基于兩階段優化算法的客戶信用評估問題研究
2013-12-23 05:24:52王興宇四川大學
商場現代化 2013年3期
關鍵詞:模型
■王興宇 四川大學
一、前言
目前,我國的信用卡業務雖然還處于發展初期,但是隨著客戶貸款數量的迅速增長,為了防范潛在風險,減少發卡機構的損失。在對客戶發放信用卡之前,對其進行信用評估已成為解決客戶信用風險的重要方法之一。決策樹是基于統計理論的非參數識別技術,可以自動進行變量選擇,降低維數,分類結果表達形式簡單易懂,并可有效的用于對數據的處理,所以被廣泛應用于數據挖掘的分類當中。但對于現實的信用評估問題,由于客戶的信息量大、屬性多,單獨使用決策樹易造成運算過程復雜。這就需要在建立決策樹之前刪除多余的屬性,然后再用決策樹進行分類。本文利用澳大利亞銀行的數據研究信用評估問題,在建立決策樹之前,采用GMDH輸入輸出模型先挑選中對分類結果影響較重要的屬性,然后再利用決策樹進行分類,以達到對決策樹優化的效果。
二、相關模型方法概述
1. GMDH輸入輸出模型
數據分組處理算法(Group Method of Data Handling)是烏克蘭科學院A.G.Ivakhnenko在1967年首次提出的。GMDH作為一種自動產生模型的算法,它使用的是演化(遺傳、變異和選擇)的原則,實現一個模型結構綜合和模型確認的自動化過程,模型從數據中自動產生,以最優的傳遞函數網絡的形式,重復產生大量具有增長復雜度的競爭模型。進行相應的模型確認并留下最好的選擇,直到產生一個最優復雜度模型。
GMDH方法有兩個基本思想:(1)以黑箱方法為主要方法分析輸入輸出關系;(2)用基本函數的網絡互聯來表達復雜函數。它從參考函數構成的初始模型(函數)集合出發,按一定的法則產生新的中間候選模型(遺傳、變異),再經過篩選(選擇),重復這樣一個遺傳、變異、選擇和進化的過程,使中間候選模型的復雜度不斷增加,直至得到最優復雜度模型。
2.決策樹理論
決策樹是一種類似于流程圖的樹結構,起源于20世紀70年代后期和80年代初期,由J.Ross Quinlan提出了ID3算法,這種算法使用貪心方法,以自頂向下的遞歸的分治方式構造,將數據從根節點向下逐步劃分,在內部節點上進行屬性的比較,訓練集即被遞歸地劃分為子集,最后形成分類的規則。比較經典的決策樹算法有基于信息熵的ID3算法及能處理連續屬性的C4.5算法。
ID3算法計算每個屬性的信息增益,并選取具有最高增益的屬性作為給定集合的測試屬性。對被選取的測試屬性創建一個節點,并以該節點的屬性標記,對該屬性的每個值創建一個分支并以此來劃分樣本。C4.5算法是對ID3算法的改進,ID3處理的是離散的屬性,而C4.5算法能處理連續的屬性,并在以下幾方面對ID3算法進行了改進:(1)用信息增益率來選擇屬性,克服了用信息增益選擇屬性時偏向選擇取值多的屬性的不足;(2)在樹構造過程中進行剪枝;(3)能夠完成對連續屬性的離散化處理;(4)能夠對不完整數據進行處理。
三、兩階段優化算法模型及算法步驟
針對信用評估這一實際問題,本文將特征提取與決策樹結合起來構建算法模型,以達到對決策樹的優化。第一階段:先用GMDH特征提取方法對原有屬性進行篩選,從中抽取對結果影響較大的屬性;第二階段:用提取出的屬性建立決策樹模型,具體操作步驟如下:

(2)用K-G多項式建立因變量(輸出)和自變量(輸入)之間的一般關系,例如對于三輸入單輸出系統,可采取二次K-G多項式


(3)從具有外補充性質的選擇準則中選出一個(或若干個)作為目標函數(體系),或稱為外準則(體系),產生第一層中間模型。同時在訓練集A上估計參數,對第一層中間模型進行篩選。根據外準則,在檢測集B上對第一層中間模型進行篩選,選出的中間模型作為網絡第二層的輸入變量;
(4)形成最優復雜度模型網絡結構。重復步驟3,可依次產生第二、第三…層中間模型,最終形成可用于分析的顯式最優復雜度模型。即得出與輸出變量最相關的幾個輸入變量,假設為xi,xj,…xn;
(5)計算xi,xj,…,xn的信息增益率,以信息增益率最大的屬性作為根節點的測試屬性,對屬性的值創建分支,據此劃分樣本;
(6)在各節點內計算剩余屬性的信息增益率,選擇信息增益率最大的屬性作為此分支的下一個測試屬性,重復此步驟直到結點屬性各分支下的訓練樣本屬于同一類或者所有屬性都已被用過為止生成決策樹。
四、實證研究
1.樣本及變量選擇
為了驗證本文所提方法的效果,本文采用了澳大利亞一家銀行的信貸數據作為初始建模樣本,共690條數據(已做預處理)。我們選取了14個類屬性,1個決策屬性,并對其做了相應的調整,例如A4最初有三個標簽屬性p、g、gg,這些標簽被改為1、2、3。各類屬性的詳細信息如表1所示:
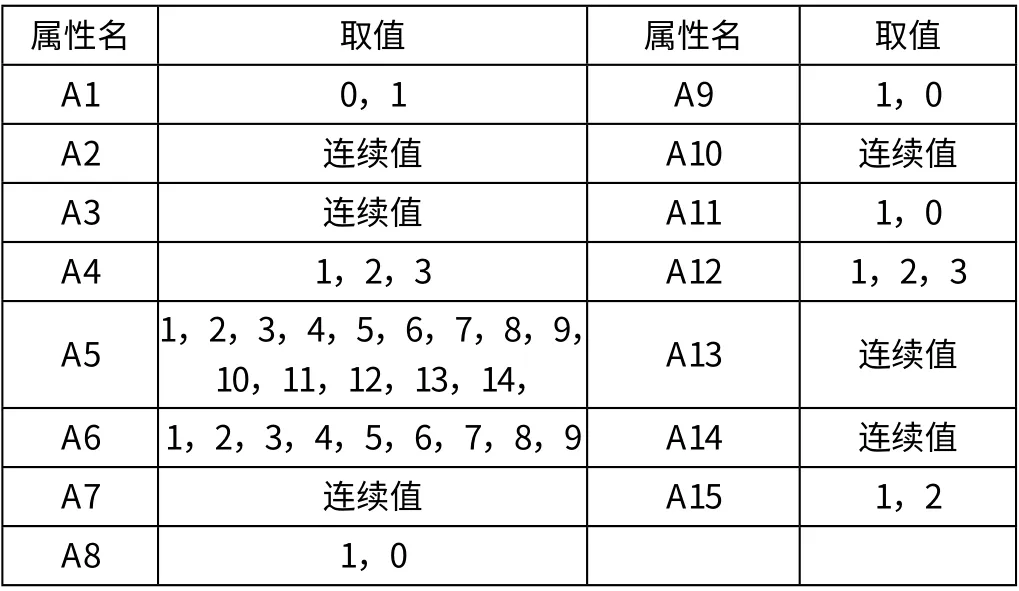
表1
2.實證結果分析
用GMDH輸入輸出模型對原有屬性進行提取之后還剩下屬性A5,A8,A9。在此基礎上運用C4.5算法得到最優樹如圖1所示:

同時本文也將使用特征提取前C4.5算法的精確度與使用特征提取后C4.5算法的精確度進行了對比,如表2所示。

表2
在信用評估這一實際問題中,銀行誤貸款給信用不好的客戶給企業帶來的損失遠遠大于拒絕貸款給信用好的客戶所帶來的損失。因此我們可以從兩方面來評價算法的準確度,一是總的錯判率,二是把不好的客戶誤判為好客戶的錯判率,從表2可以看出,在這兩方面,GMDH輸入輸出模型與決策樹相結合的算法比單獨使用決策樹算法的錯判率都低,即前者具有更高的預測精確度。
五、結論
本文采用的GMDH輸入輸出模型對客戶的屬性進行了篩選,選出了對客戶分類結果影響較大的屬性,達到了對決策樹優化的效果,有效的降低了算法的復雜度,簡化了整個決策樹的構造。
[1] Xu Peng,Lin Shen.Internet traffic classification using C4.5 decision tree.Journal of Software,2009,20(10):2692-2704.
[2]黃穎,周云軒,吳穩.基于決策樹模型的上海城市濕地遙感提取與分類[J].吉林大學學報,2009,39(6):1156-1162.
[3]黃愛輝.決策樹C4.5算法的改進及應用[J].科學技術與工程,2009,9(1):34-36.
[4]崔健.商業銀行個人信用風險評價[D]天津:天津大學管理學院,2005.06.
[5]Pan-ning Tan.Michael Steinbach.Vipin Kumar.數據挖掘導論[M].人民郵電出社.2006:181.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
