一種多粒度集群數據庫并發控制新算法
2010-10-16 03:55:42王大海賈玉珍靳冰
河北工程大學學報(自然科學版) 2010年4期
王大海,賈玉珍,靳冰
(1.新鄉職業技術學院,河南 新鄉453000;2.南陽理工學院 軟件學院,河南 南陽 473004)
數據庫集群系統以集群技術與數據庫系統相結合,是一組完整的、自治的計算處理單元,每個節點均有獨自的CPU、內存以及磁盤等硬件資源,運行獨立的操作系統和自治的數據庫系統,通過高速專用網絡或商業通用網絡互連,彼此協同計算,作為統一的數據庫系統提供并行事務處理服務[1]。
近年來,集群系統中的負載平衡問題受到人們的關注。負載平衡包含許多因素,例如系統結構[2]、算法[3]、資源管理[4]和數據分布[5]以及負載應用類型[3]等都會影響系統的性能平衡。
為了保證全局事務執行的正確性和一致性,本文在研究數據庫集群中的事務并發控制方法的基礎上,提出了一種多粒度的沖突判斷和死鎖檢測方法,使事務并發控制的粒度達到謂詞級,并討論各種謂詞的提取方法,既提高全局事務處理效率,又不需要對局部數據庫做任何限制。本文還改進了一種以事務提交圖為中心的并發事務調度算法來保證集群系統中全局事務的可串行化提交,以增加吞吐率和減少響應時間。
1 多粒度集群數據庫并發控制算法
1.1 集群系統中的事物模型
數據庫集群系統中的事務分為兩種:全局事務和局部事務,我們把只在一個站點上執行的事務稱為局部事務或本地事務[6]。
定義1:一個提交到某個數據庫站點j上的執行的事務Li是局部事務,當且僅當}。其中 Dj表示局部站點j上的所有數據集合,Oi表示事務Li的所有讀、寫操作的數據對象的集合,而R(x)和W(x)則分別表示對數據項x的讀操作和寫操作。
全局事務是需要在多個站點上執行的事務。
定義2:一個事務是全局事務 Gi,當且僅當(任意 Dj∈{D1,D2,…,Dn})?Dj),Oi=。該定義表示全局事務操作的讀寫集所需訪問的數據不僅僅只包含于一個站點而是跨多個站點的。
由以上定義可知,局部事務僅在集群中一個自治的數據庫站點上執行,而全局事務需要在集群系統中被分解為多個子事務然后發送到多個數據庫站點上執行。本文把全局事務劃分為對應站點上執行的子事務稱為全局子事務,每個子事務僅對應一個數據庫站點操作,因此全局子事務也可以看作是僅在一個數據庫站點上執行的局部事務。
由于集群中各數據庫站點的自治性和局部性,在每個局部站點的數據庫系統上既可以執行由全局事務劃分的全局子事務又可以執行不需劃分的局部事務,雖然局部事務的一致性可以在單站點數據庫上得到保證,而作為全局事務所劃分的子事務在對應的多個數據庫站點上執行時,其全局事務的原子性和一致性難以得到保證,因此這里將主要討論集群系統中跨多個站點執行的并發全局事務間的一致性和正確性。
1.2 多粒度的并發控制
數據庫集群系統中并發控制的核心部件是事務管理器,如何提高事務管理器中事務執行的并發度,提高處理效率成為研究的主要問題。集群系統中的事務管理器在調度全局事務的子事務在集群系統中的多個站點上執行時,由于資源競爭會產生沖突,這些全局事務間的沖突主要可分為直接沖突和間接沖突。全局事務間的沖突歸根結底是由兩個或兩個以上的事務在相同站點上同時訪問相同的數據對象而引起的,因而這些事務間的沖突類型主要有讀-寫、寫-寫和寫-讀沖突三種。
首先,兩個全局事務間的直接沖突[7]定義如下:
定義3:當且僅當下列條件成立時稱兩操作p和q是直接沖突的,記為pCTq:

由以上定義可知,兩個或多個數據操作產生沖突的條件是:(1)兩個操作屬于不同的全局事務;(2)兩個操作訪問相同站點上的同一數據項且其中至少有一個為寫操作,否則就不會產生沖突;(3)兩個操作都同時訪問數據對象,亦即兩全局事務在時間上同時發生才可能產生沖突。
為了保持局部站點數據庫的自治性,并發全局事務間的沖突檢測必須由集群系統中的事務管理器來執行,而且全局事務間的沖突檢測粒度會直接影響事務執行的并發度,在全局事務的并發控制中如果采用傳統的元組級封鎖,雖然可以實現細粒度的并發控制,但其缺點是開銷代價太高。本文在事務管理器中采用謂詞技術而不需封鎖元組來檢測全局事務間的直接或間接沖突,以實現多級粒度的沖突檢測機制,同時也進一步減小了死鎖檢測粒度,提高了全局事務處理的并發度。
謂詞的概念及提取技術一:為了進行全局事務間沖突的判斷,首先必須要分析出全局事務所要操作的數據粒度,而采用謂詞方法就是一種表示全局事務多級粒度操作對象的有效手段,謂詞是指全局事務的SQL語句中DML四種操作所帶的where分詞條件,這種分詞條件一般可分為謂詞常項(表示具體性質和關系的詞)和謂詞變項(表示抽象的或泛指的謂詞)[3-4]。
根據謂詞提取及轉化的定義和規則,具體的where謂詞條件分解過程如分解算法1所示。
分解算法1:
1)if謂詞pred條件的右邊是常量:(1)獲得謂詞pred左邊的屬性定義;(2)if屬性定義中存在一個選擇子句,找到選擇子句中所涉及的關系,并將它加入條件謂詞列表中;(3)調用算法2,分解屬性定義中的查詢子句;(4)else/*屬性定義是一個簡單引用*/,找到簡單引用所涉及的關系,并將它加入條件謂詞列表中;end if。
2)else/*謂詞pred的右邊不是常量*/:(1)分別得到謂詞左右兩邊的屬性定義;(2)if左右兩邊的屬性定義都是查詢,for右邊屬性定義的所有選項r,for左邊屬性定義的所有選項l,找到r和l所涉及的關系,if右邊r和左邊l的關系相同加入到謂詞列表中,else發送繼續執行,end for;/*左邊屬性定義的選擇項*/,調用算法2,分解左邊屬性定義中的查詢子句。end for;/*右邊屬性定義的選擇項*/,調用算法2,分解右邊屬性定義中的查詢子句;(3)else if;左邊的屬性定義是簡單引用,右邊的屬性定義是查詢找到左邊屬性定義中對應的關系,for右邊屬性定義的所有選項r,找到r所對應的關系。if左右兩邊關系相同,加入條件謂詞列表中。end for;/*右邊屬性定義的選擇項*/,調用算法2,分解右邊屬性定義中的查詢子句;(4)else if;左邊的屬性定義是查詢,右邊的屬性定義是簡單引用。找到右邊屬性定義中對應的關系,for左邊屬性定義的所有選擇項l,找到左邊l所對應的關系。if左右兩邊的關系相同加入條件謂詞列表中。end for;/*左邊屬性定義的選擇項*/,調用算法2,分解左邊屬性定義中的查詢子句;(5)else if左右兩邊的屬性定義都是簡單引用。如果關系左右兩邊屬性定義中各自對應的關系相同,則加入條件謂詞列表中;(6)end if;/*判斷左右兩邊的屬性定義是簡單引用還是查詢*/。
3)end if;/*判斷謂詞pred的右邊是不是常量*/。下面是分解屬性定義中的查詢子句算法2。
分解算法2:
for q的所有查詢條件cond,找到cond左右兩邊對應的關系;如果兩邊關系相同,則加入到條件謂詞列表中。end for;在算法1的謂詞分解流程中,當謂詞條件在左右兩邊的屬性定義都是查詢時最復雜,假設當左右邊各有n個屬性定義時,算法1的時間復雜度為O(n2)。
謂詞的概念及提取技術二:集群系統中的全局事務在以SQL語句形式執行時只有對應的DML操作可能會產生讀-寫、寫-寫和寫-讀三種沖突,而DML操作主要有 4種:select、update、insert和delete,如果將select等效于讀操作,而insert、update和delete操作等效于寫操作來替代,沖突矩陣如下表1。

表1 SQL語句沖突矩陣Tab.1 SQL statements conflict matrix
在表1中,“Y”表示操作在謂詞級上沖突是相容的;“N”表示操作在謂詞級上可能是沖突相容也可能是不相容的,需要進一步判斷是否有謂詞交集;“-”表示插入操作與其他操作在謂詞級上無法判斷是否沖突 (因為插入操作一般無條件謂詞,只能加表級鎖)進而退化到表級是沖突不相容的,另外如果允許關系中存在重復元組時,insert與insert操作應該在表級上是沖突相容的。以上直接沖突判斷的矩陣防止了數據庫中出現的幻象干擾。
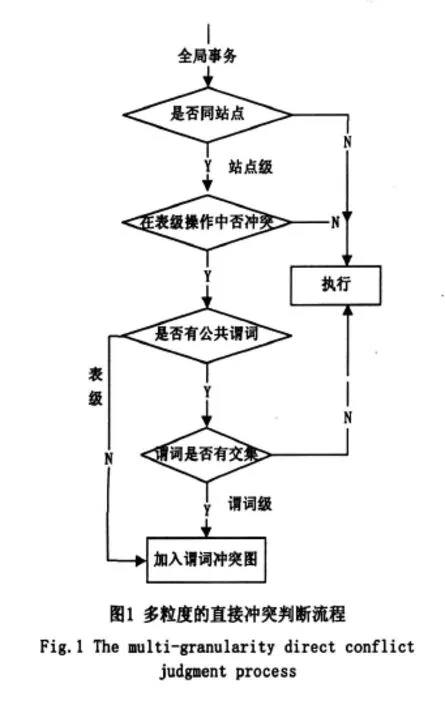
全局事務間基于謂詞的多粒度直接沖突判斷算法流程如圖1所示,該過程不需對具體的沖突對象進行繁瑣的上鎖操作從而減少了系統開銷,因此可以提高事務處理的并發度,使全局事務間直接沖突判斷的粒度能精確到謂詞級。此外,為了方便處理,當SQL語句中沒有分詞條件時,例如insert語句或不帶條件的delete、select和 update語句亦即沒有where條件和having條件時,謂詞的提取粒度就直接限定在表級;如果謂詞級條件不在相同屬性上并且也沒有定義不同屬性列間的相關匹配情況,就無法判斷元組是否有交集,因此也不能縮小檢測粒度,只能在表級判斷是否沖突。
兩個全局事務間的直接沖突雖然通過以上流程實現了多粒度的檢測,但對兩個以上的并發全局事務間的間接沖突是由兩兩全局事務間的直接沖突構成的,因此,全局事務間的間接沖突檢測比較復雜,首先需要在謂詞沖突圖中建立全局事務兩兩之間的直接沖突關系,才能進一步檢測多個并發的全局事務間是否存在間接沖突,若謂詞沖突圖中存在一條從一個全局事務Gi到另一個全局事務Gj間的路徑,Gi和Gj存在間接沖突。此外,謂詞沖突圖還可檢測多個并發全局事務間產生的死鎖。
謂詞沖突中的死鎖檢測:傳統的解決死鎖問題的方法有死鎖預防和死鎖檢測。死鎖預防要求用戶進程事先申報所需的資源或按嚴格的規程申請資源,而死鎖檢測原則上應允許死鎖發生,在適當的時機檢查,若發生死鎖,則設法排除之。預防死鎖與檢測死鎖相比,前者過于保守,導致全局事務的并發度不高。
多個并發的全局事務可能因為直接沖突或間接沖突而形成死鎖,借助謂詞沖突圖中全局事務間的沖突依賴關系需要進一步檢測全局事務是否形成死鎖。
定理1:全局事務間形成死鎖,當且僅當謂詞沖突圖中存在環。
證明:(必要性)如果謂詞沖突圖中存在環,則全局事務會產生死鎖。謂詞沖突圖是一個有向圖,圖中從 i指向j的邊即i→j,表明j被阻塞了并且等待i釋放沖突站點上的某些資源。當存在環時表示存在一條有向路徑并且第一個節點和最后一個節點是重合的,亦即 i→j…k→i,則表明全局事務i與自己產生了間接沖突形成了一個資源等待環,因此就產生死鎖。
(充分性)當全局事務間產生死鎖,則謂詞沖突圖中至少存在一個有向環。當全局事務發生死鎖時,至少存在兩個或以上的事務間彼此等待對方所持有的某些資源,分兩種情況討論:當兩個全局事務i和j間產生死鎖時,在謂詞沖突圖中既存在i→j的有向邊也存在j→i的有向邊表示,因此在圖中形成了有向環;當兩個以上的全局事務間產生死鎖時,例如全局事務i與k之間產生間接沖突時,表明k間接等待i釋放某些資源,則在謂詞沖突圖中存在i→j…→k的有向邊,另由于i也在等待k所持有的某些資源,則在圖中存在k→i,因此綜合可得i→j…→k→i,圖中存在一條有向環。證畢。
全局事務在謂詞沖突圖中形成的環可分為兩類:兩個全局事務由直接沖突形成的環和兩個以上全局事務由間接沖突形成的環。對于一個全局事務只在一個站點上而另一全局事務卻是跨站點執行情況,即如圖2所示。
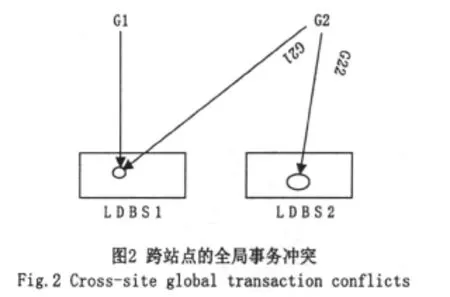
在圖2所示的情況下兩個全局事務不具備成環條件,它們在站點1上產生的沖突可由該站點數據庫處理。
兩個全局事務由直接沖突產生死鎖條件:(1)至少存在兩對或以上的直接沖突。(2)必須存在兩個不同時序關系的沖突對,這樣才可能在謂詞沖突圖中形成環。此外,兩個全局事務間產生的沖突環可分為在同一站點和不在同一站點上兩種情況,如圖3所示。

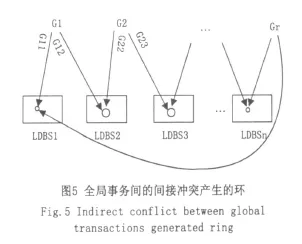
對于全局事務在同一站點上可能形成環的沖突圖,如圖4左分圖不必由集群系統中的事務管理器處理,因為全局事務的子事務都是局部化到一個站點上執行的,而本地站點上的DBMS有相應的并發控制機制。由于本地站點的自治性而無法知道其他站點全局事務間的關系,所以事務管理器需要處理的是在跨站點的全局事務產生的環,而這種環可能是兩個全局事務由直接沖突產生的如圖4右分圖,也可能是由下面將要提到的間接沖突產生的。對于兩個以上的全局事務由間接沖突產生的環,需要檢測謂詞沖突圖中的每個全局事務G是否通過間接沖突與自己沖突即G→Ο→G,那么在兩個以上的全局事務間存在間接死鎖,如圖5所示。圖5對應的間接謂詞沖突如圖6。


集群系統中的事務管理器只處理跨站點的全局事務形成的死鎖,當在謂詞沖突圖中檢測到沖突的全局事務形成環(包括本身形成的間接環如G→…→G和兩個全局事務形成的直接環如G1→G2和G2→G1)時,就需要立即解除死鎖的發生,這里事務管理器采取回滾(rollback)最近加入環的一個全局事務,保證資源利用的最大化。如果事務管理器調度的沖突全局事務在謂詞沖突圖中沒有形成環或無沖突時,就可以繼續發送到底層集群數據庫站點上執行。
2 試驗分析
集群系統中的事務管理器所采用的基于謂詞的多粒度沖突檢測機制不需要對底層數據庫上的數據進行上鎖操作,保證了局部數據庫站點的自治性,從而減少了系統開銷,提高了全局事務處理的并行度。謂詞沖突圖也有效防止了全局事務形成的死鎖,其控制粒度也比事務等待圖更精確,更靈活。另外,事務等待圖只適合單站點數據庫的死鎖檢測,而謂詞沖突圖在基于數據庫集群的多站點間事務全局死鎖檢測中性能表現優良,兩者之間的性能比較如圖7所示。

圖7中的模擬結果表明,當采用兩種不同的方式檢測到死鎖時,都采用回滾最近加入圖中的事務方法來解除死鎖,因此死鎖的效率體現在事務的回滾率上,事務間發生的死鎖越多,回滾率也就越高,事務間的并發度越低。由于兩種方式檢測死鎖的粒度不同從而導致事務的回滾率也不同,從圖中可以看出事務等待圖的執行效率比謂詞沖突圖低,多次試驗表明事務等待圖的事務回滾率都在40%以上,而謂詞沖突圖的回滾率較低,由此導致運行相同時間內,采用謂詞沖突圖成功執行和提交的事務數量較多。此外,本文在集群系統的事務管理器中實現了三級粒度的并發控制:站點級→表級→謂詞級,并對比了只到表級具有兩級粒度的并發控制性能。試驗結果對比可知,表級并發控制的粒度相對于謂詞級的大,體現在事務的回滾率上表級粒度平均在44.11%,而謂詞級則平均為26.01%。由此可見,在運行時間相同的條件下,后者(謂詞級粒度)成功執行和提交的事務數量較多,所以謂詞級多粒度控制的事務并發控制效率比表級有了較大的提高。因此,基于謂詞級的多粒度事務并發控制方法有效提高了全局事務執行的并行度。
3 結束語
集群中各局部站點數據庫的自治性和局部性只能對本地站點上的事務并發控制,而無法保證并發全局事務執行的一致性和正確性,無法防止全局事務間的沖突和死鎖發生,因此在集群系統的事務管理器中實現了全局事務間沖突檢測的多級粒度依次為:站點級→表級→謂詞級。另外,還通過檢測謂詞沖突圖中是否存在環的方法來避免沖突的全局事務可能會產生的全局死鎖。該并發控制方法不需具體的上鎖操作使并發控制粒度達到謂詞級,不僅減小了死鎖檢測粒度而且還提高了全局事務處理的并發度,同時也不需要對局部數據庫做任何限制。
[1] THAKKAR S S,SWEIGERM.Performance of anOLTP application on symmetry multiprocessor system[C] .American:IEEE Computer Society,1990,228-238.
[2] NISHIKAWA H,STEENKISE P.A general architecture for load balancing in a distributed-memory environment[C] .American:IEEE Computer Society,1993,47-54.
[3] DU X,ZHANG X.Coordinating parallel processes on networks ofworkstations[J] .Journal of Parallel and Distributed Computing,1997,46(2):125-135.
[4] LEE J L,SCHEAUERMANN P,VINGRALEK R.File assignment in parallelI/O systems withminimal variance of service time[J] .IEEE Transactions on Computers,2000,49(2):127-140.
[5] LITWIN W,NEIMAT M A,SCHNEIDER D A.LH*-a scalable,distributed data structure[J] .T ODS,1996,21(4):480-525.
[6] KEN BARKER,TAMER M OZSU.Concurrent transaction execution in multidatabase systems[C] .American:IEEE Computer Society,1990,282-288.
[7] ZHANG A,ELMAGARMID A K.On global transaction scheduling criteria in multidatabase systems[C] .American:IEEE Compurter Society,1993,117-124.
猜你喜歡
海峽姐妹(2020年9期)2021-01-04 01:35:44
VOGUE服飾與美容(2020年9期)2020-09-02 14:47:26
財經(2017年15期)2017-07-03 22:40:49
財經(2017年2期)2017-03-10 14:35:35
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
山東青年(2016年1期)2016-02-28 14:25:25
財經(2016年6期)2016-02-24 07:41:51
當代修辭學(2014年3期)2014-01-21 02:30:44
公務員文萃(2013年5期)2013-03-11 16:08:37
