語(yǔ)義網(wǎng)環(huán)境下數(shù)字圖書館信息資源集成模型研究
2014-01-13 02:31:17劉衛(wèi)寧
圖書館理論與實(shí)踐 2014年1期
劉衛(wèi)寧
(中南民族大學(xué)民族學(xué)與社會(huì)學(xué)學(xué)院,武漢430074)
語(yǔ)義網(wǎng)環(huán)境下數(shù)字圖書館信息資源集成模型研究
劉衛(wèi)寧
(中南民族大學(xué)民族學(xué)與社會(huì)學(xué)學(xué)院,武漢430074)
語(yǔ)義網(wǎng);數(shù)字圖書館;信息集成
語(yǔ)義網(wǎng)環(huán)境下數(shù)字信息呈現(xiàn)多樣性、異構(gòu)性等特點(diǎn),造成了大量冗余信息的產(chǎn)生,這些信息資源關(guān)聯(lián)度低,語(yǔ)義異構(gòu)問(wèn)題嚴(yán)重,影響了用戶獲取信息的體驗(yàn)和效率。本文為了提高數(shù)字圖書館信息資源集成的質(zhì)量,運(yùn)用有關(guān)語(yǔ)義網(wǎng)的方法和技術(shù)實(shí)現(xiàn)語(yǔ)義網(wǎng)環(huán)境下數(shù)字信息資源的整合、集成,并提出了模型框架,在本質(zhì)上改變現(xiàn)有整合方式的缺陷和不足。
1 引言
互聯(lián)網(wǎng)的普及、信息資源的數(shù)字化、信息系統(tǒng)的虛擬化,信息的獲取日益方便、簡(jiǎn)單和全面,使得用戶能夠比以前更加快捷地查找和獲取所需的信息,導(dǎo)致了信息服務(wù)的“非中介化”。[1]加上Web2.0概念的普及,許多Web2.0應(yīng)用包括博客、微博、社交網(wǎng)站、社區(qū)論壇、維基和視頻/音樂(lè)/圖像分享網(wǎng)站等進(jìn)入人們的視野,用戶原創(chuàng)內(nèi)容(User Generated Content,UGC)網(wǎng)站吸引了眾多用戶,普通用戶的角色開始轉(zhuǎn)變,從信息用戶變成了信息創(chuàng)造者,提供了大量有價(jià)值的信息。人類真正步入了信息大爆炸時(shí)代。對(duì)海量數(shù)字信息資源進(jìn)行充分的整合、集成,可大大提高用戶使用信息的效率。數(shù)字圖書館正是在這樣的背景下應(yīng)運(yùn)而生,并成為評(píng)價(jià)一個(gè)國(guó)家信息基礎(chǔ)設(shè)施水平的重要標(biāo)志。
2 語(yǔ)義網(wǎng)環(huán)境下數(shù)字圖書館信息資源集成模型
數(shù)字圖書館是基于分布式網(wǎng)絡(luò)存在的系統(tǒng),從分布在不同地理位置的數(shù)據(jù)庫(kù)中抽取元數(shù)據(jù),建立元數(shù)據(jù)庫(kù),同時(shí)對(duì)元數(shù)據(jù)庫(kù)中的信息進(jìn)行組織和加工,建立不同領(lǐng)域的本體庫(kù),促進(jìn)多領(lǐng)域之間的交流和合作,從而實(shí)現(xiàn)分布式異構(gòu)數(shù)字信息資源的集成。語(yǔ)義網(wǎng)環(huán)境下實(shí)現(xiàn)了對(duì)信息資源和它們之間的語(yǔ)義關(guān)系的描述,呈現(xiàn)數(shù)字圖書館信息資源的關(guān)聯(lián)關(guān)系和層次體系,統(tǒng)一標(biāo)識(shí)不同類型的數(shù)字化與非數(shù)字化資源。通過(guò)統(tǒng)一的元數(shù)據(jù)標(biāo)準(zhǔn)描述和組織信息,當(dāng)信息資源增長(zhǎng)的時(shí)候自動(dòng)更新和改善領(lǐng)域本體庫(kù),實(shí)現(xiàn)了信息的語(yǔ)義推理功能,解決信息的語(yǔ)義異構(gòu)問(wèn)題。語(yǔ)義網(wǎng)環(huán)境下,以信息用戶的需求為導(dǎo)向,將語(yǔ)義技術(shù)的優(yōu)勢(shì)融入數(shù)字圖書館信息資源集成模型的構(gòu)建過(guò)程中去,使信息用戶獲取和利用信息的過(guò)程與數(shù)字圖書館信息資源集成的流程保持一致,為數(shù)字圖書館信息資源集成模型研究提供了一種新的思路。
有學(xué)者提過(guò)基于元數(shù)據(jù)的信息資源集成模型,引入本體技術(shù)后又有人提出了基于本體和多Agent的信息資源集成模型,諸如此類的模型很多,但是實(shí)際操作性并不強(qiáng)。要么模型過(guò)于抽象,不易把握;要么功能模塊過(guò)于透明,不易擴(kuò)展。因此,為了更好地解決信息資源集成問(wèn)題,本文充分考慮模型的設(shè)計(jì)目標(biāo),遵循模型的設(shè)計(jì)原則和要求,參照Tim Berners-Lee提出的語(yǔ)義網(wǎng)結(jié)構(gòu)層次模型,探討語(yǔ)義網(wǎng)技術(shù)的特點(diǎn)及其在信息資源集成中的作用,提出了一種新的數(shù)字圖書館信息資源集成模型,該模型共五層,分別是數(shù)據(jù)源層、信息描述和組織層、語(yǔ)義整合層、資源存儲(chǔ)層和用戶交互層,如圖1所示。
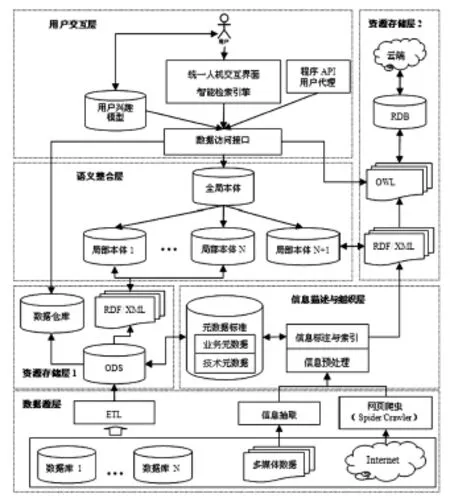
圖1 語(yǔ)義網(wǎng)環(huán)境下數(shù)字圖書館信息資源集成模型
該模型在獲取數(shù)字圖書館信息資源的基礎(chǔ)上制定元數(shù)據(jù)標(biāo)準(zhǔn),使用RDF描述信息,引入語(yǔ)義網(wǎng)中的本體技術(shù)構(gòu)建全局模式,通過(guò)RDF/RDFS和OWL賦予信息語(yǔ)義,為了提高本體的語(yǔ)義表達(dá)能力,在語(yǔ)義整合層加入語(yǔ)義規(guī)則,實(shí)現(xiàn)本體的一致性檢測(cè)和語(yǔ)義推理,[2]保證本體的準(zhǔn)確性,然后運(yùn)用數(shù)據(jù)倉(cāng)庫(kù)和本體存儲(chǔ)技術(shù)將數(shù)字信息資源統(tǒng)一存儲(chǔ)在云端,使整合后的信息可以為用戶提供更加優(yōu)質(zhì)的服務(wù)。由于信息包括結(jié)構(gòu)化、半結(jié)構(gòu)化和非結(jié)構(gòu)化信息,在數(shù)據(jù)獲取層需要將非結(jié)構(gòu)化信息和半結(jié)構(gòu)化信息先轉(zhuǎn)化為結(jié)構(gòu)化信息。為了實(shí)現(xiàn)信息的標(biāo)準(zhǔn)化描述,在信息描述和標(biāo)準(zhǔn)化層需要制定統(tǒng)一的元數(shù)據(jù)標(biāo)準(zhǔn),參照元數(shù)據(jù)標(biāo)準(zhǔn),將數(shù)據(jù)獲取層的信息同時(shí)存儲(chǔ)在RDF/XML文件和數(shù)據(jù)庫(kù)中,在語(yǔ)義整合層構(gòu)建全局本體,為每個(gè)數(shù)據(jù)源分別構(gòu)建局部本體,局部本體的構(gòu)建需要領(lǐng)域?qū)<业膮⑴c和完善,在局部本體與全局本體之間建立映射關(guān)系,創(chuàng)建映射規(guī)則庫(kù),解決語(yǔ)義異構(gòu)問(wèn)題。將RDF和OWL本體中的信息存儲(chǔ)在數(shù)據(jù)庫(kù)中,經(jīng)過(guò)ETL后把所有信息可以暫時(shí)存儲(chǔ)在ODS(Operational Data Store)中,進(jìn)一步存儲(chǔ)在數(shù)據(jù)倉(cāng)庫(kù)中,通過(guò)統(tǒng)一人機(jī)交互界面接入數(shù)據(jù)訪問(wèn)接口,根據(jù)不同的需求訪問(wèn)不同存儲(chǔ)形式的信息資源(包括數(shù)據(jù)庫(kù)、數(shù)據(jù)倉(cāng)庫(kù)和RDF/OWL文件),實(shí)現(xiàn)語(yǔ)義檢索功能,針對(duì)不同的使用目的向用戶提供個(gè)性化、專業(yè)化和智能化的協(xié)同檢索和推薦服務(wù);智能檢索引擎既能夠訪問(wèn)數(shù)據(jù)庫(kù)和數(shù)據(jù)倉(cāng)庫(kù),也能夠遍歷RDF/XML和OWL文件中的信息。
3 語(yǔ)義網(wǎng)環(huán)境下數(shù)字圖書館信息資源集成模型構(gòu)建過(guò)程
3.1 數(shù)字圖書館用戶興趣模型的表示
為了滿足用戶的信息需求和興趣偏好,本文提出的模型需要收集用戶基本信息,構(gòu)建數(shù)字圖書館用戶興趣本體庫(kù),通過(guò)用戶興趣本體表示用戶的興趣偏好,采用動(dòng)態(tài)機(jī)器學(xué)習(xí)機(jī)制獲取用戶興趣概念。[3]根據(jù)用戶主動(dòng)提供的信息以及系統(tǒng)對(duì)用戶行為的挖掘和分析(包括分析用戶的Web訪問(wèn)日志和緩存信息),運(yùn)用挖掘算法分析用戶的興趣需求,建立高質(zhì)高效的用戶興趣模型,如圖2所示。根據(jù)用戶的實(shí)際選擇和反饋信息對(duì)已經(jīng)建立的用戶興趣模型進(jìn)行修正,確保用戶興趣模型能夠自我更新和不斷完善,從而使得最終的用戶興趣模型能全面而準(zhǔn)確地反映用戶的興趣。系統(tǒng)按照初步建立的模型把檢索到的信息推薦給用戶,根據(jù)用戶模型對(duì)文本進(jìn)行預(yù)處理后形成的關(guān)鍵詞集合進(jìn)行過(guò)濾,同時(shí)發(fā)掘具有共同興趣的用戶群,為數(shù)字圖書館用戶提供個(gè)性化、專業(yè)化和智能化的協(xié)同檢索和推送服務(wù)。
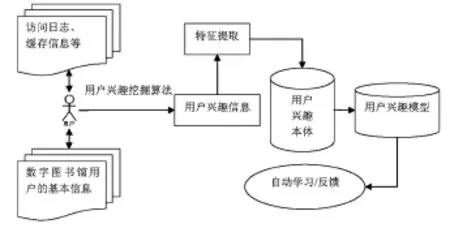
圖2 數(shù)字圖書館用戶興趣模型的構(gòu)建過(guò)程
用戶興趣模型描述了用戶的興趣偏好,同時(shí)根據(jù)用戶對(duì)信息的反饋和評(píng)價(jià),更新用戶模型,從而更新知識(shí)產(chǎn)品。構(gòu)建用戶興趣模型需要分析用戶獲取信息的方式,借助領(lǐng)域本體準(zhǔn)確、規(guī)范地描述用戶感興趣的信息,建立用戶興趣挖掘模型,向用戶提供所需的信息。數(shù)字圖書館用戶興趣挖掘運(yùn)用適當(dāng)?shù)耐诰蛩惴ǎ?jì)算分析用戶瀏覽網(wǎng)頁(yè)時(shí)留下的日志記錄信息,發(fā)現(xiàn)用戶感興趣的內(nèi)容。
用戶訪問(wèn)數(shù)字圖書館會(huì)產(chǎn)生日志記錄文件,包括訪問(wèn)日志、引用日志、代理日志和錯(cuò)誤日志等。日志文件中記錄了大量的用戶訪問(wèn)信息,包括用戶的ⅠP地址、訪問(wèn)時(shí)間、瀏覽頁(yè)面URL、請(qǐng)求方式和字節(jié)數(shù)等,還有網(wǎng)站服務(wù)器接受、處理請(qǐng)求以及運(yùn)行錯(cuò)誤等多種信息。通過(guò)挖掘相關(guān)的Web日志記錄,可以發(fā)現(xiàn)用戶訪問(wèn)Web頁(yè)面的模式;通過(guò)分析日志中的記錄規(guī)律,可以識(shí)別用戶的忠誠(chéng)度、喜好、滿意度,發(fā)現(xiàn)潛在用戶,改進(jìn)服務(wù)效果,提高服務(wù)競(jìng)爭(zhēng)力。通過(guò)用戶提供的信息,結(jié)合用戶的瀏覽行為和訪問(wèn)日志獲得用戶的偏好,利用本體庫(kù)中的相應(yīng)概念表示用戶模型,根據(jù)模型將符合條件的內(nèi)容推薦給用戶,并在相關(guān)反饋的基礎(chǔ)上改進(jìn)用戶模型。
3.2 數(shù)字圖書館領(lǐng)域本體的構(gòu)建
領(lǐng)域本體庫(kù)包含著一個(gè)領(lǐng)域中最基本的概念、概念的定義以及各個(gè)概念之間的語(yǔ)義關(guān)系網(wǎng)絡(luò),它在整個(gè)語(yǔ)義檢索過(guò)程中起著非常重要的作用。領(lǐng)域本體確定了該領(lǐng)域內(nèi)普遍認(rèn)同的確切概念,通過(guò)對(duì)概念之間的關(guān)系進(jìn)行語(yǔ)義描述,使用戶與機(jī)器之間的交流上升到語(yǔ)義層次。用戶在進(jìn)行查詢時(shí)會(huì)調(diào)用領(lǐng)域本體庫(kù),從中找出與關(guān)鍵詞相對(duì)應(yīng)的概念所在的領(lǐng)域,將該領(lǐng)域下的相關(guān)概念提供給用戶,幫助用戶生成更精確地查詢,提高查詢效率;領(lǐng)域本體的構(gòu)建方法如圖3所示。
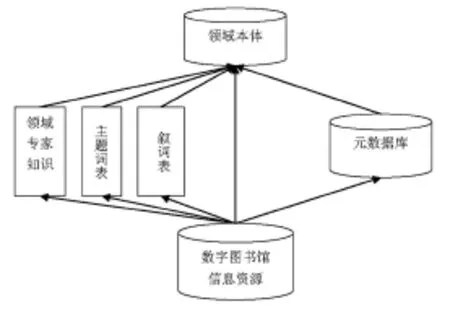
圖3 領(lǐng)域本體構(gòu)建
Noy和Hafner提出了本體構(gòu)建的七個(gè)步驟:確定領(lǐng)域和范圍;重用現(xiàn)有本體是否可行;列出本體中的重要術(shù)語(yǔ)和主題詞;定義類和類的繼承關(guān)系;定義屬性和關(guān)系;定義屬性的限制;構(gòu)建具體實(shí)例。[4]
領(lǐng)域本體庫(kù)構(gòu)建完成之后,運(yùn)用SWRL和描述邏輯對(duì)構(gòu)建的領(lǐng)域本體進(jìn)行推理得出隱含的信息,同時(shí)完成一致性檢測(cè)。例如,在某領(lǐng)域本體庫(kù)中,許多概念具有交叉相關(guān)性,因此,在構(gòu)建本體過(guò)程中,需要定義概念之間的邏輯關(guān)系,使用推理機(jī)制完成概念相互關(guān)系的說(shuō)明,避免概念的重復(fù)構(gòu)建,保持概念應(yīng)有的邏輯關(guān)系。領(lǐng)域本體庫(kù)的構(gòu)建不是一勞永逸的,因?yàn)閿?shù)字圖書館信息資源是動(dòng)態(tài)變化的。因此,必須根據(jù)數(shù)字圖書館信息資源的變化及時(shí)調(diào)整和更新已經(jīng)構(gòu)建的本體,維持領(lǐng)域本體在整個(gè)系統(tǒng)中的作用,不斷適應(yīng)用戶的需求。需要利用推理機(jī)對(duì)本體進(jìn)行預(yù)處理以消除沖突,選擇利用Racer推理機(jī)來(lái)對(duì)本體的概念和實(shí)例進(jìn)行層次分類和調(diào)整,消除本體內(nèi)部不一致性沖突,從而形成一個(gè)完整、有效的OWL知識(shí)庫(kù)。從OWL本體和SWRL規(guī)則庫(kù)到Jess事實(shí)庫(kù)和規(guī)則庫(kù),要經(jīng)過(guò)事實(shí)轉(zhuǎn)換和規(guī)則轉(zhuǎn)換。由于Jess推理機(jī)不能識(shí)別OWL格式的本體和SWRL格式的規(guī)則,所以在進(jìn)行推理之前,要對(duì)OWL本體和SWRL規(guī)則進(jìn)行轉(zhuǎn)換。Jess推理引擎是推理過(guò)程的核心部分,它基于事實(shí)庫(kù)和規(guī)則庫(kù)進(jìn)行推理,從而得出新的事實(shí)。然后,將新的事實(shí)添加進(jìn)原來(lái)的本體中,令原本體中隱含的語(yǔ)義關(guān)聯(lián)得到顯性化,從而為數(shù)字信息資源的智能檢索、個(gè)性化推送等功能打下基礎(chǔ)。
常用的規(guī)則推理引擎有Jess、CLⅠPS、Prolog等,而目前還沒(méi)有專門針對(duì)SWRL的推理引擎。Jess(Java Expert System Shell)由推理機(jī)、事實(shí)庫(kù)和規(guī)則庫(kù)三部分構(gòu)成,支持正向推理和后向推理。盡管Jess不支持基于OWL的本體和基于SWRL的規(guī)則,但是我們可以將OWL本體和SWRL規(guī)則轉(zhuǎn)換成Jess推理引擎能夠識(shí)別的格式。基于SWRL的本體推理過(guò)程如圖4所示。
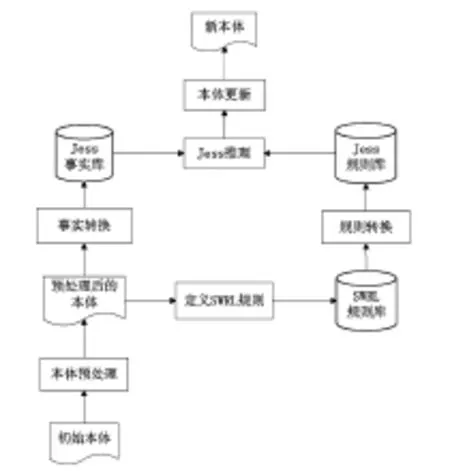
圖4 基于SWRL的推理
利用領(lǐng)域本體對(duì)數(shù)字信息資源進(jìn)行標(biāo)引,即對(duì)文檔集進(jìn)行內(nèi)容抽取并分析特征詞,建立概念集之間的關(guān)聯(lián),形成具有語(yǔ)義關(guān)聯(lián)的知識(shí)庫(kù)。本體提供了學(xué)科領(lǐng)域的概念、概念之間的關(guān)聯(lián)以及領(lǐng)域的核心理論,可以通過(guò)本體將信息資源組織成具有網(wǎng)狀結(jié)構(gòu)的、可共享的知識(shí)結(jié)構(gòu)體系,表達(dá)顯性和隱性的語(yǔ)義信息。這樣文獻(xiàn)資源能夠被更好地組織和劃分,概念間的語(yǔ)義關(guān)聯(lián)也能被精確定義,為實(shí)現(xiàn)知識(shí)推理和智能化檢索提供了鋪墊。借助領(lǐng)域本體對(duì)信息集合進(jìn)行語(yǔ)義分析與標(biāo)注后,形成具有語(yǔ)義關(guān)聯(lián)的資源元數(shù)據(jù)集合,然后存入本體知識(shí)庫(kù)。
3.3 數(shù)字圖書館元數(shù)據(jù)描述框架
對(duì)數(shù)字圖書館不同數(shù)據(jù)源的元數(shù)據(jù)信息分別進(jìn)行提取,借助XML/RDF文檔加以組織,在無(wú)人工干預(yù)的情況下,參照原有的數(shù)字圖書館元數(shù)據(jù)標(biāo)準(zhǔn)重新定義,提取不同的應(yīng)用模式,并存儲(chǔ)在元數(shù)據(jù)庫(kù)中。由于RDF模式(RDFS)具有開放性,用戶可以自行定義和擴(kuò)展RDF模式,通過(guò)XML/RDF對(duì)信息資源進(jìn)行無(wú)二義性的描述。為了保護(hù)現(xiàn)有的數(shù)字圖書館信息資源,充分挖掘數(shù)字信息資源,數(shù)字圖書館適宜采用多種元數(shù)據(jù)標(biāo)準(zhǔn)并存的方法。
可行的方案是以Dublin Core元數(shù)據(jù)為核心元數(shù)據(jù)庫(kù),多種對(duì)應(yīng)于不同資源類型的元數(shù)據(jù)方案并存,并以基于XML語(yǔ)法的RDF/RDFS語(yǔ)言將它們封裝在一起,使基于該模型的元數(shù)據(jù)資源能夠?yàn)闄C(jī)器所理解,如圖5所示。
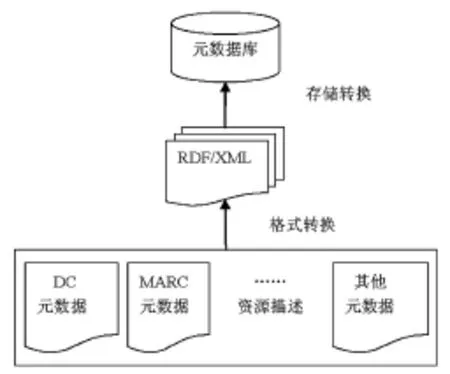
圖5 數(shù)字圖書館元數(shù)據(jù)描述框架
該元數(shù)據(jù)描述框架是一個(gè)靈活可擴(kuò)展的元數(shù)據(jù)方案,主要是利用RDF將多種不同類型的元數(shù)據(jù)進(jìn)行封裝,既充分保留和利用了數(shù)字圖書館中原有的元數(shù)據(jù)信息,也確保了對(duì)不同類型的資源性元數(shù)據(jù)描述。此外,RDF具有開放、標(biāo)準(zhǔn)和統(tǒng)一的特性,為將來(lái)數(shù)字圖書館信息資源的遷移奠定了良好的基礎(chǔ)。由于不同類型的元數(shù)據(jù)集合之間往往需要進(jìn)行互操作以完成應(yīng)用需求,定義一個(gè)統(tǒng)一的元數(shù)據(jù)庫(kù)是十分必要的,有利于實(shí)現(xiàn)不同元數(shù)據(jù)集之間的轉(zhuǎn)換和映射。
3.4 數(shù)字圖書館信息資源存儲(chǔ)平臺(tái)的搭建
數(shù)字信息資源的存儲(chǔ)需要搭建一個(gè)云計(jì)算平臺(tái),將所有信息存儲(chǔ)在云端,數(shù)據(jù)倉(cāng)庫(kù)和本體存儲(chǔ)技術(shù)實(shí)現(xiàn)了資源的云存儲(chǔ),云存儲(chǔ)是一個(gè)以數(shù)據(jù)存儲(chǔ)和管理為核心的云計(jì)算系統(tǒng)。通過(guò)云計(jì)算機(jī)技術(shù)存儲(chǔ)整合后的信息,能夠?yàn)橛脩籼峁└觾?yōu)質(zhì)高效的服務(wù)。
數(shù)據(jù)庫(kù)中的信息通過(guò)抽取、清洗和轉(zhuǎn)換等ETL過(guò)程存儲(chǔ)在ODS、數(shù)據(jù)集市和數(shù)據(jù)倉(cāng)庫(kù)中,可以根據(jù)需要進(jìn)行多次數(shù)據(jù)處理;多媒體文件存儲(chǔ)在多媒體資源庫(kù);網(wǎng)絡(luò)信息資源在預(yù)處理后參照元數(shù)據(jù)標(biāo)準(zhǔn)存儲(chǔ)在本體中,表現(xiàn)形式為XML、RDF和OWL文件,RDF信息最為直觀,XML其次,OWL最為復(fù)雜,進(jìn)一步可以將這些文件中的信息存儲(chǔ)在數(shù)據(jù)倉(cāng)庫(kù)。通過(guò)開源框架可以進(jìn)行本體存儲(chǔ),常用的有Jena和Sesame。如果是使用Oralce這樣的支持語(yǔ)義功能的數(shù)據(jù)庫(kù),則需要將RDF/XML和OWL文件先轉(zhuǎn)換為N-triples格式才能存儲(chǔ)。
4 結(jié)語(yǔ)
本文探討了語(yǔ)義網(wǎng)技術(shù)在數(shù)字圖書館信息資源集成中的作用,并運(yùn)用語(yǔ)義網(wǎng)技術(shù)解決了數(shù)字圖書館信息資源集成中的信息表示和語(yǔ)義異構(gòu)問(wèn)題,提出了一種基于語(yǔ)義網(wǎng)技術(shù)的數(shù)字圖書館信息資源集成模型。該模型具有很強(qiáng)的可操作性,各個(gè)層次完成相應(yīng)的工作,通過(guò)層與層之間的接口緊密結(jié)合,從而實(shí)現(xiàn)數(shù)字圖書館信息資源的整合,旨在為用戶提供更加優(yōu)質(zhì)的個(gè)性化服務(wù)。考慮到數(shù)字圖書館信息資源的多樣性、復(fù)雜性、海量數(shù)據(jù)和個(gè)性化等特點(diǎn),該模型力求抽象,為進(jìn)一步的完善和擴(kuò)展打下基礎(chǔ)。
[1]張曉林.走向知識(shí)服務(wù)——尋找新世紀(jì)圖書情報(bào)工作的生長(zhǎng)點(diǎn)[J].中國(guó)圖書館學(xué)報(bào),2000(5):32-37.
[2]唐曉波,金鐘鳴.基于本體與規(guī)則的語(yǔ)義推理研究[J].情報(bào)學(xué)報(bào),2011,30(7):695-703.
[3]左暉,等.個(gè)性化知識(shí)服務(wù)中基于Ontology的用戶興趣挖掘研究[J].情報(bào)學(xué)報(bào),2008,27(1): 18-23.
[4]NoyN,HafnerC.The stateoftheartinontologydesign[J].AⅠMagazine,1997,18(3):53-74.
G250.76
A
1005-8214(2014)01-0086-04
劉衛(wèi)寧(1975-),男,漢族,山東棗莊人,中南民族大學(xué)民族學(xué)與社會(huì)學(xué)學(xué)院博士生。
2012-09-27[責(zé)任編輯]王鈞梅
猜你喜歡
吉林廣播電視大學(xué)學(xué)報(bào)(2021年4期)2022-01-14 02:35:48
作文成功之路·小學(xué)版(2020年5期)2020-06-11 12:48:26
開放教育研究(2020年2期)2020-03-31 01:54:14
小天使·一年級(jí)語(yǔ)數(shù)英綜合(2018年11期)2018-11-23 09:47:26
小太陽(yáng)畫報(bào)(2018年1期)2018-05-14 17:19:25
資源再生(2017年3期)2017-06-01 12:20:59
少年博覽·小學(xué)低年級(jí)(2016年10期)2016-11-24 06:48:23
現(xiàn)代語(yǔ)文(2016年21期)2016-05-25 13:13:44
漫畫月刊·炫版(2015年4期)2015-05-27 07:52:10
大連民族大學(xué)學(xué)報(bào)(2015年2期)2015-02-27 08:28:11
