大數據環境下高校圖書館個性化信息服務系統研究
2014-02-28 14:45:26欒旭倫
圖書館學刊 2014年8期
欒旭倫
(淮陰師范學院圖書館,江蘇 淮安 223300)
大數據環境下高校圖書館個性化信息服務系統研究
欒旭倫
(淮陰師范學院圖書館,江蘇 淮安 223300)
針對當前高校圖書館個性化信息服務的不足,分析了大數據環境下高校圖書館建立個性化信息服務系統的可行性,構建了高校圖書館個性化信息服務系統模型,并對模型的功能進行了闡述。
大數據環境 個性化信息服務 數據挖掘 高校圖書館
近年來,國內高校圖書館致力于個性化信息服務的開展,作為信息定向明確、服務針對性強、使用便捷的一種新興服務模式,它的深入推廣受到了高校師生的廣泛好評。隨著個性化信息服務的大范圍推廣,如何根據用戶不斷變化的信息需求情境,實時調整信息服務策略,更好地體現信息服務的“個性化”特征成為個性化信息服務發展亟待解決的問題。
1 個性化信息服務的發展瓶頸
感知用戶真實的信息需求情境是開展個性化信息服務的前提。目前,在個性化信息服務過程中,各高校圖書館通行的做法是通過問卷調查、網絡訪談、電話咨詢等途徑事前獲知用戶的信息需求,通過對獲得的用戶需求信息進行分析,進而由學科館員或參考館員針對相應的信息需求開展獨具特色的相關服務。受用戶不斷變化的信息需求等因素的制約,傳統的個性化信息服務模式存在明顯不足。
1.1 無從感知用戶真實的信息情境
傳統的個性化信息服務模式在獲取用戶信息需求時大都以問卷調查或訪談為主,這些傳統的信息需求獲取模式受問卷調查表設計缺陷、用戶表達不清、擔憂網絡訪談泄露自身隱私等因素的限制,使得高校圖書館獲取的用戶信息需求往往存在一定偏差,在不真實的信息需求基礎上開展個性化信息服務勢必難以取得理想的效果[1]。
1.2 服務針對性有所缺失
高校圖書館的服務對象主要是在校師生。受師生的教學進度、研究任務不斷變化等相關因素的影響,個性化信息要取得良好的使用效益,必須及時根據用戶不斷變化的信息需求情境實時調整服務策略。然而受時間局限性、頻繁溝通的不便等各種因素的制約,日常服務中,師生往往無法做到或不愿向圖書館員來反映自己已經變化了的信息需求,因無從實時感知用戶變化了的信息需求,導致高校圖書館所提供的個性化信息服務與用戶的信息需求存在嚴重脫節,服務針對性較差。
1.3 個性化信息服務遭遇用戶流失危機
互聯網環境下成長起來的“90后”大學生,自身掌握了豐富的互聯網使用經驗,他們對圖書館的依賴性有所降低,受圖書館信息服務針對性不強、信息使用不便等因素影響,當有信息需求時他們首先想到的是百度、谷歌、SNS、互聯網好友圈等途徑而非求助圖書館[2]。一方面,高校圖書館掌握了豐富的館藏資源,希望通過個性化信息服務方式為資源找到使用者;另一方面,個性化信息服務針對性不強,用戶大量流失。提高個性化信息服務針對性,強化用戶使用體驗滿意度,成為高校圖書館個性化信息服務過程中必須解決的難題。
2 大數據環境下高校圖書館建立個性化信息服務系統的可行性
2.1 豐富的數據來源
高校圖書館作為全校的信息資源中心,積累了海量的用戶行為數據,如用戶查詢書目產生的OPAC日志,用戶借還書所產生的借閱信息,用戶瀏覽、下載電子資源所產生的電子數據庫使用痕跡,用戶使用學科化信息服務中與學科館員的互動信息,用戶在圖書館微博中留下的評語,用戶訪問圖書館論壇停留時間等。這些海量數據從側面真實地反映了用戶變化著的信息情境,通過對這些海量數據進行有針對性的挖掘、分析,可真實反映用戶當下的信息情境,進而為圖書館開展個性化信息服務提供決策參考。
2.2 較易識別的目標群體
開展個性化信息服務,需實時跟蹤用戶不斷變化的信息行為,分析用戶的信息需求,進而實現精準定位的信息推送。獲取用戶的信息需求離不開實時的Web數據挖掘,而Web數據挖掘的難題之一是目標用戶的身份識別。對高校圖書館個性化信息服務系統而言,目標群體具有明顯的區分度,較易識別。受經費、版權等因素的制約,目前高校圖書館的服務對象主要是在校師生,師生使用圖書館資源時,其信息均已在圖書館注冊過,通過對師生的信息記錄進行相應的識別,即可準確定位目標群體。此外,高校師生在校園內訪問網絡資源時,其電腦IP地址大都已經在校園網網絡中心注冊過,通過客戶端的用戶名及密碼,可輕松實現目標用戶的精準識別。
2.3 用戶信息需求的實時感知
用戶的信息需求可以通過其相關的信息行為體現出來。對高校師生而言,當他們在教學、科研或學習方面有信息需求時,大都會通過圖書館或互聯網等途徑進行自我服務。在自我服務過程中,后臺服務器能如實記錄用戶的信息行為數據,通過對這些數據的深入挖掘,用戶實時的信息需求顯露無疑。
3 個性化信息服務系統的構建
3.1 系統構建目標
大數據環境下構建高校圖書館個性化信息服務系統,其最終目的是通過對互聯網上用戶使用日志、會話信息、評論信息、搜索查詢記錄、圖書館使用記錄等進行深入挖掘,實時感知用戶變化著的信息需求,進而針對用戶的真實信息情境開展有針對性的個性化信息服務。基于系統的構建目的,系統的構建目標為:在圖書館已有的信息服務平臺及服務模式的基礎上,整合來自不同數據倉庫中的相關記錄,通過Web數據挖掘,感知用戶實時的信息需求,并基于此開展有針對性的個性化信息服務。
3.2 高校圖書館個性化信息服務系統模型[3]
通過對用戶行為數據的實時跟蹤,獲取用戶的信息需求,涉及數據集合、數據規范化、信息分析、信息推送等功能。大數據環境下高校圖書館個性化信息服務系統應包含數據集成模塊、數據規范化處理模塊、信息分析模塊(含結構化數據分析模塊、互聯網日志分析模塊、移動終端位置判定模塊)、信息匹配模塊、信息推送模塊、用戶使用評價模塊。系統模型如圖1。
3.3 高校圖書館個性化信息服務系統模塊功能[4]
3.3.1 數據集成模塊
高校師生的信息行為數據分散地存儲在圖書館不同的自動化系統中,數據集成模塊用于將圖書館信息系統相關記錄、學科化信息服務平臺信息、電子資源使用記錄、網絡日志等多個數據源中的相關數據進行鏈接,將不同來源、不同格式、不同記錄結構、不同含義特點的數據記錄在邏輯上進行有機集中,為數據規范化處理做好準備工作。
3.3.2 數據規范化處理模塊
數據規范化處理模塊用于對集成后數據進行規范化處理,以使數據符合數據挖掘相關算法的需要。數據規范化處理工作流程如圖2所示。

圖2 數據規范化處理模塊流程
合成記錄。圖書館所使用的自動化系統由不同的軟件開發商提供,因彼此之間缺乏溝通協調,各服務供應商的系統數據庫中的數據字段其格式及含義各不相同,要對用戶的信息行為進行挖掘,必須選取唯一標識用戶的數據字段對來自不同系統的用戶行為數據進行有機集合。對高校師生而言,他們使用圖書館的資源,須通過先前辦理的圖書借閱證,因讀者編號具有唯一性,可以將讀者編號作為連接用戶存貯在不同數據庫中的相關記錄的連接標識符。
數據規約。不同數據庫或網絡日志中的信息記錄具有不同的標識及記錄方法,比如讀者信息庫中的性別記錄可能為“男”或“女”;而校園網信息中心用戶網絡日志中的信息記錄可能為“Male”或“Female”,而實際他們具有相同的含義,數據規約功能用來對具有不同屬性名但含義相同的數據進行規范化處理,以達到降低數據歧義,提高數據分析準確性的目的。
數據清理。經合成記錄模塊、數據規約模塊處理后,同一用戶在不同數據庫中的記錄被集中到了同一字段,這些字段值中有的是重復記錄的,需要保留一個屬性值,剔除重復屬性值;有的部分數據不全,對于遺漏的數據信息,需要進行補充;有的數據有誤,需要進行更正;有的部分數值為實數值需要進行離散化處理。數據清理模塊主要用于清除噪聲數據、污染數據、錯誤數據及不一致數據。
數據變換。不同的數據分析及數據挖掘算法對數據具有不同的要求,數據變換模塊主要通過平滑聚集、數據概化等方式將數據轉換成適合數據挖掘算法要求的數據形式。
3.3.3 信息分析模塊
高校師生有信息需求時,多通過3種途徑加以解決。一是通過圖書館提供的相應服務;二是通過互聯網搜索引擎進行信息搜索;三是通過移動互聯網求助社交網。對于用戶的這幾種信息資源利用方式,分別對應產生了結構化信息、半結構化信息和非結構化信息。用戶使用圖書館信息服務時,圖書館大都通過一定的技術手段對用戶的咨詢內容、服務反饋等進行了如實記載,這些記錄大都以規范的表格存儲在相應的數據倉庫中,屬于結構化數據分析模塊處理范疇;用戶利用互聯網進行信息搜索時,會在服務器日志文件中留下使用痕跡,對用戶的網絡信息行為進行相關分析屬于互聯網日志分析模塊功能范疇;用戶使用移動互聯網,利用虛擬人際關系進行信息求助時,其核心節點是人,而非網頁,因此對于移動互聯網日志我們需要采取特殊的信息分析策略來進行有效分析。
①結構化信息分析模塊。結構化信息具有固定與規范的數據格式,該模塊主要對數據聚合、數據規范化處理后的數據進行數據挖掘操作,對數據挖掘后的相關數據進行聚類與分類處理,根據用戶的信息行為,將用戶細分為不同的數據粒度,以識別不同用戶之間相似的信息行為及相同用戶在不同時間段差異性的信息需求行為。
②互聯網日志分析模塊。互聯網日志如實地記錄了用戶對Web服務器的訪問情況,通過對這些數據進行分析,可以快速、準確獲知用戶當前的信息需求。互聯網日志分析模塊分3個工作步驟。

圖1 大數據環境下高校圖書館個性化信息服務系統模型

圖3 互聯網日志分析模塊流程
數據處理模塊主要用于對相關數據進行凈化處理,識別用戶身份,刪除不必要信息以達到縮減數據規模、降低系統響應時延的目的。經數據處理模塊對數據處理后,可形成如下用戶訪問日志(見表1)。
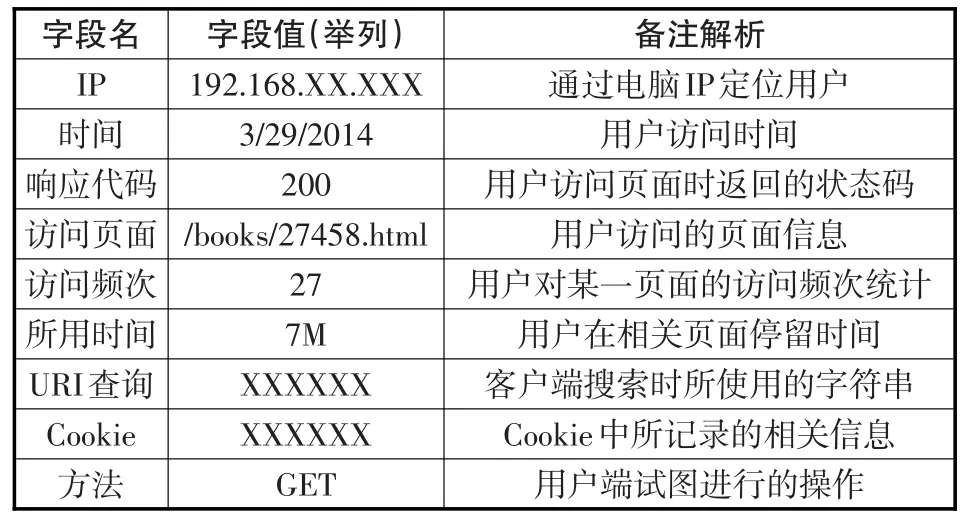
表1 用戶訪問日志
在進行互聯網信息訪問時,用戶有可能不通過網頁上的鏈接功能進行頁面訪問,而是通過瀏覽器的后退功能直接調用緩存在計算機中的歷史記錄來進行訪問。路徑補充模塊用于識別用戶當前頁面信息的原始來源,補充缺失的用戶訪問路徑。
網頁的訪問頻率及停留時間對于判定用戶的信息需求具有重要意義。如果用戶頻繁地訪問某一頁面或在某一頁面上停留了較長時間,則可以認為該頁面是用戶信息需求的一個集中反映。訪問統計模塊用于對用戶在不同時間段訪問的相關頁面進行頻次統計,填寫用戶訪問日志表中的“訪問頻次字段”,為用戶信息需求判斷提供決策參考。
③移動信息分析模塊。隨著智能手機終端、IPAD等各種移動設備的普及,高校師生通過移動終端獲取信息資源已成常態,為改進服務方式,高校圖書館適時推出了微博、微信、掌上圖書館等服務模式,對這些服務模式中所積累的用戶信息進行挖掘,對于個性化信息服務的開展具有重要意義。移動信息分析模塊用于對用戶的移動互聯網瀏覽信息進行挖掘,以獲取用戶的地理位置、興趣點等信息行為特征,根據用戶的興趣點實現信息資源與用戶移動終端的精確匹配。
3.3.4 信息匹配模塊
獲知用戶的實時信息需求后,高校圖書館工作人員在信息匹配模塊針對用戶不同的信息需求,利用館藏資源及互聯網信息資源制定不同的信息服務策略,滿足用戶的個性化信息需求。
3.3.5 信息推送模塊
信息推送模塊用于對不同的用戶進行有針對性的信息推送。系統提供3種信息推送模式,一是用戶借閱相關書籍或使用電子資源時自動給用戶推薦數據挖掘中發現的其他用戶的信息選擇結果,有針對性地推薦用戶尚未發現的信息資源;二是當用戶使用圖書館微博、微信、學科服務時,第一時間根據數據分析的結果,向用戶進行相關信息推薦提示;三是根據用戶的移動終端位置及終端類型,及時向用戶推送其訂閱的相關信息。
3.3.6 用戶使用評價模塊
通過大量的數據挖掘與分析,個性化信息服務系統發現了用戶的行為意圖,并向用戶推送了相關信息。為提高個性化信息服務的針對性,提高系統服務的精準度,用戶在接收相關信息時,可以通過用戶使用評價模塊直接對接收的信息進行評價,系統自動將用戶的評價信息存入后臺的個性化信息服務庫。個性化信息服務庫中的信息積累可以為日后高校圖書館工作人員修正數據挖掘算法提供參考,以改進個性化信息服務系統的服務效果。
4 個性化信息服務系統深入應用思考
4.1 用戶隱私權可能受損
個性化信息服務系統通過對用戶信息行為數據的集成、分析、聚類、分類等相應處理,發現數據之間隱藏著的用戶信息特質,為更好地獲取用戶信息需求,用戶信息行為痕跡被系統實時地監控,無形中增加了用戶隱私權受威脅和侵犯的概率。為保障用戶的隱私權,在進行用戶信息行為數據分析前必須征得用戶本人的同意,同時在數據分析前必須對涉及用戶隱私的相關數據進行相應的數據清洗操作,刪除與個性化信息服務無關的數據,最大程度上避免用戶的隱私權受損[5]。
4.2 數據來源的限制
只有當用戶的信息行為數據達到一定的存儲規模并具有一定的數據耦合度時,才能通過個性化信息分析系統來進行數據的深度挖掘與分析,得到具有較高價值的用戶信息需求特征。個性化信息服務系統的數據來源大部分局限于校園內,對于用戶在校園外的信息行為數據,必須通過與電信服務運營商和移動服務提供商進行溝通協調方能獲得。數據來源的局限性,在一定程度上降低了用戶信息行為特征識別的精準度。
[1]吳新年,陳永平.關于學科化信息服務的思考與建議[J].情報科學,2007(12):1834.
[2]艾春艷,游越,劉素清.讀者參與的高校圖書館學科服務新模式探討[J].大學圖書館學報,2011(5):70.
[3]李善青,趙輝,宋立榮.基于大數據挖掘的科技項目查重模型研究[J].圖書館論壇,2014(2):81.
[4]譚磊.大數據挖掘[M].北京:電子工業出版社,2014.
[5]馬曉亭.大數據時代圖書館個性化服務讀者隱私保護研究[J].圖書館論壇,2014(2):85-87.
欒旭倫男,1982年生,館員。
G252
2014-04-24;責編:王天泥。)
猜你喜歡
大眾投資指南(2021年35期)2021-02-16 01:06:26
小太陽畫報(2018年1期)2018-05-14 17:19:25
電力與能源(2017年6期)2017-05-14 06:19:37
商用汽車(2016年11期)2016-12-19 01:20:16
少年博覽·小學低年級(2016年10期)2016-11-24 06:48:23
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
信息通信技術(2015年6期)2015-12-26 01:16:46
漫畫月刊·炫版(2015年4期)2015-05-27 07:52:10
創業家(2015年5期)2015-02-27 07:53:25
