數據挖掘在外感疾病藥對中的應用研究*
2012-12-01 02:14:14馮天保譚定英陳平平
中國中醫基礎醫學雜志 2012年6期
馮天保,劉 梅,譚定英,陳平平
(廣州中醫藥大學,廣州 510405)
藥對,又稱“對藥”,是臨床上常用的、相對固定的2味藥物的配伍形式。藥對是集中醫之理、法、藥為一體的數據集合,體現交叉錯綜的關聯與對應。數據挖掘正是通過對數據特征、關系、聚類、趨向、偏差和特例現象的深層多維分析,來揭示數據間復雜和特殊的關系,發現其隱含的規則、模式和規律。本研究以《張仲景藥對集》[1]、《中藥藥對大全》[2]中外感疾病相關的藥對為數據源,利用SQL Server 2005建立數據挖掘模型,應用數據挖掘中的關聯規則算法,對藥對作“藥物-藥對-病證”對應關系進行分析。
1 數據挖掘與關聯規則
數據挖掘(Data Mining)是用于開發信息資源的1種新的數據處理技術,主要用于海量數據的分析與研究。數據挖掘技術已被廣泛地應用于經濟管理以及社會生產的各個領域,并逐漸滲入到中醫藥研究領域中,取得了一定的階段性成果。關聯規則指描述數據之間存在關系的規則,是從給定的數據中,挖掘出事物特征之間滿足一定支持度和置信度的關聯現象[3]。關聯規則相關術語如下:(1)項集:項集是1組值,每個項都是1個屬性值。每個項集都有一個大小,該大小表示項集中包含的項的數目。如項集{葶藶子、麻黃/杏仁、咳嗽}的大小是3;(2)支持度:支持度用于度量1個項集的出現頻率。最小支持度是1個閾值參數,必須在處理關聯模型之前指定該參數;(3)概率:也稱置信度,是關聯規則的屬性。最小概率是1個閾值參數,必須在運行算法之前指定該參數,它表示用戶只對某些規則感興趣,這些規則擁有比較高的概率;(4)重要性:重要性用于衡量項集和規則[4],重要性用下面的公式來定義:Importance({A,B})=probability(A,B)/(probability(A)×probability(B))。計算結果,如果importance=1,則表示 A和 B是2個獨立的事件。如果importance<1,則 A和 B是負相關,它表示 A發生,B也不太可能發生。如果 importance>1,則A和B是正相關,表示A、B很有可能發生。
2 數據挖掘在外感疾病藥對中的應用研究
2.1 數據準備
數據來源于《張仲景藥對集》及《中藥藥對大全》,主要采用其中解表類、溫里類、清熱類、瀉下類、祛濕類和止咳類藥對。將篩選后的數據進行標化、量化、錄入,并創建中藥藥對數據庫,使之易于管理、分析與查詢。
2.2 數據預處理
2.2.1 藥名的預處理 《張仲景藥對集》、《中藥藥對大全》中的數據幾乎都是文字性的描述,需要作歸類和數據屬性數據化。書中藥名幾乎每1種藥物都存在一物多名的情況,處理這一類藥名的時候,根據《中藥配伍應用》與《常用中藥配伍與名方精要》兩書進行規范化處理,統一藥名。
2.2.2 用量的預處理 在《張仲景藥對集》和《中藥藥對大全》中藥物所用劑量基本上都是以“克”為單位做計算的,所以不存在單位轉換的問題。在用量中如果是1個連續值的話,分2種方法轉化;若劑量小于30g則取最大值;反之,取平均值。如白術用量為6g~15g,最大劑量小于30g,那么取最大劑量15g;綠豆用量為30g~70g,那么就用平均值(30+70)/2=50g。
2.3 數據轉換
單味藥物本身具有的屬性包括功用、四性、五味、升降浮沉、歸經和藥物毒性等,為本數據取藥物的基本屬性,包括四性五味、歸經和功用。
2.3.1 四性的數字化 表1顯示,藥物的四性包括寒、熱、溫、涼、平,如果藥物具有相應的屬性,就在相應的屬性上編碼為“1”,反之為“0”。如某藥具有熱性,則編碼。

表1 藥物四性表
2.3.2 五味的數字化 表2顯示,藥物的五味包括酸、苦、甘、辛、咸、淡、澀,如果藥物具有相應的屬性,就在相應的屬性上編碼為“1”,反之為“0”。如某藥具有辛味,則編碼。

表2 藥物五味表
2.3.3 歸經的數字化 表3顯示,藥物的歸經包括肝、心、脾、肺、腎、胃、膽、大腸、小腸、膀胱、心包、三焦經等幾類,如果藥物具有相應的屬性,就在相應的屬性上編碼“1”,反之為“0”。

表3 藥物歸經表
2.3.4 藥物功效屬類數字化 表4顯示,將藥物功效屬類分為解表藥、清熱藥、瀉下藥、祛濕藥、溫里藥、理氣藥、消食藥、止血藥、活血化瘀藥、化痰止咳平喘藥、安神藥、平肝息風藥、補虛藥、收澀藥、殺蟲藥等共17大類,如果藥物具有相應的屬性,就在相應的屬性上編碼“1”,反之為“0”。
2.4 數據庫的建立
2.4.1 屬性表的建立 在數據庫中建立了3個藥物屬性表,包括藥物性味表、藥物歸經表、藥物功用表。性味包括寒、熱、溫、涼、平、酸、苦、甘、辛、咸、淡、澀,歸經包括肝、心、脾、肺、腎、胃、膽、大腸、小腸、膀胱、心包、三焦,功用表包括解表、清熱等17種。這些屬性表既是藥物的基本屬性,也作為藥物數據挖掘的依據。

表4 藥物功效屬類表
2.4.2 事實表的建立 事實表中的事實是指描述1種物體的詳細情況并能體現物體特征。事實表的建立可以發現物體之間的異同,也有利于信息的查詢,主要有藥對表(藥對ID、藥對組成、功效、主治等)、藥物表(藥物 ID、藥物名、藥物功能、用量(g)等)、藥對-藥物表(藥對 ID、藥物 ID、藥對功用ID、病證 ID等)。
2.5 數據建模及數據展現
經過數據轉換、數據錄入、數據清洗,數據庫正式完成并可以導入Microsoft SQL Server2005進行挖掘模型的創建。采用關聯分析方法,試圖預測藥對-藥物-病證三者之間的關系,發現頻繁項集。(1)創建Analysis Services項目;(2)創建數據源和數據源視圖;(3)選取關聯規則算法,建立數據挖掘模型;(4)利用關聯規則進行藥對數據的挖掘。下面選取2個選項卡數據作為藥對挖掘結果展示,其中項集是指該選項卡能顯示被模型識別為經常發現一起出現項集的列表,網格中有“支持”、“大小”和“項集”項目,而規則是指該選項卡顯示關聯算法發現的規則。
選擇藥對-藥物表為事例表,藥物表和藥對表作為嵌套表(見圖2)。
①項集選項卡的數據,在此選擇了其中之一作為數據展示(見圖3);②規則選項卡數據,在此選擇了部分數據展示(見圖4)。
3 結果與分析
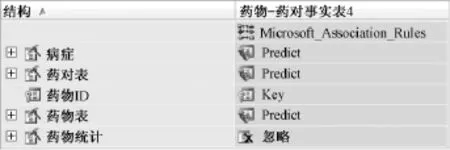
圖2 挖掘模型

圖3 項集選項卡
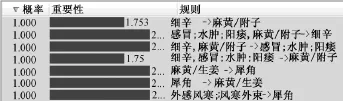
圖4 規則選項卡
本文主要研究治療傷寒疾病的藥物-藥對-病證之間的關系,利用 SQL Server 2005作為數據庫,通過關聯規則算法對傷寒疾病藥對進行挖掘。筆者只選取了部分數據進行歸納分析如下。
3.1 藥物藥對關聯規則挖掘結果及分析
表5顯示,數據信息包括藥物和藥對關聯規則、置信度和重要性,反映出藥物與藥對之間是可以互相預測的,具有雙向關聯。如“陳皮→麻黃/附子”與“麻黃/附子→陳皮”等,這些規則提示前者比后者更有用,可以理解為臨床上若以陳皮治療寒咳痰多,加入溫陽平喘的藥對麻黃/附子效果會更加好;若以麻黃/附子溫陽平喘,加入陳皮增效的作用可能沒那么顯著,而要考慮與其他藥物配伍。從表中還可以看出,有些藥物與藥對和藥對與藥物之間的關系具有相同的置信度和重要性,表明這些規則的可用性是一樣的。如“竹葉→茵陳/梔子/大黃”與“茵陳/梔子/大黃→竹葉”等。
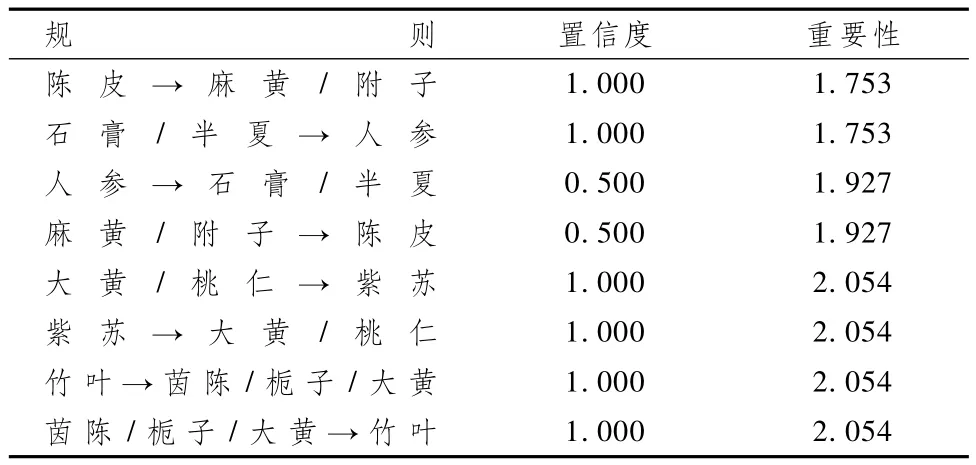
表5 項集大小為2的藥物-藥對關聯規則表
3.2 藥物-藥對-病證關聯規則挖掘結果及分析
在表6的各組合中,大部分是藥物與藥對之間是互相獨立的,可以看成這些藥物的重新組合對相關病證的治療起到更好的協同或相反相成的作用,即組成一個新的藥串。藥串[5]是指相對固定的3味或3味以上的藥物組合,作為中藥配伍的獨立單元,是針對一定病證,從歷代醫家用藥經驗中提煉出來行之有效的、符合一定的理論依據和法度的固定配伍。如表中的“葶藶子,麻黃/杏仁 → 咳嗽;細辛,麻黃/附子→感冒,水腫”等多數組合均屬這種情況。麻黃、杏仁均有宣肺平喘之功,加入瀉肺平喘、行水消腫之葶藶子作為組合,則對咳嗽痰多者療效更佳。但對于“烏頭,旋覆花/代赭石→嘔逆,嘔吐,咳嗽”這類組合,加入有回陽逐冷、祛風濕功效的烏頭,從醫理藥理上很難解析其對嘔逆、嘔吐、咳嗽等癥的治療效果,故此時還要結合臨床、古文獻及現代中藥藥理研究來綜合分析與行取舍挖掘的規律。
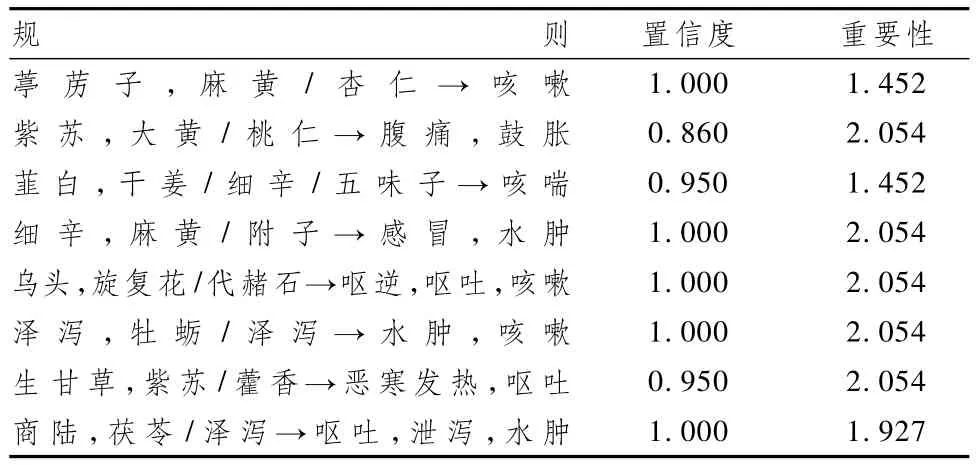
表6 項集大小為3的藥物-藥對-病證關聯規則表
4 結語
本實驗利用數據挖掘技術對中藥藥對進行研究,在一定程度上揭示了中藥藥對的應用特點,發現了一些新的用藥規律及藥物組合規律,如單味藥與藥對的對應關系,以及出現了一些新的藥物配伍組合——“藥串”,此將有助于指導臨床科學用藥,提高藥對治療的效果。筆者在挖掘過程中也發現,對挖掘出來的所有結果不一定都可用,此需結合臨床、古文獻及現代中藥藥理研究結果來綜合分析,遵循“人機結合、以人為主”的原則進行取舍。目前所研究的“藥物-藥對-病證”關聯分析方法較為簡單,而中藥藥對、證、癥、病等信息形成的多維關聯關系的深入揭示,還需在今后工作中進一步研究。
[1]王玉芝,呂昌寶.張仲景藥對集[M].長治:山西省晉東南醫學專科學校,1984.
[2]胥慶華,中藥藥對大全[M].北京:中國中醫藥出版社,2001.
[3]李虹,蔡之華.關聯規則在醫療數據分析中的應用[J].微機發展,2003,13(6):94.
[4]Jiawei Han,Micheline Kamber著,范明,孟小峰,譯.數據挖掘概念與技術[M].2版.北京:機械工業出版社,2007.
[5]趙進喜,肖永華,傅強.呂仁和用藥經驗舉隅[J].中醫雜志,2009,50(4):300-301.
猜你喜歡
小獼猴智力畫刊(2022年3期)2022-03-29 01:09:42
當代陜西(2021年17期)2021-11-06 03:21:36
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:26:14
大眾投資指南(2021年35期)2021-02-16 01:06:26
學苑創造·A版(2018年11期)2018-02-01 06:29:20
Coco薇(2017年11期)2018-01-03 20:59:57
電力與能源(2017年6期)2017-05-14 06:19:37
讀者(2017年5期)2017-02-15 18:04:18
暨南學報(哲學社會科學版)(2016年9期)2017-01-15 13:52:02
信息通信技術(2015年6期)2015-12-26 01:16:46
