Lucene.net 中文分詞算法分析
2011-12-02 02:57:02周拴龍
鄭州大學學報(理學版) 2011年3期
關鍵詞:方法
周拴龍
(鄭州大學 信息管理系 河南 鄭州 450001)
Lucene.net中文分詞算法分析
周拴龍
(鄭州大學 信息管理系 河南 鄭州 450001)
Lucene.net實現中文分詞依靠的是Analyzer類,但通過分析其內置的KeywordAnalyzer,StandardAnalyzer,StopAnalyzer,SimpleAnalyzer,WhitespaceAnalyzer 5個分詞類發現,它們幾乎都是按單字的標準進行切分的,為更好處理中文信息,必須引用外部獨立開發的中文分詞包.在對ChineseAnalyzer,CJKAnalyzer和 IKAnalyzer這3種典型的中文分詞包分別測試后,發現采用字典分詞以及正反雙向搜索方法的IKAnalyzer分詞器的分詞效果更勝一籌.
Lucene; 中文分詞; Analyzer類
0 引言
從發展歷史角度看,Lucene是Apache軟件基金會Jakarta項目組的一個子項目,是一個開放源代碼的全文搜索引擎工具包.Lucene的目的是為軟件開發人員提供一個簡單易用的工具包,以方便地在目標系統中實現全文檢索的功能,或者是以此為基礎建立起完整的全文搜索引擎[1].
到目前為止,Lucene的C#移植有3個版本,最開始是NLucene,然后是Lucene.net,當Lucene.net轉向商業化之后,SourceForge上又出現了DotLucene項目.它們都是Lucene全文搜索引擎庫的 .net實現.所以3者在架構、內核等方面與Lucene是一脈相承的.綜合性能比較,Lucene.net在3者里最為成熟、穩定,所以,本文選擇了Lucene.net分析其中文分詞算法的實現[2].
1 Lucene的工作原理
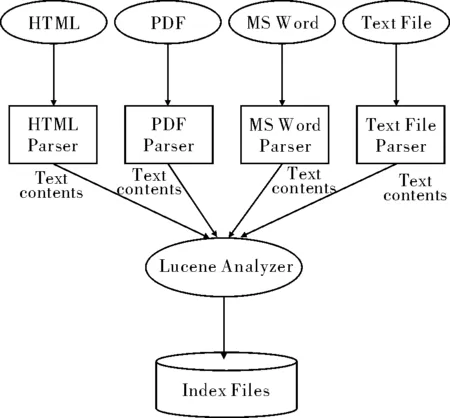
圖1 Lucene 索引機制架構Fig.1 Index mechanism structure of Lucene
Lucene包括索引和搜索兩大部分.
索引所做的工作是為各種各樣的文檔構建Lucene能識別的索引文件.具體講,第1步,Lucene 使用各種解析器對各種不同類型的文檔進行解析.Lucene有多種文檔解析器,如HTML解析器,PDF解析器,MS Word解析器,Text File解析器等等.Lucene根據文檔類型做出判斷,將不同文檔交由不同解析器處理,濾去種種不必要信息,最終輸出純文本內容.第2步, Lucene 的分詞器—Analyzer從純文本內容中提取出索引項以及相關信息,如索引項的出現頻率等.第3步,由Analyzer把這些信息寫到索引文件中[1].圖1顯示了 Lucene 索引機制的架構.
搜索所做的工作是從用戶輸入的關鍵字入手找出與之相匹配的文本并返還給用戶.搜索不是本文要討論的重點,因為Lucene默認對搜索關鍵詞不分詞,所以分詞的工作就集中在了索引部分.
Lucene的索引中有5個基礎類:
(1)Document—是用來描述要解析的文檔的,這里的文檔可以是HTML,PDF,Word或Text File等等類型.一個 Document 對象由多個 Field 對象組成.
(2)Field—是用來描述一個文檔的某個屬性的.Field有3個屬性:是否存儲,是否索引,是否分詞.
(3)Analyzer—它負責在一個文檔被索引之前,預先對文檔內容進行分詞處理,主要是提取詞匯單元,并除掉無用的信息.Analyzer 類是一個抽象類,它有多個實現.針對不同的語言和應用需要選擇適合的 Analyzer.Analyzer 把分詞后的內容交給 IndexWriter 來建立索引.
(4)IndexWriter—“寫入索引”.它的作用就是把一個個的 Document 對象加到索引中來.這是 Lucene 用來創建索引的一個核心類.
(5)Directory—標示Lucene 的索引的存儲位置[2].
最初,Lucene的設計者只考慮了英文、德文兩種西文格式的分詞情形.眾所周知,中文分詞要走的是另外一條道路.
2 中文分詞
2.1中文分詞技術的核心—分詞算法
現有的中文分詞算法可分為3大類:基于規則的分詞方法、基于統計的分詞方法和基于理解的分詞方法.
(1)基于規則的分詞方法
這種方法又叫做機械分詞法,它是按照一定的策略將待分析的漢字串與一個“充分大的”機器詞典中的詞條進行匹配,若在詞典中找到某個字符串,則匹配成功(識別出一個詞).按照掃描方向的不同,串匹配分詞方法可以分為正向(由左到右)匹配和逆向(由右到左)匹配;按照不同長度優先匹配的情況,可以分為最大(最長)匹配和最小(最短)匹配;按照是否與詞性標注過程相結合,又可以分為單純分詞方法和分詞與標注相結合的一體化方法.
常用的機械分詞方法有以下3種:正向最大匹配法;逆向最大匹配法;最少切分匹配法.一般說來,逆向匹配的切分精度略高于正向匹配,遇到的歧義現象也較少.
(2)基于統計的分詞方法
從形式上看,詞是穩定的字的組合,因此在上下文中,相鄰的字同時出現的次數越多,就越有可能構成一個詞.因此字與字相鄰共現的頻率或概率能夠較好地反映成詞的可信度.可以對語料中相鄰共現的各個字的組合的頻度進行統計,計算它們的互現信息.具體操作起來,我們可以借鑒信息計量學的方法,定義兩個字的互現信息,并最終計算兩個漢字的相鄰共現概率.互現信息體現了漢字之間結合關系的緊密程度.當緊密程度高于某一個閾值時,便可認為此字組可能構成了一個詞.
這種方法有一定的局限性,會抽出一些共現頻度高、但并不是詞的常用字組,例如“這一”、“之一”、“有的”、“我的”、“許多的”等,并且對常用詞的識別精度差,時空開銷大.實際應用的統計分詞系統都要使用一部基本的分詞詞典(常用詞詞典)進行串匹配分詞,同時使用統計方法識別一些新的詞,即將串頻統計和串匹配結合起來,既發揮匹配分詞切分速度快、效率高的特點,又利用了無詞典分詞結合上下文識別生詞、自動消除歧義的優點.
(3)基于理解的分詞方法
這種分詞方法是通過讓計算機模擬人對句子的理解,達到識別詞的效果.其核心思想就是在分詞的同時進行句法、語義分析,利用句法信息和語義信息來處理歧義現象.它通常包括3個部分:分詞子系統、句法語義子系統、總控部分.在總控部分的協調下,分詞子系統可以獲得有關詞、句子等的句法和語義信息來對分詞歧義進行判斷,這種分詞方法模擬了人對句子的理解過程,需要使用大量的語言知識和信息.由于漢語語言知識的籠統、復雜性,難以將各種語言信息組織成機器可直接讀取的形式,因此,目前基于理解的分詞系統還處在試驗階段[3].
到底哪種分詞算法的準確度更高,目前并無定論.但取得公認的是,對于任何一個成熟的分詞系統來說,不可能單獨依靠某一種算法來實現,都需要綜合不同的算法.
2.2中文分詞的難題
中文是一種十分復雜的語言,讓計算機理解中文語言更是困難.在中文分詞過程中,有2大難題一直沒有完全突破.
(1)歧義識別
歧義是指同樣的一句話,可能有兩種或者更多的切分方法.例如:表面的,因為“表面”和“面的”都是詞,那么這個短語就可以分成“表面/的”和“表/面的”.這種稱為交叉歧義.由于沒有人的知識去理解,計算機很難知道到底哪個方案正確.
交叉歧義相對組合歧義來說還是比較容易處理的,組合歧義就必需根據整個句子來判斷了.例如,在句子“這個門把手壞了”中,“把手”是個詞,但在句子“請把手拿開”中,“把手”就不是一個詞.
如果交叉歧義和組合歧義計算機都能解決的話,在歧義中還有一個難題,是真歧義.真歧義意思是給出一句話,由人去判斷也不知道哪個應該是詞,哪個應該不是詞.例如:“乒乓球拍賣完了”,可以切分成“乒乓/球拍/賣/完/了”、也可切分成“乒乓球/拍賣/完/了”,如果沒有上下文其他的句子,恐怕誰也不知道“拍賣”在這里算不算一個詞.
(2)新詞識別
新詞,專業的術語稱為未登錄詞.也就是那些在詞庫中都沒有收錄過,但又確實能稱為詞的那些詞.最典型的是人名,人可以很容易理解句子“王軍虎去廣州了”中,“王軍”是個詞,因為是一個人的名字,但要是讓計算機去識別就困難了.如果把“王軍虎”做為一個詞收錄到字典中去,全世界有那么多名字,而且每時每刻都有新增的人名,收錄這些人名本身就是一項巨大的工程.即使這項工作可以完成,還是會存在問題,例如:在句子“王軍虎頭虎腦的”中,“王軍虎”還能不能算詞[4].
新詞中除了人名以外,還有機構名、地名、產品名、商標名、簡稱、省略語等都是很難處理的問題,而且這些又正好是人們經常使用的詞,因此對于搜索引擎來說,分詞系統中的新詞識別十分重要.
目前,在設計算法時,對于此類詞的區分將會逆向考慮,不在詞庫的詞排除常用字后即為專有名詞,這也意味著要對常用“字”進行詞性分類如“西”“姆”,按照現代漢語習慣,只會和其他字結合不單獨出現,所以“馬克西姆”是專有名詞.而對于“在”、“和”、“了”之類的字可以單獨出現.
3 Lucene.net的中文分詞
3.1Lucene.net中文分詞核心—Analyzer
Lucene.net中,分詞是核心庫之一,其內置在Lucene.net里的分詞都被放在項目的Analysis目錄下,也就是Lucene.net.Analysis命名空間下.
分詞的類的命名一般都是以“Analyzer”結束,比如KeywordAnalyzer,StandardAnalyzer,StopAnalyzer,SimpleAnalyzer,WhitespaceAnalyzer等,全部繼承自Analyzer類.而它們一般各有一個輔助類,一般以“Tokenizer”結尾,分詞的邏輯大都在輔助類完成.
嚴格地講,Analyzer應該被稱作詞法分析器 ,它是一個進行詞法過濾和分析的類,實際上是個對分詞器、過濾器進行綜合包裝的類.而真正執行分詞動作的是輔助類Tokenizer,它們對文本進行分詞,可能是單字、詞、二元切分等等,是真正的分詞器.
3.2比較Lucene.net的5個內置分詞類
現在,對于KeywordAnalyzer,StandardAnalyzer,StopAnalyzer,SimpleAnalyzer,WhitespaceAnalyzer這5個內置的分詞類做兩個測試,以分析對比他們各自的分詞效果.
首先,private static String TestString=“鄭州大學信息管理系,I love my major.”做第一個測試,結果如下:
Lucene.net.Analysis.KeywordAnalyzer結果:
鄭州大學信息管理系,I love my major.
Lucene.net.Analysis.StandardAnalyzer結果:
鄭/州/大/學/信/息/管/理/系/I/love/ my/ major
Lucene.net.Analysis.SimpleAnalyzer結果:
鄭州大學信息管理系/I/love/my/major
Lucene.net.Analysis.StopAnalyzer結果:
鄭州大學信息管理系/I/love/my/major
Lucene.net.Analysis.WhitespaceAnalyzer結果:
鄭州大學信息管理系,I /love/my/major.
接下來,換一句話來做第二個測試.更改Teststring值為“鄭州大學信息管理系,I’m glad to see you.阿Q正傳.”.測試結果如下:
Lucene.net.Analysis.KeywordAnalyzer結果:
鄭州大學信息管理系,I’m glad to see you.阿Q正傳.
Lucene.net.Analysis.Standard.StandardAnalyzer結果:
鄭/州/大/學/信/息/管/理/系/I’m/glad/to/see/you/阿Q正傳/
Lucene.net.Analysis.SimpleAnalyzer結果:
鄭州大學信息管理系/I’m/glad/to/see/you/阿Q正傳
Lucene.net.Analysis.StopAnalyzer結果:
鄭州大學信息管理系/I’m/glad/to/see/you/阿Q正傳
Lucene.net.Analysis.WhitespaceAnalyzer結果:
鄭州大學信息管理系,I’m/glad/to/see/you.阿Q正傳.
由此可以看出:KeywordAnalyzer分詞,沒有任何變化;StandardAnalyzer對英文和中文都單字拆分;SimpleAnalyzer和StopAnalyzer差不多,對英文按單字分開,而對中文則幾無變化;WhitespaceAnalyzer只是按空格劃分,不屏蔽標點符號.
以上這些是初步的結論,但可以確定的是,Lucene.net自帶的分詞類幾乎都是按單字的標準進行切分的,這點在處理中文信息時是遠遠達不到應用要求的.
3.3更多的中文分詞包
上文提到,中文分詞可分為單字分詞、二元分詞、詞庫匹配、語義理解等幾種,每一種方法,Lucene.net的程序愛好者們都嘗試去研究,開發出許多達到應用級的分詞包.
上面的測試是對Lucene.net內置的分詞程序進行的測試,使用的是Lucene.net默認的單字分詞.對于后3種中文分詞方法,我們分別選擇ChineseAnalyzer,CJKAnalyzer和 IKAnalyzer 3種典型的中文分詞包進行測試.
private static String TestString = “原鄭州大學創建于1956年,是新中國成立后國家創辦的第一所綜合性大學.”;
ChineseAnalyzer結果:
原/鄭/州/大/學/創/建/于/1956/年/是/新/中/國/成/立/后/國/家/創/辦/的/第/一/所/綜/合/性/大/學
CJKAnalyzer結果:
原鄭/鄭州/大學/學創/創建/建于/于1956/1956年/年是/是新/新中/中國/國成/成立/立后/后國/國家/家創/創辦/辦的/的第/第一/一所/所綜/綜合/合性/性大/大學
IKAnalyzer結果:
鄭州大學/鄭州/大學/鄭/大/創建/1956年/1956/年/新中國/中國/成立/國家/創辦/第一所/第一/一/綜合性大學/綜合性/綜合/大學/大
由此可見:
ChineseAnalyzer采用一元分詞的方法,基本等同StandardAnalyzer;
CJKAnalyzer則是二元分詞方法,交叉雙字進行分割;
而IKAnalyzer則是字典分詞方法,并采用正反雙向搜索來提高分詞效果.且從測試中可以看出:ChineseAnalyzer和CJKAnalyzer沒有過濾常用的漢字,如“是”、“的”等,這些常用的漢字對搜索是沒有多大作用的.KIAnalyzer則可以通過在詞典中屏蔽掉這些常用字而提高分詞和檢索的效率.
[1] 趙峰.基于Lucene的全文檢索系統初探[J].黑龍江科技信息,2007,12:62-64.
[2] 孫永波,郭紅峰.天文文獻全文檢索系統的研究與實現[J].天文研究與技術,2007,4(3):296-300.
[3] 蔡建超,郭一平,王亮.基于Lucene.NET校園網搜索引擎的設計與實現[J].計算機技術與發展,2006,16(11):73-75.
[4] 趙汀,孟祥武.基于Lucene API 中文全文數據庫的設計與實現[J].計算機工程與應用,2003,20:179-181.
AnalysisonChineseSegmentationAlgorithmofLucene.net
ZHOU Shuan-long
(DepartmentofInformationManagement,ZhengzhouUniversity,Zhengzhou450001,China)
The segment of Chinese word relies on the Class Analyzer.By analyzing the five built-in analyzers of Lucene.net, it was found that their segment were based on the single character of KeywordAnalyzer, StandardAnalyzer,StopAnalyzer,SimpleAnalyzer and WhitespaceAnalyzer.An improted segment kit for a better Chinese information disposal was added.By testing the three typical kits, ChineseAnalyzer,CJKAnalyzer and IKAnalyzer, it was found that IKAnalyzer which uses Dictionary participle and the positive and negative two-way search method, worked well.
Lucene; Chinese word segment; Class Analyzer
TP 391
A
1671-6841(2011)03-0073-05
2010-12-10
周拴龍(1964-),男,副教授,碩士,主要從事信息資源數字化、全文檢索等方面的研究,E-mail:shuanlong@zzu.edu.cn.
猜你喜歡
中老年保健(2021年9期)2021-08-24 03:52:04
河北畫報(2021年2期)2021-05-25 02:07:46
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:33:04
兒童繪本(2020年5期)2020-04-07 17:46:30
兒童故事畫報(2019年5期)2019-05-26 14:26:14
Coco薇(2016年2期)2016-03-22 02:42:52
山東青年(2016年1期)2016-02-28 14:25:23
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
