支持多程序語言的靜態信息提取方法
2011-03-12 14:05:00王甜甜蘇小紅馬培軍
哈爾濱工業大學學報 2011年3期
逄 龍,王甜甜,蘇小紅,馬培軍
(哈爾濱工業大學計算機科學與技術學院,150001哈爾濱,hitpanglong@163.com)
代碼靜態分析已經廣泛應用于程序理解、軟件缺陷檢測、程序驗證等方面.靜態信息提取是代碼靜態分析的基礎,是將代碼文本轉換為可分析處理的中間邏輯表示結構的過程,其所支持解析的程序語言種類、生成的中間表示的表達能力都極大影響靜態代碼分析的應用范圍.當前主要采用的方法為:1)Yacc類語法生成解析器[1-2].該方法語言適應能力強,但后續語法的消歧和調試開銷大,中間表示結果單一;2)專用前端解析,如CIL,Clang等[3-4],文檔完整,但支持語言單一,需其他預處理工具支持,中間表示單一;3)對編譯器擴展[5-6],應用便捷,但對編譯器內部已有功能重用率低,執行效率不高;4)解析編譯器中間調試文件,重構中間表示[7-10],支持多種語言,但實現復雜,后續測試開銷大.
為了支持多語言解析,并提供統一且具備不同表達能力的中間表示,滿足健壯性和穩定性的要求,通過在代碼級別改造開源GCC編譯器來實現靜態信息的提取.該編譯器應用廣泛、成熟可靠,所以在此基礎上改造可以降低后續分析程序的復雜度,但這種方法的主要難點是代碼規模較大、整體復雜、文檔不完整、代碼的設計目標與靜態分析的目標不同,因而需要針對靜態分析的目標在代碼級別對其進行修改.本文首先對靜態信息所依賴的GCC源代碼內部運行過程和相關機制進行分析,然后針對類型和函數聲明定義、函數體內語句遍歷和中間表示訪問等靜態信息,在GCC編譯器的不同階段提出了運行改入點和內部輔助函數相結合的提取方法,并給出整體的修改、應用流程,最后通過提取典型靜態信息的對比實驗,表明該方法提高了執行效率,增強了靜態信息提取的可靠性.
1 與靜態信息提取相關的GCC源代碼分析
GCC-4.3.0編譯器整體結構如圖1所示.整體劃分為3層:前端解析源代碼、中端負責機器無關的優化和后端負責目標機器相關的優化和變換.源代碼在前端生成原始中間表示后,通過后續的層間流轉、層內變換和處理,最終生成目標代碼.本文主要針對與靜態信息提取相關的前端、中端和涉及的中間表示進行分析.
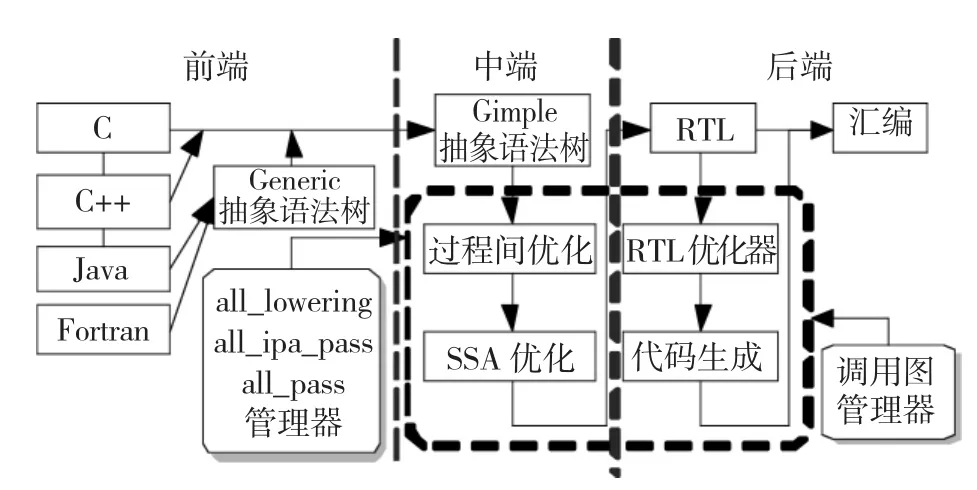
圖1 GCC編譯器結構框圖
1.1 整體流程
編譯器GCC開始執行后,針對編譯對象的不同程序語言,調用對應語言前端解析,將該編程語言源代碼文本解釋為與語言相關的抽象語法樹形式的中間表示.經前端genericize函數去除語言相關性的節點,轉換為Generic形式或直接為Gimple形式,輸入中端進行優化處理.中端優化包括與目標機器無關的過程間和過程內優化.調用圖管理器負責維護中間表示的過程間調用結構邏輯關系,用以管理過程間優化處理的中間結果,遍管理器負責維護編譯器內對中間表示進行優化處理的各步驟定義、依賴關系和調用順序,用以指導優化處理次序.
1.2 中間表示
GCC內部中間表示是各層間流轉和層內處理對象的重要數據結構,根據不同處理階段轉換為特定形式,同時也是靜態信息提取的直接來源,所蘊含靜態信息的質量和結構組織的復雜性決定著靜態信息提取方法的質量和效率.GCC前端和中端主要采用抽象語法樹、Generic、Gimple和SSA這4種形式中間表示.
抽象語法樹是經過解析源代碼文本后得到與之直接對應的邏輯結構,與語言相關.Generic形式是對抽象語法樹的簡化,統一語句結構,去除語言的相關性,包含副作用(Side Effect).Gimple形式是在Generic形式的基礎上限制每條語句的操作數<3的一種約簡,簡化了復雜表達式結構,引入中間臨時變量.SSA形式是在Gimple基礎上增加數據流信息的一種中間表示,在每次賦值時,對左邊變量都增加序號加以辨別,而且后續讀取該變量的表達式直接指向該變量序號的定義處.SSA和Gimple均適合作為靜態信息提取的中間表示.
1.3 遍(Pass)
在GCC優化中,對編譯單元(函數或文件)的一次遍歷處理,稱為遍(Pass).GCC“遍管理器”是對遍定義、組織和執行而實施管理的一組機制.根據靜態信息種類,提取過程可抽象為遍,通過在合適的步驟后對合適的中間表示遍歷來實現,這樣可以重用GCC內部已經提供的通用功能和信息,如冗余代碼去除、控制流圖、數據依賴等.GCC通過遍來關聯中端和后端內具體的優化處理步驟,遍的機制分為3個部分:遍的定義、遍的組織和遍的執行.
2 靜態信息提取
在分析與靜態信息提取相關的GCC內部代碼組織機制的基礎上,根據信息來源,給出確切的改入點,結合內部輔助函數從獲得的中間表示中提取所需信息.核心思想是在GCC運行過程中,在合適的位置得到合適的中間表示,使用合適的方法提取靜態信息.
2.1 改入點
改入點是修改GCC源代碼的位置,因為不同改入點會獲得不同中間表示,如圖2所示.
1)遍改入點.通過GCC內部遍機制,以遍歷函數體內語句方式來提取靜態信息.因為遍管理器處于編譯器中端和后端部分,獲得語言無關的中間表示,所以遍改入點可直接應用于編譯器所支持語言.根據所需提取靜態信息種類和GCC已定義遍所提供的不同中間表示,在適當類型的遍中適當順序位置處加入自定義遍.在圖2中0處 init-optimization-passes,初始化遍組織關系:低級化遍(all-lowering-passes)、過程遍(all-ipa-passes)和所有遍(all-passes).
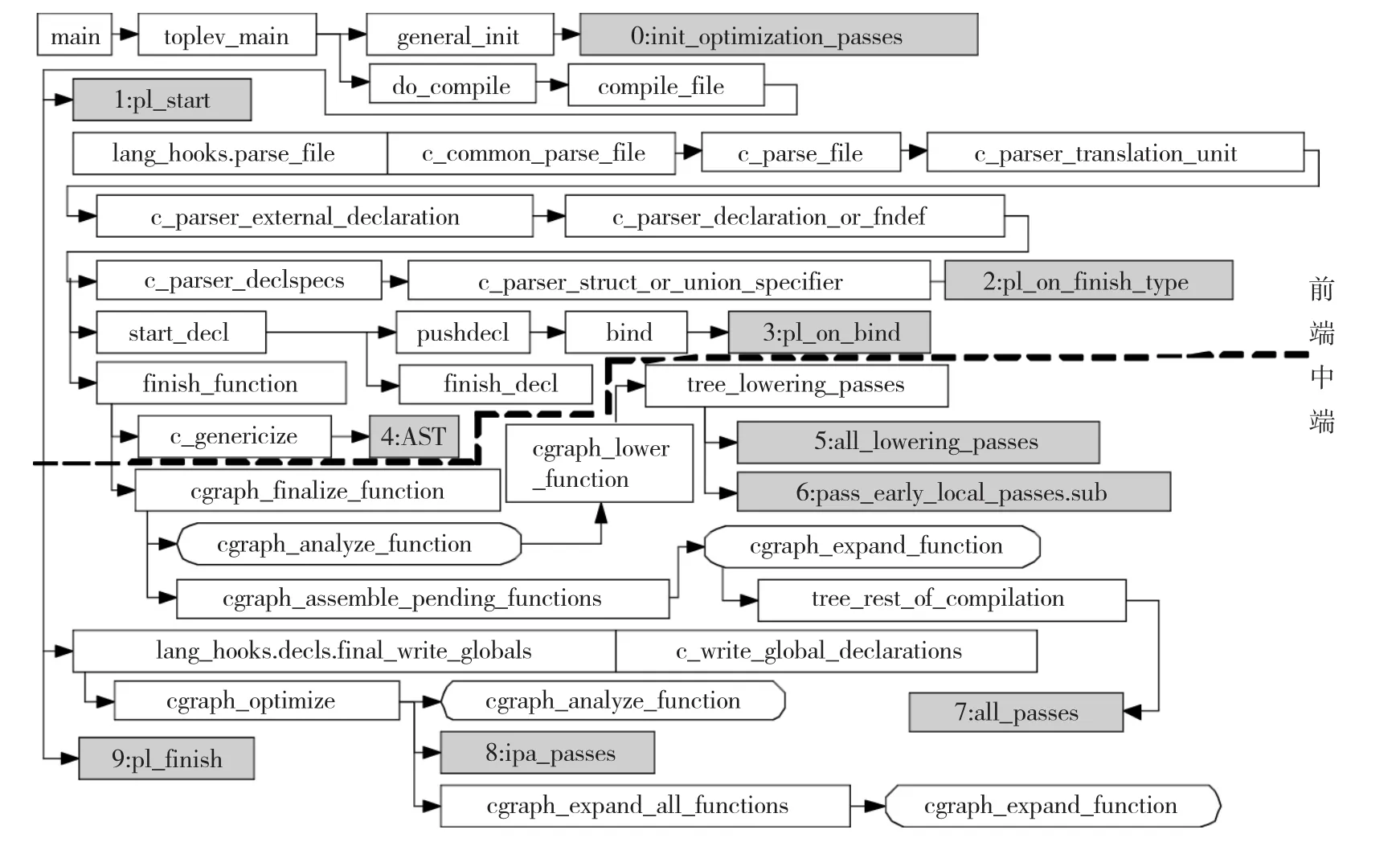
圖2 GCC 中語言前端和統一中端調用圖
為獲得Gimple形式中間表示,在低級化遍中的pass-build-cfg遍后增加自定義遍.為獲得數據流相關的中間表示,在過程間遍中的pass-earlywarn-uninitialized遍后增加改入點.其中:passbuild-cfg遍已經建立了過程內控制流圖和基本塊,通過遍歷程序基本塊間關系和塊內語句可獲得初步的Gimple格式的統一中間表示;pass-remove-useless-stmts遍去除無用冗余的語句;passearly-warn-uninitialized遍檢測使用未初始化變量情況;pass-build-ssa遍建立了SSA的中間表示,通過遍歷定義-使用鏈獲得數據流相關信息.
調用改入點是GCC調用內部遍的位置,可根據需要調整具體調用次序.在圖2中,獲取Gimple的自定義遍從屬于低級化遍,在5處調用.獲取SSA的自定義遍從屬于過程間遍的第2層子遍pass-early-local-passes,在6處和8處調用.所有遍在7處調用.
2)解析相關改入點.通過GCC前端解析提取語言相關靜態信息.
復合類型改入點為獲得結構體、聯合體和類的類型定義相關靜態信息.在聲明與函數定義翻譯單元加入改入點.在C語言前端的c-parserstruct-or-union-specifier函數內1 979行處增加改入點,該處獲得的是解析出的類型定義,如圖2中2所示.在C++語言前端(cp/Class.c)的finish-struct-1函數返回前增加改入點,以獲得類定義中的域相關靜態信息.
標識符改入點為獲得全局變量相關靜態信息.GCC的標識(Identity,ID)為3類:位置標簽、復合類型名和和其他ID.ID通過struct c-binding與具體中間表示關聯,以作用域(struct c-scope類型)為集合通過鏈表方式存儲.在關聯函數bind內加入改入點,如圖2中3所示.
原始中間表示改入點為獲得抽象語法樹等靜態信息.GCC通過lang-hooks類型定義各語言解析、后端處理等入口函數.C語言中,在c-genericize函數中,加入改入點,如圖2中4所示,獲得原始抽象語法樹中間表示.C++語言中,在cp/ decl.c的finish-function中調用cp-genericize函數前增加改入點,獲得原始抽象語法樹中間表示.
3)輔助改入點.為后續分析處理傳遞提取的靜態信息,在翻譯單元編譯開始前和結束后進行必要的初始化和終結工作,在調用語言類函數指針前和之后增加改入點,如圖2中1和9處所示.此處可以負責處理文件描述符、過程間通訊和數據庫操作等與外界交換信息的建立與消解,還可以設置初始化環境等.
2.2 輔助函數
輔助函數是在特定改入點獲得對應中間表示后,根據靜態信息種類和GCC代碼內部組織機制,來提取所需靜態信息的具體方法.
1)位集合操作.數據流分析經常使用集合操作,GCC內部實現了集合相關操作運算的抽象數據類型sbitmap,定義包含在Sbitmap.h內;提供基于位內部表示和相關操作,初始化與可變長度調整:sbitmap-alloc、sbitmap-resize;集合運算操作: sbitmap-difference、sbitmap-not;向量位集操作: sbitmap-vector-alloc;位集合設置內聯函數:SETBIT、sbitmap-iter-init等.
2)輔助信息遍歷.輔助信息包括控制流圖和數據流信息.低級化遍中建立控制流圖,在所有遍生成的SSA中間表示蘊含數據流信息.struct basic-block-def和struct edge-def定義了基本塊和邊.以ENTRY-BLOCK-PTR宏獲得入口基本塊開始,以FOR-EACH-BB宏基本塊間流轉,實現基本塊遍歷.在基本塊內,bsi-start獲得塊內首語句,bsi-next獲得下一條語句和bsi-end-p判定塊內語句結束與否來實現基本塊內語句遍歷. walk-use-def-chains函數遍歷數據流信息.
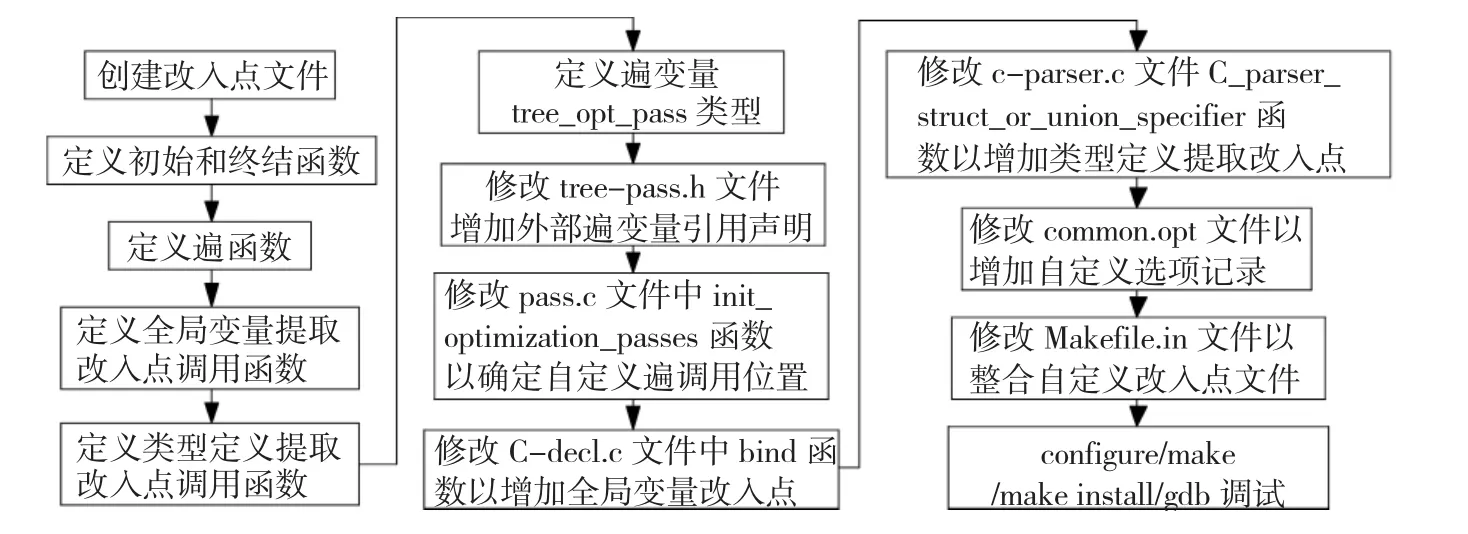
圖3 修改GCC源代碼提取靜態信息過程圖
3)表達式遍歷.遍歷表達式中的操作數來提取變量訪問.walk-tree函數遍歷抽象語法樹表達式;walk-stmts函數遍歷Gimple形式表達式,提供了賦值表達式中區別左邊和右邊表達式的標志.FOR-EACH-SSA-TREE-OPERAND配合類型標志位組合遍歷SSA操作數.
4)中間表示節點訪問.抽象數據類型tree統一表達各種中間表示,提供了對應訪問函數. TREE-CODE宏獲得節點種類;TREE-OPERAND獲得節點下指定操作數;針對COMPONENT-REF類型節點,DECL-CONTEXT獲得其域變量所屬類型;TYPE-NAME獲得變量的類型節點; DECL-NAME獲得類型節點名稱,如在C語言中typedef定義的類型名稱;IDENTIFIER-POINTER獲得具體ID字符串;TYPE-FIELDS獲得結構體或聯合體內域的列表.
2.3 其他相關修改
在特定修改點利用輔助函數獲取了所需的靜態信息后,需要通過修改配置文件實現與GCC的整合.修改GCC源代碼提取靜態信息的整體過程如圖3所示.
1)控制選項配置修改.是外部調用GCC可設置的參數,通過添加與控制靜態信息提取相關選項來控制是否運行.為便于控制,利用增加common.opt文件中選項定義記錄的方式來控制是否運行靜態信息提取.
2)工程配置修改.將自定義的文件通過編譯、鏈接整合到GCC.首先增加生成該源代碼文件的目標文件的依賴關系,然后將此目標文件加入OBJS-common所依賴列表中實現整合.
3 結果與分析
為了驗證本文所提出方法的有效性、效率和健壯性,在2.6 GHz主頻CPU、2 GB內存和Ubuntu 9.10操作系統的測試環境下,分別按本文方法和CIL方法,提取結構體域變量讀、寫和函數訪問等靜態信息,應用于5個開源軟件進行測試,測試結果如表1所示.其中通過UCC統計代碼規模,Linux系統指令time統計運行時間.
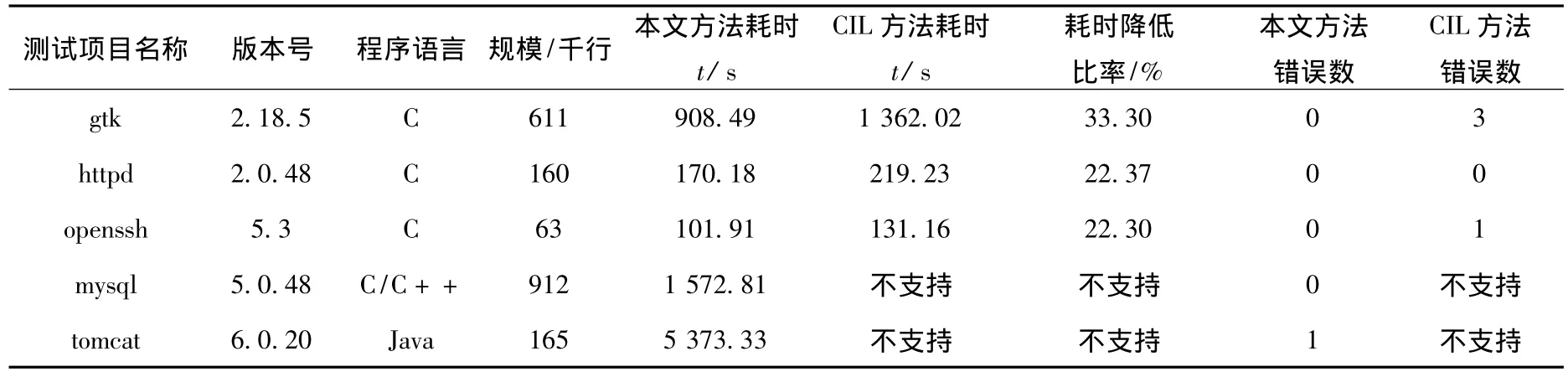
表1 實驗結果對比表
如表1所示,由于本文方法是在GCC源碼級上修改,所以繼承了GCC特點,在支持語言、耗時和錯誤數方面優于CIL方法.CIL方法由于對擴展語法支持不完備而發生的錯誤有:openssh中對64位整數常量不能識別;gtk中可變參數無法定義別名屬性.由于GCC對Java擴展庫實現不完整,導致本文方法提取tomcat時部分依賴于此的文件無法編譯,但可以利用Open Java對應庫文件替換予以解決.本文方法在處理Java語言時,較C語言耗時較大,主要由于前端頻繁啟動虛擬機造成的,通過改進前端工作方式降低耗時.CIL方法由于對編譯器參數處理不完善,導致分析gtk項目時,無法自動完成需手工干預,易用性方面弱于本文方法.
4 結論
1)一次實現后可支持多語言前端,可直接應用于C/C++/Java等主流編程語言.
2)通過增加參數選項,按項目配置文件自動執行靜態信息提取.
3)重用了GCC內前端和中端組織機制,避免了重復實現,保證了效率、健壯性和穩定性.
[1]TERENCE P.The Definitive ANTLR Reference:Building Domain-Specific Languages[M].Raleigh,Dallas: Pragmatic Bookshelf,2007.
[2]SCOTT M,GEORGE N.Elkhound:A fast,practical glr parser generator[C]//Proceedings of the 13thInternational Conference on Compiler Construction.Barcelona: EATCS,EASST,EAPLS,ACM,2004:325-336.
[3]GEORGE C N,SCOTT M,SHREE P R,et al.CIL:Intermediate language and tools for analysis and transformation of C programs[C]//Proceedings of the 11thInternational Conference on Compiler Construction.Grenoble: EATCS,EASST,EAPLS,ACM,2002:213-228.
[4]CHRIS L,VIKRAM A.LLVM:A compilation framework for lifelong program analysis&transformation[C]// Proceedings of the international symposium on Code generation and optimization.PaloAlto:ACM,2004:75-92.
[5]SEAN C,DANIEL J D,EREZ Z.Extending GCC with modular gimple optimizations[C]//Proceedings of GCC Developers’Summit.Ottawa:Linux Symposium,2007: 31-37.
[6]TARAS G,DAVID M.Using GCC instead of grep and sed[C]//Proceedings of GCC Developers’Summit.Ottawa:Linux Symposium,2008:21-32.
[7]李鑫,王甜甜,蘇小紅,等.消除GCC抽象語法樹文本中冗余信息的算法研究[J].計算機科學,2008,35(10):170-172.
[8]KRAFT A,MALLOY A,POWER F.A tool chain for reverse engineering C++applications[J].Science of Computer Programming,2007,69(13):3-13.
[9]GSCHWIND T,PINZGER M,GALL H.TUAnalyzeranalyzing templates in C++code[C]//Proceedings of the 11thWorking Conference on Reverse Engineering. Delft:IEEE,2004:48-57.
[10]ANTONIOL G,DIPENTA M,MASONE G,et al. Compiler hacking for source code analysis[J].Software Quality Journal,2004,12(4):383-06.
猜你喜歡
文苑(2020年4期)2020-05-30 12:35:30
小學生作文(中高年級適用)(2018年3期)2018-04-18 01:24:47
中華手工(2017年2期)2017-06-06 23:00:31
華北電力大學學報(社會科學版)(2016年4期)2016-12-01 03:59:30
山東青年(2016年1期)2016-02-28 14:25:25
少兒科學周刊·少年版(2015年4期)2015-07-07 21:11:17
中外會展(2014年4期)2014-11-27 07:46:46
當代修辭學(2014年3期)2014-01-21 02:30:44
公務員文萃(2013年5期)2013-03-11 16:08:37
海外英語(2006年11期)2006-11-30 05:16:56
