風力機葉片的圖像跟蹤與識別算法研究
2012-10-11 02:58:22沈繼忱劉志杰邸建銘趙世榮
黑龍江電力 2012年3期
沈繼忱,劉志杰,邸建銘,趙世榮
(東北電力大學自動化工程學院,吉林吉林132012)
0 引言
隨著風力發電的大規模建設,風力發電表現出了面廣、點多的特點。因此,隨著風力發電系統并網技術不斷深入,必須加強風力機葉片的跟蹤與識別,以使風力機能夠安全可靠運行,保證電網系統穩定并在出現故障時快速恢復穩定的供電能力[1]。
傳統模式識別技術一般包括模板匹配法[2-5]、統計特征法等。在20世紀90年代前期,隨著計算機視覺技術的快速發展,開始出現目標識別的系統化研究。1990年A.S.Johnson等運用圖像處理方法實現了目標的自動識別。1990年R.A.Lotufo等使用視覺識別技術分析所獲取的圖像,實現了目標的跟蹤[6]。這個時期應用在識別正確率方面有所突破,但還沒有考慮到識別實時性的要求,識別的速度有待進一步提高。1994年M.M.M.FAHMY等成功地運用了BAM神經網絡方法對目標進行自動識別。由于神經網絡技術能夠較好對處理和解決問題進行記憶、聯想、推理,避免了繁重的數據分析和數學建模工作,大大提高了運行速度,因此越來越受到人們的廣泛關注,但其沒能力來解釋自己的推理過程和推理依據、不能向用戶提出必要的詢問、理論和學習等缺點,制約著其發展。對此,本文利用Adaboost識別算法對風力機葉片進行了跟蹤與識別的研究。
1 Adaboost跟蹤與識別的原理
AdaBoost算法是在整個訓練集上維護一個分布權值向量wt,用賦予權值的訓練集通過弱分類算法產生簡單分類器hi(x),然后計算出其錯誤率,用得到的錯誤率去更新分布權值向量wt,錯誤分類的樣本賦予更大的權值,正確分類的樣本分配更小的權值。每次更新后用相同的簡單分類器產生新的分類假設,這些分類假設的序列構成多分類器。對這些多分類器用加權的方法進行聯合,最后得到決策結果。AdaBoost算法的任務就是完成將容易找到的識別率不高的簡單分類器提升為識別率很高的強分類器,在分類時,只要找到一個比隨機猜測略好的簡單分類器,就可以將其提升為強分類器,而不必直接去找通常情況下很難獲得的強分類器,也就是給定一個簡單分類算法和訓練集,在訓練集的不同子集上,多次調用簡單分類器,最終按加權方式聯合多次簡單分類器的預測結果得到最終學習結果。
在Adaboost算法中,每一個訓練樣本都被賦予一個權值,表明它被某個簡單分類器選入訓練集的概率。如果某個樣本點己經被準確地分類,那么在構造下一個訓練集的過程中,它被選入的概率就被降低;相反,如果某個樣本點沒有被正確分類,那么它的權值就得到提高。在具體實現上,最初令每個樣本的權值相等,對于第t次迭代操作,根據這些權值來選取樣本點,進而訓練分類器ht。利用這個分類器,提高被它錯分的那些樣本點的權值,降低被正確分類的樣本權值,然后權值更新過的樣本集被用來分類下一個分類器ht+1,整個訓練過程如此進行下去[7],算法的示意圖如圖1所示。
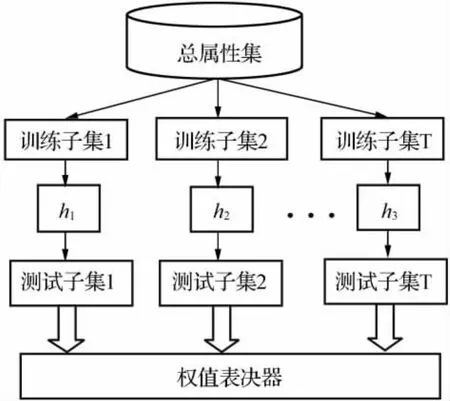
圖1 AdaBoost算法框架
1.1 AdaBoost算法框架[8]
設給出的樣本圖像集為(x1,y1),…,(xn,yn),yi={0,1}(i=1,2,…,n)對應負樣本和正樣本。對于第i個訓練樣本xi,其特征值為fi(xi)。yi=0時時;其中m表示負樣本圖像個數;l表示正樣本圖像的個數。重復以下過程T次,t=1,…,T。
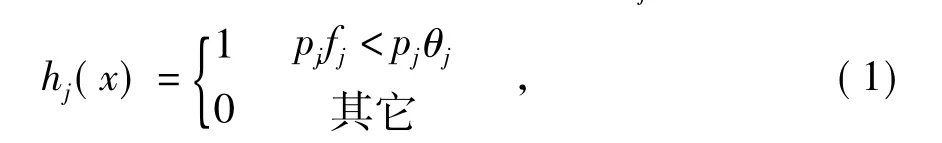
2)選取具有最小的錯誤率的εt,并將其對應的弱分類器作為ht。
4)求得強分類器:
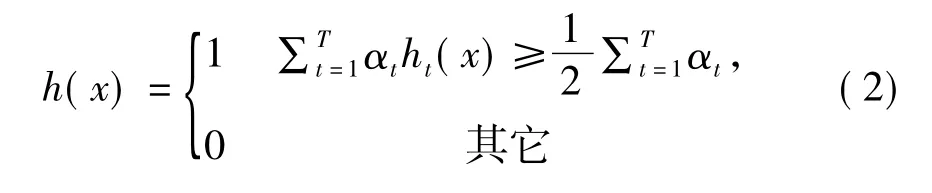
由上所述可以得出,如果每一次篩選出來特征ht+1的錯誤為εt+1≤0.5,否則下一次篩選出來的特征必為 ht,又得出 ε ≤1。因為t+1wt+1,i←wt+1,iβt+1,如果得到的被 ht+1分類的樣本是正確的,那么所有的權值都變會變小。相反,被錯誤分類的樣本權值都會變大,原因在于 w′t+1,i←對于新的 h一定是相對于t+2ht+1能更多地正確分類出弱分類器,因為所有分類器h的錯誤率ε只由錯誤分類的樣本的權值來決定,所以,只有這樣才能達到減小錯誤率的效果。
1.2 Adaboost訓練耗時原因
在樣本的訓練過程中,樣本數量非常多,因此需要的時間和空間比較大。對于每個樣本特征值在每一輪循環中都要進行計算,此外,還要加上每輪循環運算中選擇最佳閾值時必須進行的排序、遍歷等運算時間,使得在訓練過程中消耗大量的時間。
對于每個特征j,訓練出其簡單分類器hj的過程比較耗時,因為該過程中需要確定閾值θj,偏置pj,并使目標函數達到最小,從確定的簡單分類器中,找出一個具有最小的錯誤εt的簡單分類器ht。對于每個簡單分類器都有上萬個訓練樣本,而訓練一個簡單分類器需要對這些樣本進行分析并確定閾值θj和偏置pj。提取完最優簡單分類器后,訓練樣本的概率分布已經改變,那么下一次進行訓練簡單分類器時,所有的簡單分類器必須完全重新訓練,如此反復。
1.3 Adaboost訓練的優化
針對訓練樣本耗時的缺點,本文提出了一種訓練簡單分類器快速訓練算法,可以有效地避免迭代訓練以及統計概率分布耗時的過程[9]。
若訓練樣本分別用(x1,y1),…,(xn,yn)表示,一共有n個。yi=0,1分別表示樣本的負樣本和正樣本。設在訓練樣本中負樣本有m個,正例樣本l個。
計算特征fj的簡單分類器hj時,同時計算出閾值偏置pj和θj。有前面的分析可知,簡單分類器εj與 θj和 pj為函數關系,即 εj(θj,pj)。pj可分為 ± 1兩種情況進行討論。
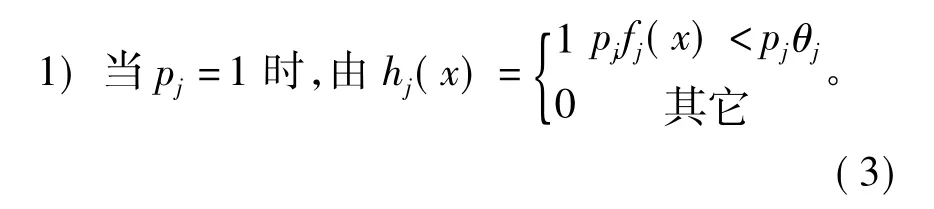
特征fj的值小于閾值θj時為真,則
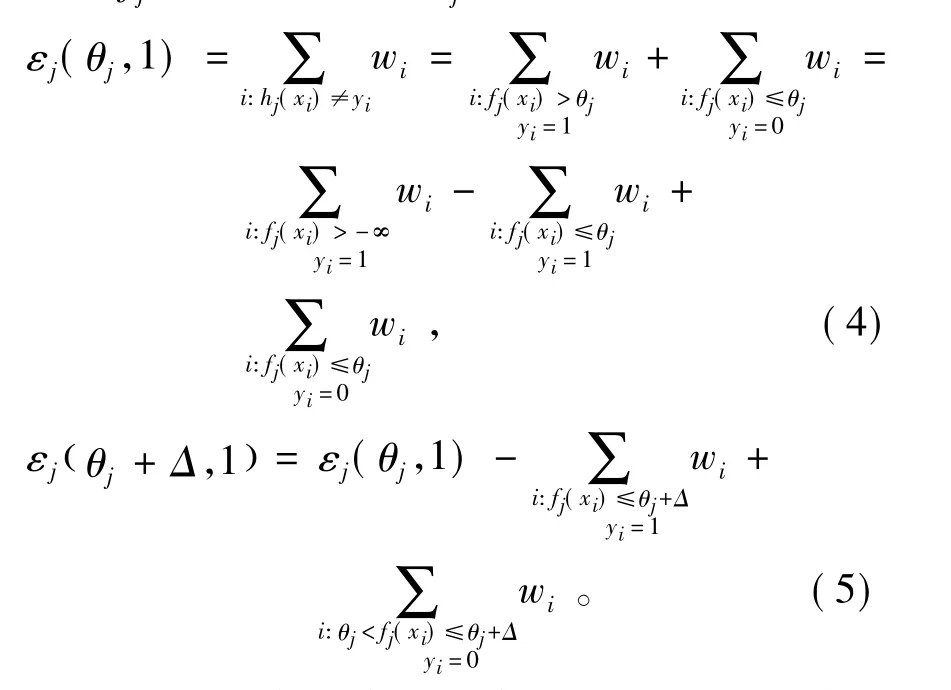
把所有的訓練的特征樣本fi按照從小到大的順序進行排列,得到一個次序表S。最小的樣本特征fi的值的序號用S(1)來表示,用fj(x(s(1)))來表示其相應的特征所得到的值,假設其所得的值就是該值的閾值,有:
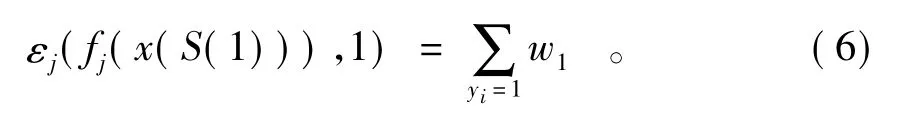
特征fi的值次小的訓練樣本x(S(2)),根據式(5)得出:
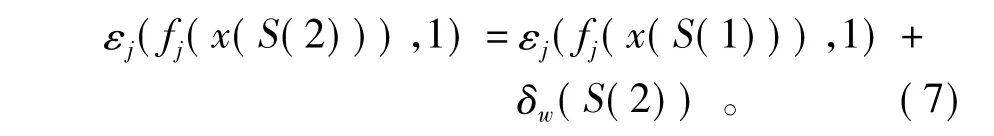
由式(5)知,y(S(2))=1時,δ= -1;y(S(2))=0時,δ=1;可知:
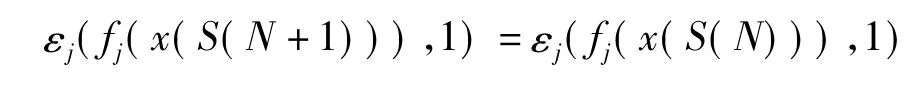

根據式(8),可以得出各個不同閾值下的εj(θ,1),最后篩選出最小的 εjmin(θ,1)。此刻 θ值定義為 θ1,有 θ1= θj|εj=εjmin(θ,1)的值就是對應特征 j分類器的最優閾值。
2) 當 pj= -1 時,可求得 εj(θ,1),εj(θ,1)的值和pj=1時互補,有 εj(θ,-1)=1-εj(θ,1),也就是 εjmin(θ,-1)=1 - εjmax(θ,1)。
由此可知,只要利用式(8)累加一次,再比較εjmin(θ,1)與1 - εjmax(θ,1),就能確定簡單分類器的最優閾值、偏置和εj。

2 實驗結果及分析
2.1 Adaboost算法訓練過程
本實驗在OpenCV平臺上,對Adaboost原程序和改進后的算法進行了分類器的訓練[10-11],在實驗中共用到1 000幅40×40的葉片樣本和不包含建筑物、大樹、藍天等圖片中截取而來的1 000幅40×40非葉片樣本,原算法和改進后的算法的訓練樣本數目、訓練時間如表1所示。
在檢測速度上,取大小為596×486圖像50幅作統計,原算法的平均檢測時間為1.426 s,改進后的平均檢測時間為0.685 s。
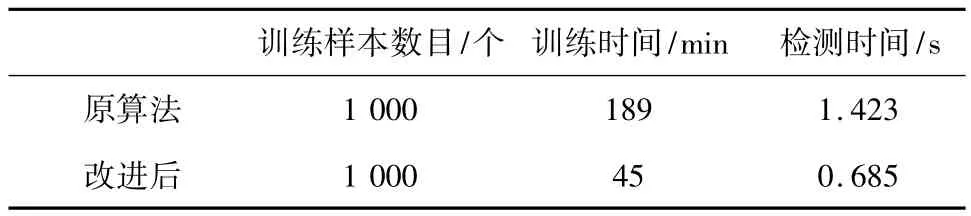
表1 Adaboost算法訓練結果
2.2 檢測實例及結果
本實例對單個葉片和多個葉片進行了檢測,圖2是對單個葉片的檢測結果,圖3為多葉片檢測結果,圖4是在有干擾的情況下進行的檢測。

圖2 單個葉片的檢測結果

從測試的結果來看,對于單個葉片的檢測(圖2)準確性相當好,對葉片的中心定位也相當準確。但存在的最大缺點就是算法復雜度太高,檢測處理時間太長。在多個葉片存在的情況下也能準確的檢測出來(見圖3)。但是在圖像模糊或有樹木及其它情況下未能檢測出來(見圖4)。
由于本文在訓練分類器時采集的樣本不夠多,可能造成檢測的失敗和漏檢,要增加精確程度,還需要進一步增加樣本的數目。
3 結束語
通過對Adaboost弱分類器中目標函數的直接求解,避免了統計和迭代訓練長耗時過程,提高了訓練和分類的速度,同時,利用少量的弱分類器構成的強分類器,較好地簡化了系統結構,減少了訓練時間,提高了檢測速度,實現了對風力機葉片的實時跟蹤與識別。另外,通過圖像分析檢測葉片運行狀態,可以及時做出準確的操作,避免風機葉片損害。
[1]吳越明.發電機組對電網穩定的適應能力分析[J].華東電力,2004,32(10):646 -648.
[2]王哲峰.基于提升小波變換的圖像匹配算法研究[D].吉林:吉林大學,2006:19-26.
[3]劉雅軒,蘇秀琴,王萍.一種基于局部投影熵的圖像匹配新算法[J].光子學報,2004,33(1):105-107.
[4]薛嬌.基于改進遺傳算法的圖像匹配方法研究[D].太原:太原理工大學,2011:25-29.
[5]鄭軍,諸靜.基于自適應遺傳算法的圖像匹配[J].浙江大學學報(工學版),2003,37(6):689 -692.
[6]王晗.基于Adaboost算法的車牌識別研究[D].太原:太原理工大學,2011:25 -29.
[7]嚴超,蘇光大.人臉特征的定位與提取[J].中國圖像圖形學,1998,3(5):375 -380.
[8]李蘇.基于Adaboost算法的人臉檢測技術研究[D].哈爾濱:哈爾濱理工大學,2010:21-23.
[9]魏冬生,李林青.Adaboost人臉檢測方法的改進[J].計算機應用,2006,26(3):619 -621.
[10]蒙豐博.快速人臉檢測與跟蹤[D].天津:天津大學,2010:32-36.
[11]秦小文,溫志芳,喬維維.基于OpenCV的圖像處理[J].電子測試,2011,7:39 -41.
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
