完全支持數據更新的XML壓縮編碼
2011-11-24 07:06:52劉先鋒張楚才
湖南師范大學自然科學學報 2011年6期
周 舟,劉先鋒,劉 萍,張楚才
(湖南師范大學數學與計算機科學學院,中國 長沙 410081)
目前,XML被認為是互聯網上的數據表示和數據交換的標準,并被大家廣泛接受,越來越多的網上資源以XML的格式來表示.如何對這些XML數據進行有效地管理就成為一個重要的研究內容,人們針對XML的查詢要求提出了一些如Xpath和Xquery查詢語言.但這些查詢語言都有一個共同的不足:當XML頻繁地發生諸如刪除、插入等更新操作時,需要重新建立索引或重新編碼,更新代價極大.因些找到一種編碼占用存儲空間小,支持結點無限更新而查詢效率又高的XML編碼方法就迫在眉睫.
本文提出了一種新的壓縮編碼方法,具體在于:
(1) 提出了一種新的XML 壓縮編碼方法,該編碼方法利用了分數特點和路徑編碼方案的優點.
(2) 編碼占用存儲空間小.目前XML文檔越來越大,提高存儲空間的利用率十分必要.該壓縮編碼方案將結點名,結點值和路徑分別保存在不同的表中,并將其編號,這樣可以避免記錄相同的結點名,結點值和路徑,提高了存儲空間的利用率.
(3) 支持數據無限更新.該編碼利用分數的特點即在任意兩個分數間可以插入無窮多個分數,支持兩結點間的任意操作,而不需要二次編碼,是真正意義上的支持動態更新.
(4) 查詢效率高.該編碼將每一個結點的路徑保存在一個表中,并將其路徑編號,避免了以往查詢算法的結構連接,且不受路徑表達式長度和中間結果的影響,從而提高了查詢效率.
1 背景知識和相關工作
為了解決XML更新帶來的編碼重構問題,很多學者和研究人員提出了一些編碼[1-5]和查詢算法[6-9].
1.1 區間編碼
一種常見的區間編碼方案稱為Zhang[1]編碼,其編碼規則為:XML文檔樹中的每一個結點被賦予一個二元組(begin,end).對樹T的所有結點訪問兩次,一次是在遍歷該結點的所有后裔結點之前訪問該結點,并產生該結點的序號begin;另一次是在遍歷完結點的所有后裔結點后再一次訪問該結點,并產生該結點的另一個序號end.
1.2 前輟編碼
LSDX[2]編碼是一種前綴編碼,LSDX編碼采用數字表示節點的層次關系,用字母表示節點的位置信息.LSDX編碼格式為nx.y,其中n是數字,表示節點的層次,x是字母,表示節點的父節點編碼,y是字母,表示節點是其父節點的子節點.如果節點沒有父節點,顯示格式為0x,表示該節點的層次為0,編碼為x.
2 FAPE方案
2.1 編碼方法
在該編碼方法中,XML文檔樹中的每個結點用一個三元組來表示〈fenzi/fenmu,PathName,PathPosition〉,其中fenzi為該結點先序遍歷所得到的值,初值設為1,以后按先序遍歷的順序每訪問下一個結點,其值加1;fenmu恒設為1,保持不變;PathName為該結點的路徑名;PathPosition表示結點的路徑序號,因為不同的路徑可能有相同的路徑名,為了區別,在訪問時按照從左到右的順序.如果某條路徑是第一次出現,則該路徑的PathPosition為1,如果某條路徑第二次出現,則該路徑的PathPosition為2,以此類推.對于如下lib.xml文檔,其文檔樹及分數路徑編碼(FAPE)如圖1所示.
lib.xml
〈library〉
〈book id=″B001″〉
〈title〉 Distribute Database Systems〈/title〉
〈author〉 Jentoner Witom〈/author〉
〈/book〉
〈magazine〉
〈title〉 Object lanauage〈/title〉
〈author〉 Neichun Hsu〈/author 〉
〈/magazine〉
〈book id=″B002″〉
〈title〉 Popular Database Systems〈/title〉
〈author〉 Alfons Kemper〈/author〉
〈/book〉
〈/library〉
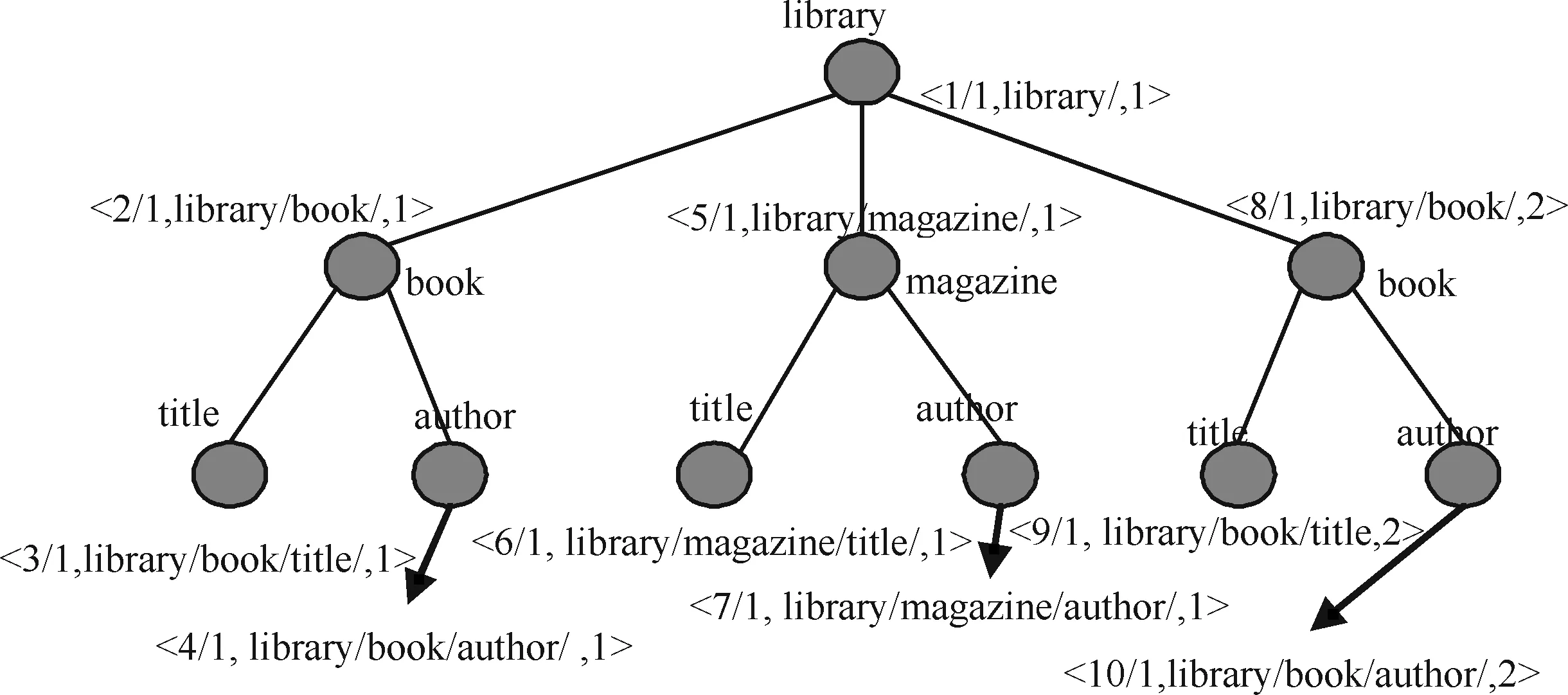
圖1 XML文檔樹及分數路徑編碼
舉例:對于右邊的book結點,其編碼為〈8/1,library/book,2〉,數字8表示magazine結點為先序編碼的第8個結點; library/book為該結點的路徑,數字2表示該路徑為第2次出現,因為在左邊已經有一個book結點具有相同的路徑,也為bibrary/book,所以用2進行區分.
3 FAPE存儲結構
FAPE用5個表記錄了XML文檔的信息,分別如下:
3.1 值索引表
記錄了結點的值和結點的值編號,不同的結點值具有不同的值編號,相同的結點值具有一樣的值編號,這樣可以節約存儲空間.表1記錄了上述lib.xml文件的結點值和值編號.
3.2 結點名索引表
結點名索引表記錄了結點名稱和結點名編號,不同的結點名稱具有不同的結點名編號,相同的結點名稱具有相同的結點名編號,這樣可以節約存儲空間.表2記錄了上述lib.xml文件的結點名稱和結點名編號.
3.3 屬性表
屬性表記錄了屬性所屬的結點編號,屬性名和屬性值.表3記錄了上述lib.xml文件的結點編號,屬性名和屬性值.
3.4 路徑索引表
路徑索引表記錄了結點的路徑和路徑的編號.路徑名指從根結點到該結點的路徑(該結點包括在路徑名里面).不同路徑名具有不同的路徑編號,相同的路徑名具有相同的編碼.表4記錄了上述lib.xml文件的路徑名和路徑編號.
3.5 結點信息表
結點信息表記錄記錄了結點編號、結點的路徑序號、路徑編號、結點名編號、結點值編號和該結點的分數.表5記錄了上述lib.xml文件的相關信息.

表1 值索引表

表2 結點名索引表

表3 屬性表
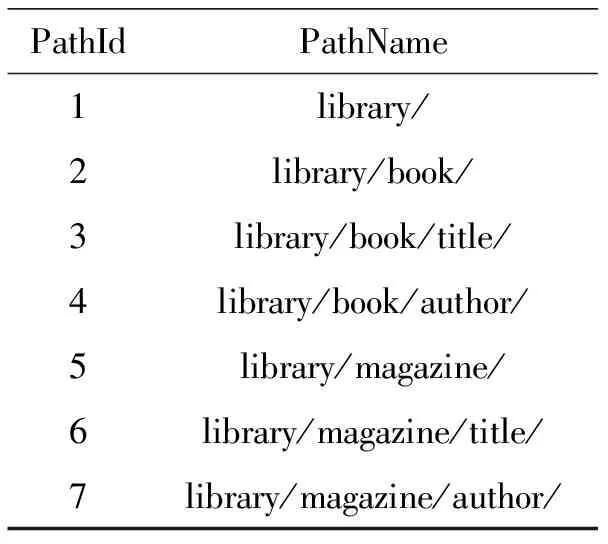
表4 路徑索引表

表5 結點信息表
4 編碼結點關系判斷
4.1 父子關系判斷
設u〈f1,n1+node1+“/”,p1〉,v〈f2,n2+node2+“/”,p2〉是XML文檔樹T中的2個結點,其中node1和node2 分別為該路徑名的最后一個結點名.如果n1+node1+“/”=n2,且p1=p2,則u結點是v結點的父結點,v是u結點的子結點.例如:結點u〈2/1,library/book/,1〉(n1=library/,node1=book)是結點v〈3/1,library/book/title/,1〉(n2=library/book/,node2=title)的父結點.
4.2 祖先/后裔關系判斷
設u〈f1,n1+node1+“/”,p1〉,v〈f2,n2+node2+“/”,p2〉是XML文檔樹T中的2個結點,其中node1和node2 分別為該路徑名的最后一個結點名.如果n1+node1+“/”是n2的前輟,且p1=p2,則u結點是v結點的祖先結點,v是u結點的后裔結點.
4.3 兄弟關系判斷
設u〈f1,n1+node1+“/”,p1〉,v〈f2,n2+node2+“/”,p2〉是XML文檔樹T中的2個結點,其中node1和node2 分別為該路徑名的最后一個結點名.如果n1=n2且p1=p2,則u結點與v結點是兄弟結點;如果n1=n2且p1=p2,f1 設u〈f1,n1+node1+“/”,p1〉,則n1中“/”符號的個數即為該結點所在的層次. 數據結點的更新包括新增、刪除和修改.節點的刪除和修改不會影響到原有的編碼數據,但新增節點會對已經編碼的數據造成影響.下面分析一下結點的插入情況, 在介紹結點的插入之前,先介紹一個重要的定理[3]: 下面討論新增結點的插入,分4種情況: (d)新插入節點無兄弟(同時無左兄弟和右兄弟),在結點A下面插入結點B(結點名設為price),如圖5所示:設A結點的編碼為〈4/1,library/book/author/,1〉,則B結點的編碼為〈5/1, library/book/author/price/,1〉. 圖2 有右兄弟但無左兄弟 圖3有左兄弟但無右兄弟 圖4 既有左兄弟也有右兄弟 圖5 即無左兄弟也無右兄弟 實現了FAPE方案,實驗中的算法用JAVA編程語言來實現.軟件環境是Windows XP+MyEclipse7.0+JDK 6.0,硬件環境是:Pentium(R)4 cpu 3.00 GHZ,內存:512 MB DDR1,硬盤:80 G. 實驗中的數據集采用Xmark[10]生成的數據,XMark來源于一個針對XML的基準測試項目. 第一個實驗用來檢測FAPE對文檔編碼所花的時間.用Xmark數據集作為測試數據.Xmark數據集選擇參數分別為0.018和0.27,分別生成大小約為2 MB和30 MB的XML文檔.用FAPE,zhang編碼,LSDX編碼對文檔編碼進行編碼,所占用的存儲空間如表6所示. 表6 存儲空間的比較 從實驗結果可以看出,相同大小的的XML文檔,LSDX所占用的空間最多,原因在于,當結點個數增加時,其結點包括其父親結點的編碼,長度呈非線性增加.Zhang編碼所占用的存儲空間比較小,隨著結點個數的增加,其編碼長度呈線性增加.FAPE所占用的存儲空間最小,原因在于其分別通過值索引表,結點名索引表和路徑索引表避免了記錄重復的結點值,結點名和結點路徑,最后只記錄其相應編號即可. 第2個實驗用來檢測FAPE查詢的效益,依舊采用Xmark作為測試數據集,選擇參數為0.27,生成了30M左右的文件,其結點個數為1 022 976.針對不同的查詢條件選擇了6個查詢實例,如表7所示.使用的編碼為FAPE,XISS[5],B+TREE[6],DUIX[7]實驗結果如表8所示. 表7 6個查詢實例 表8 查詢處理的性能 從實驗可以看出,FAPE在查詢時效率最高,關鍵在于其保存了結點的路徑,完全避免了結構連接,查詢效率不受查詢路徑表達式長度和中間結果集大小的影響,從而使查詢較快.XISS在查詢時所花的時間較長,關鍵在于其使用了結構連接.B+TREE相對XISS有所改進,但其查詢效率受中間結果集的影響較大.DUIX相對XISS和B+TREE都有所改進,但在一定程度上仍受中間結果集的影響. 從上面幾個實驗可以看出,不管在空間性能,還是在數據查詢的效率方面,FAPE相對其他的編碼都具有優勢,且支持結點的無限更新. 本文提出的編碼方案還有很多待完善的地方,如在實際應用中,XML文檔中的節點值往往具有多種類型,如日期、文本等,本文沒有考慮不同的數據類型,把他們全當成字符型數據來處理,在后續工作中,將會研究不同數據類型的查詢和存儲情況. 參考文獻: [1] ZHANG C, NAUGHTON J, DEWITT D,etal. On supporting containment queries inrelational database management systems: proceedings of the 2001 ACM SIGMOD international conference on management of data, Santa Barbara, CA, USA, Newcastle, May 21-24, 2001[C]. New York: NY,2001. [2] MAGGIE DUONG, ZHANG Y C. LSDX:a new labelling scheme for dynamically updating XML data:ADC′05 proceedings of the 16th Australian database confereace. Australian Newcastle, January, 2005[C]. Australian: Australian Computer Society, 2005. [3] 孫勇義,高 軍,王騰蛟,等.一種更新友好的基于分數的XML編碼方法[J].計算機科學,2008,35(10A):165-169. [4] 曹耀欽,宋建社,趙 霜,等.基于O-D的XML編碼及對信息查詢與更新的支持[J].計算機工程,2007,33(5):53-58. [5] 曾 捷,謝 寧,王 暉.放大轉發中繼網絡中一種改進的分布式空時編碼[J].湖南師范大學自然科學學報,2011,34(3):20-23. [6] LI C Q, LING T W, HU M. Efficient processing of updates in dynamic XML data: proceedings of the 22nd international conference on data engineering (ICDE’06), USA,April 3-7, 2006 [C]. USA:[s.n.],2006. [7] CHIEN S Y, VAGENA ZOGRAFOULA, ZHANG D H,etal. Efficient structural joins on indexed XML documents:proceedings of the 28th VLDB conference, Hong Kong, China, 2002[C].Hong Kong: VLDB Endowment, 2002. [8] 劉先鋒,朱清華,陳鳳英. 一種有效支持數據更新的XML索引研究[J].計算機工程與應用,2009,45(20):140-143. [9] 鄒為偉,宋余慶,耿 飆,等.基于Schema的XML索引方法研究[J].計算機工程,2011,37(6):74-76. [10] 于亞新,王國仁,張海寧,等.有效支持XML結構化連接的索引——CATI[J].計算機研究與發展,2007,44(1):111-118. [11] SCHMIDT A, WAAS F, KERSTEN M,etal. XMark: a benchmark for XML data management:proceedings of the 28th VLDB conference, Hong Kong, China, 2002[C]. Hong Kong: VLDB Endowment, 2002.4.4 結點所在層次判斷
5 數據更新

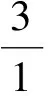
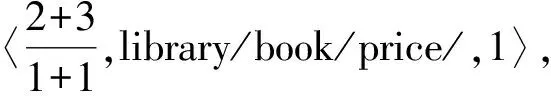

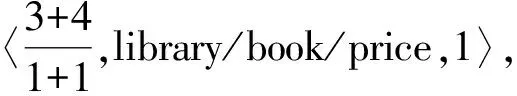

6 實驗環境
6.1 測試數據
6.2 空間性能分析

6.3 數據的查詢效率


7 結論及展望
