基于細粒度任務分配的空時自適應并行處理算法研究
2012-01-27 07:45:12袁培苑
電子與信息學報 2012年6期
王 超 劉 偉 袁培苑
(北京理工大學信息與電子學院 北京 100081)
基于細粒度任務分配的空時自適應并行處理算法研究
王 超 劉 偉*袁培苑
(北京理工大學信息與電子學院 北京 100081)
對于空時自適應信號處理(Space-Time Adaptive Processing, STAP)算法的并行處理問題,傳統方法以粗粒度的劃分方式將 STAP算法分配到特定硬件系統中的不同處理器中,利用處理器間的流水計算來提高系統計算吞吐量。該文分析了傳統并行處理方法的缺陷:粗粒度的任務劃分方式犧牲了 STAP算法的并行度;傳統處理方法僅能適用于特定的系統環境。針對上述情況,該文提出一種基于細粒度任務分配的 STAP并行處理方法,該方法分為以下3個步驟:構建細粒度的DAG(Direct Acyclic Graph)形式的STAP算法任務模型;使用統一拓撲結構模型描述不同結構的目標硬件系統;基于細粒度任務分配算法將任務模型分配到拓撲結構模型中的處理器實現并行計算。實驗結果表明該并行處理方法能夠達到良好的加速比,并且對于不同的STAP應用系統具有很好的適應性。
信號處理;空時自適應系統;并行處理;任務分配;細粒度
1 引言
空時自適應處理(STAP)是新一代相控陣雷達充分利用空域和時域信息通過空時2維濾波來抑制雜波與目標檢測的一項關鍵技術,廣泛應用于機載預警雷達、機載合成孔徑雷達、機載戰場偵察雷達及星載雷達、艦載雷達等實現雜波抑制與運動補償[1]。STAP面對著根據外界雜波及干擾的環境實時地求解自適應權值向量的問題[2,3]。求解權值向量是一個高密集計算型問題,運算量巨大,數據交互復雜,通常采用并行處理技術提高算法的實時性。
傳統的并行處理方法將STAP算法流程劃分為若干粗粒度的計算任務,分配計算任務到專用的硬件環境中的處理器,利用處理器間的流水計算來提高系統計算吞吐量[4?6]。文獻[7]提出了一種通用的STAP并行計算模型,并給出了適用于流水計算的粗粒度任務分配方法。粗粒度任務劃分易于實現,但是犧牲了算法的并行度[8]。國外對于細粒度STAP并行處理也有一些研究。文獻[9]引入遺傳算法解決STAP并行化處理過程中的細粒度任務分配問題,但是該方法僅能適用于具有全交換拓撲結構的硬件環境中。文獻[10]提出了一種細粒度數據劃分方法,并在GPU(Graphics Processing Unit)中實現了單指令多數據流形式的STAP并行處理,但是GPU并不能應用于機載平臺等嵌入式環境,這就限制了該方法實際應用性。
其次,傳統的處理方法往往只適用于特定的STAP應用系統[4?6,9]。特定應用系統中限定了系統參數,包括STAP處理通道數、脈沖數及處理距離單元數等信息;還限定了硬件環境信息,包括處理器的數量與處理器間的互聯方式。當系統參數變化或硬件環境改變時,傳統方法往往不再適用,這大大限制了傳統方法的通用性。因此研究一種具有高并行度并且具有拓撲結構獨立性的并行處理方法對于STAP算法的應用是非常有意義的。
我們可以分以下3個步驟實現STAP的并行處理:(1)劃分STAP算法為細粒度的計算任務,建立細粒度的任務模型。相比于粗粒度的方式,細粒度的劃分后任務模型具有更高的并行度[10]。(2)建立統一的拓撲結構模型,在模型參數中定義處理器的數量以及互聯方式等信息,對于不同的目標硬件環境,配置不同的模型參數。(3)基于任務分配方法,完成任務模型到拓撲結構模型的分配。細粒度劃分后計算任務的數量以及任務間的計算約束關系會變得非常復雜[10]。直接實現任務分配是非常困難的,更好的方法是選取一種合適的任務分配算法實現計算任務集到多處理器平臺的映射。任務分配算法以優化加速比為目標通過計算任務間的約束關系及并行性選擇將可并行的任務分配到不同的處理器實現獨立計算。
2 基于細粒度任務分配的STAP處理方法
2.1 任務模型


2.2 拓撲結構模型
拓撲結構模型為目標硬件系統的抽象,包含了處理器的信息及處理器間的互聯信息。定義拓撲結構模型TP = {U,CH}。其中U為有限的處理器集合,U中的每個元素表示一個獨立的處理器;CH為有限的通信通道集合,CH中的每個元素都表示處理器間的通信傳輸通道,傳輸通道分為單向傳輸通道和雙向傳輸通道。對于不同的硬件環境,需要配置不同的U與CH。
假設拓撲結構模型具有以下兩個特性:(1)非搶占式:處理器只有在完成當前計算任務才能開始執行新的任務;(2)并發性。處理器可以同時執行并發的計算任務和通信傳輸任務。任務模型中的節點V需要被分配到拓撲結構模型中不同處理器U。當間的數據傳輸eij就轉變為處理器間的 IPC(Inter Processor Communication)操作,并需要將該 IPC操作分配到連接uk與ul的傳輸通道中。處理器間傳輸通道的選擇一般采用最短路徑準則。
2.3 任務分配算法
任務分配算法以優化加速比為目標將任務模型中的節點v分配到拓撲結構模型的處理器u中,并根據節點的分配完成IPC操作到傳輸通道的分配。任務分配是一個具有 NP(Non-deterministic Polynomial) 完備性的問題,很難獲得最優的分配結果,因此常見的任務分配算法一般基于啟發式算法獲得次優結果[11]。
在現有的分配算法中,大都在分配過程中假定了理想的硬件環境[11?14],即不限定處理器數目及互聯通道數目,這并不符合于我們建立的拓撲結構模型。DLS(Dynamic Level Scheduling)是唯一具有拓撲結構獨立性的分配算法[15],即DLS脫離了拓撲結構對分配算法的影響。在分配過程中,DLS實時計算分配不同節點到不同處理器的動態優先級 DL(Dynamic Level),并依照DL順序完成節點分配。因此我們選擇DLS完成細粒度STAP任務模型的分配。
在每個分配步驟中,DLS中以∑表示當前狀態的已分配信息,分配節點vi到處理器uj時需要完成:(1)根據pr(vi)的分配信息,完成vi前向IPC操作分配;(2)完成vi到uj的分配。∑包含已分配節點以及IPC的st, end等分配信息。統計出vi執行前所需要完成的傳輸任務集合,如下:

IPC操作只能夠分配在拓撲結構模型中定義的通信通道,并根據各通信通道的已分配狀態確定IPC操作的起始執行時間。DA表示所有recv_IPC(vi)的最后結束時間,同時也表示了∑下vi在uj上的數據就緒時間。
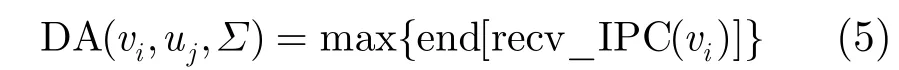
由 DA可以計算出st(vi),代入式(3)計算式end(vi)完成vi在pj上的分配。當前階段結束后更新∑。∑的迭代更新確保每個分配階段都可以完全獲取各處理器和通信通道的任務分配信息,并依此完成新任務的分配。式(6)中TF(uj,∑)表示∑下uj的空閑時間。
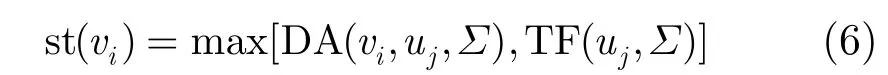

綜上所述,基于細粒度任務分配的STAP并行處理方法分為3個步驟:(1)構建任務模型。根據系統參數建立STAP處理流程圖,將其劃分為細粒度的任務集并建立任務DAG圖。DAG中每個節點的計算粒度確定后,其計算開銷以及邊界的傳輸開銷可以通過實際測試獲取。(2)構建拓撲結構模型。拓撲模型TP = {U,CH}參數中應明確定義處理器的個數以及處理器間的互聯關系。根據目標硬件環境配置拓撲結構模型參數。(3)任務分配過程。使用DLS算法實現任務模型到拓撲結構模型的映射。可由式(7)估算分配結果的加速比。最終輸出并行分配結果;并行分配結果中包括:計算任務到處理器的映射關系、IPC任務到傳輸通道的映射關系以及計算任務和IPC的執行順序關系。
3 并行處理的實現
基于細粒度任務分配的并行處理方法分3步完成,其中任務分配過程使用較為成熟的DLS分配算法,因此實現STAP應用系統的并行處理時需要完成細粒度任務模型的構建以及拓撲結構模型的配置。
3.1 細粒度任務模型構建
全自適應STAP算法計算量過于龐大,工程應用一般選擇基于頻域降維的 3DT-SAP算法。本節以3DT-SAP算法為例簡述細粒度STAP任務模型的構建方法。設置脈沖數為M,陣元數為N,距離單元數為L,參照文獻[4,5]中的 STAP處理流程構建粗粒度的任務DAG圖,如圖1(a)所示。圖中的節點表示計算任務,節點間的連接箭頭表示計算任務間的數據傳輸。
由數據分配節點將數據分發到N個多普勒濾波節點,每個節點完成L次M點FFT,完成后數據由STAP數據分配節點分配到M?2個數據組合節點中。對于每個數據組合節點,將N個處理通道中相鄰的3組脈沖數據組合在一起[15]。組合后的數據由權值生成節點計算得到自適應權值。權值生成可以通過如下步驟完成:組合數據轉置后經由QR分解節點得到3N×3N維的上三角矩陣A;聯合空時 2維導向矢量s求解兩次線性方程組計算得到自適應權值矢量w,如圖1(b)所示。最終由自適應權值聯合數據組合節點的輸出完成濾波過程,得到 STAP的輸出。
傳統的 STAP并行處理方法通常使用粗粒度QR分解操作,犧牲了算法的并行度,本文將采用一種細粒度的QR分解方法。計算權值的距離門數Lls應滿足自適應權值的收斂條件,取Lls=3 ×3N構成9N×3N的數據矩陣來求解權值向量[4]。將輸入Lls×3N階矩陣依照行順序分為K塊(Lls/K)×3N階子矩陣,在實際應用中一般保證3N為Lls/K的整數倍;將QR分解分割為兩種細粒度的計算任務:消除下三角元素操作以及消除上三角元素操作。
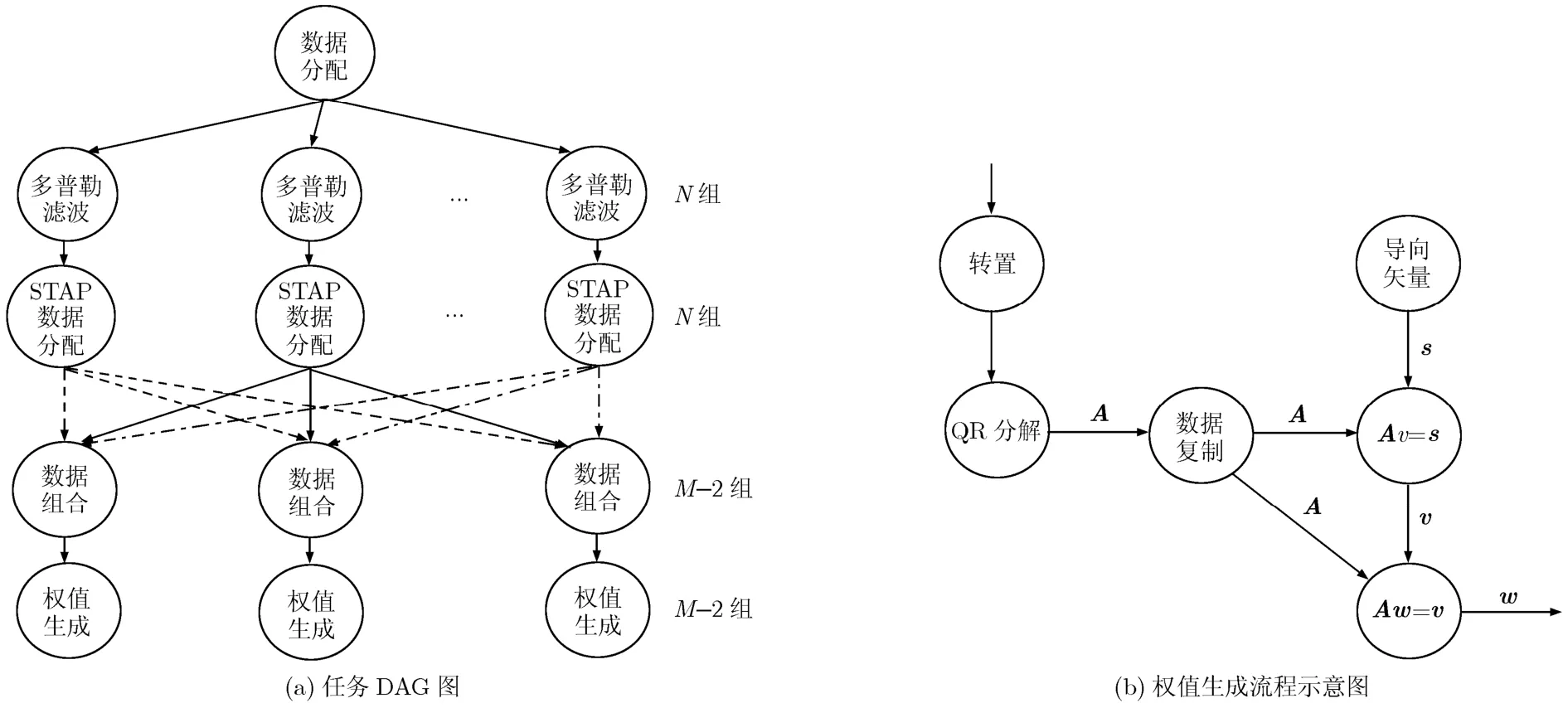
圖1 粗粒度任務模型DAG
(1)消除下三角操作過程:假設子矩陣M1的前r列元素全部為0,r+1列元素非 0,使用 Givens旋轉法將元素M1ij(i∈[2,Lls/K],j∈[r+ 1,r+i? 1])消除為0。
(2)消除上三角操作過程:選擇全0列數r相同的兩個子矩陣M1和M2,矩陣中元素M1ij和M2ij i∈[2,Lls/K],j∈ [r+ 1,r+i? 1])為0;元素M1ij和M2ij(i∈[1,Lls/K],j∈ [r+ 1,r+i])非 0。以M1作為參考矩陣將矩陣M2中的元素M2ij(i∈ [1,Lls/K],j∈ [r+ 1,r+i])消除為0。完成后M1的全0列數仍為r,M2的全0列數為r+L/K。
對于第k個子矩陣Mk,如果k≤3N/(L/K)時,分解完成的條件為:前(i? 1) × (L/K)列元素全為0,且Mkij(i∈[2,Lls/K],j∈ [r+ 1,r+i? 1])為,元素Mkij(i∈[1,Lls/K],j∈ [r+ 1,r+i])非 0;k>Lls/K× 3N時,完成條件為Mk消除為全 0矩陣。
對于所有子矩陣Mk(k∈ [1,K]),持續進行消除下三角操作和消除上三角操作,直到滿足分解完成條件。當所有K個子矩陣都完成分解后,依照行序號重新將子矩陣組合即可得到新的矩陣,其前3N行3N列為上三角矩陣,其余部分為0。將圖1(b)中的QR分解節點替換為上述分解方法,以此構建細粒度的DAG圖,完成任務模型建立。
3.2 拓撲結構模型的配置
定義 4種測試拓撲結構:Ring, Cubic,Rectangular及Cuboid如圖2所示。圖中每個節點表示一個處理器,處理器間的箭頭線表示兩個處理器間全雙工的通信通道。Ring型拓撲結構硬件上由4片TS201 DSP組成,每片DSP與相鄰的2片DSP通過LINK通道雙向互聯;Cubic型拓撲結構硬件上由8片TS201 DSP組成,每片DSP與相鄰的3片DSP通過LINK通道雙向互聯,Cubic型可以看作是Ring型結構的擴展。Rectangular型拓撲結構硬件上8片TS201 DSP組成,相鄰的DSP之間通過 LINK通道雙向互聯;Cuboid型硬件上由兩組Rectangular型拓撲結構擴展而成。依據圖2各拓撲結構中處理器的個數以及處理器間的連接關系配置拓撲結構模型TP = {U,CH}。
3.3 實驗及分析
依照表1配置5組STAP處理參數,并使用DLS算法實現并行任務分配。其中實驗1-實驗4依據4.1節中的方法建立細粒度的DAG任務圖,實驗5直接使用粗粒度的DAG任務圖。
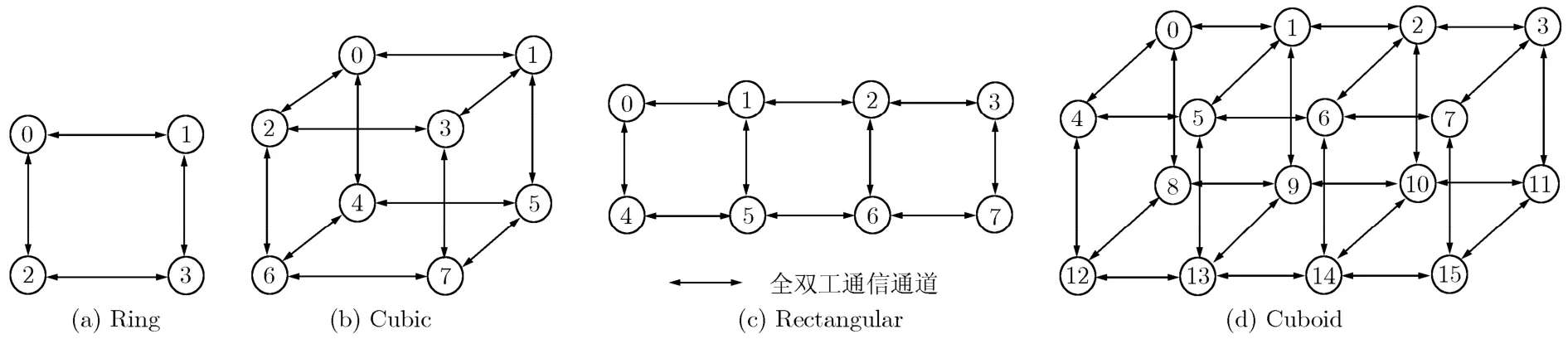
圖2 拓撲結構示意圖
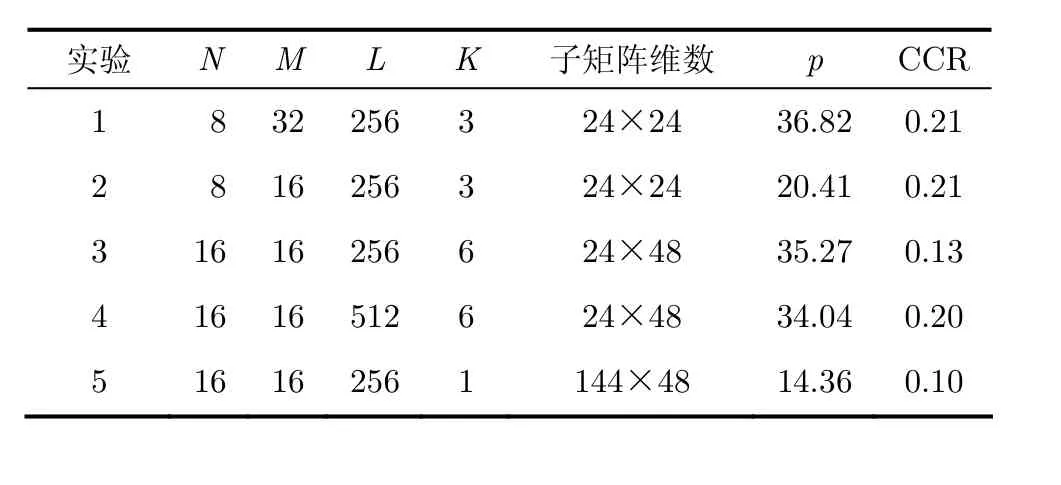
表1 STAP參數設定及p與CCR統計
通過實際測試獲取各 DAG圖中各任務在TS201中的實際計算開銷,表2統計了TS201中各維數矩陣消除上三角與消除下三角操作的計算開銷。其中實驗5中QR分解分塊個數K=1,因此僅需要一次消除下三角操作即可完成QR分解,故不存在消除上三角操作。根據式(1)與式(2)統計得到5個實驗中 DAG的并行度p及CCR,統計如表 1所示。

表2 QR分解操作計算開銷統計(μs)
由圖 1(a)可以看出,M?2組權值計算之間為相對獨立的過程。在實驗1中M=32,需完成30組權值計算與STAP濾波,因此實驗1中的并行度最高達到了36.82。對比實驗3與實驗5,實驗3中采用細粒度的任務劃分方法,并行度達到了35.27;而實驗5采用粗粒度的方法,并行度僅為14.36。可以看出細粒度的任務劃分雖然增加了傳輸開銷,但是換取了并行度的有效提高。
采用細粒度任務模型后,STAP算法中各處理階段被拆分為細粒度的計算任務與通信任務,并映射到不同的處理器交錯執行,很難直接評估各處理階段的計算開銷時間與通信開銷。因此一般使用加速比ACR來衡量各實驗中STAP的總體并行性能,ACR由式(9)計算得出。圖3給出了5組實驗中DLS的ACR統計,其中每組實驗都包含了Ring, Cubic,Rectangular以及Cuboid 4種不同拓撲結構下的分配測試。
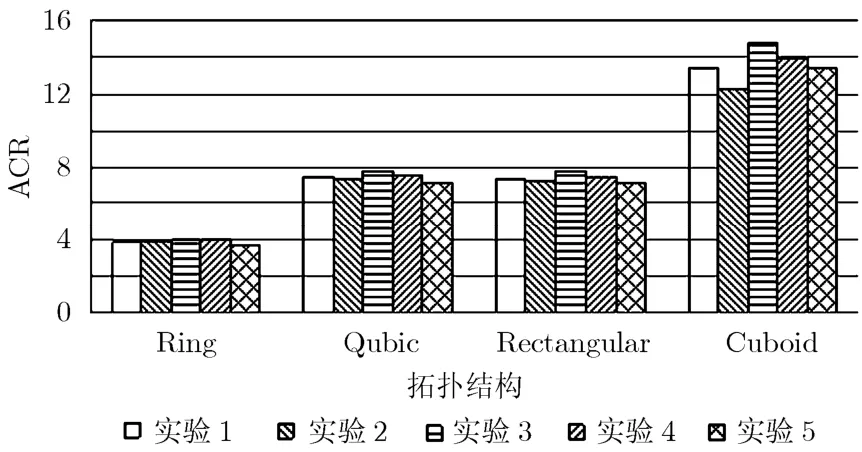
圖3 ACR統計
可以看出:(1)在同一組實驗中,隨著拓撲結構中處理器節點個數的增加,ACR也逐步增加。(2)對比實驗 1與實驗 3。雖然實驗 1中任務圖的p= 36.82大于實驗3的p= 35.27,但是實驗1的CCR較大,因此在4種拓撲結構下實驗3的ACR都超越了實驗1。可以看出在STAP算法并行度接近的情況下,較大的通信開銷將會影響并行加速性能。(3)對比實驗3與實驗5,在相同的系統參數配置下,細粒度任務模型具有更高的并行性,更適合于并行實現,因此達到了更優的ACR。
[7]提出了一種適用于流水處理的通用STAP并行計算模型,并給出了該計算模型下粗粒度的計算任務分配方法。該方法下的并行加速比統計見表 3。由于并行加速比與處理器的數量有直接關系,因此我們選擇具有相同處理器數量的拓撲結構模型實驗結果與參考文獻[7]的加速比進行比較。其中4片處理器對應于本文中Ring型拓撲結構下的5組實驗;8片處理器對應于本文中 Cubic與Rectangular型拓撲結構下的5組實驗。結果比較如表3所示。
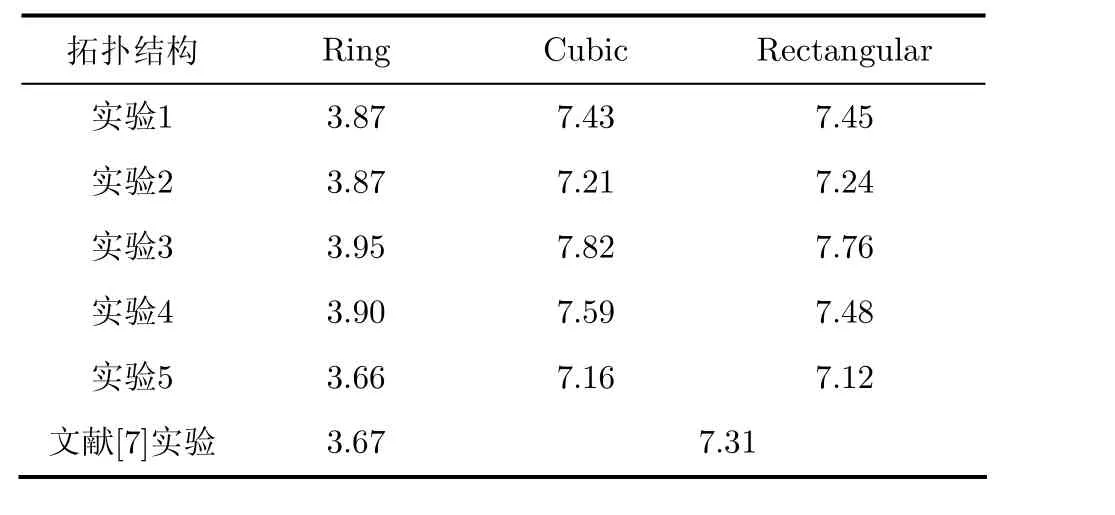
表3 加速比比較
由于細粒度 STAP算法本身具有很高的并行度,在處理器數量都為4的條件下,本文中Ring型拓撲結構模型的前4組實驗使用了細粒度的任務模型,加速比性能要優于參考文獻[7]中的加速比3.67;第5組實驗使用了粗粒度的任務模型,因此加速比與參考文獻[7]基本一致。
在Cubic與Rectangular下的實驗中,實驗1,實驗3和實驗4的加速比優于參考文獻[7]中8片處理器的實驗結果,實驗2的加速性能基本與其一致。而第5組實驗使用了粗粒度的任務模型,因此加速比小于參考文獻[7]中的結果。
聯合表1可以看出,5組實驗中實驗2與實驗5的任務模型并行度較低,因此加速比性能較差。而實驗1,實驗3和實驗4的任務模型并行度較高,因此在與參考文獻[7]的結果比較中達到了更優的加速性能。這也再次說明,并行度越高的任務模型越適合于本文提出的STAP并行處理方法。
5組實驗加載了不同的系統參數,并且每組實驗都使用了4種完全不同的拓撲結構。由結果可以看出:(1)建立細粒度的任務模型提高了算法的并行度,DAG形式的任務模型適應于不同系統參數的STAP應用;(2)構建TP = {U,CH}形式的拓撲結構可以適用于不同目標硬件環境;(3)選擇具有拓撲結構獨立性的DLS分配算法使得整個STAP并行處理過程脫離了應用參數與系統硬件結構的限制。
4 結論
在STAP并行處理算法中,傳統的并行處理方法使用粗粒度的任務劃分方式,并且僅僅能夠適用于特定的應用參數及硬件系統結構。粗粒度的任務劃分犧牲了STAP流程的并行度;限定應用參數及硬件結構雖然易于實現,但同時也限定了傳統的STAP并行處理方法的通用性。針對這些問題,本文提出了一種更具實用性的STAP并行處理方法,該方案分為以下3個步驟:建立STAP處理流程并以此構建細粒度的 DAG形式任務模型;根據實際硬件構建拓撲結構模型;基于DLS任務分配算法將任務模型中的任務分配到拓撲結構模型中的不同處理器實現STAP并行計算。
由實驗結果可以看出,該并行方法能夠達到良好的加速比,并且對于不同的STAP應用以及不同的硬件環境具有很好的適應性。
參 考 文 獻
[1] 保錚, 廖桂生, 吳仁彪, 等. 相控陣機載雷達雜波抑制的時空二維自適應濾波[J]. 電子學報, 1993, 21(9): 1-7.
Bao Zheng, Liao Gui-sheng, Wu Ren-biao,et al.. 2-D temporal-tpatial adaptive clutter suppression for phased array airborne radars[J].Acta Electronica Sinica, 1993, 21(9):1-7.
[2] Huang Yao. A reduced-rank STAP method based on solution of linear equations[C]. Proceedings of the 2010 International Conference on Computer Design and Applications (ICCDA),Qinghuangdao, China, 2010: 235-238.
[3] Wu Ren-biao, Wang Lu, and Su Zhi-gang. Study on adaptive monopulse with reduced dimension STAP technique[C].Proceedings of the 2010 International Conference on Image Analysis and Signal Processing (IASP), Xiamen, China, 2010:159-163.
[4] 范西昆, 王永良, 陳輝. 機載雷達空時自適應處理的實時實現[J]. 電子與信息學報, 2006, 28(12): 2224-2227.
Fan Xi-kun, Wang Yong-liang, and Chen Hui. Real-time implementation of airborne radar space-time adaptive processing[J].Journal of Electronics&Information Technology, 2006, 28(12): 2224-2227.
[5] 任磊, 王永良, 陳輝, 等. STAP 并行處理系統的調度問題研究[J]. 系統工程與電子技術, 2009, 31(4): 874-880.
Ren Lei, Wang Yong-liang, Chen Hui,et al.. Research on the scheduling problems of STAP parallel processing system[J].Systems Engineering and Electronics, 2009, 31(4): 874-880.
[6] Lebak J M and Bojanczyk A W. Design and performance evaluation of a portable parallel library for space-time adaptive processing[J].IEEE Transactions on Parallel and Distributed Systems, 2000, 11(3): 287-298.
[7] 邵銀波, 王永良, 李強, 等. 一種用于空時自適應處理的并行計算模型[J]. 電子學報, 2006, 34(3): 450-453.Shao Yin-bo, Wang Yong-liang, Li Qiang,et al.. A parallel computation model for space-time adaptive processing[J].Acta Electronica Sinica, 2006, 34(3): 450-453.
[8] West M and Antonio K. A genetic algorithm approach to scheduling communications for a class of parallel space-time adaptive processing algorithms[J].Journal of Parallel and Distributed Computing, 2002, 62(9): 1386-1406.
[9] Roedera M, Davisa N, Furteka J,et al.. GPU implementations for fast factorizations of STAP covariance matrices[C]. Proc. SPIE, San Diego, USA, 2008: 707403-1-707403-12.
[10] Kruatrachue B and Lewis T. Grain size determination for parallel processing[J].IEEE Transactions on Software, 1988,5(1): 23-32.
[11] Wang Chao and Liu Wei. Multi-processor task scheduling in signal processing systems[C]. Proceedings of the International Conference on Computer Science and Information Technology, Chengdu, China, 2011: 532-539.
[12] Ebaid A, Ammar R, and Rajasekaran S. Task clustering &scheduling with duplication using recursive critical path approach (RCPA)[C]. Proceedings of the 2010 IEEE International Symposium on Signal Processing and Information Technology, Luxor, 2010: 34-41.
[13] Hwang R, Gen M, and Katayama H. A comparison of multiprocessors task scheduling algorithms with communication costs[J].Computer&Research, 2008, 35(3):976-993.
[14] Sun Wei-fang, Zhu Yu-dan, Sun Zhi-yuan,et al.. A priority-Based task scheduling algorithm in Grid [C].Proceedings of the Third International Symposium on Parallel Architectures, Algorithms and Programming(PAAP), Dalian, China, 2010: 311-315.
[15] Sih G C and Lee E A. A compile-time scheduling heuristic for interconnection-constrained heterogeneous processor architecture[J].IEEE Transactions on Parallel and Distributed Systems, 1993, 4(2): 175-186.
Research on the Parallel Processing Algorithm of STAP Based on Fine-grained Task Scheduling
Wang Chao Liu Wei Yuan Pei-yuan
(School of Information and Electronics,Beijing Institute of Technology,Beijing100081,China)
In the parallelization of Space-Time Adaptive Processing (STAP) arithmetic, traditional methods schedule the STAP arithmetic to different processors in the specific hardware architecture through coral-granularity division and improve the throughput by pipeline processing between processors. In the paper, its disadvantages are discussed from two perspectives: Coarse-grained scheduling hinders the parallelism; They are only suitable for the specific system parameters and hardware architectures. Thus, a new method based on fine-grained scheduling is put forward, which consists of three steps: Firstly, fine-grained task model in the form of Direct Acyclic Graph (DAG) is constructed; Secondly, the topology model is built to describe the target system;Finally, the established task model in fine-grained manner is assigned to different processors described in model topology. The experiment of the proposed method shows that it achieves better acceleration ratio, and more flexiable adaptation to different STAP applications.
Signal processing; Space-Time Adaptive Processing (STAP) systems; Parallel processing; Task scheduling; Fine-granularity
TN911.7
A文章編號:1009-5896(2012)06-1398-06
10.3724/SP.J.1146.2011.00683
2011-07-06收到,2012-03-05改回
*通信作者:劉偉 eliuwei@bit.edu.cn
王 超: 男,1985年生,博士生,研究方向為實時信號處理.
劉 偉: 男,1976年生,講師,研究方向為實時信號處理.
袁培苑: 女,1988年生,碩士生,研究方向為實時信號處理.
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
哲學評論(2021年2期)2021-08-22 01:53:34
鐵道通信信號(2020年9期)2020-02-06 09:15:22
中華詩詞(2019年7期)2019-11-25 01:43:04
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
數學大王·趣味邏輯(2019年5期)2019-06-13 20:27:43
小學科學(學生版)(2019年5期)2019-05-21 01:00:18
經濟技術協作信息(2018年30期)2018-11-22 06:20:24
影視與戲劇評論(2016年0期)2016-11-23 05:26:01
發明與創新(2016年38期)2016-08-22 03:02:52
