語言網絡:隱喻,還是利器?
2010-09-19 03:24:50劉海濤
浙江大學學報(人文社會科學版)預印本 2010年12期
劉海濤
(浙江大學外國語言文化與國際交流學院,浙江杭州310058)
現代語言學的奠基人之一索緒爾在其《普通語言學教程》中指出:“語言是一個系統,它的任何部分都可以而且應該從它們共時的連帶關系方面去加以考慮……語言既是一個系統,它的各項要素都有連帶關系,而且其中每項要素的價值都只是因為有其他各項要素同時存在的結果。”[1]127,160此后,丹麥語言學家葉姆斯列夫進一步強化了語言系統就是“關系”系統的理念。受葉姆斯列夫的影響,美國語言學家蘭姆創建了完全基于關系的語言學理論“層次語法”[2],實現了語言是一種關系網絡的思想。認知語言學的代表性理論“認知語法”和“構式語法”等均將語言視為一種可用節點及其關系描述的系統(或網絡)。英國語言學家哈德森甚至以《語言網絡》作為其“詞語法”理論新作的標題[3]。這些事例說明,在語言學界,語言是一種網絡的思想已相當普遍。
那么,語言是一種什么樣的系統或網絡呢?徐思益認為:“語言系統是由語言的層級關系、類聚關系和組合關系構成的從有限到無限、縱橫交錯的網絡結構體。”[4]2由此可以看出,語言網絡是一種復雜程度很高的網絡,但復雜程度高的網絡不一定就是現代網絡科學中所指的復雜網絡。一般認為,復雜網絡是一種無法由其組成部分預測整體行為的網絡。認知語言學認為,“整體大于部分之和”是語言結構的一個基本特點,因此,按照復雜網絡的定義,語言是一種復雜網絡,這也意味著我們可以采用復雜網絡技術對語言進行分析和研究。
如果語言是一個復雜網絡,那么采用復雜網絡的技術與方法來研究語言是很有必要的,因為我們難以采用傳統的語言學研究方法發現語言系統的(整體)特征。由語言構成的信息網絡是信息時代的主體,因此,研究語言結構的語言學必定也會成為像物理學一樣非常重要的學科。如同物理學研究物質世界的規律一般,語言學研究的是信息世界的規律[5]1-4。復雜網絡分析方法可以在大規模真實語料的基礎上,通過實證的方法研究語言網絡的種種特征,進而加深我們對人類語言結構及其復雜性的了解。這種方法也有助于彌補其他語言學方法在發現語言規律時的不足與缺憾,有益于語言的定量及形式化研究。從宏觀角度看,采用復雜網絡分析技術研究語言有助于厘清語言網絡與自然界及人類社會其他真實網絡的異同,加深對人類知識系統組織結構的認識,構建面向計算機處理的知識體系,進而提升語言學研究的學術價值。從微觀角度看,復雜網絡方法有益于我們對以下問題的了解:語言網絡的特征,語言不同層面(網絡)結構的特征及相互關系,網絡作為語言研究手段的可能性,動態和靜態語言網絡的相互關系,語言網絡和信息網絡結構的關系,語言網絡作為計算機處理語言的知識源,某些特殊詞語在語言體系中的用法及地位等。
為了采用復雜網絡方法來研究語言網絡,我們首先要構造語言網絡。在構造網絡的過程中,我們是以語言學理論為基礎,還是采用更便于實現的隨機建網方法呢?語言學理論支持的語言網絡與隨機語言網絡的特征會有很大的不同嗎?如何用注重整體特征的網絡方法來研究語言的局部特征呢?如果局部特性不能影響網絡的整體特性,這些整體特征對于語言學研究的價值何在?語言網絡如何體現語言系統的各種關系呢?不同層面的語言網絡具有相同的復雜網絡特征嗎?語言網絡可以改善自然語言處理系統的性能嗎?語言網絡研究對于計算語言學有何價值呢?語言網絡只是一種隱喻,還是語言研究的利器呢?本文的主要任務就是盡可能回答這些問題,討論的重點為漢語相關語言網絡。
一、復雜網絡的常用統計性質
眾多研究表明,人類處于一個充滿復雜網絡的世界之中[6-7]。因此,復雜網絡研究不但在數理學科、生命學科和工程學科中起著越來越重要的作用,而且也開始滲透到人文和社會科學領域。據統計,在目前的復雜網絡研究中,約有三分之一的研究是與人文社會科學密切相關的,其數量僅次于生物分子領域[7]69,72。
復雜網絡科學不僅為我們提供了認識真實世界復雜性的科學視角,而且正在成為改造客觀世界的新方法。在這種大背景下,用復雜網絡方法來研究和考察對人類具有重要意義的語言,也成為各國學者的一個研究熱點。
為了便于理解下文,這一部分先介紹復雜網絡分析方法的一般概念與常用的分析指標。復雜網絡可以分為無向網與有向網,所謂無向指的是連接節點之間的邊沒有方向,有向指的是節點之間的邊有方向。圖1所示為兩個節點數為10,但邊連接不同的無向網絡,這意味著圖中節點B與C之間的邊既可以表示B-C,也可表示C-B。
為了衡量一個網絡的復雜性,最常用的復雜網絡參數是平均路徑長度、聚類系數和度分布[8]。
網絡中兩個節點i和j之間的距離dij是連接這兩個節點的最短路徑上的邊數。如圖1(a)中,節點A與C之間的最短路徑為3(A-E-B-C),而圖1(b)中這兩個節點中的最短路徑為1(A-C)。
網絡中任意兩個節點之間距離的最大值稱為網絡的直徑。由此定義可以得到圖1(a)的直徑為3,圖1(b)的直徑為5。
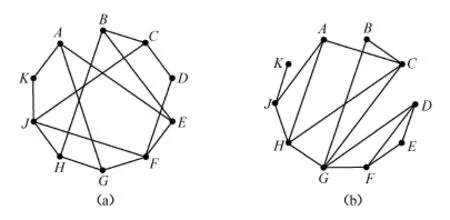
圖1 網絡示例① 圖 1與圖 2均引自M.Steyvers&J.B.T enenbaum,″The Large-Scale Structure of Semantic Networks:Statistical Analy ses and a Model of Semantic Growth,″Cognitive Science,Vol.29,No.1(2005),pp.41-78。
一個無向網絡的平均路徑長度L是任意兩個節點之間距離的平均值,則:
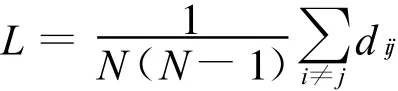
式中N為網絡的節點數。由此式可以得到1(a)的L為1.8,1(b)的L為2.18。
利用網絡的平均路徑長度,我們可以來衡量網絡是否具有小世界特點。小世界概念反映了這樣一種事實:盡管大多數網絡的規模都很大,但網絡中任意兩個節點間大多存在一條較短的路徑。如果一個網絡既有較短的平均路徑長度L,又有較高的聚類系數,這種網絡就是一種小世界網絡[10]。
所謂聚類系數是一種用來衡量網絡聚類傾向或小集群形態的指標。設網絡節點i有ki條邊與其他節點相連,則該節點就與這ki個節點構成了一個子網絡(或集群)。如果將Ei視為這ki個節點之間實際存在的邊數,那么Ei與這ki個節點間最多可有的邊數ki(ki-1)/2之比就是節點i的聚類系數Ci:
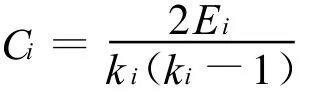
從結構特點來看,上式等價于下面這個更直觀的公式:

所謂與節點i相連的三元組是指包括節點i的三個節點,并且至少存在從節點i到其他兩個節點的兩條邊。由此可以看出,聚類系數反映的是網絡中節點的鄰接點也互為鄰節點的比例,即小集群結構的完美程度。拿圖1中的節點 A來說,在圖1(a)中,A有三個三元組(A-E-K,A-G-K,A-E-G),但沒有三角形,因此節點 A的聚類系數Ca為零;在圖1(b)中,A同樣有三個三元組(A-C-H,A-C-J,A-H-J),并且有兩個三角形(A-C-H,A-H-J),因此該網絡中的Ca為0.67。
整個網絡的聚類系數C為所有節點聚類系數Ci的平均值,即:
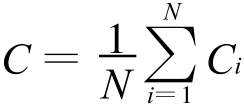
其中N為網絡的節點數。由此可以算出圖1(a)的C為零,圖1(b)的C為0.56。一般來說,如果真實網絡和隨機網絡具有相同的節點和邊,真實網絡的聚類系數要遠大于隨機網絡。
一個網絡節點i的度ki指的是與該節點相連的其他節點的數目(或邊數),它在一定程度上反映了節點在網絡中的重要性,體現了節點與其他節點結合的能力。如節點G在圖1(a)中的度為3,在圖1(b)中為5。因為圖1為無向網,所以我們沒有必要對度作進一步的區分。在一個有向網中,我們應該按照邊的方向計算節點的入度與出度,一個節點的度是它的入度與出度之和。所有節點的度ki的平均值稱為網絡的平均度〈k〉。圖1(a)與圖1(b)的平均度都是3。節點的度分布通常用分布函數P(k)來描述,該函數表示一個隨機選定的節點的度恰好為k的概率。圖2為圖1中兩個網絡的度分布示例。圖2顯示,在圖1(a)中含有2個度為2的節點,6個度為3的節點,2個度為4的節點;在圖1(b)中度為1的節點有1個,度為2的節點有2個,度為3的節點有4個,度為4的節點有2個,度為5的節點有1個。
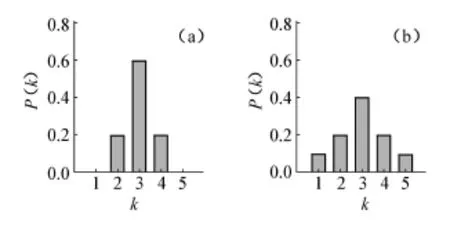
圖2 示例網絡的度分布
隨機網絡的度分布服從泊松分布,而一些真實網絡的度分布一般服從冪律分布。人們也把服從冪律分布的網絡叫做無尺度(scale-free)網絡[11]。
平均相鄰節點度表示的是一個節點的度和它的相鄰節點度之間的相關性。在一個網絡中,如果度大(小)的節點傾向于連接度大(小)的節點,則該網絡是正相關的;如果度大(小)的節點傾向于和度小(大)的節點連接,則這個網絡是負相關的。社會網絡是正相關網絡的典型代表,而生物和技術網絡則多為負相關。社會網絡與生物網絡在這一方面為何會有如此差別仍不清楚,一個可能的原因是:在這兩類網絡形成的過程中,人類的參與程度是有明顯差別的,社會網絡受人類影響的程度顯然要大于生物網絡。
利用以上這些參數我們一般就可以判斷一個網絡的性質,如網絡是否為小世界網絡或無尺度網絡。當然,復雜網絡的統計描述不僅限于這些參數,其他比較常用的參數還有脆弱性、同類性、緊密中心度、介數中心度等。限于篇幅,這里不再詳述。
二、語言網絡的構造與研究
復雜網絡的行為主要取決于兩個方面:一是連接路徑(結構),二是交換和相互作用(動力學)。從結構方面來看,無論網絡的規模有多大,結構多復雜,構成網絡的基本要素卻并不復雜。所有的網絡都是由節點與邊組成的,但在不同的現實世界網絡里,節點與邊所代表的事物是不一樣的。就語言網絡而言,節點可以是各種語言學單位,如漢字的偏旁部首、漢字、詞等,邊可以是語言中各層級元素間的關系。而網絡動力學的重點是尋求導致節點之間相互作用與聯系的動力源,因此,網絡動力學是與應用領域密切相關的。換言之,我們可以通過研究語言網絡的結構來發現語言網絡與其他網絡的共性,通過語言網絡動力學的研究來探求語言網絡的特殊性。這里主要探討語言網絡的結構。
國內外均有學者對語言網絡進行了一定的研究。就構造語言網絡的方法而言,一般采用的方法有:(1)在類屬詞典的根詞與其同義詞之間建立關系;(2)在諸如Wordnet的詞庫基礎上構建意義間的關系;(3)利用句子中詞的共現形成關系;(4)利用具有依存句法關系標注的語料庫構建語言網絡等[12]。我們可將前兩種基于詞典等語言資源所構建的網絡稱為靜態語言網絡,而把后兩種根據真實文本構造的語言網絡稱為動態語言網絡。靜態語言網絡反映的是語言作為一種知識網絡的狀況,而動態網絡可以衡量語言作為一種交際系統的某些特質。
同樣的語言材料,由于構造方式不同,所形成的語言網絡也會有差異。圖3是由三個句子構成的三種漢語網絡,即:“老張在桌子上放了一本書”,“老張的學生讀過一本有趣的書”,“那本書的封面舊了”。
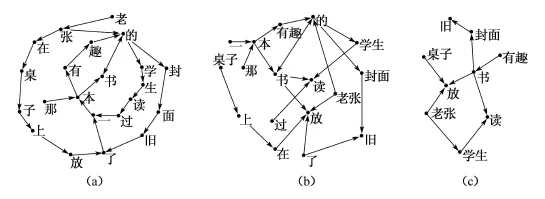
圖3 漢語網絡示例
圖3 (a)網絡中的節點是漢字,節點關系是在句中相鄰漢字間形成的,這是一種可用來研究漢語詞匯形成機制的漢語詞匯網絡。圖3(b)網絡的節點為詞,節點關系是一種依存句法關系。這個網絡的語言學理論基礎是依存語法[13],它是由經過依存句法標注的句子集合轉換而來的,是一種漢語句法網絡。圖3(c)網絡是由經過語義角色或論元結構標注的句子集合轉換得來的,是一種漢語語義網絡。盡管構成這三種網絡的節點有限,但我們已經可以看出漢語網絡在詞匯、句法和語義層面是存在較大差異的。例如,虛詞在三個網絡中作用和地位明顯不同:在圖3(a)的詞匯網絡中,如果把虛詞移走,那么網絡中相鄰節點間組成詞的概率就會大大增加;在圖3(b)中,如果將虛詞從網絡中移走,剩下的節點就不是一個聯通的網絡了,這說明虛詞在漢語句法層面占有很重要的地位;圖3(c)網絡的節點均是實詞,虛詞在語義網絡的缺失,使語義網絡更接近于一種概念網絡。三種網絡間的差異有可能反映的是概念與語言表達之間的認知機制的差異,因此,語言復雜網絡的研究有助于加深我們對人類由思維到語言實現過程的認識。當然,為了對漢語網絡進行更深入的研究,我們需要采用專門的復雜網絡算法和軟件程序來統計、計算此前提出的諸如平均路徑長度、聚類系數和度分布等網絡參數,進而對語言網絡的特性有一個整體的把握和了解。
圖3所示網絡不但有助于我們了解不同的構造方式對于網絡結構的影響,也有益于樹立不同層面語言網絡有差異的觀念。但從圖3的三個網絡中,我們很難體會到語言網絡的復雜性,主要原因在于圖3的網絡所含節點太少,導致節點之間的聯系難以體現真實語言網絡的復雜性。圖4為根據中央電視臺“新聞聯播”文本所構造的一個依存句法網絡。雖然這個網絡只含有4 000個節點,但從直觀上已經展示出語言網絡所具有的復雜性了。
與大多數其他語言相比,漢語采用漢字而非拼音文字,這使構造漢語網絡時有了更多的選擇,也為我們研究語言網絡提供了更多的素材。
李健瑜利用可以組成字的部首之間的關系[14],構造了一個以漢字部首為節點的網絡。如,部首“女”與部首“己”、“又”、“氵”可以組成漢字“妃”、“奴”和“汝”,因此在這些部首之間就有連接。
香港中文大學的彭剛等利用詞內所含漢字之間的關系,構造了節點為漢字的普通話和粵語網絡[15],王建偉、榮莉莉也采用類似的方法構造并研究了一個漢字網絡[16]。此種網絡中的節點為漢字,如果兩個漢字之間可以形成詞,則在兩者之間建立一個連接。如漢字“車”與“火”、“貨”、“汽”、“站”、“庫”等之間就有連接。也有學者構造并研究了以字為節點、以同現關系為連接的漢字網絡[17],如圖3(a)所示樣例。
李勇等采用詞組中是否含有同一漢字的方法,構造了一個漢語詞組網絡[18]。在這個漢語詞組網絡中,詞組為網絡中的節點,如果兩個詞組中含有同一個漢字,則在兩者之間建立一條連接。如“網絡”與“電網”、“網球”、“聯絡”等節點都有連接。
劉海濤采用依存語法標注了“新聞聯播”與“實話實說”文本,并在此基礎上構建了兩個漢語依存句法網絡[19];劉知遠等構造并研究了漢語詞同現網絡和一個由短語結構樹庫轉換得到的漢語依存句法網絡[20]。此種句法網絡的示例可見圖3(b)的樣例。
劉海濤通過對真實文本進行語義角色標注,構造并研究了漢語的動態語義網絡[21]。這是一種節點為實詞、連接為語義或論元關系的網絡。示例見圖3(c)的樣例。
值得注意的是,這些建構原則各不相同的語言網絡均具有小世界和無標度特征。換言之,幾乎所有語言網絡都具有復雜網絡的基本特征。
毫無疑問,以上這些研究對于認識語言網絡的普遍性是有意義的,但也存在一些不足和有待進一步研究的問題:
(1)研究者在構造語言網絡時,大多采用自動的方式,沒有經過深入的語言結構分析。這雖然有助于提高語言網絡的構造速度,但所構建的網絡可能沒有反映語言的真實結構,難以與語言學理論產生密切的聯系。
(2)由于構造網絡的基礎主要是詞典等資源,這樣所構建的網絡大多是一種靜態語言網絡,不足以反映語言的實際使用情況。
(3)對語言表層的關注過多,幾乎沒有考慮更深層次的句法、語義和概念網絡。
(4)研究重點一般為網絡的整體統計特征,對網絡局部及局部和整體之間的關系研究不夠。

圖4 語言網絡全景
在對二十多種語言網絡進行考察之后,Mehler認為,所有的語言網絡研究都應該對以下問題作出回答[22]:網絡的節點及連接它們的邊表示的是什么?為什么要研究這種語言網絡?研究了哪些小世界或復雜網絡參量?如果網絡是小世界的,其產生原因是什么?對網絡的增長方式與動力學有何考慮?遺憾的是,現有的大多數語言網絡研究都不能很好地回答這些問題。筆者認為,問題的根本在于語言學理論與復雜網絡研究的脫節。
總的說來,現有的大多數研究過于注重網絡的整體特征,忽視了局部現象和整體特征之間的聯系,所得到的結果往往難以用語言學理論來解釋。這種缺乏解釋的研究既不利于復雜網絡本身的研究,也無助于從網絡的角度認識語言。
三、復雜網絡作為語言研究的手段
許多中外語言學家都意識到,語言不是一種簡單系統,而是一種復雜系統。語言的以下特征使它足以成為一種復雜系統[23]:語言是開放的、動態的,而不是均衡的;語言含有大量相互聯系的成分;語言具有涌現的特點;語言中結構單元的分布是非線性的;語言具有縮放屬性。
嚴格說來,由于缺乏適宜的研究手段,語言學家對于語言復雜性的認識基本還停留在隱喻的層面[24]11。盡管只是隱喻的說法,語言的系統觀與網絡觀也在一定程度上有助于對語言的全面理解,有益于推動語言學在理論方面的根本性改變。王士元認為,復雜理論的應用使近年來應用語言學的研究更顯精實[25]iii。復雜網絡的迅速發展及其在各個領域的應用,產生了大量的研究工具和方法,這些工具和方法使語言學家通過復雜網絡技術研究(語言)復雜系統成為可能。
由于復雜網絡研究領域的特殊性與專業性,目前活躍在這一領域的主要研究者大多為理工科背景的學者。他們對語言網絡的研究更多關注的是語言網絡的整體特點、語言網絡與其他網絡的共性等問題,對于語言網絡作為語言研究手段的問題則鮮有論及。這樣的研究當然有其學術價值,但從語言學的角度看也存在著很多問題。有關這些問題此前已有提及,此不贅述,這一部分主要討論復雜網絡作為語言研究手段的問題、可行性和一些已有的成果。
筆者認為,如果要用復雜網絡來研究語言,那么在構造語言網絡時,應具有語言學理據,應將網絡的構造建立在語言學理論之上。非語言學家由于缺乏必要的語言學知識,所構造的網絡在語言學家看來幾乎沒有研究價值。這方面最明顯的例子是在構造以詞為節點的網絡時,人們最常用的方法是采用詞共現的方式來生成網絡。所謂詞共現網絡就是在相鄰詞之間建立一條連接。從技術上講,這種網絡是非常容易實現的,因此受到了眾多研究者的青睞。然而,按照最適宜于構建語言句法網絡的依存語法來看,在一個符合句法的句子分析中,詞間關系不一定都是在相鄰詞之間產生的。通過對20種語言依存關系的統計發現,只有大約50%—60%的依存關系是在相鄰詞之間產生的[26]。因此,利用詞共現網絡來研究人類語言幾乎沒有語言學上的價值,詞共現網絡更不等價于依存句法網絡。但在許多復雜網絡研究者眼里,這兩者是相同的。如Brede和Newth論文標題中所指的句法依存網絡,實際上只是詞共現網絡[27]。
從網絡結構上看,詞共現網絡與依存句法網絡的差異也是明顯的。圖5為兩個英文句子“The student has a book(那個學生有一本書)”與“He reads the interesting book(他讀那本有趣的書)”所構成的詞共現網絡和依存句法網絡。由圖5可見,兩種網絡的差異是明顯的。這也說明,在語言復雜網絡的研究中,語言學家的參與是非常必要的,否則,就有可能出現許多沒有語言學價值的語言網絡研究。
現在的問題是,為什么由兩個句子組成的詞共現與句法示例網絡的差異明顯,而當我們將網絡的節點增加,網絡所展現的整體統計特征卻會如此接近,以致兩者之間難以區分呢?句法在構造句法網絡的過程中難道真的沒有什么作用嗎?
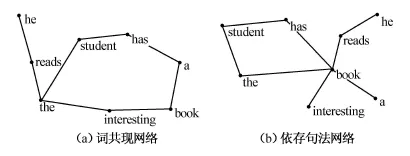
圖5 詞共現網絡與依存句法網絡示例
為了研究這個問題,劉海濤與胡鳳國在同一個漢語經依存句法標注語料庫(樹庫)的基礎上,構建了兩種隨機依存樹庫,并將這三個依存樹庫轉換為三種語言網絡[28]。他們的研究表明,三種網絡均為小世界與無尺度網絡。Brede和New th采用詞共現與隨機網絡也得到了類似結論[27]。換言之,如果我們要用本文第一部分介紹的那些統計指標來衡量一個語言網絡是否合乎句法的話,可能是沒有定論的。對這個問題,似乎可以這樣理解,采用整體統計指標的復雜網絡方法不適合研究細微的句法問題[29]。圖5所展現的兩者之間的這種差異在更大的網絡中消失了,這種無法用局部來解釋整體的特征,也正是復雜網絡的一個主要特點。但這不能成為研究者們可以用非句法的網絡來研究句法網絡的理由,而應成為激勵研究者尋求更適宜的復雜網絡統計指標的動力。
如果有語言學理論支持的語言網絡與隨機語言網絡的特征沒有明顯的不同,我們如何用注重整體特征的網絡方法來研究語言的局部特征呢?如果局部的語言特性不會影響網絡的整體特性,這些整體特征對于語言學研究的價值何在呢?在這種情況下,復雜網絡還能作為語言研究的工具嗎?對于這些問題,筆者的理解是:局部與整體之間必然有聯系,但問題在于現在的統計指標不能很好地反映這種聯系。語言網絡整體特征的研究一方面有利于從宏觀的角度比較語言系統與人類社會及自然界的其他系統的特點,另一方面也可將此種方法應用于語言研究中某些注重整體的領域,如語體研究、語言類型研究等。
語言是一種分層次的系統,每一層次的基本單位可以組合為更高層次的單位。如偏旁部首組成漢字,漢字組成詞,詞組成句子,句子組成篇章等。這種由看得見的語言學單元所構成的語言網絡,我們可以稱之為表層語言網絡。通過對表層語言網絡的研究,我們可以更好地認識語言單位的組合能力與結合模式。例如,在以部首為節點的字網絡中,我們可以研究“氵”的構字能力;在以字為節點的詞網絡中,我們可以研究“網”的構詞能力;在以詞為節點的句法網絡中,我們可以研究“的”的句法地位等。這樣的研究不僅是定量的,而且也是全局的,可以在一定程度上彌補其他語言學研究方法的不足。
為了比較研究同一種語言中不同語體的網絡特點,劉海濤構造了“新聞聯播”和“實話實說”兩種不同語體的句法網絡[19]。研究表明,盡管兩種網絡直徑相同,但在平均度、平均路徑長度、冪律指數和聚類系數方面均有明顯差異。對不同語體的字、詞共現網絡的研究也表明,復雜網絡的相關特征是可以反映語體特點的[17]。
語言學家關注的另一個問題是,在不同結構層次上構造的語言網絡,它們的網絡特征有差別嗎?對于漢語而言,同一文本的字、詞網絡有差別嗎?同一類型文本的句法網絡與語義網絡有明顯的不同嗎?如果復雜網絡可以反映語言結構層次的特點,那么,這種方法對于了解語言的結構特點是有用的。研究表明,相同文本的字、詞共現網絡雖然都是小世界與無尺度的網絡,但兩者的統計特征還是有明顯差別的。比較漢語句法網絡與語義角色(論元結構)網絡的統計特征,可以看出,盡管語義網絡也是小世界和無尺度網絡,但它與句法網絡在層級結構和節點度相關性方面存在明顯不同[21]。
網絡的層級結構可用網絡的聚類系數和節點度的相關性來度量。真實網絡一般具有較明顯的層級性,即:低度節點的相鄰節點互連的概率大,而高度節點的相鄰節點互連的概率則較小。與句法網絡相比,語義網絡的層級性較差。研究也表明,語義網絡的節點度與其相鄰節點度之間的相關性要弱于句法網絡[21]。由于句法網絡的負相關反映的是實詞和虛詞之間的聯系,因此,缺少虛詞的語義網絡幾乎沒有明顯的相關性也就不難理解了。度相關性也引出了語言是何種系統的老問題,即語言是一種生物網絡還是一種社會網絡。從句法網絡的角度看,語言是一種生物網絡,這一點似乎與喬姆斯基等人所倡導的生物語言學是一致的[30]。但語義網絡所展現的弱相關性又告誡我們,不同語言層面的結構特征可能是有差異的。
與字、詞、句法等表層語言網絡不同,語義網絡是一種深層語言網絡。語義網絡又可以分為兩種:一種是通過真實文本進行語義角色或論元結構分析所得到的語義網絡,這種網絡可以稱之為動態語義網絡。動態語義網絡有助于研究與交際過程相關的各種語義問題,有利于更好地研究語義處理策略與系統。也有根據詞典等語言資源構造的語義網絡,這種語義網絡是一種靜態語義網絡,它所反映的是人類存儲知識的方式和結構。在這樣的網絡中,節點一般為概念(或實詞),節點之間的關系可以是上下位、部分與整體、同義、反義等語義關系[12]4。靜態語義網絡對于義類和概念詞典的研究及知識庫的開發都有用處。
劉海濤用《安徒生童話全集》中的前20篇童話構建了丹麥語、漢語、英語及世界語的四個語言網絡,并計算了這些網絡的主要復雜網絡特征參數[31]。數據顯示,內容相同、(語言)形式不同的網絡具有相似的復雜網絡特征。這在一定程度上證明了翻譯文本整體特征具有可度量性,語言之間存在可譯性。該研究也表明,盡管這四種網絡都具有小世界與無尺度的特征,但其復雜網絡特征參數值之間的差異也體現了語言結構的不同。從這個意義上說,復雜網絡不僅是一種可用來研究網絡共性的方法,也可用來發現網絡的個性。
復雜網絡注重整體的特質,使它非常適宜于研究某些詞(類)對語言系統的影響。這方面最值得研究的是漢語虛詞在漢語句法體系中的作用。一般認為,由于漢語的實詞沒有形態變化,虛詞便成了漢語的主要句法手段之一。如果虛詞是漢語的主要句法手段,那么從漢語句法網絡中將虛詞移走,可能會導致漢語句法網絡的統計特征發生重大變化。陳芯瑩以概率配價模式理論[13]106-111為基礎,利用復雜網絡分析技術研究了漢語句法網絡中虛詞的網絡結構特點。她的研究發現①參見陳芯瑩《漢語虛詞的復雜網絡特征研究》,中國傳媒大學2009年碩士學位論文。:
(1)“的”是漢語句法網絡的全局中心節點。它的被支配能力是網絡中最強的,同時它還具備很強的支配能力。而且“的”的這些網絡特性受語體影響較小。從網絡中剔除“的”節點,會造成句法網絡的平均度下降、平均路徑長度增加、直徑增加、密度降低,并導致孤立節點的產生。
(2)“了”是網絡中的局部中心節點,不是全局中心節點。它具有較強的被支配能力,但不具備支配能力。刪除“了”會造成網絡的平均度下降,但其對網絡的影響比“的”要小;還會使平均路徑長度增加、直徑增加、密度降低,其影響均大于“的”;不會使網絡產生孤立節點。
(3)介詞“在”接近網絡的全局中心節點。但“在”的支配能力與被支配能力受語體影響較大,在書面語體中的被支配能力強于在口語體中的被支配能力。剔除“在”會使網絡的平均度下降,但其影響比“的”要小;使平均路徑長度增加、直徑增加、密度降低,其影響均大于“的”,與“了”相當;會使網絡產生孤立節點。
此種研究用直觀、定量的方式,從系統、整體的角度來考察虛詞在漢語句法系統中的使用和地位,有助于加深對漢語句法網絡的全面了解。這樣的研究也表明,漢語缺乏形態并不意味著它沒有句法,也不意味著它是一種所謂的“意合語言”。
語言網絡對于語言的整體概括能力,也使通過語言網絡的復雜網絡參數來進行語言的類型學研究成為可能。劉海濤構造了15個句法復雜網絡,并采用復雜網絡研究工具對這些語言網絡進行了研究[32]。研究結果顯示,通過復雜網絡的主要參數,即節點的平均度、聚類系數、平均路徑長度、網絡中心度、直徑、節點度冪律分布的冪指數、度分布與冪律擬合的決定系數,可以對人類語言進行分類,其準確性與利用現代語序類型學主要指標進行語言分類的準確性相當[33]。這種方法不但克服了類型學研究中語種庫語料為非真實語料及參數選擇中過于注重微觀的問題,所得到的結果更能體現語言的整體類型學特征,也拓展了復雜網絡在人文、社會與生命科學等領域的應用。
語言復雜網絡也可用于計算語言學相關領域,如:同義詞的選用,通過網絡的統計性質來判定文本的質量,通過比較兩種語言的詞共現網絡評價機器翻譯的質量,作家風格的研究,將詞網絡用于拼寫校正軟件的開發等[7]。此種應用的基礎一般是一個以詞為節點的語言網絡,通過比較網絡的各種統計性質來判定文本的質量或對文本進行分類。
廣義上講,基于復雜網絡的方法與在自然語言處理領域廣為應用的基于圖的方法差別不大,盡管這兩個領域所用的術語與目標有些不同。因此,以復雜網絡作為語言資源,可用各種已成熟的圖算法來進行一些面向應用的開發與研究。這方面的可用領域有:句法、語義范疇的自動識別,歧義消解,信息檢索,自動分析,文本摘要及關鍵詞提取等[34]。
四、結 語
語言是一種(復雜)網絡。長久以來,由于缺乏適宜的研究工具,語言的網絡觀更多的只是一種隱喻。復雜網絡研究的盛行,使我們有可能采用真正的網絡分析工具來研究語言網絡。遺憾的是,目前語言網絡的研究者大多是理工科的學者,所以他們的研究一般關注的是語言網絡的普遍特征。這種只注重共性、忽視個性的研究方式,既不利于語言網絡個性的發現,也無助于從復雜網絡的角度來探索語言結構的本質規律。
筆者認為,如果要用復雜網絡來研究語言,那么在構造語言網絡時,應具有語言學理據,換言之,網絡的構造應建立在語言學理論之上。只有這樣,復雜網絡才可能作為一種語言研究的工具,語言學家也才有可能走出語言網絡的隱喻世界。
研究表明,復雜網絡的相關特征不僅可以反映語體特點,可以作為區分語言各個層面結構的手段,而且適宜于研究某些詞(類)對語言系統的影響。但僅有這些是不夠的,我們還需要進一步挖掘復雜網絡分析技術的潛力。為了更好地利用網絡手段來研究語言,研究者一要選好適宜的研究領域,二要在注重研究共性的基礎上,加強對網絡個性的研究。對于語言系統的研究來說,我們不但可通過復雜網絡來研究語言系統與其他系統的共性,更應通過社會網絡分析等方法來挖掘語言網絡的個性。這種局部與整體的結合、共性與個性的統一,有助于我們更好地理解語言結構的本質。
具體而言,值得在以下方面作進一步的深入研究:由特殊語言結構組成的語言網絡反映的是語言網絡的共性還是個性?如何尋求更適宜的語言學理論來研究語言網絡的增長與演化?局部結構與整體特征之間的關系可以用統計特征來表示嗎?如何通過語言習得來擴大語言網絡的規模?相同類型的語言網絡,其統計特征具有跨語言的相似性嗎?語言網絡可以作為語言對比或翻譯研究的工具嗎?語言網絡與認知有什么聯系?
未來的路很長,但很光明。因為語言網絡的研究不但有助于我們更好地理解語言的結構和組織,認識語言的普遍性和特殊性,有益于對語言信息網絡的認識,研制更好的自然語言處理系統,也有益于提升語言學研究的現代化水平和學術價值。
[1][瑞士]索緒爾:《普通語言學教程》,高名凱譯,北京:商務印書館,1980年。[F.De Saussure,Course in General Linguistics,trans.by Gao Mingkai,Beijing:The Commercial Press,1980.]
[2]S.M.Lamb,Outline of Stratif icational Grammar,Washington:Georgetown University Press,1966.
[3]R.A.Hudson,Language Networks:The New Word Grammar,Oxford:Oxford University Press,2007.
[4]徐思益:《語言研究探索》,北京:商務印書館,2009年。[Xu Siyi,Exploration in Language Research,Beijing:The Commercial Press,2009.]
[5]馮志偉:《現代語言學名著導讀?序》,北京:北京大學出版社,2008年。[Feng Zhiwei,Readings of Modern Linguistics:Preface,Beijing:Peking University Press,2008.]
[6]汪小帆、李翔、陳關榮:《復雜網絡理論及其應用》,北京:清華大學出版社,2006年。[Wang Xiaofan,Li Xiang&Chen Guanrong,Complex Network and Its Application,Beijing:Tsinghua University Press,2006.]
[7]L.da F.Costa,O.N.Oliveira Jr.&G.Travieso,et al,″Analyzing and Modeling Real-World Phenomena with Complex Networks:A Survey of Applications,″http://arxiv.org/PS_cache/arxiv/pdf/0711/0711.3199v3.pdf,2010-09-15.
[8]R.Albert&A.L.BarabáSi,″Statistical Mechanics of Complex Networks,″Reviews of Modern Physics,Vol.74,No.1(2002),pp.47-97.
[9]M.Steyvers&J.B.Tenenbaum,″The Large-Scale Structure of Semantic Networks:Statistical Analyses and a Model of Semantic Growth,″Cognitive Science,Vol.29,No.1(2005),pp.41-78.
[10]D.Watts,Small Worlds:The Dynamics of Networks between Order and Randomness,Princeton:Princeton University Press,1999.
[11]A.L.Barabá Si&R.Albert,″Emergence of Scaling in Random Networks,″Science,Vol.286,No.5439(1999),pp.509-512.
[12]R.Solé,B.Mutra&S.Valverde,et al,″Language Networks:Their Structure,Function and Evolution,″http://www.santafe.edu/research/working-papers/abstract/7f172d0b8df9c491f4b12d0349b45e5a,2010-09-10.
[13]劉海濤:《依存語法的理論與實踐》,北京:科學出版社,2009年。[Liu Haitao,Dependency Grammar:From Theory to Practice,Beijing:Science Press,2009.]
[14]J.Li&J.Zhou,″Chinese Character Structure Analysis Based on Complex Networks,″Physica A,Vol.380(2007),pp.629-638.
[15]G.Peng,J.W.Minett&W.S.-Y.Wang,″The Networks of Syllables and Characters in Chinese,″Journal of Quantitative Linguistics,Vol.15,No.3(2008),pp.243-255.
[16]王建偉、榮莉莉:《基于復雜網絡理論的中文字字網絡的實證研究》,《大連海事大學學報》2008年第4期,第15-18頁。[Wang Jianwei&Rong Lili,″An Empirical Study on Chinese Word-Word Network Based on Complex Network Theory,″Journal of Dalian Maritime University,No.4(2008),pp.15-18.]
[17]Y.Shi,W.Liang&J.Liu,et al,″Structural Equivalence between Co-occurrences of Characters and Words in the Chinese Language,″http://www.eie.polyu.edu.hk/ ~ cktse/pdf-paper/NOLTA08-Shi.pdf,2010-09-12.
[18]Y.Li,et al,″Structural Organization and Scale-Free Properties in Chinese Phrase Networks,″Chinese Science Bulletin,Vol.50,No.13(2005),pp.1304-1308.
[19]H.T.Liu,″The Complexity of Chinese Dependency Syntactic Networks,″Physica A,Vol.387,No.12(2008),pp.3048-3058.
[20]劉知遠、鄭亞斌、孫茂松:《漢語依存句法網絡的復雜網絡性質》,《復雜系統與復雜性科學》2008年第2期,第37-45頁。[Liu Zhiyuan,Zheng Yabin&Sun Maosong,″Complex Network Properties of Chinese Syntactic Dependency Network,″Complex Systems and Complexity Science,No.2(2008),pp.37-45.]
[21]H.T.Liu,″Statistical Properties of Chinese Semantic Networks,″Chinese Science Bulletin,Vol.54(2009),pp.2781-2785.
[22]A.Mehler,″Large Text Networks as an Object of Corpus Linguistic Studies,″in A.Lüdeling&M.Kyt?(eds.),Corpus Linguistics:An InternationalHandbook,Vol.1,Berlin&New York:De Gruyter,2008,pp.328-382.
[23]W.A.Kretzschmar,The Linguistics of Speech,New York:Cambridge University Press,2009.
[24]D.Larsen-Freeman&L.Cameron,Complex Systems and Applied Linguistics,Oxford:Oxford University Press,2008.
[25]王士元編:《語言涌現:發展與演化》,臺北:“中央研究院”語言學研究所,2008年。[Wang Shiyuan(ed.),The Emergence ofLanguage Development and Evolution,Taipei:Institute ofLinguistics,Academia Sinica,2008.]
[26]H.T.Liu,″Dependency Distance as a Metric of Language Comprehension Difficulty,″Journal of Cognitive Science,Vol.9,No.2(2008),pp.159-191.
[27]M.Brede&D.Newth,″Patterns in Syntactic Dependency Networks from Authored and Randomised Texts,″Complexity International,Vol.12(2008),Paper ID:msid23.
[28]H.T.Liu&F.G.Hu,″What Role Does Syntax Play in a Language Network ?″EPL(Europhysics Letters),Vol.83,No.1(2008),Paper ID:18002.
[29]H.T.Liu,Y.Zhao&W.Huang,″How Do Local Syntactic Structures Influence Global Properties in Language Networks?″Glottometrics,Vol.20(2010),pp.38-58.
[30]C.Boeckx&K.K.Grohmann,″The Biolinguistics Manifesto,″Biolinguistics,Vol.1(2007),pp.1-8.
[31] 劉海濤:《翻譯的復雜網絡視角》,《北華大學學報(社會科學版)》2010年第4期,第 59-63頁。[Liu Haitao,″T ranslation Studies from Complex Networks,″J ournal of Beihua University(Social Sciences),No.4(2010),pp.59-63.]
[32]劉海濤:《語言復雜網絡的聚類研究》,《科學通報》2010年第 27-28期,第2667-2674頁.[Liu Haitao,″A Clustering Study on Linguistic Complex Networks,″Chinese Science Bulletin,No.27-28(2010),pp.2667-2674.]
[33]H.T.Liu,″Dependency Direction as a M eans of Word-Order Typology:A Method Based on Dependency T reebanks,″Lingua,Vol.120,No.6(2010),pp.1567-1578.
[34]M.Choudhury&A.Mukherjee,″The Structure and Dynamics of Linguistic Networks,″in N.Ganguly,A.Deutsch,A.Mukherjee,et al(eds.),Dynamics on and of Complex Networks,Boston:Birkhaeuser,2009,pp.145-166.
猜你喜歡
中華詩詞(2021年3期)2021-12-31 08:07:22
大連民族大學學報(2021年2期)2021-07-16 05:41:42
文苑(2020年4期)2020-05-30 12:35:30
開放教育研究(2020年2期)2020-03-31 01:54:14
中華詩詞(2018年3期)2018-08-01 06:40:40
小學生作文(中高年級適用)(2018年3期)2018-04-18 01:24:47
中華詩詞(2018年11期)2018-03-26 06:41:32
華北電力大學學報(社會科學版)(2016年4期)2016-12-01 03:59:30
現代語文(2016年21期)2016-05-25 13:13:44
少兒科學周刊·少年版(2015年4期)2015-07-07 21:11:17
