數據預處理:數字圖書館的“清洗機”
2013-09-12 04:12:36聶飛霞
圖書館界 2013年4期
聶飛霞,付 敏
(西北大學圖書館,陜西 西安 710127)
隨著網絡化的發展以及數字圖書館的崛起,圖書館也開始走入了數字化時代。圖書館現有的自動化管理系統中存儲著大量的書目數據、讀者流通借還數據、書目檢索記錄、Web訪問記錄等。但目前圖書館所應用的信息化管理系統只有簡單的統計分析功能,無法預測讀者的需求以及圖書的借閱趨勢。數據挖掘技術的應用,使圖書館自動化信息系統中的數據得到了整理與預測,使龐雜的數據成為有用的知識。而數據預處理技術是根據數據挖掘的需求,將現有的已知數據進行清洗轉換匯總等操作。由于數據源的龐大與雜亂,預處理前得數據常常被人稱為“臟數據”,這就使得數據預處理工作成為數據挖掘前期重要的步驟。只有對預處理過的數據進行數據挖掘,數據挖掘工作才會科學有效。
1 數據提取
數據預處理的前期工作是對所需要的數據進行提取。圖書館信息系統中存在著大量的讀者信息、圖書信息、讀者借還數據、圖書借還數據、讀者檢索數據等,因此數據提取工作也是相對較為繁瑣的。下面給出所提取數據的重要字段結構表(本文所提取的數據是西北大學圖書館ILAS系統中的部分數據)。
讀者信息表主要包括讀者姓名、讀者證號(區別讀者的唯一標志)、性別、院系、部門等。讀者信息表結構如表1所示。
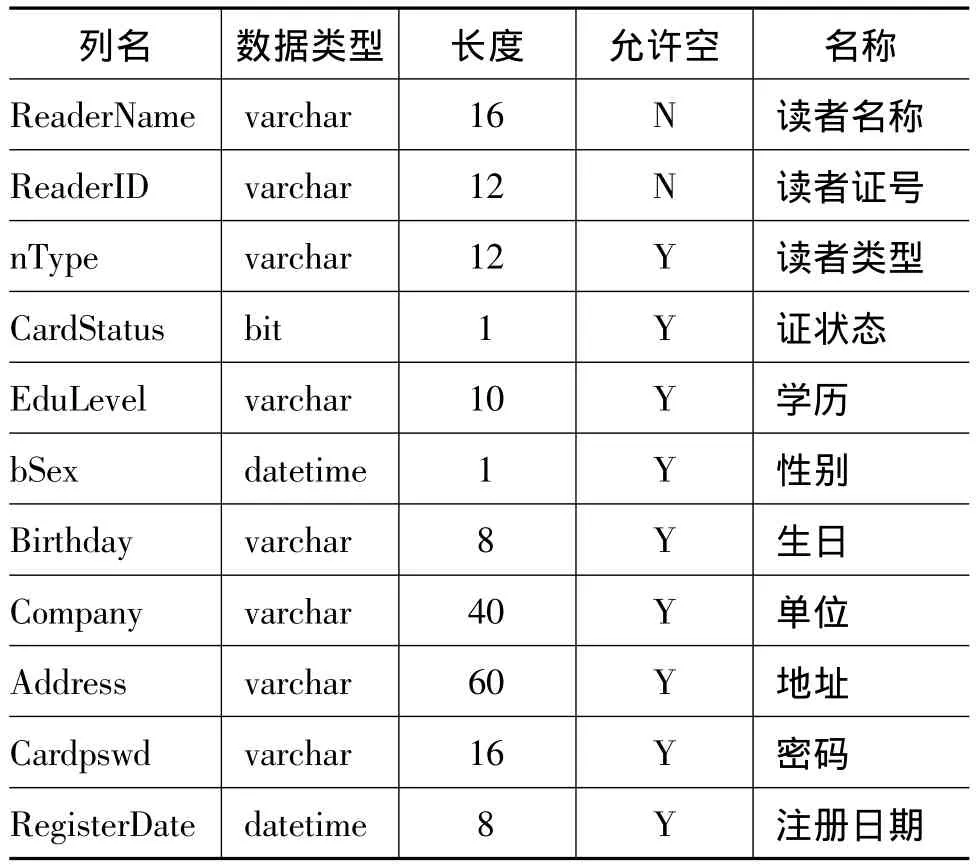
表1 讀者信息表結構
圖書信息表記錄了館藏圖書的題名、分類號、索取號、ISBN號、條碼(區別圖書的唯一標志)等。圖書信息表結構如表2所示。
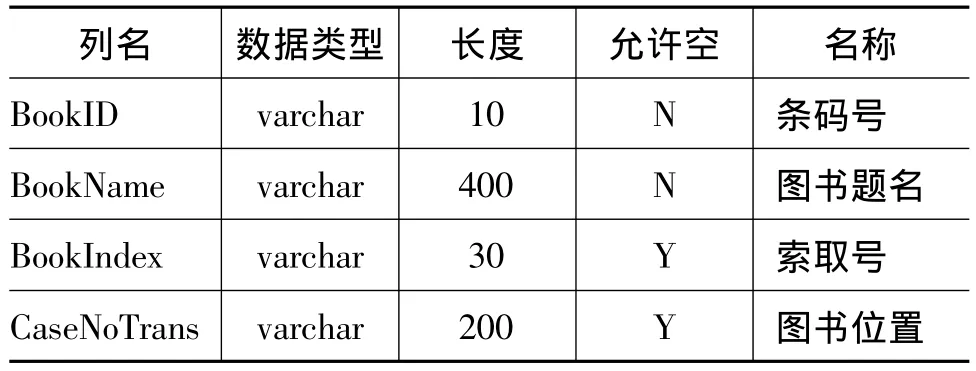
表2 圖書信息表結構
借還信息表主要記錄了借閱和歸還兩個過程的讀者以及圖書信息,包括讀者姓名、讀者證號、圖書題名、圖書條碼、還書時間等。借還信息表結構如表3所示。
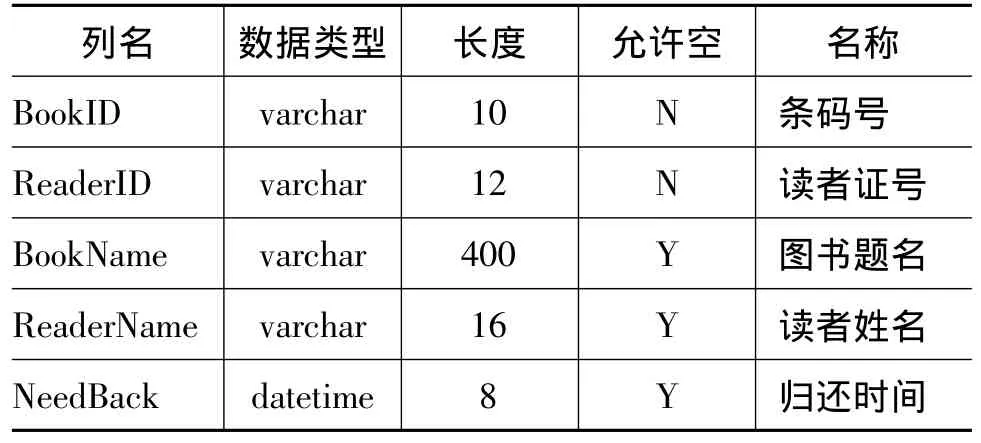
表3 借還信息表結構
2 數據預處理
數據源的獲取、數據獲取和信息集成等相關研究為數據預處理提供了基礎。根據數據挖掘的需求,將相關的多源數據集成融合后,需要進行多種數據預處理操作。數據預處理的主要流程包括數據清理、數據集成和融合、數據變換、數據規約以及在數據挖掘結果的評價計劃基礎上進行的二次預處理的精煉。數據預處理的基本流程如圖1所示。
2.1 數據清理
數據清理工作是數據挖掘準備工作中最耗時耗力的工作,但也是最重要的工作。最初獲得的原始數據往往是夾雜著很多錯誤的、有噪聲的、空白的、缺失的或者冗余的數據。數據清理工作就是將這一部分數據加以處理。
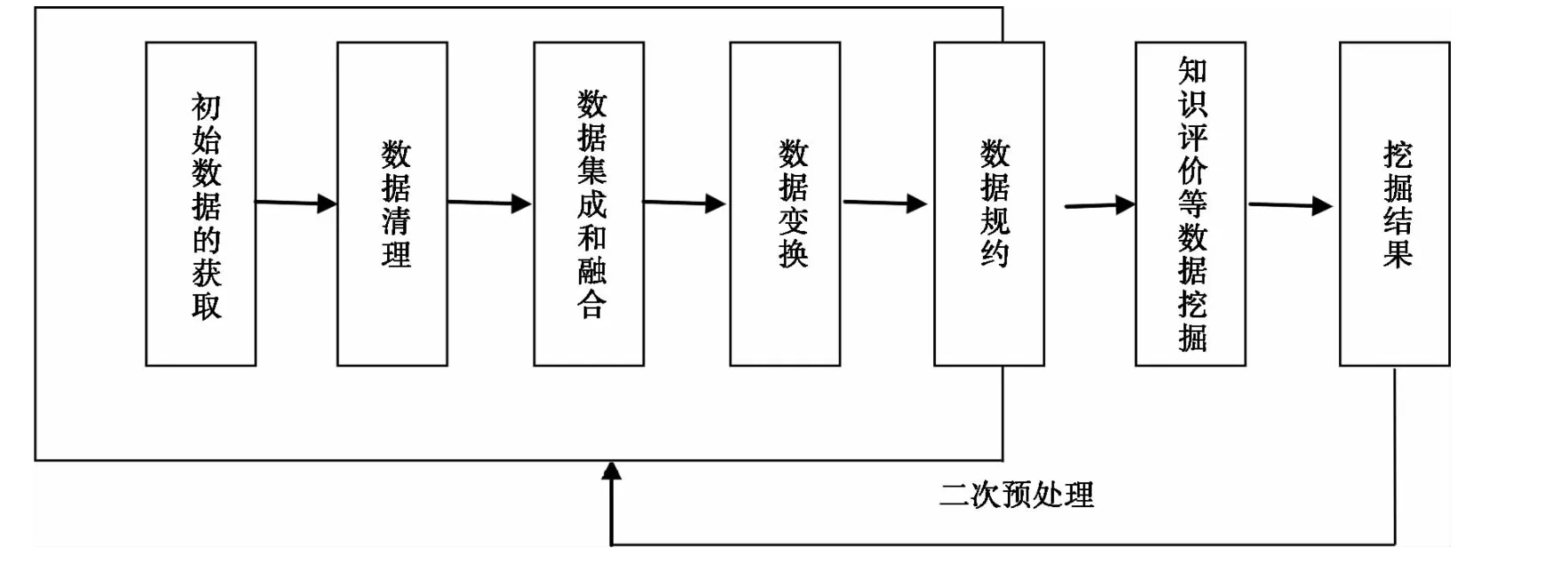
圖1 數據預處理基本流程圖
在圖書館信息系統中獲得的數據源,主要需要做的工作是刪除錯誤值、補充空缺的信息以及修改部分不吻合的值。本次從圖書館信息系統中共獲得借閱數據6798條,圖書數據6704條,讀者數據621條。其中借閱數據中有借閱失敗的冗余數據以及與數據挖掘工作無關的屬性值,而讀者數據中有讀者名稱空缺專業名稱錯誤等信息都需要進行處理。表4是某一時間段西北大學圖書館圖書借閱原始信息表dbo.BorrowHistory中的數據。

表4 讀者原始借還信息表
如表4所示,該原始數據記錄了某一時間段讀者的借閱信息,其中szMemo屬性列記錄了借閱失敗的信息,我們可以通過編寫SQL語句對bResult屬性值為False的行進行刪除。同時,可以刪除我們數據挖掘工作不需要的屬性列,如對bBooking列與szRead列進行刪除。得到讀者借還信息表如表5所示。
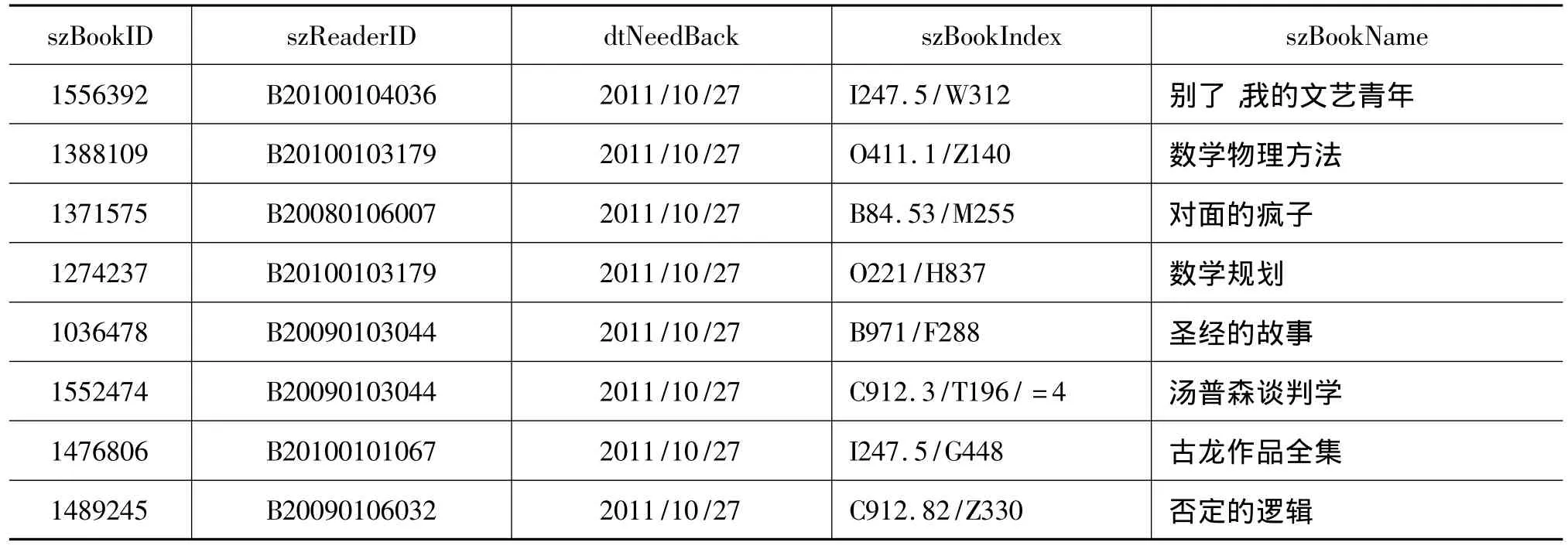
表5 讀者借還信息表
2.2 數據融合與變換
本文所用到的讀者信息與讀者借還信息是分別處于兩個數據表中的單獨數據,我們需要利用SQL語言將這兩個表進行融合與變換。文中表5為數據清理后的讀者借還信息表,表6為數據清理后的讀者信息表,將讀者信息表中的讀者姓名即Reader-Name屬性列與讀者單位Company屬性列增加到讀者借還信息表中,得到加了 ReaderName屬性與Company屬性的讀者借還信息表,如表7所示。
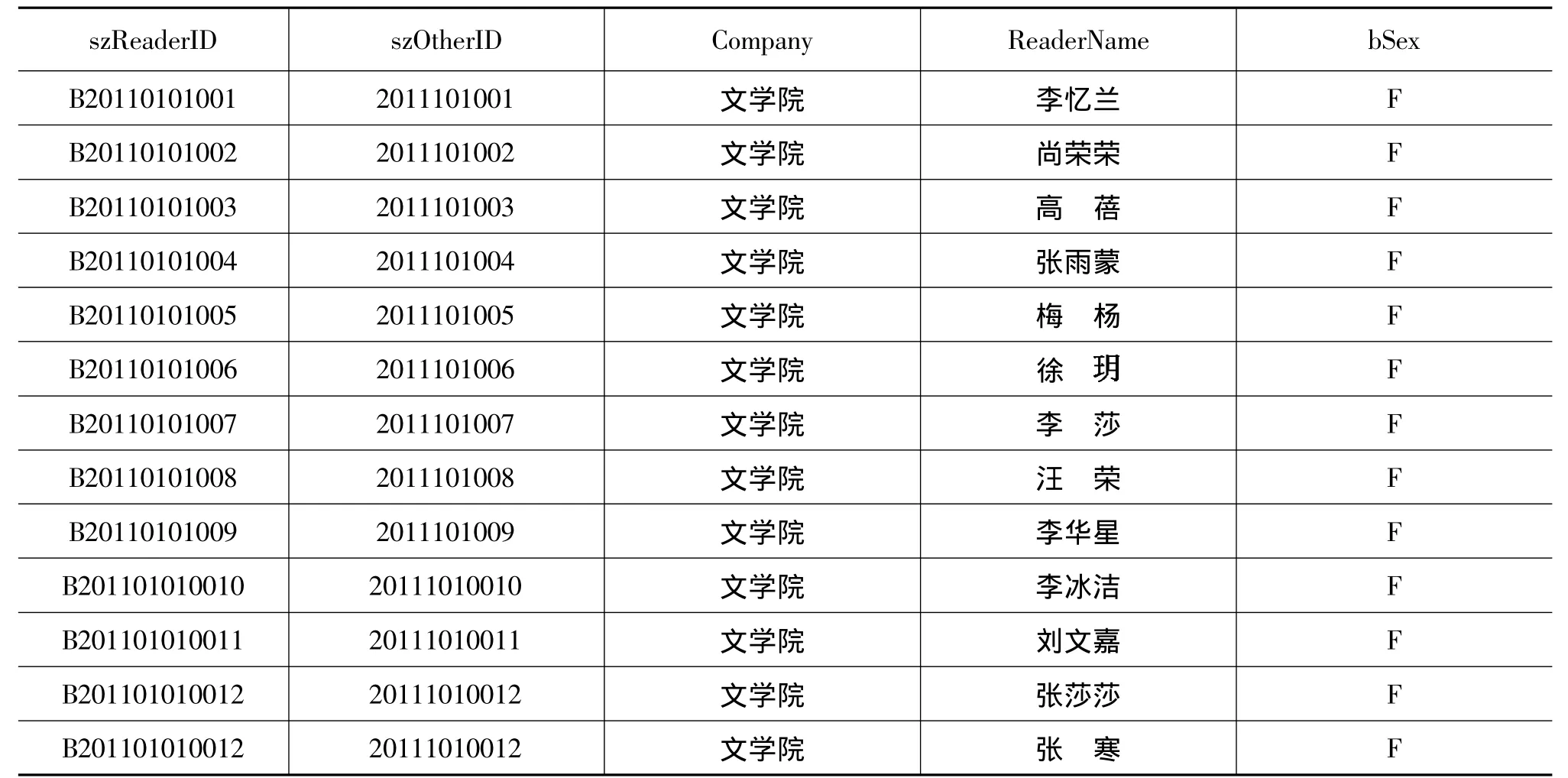
表6 讀者信息表

表7 加了ReaderName屬性與Company屬性的讀者借還信息表
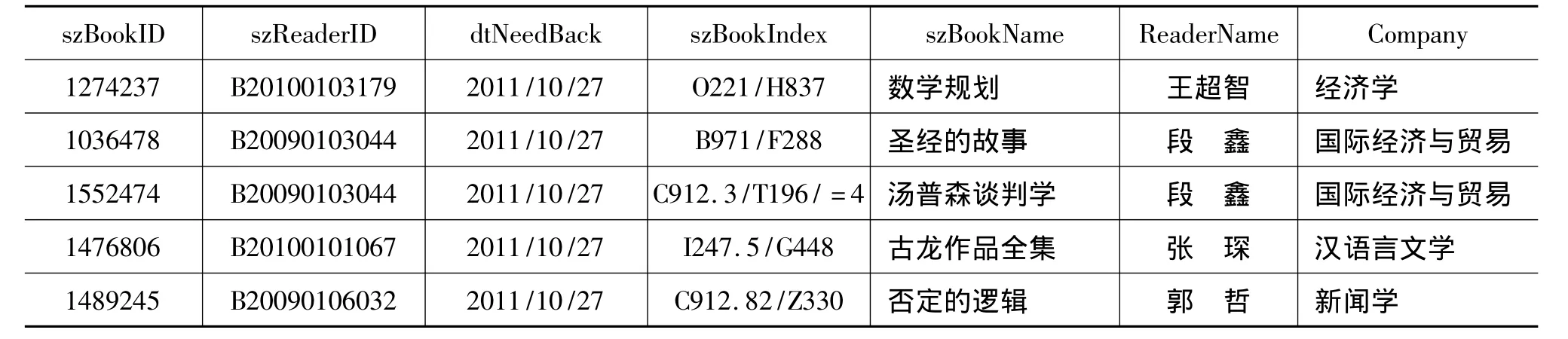
續表7
2.3 數據規約
一般數據庫中的數據表都很龐大,為了節約運算時間,我們需要對其進行規約。規約以后的數值將比原值小很多,但卻保持了原值的完整性。規約技術使得數據挖掘更加有效可行。利用圖書信息表、讀者信息表、借還信息表清理融合后得到表7所示的讀者借還信息表。該讀者借還信息表所記錄的讀者借閱記錄中,圖書的屬性有條碼號、書名以及索取號。其中條碼號為識別圖書的唯一標志,也就是說每本圖書的條碼號都是唯一的。而書名和索取號則可能相同,索取號由于記錄得比較詳細不利于數據挖掘的運算,我們把圖書的索取號即szBookIndex屬性進行規約。將圖書按中圖法的22個大類進行劃分,得到增加了新屬性szCategory的讀者借還信息表,如表8所示。
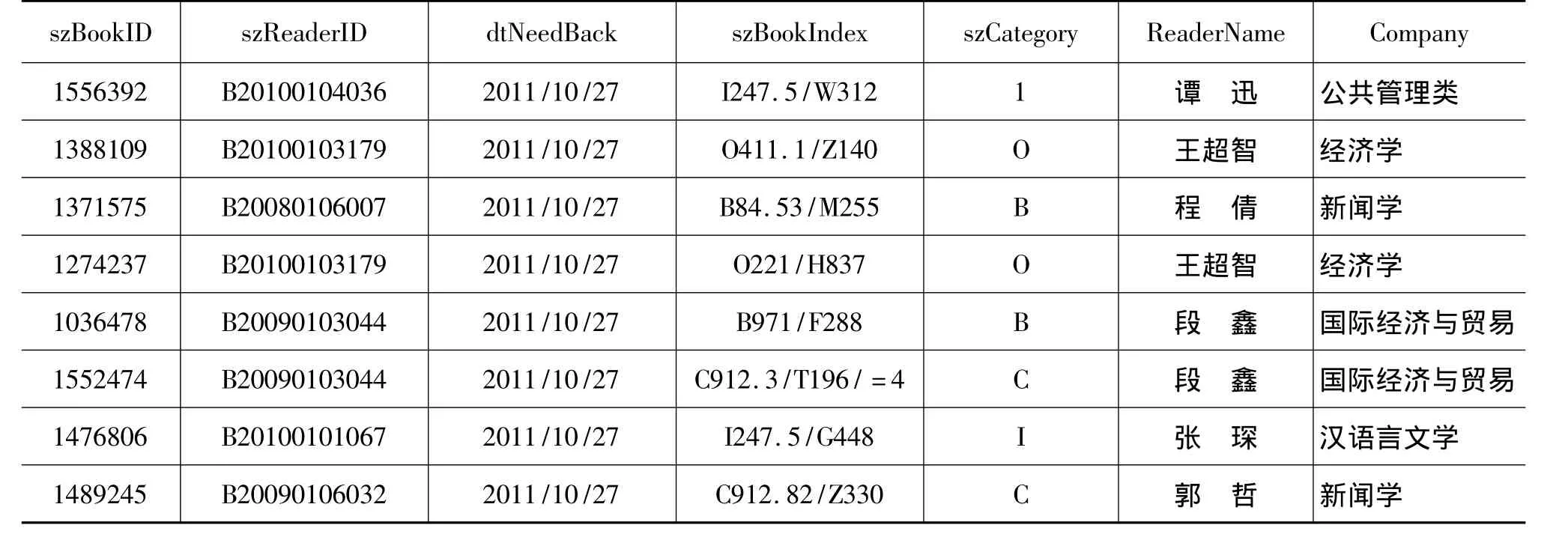
表8 規約后的讀者借還信息表
3 結語
數據挖掘技術近幾年已經開始應用于數字圖書館,利用數據挖掘方法中的聚類分析可以將讀者按閱讀興趣、借閱次數等進行分類。利用數據挖掘方法中的關聯規則可以為讀者提供個性化的推薦服務,如將讀者可能喜歡的圖書進行推薦,或者將可能流行的書推薦給采購人員。以上所說的數據挖掘技術的應用都離不開對數據的預處理。因此數據的預處理工作既是數據挖掘工作的基礎,也是數據挖掘工作中相對重要的步驟。數據預處理是數據挖掘工作科學有效的基礎。
[1]Han Jiawei,Kamber Micheline.數據挖掘:概念與技術[M].北京:高等教育出版社,2001.
[2]謝邦昌.數據挖掘Clementine應用實務[M].北京:機械工業出版社,2008.
[3]Tan Pang - Ning,Steinbach Michael,Kumar Vipin.數據挖掘導論:完整版[M].北京:人民郵電出版社,2011.
[4]高建煌.個性化推薦系統技術與應用[D].中國科學技術大學計算機應用技術,2010.
猜你喜歡
大眾投資指南(2021年35期)2021-02-16 01:06:26
小太陽畫報(2018年1期)2018-05-14 17:19:25
中華手工(2017年2期)2017-06-06 23:00:31
電力與能源(2017年6期)2017-05-14 06:19:37
少年博覽·小學低年級(2016年10期)2016-11-24 06:48:23
信息通信技術(2015年6期)2015-12-26 01:16:46
漫畫月刊·炫版(2015年4期)2015-05-27 07:52:10
中外會展(2014年4期)2014-11-27 07:46:46
小天使·一年級語數英綜合(2014年8期)2014-06-26 14:42:04
電子設計工程(2014年18期)2014-02-27 12:00:13
