基于APRIORI算法和OLAP的關聯規則對圖書信息分類模型的設計
2013-11-20 11:31:30毛敬玉
黑龍江生態工程職業學院學報 2013年4期
毛 敬 玉
(蘭州職業技術學院,甘肅 蘭州 730070)
1 APRIORI算法和OLAP
數據挖掘是近年來研究數據庫領域的熱點之一。在眾多數據挖掘方法中,關聯規則是數據挖掘中的重要研究對象。它最典型的應用就是在大量的數據庫信息中發現新的有用的信息。APRIORI算法是一種使用很廣泛的挖掘布爾關聯規則頻繁項集的算法,是關聯規則挖掘算法中的經典算法之一。它的基本思想是:首先找出所有的項集,這些項集出現的頻繁性至少要與預定義的最小支持度一致。然后由這些頻集生成強關聯規則,這些規則必須滿足最小支持度與最小可信度。然后使用第1步找到的項集產生期望的規則,產生只包含集合的項的所有規則,其中每一條規則在右部只有一項,這里采用的是中規則的定義。一旦這些規則被生成,那么只有那些大于用戶所給定的最小可信度的規則才會被留下來。為了生成所有頻繁項集,使用了遞歸的方法。 程序如下:
algorithm apriori(T)
C1←init-pass(T)
while (k=2;Fk-1≠¢;k++)do
Ck←candidate-gen(Fk-1)
while each transaction t∈T do
while each condidate c∈Ck do
if c is contained int
then c.count++
end if
end while
end while
end while
return F←UkFk
OLAP聯機分析處理技術是目前數據倉庫中數據多維分析的使用最多的驗證型工具。OLAP系統采用數據存儲方案為物化數據立方體,以空間代價來換取時間效率。對關聯規則挖掘來說,挖掘過程中大量所需的中間數據已經被物化在數據立方體中而無需重新計算,由此可以節約大量的數據挖掘時間。
圖書行業在其發展過程中,積累了大量的各種圖書的流通信息,以往的信息管理系統缺少尋找大量數據間的有用的、隱含的和潛在的信息能力,如何有效利用APRIPRI算法和OLAP關聯規則,從海量的數據中挖掘出有實用價值的信息,并在圖書管理過程中將其轉化為效益,是圖書管理者們的急迫任務之一。本文將根據APRIORI算法的特點對OLAP數據立方體維度、度量值等方面設計進行充分考慮,設計出能高效地為關聯規則挖掘程序提供更多的中間數據,以此為基石,通過現存的圖書關系數據庫和實際的圖書信息數據,生成數據立方體并進行關聯規則的挖掘。
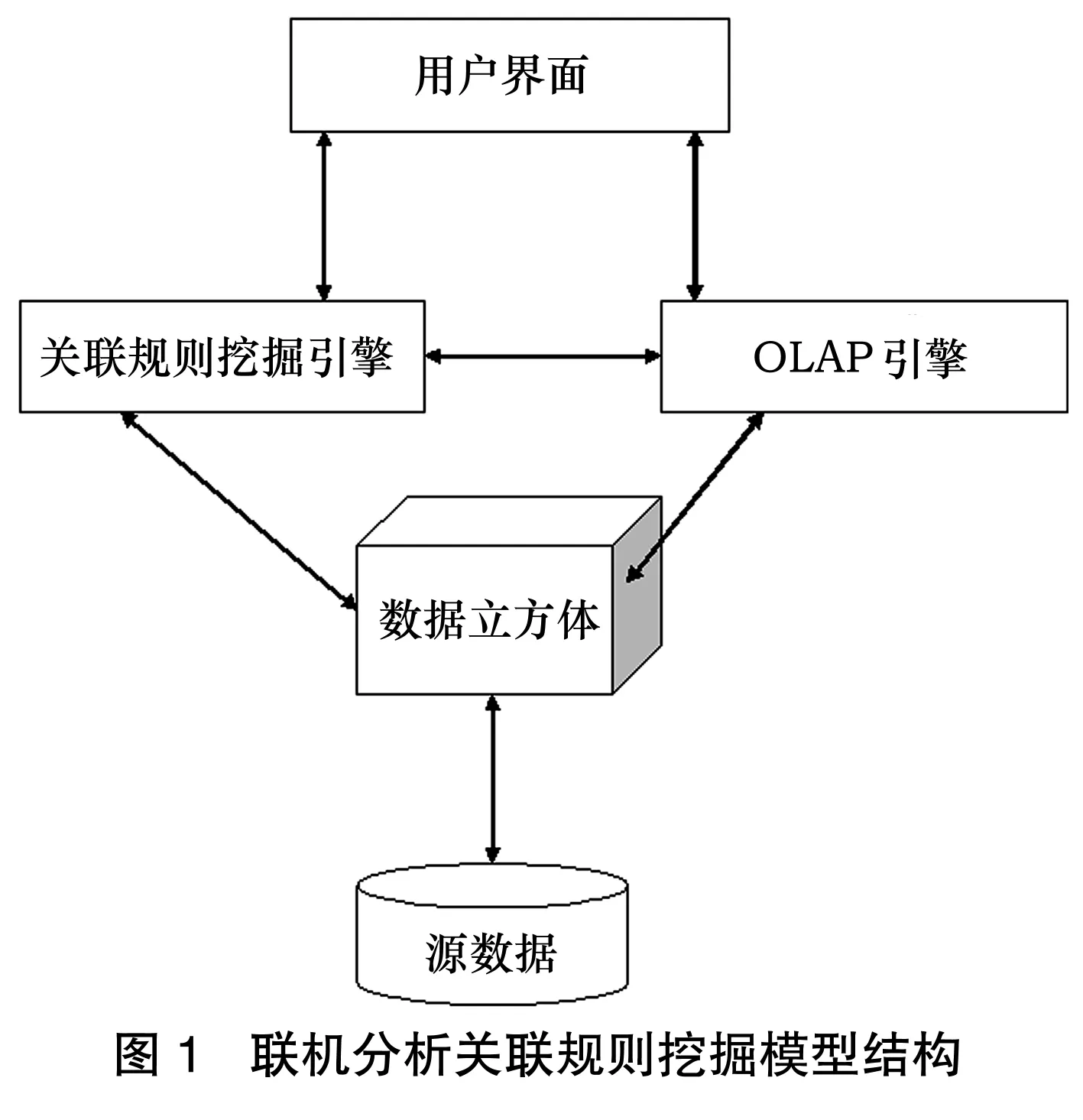
2 APRIORI算法在圖書系統數據挖掘中的應用
隨著專業的不斷分支發展,人們對于專業學習的不斷深入和細化,圖書在圖書營銷或圖書館建設過程中都積累了大量的圖書信息數據,并且這個數據與日俱增。如何處理和如何深入其內部獲取有用的信息,研究人員進行了大量的探索,而人們也不再只停留在對數據的簡單操作上轉而開始思考和探索如何從海量的數據中提取藏在數據背后的、潛在的知識或信息為最終的決策提供有力的數據支持。例如圖書館藏書的分類整理、圖書市場的運營管理決策、電子圖書館建設過程中對于圖書的選擇等等。
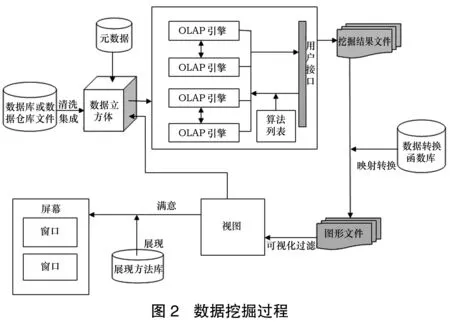
我們可以按圖2流程來進行:
2.1 OLAP引擎和數據立方體
從圖1我們可以看出,OLAP引擎和數據立方體是不同的兩個模塊,但是兩者的關系很密切。數據立方體為OLAP引擎提供數據存儲,OLAP引擎為數據立方體提供I/O接口操作和其他數據立方體操作。
2.2 維度表和事實表的設計
在整個數據挖掘過程中,需要用到事實表和維度表。事實表是數據倉庫架構中的中央表,它包含連接事實與維度表之間的數字度量值和關鍵字。事實數據表包含描述運作過程中特定事件的數據。維度表可以是用戶用來分析數據的窗口。維度表中包含事實數據表中事實記錄的特性,有些提供描述性特性信息,有些指定如何匯總事實數據表特性數據,以便提供有用的信息給分析者,維度表包含幫助匯總數據的特性的層次結構。
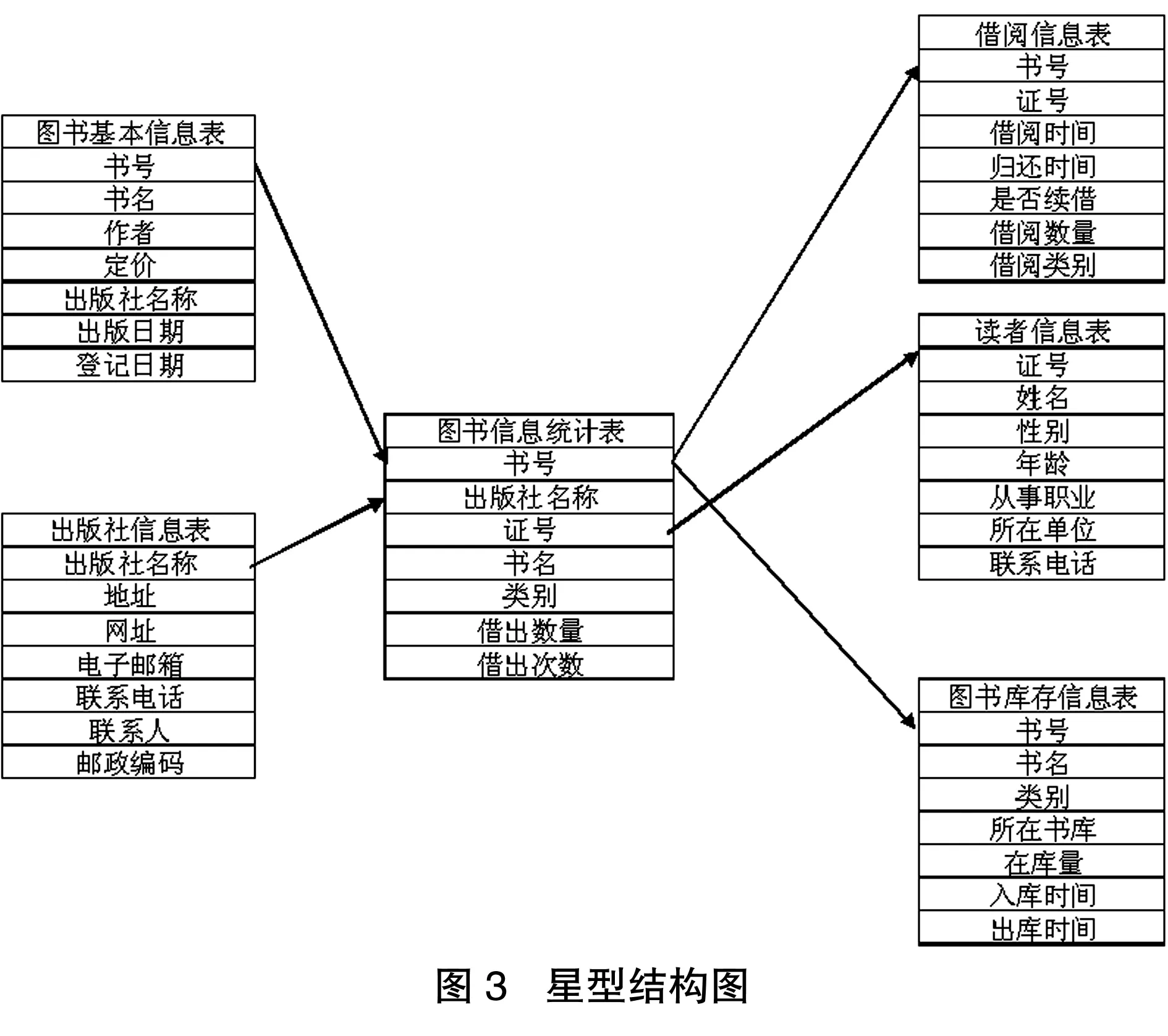
我們給每一個信息表建立一張對應的維度表,為了避免重復,我們需要給這些維度表重新用一個序號來標識,同時建立一張事實表,以各維度表的主關鍵字為關鍵字,并建立一個事實表的關鍵字序號,形成一個相應的星型結構,如圖3所示。
以圖書館管理為例,我們需要用到的主要的數據表有以下內容:
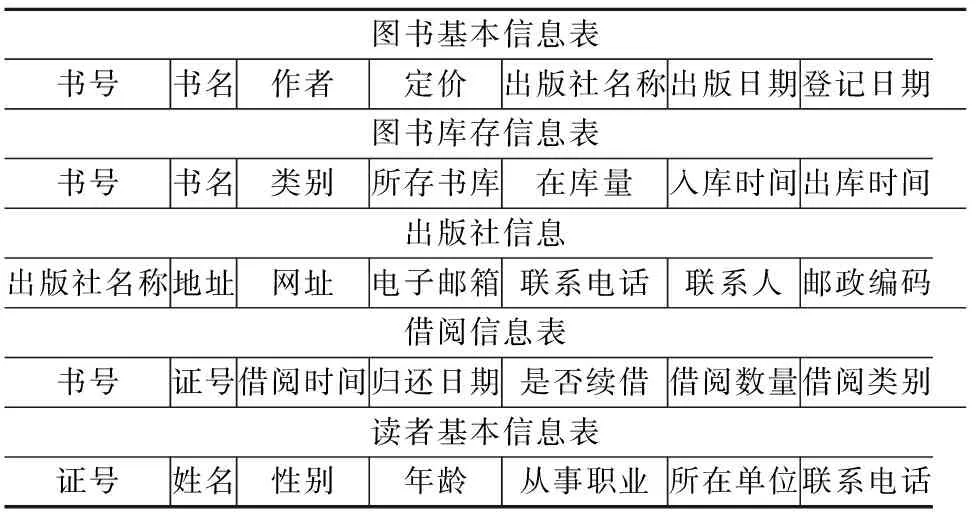
圖書基本信息表書號書名作者定價出版社名稱出版日期登記日期圖書庫存信息表書號書名類別所存書庫在庫量入庫時間出庫時間出版社信息出版社名稱地址網址電子郵箱聯系電話聯系人郵政編碼借閱信息表書號證號借閱時間歸還日期是否續借借閱數量借閱類別讀者基本信息表證號姓名性別年齡從事職業所在單位聯系電話
這些表格產生的維度表構成的星型結構圖如下:
APRIORI算法存在以下兩個比較明顯的缺陷。首先,有可能產生大量的候選集;其次,需要重復掃描數據倉庫中的數據,在挖掘過程中會因迭代產生候選項集用來統計其支持度而花費大量的時間。為了節約運算時間,我們需要將算法加以改進來提高效率,改進的算法描述如下:
任何長度為k的事務都不可能包含(k+1)-項子集。對原始事務數據庫中的每一個事務進行第一次掃描并計數后,立即刪除長度為1的當前事務,因為該事務不會對后面的頻繁2-項集的生成起作用,所以以后的操作不再需要該事務了。在進行第二次掃描并對2-項集計數之后,立即刪除長度為2的事務。這樣,第二遍掃描的事務數據庫就被壓縮了,從而提高了算法的效率。該方法可以應用到以后的每一趟掃描中,即在對候選k-項集計數之后,立即刪除長度為k的事務。
procedure apriori-whb(Lk-l,min-sup)
forall items l1∈Lk-l
forall items l2∈Lk-l
if ((l1[1]=l2[1])∧...∧(l1[k-2]=l2[k-2])∧l1[k-1] C=l1?l2 //連接兩個項集 if has-infrequent-item set(C,Lk-l) delete C else Ck=Ck∨{C} end if Dk=whb-del(Dk-l,Lk-l)//刪除不滿足條件項集,減少下次掃描DB的記錄次數 end if return Ck procedure whb-del(Lk-l,Dk-l) forall items l1∈Dk-l if |l1| end if if l1≮Lk-l then delete l1 end if return Dk procedure has-infrequent-sub set(C,Lk-l) forall (K-1)subset s of C if s¢Lk-l then return true else return false end if L1={large l-itemsets}//D中的L項集 for(k=2;Lk-l≠?;k++)do begin Ck=apriori-gen(Lk-l,minsup) forall transaction t∈D do begin Ct=subset(Ck,t)//t所包含的候選項集 forall candidate c∈Ct do c.count++ end Lk={c∈Ck|c.count≥minsup} end answer=UkLk 本文主要介紹了基于APRIORI算法和OLAP的關聯規則對圖書信息分類模型的設計,為圖書館或者學校圖書管理提供了很好的技術支持,使圖書管理和圖書分類變得越來越簡單,越來越方便。 參考文獻: [1][美]陳封能,斯坦巴赫,庫瑪爾.數據挖掘導論[M].北京:人民郵電出版社,2011. [2]董琳.數據挖掘實用機器學習技術[M].北京:機械工業出版社,2006. [3]林杰斌.數據挖掘與OLAP理論與實務[M].北京:清華大學出版社,2003. [4]何玉潔,張俊超.數據倉庫與OLAP實踐教程[M].北京:清華大學出版社,2008.3 結語
猜你喜歡
小獼猴智力畫刊(2022年3期)2022-03-29 01:09:42當代陜西(2021年17期)2021-11-06 03:21:36數學小靈通(1-2年級)(2021年4期)2021-06-09 06:26:14大眾投資指南(2021年35期)2021-02-16 01:06:26學苑創造·A版(2018年11期)2018-02-01 06:29:20Coco薇(2017年11期)2018-01-03 20:59:57電力與能源(2017年6期)2017-05-14 06:19:37讀者(2017年5期)2017-02-15 18:04:18暨南學報(哲學社會科學版)(2016年9期)2017-01-15 13:52:02信息通信技術(2015年6期)2015-12-26 01:16:46
