復(fù)雜網(wǎng)絡(luò)在新聞網(wǎng)頁(yè)關(guān)鍵詞提取中的應(yīng)用
2012-09-21 07:28:32唐俊
唐俊
(西南交通大學(xué)電氣工程學(xué)院,四川成都610031)
復(fù)雜網(wǎng)絡(luò)在新聞網(wǎng)頁(yè)關(guān)鍵詞提取中的應(yīng)用
唐俊
(西南交通大學(xué)電氣工程學(xué)院,四川成都610031)
通過分析新聞網(wǎng)頁(yè)文檔的特征,引入節(jié)點(diǎn)權(quán)重、有向網(wǎng)絡(luò)加權(quán)聚類系數(shù)、中心介數(shù)等特征量,并結(jié)合傳統(tǒng)關(guān)鍵詞提取算法的一些優(yōu)點(diǎn)及網(wǎng)頁(yè)文檔的部分特征,提出了一種改進(jìn)的基于加權(quán)復(fù)雜網(wǎng)絡(luò)的新聞網(wǎng)頁(yè)關(guān)鍵詞提取算法,并通過實(shí)驗(yàn)證實(shí)了該算法的正確性.
關(guān)鍵詞自動(dòng)提取;新聞網(wǎng)頁(yè)關(guān)鍵詞;復(fù)雜網(wǎng)絡(luò);節(jié)點(diǎn)權(quán)重
隨著互聯(lián)網(wǎng)的快速發(fā)展,網(wǎng)頁(yè)信息量以驚人的速度爆發(fā)式地增長(zhǎng).面對(duì)海量新聞,信息技術(shù)如何輔助人們快速了解新聞主要內(nèi)容,節(jié)省瀏覽時(shí)間,已經(jīng)成為一個(gè)關(guān)注的熱點(diǎn).新聞關(guān)鍵詞的自動(dòng)提取,為該問題提供了一個(gè)有效的解決方案,它也是新聞文檔的自動(dòng)分類、輿論熱點(diǎn)的自動(dòng)發(fā)現(xiàn)、新聞網(wǎng)站的自動(dòng)聚類、個(gè)性化的智能檢索等的基礎(chǔ).現(xiàn)有比較成熟的關(guān)鍵詞提取技術(shù)主要有:基于詞頻統(tǒng)計(jì)的方法[1]、基于機(jī)器學(xué)習(xí)的方法[2]、基于語(yǔ)言學(xué)的分析方法[3],其分別主要從詞語(yǔ)的出現(xiàn)頻率、詞語(yǔ)的訓(xùn)練集、詞語(yǔ)的位置與語(yǔ)義等方面進(jìn)行分析,都存在不同程度的缺陷.近年來,隨著復(fù)雜網(wǎng)絡(luò)的快速發(fā)展,基于復(fù)雜網(wǎng)絡(luò)的關(guān)鍵詞提取算法被眾多學(xué)者所研究,并取得了一定的成果[4-8],這些成果多從單個(gè)角度分析了節(jié)點(diǎn)在局部小世界,或者節(jié)點(diǎn)在整個(gè)網(wǎng)絡(luò)中的影響,而忽視了個(gè)體與總體的辯證統(tǒng)一關(guān)系,并且忽視了吸收傳統(tǒng)關(guān)鍵詞提取方法的一些優(yōu)點(diǎn),在算法上也存在一些缺陷.本文通過分析新聞網(wǎng)頁(yè)文檔的特征,引入節(jié)點(diǎn)權(quán)重、有向網(wǎng)絡(luò)加權(quán)聚類系數(shù)、中心介數(shù)等特征量,并結(jié)合詞性、詞語(yǔ)在文檔中的位置等信息,提出了一種改進(jìn)的基于有向加權(quán)復(fù)雜網(wǎng)絡(luò)的新聞網(wǎng)頁(yè)關(guān)鍵詞自動(dòng)提取算法.
1 復(fù)雜網(wǎng)絡(luò)相關(guān)理論
經(jīng)科學(xué)論證,發(fā)現(xiàn)大多數(shù)真實(shí)的網(wǎng)絡(luò)都表現(xiàn)為復(fù)雜網(wǎng)絡(luò).目前,表征復(fù)雜網(wǎng)絡(luò)模型的主要統(tǒng)計(jì)參量有:節(jié)點(diǎn)的度、度分布、節(jié)點(diǎn)度的相關(guān)性、聚類系數(shù)、平均路徑長(zhǎng)度、介數(shù)、最大連通子圖、模塊性和團(tuán)體等,通過對(duì)統(tǒng)計(jì)參量在網(wǎng)頁(yè)文檔中的物理含義的理解,本文選擇對(duì)節(jié)點(diǎn)的加權(quán)度、聚類系數(shù)、節(jié)點(diǎn)權(quán)重、中心介數(shù)進(jìn)行綜合利用,并改進(jìn)了基于加權(quán)復(fù)雜網(wǎng)絡(luò)的新聞網(wǎng)頁(yè)關(guān)鍵詞自動(dòng)提取算法.
定義1:設(shè)節(jié)點(diǎn)集合V={v1,v2,…,vn},其中n為網(wǎng)絡(luò)中節(jié)點(diǎn)的個(gè)數(shù),有向邊的集合E={(vi,vj)|vi,vj∈V},邊的權(quán)值集合We= {weij|(vi,vj)∈E},故有向加權(quán)網(wǎng)絡(luò)G可以表示為G={V,Wv,E,We}.
定義2:節(jié)點(diǎn)vi的加權(quán)度定義為該節(jié)點(diǎn)連接邊的權(quán)值和,即ij∈
定義3:節(jié)點(diǎn)的聚類系數(shù)Ci改進(jìn)定義為節(jié)點(diǎn)vi的鄰節(jié)點(diǎn)vj組成的集合中彼此實(shí)際有向連邊的權(quán)值和∑wejk與概率存在的最大有向連邊數(shù)A|vj|2乘σ上所有連邊權(quán)值的平均值A(chǔ)∑LLwekm/|E|的比值,即特殊的,當(dāng)為無權(quán)無向圖時(shí),所有連邊的權(quán)值平均值A(chǔ)∑LLwekm/|E|退化為1,權(quán)值和∑wejk退化為鄰節(jié)點(diǎn)連邊數(shù),即該改進(jìn)定義式包含了一般復(fù)雜網(wǎng)絡(luò)的聚類系數(shù)的定義.通過對(duì)原聚類系數(shù)公式的改進(jìn),更能體現(xiàn)有向加權(quán)網(wǎng)絡(luò)中邊的有向性和邊的權(quán)重(邊的權(quán)重在網(wǎng)頁(yè)文檔中,即相同詞語(yǔ)連邊的多次出現(xiàn)).
定義4:節(jié)點(diǎn)的權(quán)值定義為該節(jié)點(diǎn)在節(jié)點(diǎn)集合V={v1,v2,…,vn}中的相對(duì)重要程度.
節(jié)點(diǎn)權(quán)值的定義類比邊的權(quán)值定義得到,定義它的用意是表征節(jié)點(diǎn)的一些屬性,區(qū)別不同節(jié)點(diǎn)的重要程度,引入到新聞網(wǎng)頁(yè)復(fù)雜網(wǎng)絡(luò)中的主要意圖有:第1,區(qū)別網(wǎng)頁(yè)標(biāo)題、核心提示等分句中出現(xiàn)的詞語(yǔ)節(jié)點(diǎn)與普通正文中出現(xiàn)的詞語(yǔ)節(jié)點(diǎn)彼此間不同程度的重要性;第2,區(qū)別不同詞性的詞語(yǔ)以及常用詞等構(gòu)成的節(jié)點(diǎn)在新聞網(wǎng)頁(yè)復(fù)雜網(wǎng)絡(luò)中的重要程度.通過該參量的引入可以結(jié)合傳統(tǒng)關(guān)鍵詞抽取算法的一些優(yōu)點(diǎn),希望能達(dá)到更準(zhǔn)確的關(guān)鍵詞抽取結(jié)果.
2 模型構(gòu)建與抽取算法
復(fù)雜網(wǎng)絡(luò)是復(fù)雜系統(tǒng)研究的一個(gè)重要手段,學(xué)者們從各個(gè)領(lǐng)域進(jìn)行了復(fù)雜網(wǎng)絡(luò)建模、描述與實(shí)證,雖然應(yīng)用領(lǐng)域不同,但思路基本一致,總結(jié)這些模型可以得到復(fù)雜網(wǎng)絡(luò)一般建模方法如圖1所示.
不難發(fā)現(xiàn),在新聞網(wǎng)頁(yè)文檔中,詞是基本的單元,不同詞以不同的詞性和不同的順序連接起來便構(gòu)成了一篇完整的新聞文章,也正是詞的不同組合形式傳達(dá)了形形色色的新聞信息,表達(dá)了人們生活的點(diǎn)點(diǎn)滴滴.本文將網(wǎng)頁(yè)中的詞映射為復(fù)雜網(wǎng)絡(luò)中的節(jié)點(diǎn),將詞與詞之間有序聯(lián)系映射為節(jié)點(diǎn)的有向邊,從而就將1個(gè)網(wǎng)頁(yè)文本轉(zhuǎn)化成了1個(gè)網(wǎng)絡(luò).文本中越重要的詞,也就越有可能是關(guān)鍵詞,映射到復(fù)雜網(wǎng)絡(luò)也就是尋求重要的節(jié)點(diǎn),在網(wǎng)絡(luò)拓?fù)浣Y(jié)構(gòu)中,重要的節(jié)點(diǎn)分為以下2類.

1)加權(quán)度較大、聚類系數(shù)較高的節(jié)點(diǎn).加權(quán)度越大,說明與其連接的節(jié)點(diǎn)越多,其在網(wǎng)絡(luò)中就越重要,映射到新聞網(wǎng)頁(yè)中即該詞出現(xiàn)的頻率越高,這也是文獻(xiàn)[1]基于詞頻統(tǒng)計(jì)方法主要的研究對(duì)象.聚類系數(shù)越高,說明該節(jié)點(diǎn)的鄰節(jié)點(diǎn)組成的集合中彼此實(shí)際的連邊數(shù)越多,說明鄰節(jié)點(diǎn)彼此之間聯(lián)系越緊密,局部范圍內(nèi)聚集性越強(qiáng),映射到新聞網(wǎng)頁(yè)中即該詞的鄰居節(jié)點(diǎn)對(duì)應(yīng)的詞語(yǔ)之間聯(lián)系越緊密,可能體現(xiàn)了原文的某個(gè)小主題,而該單詞則是該主題的主題詞.
2)介數(shù)高的節(jié)點(diǎn).介數(shù)的定義在前文已經(jīng)提及,它指的是網(wǎng)絡(luò)中通過該節(jié)點(diǎn)最短路徑的數(shù)目.顯然,介數(shù)越高,說明通過該介數(shù)的最短路徑越多,一定程度上影響著全文的平均最短路徑,因此該節(jié)點(diǎn)越重要.
綜合考慮前面提及的復(fù)雜網(wǎng)絡(luò)模型的主要統(tǒng)計(jì)參量及其物理意義,本文選擇復(fù)雜網(wǎng)絡(luò)中的聚類系數(shù)和介數(shù)作為網(wǎng)絡(luò)統(tǒng)計(jì)參量,但網(wǎng)頁(yè)文檔作為一個(gè)特殊復(fù)雜網(wǎng)絡(luò)有其本身的一些特點(diǎn),在傳統(tǒng)復(fù)雜網(wǎng)絡(luò)中并不能很好得以體現(xiàn).例如:傳統(tǒng)復(fù)雜網(wǎng)絡(luò)中,網(wǎng)絡(luò)的權(quán)值代表該邊的重要程度,其最短路徑為連通2個(gè)節(jié)點(diǎn)邊的權(quán)值和的最小值.在實(shí)際的文檔網(wǎng)絡(luò)中邊的權(quán)值代表2個(gè)詞的連接次數(shù),間接代表著節(jié)點(diǎn)的重要性,因此其最短路徑顯然不能以權(quán)值和來衡量,事實(shí)上,恰恰相反的是權(quán)值越大距離越近,因此,在最短路徑的計(jì)算中需要改進(jìn)為權(quán)值倒數(shù)的和才能正確體現(xiàn)文檔網(wǎng)絡(luò)的特征;再如,傳統(tǒng)復(fù)雜網(wǎng)絡(luò)初始對(duì)各個(gè)節(jié)點(diǎn)視為同等重要,但在現(xiàn)實(shí)的網(wǎng)頁(yè)文檔中,有些節(jié)點(diǎn)顯然更重要,如網(wǎng)頁(yè)標(biāo)題、相關(guān)主題鏈接、重要的網(wǎng)頁(yè)標(biāo)記如網(wǎng)易網(wǎng)頁(yè)標(biāo)記<description>等中出現(xiàn)的詞,另外,詞語(yǔ)的詞性顯然在不同程度上體現(xiàn)了詞語(yǔ)的重要性,這在傳統(tǒng)分析方法中也得到了較好的應(yīng)用,對(duì)這些節(jié)點(diǎn)的特點(diǎn)本文引入節(jié)點(diǎn)權(quán)重予以描述,初始時(shí),充分利用已知信息對(duì)不同節(jié)點(diǎn)賦予不同權(quán)值.結(jié)合網(wǎng)頁(yè)文檔的這些特征,本文提出了基于有向加權(quán)復(fù)雜網(wǎng)絡(luò)的新聞網(wǎng)頁(yè)關(guān)鍵詞自動(dòng)提取算法如下:
輸入待處理的本地網(wǎng)頁(yè)文檔存儲(chǔ)路徑;
輸出網(wǎng)頁(yè)文檔的K個(gè)關(guān)鍵詞;
Step 1解析網(wǎng)頁(yè)標(biāo)題、正文等相關(guān)信息.各個(gè)門戶網(wǎng)站的網(wǎng)頁(yè)格式不盡一致,對(duì)不同的門戶網(wǎng)站分析其網(wǎng)頁(yè)模板形式,再通過廣泛應(yīng)用的HTMLParser包或正則表達(dá)式即可解析獲取網(wǎng)頁(yè)正文、標(biāo)題、重要標(biāo)記等信息;
Step 2對(duì)網(wǎng)頁(yè)文檔進(jìn)行預(yù)處理.通過正則表達(dá)式判斷原文是否含有中文字符,如果有則認(rèn)為是中文文檔,并采用中文分詞程序?qū)tep 1解析的結(jié)果進(jìn)行分詞,對(duì)去停用詞等預(yù)處理后的分詞結(jié)果,按出現(xiàn)的位置(如標(biāo)題及各重要標(biāo)記)和詞性對(duì)詞節(jié)點(diǎn)賦予初始權(quán)值wv;
Step 3構(gòu)建有向加權(quán)網(wǎng)絡(luò).將上一步得到的詞語(yǔ)進(jìn)行數(shù)字編碼,將編碼結(jié)果作為節(jié)點(diǎn),同時(shí)建立索引表,而網(wǎng)絡(luò)的邊采用文獻(xiàn)[4]中的距離2作為詞語(yǔ)關(guān)聯(lián)關(guān)系的距離,即對(duì)每個(gè)句子循環(huán)判斷,如果一個(gè)詞后續(xù)距離k=1或k=2的位置上有詞語(yǔ),則建立權(quán)重為1的有向邊,邊的方向由前續(xù)節(jié)點(diǎn)指向后續(xù)節(jié)點(diǎn),如果相同詞語(yǔ)有相同方向的連接,則對(duì)網(wǎng)絡(luò)權(quán)重加1;
Step 4計(jì)算各個(gè)節(jié)點(diǎn)加權(quán)度及聚類系數(shù).按前述節(jié)點(diǎn)加權(quán)度及聚類系數(shù)的定義計(jì)算各節(jié)點(diǎn)的值,并對(duì)其進(jìn)行歸一化,再進(jìn)行降序排列,獲得加權(quán)度及聚類系數(shù)綜合值相對(duì)較高的前N個(gè)節(jié)點(diǎn),綜合特征值的計(jì)算式為:
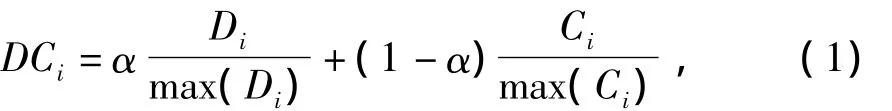
其中,α∈(0,1),本文α取0.5.
Step 5計(jì)算中心介數(shù).上一步獲得的N個(gè)節(jié)點(diǎn)視為中心網(wǎng)絡(luò)節(jié)點(diǎn),尋找中心網(wǎng)絡(luò)兩兩節(jié)點(diǎn)之間的最短路徑,統(tǒng)計(jì)計(jì)算被經(jīng)過所有節(jié)點(diǎn)的歸一化中心介數(shù)B*i;
Step 6生成網(wǎng)頁(yè)的K個(gè)關(guān)鍵詞:

其中,β∈(0,1),wvi∈(0,1),本文β取0.5.式(2)中DCi為Step 4獲得的各個(gè)節(jié)點(diǎn)的加權(quán)度與聚類系數(shù)綜合值,wvi為Step 2中求得的各節(jié)點(diǎn)權(quán)重.由該公式計(jì)算各個(gè)節(jié)點(diǎn)的最終重要程度值,并進(jìn)行降序排列,取前K個(gè)節(jié)點(diǎn)序號(hào)查找索引表獲得關(guān)鍵詞.
3 數(shù)據(jù)獲取與仿真分析
本文數(shù)據(jù)來源于國(guó)內(nèi)外著名的門戶網(wǎng)站新聞模塊,通過構(gòu)建基于Heritrix的垂直搜索引擎,直接獲取搜狐、網(wǎng)易、騰訊網(wǎng)的新聞網(wǎng)頁(yè).這些網(wǎng)站的網(wǎng)頁(yè)都以模塊化形式產(chǎn)生,能友好支持專業(yè)爬蟲工具,并基本涵蓋了重要的有價(jià)值的新聞.實(shí)驗(yàn)首先基于Heritrix-1.14.0構(gòu)建網(wǎng)絡(luò)爬蟲,從指定的網(wǎng)站上爬取網(wǎng)頁(yè)信息保存到本地構(gòu)成網(wǎng)頁(yè)集;然后分析各個(gè)網(wǎng)站新聞模塊的特點(diǎn),結(jié)合HTMLParser和正則表達(dá)式分別提取出各個(gè)網(wǎng)頁(yè)的新聞標(biāo)題、新聞內(nèi)容等,為下一步對(duì)不同節(jié)點(diǎn)賦予節(jié)點(diǎn)權(quán)重做準(zhǔn)備.
解析各部分內(nèi)容后,使用Java版Ictclas對(duì)各個(gè)網(wǎng)頁(yè)進(jìn)行分詞、標(biāo)注詞性.表1給出了對(duì)一則題為《交通銀行發(fā)布聲明稱用戶資料外泄屬謠言》的網(wǎng)頁(yè)標(biāo)題的分詞結(jié)果.

表1 網(wǎng)頁(yè)標(biāo)題的分詞結(jié)果
最后,建立各個(gè)網(wǎng)頁(yè)的復(fù)雜網(wǎng)絡(luò)模型,計(jì)算模型中各參數(shù)值,降序排列計(jì)算所得綜合值,以前K個(gè)詞作為網(wǎng)頁(yè)關(guān)鍵詞.表2給出了對(duì)表1所對(duì)應(yīng)網(wǎng)頁(yè)新聞進(jìn)行建模、分析、計(jì)算所得綜合值降序排列的部分結(jié)果.從處理結(jié)果易知,以這些節(jié)點(diǎn)作為關(guān)鍵詞已基本能代表原新聞的大意,說明了本算法有一定的實(shí)用性.

表2 部分關(guān)鍵詞排序結(jié)果截圖
不失一般性,本文選擇爬取的50篇新聞進(jìn)行分析,引入召回率、準(zhǔn)確率等特征量作為評(píng)價(jià).

其中EKi為第i篇新聞自動(dòng)抽取的關(guān)鍵詞集合,Ti為第i篇新聞的標(biāo)題,N為分析的新聞篇數(shù)(實(shí)驗(yàn)中為50),KEYi為第i篇新聞的核心詞語(yǔ).由于Web信息的特殊性,核心詞語(yǔ)并沒有在新聞中給出,這給自動(dòng)提取關(guān)鍵詞的客觀評(píng)價(jià)帶來了困難,本實(shí)驗(yàn)中新聞的核心詞語(yǔ)是對(duì)新聞標(biāo)題或者網(wǎng)站給出的核心提示進(jìn)行分詞,去除介詞、連詞等詞性后得到的詞語(yǔ),通過實(shí)驗(yàn)計(jì)算獲得的召回率和準(zhǔn)確率數(shù)據(jù)如圖2.

由圖2可知,隨著抽取關(guān)鍵詞個(gè)數(shù)的不斷增加,候選詞不斷增多,導(dǎo)致準(zhǔn)確率達(dá)到一定高度后反倒降低,而隨著候選詞的增加,正確的關(guān)鍵詞越來越多,召回率持續(xù)上升.因此,抽取關(guān)鍵詞的個(gè)數(shù)有著一定的范圍,對(duì)不同的文檔這個(gè)值有一定的波動(dòng).對(duì)由表1對(duì)應(yīng)的網(wǎng)頁(yè)新聞所獲得的召回率和準(zhǔn)確率數(shù)據(jù)存在一定的缺陷,準(zhǔn)確率曲線前4個(gè)點(diǎn)都是100%,反映到關(guān)鍵詞上即“銀行”、“交通”、“稱”、“用戶”等節(jié)點(diǎn)都是正確反映原文內(nèi)容的節(jié)點(diǎn),而后3個(gè)圖反映的是一般情況,即一般情況下排名第1的節(jié)點(diǎn)并不一定在新聞標(biāo)題中,圖中顯示一般為第4~7個(gè)離散點(diǎn)的值才為峰值,即準(zhǔn)確率在抽詞數(shù)為4~7個(gè)時(shí)才達(dá)到最高.由召回率曲線趨勢(shì)可以發(fā)現(xiàn)表1對(duì)應(yīng)的網(wǎng)頁(yè)新聞的召回率存在一定的跳躍性,而后3個(gè)圖變化的趨勢(shì)顯然要光滑,這說明隨著文檔數(shù)的增加,單個(gè)節(jié)點(diǎn)對(duì)召回率的影響要明顯下降,從而呈現(xiàn)出漸變的特性.易知對(duì)50篇新聞的處理結(jié)果更具有一般性,對(duì)該處理結(jié)果單獨(dú)分析,見圖3.

由圖3可以清楚地獲知該50篇新聞在抽取4個(gè)關(guān)鍵詞時(shí)準(zhǔn)確率最高,最高值達(dá)到近70%,并且當(dāng)抽取10~15個(gè)節(jié)點(diǎn)時(shí)召回率達(dá)到70%~80%.由此可以印證由本文算法自動(dòng)抽取的關(guān)鍵詞基本能反映原文大意,而且由于日常習(xí)語(yǔ)、網(wǎng)絡(luò)用詞的存在,自動(dòng)抽取關(guān)鍵詞的準(zhǔn)確率在客觀上應(yīng)該會(huì)略高于實(shí)驗(yàn)數(shù)據(jù)反映的情況,如實(shí)驗(yàn)數(shù)據(jù)中的詞語(yǔ)“西南交通大學(xué)”與“西南交大”的差異顯然會(huì)降低新聞的召回率和準(zhǔn)確率的統(tǒng)計(jì)數(shù)據(jù),但這些關(guān)鍵詞卻能體現(xiàn)原文大意,被人所識(shí)別.

為了進(jìn)一步驗(yàn)證本算法的效果,本文分別采用TF方法(term frequency,詞頻權(quán)重計(jì)算方法)和文獻(xiàn)[5]的方法對(duì)相同的50篇新聞進(jìn)行了對(duì)比實(shí)驗(yàn),實(shí)驗(yàn)結(jié)果如圖4所示.
TF方法的主要思想是利用詞在文檔中出現(xiàn)的頻率來衡量詞對(duì)文檔的重要程度,改進(jìn)的TF方法在考慮局部范圍內(nèi)詞對(duì)文檔的重要程度的基礎(chǔ)上,還考慮了詞在全局范圍內(nèi)的影響.而文獻(xiàn)[5]利用度和聚集系數(shù)對(duì)文檔進(jìn)行了關(guān)鍵詞的抽取.本文在綜合考慮了度、聚集系數(shù)、介數(shù)等基礎(chǔ)上,還結(jié)合了部分語(yǔ)言學(xué)的分析方法,通過引入節(jié)點(diǎn)權(quán)重,將詞性、節(jié)點(diǎn)位置等信息融入,通過圖4對(duì)比可以看出,本文方法較前2種方法有一定的提高.
4 結(jié)語(yǔ)
理論分析與實(shí)驗(yàn)結(jié)果表明本文算法是正確、有效的,通過該算法抽取的關(guān)鍵詞基本能體現(xiàn)原新聞大意,從而為進(jìn)一步的新聞去重、新聞聚類、辨識(shí)不良網(wǎng)站等奠定了前提與基礎(chǔ).另外,由于分詞程序的一些缺陷給實(shí)驗(yàn)結(jié)果帶來了一定的影響,在進(jìn)一步研究中將予以改進(jìn).在理論分析的基礎(chǔ)上,本文還通過Java的數(shù)據(jù)結(jié)構(gòu)實(shí)現(xiàn)了復(fù)雜網(wǎng)絡(luò)圖的存儲(chǔ)及各個(gè)特征參數(shù)的計(jì)算,為復(fù)雜網(wǎng)絡(luò)進(jìn)一步在網(wǎng)絡(luò)信息應(yīng)用研究中提供了實(shí)現(xiàn)工具,這也將為本文算法的應(yīng)用提供更廣闊的空間.
[1]尹倩,胡學(xué)鋼,謝飛,等.基于密度聚類模式的中文新聞網(wǎng)頁(yè)關(guān)鍵詞提取[J].廣西師范大學(xué)學(xué)報(bào):自然科學(xué)版,2009,27(1):201-204.
[2]IKONOMAKIS M,KOTSIANTIS S,TAMPAKAS V.Text classification usingmachinelearningtechniques[J].WSEAS Transactions on Computers,2005,4(8):966-974.
[3]BO Jin,TENG Hong-fei,SHI Yan-jun,et al.Chinese patent mining based on sememe statistics and key-phrase extraction[C]//Proc of ADMA Conference.China:Harbin,2007:516–523.
[4]馬力,焦李成,白琳,等.基于小世界模型的復(fù)合關(guān)鍵詞提取方法研究[J].中文信息學(xué)報(bào),2009,23(3):122-128.
[5]趙鵬,蔡慶生,王清毅,等.一種基于復(fù)雜網(wǎng)絡(luò)特征的中文文檔關(guān)鍵詞抽取算法[J].模式識(shí)別與人工智能,2007,20(6):827-831.
[6]MATSUO Y,OHSAWA Y,ISHIZUKA M.Keyword:extracting keywords in a document as a small world[J].Lecture Notes in Computer Science,2001,2226:271-281.
[7]CANCHO R F I,SOLE R V.The small world of human language[C]//Proceedings of The Royal Society of London.London,2001,268:2261-2265.
[8]ZHANG K,XU H,TANG J,et al.Keyword extraction using support vector machine[C]//Proceedings of the Seventh International Conference on Web-Age information Management(WAIM2006).Hong Kong,2006:85-96.
(責(zé)任編輯莊紅林)
Application of Complex Networks to Keyword Extraction of News Web Pages
TANG Jun
(School of Electrical Engineering,Southwest Jiaotong University,Chengdu 610031,China)
The characteristics of the news web pages documents and the node weights are analyzed,the clustering coefficient of the directed network weight and the center section are introduced.With absorbing the advantages of traditional algorithms,an improved algorithm for the automatic extraction of news keywords based on the weighted complex networks is proposed,and the experiment has proved that this algorithm is correct.
automatic extraction of news keywords;news web page keywords;complex networks;node weights
TP 391
A
1672-8513(2012)04-0305-04
10.3969/j.issn.1672-8513.2012.04.019
2012-03-29.
唐俊(1986-),男,碩士研究生.主要研究方向:網(wǎng)絡(luò)信息技術(shù)及復(fù)雜網(wǎng)絡(luò).
