公司運營危機預警模型的比較研究
——以中國上市公司為例
2012-10-25 05:38:56李同正孫林巖馮泰文
河南社會科學 2012年6期
李同正,孫林巖,馮泰文
(西安交通大學 管理學院,陜西 西安 710004)
公司運營危機預警模型的比較研究
——以中國上市公司為例
李同正1,孫林巖2,馮泰文3
(西安交通大學 管理學院,陜西 西安 710004)
研究當前國內外公司運營危機預警問題的現狀,首先要尋找一套適合于我國上市公司的財務狀況識別指標體系,然后依據該指標體系采用不同方法建立運營危機預警模型,最后利用樣本公司實際指標數據對各個模型的短期及中期預警效果進行比較分析與實證研究。結果表明,分類樹模型的三年期預警準確率都在80%以上。
運營危機預警;判別分析;logistic回歸;BP神經網絡;分類樹
公司經營狀況的好壞往往是企業經營者、投資者、債權人和審計師關注的焦點。致使公司陷入經營困境的原因是多方面的,既可能是企業經營者決策失誤,也可能是管理失控,還可能是外部環境變化等。由于影響企業出現運營危機的因素很多,大多企業管理當局局限于各種主客觀因素,對出現危機的潛在信息不能及時發覺。對于預警模型的構建,目前采用較多的方法是判別分析、logistic回歸和神經網絡。本文將在比較運營危機預警模型構建方法的基礎上,對各個模型的短期及中期預警效果進行比較分析與實證研究。
一、分類樹與回歸樹介紹
分類樹是一種基于統計理論的非參數識別技術,其特點在于既保持了多元參數、非參數統計的一些優點,又克服了其不足。其表現為:自動進行變量的選取,降低維數;充分利用先驗信息處理數據間非同質的關系;分類結果表達形式簡單易于解釋,并可有效地用于對數據的分類[1,2]。分類樹分析的一般性思路:在整體樣本數據的基礎上,生成一個層次多、葉結點多的大樹,以充分反映數據之間的聯系,然后對其進行刪減,產生一系列子樹,參照一定規則從中選擇適當大小的樹,用于對新數據進行分類[3,4]。
(一)分類樹的建立
分類樹的目標是產生一系列規則,對那些只知道屬性變量值的樣本進行正確分類。分類樹的算法:按照特定規則逐個檢驗每個屬性變量,看它們對不同類別樣本的判別情況,之后選擇對正確分類提供信息量最大的變量將樣本集合分為2個子集。這個過程遞歸地應用于每個子集,直到達到止停點(如每個樣本都被正確分類)。在對樣本進行分類時,分類規則采用二叉樹形式,對于連續變量Xi:表示為{Xi|Xj>C嗎?C為樣本空間中變量Xii的取值范圍內的一個常數,i= 1,…,m,m為連續變量個數};而對于離散變量Xij:表示為{Xij|Xij∈V?V為樣本空間中變量Xii所有可能取值集合U的某個子集,,j=1,…,n,n為離散變量個數}。據此樣本對分類規則“是”或“否”的回答將這個節點分為左右2個子節點。
圖1中X為樣本集合,大寫字母A、B、C表示不同的樣本類別,( )為非葉節點,[ ]為葉節點,Si表示分類規則,最終結果:XA=X7∪X9∪X5,XB=X4∪X11,XC=X10∪X12。樹上表現出的變量通常只是變量指標集中的一部分。分類樹的一個優點是它能提供易于理解的分類規則。每個葉子相當于一個分類規則。

圖1 分類樹模型的一般表示形式
(二)分類樹的刪減和選擇
現實生活中的數據會含有一些噪聲,故訓練樣本所確定的分類樹結構不能完全正確判別所有類別的樣本。另外,當分類樹的層數和葉節點較多時,其可讀性比較差,不易理解。因此需要對原始樹進行刪減,去掉那些僅反映數據間特殊關系的樹枝。分類樹刪減算法包括漸進刪減算法、最優刪減算法(OPT)及其變形。
其中OPT算法是基于動態規劃的一種遞歸刪減算法,其主要用于實現概念簡化的功能,同時減少噪聲影響;它能夠產生一系列比較密集的刪減子樹從而擴大選擇的范圍。OPT算法或類似變形的目的是產生Tmax的最優刪減樹序列S0。此算法首先生成幾乎為葉節點的很小的子樹序列,之后這些小的子樹被一步步結合起來,產生越來越大的子樹,由之繼續構成T0的子樹序列。直到最終形成大樹Tmax。因為每一個T的子樹又都是由它自己的最優刪減序列構成,因此這類算法在尋求全局最優。其缺點在于它的時間復雜度仍然比較高。
二、樣本公司和指標變量的選擇
(一)樣本公司的選擇
本文的研究對象是中國上市公司,為研究方便將滬深兩地證券市場的ST公司界定為處于運營危機中的公司。
本文選擇樣本時,從2005年被宣布特別處理的公司中選取了32家ST公司及與之相對應(與ST公司同行業、資產總額大體相等)的32家非ST公司共64家公司作為研究樣本。樣本被分為訓練樣本和檢驗樣本兩組,訓練樣本包含16家ST公司和對應的16家非ST公司,檢驗樣本包含16家ST公司和對應的16家非ST公司。研究所選取的財務數據是這些公司被宣布特別處理前三年的財務數據,32家非ST公司的數據按照對應的ST公司財務數據選取的年度選取,因為ST公司是在2005年被宣布特別處理的,其選取數據的年份為2004年、2003年和2002年,其對應的非ST公司選取數據的年份也為2004年、2003年和2002年。數據來源于深圳市國泰安(GTA)信息技術有限公司中國上市公司財務數據庫。
(二)指標變量的選取
根據企業破產理論和數據可得性原則,同時借鑒前人相關的研究成果,本文分別從短期償債能力、營運能力、長期償債能力、盈利能力、風險水平、股東獲利能力、現金流量分析和發展能力等八個方面選擇了42個財務指標(見表1)。這些指標的選取原則以能全面、準確地反映公司財務狀況為基礎,充分借鑒了國內外這一領域的前期研究成果,如A ltman的Z-Score模型采用的預測變量,Robert、Mark、張玲[5]和姚靠華[6]等在其研究中采用的指標。
三、分類樹模型的建立與比較
分類樹分析在計算過程中自動選取變量,避免了主觀因素的影響。在公司運營危機預警過程中存在兩類錯分成本:第一類錯誤是將有運營困難的公司預測為正常,第二類是將正常公司預測為處于運營困境中的公司。分類樹分析可以將兩類成本設置成不同的數值,以滿足不同利益相關者的需要。分類樹分析的這些優點保證了其在構建運營危機預警模型時的有效性。
在本文的研究中,令ST公司為1,非ST公司為0,得到目標變量(Target Variable);將選定的42個變量作為預測變量(Predicator Variable)全部納入模型,分類方法采用Gini法,兩類錯分成本的數值相等。
(一)短期預警
所謂短期預警是指根據2003年或2004年的公司財務數據對公司2005年的經營狀況進行預警,預警期限為1年或2年。

表1 預警指標集

表2 2004年判別分析模型結果

表3 2004年logistic回歸模型結果

表4 2004年BP神經網絡模型結果
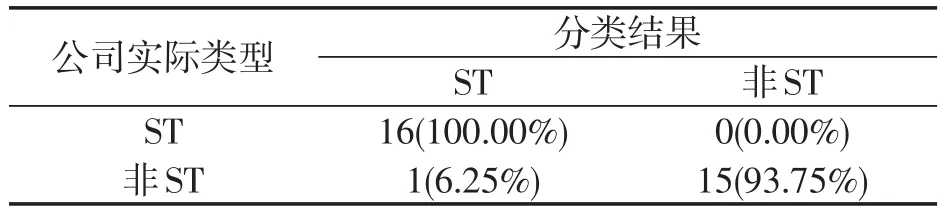
表5 2004年分類樹模型結果
四種模型的1年期預警準確率分別為87.50%、65.63%、84.37%和96.88%,判別分析模型、BP神經網絡模型和分類樹模型的預警準確率都達到了80%以上。
四種模型的2年期預警準確率分別為62.50%、65.63%、68.75%和90.63%,分類樹模型的預警準確率遠高于其他三個模型。
(二)中期預警
所謂中期預警是指根據2002年的公司財務數據對公司2005年的經營狀況進行預警,預警期限為3年。

表6 2002年判別分析模型結果

表7 2002年logistic回歸模型結果

表8 2002年BP神經網絡模型結果

表9 2002年分類樹模型結果
四種模型的中期預警準確率分別為62.50%、62.50%、 68.75%和84.38%,分類樹模型的預警準確率仍在80%以上,表現出較好的中期預警效果。
四、結論
通過以上42個指標體系建立分類樹模型來進行中國上市公司運營危機預警分析是可行的。分類樹模型與其他模型相比預警的準確率都比較高,說明分類樹模型更有效;預警準確率都隨時間長度的增加而降低;在建立分類樹模型時,對分類結果起決定作用的指標主要有利息保障倍數、營業收入凈利潤率、總資產凈利潤率、財務杠桿系數、經營杠桿系數和每股收益。
對于公司預警模型的研究還可以在以下幾方面進行深入探討:
(1)建立有效的指標體系。國內企業預警研究用到的指標來自定性研究,一般都沒有經過主成分分析或時差檢驗,很難符合最小完備集的要求。
(2)加入非財務變量。Lee等證明,臺灣上市公司治理結構與經營困境相關。姜秀華等認為,弱化的公司治理是中國上市公司陷入危機的重要因素。可見,公司治理與經營困境關系的研究備受關注,但有關治理變量的選擇及其他因素的影響尚值得研究。
(3)分析企業陷入經營困境的影響因素,為中國公司避免經營困境提供建議。
(4)定性研究與定量研究相結合。目前,大部分研究集中于指標處理方法和預警模型等定量研究,少數關于預警原理的研究缺乏深度。尚玉釩和席酉民研究了企業文化管理與企業預警的關系,為研究財務預警提供了新思路。
(5)開展對預警系統的評價研究。大部分研究忽視對預警模型或預警系統結論的檢驗,尚缺乏關于預警系統評價的研究。
[1]Altmen E.,Fraydman H.,Kao E.D.Introducing recursive partitioning for financial classification: the case of financial distress[J].Journal of Banking and Finance,1985,(2):269—291.
[2]Breiman L.Technical note:some properties of splitting criteria[J].Machine Learning,1996,(1):41—47.
[3]Bohance M.,Bratko I.Trading accuracy for simplicity in decision tree[J].Machine Learning,1994,(3):233—250.
[4]Mark E. Z. Methodological Issues Related to the Estimation ofFinancialDistressPrediction Models[J]. Journal of Accounting Research,1984,(22):59—82.
[5]張玲.財務危機預警分析判別模型及其應用[J].預測,2000,(6):38—40.
[6]姚靠華,蔣艷輝.基于決策樹的財務預警[J].系統工程,2005,(10):102—106.
F83
A
1007-905X(2012)06-0052-03
2012-03-07
1.李同正,男,河南人,西安交通大學管理學院博士研究生;2.孫林巖(1955— ),男,河北景縣人,管理學博士,西安交通大學管理學院副院長,教授,博士生導師,研究方向為制造戰略、工業工程。
責任編輯 姚佐軍
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
體育科技文獻通報(2022年3期)2022-05-23 13:46:54
遼金歷史與考古(2021年0期)2021-07-29 01:06:54
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
科技傳播(2019年22期)2020-01-14 03:06:54
民用飛機設計與研究(2019年4期)2019-05-21 07:21:24
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
