優化地學詞匯標注方案 奠定完善地質語料庫基礎*
2013-10-23 11:58:26張翼翼董淑欣楊會蘭
外語學刊 2013年4期
張翼翼 董淑欣 楊會蘭
(中國地質大學,北京100083)
優化地學詞匯標注方案 奠定完善地質語料庫基礎*
張翼翼 董淑欣 楊會蘭
(中國地質大學,北京100083)
在地學文獻翻譯實踐過程中,筆者通過Google在線翻譯提供的譯文,結合地質專業詞匯的特點,分析基于語料庫的機器翻譯系統存在的一些典型問題。同時,從優化詞匯標注方案角度對語料處理提出建議,借此提升地學文獻的機器翻譯質量,為構建地學領域的專用型語料庫奠定基礎。
語料庫;詞匯;標注
1 引言
關于語料庫的定義,Atkins 和Clear認為,語料庫是為專門目的、按照明確設計標準收集的文章集合(Granger 1998:7)。該定義包含3個方面:(1)建構語料庫具有專門的目的;(2)語料庫具有明確的設計標準;(3)語料庫是由文章組成的集合(王建新 2005:16)。也就是說,語料庫由自然出現的語言樣本匯集而成,是為語言研究而收集并用電子形式保存的語言材料。
計算機技術迅速發展,使包含廣泛自然語料的語料庫得以建立。語料庫不僅對詞匯學、翻譯、語言教學等研究有巨大促進作用,而且對機器翻譯軟件、信息提取軟件、拼寫檢查軟件的發展具有重大的推動作用,語料庫方法也因此成為自然語言處理的重要方法(王建新2005:4)。
近年來,計算機語料庫對自然語言處理的各個不同方面(如話語識別、人機對話、信息提取、網頁分類、機器翻譯、文字處理等)都顯得極為重要,而且極具潛力,這已經得到國際計算語言學界的廣泛認可(王建新 2005:3)。但是,基于語料庫的機器翻譯的效果仍然不夠理想,尤其是涉及到具有專業背景和行業特色的相關文獻時,這種不理想體現得更加明顯。
目前,地學領域的中英文語料庫還未完全建立,作為專用型語料庫,地質語料庫是專門為地學領域的科研、教學、教材編寫以及語言比較研究而收集的文章集合,其取樣的文本應該力求代表地學環境中的英語語言及其變體。語料庫中除了大量地學信息有助于提升機器翻譯質量之外,相應語料處理尤其是詞匯標注(附碼)在很大程度上決定著翻譯質量的高低。因此,本文以節選自Long-termpersistenceofoilfromtheExxonValdezspillintwo-layerbeaches(NatureGeoscience)的片段為例,說明如何通過優化語料庫詞匯的標注方案,提升地學文獻的機器翻譯質量,為完善地學領域的專用型語料庫奠定基礎。
2 實證分析
原文:Oil spilled from the tanker Exxon Valdez in 1989 (refs 1, 2) persists in the subsurface of gravel beaches in Prince William Sound, Alaska. / The contamination includes considerable amounts of chemicals that are harmful to the local fauna 3. / However, remediation of the beaches was stopped in 1992, because it was assumed that the disappearance rate of oil was large enough to ensure a complete removal of oil within a few years. / Here we present field data and numerical simulations of a two-layered beach with a small freshwater recharge in the contaminated area, where a high-permeability upper layer is underlain by a low-permeability lower layer.
利用Google 提供的在線翻譯譯文:石油從油輪,埃克森公司在1989年瓦爾迪茲(文獻1,2)瀉堅持在阿拉斯加州威廉王子灣,礫石的海灘地下。/ 污染向當地動物都是有害的化學物質,包括相當數量。/ 然而,泳灘的整治是在1992年停止,因為它是假設石油的消失率足夠大,以確保在幾年之內徹底清除的石油。這里我們提出一個兩層的海灘,在污染區,其中一個高滲透率的上層是由一個低滲透率較低層之下的小淡水補給領域的數據和數值模擬。
在討論之前,首先看機器翻譯的基本模式(巢文涵 2008:9):
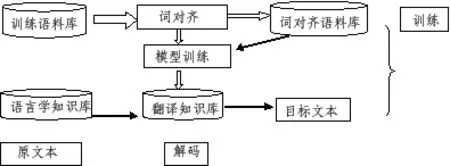
從圖中可以看出,處理語料庫中的詞匯在機器翻譯中扮演著重要角色。Google提供的在線翻譯將remediation,removal分別譯為“整治”、“清除”,這說明機器翻譯系統針對某些詞匯能根據整個語篇進行意義層面的對齊,然而對另外一些詞匯的釋義卻不夠理想。例如,將persist譯為“堅持”,是由于受到后面介詞in的影響。英文單詞persist既有 “堅持做某事”的釋義,也有“持續/存留”的釋義。Google在線翻譯使用的翻譯系統對語料庫中persist進行詞類自動標注時,依據局部上下文線索(王建新 2005:180)區分persist的兩種含義,致使in及其后面單詞的詞性成為區分兩種不同意義的關鍵。其實,原文中的in是地點狀語的一部分,與后面的名詞關系密切,與前面的動詞關系松散,并不代表persist in doing sth中的in,因此persist應該翻譯為“存留”而非“堅持”。有鑒于此,標注詞匯時是將詞組拆開還是另覓其他組合方式,有賴于句法規則和出現頻率。
受到固定搭配影響的例子還包括將assumed錯誤地翻譯為“假設”,而沒有視其為常常出現在科技文章中的習慣性用法,正確地將it is assumed that翻譯成“人們認為”。語料庫中的詞匯大部分是一個一個被標注的,而特定語言環境要求靈活地將幾個單詞標注為一個整體,這往往成為機器翻譯的死角。
再如,由于忽略地質英語詞匯的特點,將field data直譯為“領域上的數據”。這說明現有語料庫對地學領域的語料收集不足,單詞釋義也缺乏融合專業背景的詳盡標注。許多術語雖然由日常詞匯構成,卻有別于常規用法,不可“望詞生義”,更不能將兩個單詞的詞義簡單疊加:field data 應該譯為“野外數據”,field moisture 應該譯為“土壤水分”,field capacity 應該譯為“田間持水量”,oil field 應該譯為“油田”。其他的例子還包括:ground water不是“地上的水”而是“地下水”,guide fossil不是“指導化石”而是“標準化石”,induced fracture 不是“引導裂縫”而是“次生裂縫”,oil recovery 不是“油恢復”而是“采油”,pressure buildup 不是“壓力增加”而是“壓力恢復”(何大順 2007)。
高璞等(2009)認為,地質英語詞匯的特點按照構成方式的不同可以分為:(1)本專業特有的詞匯,如geology(地質學)、mineral (礦石) 和dinosaur(恐龍);(2)與其他專業共有的詞匯,如reservoir(水力專業)譯為“水庫”、plat form (交通專業)譯為“站臺”;(3)與日常生活共用的詞匯,如fault (平時譯為“缺點”,地質含義為“斷層”)、basin(平時譯為“盆或者臉盆”,地質含義為“盆地或者流域”)、shear(平時譯為“剪切”,地質含義為“受剪切破壞的面或者帶”)、graduate(平時譯為“畢業或者畢業生”,地質含義為“刻度”)、envelope(平時譯為“封皮”,地質含義為“圍巖”)、horizon(平時譯為“地平線”,地質含義為“層位”)、joint(平時譯為“接頭”,地質含義為“節理”)。顯然,上述因素會加大語料庫構建過程中詞匯的標注難度。
即便都是地學的相關文獻,由于細分的專業不同,同一單詞會呈現出不同含義,這使得詞匯的標注過程更加復雜。例如,earth core 在普通地質學中譯為“地核”,rare earth在能源地質學中譯為“稀有金屬”,earth slide在工程地質學中譯為“滑坡”(林徹 1983)。有時候,同一詞匯的含義在不同學科的地質著作中大相徑庭。例如,當trap與地層、構造、沉積作用有關時,譯為“圈閉”;與石油有關時,譯為“油捕”;與火山巖有關時,則譯為“暗色巖”。又如,deposit與各種礦產、礦床類型的術語以及專有名詞Noranda,Quemont,Jerome 等連用時,通常譯為“礦床”,而與表示各種沉積巖類型的術語聯用時則譯為“沉積”。不僅如此,某些詞的單、復數形式也影響單詞的含義,例如,單數compass 譯為“羅盤”,復數compasses 則譯為“圓規”;單數earth譯為“地球”,復數earths譯為“土族金屬”;單數fold譯為“褶曲”,復數folds譯為“褶皺”;單數scale譯為“比例尺”,復數scales譯為“天平”(尹麗莉 2009)。遺憾的是,目前機器翻譯系統尚不能識別、區分這些詞匯及其形式所表意義上的細微差別。
3 研究結論
綜上所述,我們應該加大帶有行業背景的專業語料的收集力度,為完善地學領域的專用型語料庫奠定堅實的“物質基礎”。而語料庫中的詞匯是否能夠被合理地標注,則成為語料庫構建的重中之重。筆者認為,對于經常用到的固定搭配,要根據科技文獻的寫作特點,用整體標注替代分別標注;若通過機器翻譯系統的自動標注軟件難以實現詞間“整合”,則在必要時采取自動標注后的人工核對或者人工標注;對于容易產生歧義的詞匯,要基于規則和概率結合的方法,根據上下文和專業排除可能的歧義。
實際上,除了可以通過改進詞匯的標注方式來實現語料庫的維護和升級外,語料本身的質量也決定著機器翻譯的質量。這要求在收集語料時,既要保證收錄高質量的源語言語料,又要保證收錄相應的高質量譯文,如此,才能為語料的后期處理提供更多方便。
巢文涵.基于雙語語料庫的機器翻譯關鍵技術研究[D]. 國防科學技術大學博士學位論文, 2008.
陳群秀.計算機輔助翻譯系統漫談[Z].第十一屆全國民族語言文字信息研討會, 2007.
馮志偉.機器翻譯研究[M].北京:中國對外翻譯出版公司, 2004.
馮志偉.基于語料庫的機器翻譯系統[J].術語標準化與信息技術, 2010(1).
高璞等.石油地質英語詞匯教學方法探析[J].中國地質教育, 2009(4).
何大順 何 春. 論地學專業文獻的英漢翻譯[J].成都理工大學學報(社會科學版), 2007(4).
林 徹.地質翻譯參考[M].北京:地質出版社, 1983.
曲江秀 譚麗娟.地質專業英語的特點和教學方法探討[J].中國科教創新導刊, 2008(19).
王建新.計算機語料庫的建設與應用[M].北京:清華大學出版社, 2005.
肖維青.平行語料庫與應用翻譯研究[J].中國科技翻譯, 2007(3).
尹麗莉.地質英語的詞匯特點探析[J].吉林地質, 2009(3).
Granger, S.TheComputerLearnerCorpus:AVersatileNewSourceofDataforSLAResearch[M]. London/New York: Longman, 1998.
Mona, B.CorpusLinguisticsandTranslationStudies:ImplicationsandApplications[M]. Amsterdam: John Benjamins Publishing Company, 1993.
OnWord-processingBasedupontheAnnotatedCorpus
Zhang Yi-yi Dong Shu-xin Yang Hui-lan
(China University of Geosciences, Beijing 100083, China)
This study is done by the Work-shop of English for Geology, an academic group under the Department of Foreign Languages at China University of Geosciences (Beijing). According to a piece of Chinese episode translated into English by Google on the Internet, this paper focuses on how to make computer-aid-translation better in light of word-processing based upon the annotated corpus, by means of correcting the translations with problems and analyzing the features of writing in Geological field.
corpus; word; annotated
*本文系中央高校基本科研業務費專項資金資助項目“基于我國世界地質公園的中英文公示語研究雙語平行對譯語料庫的構建”(2-9-2012-04)的階段性成果。
H314
A
1000-0100(2013)04-0122-3
2013-03-31
【責任編輯王松鶴】
猜你喜歡
英語世界(2022年9期)2022-10-18 01:11:46
中華胰腺病雜志(2021年1期)2021-02-26 11:28:36
山東醫藥(2020年34期)2020-12-09 01:22:24
瘋狂英語·新策略(2019年9期)2019-10-17 01:51:32
中華胰腺病雜志(2019年4期)2019-08-29 08:52:20
中學生數理化·七年級數學人教版(2017年3期)2018-01-20 12:45:49
山東醫藥(2017年35期)2017-10-10 02:45:28
學生天地(2016年16期)2016-05-17 05:45:55
中國工程咨詢(2015年6期)2015-02-16 05:33:56
中華胰腺病雜志(2013年3期)2013-10-19 03:16:56
