閾值協整參數的修正估計法小樣本性質的比較
2012-09-26 09:11:00劉漢中李陳華
統計與決策 2012年12期
關鍵詞:方法
劉漢中,李陳華
0 引言
協整方法已經成為宏觀經濟和金融經濟分析的主流,而協整參數向量的估計與檢驗就成為了協整方法論發展中的重中之重。雖然Engle和Granger(1987)[1]的經典論文已經證明:當樣本容量趨于無窮大時,協整向量的OLS估計量具有超一致性,即OLS估計量以T-1階收斂于真實的未知參數。同時,眾所周知,在平穩序列的回歸中,如果解釋變量與隨機干擾項不相關,即解釋變量滿足嚴格外生性(Strict Exogeneity)時,OLS估計量是一致估計量;如果解釋變量不滿足嚴格外生性,則OLS估計不是一致估計量;而在非平穩序列的協整回歸中,即使解釋變量與隨機干擾項相關,則協整參數的OLS估計仍然滿足一致性(Stock,1987[2];Phillips和Hansen,1990[3])。這說明只要樣本容量足夠大,不論解釋變量與隨機干擾項是否相關,OLS估計量是協整參數的一致估計量,這為利用OLS估計協整參數提供了堅實的理論基礎。但是由于在實際經濟分析中,樣本容量的限制,OLS估計方法存在小樣本偏差性已經得到了理論計量經濟學家的高度重視。
我們通過對各種閾值協整設定下的三種估計法(FM-OLS、CCR和DOLS)小樣本性質的模擬并與OLS估計進行比較,揭示各種方法在閾值協整參數估計中的優缺點。這樣一方面可以避免利用傳統的t、F或Wald檢驗對參數約束性檢驗的誤導;另一方面又可以揭示各種修正估計方法在閾值協整參數估計中的性質。目的在于通過在小樣本下各種估計方法的偏差和標準差的比較研究,找出最合適的閾值協整參數估計方法。
1 閾值協整(Threshold Cointegration)概述
Engle和Granger(1987)認為協整是指如果經濟變量Xt=(X1t,X2t,…,XKt)'和Yt之間存在長期協整關系,且正則化協整向量是(1,-β'),則Xt、Yt之間的長期均衡關系可以表示為:

其中 Xt、Yt都是I(1)過程,μt是I(0)過程,且可以表示為一個平穩的自回歸過程。而當Balke和Fomby(1997)把閾值協整引入宏觀經濟分析時,他們認為如果(1)式中的協整誤差項μt的數據生成過程(DGP)是以下閾值自回歸模型(Threshold Autoregression,TAR):
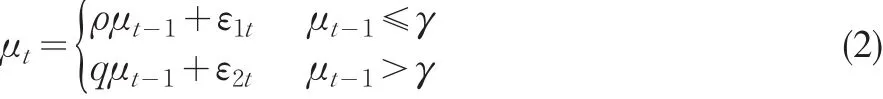
或者
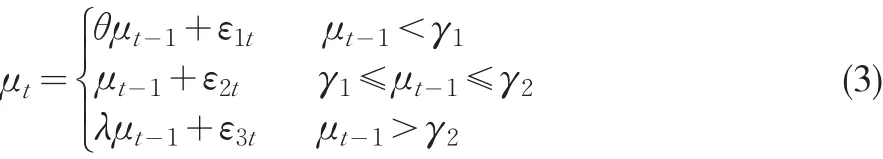
其中,參數β是變量之間的協整系數向量,γ是閾值變量,μt-1是轉換變量。這時的協整被稱之為閾值協整。如果協整誤差項是形如式(2)的數據生成機制,則稱為兩機制(Two-Regime)的閾值協整;如果是形如式(3)的誤差生成機制,則稱為三機制(Three-Regime)的閾值協整。根據Granger表述定理,閾值協整轉化為誤差修正模型,閾值ECM模型具有非線性調整機制,非線性調節對于檢驗經濟學和金融學理論具有重要的意義(劉漢中,2007)[4]。
如果上面的式(1)表示閾值協整時,隨機干擾項必須服從形如式(2)和(3)所示的TAR模型,且同時也要滿足平穩性。對于TAR模型的平穩性,Chan和Petruccelli等(1985)[5]提出了式(2)滿足平穩遍歷的充分條件,即ρ×q<1,ρ,q<1;Bec、Salem和Carrasco(2004)[6]提出了式(3)的平穩遍歷性條件,即θ×λ<1,θ,λ<1,且不論中間機制數據過程是否為單位根過程。
2 閾值協整參數的各種估計方法
2.1 完全修正的最小二乘估計(FM-OLS)
FM-OLS估計是基于協整系統的三角形表述而建立,這種協整表述的優點在于:揭示非平穩變量之間的協整關系。假設n維向量Y,都是服從一階單位根過程,即I(1),且Yt=(Y1t,Y'2t)',其中Y1t是一維標量(Scalar),Y2t是(n-1)×1階向量,同時也假設這些變量之間存在一個閾值協整關系,規范化的協整系數設定為(1,-γ')',因此閾值協整系統表述如下:

其中,隨機干擾項μ1t是形如式(2)或(3)所示的TAR模型,說明式(4)所表示的協整系統是閾值協整,系統的隨機干擾項向量的長期方差-協方差矩陣可以表示為:
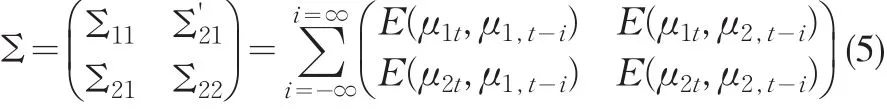
在(5)式中如果矩陣Σ21不為0,說明協整方程的隨機干擾項與解釋變量是相關的,即Y2t不滿足嚴格外生性,則閾值協整系數的OLS估計不再具有正態的漸近分布,這也是FM-OLS估計法提出的主要原因之一。
由于樣本容量長度的限制,長期方差-協方差矩陣的滯后不可能太長,因此要估計式(5)所示的矩陣且要得到一致估計量,必須借助其他方法來進行。目前較常用的估計方法是采用根據Newey-West(1987)[7]所提出的一致估計方法,其中滯后參數q的選擇是根據Newey-West(1994)[8]提出的自動選擇原則,即q=4(的整數部分,該法的優點在于對不同的協方差矩陣采用不同的權數,越近的協方差占的權數也越大,目的在于提高長期方差-協方差估計的收斂速度,同時該估計量是長期方差-協方差矩陣的一致估計量。式(5)的一致估計量為:
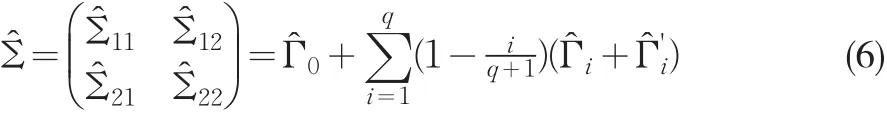
其中:
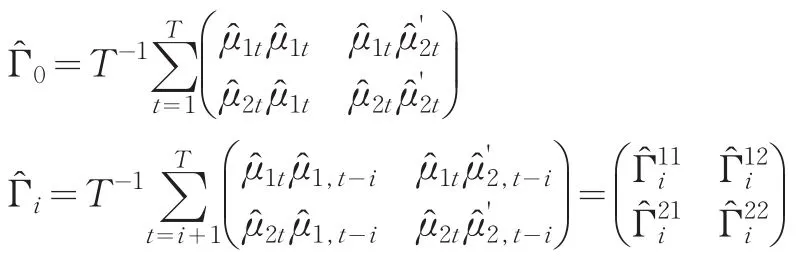

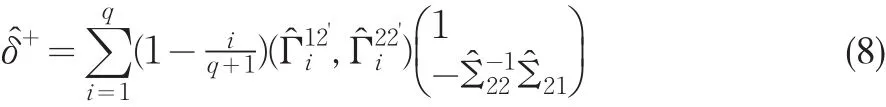
所以,式(7)的FM-OLS估計量的最終表達式可表示為:
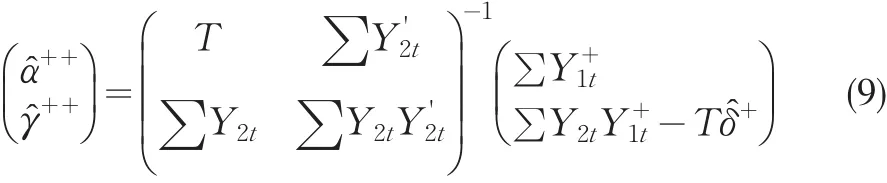
綜上所述,對閾值協整的FM-OLS估計不僅修正了由隨機干擾項的自相關而導致的偏差,而且也可以解決協整回歸解釋變量的內生性問題。在閾值協整中,FM-OLS估計法尤為重要,因為根據閾值協整的定義,協整方程中的隨機干擾項服從TAR模型,隨機干擾項本身存在自相關是不容置疑的;另外在單方程閾值協整建模中,經常性的問題是靜態回歸解釋變量的內生性問題,利用FM-OLS估計可以修正內生性所帶來的影響,此時傳統的Wald統計量仍然具有標準的χ2分布(劉漢中,2010[10])。
2.2 正則協整回歸(CCR)估計法
根據(4)所示的三角形表述,式(6)所表示的長期方差-協方差矩陣可以寫成:

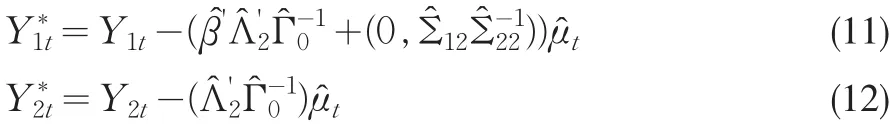
其中,μ?t=(μ?1t,μ?'2t)'是協整方程的OLS殘差與差分變量構成的列向量,是式(4)閾值協整參數γ的OLS估計量,在上述變換的基礎上進行以下回歸:

對(13)進行OLS估計就是閾值協整參數的CCR估計量。Park(1992)已經證明式(13)中參數的OLS估計量是漸近有效估計量(Asymptotically Efficient Estimators),且基于該估計量構造的Wald統計量具有漸近的χ2分布,構造的t統計量具有漸近的標準正態分布,因此CCR估計量與FM-OLS估計量一樣,同樣能修正OLS估計量的小樣本偏差,也同樣具有漸近有效性,并且CCR估計量比FM-OLS估計量計算簡單,更便于操作。
2.3 動態OLS估計(DOLS)
與非參數的FM-OLS和CCR方法不同,DOLS是基于協整回歸式,加入解釋變量的一階差分項的超前(Leads)與滯后(Lags)作為回歸方程的解釋變量,然后再針對新的回歸模型進行OLS估計,以此求得閾值協整參數的估計量。用公式表示如下:
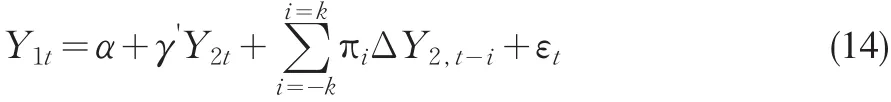
通過對上式進行OLS回歸,求得參數α、γ的OLS估計量就是閾值協整參數的DOLS估計量,并且由DOLS估計量構造的t統計量和Wald統計量具有漸近的標準分布,即分別趨于標準正態分布與標準的χ2分布,這樣可以利用標準分布對閾值協整回歸參數進行統計推斷。對于階數K的確定:運用赤池信息準則(AIC)、許瓦茲信息準則(SC)或利用一般到特殊的建模步驟來確定最佳階數(Ng和Perron,1995)[11],并且Saikkonen(1991)認為階數K只要隨著樣本容量T的增加而增加的速度慢于T13,則(14)的DOLS估計量仍然是超一致估計量,且由此構造的t和Wald統計量仍具有標準的漸近分布。
DOLS估計的基本思想是當(6)中的隨機誤差項μ1t不僅具有自相關而且也與解釋變量Y2t相關時,雖然OLS估計量仍然是超一致估計量,但是在小樣本中OLS估計量具有偏差且基于OLS估計量構造的t和Wald統計量不再具有漸近的標準分布(漸近分布依賴于μt=(μ1t,μ'2t)'的方差-協方差矩陣),此時在協整回歸式中加入解釋變量一階差分的超前和滯后項,可以保證(14)中隨機誤差項與解釋變量(Y2t和ΔY2t)不相關,即(14)中的解釋變量滿足嚴格外生性(Strict Exogeneity),由此得到的DOLS估計量不僅是漸近有效估計量,而且相應的t和Wald統計量具有漸近的標準分布(Saikkonen,1991)。
上述三種估計方法具有同樣的極限分布(Kurozumi和 Hayakawa,2009),并且Saikkonen(1991)已經證明三種估計量都是漸近有效估計量,但在有限樣本中,三種估計法呈現出不同的小樣本性質。目前的研究表明,在不同的數據生成機制下三種方法都有不同的優缺點(Montalvo,1995[23]、Cappuccio 和 Lubian,2001[13]、Christou 和 Pittis,2002[14]等),所以不能籠統地認為哪個方法比其他方法有更加優良的小樣本性質。而在閾值協整中,迄今為止還沒有對三種估計的小樣本性質進行過系統研究。鑒于此,本文將運用模擬技術,揭示三種估計法在各種閾值協整中的小樣本性質。
3 Monte-Carlo模擬設計與研究
3.1 MC模擬設計及部分結果
為了研究各種估計法的小樣本性質,利用三角形表述設定以下的閾值協整系統,不失一般性,Y1和Y2是I(1)單位根過程,且都是一維的:

其中,μ1t服從TAR(1)模型,說明Y1和Y2之間存在閾值協整。如果是兩機制的閾值協整,則μ1t可以設定為式(2);如果是三機制的閾值協整,則為式(3)。隨機干擾項εt設定為:
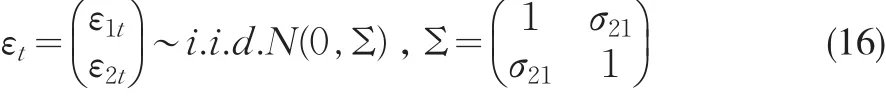
模擬中 σ21分別取0、0.4和0.8,當 σ21=0 時說明(15)中的解釋變量是嚴格外生的。樣本容量分別為150和50,真實的協整參數設定為α=1,β=2,Newey-West(1987)一致估計量的滯后階確定是根據Newey-West(1994)的自動選擇原則,各估計量都模擬10000次,分別計算估計量的偏差和標準差。在DOLS的模擬中,利用AIC準則來確定階數K,K的最大值是不超過12(T/100)14的最大正整數(Kurozumi和Hayakawa,2009)。
在兩機制的閾值協整中,ρ1=0.4和ρ2=0.55,0.75,0.85,0.95,0.99,閾值γ=0.2,這樣設定參數的目的在于:即使樣本容量較小,所生成的數據過程仍包含有閾值效應。見表1。
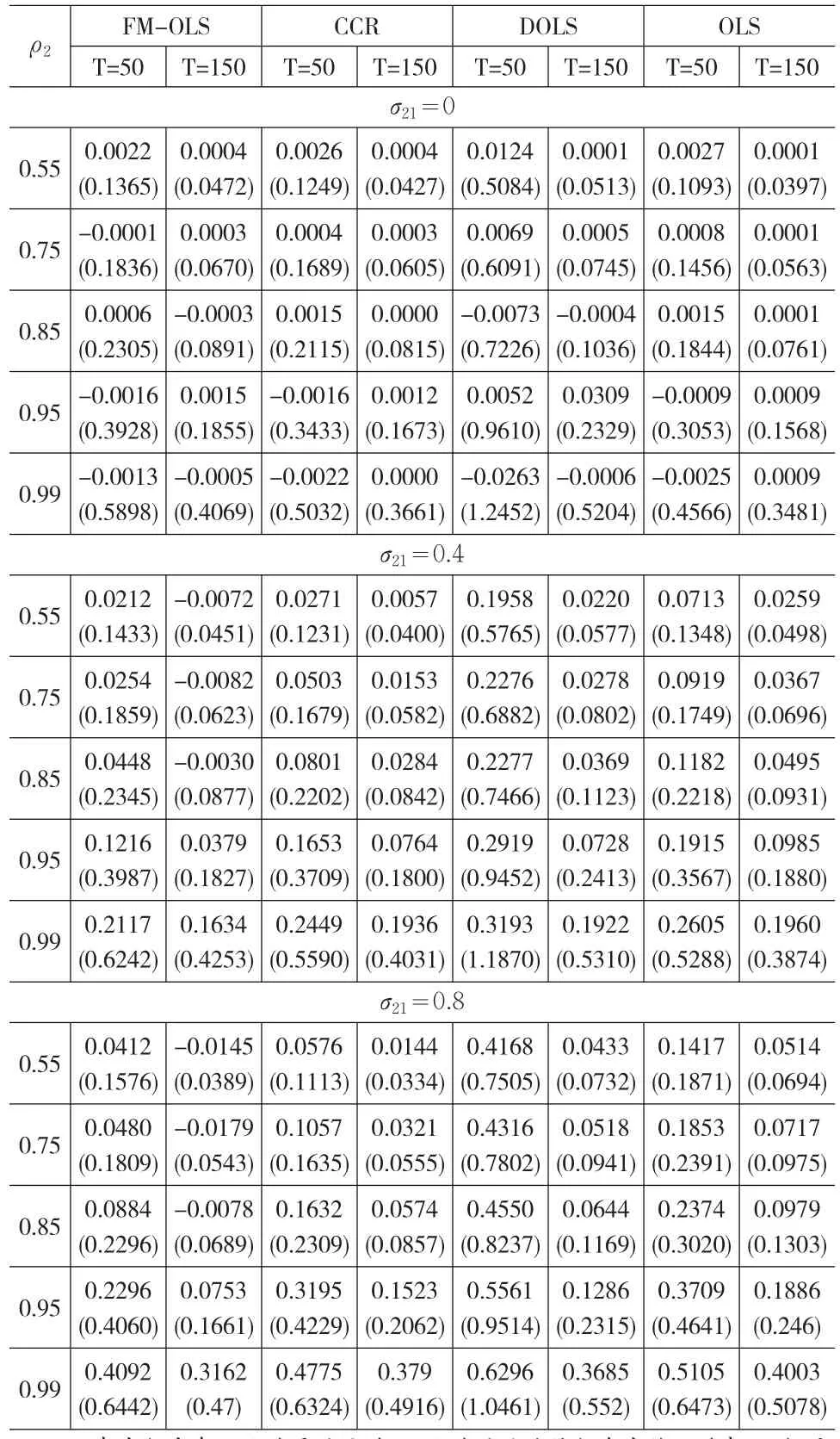
表1 兩機制閾值協整參數估計的小樣本性質
在三機制的閾值協整模擬中,自回歸參數設定與兩機制同,只是閾值設定為0.3,這樣便于各種估計方法在兩種閾值協整中的小樣本性質比較研究,因為自回歸系數相同的三機制模型比兩機制模型具有更多的持久性,即數據過程均值回復的速度要慢。見表2。
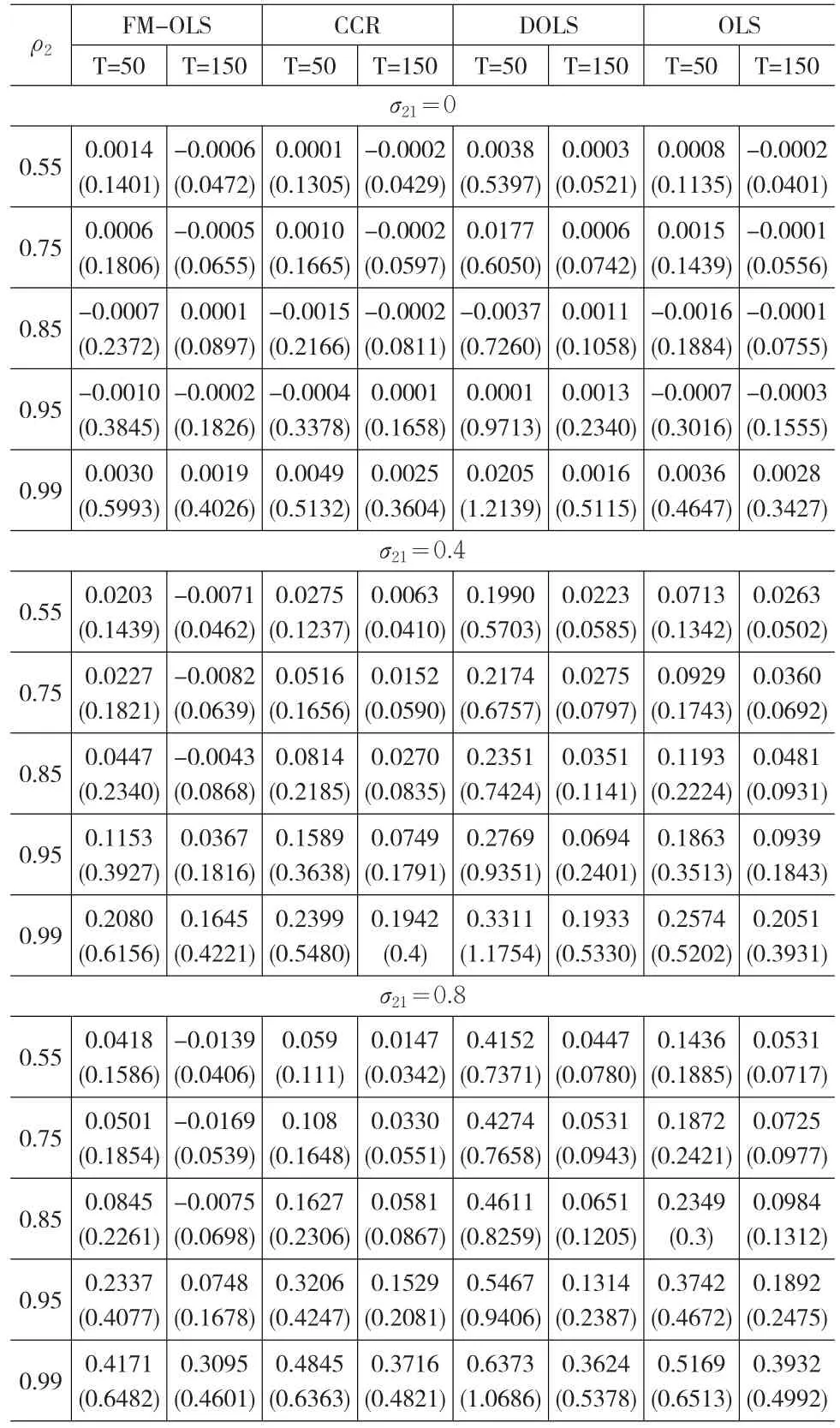
表2 三機制閾值協整參數估計的小樣本性質
從模擬結果可以得出結論:①所有估計量的偏差和標準差會隨著ρ2和σ21的增加而增加,同時在三機制的閾值協整中,所有估計量的偏差與標準差要比兩機制的閾值協整大,這充分說明數據過程的持久性(即數據過程回復均值的速度)是影響各個估計方法的小樣本性質的主要原因;另外隨機誤差項與解釋變量之間的相關程度和樣本容量T也是影響小樣本性質的主要原因,即相關程度越強則偏差與標準差也越大,樣本容量越大則偏差與標準差越小;②在所有情形中,FM-OLS和CCR估計都能或多或少地消除OLS的偏差,但只有在持久性和誤差項與解釋變量的相關性都較強時,FM-OLS和CCR估計比OLS估計更加有效,而DOLS法并沒有修正OLS估計的偏差與標準差;③FM-OLS和CCR估計量的偏差與標準差,需進一步研究才能揭示它們之間的優劣。
3.2 小樣本性質的進一步研究
以估計量的平均值與真實值之差來表示偏差還不能全面揭示估計量的偏差性,必須通過更深層次的研究方能全面、準確反映估計量的偏差,同時光通過估計量的標準差也不能全面揭示估計量的小樣本性質。鑒于此,我們將采用一種新的方法,即設計多個以真實值為中心的區間,計算各種估計量落在區間內的概率,通過該概率就可以更加全面地反映其小樣本性質。具體的設計為:首先設定一個以真實值為上界的區間,如(c-a,c),其中c是真實值,a表示固定間隔的一列參數,這樣就能揭示估計量抽樣分布是否是左偏的;同樣可以設計以真實值為下界的相同長度的區間,能揭示估計量抽樣分布是否是右偏;然后再合并區間和相應的概率,就可以揭示抽樣分布的離散程度(即有效性)。
從前面的模擬結果可非常明顯地得出,在其他條件不變的情況下,各估計量的偏差和標準差會分別隨著ρ2和σ21值的增加而增加,且不論是兩機制還是三機制的閾值協整。因此,這部分的模擬設計中,閾值協整被設定為兩機制閾值協整,設定參數ρ2=0.99和σ21=0.8,樣本容量設定為100,這是宏觀經濟分析中通常所遇到的樣本長度。其他參數設定同上,模擬次數為20000次,參數a的設定為±0.1,±0.2,±0.3,±0.4,±0.5,±0.6,±0.7,±0.8,±0.9,±1,落在區間中概率通過落在區間內的樣本點占全體樣本的比例來估計得到。見表3。
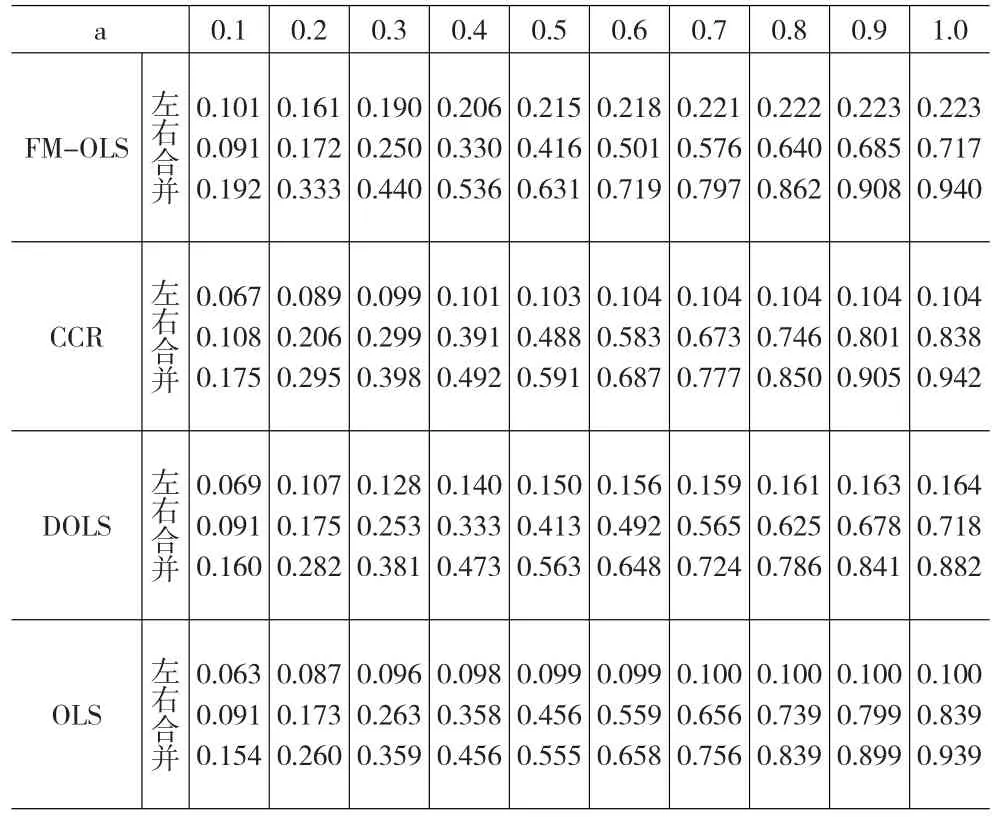
表3 落在給定區間內的概率模擬研究
從結果來看:①四種估計法都呈現出較嚴重的右偏,說明四種估計法都會高估協整參數,尤其OLS和CCR估計更容易高估參數;②FM-OLS估計落在給定區間內的概率是四種方法中最高的,說明FM-OLS估計量比其他估計量更加有效,CCR估計量的有效性次之;③DOLS與OLS法的有效性比較,10種情形中各占5中,即在前5種中DOLS占優勢,而在后5種中OLS估計占優勢。為了進一步能看出各方法的小樣本性質,用核密度估計圖和累積分布圖進行研究,從圖可以得到結論:①四種估計量都能高估未知參數,尤其OLS和CCR估計量高估未知參數的可能性最大;②三種方法的有效性由強到弱的順序是FM-OLS、CCR和OLS,并且四種估計方法都會高估未知的閾值協整參數;③當累積概率小于約0.7時,DOLS比OLS估計有優勢;而當累積概率大于0.7時,OLS估計比DOLS估計更有優勢;因此不能得出DOLS比OLS估計量更加有效的結論。為了比較各種估計法高估未知參數的概率,針對不同的a值得到以下概率趨勢圖:
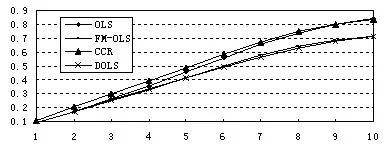
從上圖知,OLS和CCR方法高估未知參數的可能性要大于FM-OLS和DOLS法,且隨著a值的增大OLS高估概率增長要快于CCR法,而FM-OLS和DOLS的概率增加速度很接近,二者增長速度沒有明顯的區別,說明二者高估未知參數的可能性很接近。
4 結論
閾值協整在宏觀經濟分析中具有越來越廣泛的應用,就目前的文獻來看,一般是通過OLS法來估計閾值協整參數,因為OLS估計量具有超一致性。但是在實際的經濟學分析中,由于樣本容量的限制,使得OLS估計量具有偏差,且也不是有效估計量,因此對閾值協整參數估計方法的修正具有十分重要的理論和現實意義。本文針對三種修正的協整參數估計方法(FM-OLS、CCR和DOLS),運用模擬技術,揭示了三種方法在參數估計中的小樣本性質,研究結果表明:①數據過程的持久性、解釋變量與隨機誤差項的相關性和樣本容量是影響估計量小樣本性質的主要因素,即隨著持久性和解釋變量與隨機誤差項的相關性的增強,則四估計量的偏差和標準差就越大,而隨著樣本容量的增加則偏差和標準差就減少;②四種估計方法都會高估未知參數,尤其OLS和CCR估計量高估的可能性最大,而FM-OLS和DOLS高估未知參數的概率很接近;③在同一數據過程下,有效性由強到弱的順序是FM-OLS→CCR→OLS,小樣本偏差由小到大的順序也是FM-OLS→CCR→OLS,而在模擬中,不能得出DOLS比OLS估計量更加有效的結論。對于CCR方法,從右偏概率來看要明顯比FM-OLS和DOLS要大,但比DOLS法更加有效。而對于DOLS估計量,雖然計算很簡單,但是由于沒有更加合適的確定滯后與超前階的方法,使得DOLS估計量的偏差與標準差沒有明顯優勢,因此在現實的經濟分析中,文章的模擬結果顯示DOLS估計法并不是一個好的估計法。綜上所述,在閾值協整的經濟學分析中,對于協整參數的估計,綜合考慮右偏性和有效性。我們認為FM-OLS具有最小的右偏概率且是最有效的估計量。
[1]Engle R.F,Granger C.W.J.Cointegration and Error Correction:Repre?sentation,Estimation and Testing[J].Econometrica,1987,(2).
[2]Stock,J.Asymptotic Properties of Least-Squares Estimators of Cointe?grating Vectors[J].Econometrica,1987,(5).
[3]Phillips,Hansen.Statistical Inference in Instrumental Variables Re?gression with I(1)Processes[J].Reviewsof Economic Studies,1990,(1).
[4]劉漢中.Ender-Granger方法在協整檢驗中的應用研究[J].數量經濟技術經濟研究,2007,(8).
[5]Chan,K.S,Petruccelli,J.D.,H.Tong.A Multiple Threshold Model AR(1)Model[J].Journal of Applied Probability,1985,(2).
[6]Frederique Bec,Melika Ben Salem,Marine Carrasco.Tests for Unit-root Versus Threshold Specification with an Application to the Purchasing Power Parity Relationship[J].Journal of Business&Eco?nomic Statistics,2004,22(4).
[7]Whitney K.Newey,Kenneth D.West.A Simple,Positive Semi-defi?nite,Heteroskedasticity and Autocorrelation Consistent Covariance Matrix[J].Econometrica,1987,(3).
[8]Newey Whitney,Kenneth West.Automatic Lag Selection in Covari?ance Matrix Estimation[J].Review of Economic Studies,1994,(4).
[9]Phillips,P.C.B,Durlauf.Multiple Time Series with Integrated Variable[J].Review of Economic Studies,1986,(3).
[10]劉漢中.閾值協整參數的完全修正的最小二乘估計的小樣本性質研究[J].預測,2010,(6).
[11]Ng,Perron.Unit Root Tests in ARMA Models with Data-dependent Methods for the Selection of the Truncation Lag[J].Journal of the American Statistical Society,1995,(90).
[12]Montalvo,J.G.Comparing Cointegrating Regression Estimators:Some Additional Monte-Carlo Results[J].Economics Letters,1995,(3).
[13]Cappuccio,N,D.Lubian.Estimation and Inference on Long-Run Equilibria:A Simulation Study[J].Econometric Reviews,2001,(1).
[14]Christou,C.,N.Pittis.Kernel and Bandwidth Selection,Prewhitening,and the Performance of the Fully Modified Least Squares Estimation Method[J].Econometric Theory,2002,(4).
猜你喜歡
中老年保健(2021年9期)2021-08-24 03:52:04
河北畫報(2021年2期)2021-05-25 02:07:46
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:33:04
兒童繪本(2020年5期)2020-04-07 17:46:30
兒童故事畫報(2019年5期)2019-05-26 14:26:14
Coco薇(2016年2期)2016-03-22 02:42:52
山東青年(2016年1期)2016-02-28 14:25:23
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
