基于支持向量機的高新技術企業與傳統企業的類型辨識模型研究
2012-09-29 08:10:46潘建欣張瑞穩
中國科技論壇 2012年8期
鄭 佳,潘建欣,張瑞穩
(1.中國科學技術大學管理學院,安徽 合肥 230026;2.清華大學核能與新能源技術研究院,北京 100084)
基于支持向量機的高新技術企業與傳統企業的類型辨識模型研究
鄭 佳1,潘建欣2,張瑞穩1
(1.中國科學技術大學管理學院,安徽 合肥 230026;2.清華大學核能與新能源技術研究院,北京 100084)
基于支持向量機神經網絡理論,首創性地建立了一個由業績產出財務指標辨識高新技術企業與傳統企業類型的支持向量機模型。模型以企業的業績產出財務指標數據為基礎,以徑向基函數作為核函數,使用網格尋優方法調節模型參數,得到優化后的模回去型,并使用測試集數據驗證了模型。對結果進行二元分類決策分析,結果表明:該模型的準確率和決策率等主要評價指標都達到了85%以上,具有較高的辨識能力和可信度,為高新技術企業和傳統企業的類型辨識提供了一種可靠的、簡單方便的方法,可以直接量化地判別企業是否屬于高新技術企業。
高新技術企業;類型辨識模型;支持向量機;神經網絡
1 引言
高新技術企業在國家的經濟增長中起著重要作用,但是由于高新技術是一個動態發展、不斷演進的過程,這使得高新技術企業很難有能夠被廣泛接受的定義。在中國,高新技術企業主要是產品 (服務)屬于國家重點支持的高新技術領域,且研發投入密集度、科研人員比例符合條件的企業,但這一定義并沒有細化至每個企業的生產方式及產品 (服務)。現行的定義可能導致:處于傳統領域的某些企業,仍然具有領先的工藝、卓越的創新能力,且創新性、成長性和盈利能力優于某些高新技術企業,但是因所處的行業不屬于國家重點支持的高新技術領域,而無法認定為高新技術企業;或者,某些高新技術企業的業績表現,并不具備高成長性和高盈利性。高新技術企業資質作為企業的無形資產,是企業科研實力的有力證明,可以獲得稅收政策、人才引進、投融資、土地和工商等各方面的優惠。據統計,2012年第一季度中,148家通過高新技術企業資格復審的創業板企業中,有27家沒有達到高新技術企業的認定標準;對于上述不符合高新技術企業認定的公司,如果按利潤總額乘以10%的企業所得稅優惠粗略計算的話,僅2011年,這27家企業就至少享受了2.61億元的企業所得稅優惠。因此,對于管理者、投資者、戰略政策的研究制定者,制定出更清晰成熟的高新技術企業評價標準就具有重要意義;也正因為如此,我們嘗試從財務指標的角度,建立模型,希望能形成更公正客觀的認證評價標準。
Oakey和Mukhar(1999)[1]主張績效指標是高新技術企業與傳統企業的重要區分指標。正是由于在資源投入上高新技術企業與傳統企業之間存在顯著差異,因此在業績產出上,高新技術企業應當表現出與其高技術、高投入、高風險相對應的財務特征;但這并不能滿足市場上信息需求者的要求。Nicholas和Martin(2008)[2]的研究指出現有的標準產業分類 (SIC)只能將企業進行模糊的分類,而不是建立在系統分類的基礎上,并證實使用績效指標途徑來定義高新技術企業的可能。
Vapnik(1995)[3]基于統計學習理論提出了支持向量機 (support vector machine,SVM)神經網絡,具有魯棒性、計算簡單以及理論上完善等優點,可用于模式分類和非線性回歸的研究。已有文獻報道了SVM用于商業銀行構建企業破產預測機制[4]、上市公司經營決策失敗預警[5]和糧食產量預測[6]等領域,但暫未有SVM用于高新技術企業與傳統企業分類研究的文獻報導。
2 類型辨識模型的建立
2.1 模型理論
SVM模型主要思想是建立一個超平面作為決策曲面,使得正例與反例之間的隔離邊緣被最大化。對于考慮訓練樣本,其中x為第i個
i輸入模式向量,di為對應的目標輸出,用于分離的超平面形式的決策曲面方程則為:wTx+b=0,使得wTx+b>0時di=+1,否則為-1。其中在正反例附近用于確定最優決策超平面的向量稱為支持向量,也是最難區分的數據點。理論研究表明模型的原問題即最優分離邊緣為2/||w||,通過最小化權值向量w的歐幾得里范數||w||,提供正反例之間的最大分離的可能。一般通過Lagrange乘子方法轉化成其對偶問題,解決約束最優問題。建立的Lagrange函數為:
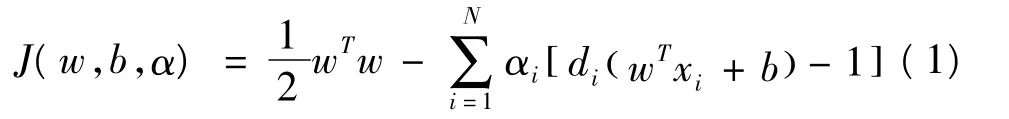
其中的α為輔助的Lagrange乘子,在N個向量中αi為非負值的向量即為支持向量。
在LIBSVM工具箱中,SVMtrain函數中預設的用于分類的C-SVM類型,其決策函數為:
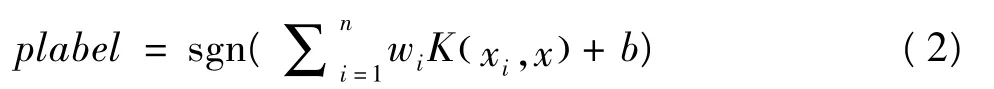
其中K為核函數,其主要類型有線性核函數、多項式核函數、徑向基核函數和sigmoid核函數等。研究表明,在一般條件下徑向基函數K(xi,x)=exp(-r|xi-x|2),表示以x為中心、xi到x的徑向距離半徑為r形成的構成的函數系,具有較好普適性。
2.2 建模過程
本文使用具有產出性質的10項績效財務指標作為參數,直接量化地判別企業是否屬于高新技術企業。區別于我國目前《高新技術企業認定管理辦法》中,“企業產品 (服務)屬于《國家重點支持的高新技術領域》”加“研發人員及R&D投入強度標準”的認定方法,避免了樣本的投入性參數和依據此類參數所確定的高新企業之間存在的必然聯系;總結已有的相關文獻在指標設置上出現的頻度,主要從企業的盈利能力、成長能力、營運能力上來選定財務指標,這十項績效財務指標分別為:總資產凈利率、成本費用利潤率、銷售毛利率、主營業務收入增長率、凈利潤增長率、凈資產增長率、總資產增長率、存貨周轉率、固定資產周轉率和總資產周轉率。在選擇樣本企業時還考慮到:樣本企業是否上市與該企業是否屬于高新技術企業沒有必然聯系;本模型使用十項績效財務指標對企業類別進行判斷,將模型所得結果與該企業的真實分類進行比較,作為模型判斷的準確率;為了保證樣本數據的絕對真實可靠,防止原始數據的不準確引起的模型準確率下降,因此選用財務數據更可靠的上市公司作為樣本企業。
根據2008年4月24日由財政部、科技部、國家稅務總局聯合發出的《高新技術企業認定管理辦法》,以及《2010年國家高新技術企業名單》隨機抽取102家高新技術上市公司,剔除數據不全的企業,得到98家樣本企業,這98家樣本企業中有創業板上市公司21家,非創業板上市公司77家;學者王今朝、王靜 (2008)[7]認為,我國當前的傳統產業主要屬于第二產業中的原材料工業以及加工工業中的輕加工工業,主要包括紡織業、輕工、部分機械、化工和建材工業。并根據證監會2010年頒布的《上市公司行業分類指引》,從食品飲料(C0)、紡織業 (C11)、煤炭采選業 (B01)、建筑業 (E)的130家企業中剔除財務特征異常的ST板塊和數據不全的企業,為了保證數據的一致性和可比性,再隨機抽取與高新技術企業數相當的企業,得到99家傳統企業樣本;選取此197個樣本企業2007—2010年的年報數據中盈利能力、成長能力、營運能力10個參數為輸入值。
建立模型首先從原始數據中隨機分離出訓練集和測試集,訓練集用于神經網絡的學習,得到合適的模型;測試集用于測試網絡的泛化能力,即檢驗模型的正確性。正態分布化、歸一化和主成分分析降維等方法對數據進行預處理,得到有效不失真的處理后數據。使用訓練集數據訓練得到SVM模型,使用測試集數據對模型進行檢驗,并不斷調節模型參數,得到最優模型。使用模型對未知數據的運算,判斷企業是否為高新技術企業,達到預測的目的。
3 模型的Matlab實現
模型利用Matlab軟件包編程,使用臺灣大學林智仁教授等[8]開發的LIBSVM工具箱,部分函數參考了 Faruto等[9]基于 LIBSVM開發的加強工具箱。
3.1 原始數據處理
原始數據整體保存在corporation.mat文件中,記錄了全部197個樣本的10個參數值的197×10 double型的名為corp的矩陣,以及一個197×1的double型列向量corp_labels記錄企業類型標簽(T設置為傳統企業,C為高新技術企業)。使用load命令載入數據,并使用figure命令查看數據。
3.2 原始數據的預處理
將corp的197×10矩陣按每一列 (即每個指標)進行正態化,得到正態化后的197×10矩陣corp_norm,目的是獨立地將每一個特征成分正態化為特定區間范圍。這樣確保更大值的輸入屬性不會覆蓋更小值的輸入屬性,有助于減少預測誤差[10]。
使用ismember(corp_labels,H)命令,對企業標簽corp_labels列向量元素進行邏輯判斷,是“H”的元素為logic型的“1”,即為高新技術企業,不是“H”的元素為logic型的“0”,為傳統企業。得到了一個名為groups的197×1的列向量。使用[train,test]=crossvalind('holdOut',groups,0.40)命令劃分訓練集和測試集。其中crossvalind是產生交差檢驗 (Cross-Validation)的函數,從groups集中以40%的概率隨機選出近似比例的測試集。輸出為一個含78(約197×40%)個logic“1”元素的197×1的test集,以及一個含119(=197-78) 個 logic“1”元素的 197×1的train集。利用train和test集,隨機挑選得到了訓練集和測試集的數據和標簽,分別為train_corp,train_corp_labels,test_corp和test_corp_labels。
經驗表明,對數據進行歸一化處理,可以提高模型的準確率。對上一步得到的train_corp和test_corp采用 [0,1]歸一化,得到了119×10的歸一化后的訓練集train_scale和78×10的歸一化后的測試集test_scale。
變量個數太多就會增加課題的復雜性,使用主成分分析方法,從中可以取出較少的綜合變量盡可能多地反映原來變量的信息。對train_scale和test_scale進行主成分分析,如圖1所示,當10個參數降維成7個參數時,仍保留了95%的原始數據信息。得到了119×7的 PCA后的訓練集train_pca和78×7的歸一化后的測試集test_pca。代碼如下:
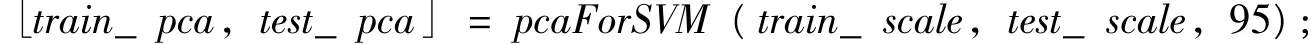
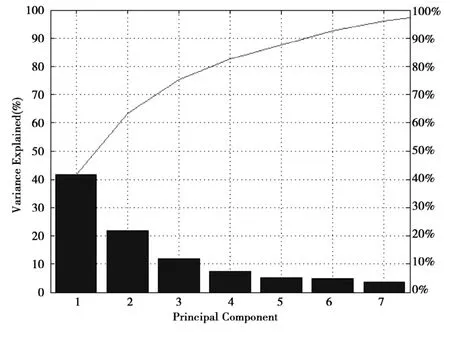
圖1 SVM模型數據的主成分分析圖
3.3 建模
使用依次進行正態化,歸一化和主成分分析后得到數據進行網絡訓練,得到SVM網絡模型。代碼如下:

模型的輸入值為測試集標簽train_corp_labels和處理后的數據 train_pca,參數'-s 0 -t 2'表示使用了SVMtrain函數中預設的用于分類的C-SVM類型,其核函數類型徑向基函數。'-c 7-g 2'中c和g是SVM神經網絡的兩個重要參數,分別對其賦值為7和2,具體選擇和優化在3.5節討論。命令輸出得到了一個名為model的數據結構體,包含決策函數中的承裝系數列向量w(model.sv_coef)和常數項系數的相反數-b(rho),以及得到了支持向量 (SVs)等參數。
3.4 模型預測
使用svmpredic命令,建模得到的model結構體,以及用于測試的標簽和數據test_corp_labels和test_pca進行預測,Matlab命令如下:

命令輸出78×1預測后的標簽predict_label列向量和準確率Accuracy=85.8974%(67/78)。
3.5 c和g參數優化
核參數c和g是徑向基函數RBF的SVM兩個重要參數,對模型的性能起關鍵作用,不合適的c和g會導致網絡欠學習或者過學習。最優SVM算法的核函數和參數選擇,目前沒有理論依據,只能是憑借經驗、實驗對比、大規模搜索以及使用交叉驗證方法進行尋優。交叉驗證方法可以在沒有測試集表情的情況下,找到一定意義上的最佳參數c和g,即能使訓練集在交叉驗證下達到最高分類率,但并不能保證在測試集下也能達到最高分類準確率。
常用的經驗方法有網格尋優、基于遺傳算法尋優和基于粒子群算法尋優。本模型選用最簡單的網格尋優,即建造二維的cg網格,在網格暴力尋找最大的準確率及其對應的c和g值。使用內置的SVMcgForClass函數尋優,在c和g都在 [2-10,210]廣域區間內搜索,后縮小至c為 [2-3,24],g 為 [2-5,22]區間內以 20.2的步長,使用 5-folder交叉驗證方法尋找最佳值,Matlab代碼為:

輸出得到了最大的精度值和對應的最佳c值bestc_cg和g值bestg_cg。需要說明的是,只是對測試標簽和數據進行運算,還需要在該計算值附近手動尋找最佳值,本例選取了c為7和g為2。
4 結果分析
4.1 模型結果分析
使用CR_train=ClassResult(train_corp_labels,train_pca,model,1)查看訓練集結果。結果表明:支持向量數目為93,整體分類準確率為92.437%(110/119),其中高新技術企業分類準確率為89.8305%(53/59),傳統企業分類準確率達到了95%(57/60),學習效果好。同樣的,CR_test=ClassResult(test_corp_labels,test_pca,model,2)命令查看測試集結果,整體分類準確率達到了85.8974%(67/78),其中高新技術企業分類準確率為87.1795%(34/39)傳統企業分類準確率達到了84.6154%。
對于二元分類決策分析,多使用Tp、Fp、Tn和Fn等參數來計算準確率、決策率、召回率、F參數、特異值和綜合平衡參數等評價模型。其中,Tp表示模型辨識正確的正例數,Fp表示模型辨識錯誤的正例數,Tn表示模型辨識正確的反例數,以及Fn表示模型辨識錯誤的反例數。對于本模型而言,Tp、Fp、Tn和Fn的含義及對應數值如表1:

表1 驗證集參數結果表
計算得到準確度:Accuracy=85.8974%,即高新技術企業和傳統企業都被正確判別的數量占整個樣本數的比重,反映了模型對整個樣本的判斷能力;決策率:Precision=85%,表示被模型判斷為高新技術企業的40家企業中,34家真正的高新技術企業所占的比重,即模型做出企業為高新技術企業的判斷,Precision表示這一判斷的可信程度;召回率:Recall=87.1795%,表示在實際為高新技術企業的39家之中,被模型正確判定為高新技術企業的34家企業所占的百分比,即模型從樣本企業中正確辨識出高新技術企業的能力,該參數也被稱為靈敏度 (Sensitivity);特異性:Specificity=84.6154%,表示在實際真為傳統企業的39家之中,被模型正確判定為傳統企業33家所占的百分比。總體F評估指數:F-score=86.0759%,總體平衡精度:BAC=85.8975%,上述兩項是綜合評價指標,評價模型對兩類指標的整體判別能力。本模型的主要評價參數指標大于85%,可知本模型在高新技術企業與傳統企業的類型辨識上具有較高的辨識能力和可信度。
4.2 模型預測
構建的模型目的是用于對未知企業是否為高新技術企業進行辨識,只需要該企業 (或M個企業)的10個參數,構成M×10的數據矩陣Data,元素為隨機生成0和1的M×1標簽列向量Labels,表明在測試前隨意的劃歸企業為傳統的非高新的(T)或是高新的 (H),然后使用svmpredict函數,輸出N×1的預測的標簽Predict_label。
[Predict_label,Accuracy]=svmpredict(Labels,Data,model);
需要說明的是,由于Labels中的數據是隨機的,企業是否為高新技術企業未知,只是程序計算時所需的初始賦值,而準確率Accuracy,僅表示初始的Labels和最終結果Predict_label相同的比率,在此處是沒有意義的。查看Predict_label列向量的數據,當某行結果為1時表明對應的該企業是高新的,否則是傳統的。對高新技術企業和傳統企業,其預測結果的決策接受率,即 Precision和Recall,才是用于預測時的模型準確率,由測試集的結果來看,達到了85%和87.1795%,因此模型是可靠的。
5 結論
本文首次將支持向量機神經網絡引入到高新技術企業與傳統企業的類型辨識研究,建立了一個支持向量機神經網絡的模型,使用企業的業績產出財務數據直接辨識該企業是屬于高新技術企業或者傳統企業。模型的原始數據經過正態分布化、歸一化和主成分分析降維等方法,以徑向基函數為核函數,使用訓練集數據訓練得到了模型,利用網格尋優方法調節模型的c參數和g參數,并使用測試集數據驗證了模型的準確性。使用優化后的模型的各項評價參數都達到了85%以上,結果表明模型具有優異的辨識能力和可信度,是可以用于高新技術企業與傳統企業的類型辨識的。
使用SVM模型用于高新技術企業與傳統企業的類型辨識的研究,與現有的評測標準相比,提供了一種全新的、可靠的但又操作簡單的量化方法;十項參數指標是對企業業績的計量和評價,對企業的管理者、投資者、戰略政策的研究制定者來說,財務績效指標更加直觀、規范、容易獲得;且相較于現行的高新技術企業認定指標,不存在計量上的爭議和主觀操作性,可以進行更客觀的評判。該模型可以運用于高新技術企業對其業績表現進行自我評價,也可作為各級高新技術企業的認定管理機構對申請企業認定審查的參考依據,還可作為高新技術企業的投資人對被投資企業綜合業績表現的評估工具。本論文使用SVM對高新技術企業與傳統企業的類型辨識模型做了初步探索,在參數指標的選擇、模型的優化等方面還可進一步研究。
[1]R.P.Oakey,S.M.Mukhar.United Kingdom high-technology small firms in theory and practice:a review of recent trends.International Small Business Journal.1999,(17):48 -64.
[2]Nicholas O’Regan,Martin A.Sims.Identifying high technology small firms,A sectoral analysis[J].Technovation,2008,(28):408-423.
[3]C.Cortes,V.Vapnik.Support-Vector Network[J].Machine Learning,1995,(20):273 -297.
[4]楊毓,蒙肖蓮.用支持向量機(SVM)構建企業破產預測模型[J].金融研究.2006,(10):67-75.
[5]宋新平,丁永生.基于最優支持向量機模型的經營失敗預警研究[J].管理科學.2008,(2):115-121.
[6]向昌盛,周子英.糧食產量預測的支持向量機模型研究[J].湖南農業大學學報.2010,(2):6-10.
[7]王今朝,王靜.論高技術產業與傳統產業的融合發展[J].商業時代.2008,(7):98-99.
[8]Chih-Chung Chang and Chih-Jen Lin,LIBSVM:a library for support vector machines[EB/OL].http://www.csie.ntu.edu.tw/~cjlin/libsvm,2010.
[9]Faruto and Liyang,LIBSVM-Faruto Ultimate Version.A toolbox with implements for support vector machines based on libsvm[EB/OL].http://www.matlabsky.com,2011.
[10]Hsu C-W.,Chang C C.,Lin C J.A Practical Guide to Support Vector Classification[R].Department of Computer Science and Information Engineering.Taiwan:National Taiwan University,2004.
(責任編輯 劉傳忠)
Type Identification Model of High-tech Companies and Traditional Companies
Zheng Jia1,Pan Jianxin2,Zhang Ruiwen1
(1.School of Management,University of Science and Technology of China,Hefei 230026,China;2.Institute of Nuclear and New Energy Technology,Tsinghua University,Beijing 100084,China)
This paper presents a novel identification model for the identification of high technology companies and traditional ones from financial performance indexes for the first time,based on the support vector machine(SVM)neural network(NN).The model is on the basis of the data of companies’indexes,employs radial basis function(RFB)as the kernel function.The kernel parameters are selected and adjusted by grid search method.The optimized model is verified by the test data.The results are discussed by binary classification decision analysis.It indicates that the accuracy,precision,recall and other main evaluation indexes of the model are achieved 85%above,which means high reliability.The model provides a reliable,simple and convenient approach for the type identification of high technology companies quantitatively.
High technology companies;Type identification model;Support vector machine;Neural network
F270
A
2012-02-27
鄭佳 (1987-),女,湖北宜昌人,管理學碩士;研究方向:高新技術企業的財務管理。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
浙江國土資源(2022年11期)2022-12-13 02:54:48
浙江國土資源(2022年8期)2022-09-06 13:26:44
當代水產(2022年5期)2022-06-05 07:55:06
當代水產(2022年3期)2022-04-26 14:27:04
當代水產(2022年2期)2022-04-26 14:25:10
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
云南畫報(2020年9期)2020-10-27 02:03:26
華人時刊(2020年13期)2020-09-25 08:21:50
數學物理學報(2020年2期)2020-06-02 11:29:24
