支持向量機(jī)算法的研究及其實(shí)現(xiàn)
2010-10-16 03:55:46范玉妹郭春靜
關(guān)鍵詞:分類
范玉妹,郭春靜
(北京科技大學(xué)應(yīng)用科學(xué)學(xué)院,北京100083)
支持向量機(jī) (support vector machine,SVM)是數(shù)據(jù)挖掘中的一項(xiàng)新技術(shù),是針對(duì)小樣本數(shù)據(jù)提出的,借助于最優(yōu)化方法解決機(jī)器學(xué)習(xí)問(wèn)題的新工具。它最初于20世紀(jì)90年代由Vapnik提出,近年來(lái)在其理論和算法實(shí)現(xiàn)方面都取得了突破性進(jìn)展,開(kāi)始成為克服 “維數(shù)災(zāi)難”和 “過(guò)學(xué)習(xí)”等傳統(tǒng)困難的有力手段。雖然它還處于飛速發(fā)展的階段,但是它的理論基礎(chǔ)和實(shí)現(xiàn)途徑的基本框架已經(jīng)形成。它是建立在統(tǒng)計(jì)學(xué)習(xí)理論基礎(chǔ)之上,對(duì)統(tǒng)計(jì)學(xué)習(xí)理論的發(fā)展起到巨大的推動(dòng)作用并被廣泛應(yīng)用。由于其出色的學(xué)習(xí)性能,該技術(shù)已成為機(jī)器學(xué)習(xí)界的研究熱點(diǎn),并在很多領(lǐng)域都得到了成功的應(yīng)用,如人臉檢測(cè)、手寫(xiě)體數(shù)字識(shí)別、文本自動(dòng)分類等。支持向量機(jī)與其他的學(xué)習(xí)機(jī)相比,具有較好的泛化能力、非線性處理能力和高維處理能力。
1 支持向量分類機(jī)算法研究
1.1 C-SVM算法
標(biāo)準(zhǔn)的C-SVM(C-Support Vector Machines,簡(jiǎn)稱C-SVM)算法是樣本點(diǎn)線性不可分情況下,引入松弛變量后的支持向量分類機(jī)算法。已知訓(xùn)練向量i=1,…,l屬于兩類,即 yi∈{1,-1},把訓(xùn)練數(shù)據(jù)正確分類是指求得的最優(yōu)分類超平面不但要把兩類數(shù)據(jù)正確分開(kāi),而且要使分類間隔最大,引進(jìn)從輸入空間Rn到Hilbert空間H的變換。
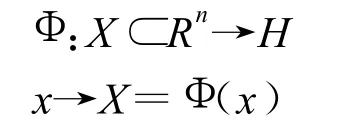
把訓(xùn)練集 T={(x1,y1),…,(xl,yl)}映射為={(x1,y1),…,(xl,yl)}={(Φ(x1),y1),…,(Φ(xl),yl)}。由此得到的初始問(wèn)題為
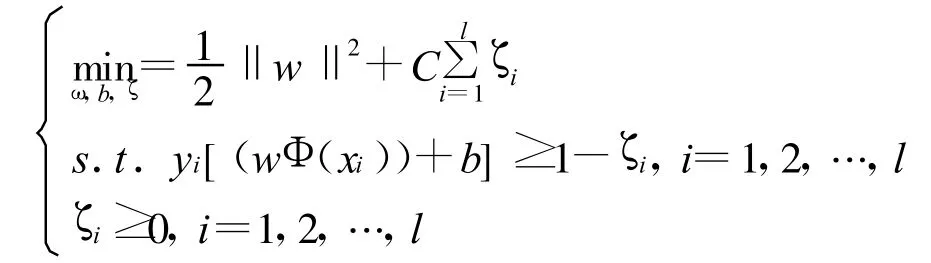
式中 C—懲罰參數(shù),C越大表示對(duì)錯(cuò)誤分類的懲罰越大,它是算法中唯一可以調(diào)節(jié)的參數(shù);ζ—在訓(xùn)練集線性不可分時(shí)引進(jìn)的松弛因子。
1.2 v-SVM算法
v-SVM(v-Support Vector Machines,簡(jiǎn)稱 v-SVM),在2.1中討論的 C-SVM算法中,有兩個(gè)相互矛盾的目標(biāo):最大化間隔和最小化訓(xùn)練錯(cuò)誤。其中常數(shù)C起著調(diào)和這兩個(gè)目標(biāo)的作用。定性地講,C值的含義即選取大的C值,意味著更強(qiáng)調(diào)最小化訓(xùn)練錯(cuò)誤。但定量地講,C值本身并沒(méi)有確切的意義,所以 C值的選取比較困難。為此,Scholkoph提出了v-SVM模型。所謂v-SVM,即針對(duì)C-SVM算法中唯一可以調(diào)節(jié)的參數(shù)C沒(méi)有直觀解釋,在實(shí)際應(yīng)用中很難選擇合適的值,v-SVM中用參數(shù)v取代C。在一定條件下,當(dāng)樣本點(diǎn)個(gè)數(shù)l→∞時(shí),v以1的概率漸近于支持向量個(gè)數(shù)與樣本點(diǎn)個(gè)數(shù)之比。v參數(shù)可以控制支持向量的數(shù)目和誤差,也易選擇。
引進(jìn)從輸入空間到希爾伯特空間的變換,利用這個(gè)變換,由原來(lái)的訓(xùn)練集得到新的訓(xùn)練集
此訓(xùn)練集對(duì)應(yīng)的最優(yōu)化問(wèn)題為
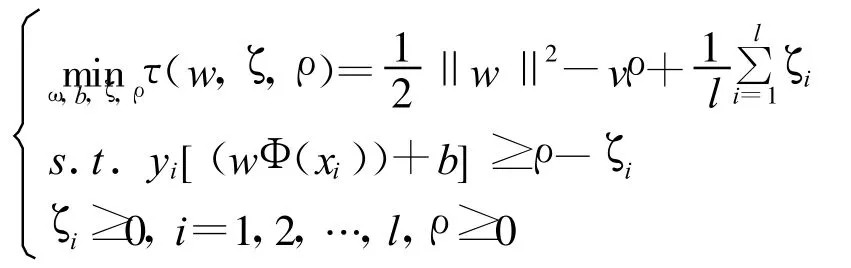
式中 ζ=(ζ1,…,這里不含參數(shù)C,而是換成了參數(shù)v這個(gè)需要實(shí)際選定的參數(shù)。模型中還多了一個(gè)變量 ρ,我們可以注意到當(dāng) ζ=0的時(shí)候,約束條件意味著兩類點(diǎn)以2ρ/‖w‖的間隔被分開(kāi)。
1.3 One-classSVM算法
One-class SVM最初是用于高維分布估計(jì),即用來(lái)尋找超平面VC維的估計(jì)值。對(duì)于沒(méi)有任何分類信息的訓(xùn)練向量∈Rn,i=1,…,l,初始最優(yōu)化問(wèn)題為
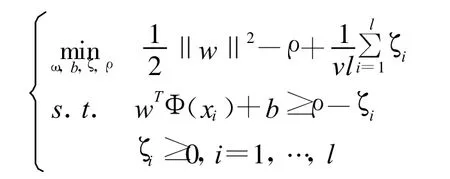
1999年Tax提出用超球面代替超平面來(lái)劃分?jǐn)?shù)據(jù)的想法,改變了數(shù)據(jù)集的描述,目標(biāo)函數(shù)的初始最優(yōu)化問(wèn)題變?yōu)?/p>
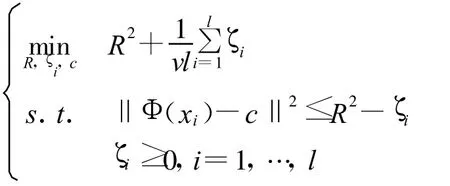
其中R為超球面的半徑,通過(guò)設(shè)定參數(shù)0≤v≤1,使超球面的半徑和它所能包含的訓(xùn)練樣本數(shù)目之間進(jìn)行折衷。當(dāng)v小的時(shí)候,盡量把數(shù)據(jù)放進(jìn)球里面,當(dāng)v大的時(shí)候,盡量壓縮球的尺寸,使用Lagrangian函數(shù)來(lái)解這個(gè)優(yōu)化問(wèn)題。
2 支持向量回歸機(jī)算法的研究
2.1 ε-SVR 算法
ε-SVR采用了ε-不敏感損失函數(shù),所以它有一個(gè)明顯的優(yōu)點(diǎn)即具有稀疏性:所有在ε-帶內(nèi)部的樣本點(diǎn)都不是支持向量,它們對(duì)決策函數(shù)沒(méi)有貢獻(xiàn)。換句話說(shuō),去掉這些樣本點(diǎn),不會(huì)影響最終的決策函數(shù),只有支持向量才會(huì)影響決策函數(shù)。
ε-SVR的原始問(wèn)題如下:
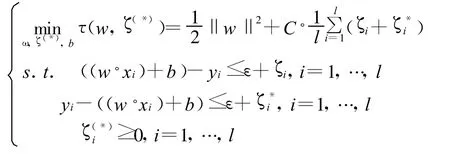
2.2 v-SVR算法
在ε-SVR中,需要事先確定 ε-不敏感損失函數(shù)中的參數(shù)ε。然而在某些情況下選擇合適的ε并不是一件容易的事情。因此,與2.2中的分類算法類似,引進(jìn)參數(shù)v取代ε,構(gòu)造能夠自動(dòng)計(jì)算ε的一種變形算法—v-SVR。引進(jìn)參數(shù)v后,則可將3.1中的最優(yōu)化問(wèn)題修改為如下v-SVR問(wèn)題:
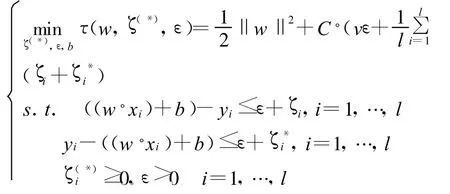
3 仿真實(shí)例及結(jié)果分析
仿真實(shí)例是利用matlab軟件和Libsvm2.89版本來(lái)實(shí)現(xiàn)的,在實(shí)驗(yàn)中所用到的核函數(shù)類型均為徑向基核函數(shù),分類實(shí)驗(yàn)數(shù)據(jù)來(lái)源均為UCI學(xué)習(xí)庫(kù),回歸實(shí)驗(yàn)數(shù)據(jù)來(lái)源為公司實(shí)際數(shù)據(jù)。
3.1 分類實(shí)例及結(jié)果
本文采用一個(gè)大樣本與一個(gè)小樣本數(shù)據(jù)分別用三種不同的算法對(duì)其進(jìn)行訓(xùn)練與預(yù)測(cè)。其中,大樣本數(shù)據(jù)集有 83個(gè)特征,訓(xùn)練集 train1包含1 605個(gè)數(shù)據(jù),測(cè)試集test1包含30 956個(gè)數(shù)據(jù);小樣本數(shù)據(jù)集只有兩個(gè)特征,訓(xùn)練集train2包含500個(gè)樣本點(diǎn),測(cè)試集test2包含362個(gè)樣本點(diǎn)。
從表1我們可以看到采用C-SVC算法對(duì)數(shù)據(jù)train1和test1大樣本數(shù)據(jù)進(jìn)行訓(xùn)練和測(cè)試時(shí),參數(shù)對(duì)(C,γ)的變化對(duì)實(shí)驗(yàn)結(jié)果的影響,最重要的結(jié)果是對(duì)訓(xùn)練集和測(cè)試集的分類正確率。正確率越大,說(shuō)明分類準(zhǔn)確度越高,算法越適用于這個(gè)數(shù)據(jù)集。從表1可看出,此算法對(duì)train1和test1的分類正確率只能達(dá)到80%左右,相對(duì)比較低。此算法中,當(dāng)支持向量個(gè)數(shù)越多時(shí),對(duì)訓(xùn)練集和測(cè)試集的分類正確率都越低,這個(gè)結(jié)果也是符合前面理論部分的,而且,我們看到對(duì)訓(xùn)練集的正確率越高,相應(yīng)的對(duì)測(cè)試集的測(cè)試正確率也越高,這說(shuō)明我們做十折交叉驗(yàn)證實(shí)驗(yàn)得到最優(yōu)參數(shù)對(duì),再選擇最優(yōu)參數(shù)對(duì)進(jìn)行訓(xùn)練得到訓(xùn)練模型,最后用測(cè)試集進(jìn)行測(cè)試是很有必要的。從表1整體來(lái)看,用C-SVC算法對(duì)train1數(shù)據(jù)集進(jìn)行訓(xùn)練支持向量的個(gè)數(shù)很多,正確率不高,對(duì)測(cè)試集test1的分類正確率也不高,說(shuō)明此算法對(duì)所選的大樣本數(shù)據(jù)是不太適用的。
表2反應(yīng)的是采用v-svm算法對(duì)數(shù)據(jù)train1和test1大樣本數(shù)據(jù)進(jìn)行訓(xùn)練和測(cè)試時(shí),參數(shù)對(duì)(v,γ)的變化對(duì)實(shí)驗(yàn)結(jié)果的影響。其中,參數(shù)對(duì)的變化對(duì)訓(xùn)練集及測(cè)試集分類正確率的影響不太明顯,一般在80%左右波動(dòng)。從表2還可看到,當(dāng)選擇參數(shù)不適當(dāng)時(shí),得到的正確率是很低的,如當(dāng)v=0.01,γ=0.1時(shí),對(duì)訓(xùn)練集及測(cè)試集的正確率分別只有57%和30%,這個(gè)結(jié)果是很差的。因此,根據(jù)特定的數(shù)據(jù)集選擇合適的參數(shù)對(duì)進(jìn)行訓(xùn)練是很有必要的。用v-svm算法對(duì)train1數(shù)據(jù)集進(jìn)行訓(xùn)練支持向量的個(gè)數(shù)較多,正確率不高,對(duì)測(cè)試集test1的分類正確率也不高,說(shuō)明此算法對(duì)所選的大樣本數(shù)據(jù)是不太適用的。
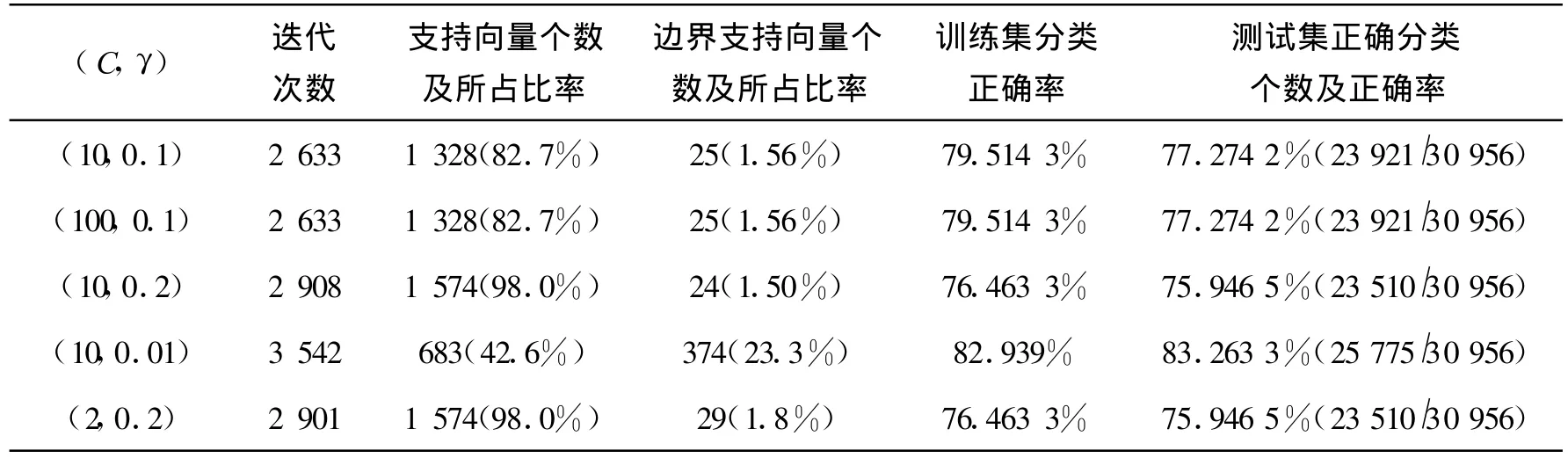
表1 C-SVM算法對(duì)train1和test1的訓(xùn)練和測(cè)試結(jié)果Tab.1 The training and testing results for train1 and test1 with C-SVM algorithm
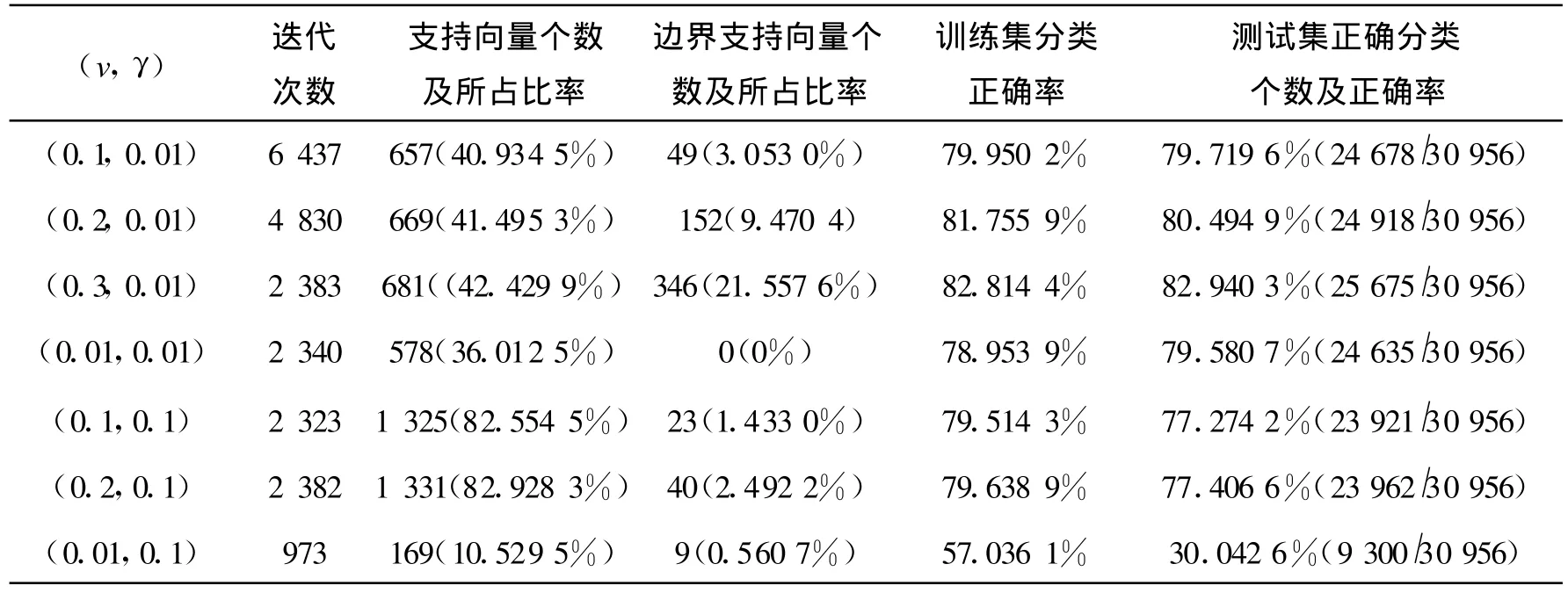
表2 v-SVM算法對(duì)train1和test1的訓(xùn)練和測(cè)試結(jié)果Tab.2 The training and testing results for train1 and test1 with v-SV M algorithm
從表3我們可以看到,此表中的結(jié)果與表1、表2的結(jié)果不太一樣,主要反應(yīng)在對(duì)訓(xùn)練集和測(cè)試集的分類正確率上。如當(dāng)γ都取0.1,v分別取0.01,0.1,0.9時(shí),對(duì)訓(xùn)練集的分類正確率分別為55.977 6%、56.164 4%、72.602 7%,有較大的變化,但對(duì)測(cè)試集的分類正確率都為75.946 5%,沒(méi)有變化,這個(gè)結(jié)果跟其它兩個(gè)算法是不一樣的。當(dāng)γ都取0.01,v分別取0.01,0.1,0.9時(shí),對(duì)訓(xùn)練集的分類正確率分別為26.525 5%、29.078 5%、71.731%,最低為26%,這個(gè)正確率是相當(dāng)?shù)偷?而對(duì)測(cè)試集的分類正確率確有75.365%變化不大。整體來(lái)看,此算法對(duì)train1和test1數(shù)據(jù)集訓(xùn)練和測(cè)試的正確率不高,最低有20%多,最高不到76%,比前面兩個(gè)算法的精度都差。說(shuō)明此算法對(duì)這個(gè)數(shù)據(jù)集很不適用。另外,也反應(yīng)了參數(shù)選擇的重要性,如果參數(shù)選擇不當(dāng),則最后得到的結(jié)果尤其是正確率會(huì)特別不理想。
通過(guò)表1、表2與表3之間的對(duì)比,三個(gè)表反應(yīng)的是三種算法對(duì)大樣本數(shù)據(jù)集的訓(xùn)練和預(yù)測(cè)結(jié)果,參數(shù)的變化對(duì)結(jié)果都有不同程度的影響,說(shuō)明我們?cè)趯?duì)具體的數(shù)據(jù)集進(jìn)行訓(xùn)練和預(yù)測(cè)時(shí)選擇適當(dāng)?shù)膮?shù)的必要性。另外,通過(guò)比較發(fā)現(xiàn),采用C-svm與v-svm算法,正確率最高能達(dá)到83%左右,而采用 one-class svm算法正確率最高不到76%,說(shuō)明對(duì)具體的數(shù)據(jù)集選擇適當(dāng)?shù)乃惴ǖ谋匾?也說(shuō)明了改進(jìn)的算法不一定適合于所有的數(shù)據(jù)集。從以上分析看,這三種算法的訓(xùn)練和測(cè)試正確率并不高,說(shuō)明它們不太適用于大樣本數(shù)據(jù)集。表4采用C-svm算法對(duì)小樣本數(shù)據(jù)集進(jìn)行訓(xùn)練和測(cè)試時(shí),參數(shù)對(duì)(C,γ)的變化對(duì)實(shí)驗(yàn)結(jié)果的影響。從正確率方面看,算法的結(jié)果比較理想,對(duì)訓(xùn)練集的正確率最高達(dá)到了99.6%接近100%,對(duì)測(cè)試集的正確率也達(dá)到了99%以上,此算法對(duì)這樣的小樣本數(shù)據(jù)的擴(kuò)展性很好,但當(dāng)參數(shù)取得不合適時(shí),如 γ=0.9,C=1時(shí),正確率只有80%多,再一次說(shuō)明了參數(shù)選擇的重要性。從表4來(lái)看,用C-SVM算法對(duì)訓(xùn)練集train2數(shù)據(jù)集進(jìn)行訓(xùn)練支持向量的個(gè)數(shù)不多,能達(dá)到的最高正確率很高,對(duì)測(cè)試集test2能達(dá)到的分類正確率也很高,說(shuō)明此算法對(duì)所選的小樣本數(shù)據(jù)是很適用的。
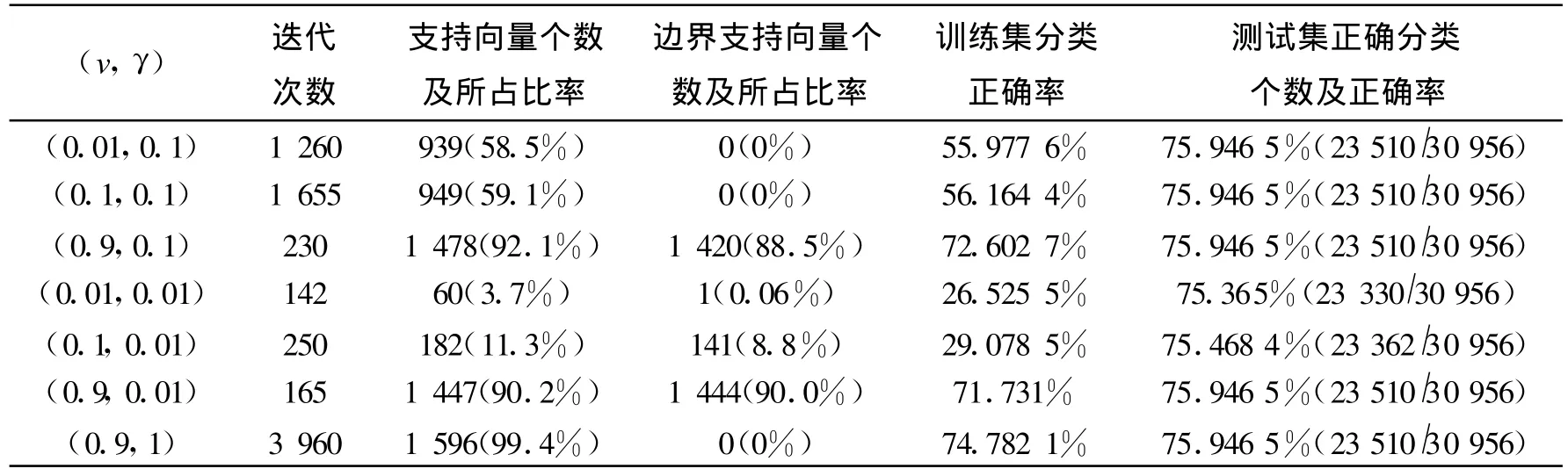
表3 one-class svm算法對(duì)train1和test1的訓(xùn)練與測(cè)試結(jié)果Tab.3 The training and testing results for train1 and test1 with one-class svm algorithm
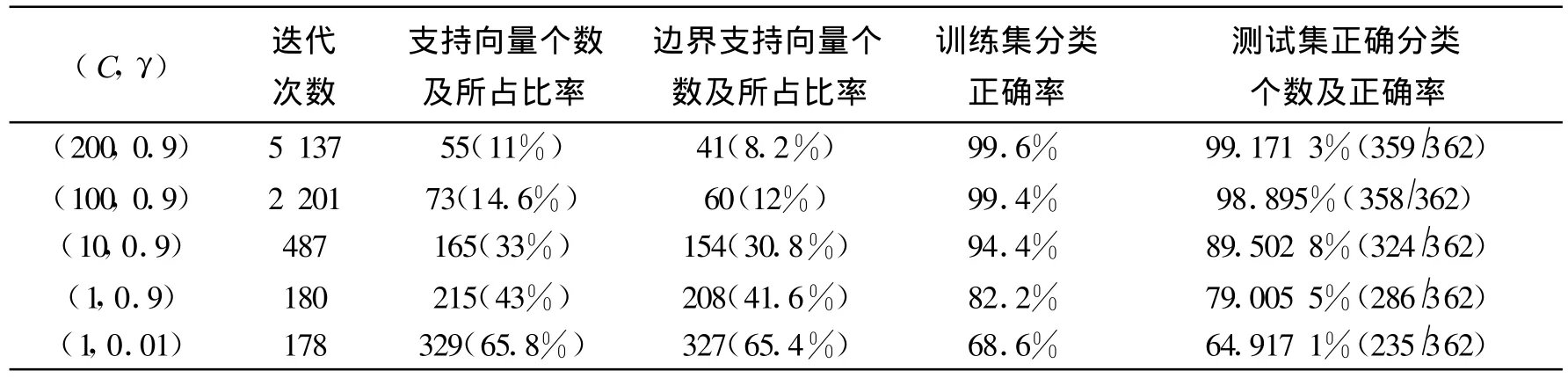
表4 C-SVM算法對(duì)train2和test2的訓(xùn)練和測(cè)試結(jié)果Tab.4 The training and testing results for train2 and test2 with C-svm algorithm
表5反應(yīng)的是采用v-svm算法對(duì)數(shù)據(jù)集train2和test2小樣本數(shù)據(jù)進(jìn)行訓(xùn)練和測(cè)試時(shí),參數(shù)(v,γ)的變化對(duì)實(shí)驗(yàn)結(jié)果的影響。從分類正確率上來(lái)看,參數(shù)的變化對(duì)結(jié)果有明顯的影響,對(duì)訓(xùn)練集和測(cè)試集的最高正確率都達(dá)到了99%以上,而最低分別為50%左右和47%左右。從表5同樣可看到,當(dāng)選擇參數(shù)不適當(dāng)時(shí),得到的正確率是很低的,如當(dāng)v=0.05,γ=0.1時(shí),對(duì)訓(xùn)練集及測(cè)試集的正確率分別只有38%和51%,這個(gè)結(jié)果是很差的。因此,根據(jù)特定的數(shù)據(jù)集選擇合適的參數(shù)對(duì)即進(jìn)行模型選擇進(jìn)行訓(xùn)練是很有必要的。從表5來(lái)看,用v-svm算法對(duì)train2數(shù)據(jù)集進(jìn)行訓(xùn)練支持向量的個(gè)數(shù)不多,能達(dá)到的最高正確率很高,對(duì)測(cè)試集test2能達(dá)到的分類正確率也很高,說(shuō)明此算法對(duì)所選的小樣本數(shù)據(jù)是比較適用的。
表6的結(jié)果與表4、表5的結(jié)果不太一樣。主要反應(yīng)在對(duì)訓(xùn)練集和測(cè)試集的分類正確率上。從表中結(jié)果我們看到,采用one-class svm算法對(duì)train2訓(xùn)練集的正確率最高只能達(dá)到67%左右,對(duì)test2測(cè)試集的正確率最高也只能達(dá)到60%左右,這樣的結(jié)果是很不理想的。從表5可以看到參數(shù)的變化并不能提高正確率,說(shuō)明此算法對(duì)所選取的數(shù)據(jù)集是不適用的。
通過(guò)表4、表5與表6之間的對(duì)比,參數(shù)的變化對(duì)結(jié)果都有不同程度的影響,說(shuō)明我們?cè)趯?duì)具體的數(shù)據(jù)集進(jìn)行訓(xùn)練和預(yù)測(cè)時(shí)選擇適當(dāng)參數(shù)的必要性。另外,通過(guò)比較發(fā)現(xiàn),采用C-svm與vsvm算法,正確率最高能達(dá)到99%以上,而采用one-class svm算法正確率最高不到70%,說(shuō)明對(duì)具體的數(shù)據(jù)集選擇適當(dāng)?shù)乃惴ǖ谋匾?也說(shuō)明了改進(jìn)的算法不一定適合于所有的數(shù)據(jù)集。C-svm與v-svm的訓(xùn)練和測(cè)試正確率都能達(dá)到理想的結(jié)果,說(shuō)明它們適用于這樣的小樣本數(shù)據(jù)集。一般,在實(shí)際問(wèn)題中要具體問(wèn)題具體分析,盡量選擇合適的參數(shù)對(duì),使得正確率盡量高,提高算法的精度。然而,我們可以看到,對(duì)C-svm算法而言,C的變化范圍很大,對(duì)具體實(shí)力來(lái)說(shuō)是比較難選取合適的C值的,v-svm作為C-svm算法的改進(jìn)算法,用參數(shù)v代替參數(shù)C,v的選取相對(duì)較容易且在算法迭代過(guò)程中,C值作為結(jié)果的一部分自動(dòng)計(jì)算。用兩種算法對(duì)小樣本數(shù)據(jù)集的訓(xùn)練結(jié)果正確率都能達(dá)到理想的效果,精確度都很高。
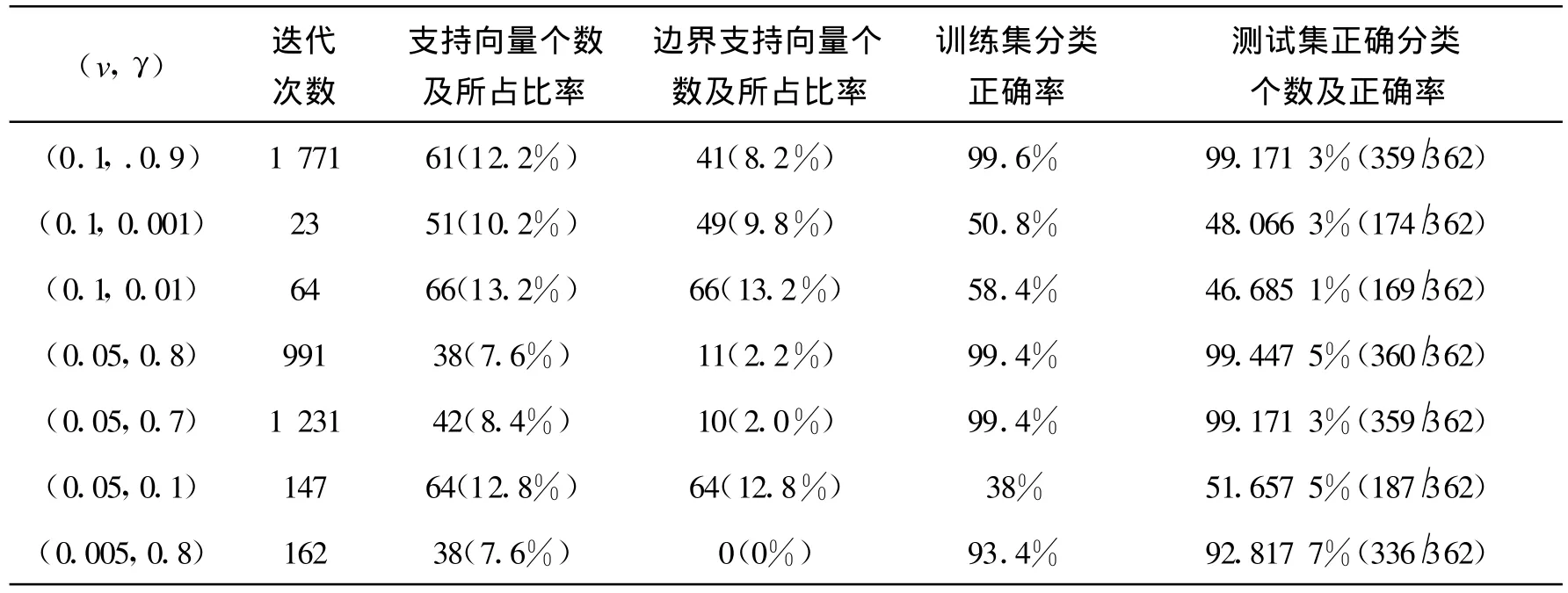
表5 v-SVM算法對(duì)train2和test2的訓(xùn)練和測(cè)試結(jié)果Tab.5 The training and testing results for train2 and test2 with v-svm algorithm
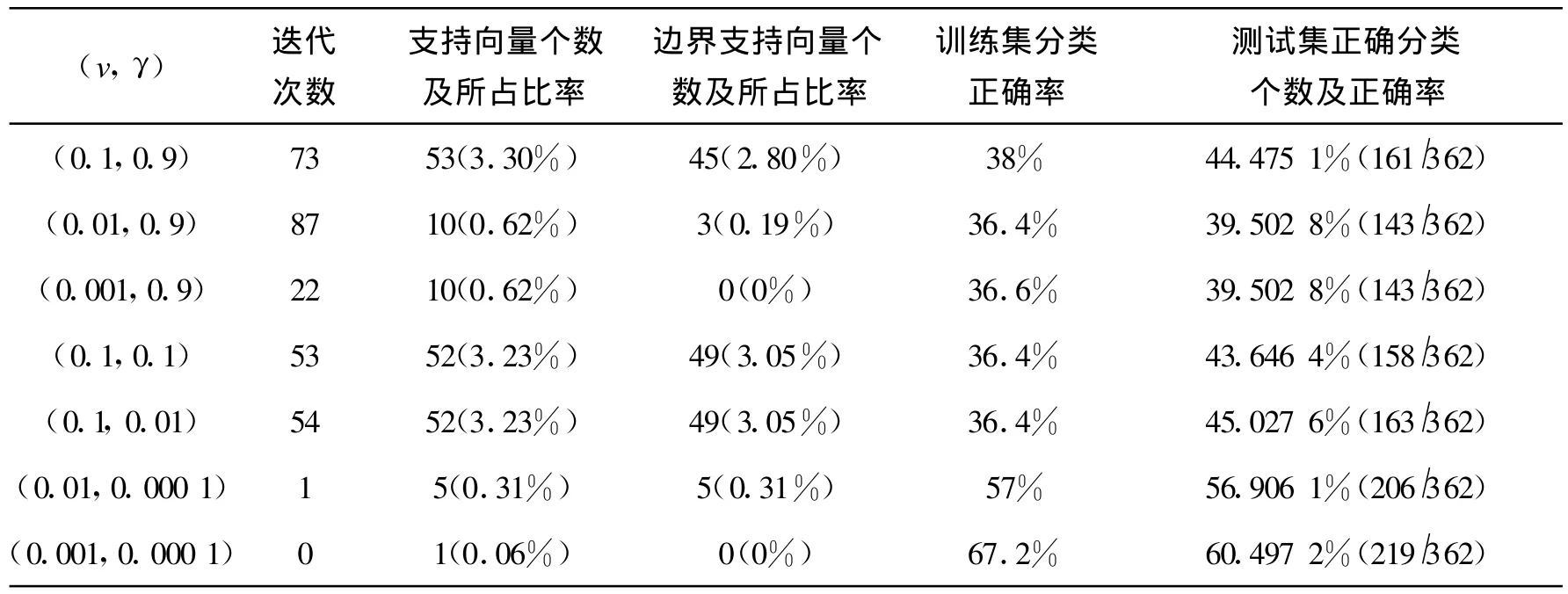
表6 one-class svm算法對(duì)train2和test2的訓(xùn)練和測(cè)試結(jié)果Tab.6 The training and testing results for train2 and test2 with one-class svm algorithm
最后,比較同一種算法對(duì)不同的訓(xùn)練集和測(cè)試集的結(jié)果。通過(guò)表1與表4的結(jié)果我們不難發(fā)現(xiàn),采用C-svm算法不管對(duì)大樣本數(shù)據(jù)集train1、test1還是對(duì)小樣本數(shù)據(jù)train2、test2來(lái)說(shuō),選擇不同的參數(shù)對(duì)對(duì)實(shí)驗(yàn)結(jié)果都有不同程度的影響,而從分類正確率的角度來(lái)看,對(duì)大樣本數(shù)據(jù)集的最高正確率達(dá)到83%左右,對(duì)小樣本數(shù)據(jù)的最高正確率能達(dá)到99%以上,接近100%,這充分說(shuō)明了此算法較適用于小樣本數(shù)據(jù)。同樣,通過(guò)表2與表5的對(duì)比發(fā)現(xiàn)v-svm算法較適用于小樣本數(shù)據(jù)集,只是它在參數(shù)選擇上更容易一些。通過(guò)表3與表5的比較發(fā)現(xiàn),one-class svm算法對(duì)本文選取的大樣本與小樣本數(shù)據(jù)集的分類正確率都不理想,即它對(duì)一般的數(shù)據(jù)集并不適用,還不如最基本的C-svm與v-svm算法效果好。
3.2 回歸實(shí)例及結(jié)果
此部分本文選用公司實(shí)際數(shù)據(jù),數(shù)據(jù)集train3有3個(gè)特征,共有130個(gè)樣本點(diǎn)。
表7反應(yīng)的是采用 ε-SVR算法對(duì)數(shù)據(jù)集進(jìn)行訓(xùn)練時(shí),參數(shù)變化對(duì)實(shí)驗(yàn)結(jié)果的影響。最重要的結(jié)果是均方誤差和平方相關(guān)系數(shù),其中均方誤差越小,說(shuō)明回歸的準(zhǔn)確度也越高,即擬合曲線與實(shí)際的越接近,平方相關(guān)系數(shù)的大小是對(duì)變量與特征之間的相關(guān)程度的一種度量,其值越大即越接近1,表示變量與特征之間相關(guān)程度也越大。從表8的結(jié)果可以看到,γ一定C變化時(shí),對(duì)均方誤差和平方相關(guān)系數(shù)沒(méi)有影響。均方誤差的值很小,都為0.004 054 63,說(shuō)明此算法對(duì)train4的訓(xùn)練結(jié)果準(zhǔn)確度較高。平方相關(guān)系數(shù)的值都為0.976 418,比較接近1,說(shuō)明變量與三個(gè)變量間的相關(guān)程度很高。當(dāng)均方誤差越小時(shí),平方相關(guān)系數(shù)相對(duì)變大,這也是符合實(shí)際情況的,當(dāng)均方誤差越小時(shí),說(shuō)明算法回歸的準(zhǔn)確度越高,自然變量與特征之間的平方相關(guān)系數(shù)越大。
從表8的結(jié)果可以看出v一定γ變化時(shí),對(duì)均方誤差的影響并不明顯,其值基本在0.001左右波動(dòng),但也有特殊情況,如 γ=0.01時(shí),均方誤差達(dá)到了0.018,γ對(duì)平方相關(guān)系數(shù)的影響也不太明顯,其值都在0.9以上,但整體來(lái)說(shuō)平方相關(guān)系數(shù)的值很接近1,說(shuō)明變量與特征之間的相關(guān)程度很高。對(duì)均方誤差、平方相關(guān)系數(shù)結(jié)果無(wú)明顯影響。從以上分析可以看出,此算法對(duì)train4數(shù)據(jù)集的訓(xùn)練結(jié)果是比較穩(wěn)定的,無(wú)明顯偏差。
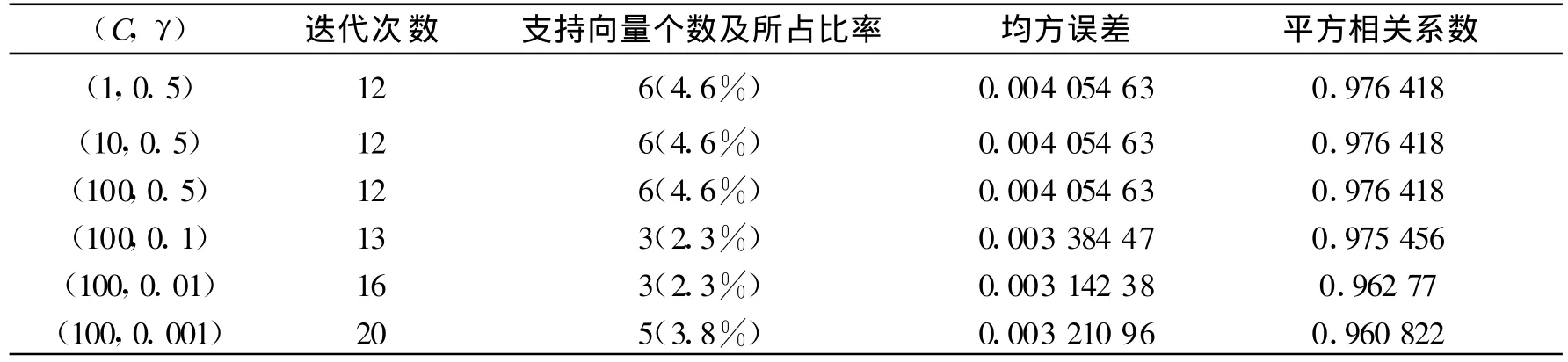
表7 ε-SVR算法對(duì)train4的訓(xùn)練結(jié)果Tab.7 The training results for train4 with ε-SVR algorithm
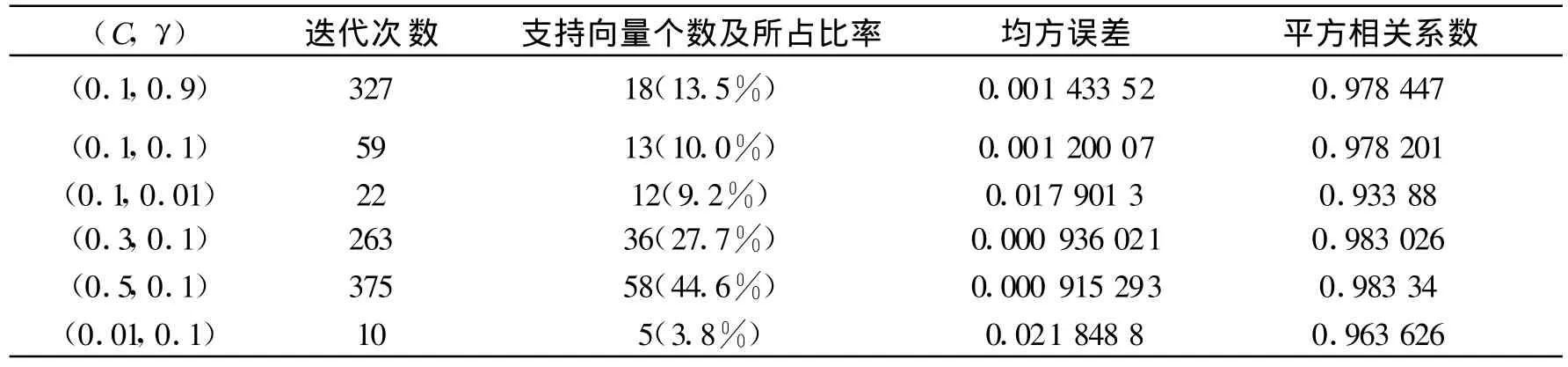
表8 v-SVR算法對(duì)train4的訓(xùn)練結(jié)果Tab.8 The training results for train4 with v-svr algorithm
從表7與表8的結(jié)果對(duì)比發(fā)現(xiàn),無(wú)論是ε-svr還是v-svr算法,選取不同的參數(shù)對(duì)對(duì)實(shí)驗(yàn)結(jié)果都有不同程度的影響。因此,在實(shí)際問(wèn)題中要具體問(wèn)題具體分析,盡量選擇合適的參數(shù)對(duì),使得均方誤差盡量小,提高算法的精確度。對(duì)ε-svr算法而言,C的變化范圍很大,對(duì)具體實(shí)例來(lái)說(shuō)是比較難選取合適的C值的,作為ε-svr算法的改進(jìn)算法,用參數(shù)v代替參數(shù)C,v的選取相對(duì)較容易且在算法迭代過(guò)程中,C值作為結(jié)果的一部分自動(dòng)計(jì)算。用兩種算法對(duì)train4這個(gè)小樣本數(shù)據(jù)集的訓(xùn)練結(jié)果均方誤差都很小,精確度都很高,而且當(dāng)參數(shù)變化時(shí),對(duì)均方誤差的大小無(wú)明顯影響,說(shuō)明算法都比較穩(wěn)定。
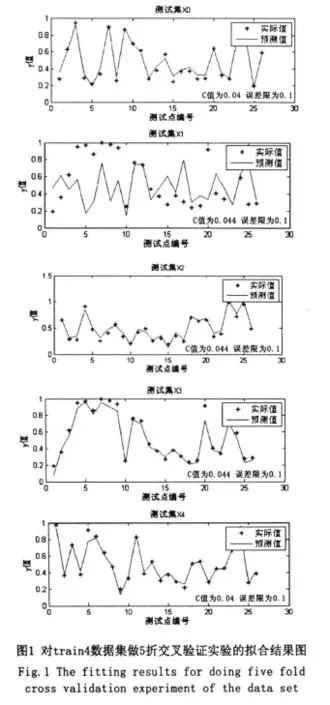
用Matlab實(shí)現(xiàn)ε-SVR算法,對(duì)train4數(shù)據(jù)集做5折交叉驗(yàn)證實(shí)驗(yàn)的擬合結(jié)果如圖1所示。
4 結(jié)論
1)標(biāo)準(zhǔn)的支持向量機(jī)C-SVM是一個(gè)基礎(chǔ)算法,可以對(duì)所有的數(shù)據(jù)進(jìn)行分類。但是,從正確率來(lái)看,比較適用于小樣本數(shù)據(jù)集。
2)v-SVM中支持向量的取值可以通過(guò)選擇合適的v來(lái)得到一個(gè)好的結(jié)果,但是對(duì)于大樣本問(wèn)題還是需要核函數(shù)中參數(shù)的調(diào)節(jié)才能得到比較滿意的結(jié)果。
3)One-class SVM對(duì)一般數(shù)據(jù)集的分類正確率并不高,所以不適用于一般的數(shù)據(jù)集。
4)對(duì)于所選取的小樣本數(shù)據(jù)集,兩種回歸算法的結(jié)果都是比較理想的,即分類均方誤差較小,平方相關(guān)系數(shù)都接近1,且結(jié)果隨參數(shù)對(duì)的變化是不明顯的,算法比較穩(wěn)定。
5)不論分類算法還是回歸算法,參數(shù)的變化對(duì)實(shí)驗(yàn)結(jié)果都有不同程度的影響。
[1] 鄧乃楊,田英杰.數(shù)據(jù)挖掘中的新方法-支持向量機(jī)[M] .北京:科學(xué)出版社,2004.
[2] 云潛,張學(xué)工.支持向量機(jī)函數(shù)擬合在分形插值中的應(yīng)用[J] .清華大學(xué)學(xué)報(bào)(自然科學(xué)版),2000,40(3):76-78.
[3] 劉華富.一種快速支持向量機(jī)分類算法[J] .長(zhǎng)沙大學(xué)學(xué)報(bào),2004,17(7):40-41.
[4] VAPNIK N.The nature of statistical learning theory[M] .New York:Springer-Verlag,1995.
[5] REYZIN L,SCHAPIRE R E.How boosting the margin can also boost classifier complexity[C] //ICML'06,the 23rd Int.Conf.,on MachineLearningPittsburgh,Pennsylvania,USA,2006:753-760.
[6] PLATT J.Fast training of support vector machines using sequential minimal optimization[C] //in Advances in Kernel Methods--Support Vector Learning,B.Schoelkopf,C.Burges,and A.Smola Eds.,1999:185-208.
[7] VAPNIK V.Statistical learning theory[M] .New York:John Wiley&Sons,1998.
[8] COTTES C,VAPNIK V N.Support vector networks[M] .Mach Learn,1995.
[9] YU H,YANG J,HAN J.Classifying large data sets using SVMswith hierarchical clusters[C] //in proc.of the ACM SIGKDD Int.Conf.on KDD,2003:306-315.
猜你喜歡
西北民族大學(xué)學(xué)報(bào)(自然科學(xué)版)(2021年4期)2021-12-29 02:54:24
數(shù)學(xué)小靈通(1-2年級(jí))(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
小聰仔(科普版)(2020年12期)2021-01-18 09:16:52
東方少年·布老虎畫(huà)刊(2020年4期)2020-06-08 15:48:10
學(xué)生天地(2019年32期)2019-08-25 08:55:22
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2019年4期)2019-05-20 10:06:32
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2018年6期)2018-06-26 08:36:06
小天使·一年級(jí)語(yǔ)數(shù)英綜合(2017年11期)2017-12-05 18:49:56
初中生世界·七年級(jí)(2017年9期)2017-10-13 22:27:46
