基于MapReduce的HITS算法的實現
2013-10-23 09:56:10王笑梅
上海師范大學學報·自然科學版 2013年5期
余 輝,王笑梅
(上海師范大學信息與機電工程學院,上海200030)
0 引言
HITS算法是一種基于“導航頁”和“權威頁”的迭代算法[1],用于計算每個網頁的重要性.由于處理的網頁數量巨大,普通的串行實現效率太低,在這種情況下,考慮使用MapReduce編程模型來實現HITS算法成為必然.MapReduce編程模型最早由Google公司提出[2],用于并行處理大規模數據集,并逐漸成為云計算的核心技術之一.MapReduce的開源實現框架Hadoop[3-4]是一個優秀的并行編程平臺,它克服了傳統并行計算框架MPI的不足,實現了計算向存儲遷移[5],在處理密集型的大規模數據集時有很大的優勢.
1 HITS算法與Hadoop框架
1.1 HITS 算法
HITS算法對網頁重要性的計算有兩個度量準則,第一個是網頁作為導航頁的重要性,即它的導航度;第二個是網頁作為權威頁的重要性,即它的權威度.網頁的導航度和權威度分別用n維向量h和a表示,第i個網頁的導航度為向量h的第i個分量,權威度為向量a的第i個分量.為了計算出向量h和a,還需要一個n×n維的連接矩陣L和它的轉置矩陣LT,如果Lij=1,則表示第i個網頁到第j個網頁存在鏈接,如果Lij=0,則表示兩個網頁之間沒有關聯.
一個網頁的導航度依賴于這個網頁所鏈出網頁的權威度,權威度依賴于這個網頁所鏈入網頁的導航度,所以有以下公式:

由權威度a計算出導航度h,再由導航度h計算出權威度a.顯然,這是一個迭代過程,第一次迭代時取a為n維全1向量.由于迭代過程中h和a的分量可能會急劇增大,所以需要做歸一化處理:

其中ξ和δ是歸一化因子,它們將每次迭代計算出的h和a的最大分量變為1.以上公式(3)和(4)作為1次完整的迭代,當h和a分別達到一定精度要求時即停止迭代.
1.2 Hadoop 框架
基于MapReduce編程模型的云計算框架Hadoop是一種分布式并行計算框架,在其底層支撐MapReduce數據處理功能的是分布式文件系統HDFS[6,7],MapReduce編程模型和HDFS構成了Hadoop最基本、最核心的組件.HDFS的結構如圖1所示.
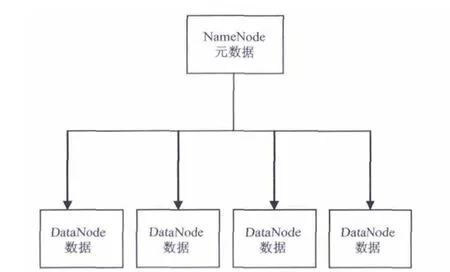
圖1 HDFS結構
在分布式環境中,存在著一個主節點NameNode和多個從節點DataNode.主節點存儲著文件系統的元數據,比如文件系統的名字空間等,用于向用戶映射文件.但實際的數據并非存儲于主節點,而是分布存儲在多個從節點上.Hadoop在MapReduce編程模型上的主程序被稱為Jobtracker,子程序被稱為Tasktracker.主程序負責整個MapReduce執行流程的控制工作,由于需要讀取文件系統的相關信息,所以它通常位于主節點.主程序啟動之后,會創建位于從節點的子程序.子程序Tasktracker每隔一段時間向主程序Jobtracker發送心跳,返回自己的執行狀態.子程序會在從節點創建兩種類型的子任務,分別是map任務和reduce任務.在Hadoop中由于有HDFS文件系統的支持,數據是分布式存儲在各個節點的,map任務在并行運行時,各節點讀取存儲在自己節點的數據進行處理,從而避免了大量數據在網絡上的傳遞,實現了計算向存儲的遷移.map任務生成中間的<key,value>對集合,將其存儲在本地,并將具有相同key的中間值合并發送給reduce任務;reduce任務將合并的值進行相關的計算后產生最后的<key,value>對集合.MapReduce編程模型如圖2所示.

圖2 MapReduce編程模型
2 算法設計
2.1 基本思想
從公式(3)和(4)可以看出,HITS算法可以簡化為矩陣和向量的乘法.若有n×n維矩陣A和n維向量 b,則

基于MapReduce的矩陣和向量乘法的算法思想如下:
map階段:對于矩陣A的每個元素 Aij,生成鍵值對 < <i,1>,<A,j,Aij> >;對于向量 b的每個元素 bj,生成鍵值對 < <i,1 > ,<b,j,bj> > ,其中 i=1,2,…,n.
reduce階段:根據MapReduce編程模型的原理,具有相同key的鍵值對合并后發送給reduce任務,此時即可計算出(Ab)i,并輸出鍵值對 < <i,1>,(Ab)i>.
2.2 算法實現
為了實現基于MapReduce的HITS算法,需要編寫3個函數,即map函數,reduce函數和main函數.map和reduce函數分別實現上述算法思想中的map階段和reduce階段,main函數則負責向量的精度控制.當同時滿足兩個條件時,就停止迭代.基于 MapReduce的HITS算法的偽代碼描述如下:

3 實驗
3.1 實驗平臺
采用一臺Intel(R)Xeon(R)cpu E5-16070@3.0GHZ,8G內存pc作為主機,在 pc上安裝5臺VMware虛擬機,其中1臺作為NameNode(Jobtracker)節點,另外4臺作為DataNode(Tasktracker)節點.每臺虛擬機安裝linux Red Hat 9.0操作系統,分配1G內存;Hadoop和java的版本分別為hadoop-0.20.2,jdk1.6.實驗數據采用來自斯坦福大學的StanfordBerkeleyWeb數據集,其中包含685230個網頁,頁面之間存在7636535條鏈接,數據集大小為143M.
3.2 實驗分析
3.2.1 分塊大小對算法運行時間的影響
在Hadoop框架中,分塊大小(blocksize)會直接影響算法執行的效率.在集群中,map任務的數量和對輸入文件進行分塊后的塊數是相等的,所以輸入文件的大小和blocksize決定了集群中map任務的數量.如果blocksize太小,則啟動的map任務過多,就會導致集群負載劇增,過多地損耗資源,降低算法性能;反之,如果blocksize太大,map任務太少,算法就不能充分利用集群資源,不能充分發揮出并行的特性.因此,在執行算法時,需要合理的配置集群中blocksize的大小,在不增加集群負載的情況下充分發揮出并行處理的優勢.實驗中采用數據集StanfordBerkeleyWeb,將blocksize分別設置為16、32、64、128、256M,在不同的blocksize下分別執行算法,結果如表1所示.

表1 不同blocksize下算法執行時間
由于集群有5臺虛擬機,其中4個是DataNode節點,所以blocksize為16、32、64、128、256M時,平均每個DataNode節點分配到的map任務為2~3個,1~2個,0~1個,0~1個,0~1個.從表1可以看出,當blocksize為16M,即每個DataNode節點分配2~3個map任務時,算法運行的效率最高;當blocksize增大時,由于沒有充分利用集群的并行特性,算法效率逐漸降低.
3.2.2 集群規模對算法運行時間的影響
將blocksize設置為64M,分別在3機集群、4機集群、5機集群的環境中執行算法,結果如表2所示.

表2 不同集群下算法執行時間
從表2可以看出,適當擴大集群規模,算法運行效率逐漸提高.這是因為隨著集群規模的擴大,集群中可利用的處理器和內存也會隨之增加,從而集群也獲得了更強大的并行處理能力.
4 結語
提出了一種基于Hadoop框架下的HITS算法的設計與實現.算法的設計主要涉及map階段和reduce階段,其中map階段是算法并行化的關鍵.在試驗中深入分析了集群配置參數blocksize和集群規模對算法執行效率的影響,探索了執行map任務期間的集群負載和集群的可伸縮性.在后續工作中,將繼續探索云計算環境下的搜索引擎相關算法的設計與實現,并就如何提高算法的性能展開研究.
[1]RAJARMAN A,ULLMAN J D.Mining of Massive Datasets[M].Cambridge:Cambridge University Press,2011.
[2]DEAN J,GHEMAWAT S.Mapreduce:simplified data processing on large clusters[J].Communications of the ACM,2008,51(1):1-13.
[3]WHITE T.Hadoop:The Definitive Guide[M].Newton:O’Reilly Media,2010.
[4]WIKIPEDIA.Hadoop[EB/OL].[2011 -10 -15](2013 -04 -15).http://en.wikipedia.org/wiki/Hadoop.
[5]王鵬.云計算的關鍵技術與應用實例[M].北京:人民郵電出版社,2010.
[6]SHVACHKO K,KUANG H.The Hadoop Distributed File System[C]//Proceedings of the 26thIEEE Symposium on Massive Storage Systems and Technologies,Piscataway:IEEE Press,2010.
[7]GHEMAWAT S,GOBIOFF H,LENNG S.The google file system[J].ACM Sigops Operating Systems Review,2003,37(5):29-43.
