一種不確定性數據中最大頻繁項集挖掘方法
2013-12-18 06:58:14汪金苗張龍波閆光輝王鳳英
山東理工大學學報(自然科學版) 2013年5期
關鍵詞:實驗
汪金苗, 張龍波, 閆光輝, 王鳳英
(1.山東理工大學 計算機科學與技術學院, 山東 淄博 255091;2.蘭州交通大學 電子與信息工程學院, 甘肅 蘭州 730070)
不確定性數據廣泛存在于多個應用領域中,例如RFID(Radio Frequency Identification),LBS (Location Based Services),傳感器網絡等,其特點是每個數據對象不再是傳統的單個數據點,而是按照概率分布在多個數據點上[1].目前對不確定性數據挖掘算法的研究已經成為了數據挖掘領域的新熱點.不確定性數據挖掘主要包括分類、聚類、孤立點檢測、頻繁項集挖掘等方面,其中頻繁項集挖掘是重點研究的問題之一.
文獻[2]在Apriori算法的基礎上提出了適用于不確定數據挖掘的U-Apriori算法,文獻[3]在FP-growth算法的基礎上提出了基于樹結構的不確定數據頻繁項集挖掘算法UF-growth,文獻[4-6]進一步在此基礎上提出了包含約束條件的頻繁項集挖掘算法,文獻[7]綜述了不確定性數據中的頻繁項集挖掘算法,文獻[8]在基于約束的頻繁項集挖掘算法U-FPS的基礎上,提出了一種不確定性數據中基于約束的頻繁項集挖掘算法,其支持度的計算采用數據庫垂直模式求交集的方式.文獻[9]提出了一種不確定性數據中頻繁項的查詢算法,通過兩條過濾規則來減少檢測數據的數量,從而提高查詢精度.
目前,不確定性數據中最大頻繁項集的挖掘算法尚不多見,在此背景下本文提出一種不確定性數據中最大頻繁項集挖掘算法UMF-growth(Uncertain Maximal Frequent-growth),該算法以UF-growth算法為基礎,可通過兩個步驟完成最大頻繁項集的挖掘:(1)獲取所有的頻繁1-項集,進而挖掘出以所有頻繁1-項集為后綴的局部最大頻繁項集;(2)在UMF-tree的幫助下,從第(1)步得到的局部最大頻繁項集中挖掘出所有全局最大頻繁項集.
1 問題定義
在不確定性數據中,數據集D由d個事務t1,t2,…,td構成,每個事務ti由多個項構成,多個項的集合可用X來表示,每個項x在ti中出現的概率用P(x,ti)來表示.一個項集X出現在現實世界的概率(預計支持度except support)是通過將X出現在每個可能世界Wj的支持度相加得到的.用expSup(X)表示X出現在現實世界的預計支持度,可能世界Wj出現的概率用P(Wj)表示,X出現在可能世界Wj的概率用S(X,Wj)表示,則有如下公式:
P(Wj)=
(1)
expSup(X)=
(2)
如果一個由不確定性數據構成的頻繁項集Y的所有超集都是非頻繁項集,則稱Y為最大頻繁項集,所有的最大頻繁項集記為UMF(Uncertain Maximal Frequent);在挖掘過程中得到的、以某個項y為后綴的最大頻繁項集稱為y的局部最大頻繁項集,記為y-LUMF(Local Uncertain Maximal Frequent).
2 不確定性數據中最大頻繁項集挖掘算法UMF-growth
與UF-growth算法類似,我們提出的UMF-growth算法也是首先構建UF-tree,然后借助UF-tree進行最大頻繁項集的挖掘.UF-tree的每個節點包括三個字段:(1)項的名稱(2)預計支持度(3)預計支持度相等的同一個項出現的次數count.其構建過程如下:
(a)掃描整個事務數據庫,分別將每個項的支持度進行相加,結果(該項的預計支持度)不小于閾值的項記為頻繁1-項集,按照累加的預計支持度對所有的頻繁1-項集降序排序,結果保存在L中.
(b)類似與FP-tree的構建過程,再一次掃描事務數據庫,將每條事務中的頻繁1-項集按照L中的順序進行排序,然后插入到UF-tree中,同時舍棄非頻繁項,當數據庫中所有包含頻繁1-項集的事務均插入到UF-tree中后即完成了UF-tree的構建.UF-tree的構建過程與FP-tree的不同之處在于,當要插入某條事務時,當且僅當該事務包含的所有項的名稱及預計支持度依次與UF-tree中已有的某個分支上的項名及預計支持度完全一致時,該事務可以與這個分支合并,同時每個節點的count加1;如果即將插入的事務所包含的項與某個分支不完全一致,或者項名一致而某些項的預計支持度不一致,則該事務都要作為UF-tree的一個新的分支插入進來.
完成UF-tree的構建后就可以進行最大頻繁項集的挖掘了.UMF-growth算法將挖掘過程分為兩個步驟,(1)采用LUMF-growth(Local Uncertain Maximal Frequent-growth)挖掘所有以頻繁1-項集為后綴的局部最大頻繁項集;(2)利用所有的局部最大頻繁項集構建UMF-Tree,從而挖掘出所有的全局最大頻繁項集,即真正的最大頻繁項集.
2.1 局部最大頻繁項集挖掘算法LUMF-growth
UF-tree構建完成后,從L中的最后一個項x(即支持度最小的頻繁1-項集)開始,遍歷UF-tree,找出所有包含x的分支,這些分支即表示以x為后綴的局部最大項集(不一定是頻繁的).局部最大項集可能有多個,設其中的一個為{X,x},其中X包含k個項,x在此分支上的頻數count為n,計算項集{X,x}的預計支持度,根據不同的結果分兩種情況處理:
(1)如果得到的預計支持度不小于最小支持度閾值min_sup,即項集{X,x}是頻繁的,則將{X,x}記為以x為后綴的局部最大頻繁項集x-LUMF.同時按以下方法對UF-tree進行剪枝操作:如果項集{X,x}包含該分支上的所有節點,則將這些節點的頻數count減n(即減去已參與計算的部分),如果某些節點的count減為0,則將其剪枝.進行剪枝的原理為:由于x是支持度最小的項,所以x必定位于UF-tree的葉子節點,這樣x-LUMF就包含了該分支上的所有節點,以該分支上其他節點為后綴的局部最大頻繁項集一定是x-LUMF的子集,因此都不可能是最大頻繁項集,所以將其進行剪枝.
(2)如果得到的預計支持度小于支持度閾值min_sup,則對X生成包含k-1個項的子項集{X1,X2,…,Xk},然后分別計算{X1,x},{X2,x},…,{X,x}的預計支持度.對于{X1,x},如果其預計支持度不小于閾值min_sup,則按步驟(1)進行處理;否則,繼續對X1生成包含k-2個項的子項集,然后按同樣的方式處理,直到找到以x為后綴的局部最大頻繁項集或者子項集為空.
重復步驟(1)與(2),直到找到所有的x-LUMF,然后將UF-tree中所有包含x的節點刪除,對L中倒序排序的下一個頻繁1-項集按同樣的方式進行處理,直到UF-tree為空.此時即得到了所有以頻繁1-項集為后綴的局部最大頻繁項集.
算法的偽代碼如下:
(Ⅰ)LUMF_growth(UF-tree,Header)
輸入:當前的UF-tree,頭表Header
輸出:所有的局部最大頻繁項集
(1)forHeader中最后一個節點x的每個路徑{X,x}
(2)if (expSup{X,x}>=min_sup)
(3)x.LUMF=x.LUMF∪X
(4)ifX包含該路徑上的所有節點
(5) for每個節點β
(6)β.count=β.count-checkCount;
//checkCount指該節點參與計算的頻數
(7) if(β.count=0)
(8)Remove(β);
//如果頻數減為0則將該節點刪除
(9)else
(10)getMFSubset(UF-tree,{X,x});
(11)Remove(x);//將節點x從UF-Tree刪除
(12)Delete(x);//將x從Header中刪除
(13)LUMF_growth(UF-tree,Header);
(Ⅱ)getMFSubset(UF-tree,{X,x})
輸入:當前的UF-tree,項集 {X,x}
輸出:項集{X,x}的所有最長頻繁子項集
(1)k=getNodenum(X);//獲得集合X包含的節點數
(2)if (k>1)
(5) if(expSup{Xi,x}>=min_sup)
(6)x.LUMF=x.LUMF∪Xi;
(7) return( );
(8) else
(9)getMFSubset(UF-tree,{Xi,x});
2.2 最大頻繁項集的挖掘
完成局部最大頻繁項集的挖掘后,通過構建UMF-tree的方式來進行最大頻繁項集的挖掘.UMF-tree的構建過程與FP-tree類似,從L中的最后一個項、倒序開始(即按預計支持度從小到大的順序),將每個以頻繁1-項集為后綴的局部最大頻繁項集作為UMF-tree的一個分支,但是在插入之前需要檢查UMF-tree中是否存在某個分支已包含該項集,如果存在這樣的分支,則說明UMF-tree中存在該局部最大頻繁項集的超集,則該項集就不可能是最大頻繁項集,將其舍棄,否則,按照FP-tree的構建方式插入到UMF-tree中.對所有的局部最大頻繁項集進行如上操作,最后得到的UMF-tree即包含了所有的最大頻繁項集.
根據局部最大頻繁項集的挖掘方式以及UMF-tree的構建方式可以得出如下結論:將要插入到UMF-tree的局部最大頻繁項集,要么是UMF-tree中某個分支的子項集,要么是全局最大頻繁項集,而不會是在其之后插入的局部最大頻繁項集的子項集.這是因為,進行局部最大頻繁項集挖掘時,是從L中的最后一個項開始、倒序進行的,也就是按頻繁1-項集的預計支持度從小到大的順序進行的,這樣得到的局部最大頻繁項集是按照其后綴在L中的順序倒序排列的;而UMF-tree的構建也是從L中的最后一個項開始、倒序進行的,由局部最大頻繁項集的挖掘方法可知,先進行插入操作的局部最大頻繁項集的后綴項,肯定不會出現在之后插入的局部最大頻繁項集中,即先插入的局部最大頻繁項集不可能是后插入的局部最大頻繁項集的子項集,而只能是其超集,所以可以得出上述結論.
根據這個結論得知:UMF-tree包含且僅包含了數據庫中的所有最大頻繁項集,其每個分支即為一個最大頻繁項集.
3 實驗與分析
IBM數據生成器(IBM Quest Market-Basket Synthetic Data Generator)是數據挖掘領域常用的一種數據生成工具,本實驗中所使用的數據集也是由該數據生成器生成.我們生成的事務數據庫中共含有1 000種項,包含100k條事務,平均事務長度為10,實驗進行之前,先對每條事務中的每個項設置一個隨機概率作為該項的支持度,其范圍為 (0,1].實驗環境為CPU Intel core×2,內存2G,操作系統為LINUX,算法采用C語言編寫,算法運行時間包括CPU消耗時間及I/O時間,實驗數據均是多次測試得到的平均值.
由于目前對不確定性數據的挖掘大都集中在完全頻繁項集,而尚未發現最大頻繁項集挖掘算法,因此無法進行實驗結果的對比.我們分別設計了4個實驗來對UMF-growth算法的各項性能進行測試,包括最小支持度閾值對算法性能的影響、算法的可伸縮性、數據集的稠密情況對算法性能的影響以及同一個項名不同支持度個數對算法性能的影響,并對每個實驗的結果進行了解釋與分析.
在第一個實驗中,測試了支持度閾值對算法性能的影響,如圖1所示.UMF-growth算法的運行時間隨支持度閾值的增大而逐漸增加,這是因為,當支持度閾值較小時,最大頻繁項集長度較大,在局部最大頻繁項集挖掘過程中不用生成子項集,所以挖掘時間較少.隨著支持度閾值的增加,最大頻繁項集的長度越來越小,在局部最大頻繁項集挖掘過程中需要不斷生成這些非頻繁項集的子項集,所以挖掘時間隨支持度閾值的增加而增加.在實驗過程中發現,UMF-growth算法的時間消耗大都集中在局部最大頻繁項集的挖掘部分,而UF-tree及UMF-tree的構建時間所占比重較小,因此總體時間隨支持度閾值的增大而增加.
第二個實驗測試的是UMF-growth算法的可伸縮性.這個實驗中不僅要用到包含100KB個事務的數據集,還要用到另外9個不同規模的數據集,其規模大小為10KB,10KB,20KB,30KB,40KB,50KB,60KB,70KB,80KB和90KB.對這10個規模不同的數據集分別利用UMF-growth算法進行最大頻繁項集的挖掘,其中支持度閾值設為0.1,得到的結果如圖2所示.UMF-growth算法的運行時間隨數據庫規模的增大幾乎成線性增長,這說明UMF-growth算法具有良好的可伸縮性.
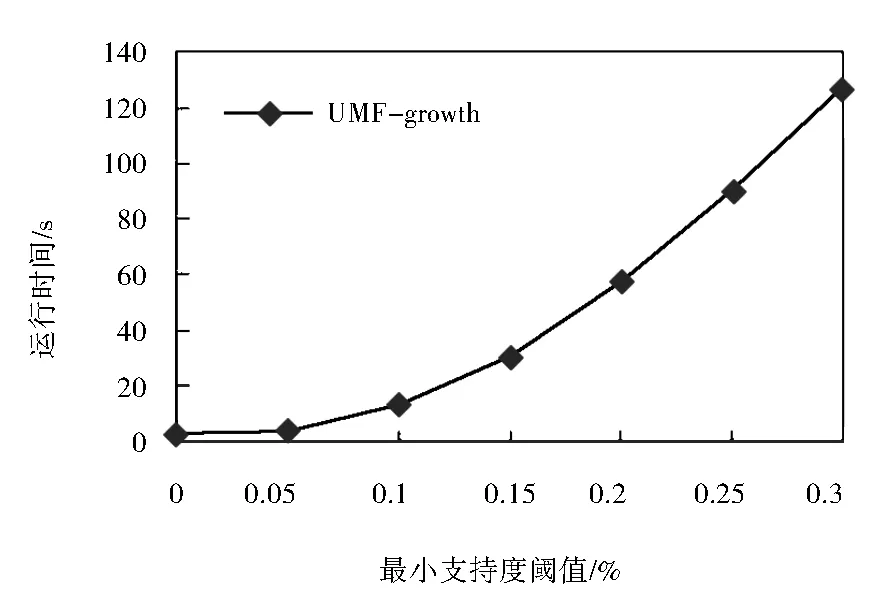
圖1 運行時間隨閾值的變化
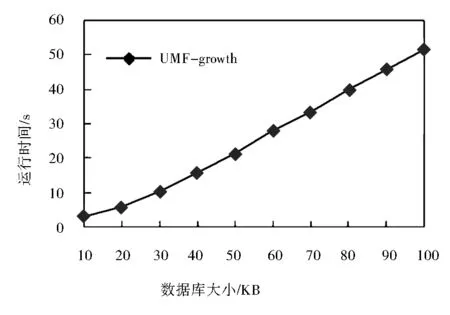
圖2 運行時間隨數據集規模的變化
第三個實驗進行了數據集稠密程度對算法性能的影響測試.一個數據集的參數主要包含項的個數、事務個數、平均事務長度以及最大頻繁項集平均長度等.若某數據集的最大頻繁項集平均長度與平均事務長度相差很小,則認為該數據集屬于稠密型,否則認為該數據集屬于稀疏型.數據集的稠密程度往往會對算法的性能產生較大影響.選取兩個稠密程度不同的數據集對UMF-growth算法的性能進行測試,觀察在不同的數據集上UMF-growth算法運行時間的大小及其隨支持度閾值的變化情況,這兩個數據集的參數如表1所示,其中D1為稀疏型數據集,D2為稠密型數據集,實驗結果如圖3所示.UMF-growth算法在D1上的運行時間總是長于在D2上的運行時間.這是因為D1屬于稀疏型數據集,其最大頻繁項集平均長度遠遠小于平均事務長度,所以在挖掘過程中總是要產生非頻繁項集的子項集,子項集的生成消耗時間較長,導致挖掘時間較長;而數據集D2屬于稠密型數據集,其最大頻繁項集的長度與平均事務長度一致,在挖掘過程中可直接得到局部最大頻繁項集,無需產生子項集,所以挖掘時間較短.通過這個實驗可以得知,UMF-growth算法特別適用于平均事務長度較短、比較稠密的數據集.

圖3 稀疏數據集VS.稠密數據集
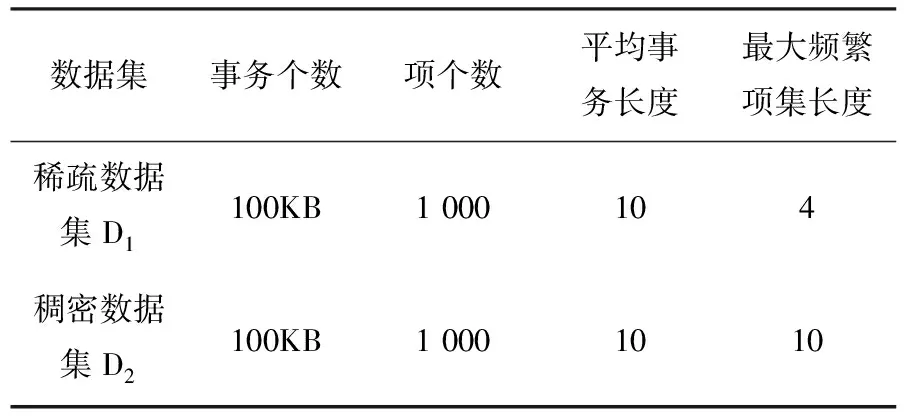
數據集事務個數項個數平均事務長度最大頻繁項集長度稀疏數據集D1100KB1 000104稠密數據集D2100KB1 0001010
在最后一個實驗中同一項名的不同支持度個數對算法性能的影響進行了測試.本實驗采用兩個規模及參數都相同的數據集,分別將其同一項名的不同支持度個數設置為較多個和較少個,對UMF-growth算法在這兩個數據集上的運行時間進行對比,實驗結果如圖4所示.由圖可知,UMF-growth算法在具有較多支持度個數的數據集上的運行時間要長于在具有較少支持度個數的數據集上的運行時間.這是因為,在構建UF-tree時我們規定,只有當項名相同且支持度相同的情況下,兩個分支才可以合并,當項名相同而支持度不同時,需要作為不同的分支插入到UF-tree中,此時UF-tree的規模會增大,UMF-growth的運行時間會增加,所以具有較少支持度個數的數據集中分支可合并的概率更大,UF-tree的規模更小,運行時間較短.
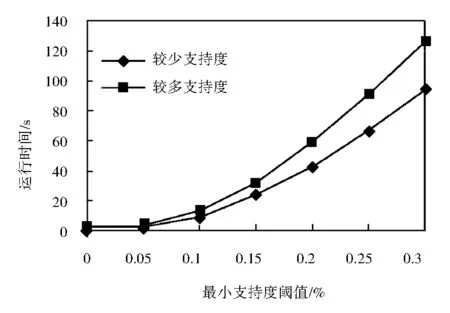
圖4 較少支持度VS.較多支持度
由以上4個實驗可知,UMF-growth算法的運行時間隨支持度閾值的增加而增加,同一項名支持度個數較少時效率較高,具有良好的可伸縮性并且特別適用于稠密型數據集.但是該算法也存在一些不足,例如在LUMF-growth步驟中需要不斷的產生非頻繁項集的子項集,當事務平均長度較大且比較稀疏時,生成子項集需占用大量內存、消耗大量時間,因此UMF-growth算法在稀疏型數據集上的效率還有待進一步提高.
4 結束語
本文提出的基于UF-tree的最大頻繁項集挖掘算法UMF-growth算法,是通過兩個步驟完成最大頻繁項集的挖掘,首先在UF-tree的基礎上獲得局部最大頻繁項集,然后將局部最大頻繁項集插入UMF-tree中獲得所有的最大頻繁項集.實驗結果證明,UMF-growth算法具有良好的可伸縮性且特別適用于稠密型數據集,尤其是那些平均事務長度較短或最大頻繁項集長度與平均事務長度接近的數據集.但是,UMF-growth算法在稀疏型數據集,特別是平均事務長度較大的數據集中效率較低,因此該算法的效率還有待進一步優化提高.
[1]Leung C K S. Mining uncertain data[J]. Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery, 2011, 1(4): 316-329.
[2]Chui C K, Kao B, Hung E. Mining frequent itemsets from uncertain data[M]. Advances in knowledge discovery and data mining.Heidelberg:Springer Berlin, 2007: 47-58.
[3]Leung C K S, Mateo M A F, Brajczuk D A. A tree-based approach for frequent pattern mining from uncertain data[M]. Advances in Knowledge Discovery and Data Mining. Heidelberg:Springer Berlin, 2008: 653-661.
[4]Leung C K, Brajczuk D A. Efficient algorithms for the mining of constrained frequent patterns from uncertain data[J]. SIGKDD Explorations, 2010, 11(2):123-130.
[5]Cuzzocrea A, Leung C K. Distributed mining of constrained frequent sets from uncertain data[C]//Algorithms and Architectures for Parallel Processing. Springer Berlin Heidelberg, 2011: 40-53.
[6]Leung C K S, Sun L. Equivalence class transformation based mining of frequent itemsets from uncertain data[C]// Proceedings of the 2011 ACM Symposium on Applied Computing. ACM, 2011: 983-984.
[7]汪金苗, 張龍波, 鄧齊志,等.不確定數據頻繁項集挖掘方法綜述[J]. 計算機工程與應用, 2011, 47(20):121-125.
[8]劉衛明,楊健,毛伊敏.基于約束的不確定數據頻繁項集挖掘算法研究[J].計算機應用研究,2012, 29(10): 3 669-3 671.
[9]王爽, 楊廣明, 朱志良.基于不確定數據的頻繁項查詢算法[J].東北大學學報:自然科學版,2011, 32(3): 344-347
猜你喜歡
作文·小學低年級(2025年2期)2025-02-13 00:00:00
小雪花·小學生快樂作文(2024年11期)2024-12-31 00:00:00
作文·小學低年級(2024年2期)2024-04-29 00:00:00
作文·小學低年級(2023年3期)2023-04-29 00:00:00
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
小主人報(2022年4期)2022-08-09 08:52:06
中學生數理化·中考版(2022年11期)2022-02-16 07:01:20
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
