道路客運(yùn)實(shí)載率分層抽樣的估計(jì)方法
2012-09-26 09:11:00岑晏青
統(tǒng)計(jì)與決策 2012年12期
關(guān)鍵詞:定義
岑晏青,董 靜
0 引言
道路客運(yùn)實(shí)載率是交通運(yùn)輸行業(yè)節(jié)能減排的重要考核指標(biāo),也是運(yùn)輸主管部門合理調(diào)控運(yùn)力的重要依據(jù)。在計(jì)劃經(jīng)濟(jì)的“單車→車隊(duì)→企業(yè)→行業(yè)”分級管理模式下,運(yùn)輸主管部門通過全面統(tǒng)計(jì)報(bào)表制度,對包括實(shí)載率在內(nèi)的所有旅客運(yùn)輸生產(chǎn)指標(biāo)進(jìn)行全面調(diào)查并層層匯總。隨著道路客運(yùn)市場化程度的不斷提高,運(yùn)輸主管部門的職責(zé)由直接經(jīng)營管理轉(zhuǎn)變?yōu)楹暧^政策調(diào)控,掌握每一輛載客汽車的基礎(chǔ)信息已經(jīng)不再可能也沒有必要。此時(shí),調(diào)查成本較低、推算精度有保證的抽樣調(diào)查在全國范圍內(nèi)逐漸推廣應(yīng)用。但由于調(diào)查經(jīng)費(fèi)等原因,以往的公路運(yùn)輸量抽樣調(diào)查主要是針對客運(yùn)量和旅客周轉(zhuǎn)量等核心指標(biāo)進(jìn)行設(shè)計(jì)和實(shí)施,使得實(shí)載率等運(yùn)輸效率指標(biāo)無法進(jìn)行科學(xué)、合理的調(diào)查和推算。
因此,本文將基于道路客運(yùn)實(shí)載率的定義和計(jì)算公式,結(jié)合交通運(yùn)輸部2008年組織開展的全國公路水路運(yùn)輸量專項(xiàng)調(diào)查,提出實(shí)載率指標(biāo)抽樣估計(jì)值及其精度的估計(jì)方法,以期對規(guī)范實(shí)載率指標(biāo)的調(diào)查和推算、支撐交通運(yùn)輸行業(yè)的相關(guān)工作有所裨益。
1 定義和計(jì)算公式
現(xiàn)行的實(shí)載率定義、統(tǒng)計(jì)調(diào)查方式和計(jì)算方法遵循的是2002年交通運(yùn)輸部頒布的《公路、水路、港口主要統(tǒng)計(jì)指標(biāo)及計(jì)算方法規(guī)定》,是基于原計(jì)劃經(jīng)濟(jì)條件下“單車→車隊(duì)→企業(yè)→行業(yè)”的全面調(diào)查方式而設(shè)計(jì)的。根據(jù)定義,道路客運(yùn)實(shí)載率是指報(bào)告期內(nèi)載客汽車完成的旅客周轉(zhuǎn)量占總行程載客量的比重,用以反映總行程載客量利用程度,計(jì)算公式為:

設(shè)ki,yi,xi分別為第i輛載客汽車的實(shí)載率、旅客周轉(zhuǎn)量和總行程載客量,則對于單車而言,其實(shí)載率ki的計(jì)算公式為:

對于車隊(duì)、企業(yè)或行業(yè)而言,實(shí)載率的計(jì)算公式為:
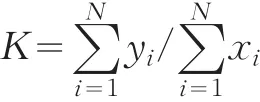
其中,N為車隊(duì)、企業(yè)或行業(yè)擁有載客汽車的數(shù)量。可見,在全面統(tǒng)計(jì)報(bào)表制度下,只要掌握了所有載客汽車的旅客周轉(zhuǎn)量 yi和總行程載客量 xi(即i=1,2,3,……N),利用上述計(jì)算公式就可以得出總體N(如全行業(yè))或者任何一個(gè)子總體Nj(如車隊(duì)或企業(yè))的實(shí)載率k或者kj。但在抽樣調(diào)查中,由于只獲取了部分載客汽車(即樣本車輛)的相關(guān)數(shù)據(jù),此時(shí)i=1,2,…,n(n<N),要計(jì)算出總體N或者某一子總體Nj的實(shí)載率k或者kj,就必須要遵循抽樣調(diào)查方法對目標(biāo)變量的均值和方差進(jìn)行推算。
2 兩種估計(jì)方法
為提高抽樣效率,2008年全國公路客運(yùn)專項(xiàng)調(diào)查以地市、車輛類型、線路類型和標(biāo)記客位等指標(biāo)作為分層標(biāo)志,采用了較為復(fù)雜的多重分層抽樣方法。這里為方便討論,我們假設(shè)只進(jìn)行了一次分層。下面討論實(shí)載率指標(biāo)的兩種估計(jì)方法。
2.1 定義法
所謂定義法,就是嚴(yán)格按照實(shí)載率的計(jì)算公式,先分別估計(jì)旅客周轉(zhuǎn)量Y和總行程載客量X兩個(gè)中間變量的估計(jì)值,再利用計(jì)算公式實(shí)載率K=Y/X得到K的估計(jì)值。
根據(jù)抽樣方案設(shè)計(jì),旅客周轉(zhuǎn)量Y采用逐層推算的模式。設(shè)yhi為第h層第i個(gè)樣本車輛的旅客周轉(zhuǎn)量,nh和Nh分別為對應(yīng)層的載客汽車樣本數(shù)和總體數(shù),Yh為對應(yīng)層的旅客周轉(zhuǎn)量。
根據(jù)分層抽樣調(diào)查的推算原理,第h層樣本車輛的平均旅客周轉(zhuǎn)量為:
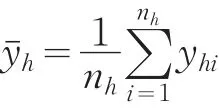
第h層旅客周轉(zhuǎn)量的估計(jì)值Y?h為:
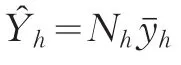
Y?h的方差估計(jì)值 v(Y?h)為:
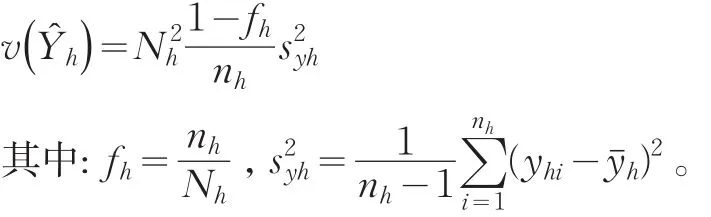
由此可得,旅客周轉(zhuǎn)量Y的估計(jì)值Y?為:
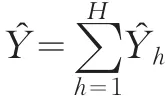

在正態(tài)分布假定條件下,Y?的置信水平為1-∝時(shí)的置信區(qū)間為:
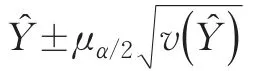
按照同樣的步驟,可以獲得總行程載客量X的置信水平為1-∝時(shí)的置信區(qū)間為:
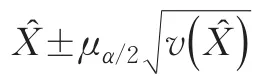
其中,X?為總行程載客量X的估計(jì)值,v(X?)為 X?的方差估計(jì)值。
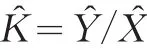
顯然,根據(jù)現(xiàn)有抽樣技術(shù)理論,估計(jì)值K?的方差是無法進(jìn)行科學(xué)計(jì)算的。但按照精度估計(jì)的穩(wěn)健性原則,可以根據(jù)Y?和X?的置信區(qū)間來估計(jì)出K?的近似置信區(qū)間。實(shí)載率K?的置信水平為(1-∝)2時(shí)的近似置信區(qū)間為:
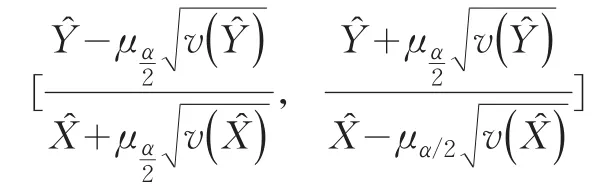
2.2 變量替換法
所謂變量替換法,就是根據(jù)調(diào)查數(shù)據(jù)計(jì)算出每一個(gè)樣本車輛的實(shí)載率ki=yi/xi,然后將ki視為目標(biāo)變量進(jìn)行分層簡單估計(jì),得到K的估計(jì)值及其方差。
根據(jù)抽樣方案設(shè)計(jì),實(shí)載率K同樣也采用逐層推算的模式。設(shè)khi為第h層第i個(gè)樣本車輛的實(shí)載率,nh和Nh分別為對應(yīng)層的載客汽車樣本數(shù)和總體數(shù),kˉh為對應(yīng)層的實(shí)載率。
根據(jù)分層抽樣調(diào)查的推算原理,第h層樣本車輛的平均實(shí)載率 kˉh為:
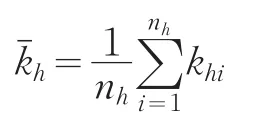
第h層總體車輛的實(shí)載率估計(jì)值K?h為:
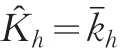
K?h的方差估計(jì)值 v(K?h)為:
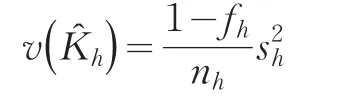
由此可得,實(shí)載率K的估計(jì)值K?為:
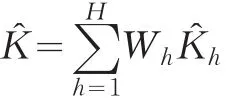
K? 的方差估計(jì)值 v(K?)為:

在正態(tài)分布假定條件下,K?的置信水平為1-∝時(shí)的置信區(qū)間為:
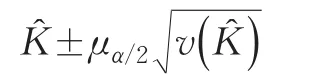
3 實(shí)例分析
以2008年陜西省班線客車運(yùn)輸量調(diào)查為例,為簡化計(jì)算,假設(shè)僅按經(jīng)營線路類型分為縣內(nèi)班線客車、跨縣班線客車、跨地市班線客車和跨省班線客車4層(即h=1)。已知:N1=7427,N2=5210,N3=3646,N4=1308,n1=784,n2=443,n3=341,n4=155;可得 f1=0.1056,f2=0.0850,f3=0.0935,f4=0.1185,W1=0.4222,W2=0.2962,W3=0.2073,W4=0.0744。
采用上述兩種方法對該省班線客車實(shí)載率進(jìn)行估計(jì),設(shè)Y為日均旅客周轉(zhuǎn)量,X為日均總行程載客量,K為客運(yùn)實(shí)載率。根據(jù)調(diào)查數(shù)據(jù)計(jì)算出來的有關(guān)結(jié)果見表1。
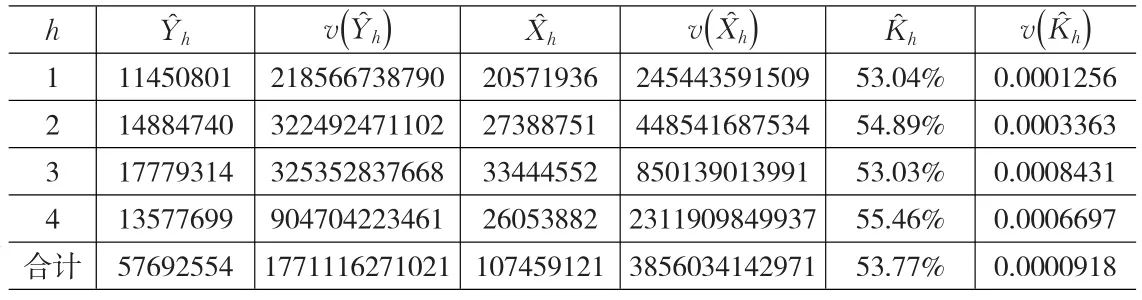
表1 根據(jù)調(diào)查數(shù)據(jù)計(jì)算出來的有關(guān)結(jié)果
3.1 采用定義法
實(shí)載率的估計(jì)值K?為:

實(shí)載率K?的(1-∝)2=90.25%的置信區(qū)間近似為:
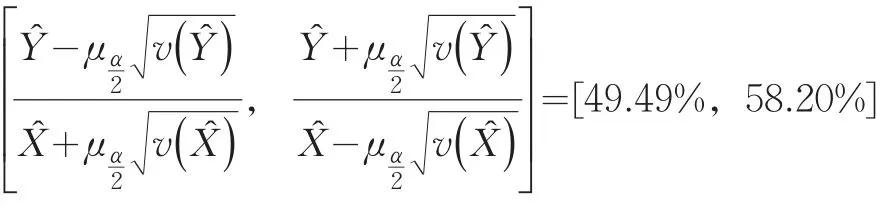
3.2 采用變量替換法
實(shí)載率的估計(jì)值K?為:
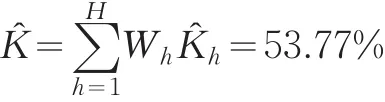
實(shí)載率K?的1-∝=95%的置信區(qū)間為:
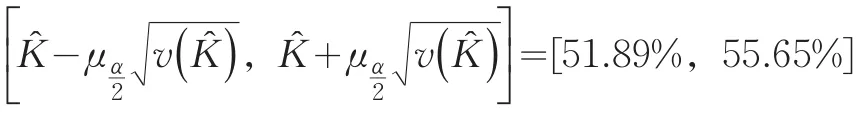
上述結(jié)果表明,采用定義法和變量替換法計(jì)算得到的實(shí)載率估計(jì)值K?基本相同,分別為53.69%和53.77%,兩者相差不到0.1%;但估計(jì)的置信區(qū)間顯示出變量替換法的精度要明顯高于定義法。
4 結(jié)論
本文基于抽樣調(diào)查的理論和方法,從道路客運(yùn)實(shí)載率的定義和計(jì)算公式出發(fā),研究提出了分層抽樣條件下實(shí)載率的兩種估計(jì)方法,即定義法和變量替換法;并以2008年陜西省班線客車運(yùn)輸量調(diào)查為例,對兩種估計(jì)方法進(jìn)行了實(shí)證分析。結(jié)果表明,適用于全面統(tǒng)計(jì)報(bào)表制度的定義法同樣也適用于抽樣調(diào)查方法,但其估計(jì)精度和操作簡易性方面卻遠(yuǎn)不及變量替換法,尤其是采用多重分層抽樣時(shí),變量替換法的優(yōu)勢將更為突出。事實(shí)上,本文提出的估計(jì)方法不僅可用于實(shí)載率的推算,同時(shí)也可以應(yīng)用于里程利用率、客位利用率等其他運(yùn)輸效率指標(biāo)的推算,為道路運(yùn)輸統(tǒng)計(jì)調(diào)查提供了新的思路和方法。
[1]中華人民共和國交通部.公路、水路、港口主要統(tǒng)計(jì)指標(biāo)及計(jì)算方法規(guī)定[M].北京:人民交通出版社,2002.
[2]馮士雍等.抽樣調(diào)查——理論、方法與實(shí)踐[M].上海:上海科學(xué)技術(shù)出版社,1994.
[3]杜子芳.抽樣技術(shù)及其應(yīng)用[M].北京:清華大學(xué)出版社,2005.
猜你喜歡
幼兒教育·父母孩子版(2022年4期)2022-05-08 21:35:35
中學(xué)生數(shù)理化(高中版.高考數(shù)學(xué))(2021年3期)2021-06-09 06:09:14
中學(xué)生數(shù)理化(高中版.高二數(shù)學(xué))(2021年12期)2021-04-26 07:43:38
中學(xué)生數(shù)理化(高中版.高二數(shù)學(xué))(2021年2期)2021-03-19 08:54:04
海峽姐妹(2020年9期)2021-01-04 01:35:44
華人時(shí)刊(2020年13期)2020-09-25 08:21:32
VOGUE服飾與美容(2020年9期)2020-09-02 14:47:26
山東青年(2016年1期)2016-02-28 14:25:25
汽車維護(hù)與修理(2015年6期)2015-02-28 12:16:55
當(dāng)代修辭學(xué)(2014年3期)2014-01-21 02:30:44
