
數學大世界(2018年1期)2018-04-12 05:39:14
幸福(2017年18期)2018-01-03 06:34:53
中國衛生(2016年8期)2016-11-12 13:26:50
